Kafka¶
Apuntes sin actualizar
Estos apuntes pertenecen al curso 21/22 y, por lo tanto, ya no se actualizan.
Puedes acceder a la última versión de esta sesión en https://aitor-medrano.github.io/iabd2223/dataflow/02kafka.html.
Introducción¶
Apache Kafka es, en pocas palabras, un middleware de mensajería entre sistemas heterogéneos, el cual, mediante un sistema de colas (topics, para ser concreto) facilita la comunicación asíncrona, desacoplando los flujos de datos de los sistemas que los producen o consumen. Funciona como un broker de mensajes, encargado de enrutar los mensajes entre los clientes de un modo muy rápido.
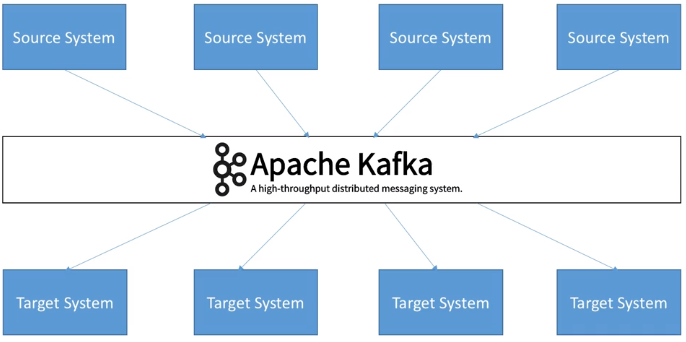
En concreto, se trata de una plataforma open source distribuida de transmisión de eventos/mensajes en tiempo real con almacenamiento duradero y que proporciona de base un alto rendimiento (capaz de manejar billones de peticiones al día, con una latencia inferior a 10ms), tolerancia a fallos, disponibilidad y escalabilidad horizontal (mediante cientos de nodos).
Evento / Mensaje
Dentro del vocabulario asociado a arquitectura asíncronas basadas en productor/consumidor o publicador/suscriptor, se utiliza el mensaje para indicar el dato que viaja desde un punto a otro. En Kafka, además de utilizar el concepto mensaje, se emplea el término evento.
Más del 80% de las 100 compañías más importantes de EEUU utilizan Kafka: Uber, Twitter, Netflix, Spotify, Blizzard, LinkedIn, Spotify, y PayPal procesan cada día sus mensajes con Kafka.
Como sistema de mensajes, sigue un modelo publicador-suscriptor. Su arquitectura tiene dos directivas claras:
- No bloquear los productores (para poder gestionar la back pressure, la cual sucede cuando un publicador produce más elementos de los que un suscriptor puede consumir).
- Aislar los productores y los consumidores, de manera que los productores y los consumidores no se conocen.
A día de hoy, Apache Kafka se utiliza, además de como un sistema de mensajería, para ingestar datos, realizar procesado de datos en streaming y analítica de datos en tiempo real, así como en arquitectura de microservicios y sistemas IOT.
Amazon Kinesis
Amazon Kinesis es un producto similar a Apache Kafka pero dentro de la plataforma AWS, por lo que no es un producto open source como tal. Su principal ventaja es la facilidad de escalabilidad a golpe de click e integración con el resto de servicios que ofrece AWS. Se trata de una herramienta muy utilizada que permite incorporar datos en tiempo real, como vídeos, audios, registros de aplicaciones, secuencias de clicks de sitios web y datos de sensores IoT para machine learning, analítica de datos en streaming, etc...
Publicador / Suscriptor¶
Antes de entrar en detalle sobre Kafka, hay que conocer el modelo publicador/suscriptor. Este patrón también se conoce como publish / subscribe o productor / consumidor.
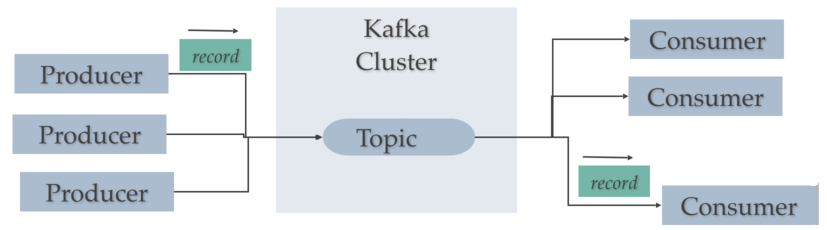
Hay tres elementos que hay que tener realmente claros:
- Publicador (publisher / productor / emisor): genera un dato y lo coloca en un topic como un mensaje.
- topic (tema): almacén temporal/duradero que guarda los mensajes funcionando como una cola.
- Suscriptor (subscriber / consumidor / receptor): recibe el mensaje.
Cabe destacar que un productor no se comunica nunca directamente con un consumidor, siempre lo hace a través de un topic:
Caso 0: Hola Kafka¶
Para arrancar Kafka, vamos a utilizar la instalación que tenemos creada en nuestra máquina virtual.
Kafka mediante Docker
Bitnami tiene una imagen para trabajar con Docker la cual permite probar todos los ejemplos de esta sesión. Para ello, se recomienda seguir los pasos de la página oficial: https://hub.docker.com/r/bitnami/kafka/
El primer paso, una vez dentro de la carpeta de instalación de Kafka (en nuestro caso /opt/kafka_2.13-2.8.1), es arrancar Zookeeper mediante el comando zookeeper-server-start.sh, el cual se encarga de gestionar la comunicación entre los diferentes brokers:
zookeeper-server-start.sh ./config/zookeeper.properties
zookeeper.properties
Del archivo de configuración de Zookeeper conviene destacar dos propiedades:
clientPort: puerto por defecto (2181)dataDir: indica donde está el directorio de datos de Zookeeper (por defecto estmp/zookeeper, pero si queremos que dicha carpeta no se elimine es mejor que apunte a una ruta propia, por ejemplo/opt/zookeeper-data)
Para comprobar que Zookeeper está arrancado, podemos ejecutar el comando lsof -i :2181, el cual escanea el puerto 2181 donde está corriendo Zookeeper.
Una vez comprobado, en un nuevo terminal, arrancamos el servidor de Kafka mediante el comando kafka-server-start.sh (de manera que tenemos corriendo a la vez Zookeeper y Kafka):
kafka-server-start.sh ./config/server.properties
Creando un topic¶
A continuación, en un tercer terminal, vamos a crear un topic mediante el comando kafka-topics.sh:
kafka-topics.sh --create --topic iabd-topic --bootstrap-server iabd-virtualbox:9092
Si queremos obtener la descripción del topic creado con la cantidad de particiones le pasamos el parámetro --describe:
kafka-topics.sh --describe --topic iabd-topic --bootstrap-server iabd-virtualbox:9092
Obteniendo la siguiente información:
Topic: iabd-topic TopicId: ogKnRpOFS7mfOhspLcuB4A PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: iabd-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Produciendo mensajes¶
Para enviar un mensaje a un topic, ejecutaremos en un cuarto terminal un productor mediante el comando kafka-console-producer.sh. Por defecto, cada línea que introduzcamos resultará en un evento separado que escribirá un mensaje en el topic (podemos pulsar CTRL+C en cualquier momento para cancelar):
kafka-console-producer.sh --topic iabd-topic --bootstrap-server iabd-virtualbox:9092
Así pues, escribimos los mensajes que queramos:
>Este es un mensaje
>Y este es otro
>Y el tercero
Consumiendo mensajes¶
Y finalmente, en otro terminal, vamos a consumir los mensajes:
kafka-console-consumer.sh --topic iabd-topic --from-beginning --bootstrap-server iabd-virtualbox:9092
Al ejecutarlo veremos los mensajes que habíamos introducido antes (ya que hemos indicado la opción --from-beginning). Si ahora volvemos a escribir en el productor, casi instantáneamente, aparecerá en el consumidor el mismo mensaje.
Tras esto, paramos todos los procesos que se están ejecutando mediante CTRL+C y hemos finalizado nuestro primer contacto con Kafka.
Elementos¶
Dentro de una arquitectura con Kafka, existen múltiples elementos que interactúan entre sí.
Topic y Particiones¶
Un topic (¿tema?) es un flujo particular de datos que funciona como una cola almacenando de forma temporal o duradera los datos que se colocan en él.
Podemos crear tantos topics como queramos y cada uno de ellos tendrá un nombre unívoco.
Un topic se divide en particiones, las cuales se numeran, siendo la primera la 0. Al crear un topic hemos de indicar la cantidad de particiones inicial, la cual podemos modificar a posteriori. Cada partición está ordenada, de manera que cada mensaje dentro de una partición tendrá un identificador incremental, llamado offset (desplazamiento). Cada partición funciona como un commit log almacenando los mensajes que recibe.
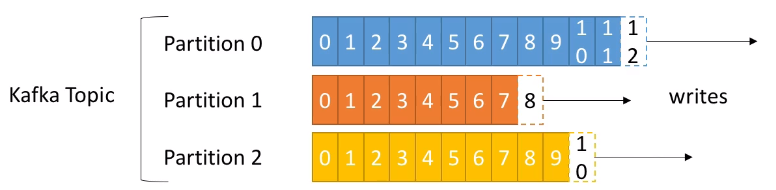
Como podemos observar en la imagen, cada partición tiene sus propios offset (el offset 3 de la partición 0 no representa el mismo dato que el offset 3 de la partición 1).
Habíamos comentado que las particiones están ordenadas, pero el orden sólo se garantiza dentro de una partición (no entre particiones), es decir, el mensaje 7 de la partición 0 puede haber llegado antes, a la vez, o después que el mensaje 5 de la partición 1.
Los datos de una partición tiene un tiempo de vida limitado (retention period) que indica el tiempo que se mantendrán los mensajes antes de eliminarlos. Por defecto es de una semana. Además, una vez que los datos se escriben en una partición, no se pueden modificar (las mensajes son immutables).
Finalmente, por defecto, los datos se asignan de manera aleatoria a una partición. Sin embargo, existe la posibilidad de indicar una clave de particionado.
Brokers¶
Un clúster de Kafka está compuesto de múltiples nodos conocidos como Brokers, donde cada broker es un servidor de Kafka. Cada broker se identifica con un id, el cual debe ser un número entero.
Cada broker contiene un conjunto de particiones, de manera que un broker contiene parte de los datos, nunca los datos completos ya que Kafka es un sistema distribuido. Al conectarse a un broker del clúster (bootstrap broker), automáticamente nos conectaremos al clúster entero.
Para comenzar se recomienda una arquitectura de 3 brokers, aunque algunos clústers lo forman cerca de un centenar de brokers.
Por ejemplo, el siguiente gráfico muestra el topic A dividido en tres particiones, cada una de ellas residiendo en un broker diferente (no hay ninguna relación entre el número de la partición y el nombre del broker), y el topic B dividido en dos particiones:
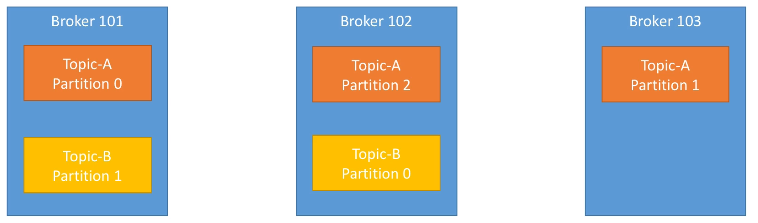
En el caso de haber introducido un nuevo topic con 4 particiones, uno de los brokers contendría dos particiones.
Factor de replicación¶
Para soportar la tolerancia a fallos, los topics deben tener un factor de replicación mayor que uno (normalmente se configura entre 2 y 3).
En la siguiente imagen podemos ver como tenemos 3 brokers, y un topic A con dos particiones y una factor de replicación de 2, de manera que cada partición crea un replica de si misma:
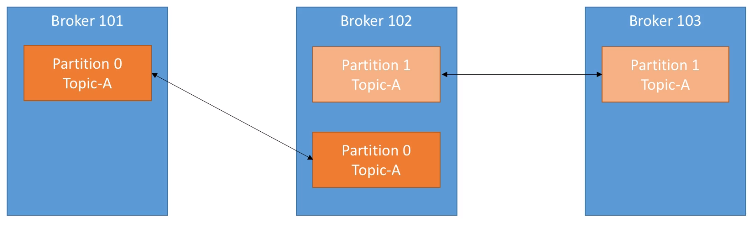
Si se cayera el broker 102, Kafka podría devolver los datos al estar disponibles en los nodos 101 y 103.
Réplica líder¶
Acabamos de ver que cada broker tiene múltiples particiones, y cada partición tiene múltiples réplicas, de manera que si se cae un nodo/broker, Kafka puede utilizar otro broker para servir los datos.
En cualquier instante, una determinada partición tendrá una única réplica que será la líder, y esta réplica líder será la única que pueda recibir y servir los datos de una partición. La réplica líder es importante porque todas las lecturas y escrituras siempre van a esta réplica. El resto de brokers sincronizarán sus datos. En resume, cada partición tendrá un líder y múltiples ISR (in-sync replica).
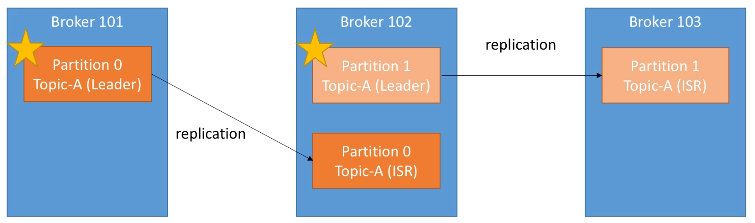
Si se cayera el Broker 101 , entonces la partición 0 del Broker 102 se convertiría en la líder. Y cuando vuelva a funcionar el Broker 101, intentará volver a ser la partición líder.
Productores¶
Los productores escriben datos en los topics, sabiendo automáticamente el broker y la partición en la cual deben escribir. En el caso de un fallo de un broker, los productores automáticamente se recuperan y se comunican con el broker adecuado.
Si el productor envía los datos sin una clave determinada, Kafka realiza una algoritmo de Round Robin, de manera que cada mensaje se va alternando entre los diferentes brokers.
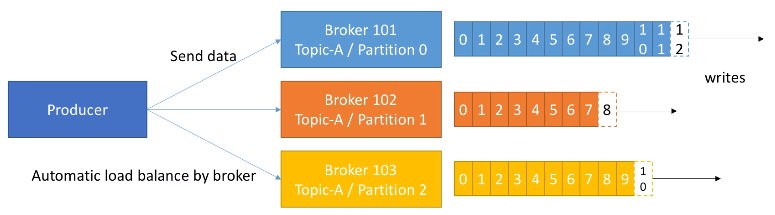
Podemos configurar los productores para que reciban un ACK de las escrituras de los datos con los siguientes valores:
ack=0: El productor no espera la confirmación (posible pérdida de datos).ack=1: El productor espera la confirmación del líder (limitación de la pérdida de datos).ack=all: El productores espera la confirmación del líder y de todas las réplicas (sin pérdida de datos).
Clave de mensaje¶
Los productores pueden enviar una clave con el mensaje (de tipo cadena, numérico, etc...). Cuando la clave no se envía, ya hemos comentado que los datos se envían mediante Round Robin (primero Broker 101, luego el 102, el 103, etc... y vuelta al 101).
Si se envía la clave, todos los mensajes con la misma clave siempre irán a la misma partición. Por lo tanto, enviaremos una clave cuando necesitemos ordenar los mensajes por un campo específico (por ejemplo, el identificador de una operación).
Consumidores¶
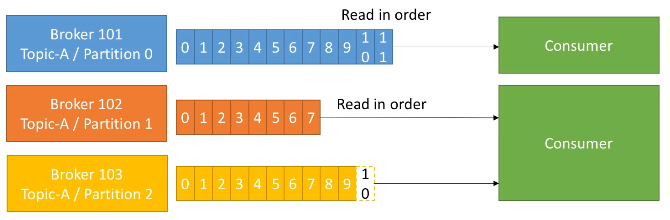
Los consumidores obtienen los datos de los topics y las particiones, y saben de qué broker deben leer los datos. Igual que los productores, en el caso de un fallo de un broker, los consumidores automáticamente se recuperan y se comunican con el broker adecuado.
Los datos se leen en orden dentro de cada partición, de manera que el consumidor no podrá leer, por ejemplo, los datos del offset 6 hasta que no haya leído los del offset 5. Además, un consumidor puede leer de varias particiones (se realiza en paralelo), pero el orden sólo se respeta dentro de cada partición, no entre particiones:
Grupo de consumidores¶
Un consumidor puede pertenecer a un grupo de consumidores, de manera que cada uno de los consumidores del grupo obtendrán una parte de los datos, es decir, una partición de un topic.
Por ejemplo, tenemos una aplicación compuesta de dos consumidores, formando un grupo de consumidores. El consumidor 1 lo hará de dos particiones, y el consumidor 2 lo hará de la tercera partición. También tenemos otra aplicación compuesta de tres consumidores, de manera que cada consumidor lo hará de cada una de las particiones. Finalmente, tenemos un tercer grupo de consumidores formado por un único consumidor que leerá las tres particiones. En conclusión, cada grupo de consumidores funciona como un único consumidor de manera que accede a todas las particiones de un topic.
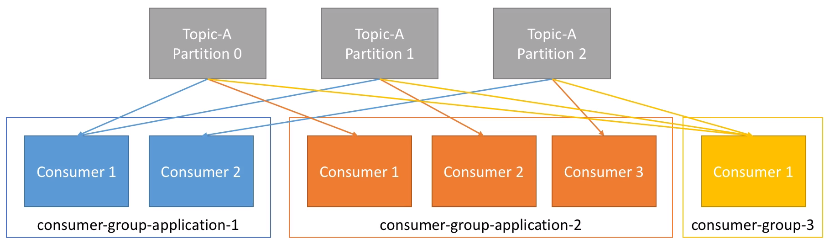
Coordinando los consumidores
Los consumidores, por sí solos, no saben con que partición se deben comunicar. Para ello, se utiliza un GroupCoordinator y un Consumer Coordinator para asignar los consumidores a cada partición. Esta gestión la realiza Kafka.
Cabe destacar que los diferentes grupos de consumidores reciben el mismo dato de cada partición, es decir, el consumidor 1 del grupo 1 y el consumidor 1 del grupo 2 reciben la información que había en la partición 0. Este caso de uso es muy útil cuando tenemos dos aplicaciones que queremos que reciban los mismos datos (por ejemplo, uno encargado de realizar machine learning y otro analítica de datos).
En el caso de tener más consumidores que particiones, algunos consumidores no realizarán nada. Este caso de uso es atípico, ya que lo recomendable es tener tantos consumidores como el mayor número de particiones existentes.
Probando los grupos de consumidores¶
Vamos a simular el gráfico anterior mediante un ejemplo con el terminal. Primero crearemos un topic que contenga tres particiones:
kafka-topics.sh --create --topic iabd-topic-group \
--bootstrap-server iabd-virtualbox:9092 --partitions 3
Si comprobamos el estado del topic mediante:
kafka-topics.sh --describe --topic iabd-topic-group \
--bootstrap-server iabd-virtualbox:9092
Obtendremos la siguiente información:
Topic: iabd-topic-group TopicId: p1i3m4fMRximngLjAV5rsA PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: iabd-topic-group Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: iabd-topic-group Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: iabd-topic-group Partition: 2 Leader: 0 Replicas: 0 Isr: 0
A continuación, en dos pestañas diferentes, vamos a crear dos consumidores que pertenezcan al mismo grupo de consumidores:
kafka-console-consumer.sh --topic iabd-topic-group \
--group iabd-app1 \
--bootstrap-server iabd-virtualbox:9092
Y finalmente, creamos un nuevo productor sobre el topic:
kafka-console-producer.sh --topic iabd-topic-group \
--bootstrap-server iabd-virtualbox:9092
Y si creamos varios mensajes en el productor, veremos cómo van llegando de manera alterna a los diferentes consumidores:
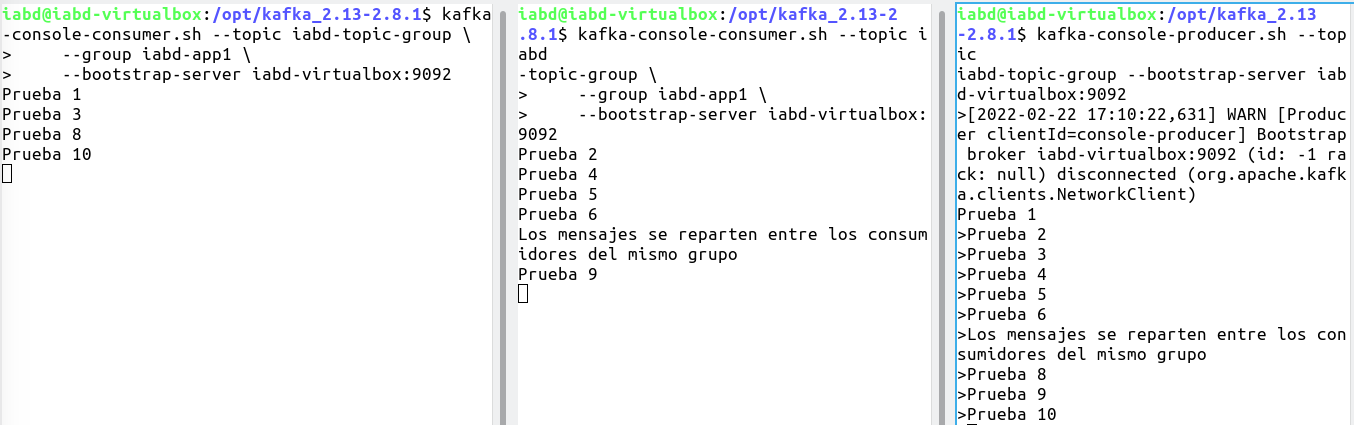
Autoevaluación
- ¿Que sucederá se creamos un nuevo consumidor que lo haga del mismo topic pero con un grupo de consumidores diferente (por ejemplo,
iabd-app2) y le pedimos que lea los mensajes desde el principio (mediante--from-beginning) ?
Que aparecerán todos los mensajes desde el principio. - ¿Y si lo detenemos y volvemos a crear el mismo consumidor (también con el grupo de consumidores
iabd-app2y los vuelva a leer desde el principio también)?
En esta ocasión, ya no recibirá ningún mensaje, ya que el primer consumidor hace commit de la lectura y el segundo al hacerlo desde el mismo grupo de consumidores ya tiene los mensajes previos marcados como leídos. - ¿Y si detenemos todos los consumidores y seguimos creando mensajes en el productor?
Los mensajes se almacenan en el topic. - ¿Y si arrancamos de nuevo un consumidor sobre el grupo de consumidores
iabd-app2?
Que consumirá los mensajes que acabamos de crear.
Mediante el comando kafka-consumer-groups.sh podemos obtener sobre los diferentes grupos de consumidores que tenemos creado, así como eliminarlos o resetear sus offsets.
Por ejemplo, si queremos listar los grupos de consumidores existentes ejecutaremos:
kafka-consumer-groups.sh --list \
--bootstrap-server iabd-virtualbox:9092
En cambio, si queremos obtener la información de un determinado grupo ejecutaremos:
kafka-consumer-groups.sh --describe --group iabd-app1 \
--bootstrap-server iabd-virtualbox:9092
Obteniendo información a destacar como:
CURRENT-OFFSET: valor actual del offsetLOG-END-OFFSET: offset del último mensaje de la particiónLAG: cantidad de mensajes pendientes de leer
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
iabd-app1 iabd-topic-group 0 4 4 0 consumer-iabd-app1-1-405b2b39-2252-4e12-ba55-00a579441df2 /127.0.0.1 consumer-iabd-app1-1
iabd-app1 iabd-topic-group 1 2 2 0 consumer-iabd-app1-1-405b2b39-2252-4e12-ba55-00a579441df2 /127.0.0.1 consumer-iabd-app1-1
iabd-app1 iabd-topic-group 2 4 4 0 consumer-iabd-app1-1-8f09bc45-8e8c-46d2-9c9c-cf6bd3a5fdc7 /127.0.0.1 consumer-iabd-app1-1
Si por ejemplo, con todos los consumidores detenidos, mediante un productor lanzamos 5 mensajes nuevos, estos se quedarán en el topic a la espera de ser consumidos, y se habrán repartidos entre las diferentes particiones. Si volvemos a lanzar el comando anterior obtendríamos:
Consumer group 'iabd-app1' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
iabd-app1 iabd-topic-group 2 4 5 1 - - -
iabd-app1 iabd-topic-group 1 2 4 2 - - -
iabd-app1 iabd-topic-group 0 4 6 2 - - -
Offsets de Consumidor¶
Kafka almacena los offsets por el que va leyendo un grupo de consumidores, a modo de checkpoint, en un topic llamado __consumer_offsets.
Cuando un consumidor de un grupo ha procesado los datos que ha leído de Kafka, realizará un commit de sus offsets. Si el consumidor se cae, podrá volver a leer los mensajes desde el último offset sobre el que se realizó commit.
Por ejemplo, supongamos que tenemos un consumidor el cual ha hecho un commit tras el offset 4262. Tras el commit seguimos leyendo los siguientes mensajes: 4263, 4264, 4265 y de repente el consumidor se cae sin haber hecho commit de esos mensajes. Cuando el consumidor vuelva a funcionar, volverá a leer los mensajes desde el 4263, asegurándose que no se ha quedado ningún mensaje sin procesar.
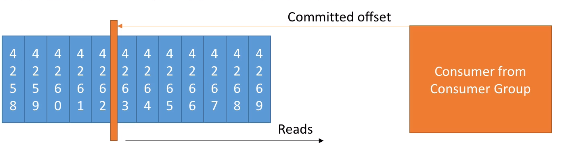
El commit de los mensajes está muy relacionado con la semántica de la entrega. Los consumidores eligen cuando realizar el commit de los offsets:
- As most once: se realiza el commit del mensaje tan pronto como se recibe el mensaje. Si falla su procesamiento, el mensaje se perderá (y no se volverá a leer).
- At least once (opción más equilibrada): El commit se realiza una vez procesado el mensaje. Este enfoque puede resultar en un procesado duplicado de los mensajes, por lo que hemos de asegurarnos que son idempotentes (el volver a procesar un mensaje no tendrá un impacto en el sistema)
- Exactly once: sólo se puede conseguir utilizando flujos de trabajo de Kafka con Kafka mediante el API de Kafka Streams. Si necesitamos la interacción de Kafka con un sistema externo, como una base de datos, se recomienda utilizar un consumidor idempotente que nos asegura que no habrá duplicados en la base de datos.
Descubrimiento de brokers¶
Cada broker de Kafka es un bootstrap server, lo que significa que dicho servidor contiene un listado con todos los nodos del clúster, de manera que al conectarnos a un broker, automáticamente nos conectaremos al clúster entero.
Mediante esta configuración, cada broker conoce todos los brokers, topics y particiones (metadatos del clúster).
Así pues, cuando un cliente se conecta a un broker, también realiza una petición de los metadatos, y obtiene un listado con todos los brokers. Tras ello, ya puede conectarse a cualquiera de los brokers que necesite:
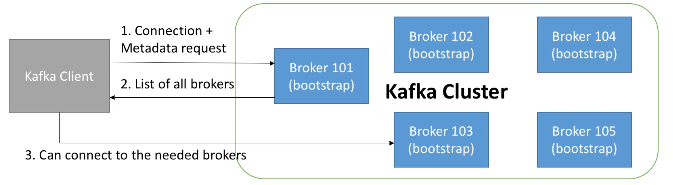
Zookeeper¶
En la primera sesión de Hadoop ya vimos que ZooKeeper es un servicio para mantener la configuración, coordinación y aprovisionamiento de aplicaciones distribuidas dentro del ecosistema de Apache. No sólo se utiliza en Hadoop, pero es muy útil ya que elimina la complejidad de la gestión distribuida de la plataforma.
En el caso de Kafka, Zookeeper:
- gestiona los brokers (manteniendo una lista de ellos).
- ayuda en la elección de la partición líder
- envía notificaciones a Kafka cuando hay algún cambio (por ejemplo, se crea un topic, se cae un broker, se recupera un broker, al eliminar un topic, etc...).
Por todo ello, Kafka no puede funcionar sin Zookeeper.
En un entorno real, se instalan un número impar de servidores Zookeeper (3, 5, 7). Para su gestión, Zookeeper define un líder (gestiona las escrituras) y el resto de servidores funcionan como réplicas de lectura.
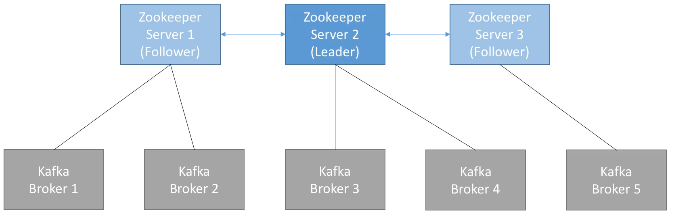
Pese a su dependencia, los productores y consumidores no interactúan nunca con Zookeeper, sólo lo hacen con Kafka.
Kafka garantiza que...
- Los mensajes se añaden a una partición/topic en el orden en el que se envían
- Los consumidores leen los mensajes en el orden en que se almacenaron en la partición/topic
- Con un factor de replicación N, los productores y consumidores pueden soportar que se caigan N-1 brokers.
- Por ejemplo, con un factor de replicación de 3 (el cual es un valor muy apropiado), podemos tener un nodo detenido para mantenimiento y podemos permitirnos que otro de los nodos se caiga de forma inesperada.
- Mientras el número de particiones de un topic permanezca constante (no se hayan creado nuevas particiones), la misma clave implicará que los mensajes vayan a la misma partición.
Caso 1: Kafka y Python¶
Para poder producir y consumir mensajes desde Python necesitamos instalar la librería Kafka-python:
pip install kafka-python
KafkaConsumer¶
Vamos a crear un consumidor, mediante un KafkaConsumer, que escuche de nuestro servidor de Kafka:
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'iabd-topic',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='iabd-grupo-1',
value_deserializer=lambda m: loads(m.decode('utf-8')),
bootstrap_servers=['iabd-virtualbox:9092'])
for m in consumer:
print(m.value)
Al crear el consumidor, configuramos los siguientes parámetros:
- en el primer parámetro indicamos el topic desde el que vamos a consumir los mensajes
bootstrap_servers: listado de brokers de Kafkaauto_offset_reset: le indica al consumidor desde donde empezar a leer los mensaje si se cae:earliestse moverá hasta el mensaje más antiguo ylatestal más reciente.enable_auto_commit: siTrue, el offset del consumidor realizará periódicamente commit en segundo plano.value_deserializer: método utilizado para deserializar los datos. En este caso, transforma los datos recibidos en JSON.
KafkaProducer¶
Y para el productor, mediante un KafkaProducer, vamos a enviar 10 mensajes en formato JSON:
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(
value_serializer=lambda m: dumps(m).encode('utf-8'),
bootstrap_servers=['iabd-virtualbox:9092'])
for i in range(10):
producer.send("iabd-topic", value={"nombre": "producer " + str(i)})
# Como el envío es asíncrono, para que no se salga del programa antes de enviar el mensaje, esperamos 1 seg
time.sleep(1)
# producer.flush()
Tras ejecutar ambos programas en pestañas diferentes, en la salida del consumidor recibiremos:
{'nombre': 'producer 0'}
{'nombre': 'producer 1'}
{'nombre': 'producer 2'}
{'nombre': 'producer 3'}
{'nombre': 'producer 4'}
{'nombre': 'producer 5'}
{'nombre': 'producer 6'}
{'nombre': 'producer 7'}
{'nombre': 'producer 8'}
{'nombre': 'producer 9'}
Caso 2: Clúster de Kafka¶
En Kafka hay tres tipos de clústers:
- Un nodo con un broker
- Un nodo con muchos brokers
- Muchos nodos con múltiples brokers
Para nuestro ejemplo, como sólo disponemos de una máquina, vamos a crear 3 brokers en un nodo.
Creando brokers¶
Para ello, vamos a crear diferentes archivos de configuración a partir del archivo config/server.properties que utilizábamos para arrancar el servidor.
Así pues, crearemos 3 copias del archivo modificando las propiedades broker.id (identificador del broker), listeners (URL y puerto de escucha del broker) y log.dirs (carpeta donde se guardaran los logs del broker):
broker.id=101
listeners=PLAINTEXT://:9092
log.dirs=/opt/kafka_2.13-2.8.1/logs/broker_101
zookeeper.connect=localhost:2181
broker.id=102
listeners=PLAINTEXT://:9093
log.dirs=/opt/kafka_2.13-2.8.1/logs/broker_102
zookeeper.connect=localhost:2181
broker.id=103
listeners=PLAINTEXT://:9094
log.dirs=/opt/kafka_2.13-2.8.1/logs/broker_103
zookeeper.connect=localhost:2181
Una vez creados los tres archivos, ejecutaremos los siguientes comandos (cada uno en un terminal diferente) para arrancar Zookeeper y cada uno de los brokers:
zookeeper-server-start.sh ./config/zookeeper.properties
kafka-server-start.sh ./config/server101.properties
kafka-server-start.sh ./config/server102.properties
kafka-server-start.sh ./config/server103.properties
Creando topics¶
Con cada comando que vayamos a interactuar con Kafka, le vamos a pasar como parámetro --bootstrap-server iabd-virtualbox:9092 para indicarle donde se encuentra uno de los brokers (en versiones antiguas de Kafka se indicaba donde estaba Zookeeper mediante --zookeeper iabd-virtualbox:9092).
A la hora de crear un topic, además de indicarle donde está Zookeeper y el nombre del topic, indicaremos:
- la cantidad de particiones con el parámetro
--partitions - el factor de replicación con el parámetro
--replication-factor
Así pues, vamos a crear un topic con tres particiones y factor de replicación 2:
kafka-topics.sh --create --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092 \
--partitions 3 --replication-factor 2
Si ahora obtenemos la información del topic
kafka-topics.sh --describe --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092
Podemos observar como cada partición tiene la partición líder en un broker distinto y en qué brokers se encuentran las réplicas:
Topic: iabd-topic-3p2r TopicId: lyrv4qXkS1-c09XAXnIj7w PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: iabd-topic-3p2r Partition: 0 Leader: 103 Replicas: 103,102 Isr: 103,102
Topic: iabd-topic-3p2r Partition: 1 Leader: 102 Replicas: 102,101 Isr: 102,101
Topic: iabd-topic-3p2r Partition: 2 Leader: 101 Replicas: 101,103 Isr: 101,103
Produciendo y consumiendo¶
Respecto al código Python, va a ser el mismo que hemos visto antes pero modificando:
- el nombre del topic
- la lista de boostrap_servers (aunque podríamos haber dejado únicamente el nodo principal, ya que Kafka le comunica al cliente el resto de nodos del clúster, es una buena práctica por si el nodo al que nos conectamos de manera explícita está caído).
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(
value_serializer=lambda m: dumps(m).encode('utf-8'),
bootstrap_servers=['iabd-virtualbox:9092','iabd-virtualbox:9093','iabd-virtualbox:9094'])
for i in range(10):
producer.send("iabd-topic-3p2r", value={"nombre": "producer " + str(i)}, key=b"iabd")
# Como el envío es asíncrono, para que no se salga del programa antes de enviar el mensaje, esperamos 1 seg
time.sleep(1)
En el consumidor, además hemos modificado la forma de mostrar los mensajes para visualizar más información:
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'iabd-topic-3p2r',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='iabd-grupo-1',
value_deserializer=lambda m: loads(m.decode('utf-8')),
bootstrap_servers=['iabd-virtualbox:9092','iabd-virtualbox:9093','iabd-virtualbox:9094'])
for m in consumer:
print(f"P:{m.partition} O:{m.offset} K:{m.key} V:{m.value}")
Como ahora tenemos los datos repartidos en dos brokers (por el factor de replicación) y tres particiones, los datos consumidos no tienen por qué llegar en orden (como es el caso), ya que los productores han enviado los datos de manera aleatoria para repartir la carga:
P:1 O:0 K:None V:{'nombre': 'producer 0'}
P:1 O:1 K:None V:{'nombre': 'producer 3'}
P:2 O:0 K:None V:{'nombre': 'producer 1'}
P:2 O:1 K:None V:{'nombre': 'producer 5'}
P:2 O:2 K:None V:{'nombre': 'producer 6'}
P:2 O:3 K:None V:{'nombre': 'producer 7'}
P:2 O:4 K:None V:{'nombre': 'producer 8'}
P:0 O:0 K:None V:{'nombre': 'producer 2'}
P:0 O:1 K:None V:{'nombre': 'producer 4'}
P:0 O:2 K:None V:{'nombre': 'producer 9'}
Para asegurarnos el orden, debemos enviar los mensajes con una clave de partición con el atributo key del método send:
producer.send("iabd-topic-3p2r",
value={"nombre": "producer " + str(i)},
key=b"iabd")
Si volvemos a ejecutar el productor con esa clave, el resultado sí que sale ordenado:
P:0 O:3 K:b'iabd' V:{'nombre': 'producer 0'}
P:0 O:4 K:b'iabd' V:{'nombre': 'producer 1'}
P:0 O:5 K:b'iabd' V:{'nombre': 'producer 2'}
P:0 O:6 K:b'iabd' V:{'nombre': 'producer 3'}
P:0 O:7 K:b'iabd' V:{'nombre': 'producer 4'}
P:0 O:8 K:b'iabd' V:{'nombre': 'producer 5'}
P:0 O:9 K:b'iabd' V:{'nombre': 'producer 6'}
P:0 O:10 K:b'iabd' V:{'nombre': 'producer 7'}
P:0 O:11 K:b'iabd' V:{'nombre': 'producer 8'}
P:0 O:12 K:b'iabd' V:{'nombre': 'producer 9'}
Decisiones de rendimiento¶
Aunque podemos modificar la cantidad de particiones y el factor de replicación una vez creado el clúster, es mejor hacerlo de la manera correcta durante la creación ya que tienen un impacto directo en el rendimiento y durabilidad del sistema:
- si el número de particiones crece con el clúster ya creado, el orden de las claves no está garantizado.
- si se incrementa el factor de replicación durante el ciclo de vida de un topic, estaremos metiendo presión al clúster, que provocará un decremento inesperado del rendimiento.
Cada partición puede manejar un rendimiento de unos pocos MB/s. Al añadir más particiones, obtendremos mejor paralelización y por tanto, mejor rendimiento. Además, podremos ejecutar más consumidores en un grupo. Pero el hecho de añadir más brokers al clúster para que las particiones los aprovechen, provocará que Zookeeper tenga que realizar más elecciones y que Kafka tenga más ficheros abiertos.
Guía de rendimiento
Una propuesta es:
- Si nuestro clúster es pequeño (menos de 6 brokers), crear el doble de particiones que brokers.
- Si tenemos un clúster grande (más de 12 brokers), crear la misma cantidad de particiones que brokers.
- Ajustar el número de consumidores necesarios que necesitamos que se ejecuten en paralelo en los picos de rendimiento.
Independientemente de la decisión que tomemos, hay que realizar pruebas de rendimiento con diferentes configuraciones.
Respecto al factor de replicación, debería ser, al menos 2, siendo 3 la cantidad recomendada (es necesario tener al menos 3 brokers) y no sobrepasar de 4. Cuanto mayor sea el factor de replicación (RF):
- El sistema tendrá mejor tolerancia a fallos (se pueden caer RF-1 brokers)
- Pero tendremos mayor replicación (lo que implicará una mayor latencia si
acks=all) - Y también ocupará más espacio en disco (50% más si RF es 3 en vez de 2).
Respecto al clúster, se recomienda que un broker no contenga más de 2000-4000 particiones (entre todos los topics de ese broker). Además, un clúster de Kafka debería tener un máximo de 20.000 particiones entre todos los brokers, ya que si se cayese algún nodo, Zookeeper necesitaría realizar muchas elecciones de líder.
Caso 3: De Twitter a Elasticsearch con Python¶
A continuación vamos a crear un ejemplo completo de flujo de datos mediante Python que nos permita recoger tweets y meterlos dentro de ElasticSearch.
Vamos a suponer que ya disponemos de una cuenta de Twitter y que tenemos las credenciales de acceso, las cuales vamos a almacenar en un fichero denominado credential.py:
API_KEY = 'YOUR_API_KEY'
API_SECRET_KEY = 'YOUR_API_SECRET_KEY'
ACCESS_TOKEN = 'YOUR_ACCESS_TOKEN'
ACCESS_TOKEN_SECRET = 'YOUR_ACCESS_TOKEN_SECRET'
Tweepy¶
Para acceder a Twitter desde Python, la librería por excelencia es Tweepy, la cual instalaremos mediante:
pip install tweepy
A continuación, vamos a realizar el proceso de autenticación en Tweepy y recoger el timeline de mi usuario:
import credentials
import tweepy
# Nos autenticamos mediante OAuth
auth = tweepy.OAuthHandler(credentials.API_KEY, credentials.API_SECRET_KEY)
auth.set_access_token(credentials.ACCESS_TOKEN, credentials.ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
miTimeline = api.home_timeline()
for tweet in miTimeline:
print(f'{tweet.user.screen_name}:\n{tweet.text}\n{"*"*60}')
Productor de Tweets¶
En este caso de uso vamos a buscar los tweets que contengan la palabra bigdata y meterlos en un topic de Kafka. Así pues, en vez de obtener el timeline de un usuario, realizaremos una búsqueda mediante la función search y para cada elemento recuperado, lo enviaremos al productor con toda la información (seguimos un planteamiento ELT).
Primero creamos el topic:
kafka-topics.sh --create --topic iabd-twitter --bootstrap-server iabd-virtualbox:9092
Y a continuación desarrollamos el productor:
import credentials
import tweepy
from kafka import KafkaProducer
from json import dumps
import time
# Creamos el productor de Kafka
producer = KafkaProducer(
value_serializer=lambda m: dumps(m).encode('utf-8'),
bootstrap_servers=['iabd-virtualbox:9092'])
# Nos autenticamos mediante OAuth en Twitter
auth = tweepy.OAuthHandler(credentials.API_KEY, credentials.API_SECRET_KEY)
auth.set_access_token(credentials.ACCESS_TOKEN, credentials.ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
# Cargamos 500 tweets
id = None
cantidad = 0
while cantidad <= 500:
tweets = api.search_tweets(q='bigdata', tweet_mode='extended', max_id=id)
for tweet in tweets:
producer.send("iabd-twitter", value=tweet._json)
cantidad += 1
# Al final del ciclo le asignamos el id del último tweet
# para que en cada ciclo se consulten solo los tweets hasta el más antiguos del ciclo anterior
id = tweet.id
# Como el envío es asíncrono, para que no se salga del programa antes de enviar el último mensaje, esperamos 1 seg
time.sleep(1)
Elasticsearch desde Python¶
Para poder acceder a Elasticsearch desde Python necesitamos descargar la librería:
pip install elasticsearch
El siguiente fragmento muestra varias operaciones básicas y como las operaciones REST de Elasticsearch se traducen en métodos:
from datetime import datetime
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
doc1 = {
'author': 'Aitor Medrano',
'text': 'Prueba de texto desde Python',
'timestamp': datetime.now(),
}
doc2 = {
'author': 'Aitor Medrano',
'text': 'Y otra #prueba desde @Python',
'timestamp': datetime.now(),
}
# Inserción
resp = es.index(index="prueba", id=1, document=doc1)
resp = es.index(index="prueba", id=2, document=doc2)
print(resp['result'])
# Recuperación
resp = es.get(index="prueba", id=1)
print(resp['_source'])
es.indices.refresh(index="prueba")
# Búsqueda
resp = es.search(index="prueba", query={"match_all": {}})
print("Encontrados %d Hits:" % resp['hits']['total']['value'])
for hit in resp['hits']['hits']:
print("%(timestamp)s %(author)s: %(text)s" % hit["_source"])
resp = es.index(index="prueba", id=1, document=doc1)
resp = es.index(index="prueba", id=2, document=doc2)
updated
resp = es.get(index="prueba", id=1)
{'author': 'Aitor Medrano', 'text': 'Prueba de texto desde Python', 'timestamp': '2022-02-25T15:11:43.720820'}
es.indices.refresh(index="prueba")
resp = es.search(index="prueba", query={"match_all": {}})
Encontrados 2 Hits:
2022-02-25T15:11:43.720820 Aitor Medrano: Prueba de texto desde Python
2022-02-25T15:11:43.720826 Aitor Medrano: Y otra #prueba desde @Python
Consumidor en Elasticsearch¶
Finalmente, vamos a crear un consumidor que se conecte a Kafka para consumir los mensajes, e introduzca cada uno de los tuits en Elasticsearch:
from datetime import datetime
from elasticsearch import Elasticsearch
from kafka import KafkaConsumer
from json import loads
import ast
es = Elasticsearch("http://localhost:9200")
consumer = KafkaConsumer(
'iabd-twitter',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='iabd-caso3',
value_deserializer=lambda m: loads(m.decode('utf-8')),
bootstrap_servers=['iabd-virtualbox:9092'])
cantidad = 1
for m in consumer:
tweet = m.value
# print(type(tweet))
# tweet = ast.literal_eval(m.value)
# print(tweet['user'])
# doc = {
# 'user': m.value.user.screen_name,
# 'text': m.value.full_text,
# 'created_at': m.value.created_at,
# 'likes': m.value.favourite_count
# }
resp = es.index(index="iabd-twitter-es", id=cantidad, document=tweet)
cantidad += 1
# Forzamos que se persistan los cambios
es.indices.refresh(index="iabd-twitter-es")
Si accedemos a http://localhost:9200/iabd-twitter-es/_search?pretty podremos ver como Elasticsearch contiene los tuits que habíamos producido previamente:
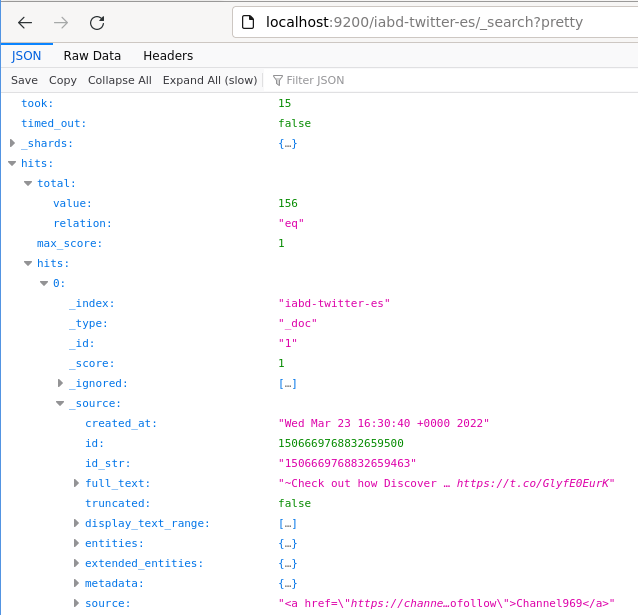
Todo en uno con Nifi¶
Vamos a realizar un flujo de datos en Nifi para el mismo caso de uso que acabamos de desarrollar. Para ello, vamos a crear dos grupos de procesos para tener los flujos ordenados:
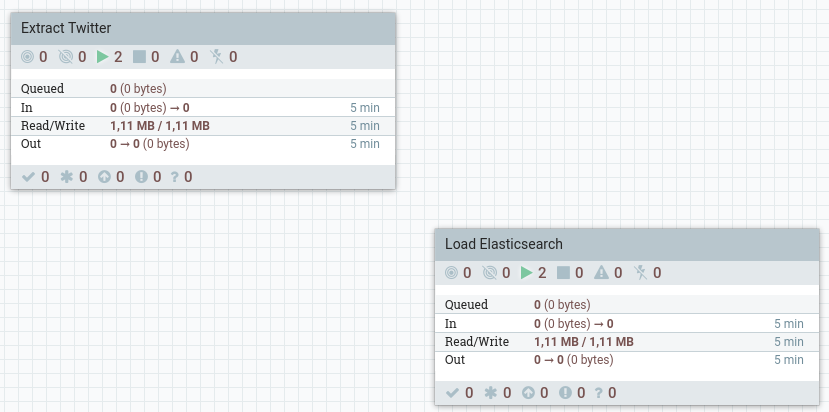
En el primer grupo, que hemos denominado Extract Twitter, vamos a realizar la carga desde Twitter (filtrando los mensajes que contengan la palabra bigdata) y los vamos a meter en el topic iabd-twitter.
Para ello, conectaremos los siguientes procesadores:
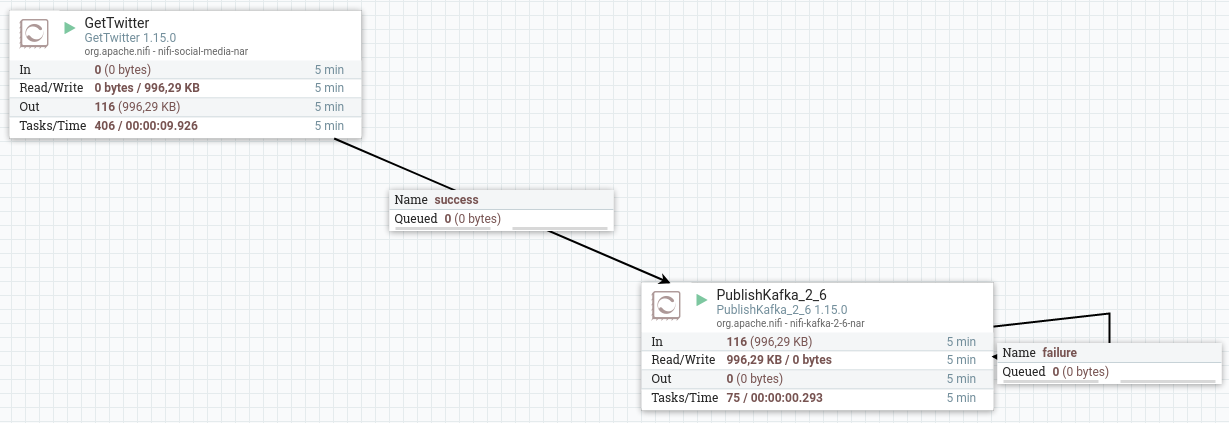
- GetTwitter: tras introducir los valores para autenticarnos en Twitter, configuraremos como endpoint que sea de tipo Filter Endpoint y como término a filtrar bigdata (no olvides poner las claves de autenticación).
- PublishKafka_2_6: en este procesador, además del topic
iabd-twitter, indicaremos que no utilizaremos transacciones (Use Transactions: false), así como que intente garantizar la entrega (*Delivery Guarantee: Best Effort):
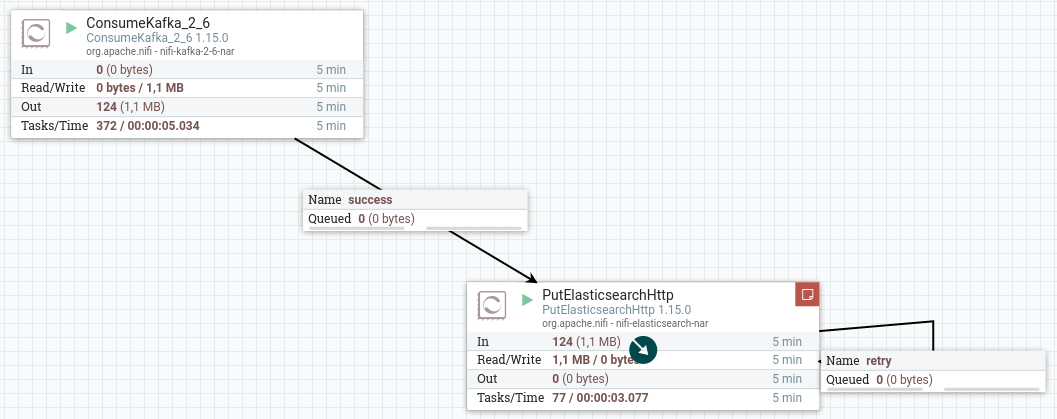
Del mismo modo, dentro del segundo grupo (Load Elasticsearch), conectaremos los siguientes procesadores:
- ConsumerKafka_2_6: donde consumiremos los mensajes del topic
iabd-twitterde Kafka, y por ejemplo, como grupo de consumidores le indicaremos que usamos nifi (group id: nifi) - PutElasticsearchHttp: como ya hicimos en la sesión de Nifi, indicaremos la URL de Elasticsearch (
http://localhost:9200) y que lo almacene en un indice que hemos denominadoiabd-twitter-es:
Kafka Connect¶
Si hacerlo con Nifi ya es un avance respecto a tener que codificarlo con Python, ¿qué dirías si Kafka ofreciera una serie de conectores para las operaciones más comunes?
Así pues, Kafka Connect permite importar/exportar datos desde/hacia Kafka, facilitando la integración en sistemas existentes mediante alguno del centenar de conectores disponibles.
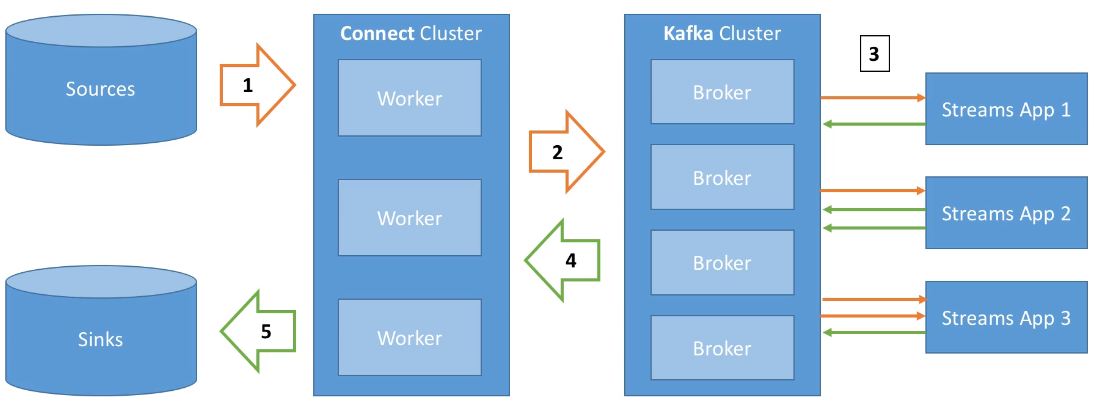
Los elementos que forman Kafka Connect son:
- Conectores fuente (source), para obtener datos desde las fuentes de datos (E en ETL)
- Conectores destino (sink) para publicar los datos en los almacenes de datos (L en ETL).
Estos conectores facilitan que desarrolladores no expertos puedan trabajar con sus datos en Kafka de forma rápida y fiable, de manera que podamos introducir Kafka dentro de nuestros procesos ETL.
Hola Kafka Connect¶
Vamos a realizar un ejemplo muy sencillo leyendo datos de una base de datos para meterlos en Kafka.
Para ello, utilizaremos la base de datos de retail_db que ya hemos empleado en otras sesiones y vamos a cargar en Kafka los datos de la tabla categories:
MariaDB [retail_db]> describe categories;
+------------------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-------------+------+-----+---------+----------------+
| category_id | int(11) | NO | PRI | NULL | auto_increment |
| category_department_id | int(11) | NO | | NULL | |
| category_name | varchar(45) | NO | | NULL | |
+------------------------+-------------+------+-----+---------+----------------
Configuración¶
Cuando ejecutemos Kafka Connect, le debemos pasar un archivo de configuración. Para empezar, tenemos config/connect-standalone.properties el cual ya viene rellenado e indica los formatos que utilizarán los conversores y otros aspectos:
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
Los conectores se incluyen en Kafka como plugins. Para ello, primero hemos de indicarle a Kafka donde se encuentran. Para ello, en el archivo de configuración le indicaremos la siguiente ruta:
plugin.path=/opt/kafka_2.13-2.8.1/plugins
Extrayendo datos mediante Kafka Connect¶
Así pues, el primer paso es crear el archivo de configuración de Kafka Connect con los datos (en nuestro caso lo colocamos en la carpeta config de la instalación de Kafka) utilizando un conector fuente de JDBC:
name=retaildb-mariabd-source-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost/retail_db
connection.user=iabd
connection.password=iabd
table.whitelist=categories
mode=incrementing
incrementing.column.name=category_id
topic.prefix=iabd-retail_db-
Antes de ponerlo en marcha, debemos descargar el conector y colocar la carpeta descomprimida dentro de nuestra carpeta de plugins /opt/kafka_2.13-2.8.1/plugins y descargar el driver de MySQL y colocarlos en la carpeta /opt/kafka_2.13-2.8.1/lib.
Y a continuación ya podemos ejecutar Kafka Connect:
connect-standalone.sh config/connect-standalone.properties config/retaildb-mariadb-source-connector.properties
Guava
Es posible que salte un error de ejecución indicando que falta la librería Guava la cual podéis descargar desde aquí y colocar en la carpeta /opt/kafka_2.13-2.8.1/lib
Si ahora arrancamos un consumidor sobre el topic iabd-retail_db-categories:
kafka-console-consumer.sh --topic iabd-retail_db-categories --from-beginning --bootstrap-server iabd-virtualbox:9092
Veremos que aparecen todos los datos que teníamos en la tabla en formato JSON (es lo que hemos indicado en el archivo de configuración de Kafka Connect):
{"schema":{
"type":"struct","fields":[
{"type":"int32","optional":false,"field":"category_id"},
{"type":"int32","optional":false,"field":"category_department_id"},
{"type":"string","optional":false,"field":"category_name"}],
"optional":false,"name":"categories"},
"payload":{"category_id":1,"category_department_id":2,"category_name":"Football"}}
{"schema":{
"type":"struct","fields":[
{"type":"int32","optional":false,"field":"category_id"},
{"type":"int32","optional":false,"field":"category_department_id"},
{"type":"string","optional":false,"field":"category_name"}],
"optional":false,"name":"categories"},
"payload":{"category_id":2,"category_department_id":2,"category_name":"Soccer"}}
...
Autoevaluación
Vamos a dejar el consumidor y Kafka Connect corriendo.
¿Qué sucederá si inserto un nuevo registro en la base de datos en la tabla categories?
Que automáticamente aparecerá en nuestro consumidor.
REST API¶
Como Kafka Connect está diseñado como un servicio que debería correr continuamente, ofrece un API REST para gestionar los conectores. Por defecto está a la escucha el puerto 8083, de manera que si accedemos a http://iabd-virtualbox:8083/ obtendremos información sobre la versión que se está ejecutando:
{"version":"2.8.1","commit":"839b886f9b732b15","kafka_cluster_id":"iHa0JUnTSfm85fvFadsylA"}
Por ejemplo, si queremos obtener un listado de los conectores realizaremos una petición GET a /connectors mediante http://iabd-virtualbox:8083/connectors:
["retaildb-mariabd-source-jdbc-autoincrement"]
Más información en https://kafka.apache.org/documentation/#connect_rest
Kafka Streams
Kafka Streams es la tercera pata del ecosistema de Kafka, y permite procesar y transformar datos dentro de Kafka. Una vez que los datos se almacenan en Kafka como eventos, podemos procesar los datos en nuestras aplicaciones cliente mediante Kafka Streams y sus librerías desarrolladas en Java y/o Scala, ya que requiere una JVM.
En nuestro caso, realizaremos en posteriores sesiones un procesamiento similar de los datos mediante Spark Streaming, permitiendo operaciones con estado y agregaciones, funciones ventana, joins, procesamiento de eventos basados en el tiempo, etc...
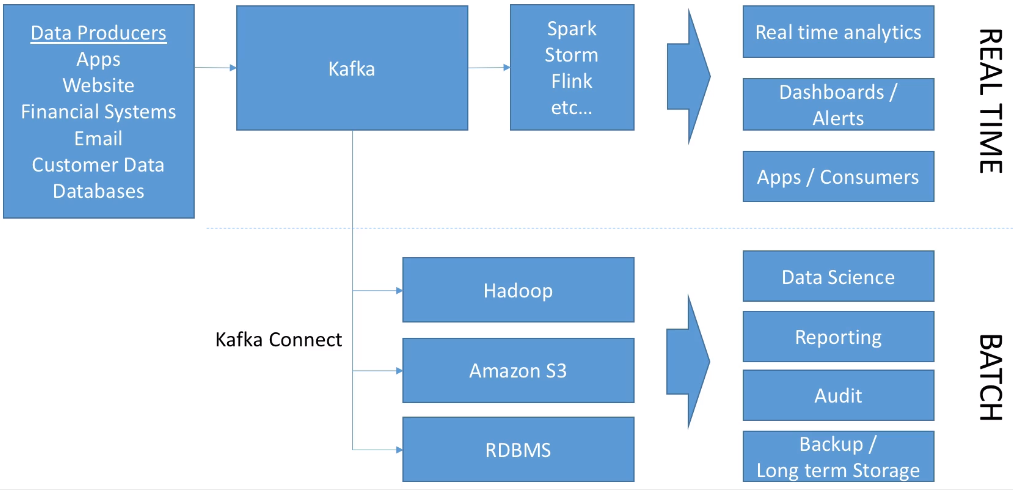
Kafka y el Big Data¶
El siguiente gráfico muestra cómo Kafka está enfocado principalmente para el tratamiento en streaming, aunque con los conectores de Kafka Connect da soporte para el procesamiento batch:
Actividades¶
- Realiza los casos de uso 0 y 1.
- (opcional) A partir del caso 2, crea un clúster de Kafka con 4 particiones y 3 nodos. A continuación, en el productor utiliza Faker para crear 10 personas (almacénalas como un diccionario). En el consumidor, muestra los datos de las personas (no es necesario recibirlos ordenados, sólo necesitamos que se aproveche al máximo la infraestructura de Kafka).
- Realiza el caso de uso 3 (De Twitter a ElasticSearch) tanto con Python como con Nifi.
- (opcional) Repite el caso de uso 2 únicamente mediante Kafka Connect.
- (opcional) Investiga en qué consiste el patrón CDC (Change Data Capture) y cómo se realiza CDC con Kafka/Kafka Connect y Debezium. ¿Qué ventajas aportan las soluciones CDC?
Referencias¶
- Apache Kafka Series - Learn Apache Kafka for Beginners
- Serie de artículos de Víctor Madrid sobre Kafka en enmilocalfunciona.io.
- Distributed Databases: Kafka por Miguel del Tio
- Introduction to Kafka Connectors
- Kafka Cheatsheet