Redis¶
Propuesta didáctica¶
Seguimos trabajando el siguiente resultado de aprendizaje (RA):
- RA7: Gestiona la información almacenada en bases de datos no relacionales, evaluando y utilizando las posibilidades que proporciona el sistema gestor.
Criterios de evaluación¶
- CE7c: Se han identificado los elementos utilizados en estas bases de datos.
- CE7d: Se han identificado distintas formas de gestión de la información según el tipo de base de datos no relacionales.
- CE7e: Se han utilizado las herramientas del sistema gestor para la gestión de la información almacenada.
Contenidos¶
Bases de datos no relacionales:
- Elementos de las bases de datos no relacionales.
- Sistemas gestores de bases de datos no relacionales.
- Herramientas de los sistemas gestores de bases de datos no relacionales para la gestión de la información almacenada.
Cuestionario inicial
- ¿Qué es Redis y cuáles son sus principales características como base de datos NoSQL?
- ¿Cuáles son las ventajas y desventajas de utilizar Redis como sistema de almacenamiento en memoria frente a otros sistemas de almacenamiento persistente?
- ¿Cómo se diferencian las bases de datos clave-valor de las bases de datos relacionales tradicionales?
- ¿Qué estructuras de datos admite Redis y cómo se utilizan en la gestión de información?
- ¿Cómo se implementan las operaciones CRUD?
- ¿Qué son los espacios de nombres y cuál es su propósito en la organización de claves?
- ¿Por qué es recomendable utilizar claves con prefijos en vez de espacios de nombres?
- ¿Cómo se maneja la expiración de claves y qué comandos se utilizan para ello?
- ¿Cómo se implementan para garantizar la atomicidad de las operaciones?
- ¿Cómo se pueden representar y manipular estructuras de datos complejas, como JSON, dentro de Redis?
- ¿Qué es un hash en Redis y para qué se utiliza?
- ¿Cómo se crea un hash en Redis y cómo se añaden campos y valores?
- ¿Qué comando se utiliza para obtener el valor de un campo específico en un hash?
- ¿Cómo se eliminan uno o más campos de un hash en Redis?
- ¿Es posible incrementar el valor numérico de un campo dentro de un hash? ¿Qué comando se utiliza para ello?
- ¿Qué es una lista en Redis y cómo se diferencia de otras estructuras de datos?
- ¿Cómo se añaden elementos al principio y al final de una lista en Redis? Proporcione los comandos correspondientes.
- ¿Qué comando se utiliza para obtener un rango específico de elementos de una lista?
- ¿Cómo se puede obtener y eliminar el primer elemento de una lista en una sola operación?
- ¿Qué sucede si se intenta extraer un elemento de una lista vacía utilizando una operación de bloqueo?
- ¿Qué es un conjunto en Redis y cuáles son sus características principales?
- ¿Cómo se añaden uno o más miembros a un conjunto en Redis?
- ¿Qué comando se utiliza para determinar si un elemento es miembro de un conjunto?
- ¿Cómo se obtienen todos los miembros de un conjunto en Redis?
- ¿Qué operaciones de conjuntos (como intersección, unión y diferencia) se pueden realizar en Redis y qué comandos se utilizan para cada una?
Programación de Aula (6h)¶
Seguimos con la penúltima unidad, y tras haber introducido los conceptos y elementos de los sistemas NoSQL, vamos a profundizar en el manejo de Redis, conociendo cómo funciona una solución clave-valor, con una duración estimada de 6 horas:
| Sesión | Contenidos | Actividades | Criterios trabajados |
|---|---|---|---|
| 5 | Redis. CRUD | AC1207 | CE7c, CE7d, CE7e |
| 6 | Hashes | AC1208 | CE7d, CE7e |
| 7 | Listas | AC1210 | CE7d, CE7e |
| 8 | Conjuntos | AC1212 | CE7d, CE7e |
| 9 | JSON | AC1214 | CE7d, CE7e |
| 10 | Mensajería | AC1216 | CE7d, CE7e |
Redis¶
Redis es una base de datos NoSQL open source en memoria, con un modelo de datos de clave-valor, que permite el cacheo de los datos y funcionar como un broker de mensajería. Soporta estructuras de datos como cadenas, hash, listas, conjuntos, conjuntos ordenados, consultas por rango, así como otras estructuras más específicas como mapas de bit, consultas radius, índices geoespaciales, etc...
El nombre Redis proviene de las iniciales de Remote Dictionary Server (servidor de diccionario remoto), un tipo de servidor apto como memoria rápida para datos, permitiendo su uso como una base de datos en memoria y como de clave-valor.
También se ofrece como una opción de pago mediante Redis Lab, ofreciéndola como una solución gestionada donde no tenemos que preocuparnos de la infraestructura.
Redis y Valkey: el vaivén de las licencias (2024-2025)
En marzo de 2024, Redis Labs cambió la licencia de Redis desde BSD a las licencias SSPLv1 y RSALv2, ninguna de las cuales está reconocida como open source por la Open Source Initiative (OSI). Como respuesta, la Linux Foundation anunció Valkey, un fork open source de Redis respaldado por AWS, Google Cloud, Oracle y Ericsson, entre otros. Valkey mantiene compatibilidad de comandos con Redis y es la opción que adoptaron muchas distribuciones de Linux y servicios cloud (por ejemplo, AWS ElastiCache ofrece soporte de Valkey desde finales de 2024).
Apenas un año después, en mayo de 2025, con la salida de Redis 8, la empresa añadió la licencia AGPLv3 (sí reconocida por la OSI) como tercera opción, junto a las dos anteriores. Es decir, Redis 8 es de nuevo open source en sentido estricto, y además incluye en el core lo que antes eran módulos separados (RedisJSON, RediSearch, RedisTimeSeries y RedisBloom).
En estos apuntes seguiremos hablando de Redis por familiaridad, pero todos los comandos que veremos funcionan exactamente igual en Valkey.
Características¶
Redis almacena los datos como pares clave-valor, donde:
- Cada clave (key) es un identificador único (similar a una clave primaria en SQL)
- Cada valor (value) puede ser de diferentes tipos (número, cadena, lista, hash, etc...)
Este modelo es fundamentalmente diferente del modelo relacional:
| Característica | Redis (clave-valor) | SQL (relacional) |
|---|---|---|
| Estructura | Plana, no relacional | Tabular, relaciones entre entidades |
| Esquema | Flexible, sin esquema fijo | Rígido, esquema predefinido |
| Consultas | Basadas en claves | Basadas en conjuntos (SELECT) |
| Transacciones | Soporte básico con comandos MULTI/EXEC |
Completo soporte ACID |
Cuando decimos que Redis es una base de datos en memoria, estamos indicando que el servidor almacena todos los datos en la memoria principal (RAM), ya que es la manera más rápida para almacenar y recuperar datos. Esto permite que Redis funcione como memoria caché y también como unidad de memoria principal, con independencia de si los datos permanecen en la base de datos por mucho o poco tiempo. Así pues, en un servidor Redis con su uso principal, los datos no se guardan en el disco duro, sino en la memoria principal.
Gracias a ser un almacén clave-valor, ofrece un alto rendimiento y puede escalarse fácilmente. Para cada entrada se crea una clave mediante la que se puede volver a solicitar la información en cuestión. Esto implica que las entradas no necesitan estar relacionadas entre sí ni tampoco consultarse con varias tablas diferentes, sino que la información está disponible de manera directa.
¿Y si falla el servidor o se va la luz? ¿Corremos el riesgo de perder todos los datos? Para evitar que eso ocurra, Redis puede, o bien hacer regularmente un duplicado de todos los datos en un disco duro secundario (persistencia RDB - Redis Database), o bien guardar en un archivo de registro todas las órdenes necesarias para llevar a cabo una reconstrucción (persistencia AOF - Append Only File).
Finalmente, respecto a la escalabilidad, como solución NoSQL, si toda la información no cabe en un único nodo, el sistema puede escalar horizontalmente añadiendo más nodos. Si cada nodo puede almacenar 64GB RAM, y tenemos 4 servidores, podríamos almacenar hasta 256GB de datos en nuestro servidor Redis.
Hablemos de tamaños
Un millón de cadenas almacenadas en Redis ocupan aproximadamente 85MB de almacenamiento.
Una instancia vacía de Redis utiliza 3 MB de RAM.
Los valores en Redis son de 64 bits.
En teoría, Redis puede almacenar 2^32 claves en una única instancia Redis. En la práctica, hay servidores de una única instancia con 250 millones de claves.
Puesta en marcha¶
Para poner en marcha Redis, bien podemos instalarlo en nuestro sistema, usar un contenedor Docker o utilizar la solución Redis cloud. Para ello, consulta la sección de Redis en la página de Entorno.
Uso del cliente redis-cli¶
Aunque hayamos visto que existe un interfaz gráfico, de momento vamos a centrarnos en el uso mediante la consola y acceder al cliente interactivo mediante redis-cli:
redis-cli
# 127.0.0.1:6379>
Si queremos conectarnos a una instancia remota, y con un usuario determinado (parámetro -u), realizaremos una conexión similar a la siguiente, donde al conectarnos siempre se nos indicará a qué host estamos conectados:
redis-cli -u redis://usuario:password@redis-16677.c339.eu-west-3-1.ec2.redns.redis-cloud.com:16677
redis-16677.c339.eu-west-3-1.ec2.redns.redis-cloud.com:16677>
Al ejecutar un comando, siempre recibiremos una respuesta en la línea inferior. Por ejemplo, vamos a comprobar la conectividad haciendo PING:
127.0.0.1:6379> PING
# PONG
Si no hubiéramos podido conectarnos, habríamos recibido un mensaje de error. Mediante help aparecerá, además de la versión instalada, una lista de opciones de ayuda, así como la posibilidad de obtener más información de un comando concreto:
127.0.0.1:6379> help
# redis-cli 8.6.2
# To get help about Redis commands type:
# "help @<group>" to get a list of commands in <group>
# "help <command>" for help on <command>
# "help <tab>" to get a list of possible help topics
# "quit" to exit
CRUD¶
En este apartado vamos a simular que queremos crear un acortador de URLs, del tipo bit.ly, de manera que cuando un usuario pone una URL corta, accederíamos a la URL larga, lo que también nos permite llevar un contador de las visitas a cada dirección.
Usaremos los comandos SET y GET para asignar y recuperar un valor de una clave. SET clave valor siempre requiere dos parámetros, la clave y el valor, mientras que GET clave sólo permite recuperar por la clave:
SET aitor-bd aitor-medrano.github.io/bd
# OK
GET aitor-bd
# "aitor-medrano.github.io/bd"
Tras ejecutar un comando en Redis, siempre recibiremos una respuesta, ya sea OK, la cantidad de claves implicadas, o el resultado del comando (el valor devuelto, la lista de valores, etc...).
Letra inicial
La primera letra de los comandos normalmente puede indicar el tipo de datos sobre el que trabaja, el módulo de Redis que emplea o un tipo de operación específica. En este caso, todas las operaciones que empiezan por M se consideran operaciones múltiples que operan sobre más de una clave o valor con el mismo comando.
Si queremos hacer más de una entrada de una sola vez usaremos MSET y MGET:
MSET aitor-iabd aitor-medrano.github.io/iabd aitor-blog aitor-medrano.github.io/iabd/blog
# OK
MGET aitor-bd aitor-iabd aitor-blog
# 1) "aitor-medrano.github.io/bd"
# 2) "aitor-medrano.github.io/iabd"
# 3) "aitor-medrano.github.io/iabd/blog"
Si queremos recuperar las claves existentes usaremos KEYS, al cual le podemos pasar * para mostrar todas o un prefijo para que muestre aquellas que lo cumplen (permite el uso de expresiones regulares, del estilo KEYS clave[1-3]* o KEYS clave[^6]):
KEYS aitor-*
# 1) "aitor-blog"
# 2) "aitor-bd"
# 3) "aitor-iabd"
SCAN & MATCH
Aunque KEYS permita recuperar todas las claves, el problema es que bloquea el servidor mientras las recorre. Esto puede provocar problemas serios en entornos de producción, ya que mientras Redis ejecuta el comando KEYS, el servidor queda bloqueado para atender otras operaciones. En bases de datos con millones de claves, esto puede significar interrupciones de servicio inaceptables.
Para evitar esto, se recomienda utilizar SCAN cursor [MATCH patrón] [COUNT cantidad] [TYPE tipo], el cual ofrece una alternativa eficiente, ya que funciona de manera incremental, devolviendo las claves en lotes. Veamos un ejemplo (a lo largo de la sesión iremos creando nuevas claves que ahora aparecen en el ejemplo):
SCAN 0
# 1) "7" # El cursor para la siguiente iteración
# 2) 1) "visitas"
# 2) "pedro:visitados"
# 3) "sitiosweb"
# 4) "aitor-bd"
# 5) "noticias"
# 6) "contador"
# 7) "aitor-dwes"
# 8) "usuario:aitor:nombre"
# 9) "tech"
# 10) "usuario:aitor:pwd"
# 11) "usuario:aitor"
SCAN 7
# 1) "0" # El cursor 0 indica que se ha completado la iteración
# 2) (empty array)
También podemos filtrar por las claves, así como restringir el tipo de valor:
SCAN 0 MATCH usuario:aitor* COUNT 15
# 1) "0"
# 2) 1) "usuario:aitor:nombre"
# 2) "usuario:aitor:pwd"
# 3) "usuario:aitor"
SCAN 0 TYPE "string" COUNT 10
# 1) "7"
# 2) 1) "aitor-bd"
# 2) "contador"
# 3) "aitor-dwes"
# 4) "usuario:aitor:nombre"
# 5) "usuario:aitor:pwd"
SCAN 0 TYPE "set"
# 1) "7"
# 2) 1) "sitiosweb"
# 2) "noticias"
# 3) "tech"
Las características principales de SCAN son:
- Iteración incremental: Devuelve un cursor que se utiliza para continuar la iteración
- No bloqueante: Permite que otras operaciones se ejecuten mientras se realiza el escaneo
- Cobertura completa: Garantiza que se examinan todas las claves existentes
- Opciones de filtrado: Permite filtrar mediante patrones con
MATCH - Control de rendimiento: El parámetro
COUNTsugiere cuántas claves examinar por iteración
Para borrar una determinada clave usaremos DEL y EXISTS para comprobar si existe:
EXISTS aitor-iabd
# (integer) 1
DEL aitor-iabd
# (integer) 1
EXISTS aitor-iabd
# (integer) 0
GET aitor-bd
# (nil)
DEL vs UNLINK
Desde la versión 4, podemos utilizar UNLINK para eliminar una clave de forma similar a DEL, pero con mejor rendimiento, al ejecutarse en otro hilo de ejecución:
UNLINK aitor-iabd
# (integer) 1
DEL es el comando tradicional que elimina la clave inmediatamente y bloquea el hilo principal hasta que la memoria sea liberada. Esto puede causar problemas de rendimiento si eliminas claves muy grandes.
UNLINK fue introducido para resolver este problema. Elimina la clave del espacio de claves instantáneamente (como DEL), pero libera la memoria asociada en un hilo separado, permitiendo que el servidor Redis continúe atendiendo otras solicitudes.
Cadenas¶
Si nuestros valores son cadenas, podemos emplear una serie de operaciones para trabajar con ellos, como STRLEN para recuperar el tamaño de un valor, GETRANGE clave inicio fin para obtener una subcadena o APPEND para añadir contenido al final
GET aitor-bd
# "aitor-medrano.github.io/bd"
STRLEN aitor-bd
# (integer) 26
GETRANGE aitor-bd 0 22
# "aitor-medrano.github.io"
GETRANGE aitor-bd 24 -1
# "bd"
APPEND aitor-bd "/"
# (integer) 27
GET aitor-bd
# "aitor-medrano.github.io/bd/"
Enteros¶
Aunque Redis almacene cadenas, también permite almacenar números enteros y realizar ciertas operaciones sobre ellos, como INCR para incrementar de uno en uno INCRBY para indicar la cantidad, y sus contrarios DECR y DECRBY:
SET contador 2
# OK
INCR contador
# (integer) 3
GET contador
# "3"
INCRBY contador 2
# (integer) 5
DECR contador
# (integer) 4
Casos de uso muy comunes de almacenamiento de número enteros pueden ser contar el número de clics que se realiza sobre un enlace, o controlar la cantidad de entradas disponibles de un evento/concierto/partido/festival, etc...
Espacios de nombres¶
Redis utiliza un concepto diferente al de las bases de datos tradicionales. En lugar de tener múltiples bases de datos separadas, proporciona bases de datos lógicas numeradas dentro de una única instancia. Por defecto, Redis cuenta con 16 bases de datos numeradas de 0 a 15, aunque este número se puede configurar en el archivo redis.conf mediante la directiva databases.
Redis cloud
Si estás utilizando Redis en modo clúster en el cloud, este solo soporta la base de datos 0.
Los comandos SELECT con índices distintos de 0 no funcionarán en Redis Cluster.
Podemos recuperar las bases de datos que tenemos mediante CONFIG GET DATABASES:
127.0.0.1:6379> CONFIG GET DATABASES
1) "databases"
2) "16"
Para elegir qué base de datos queremos emplear, usaremos el comando SELECT, que permite cambiar la base de datos actual a otro espacio de nombres (al cambiar de base de datos, si no empleamos la base de datos 0, en el CLI aparecerá entre corchetes su número identificador):
127.0.0.1:6379> GET aitor-bd
# "aitor-medrano.github.io/bd"
127.0.0.1:6379> SELECT 1
# OK
127.0.0.1:6379[1]> GET aitor-bd
# (nil)
De esta manera, podemos crear espacios de nombres separados para diferentes aplicaciones o componentes de la misma aplicación.
Convención de nombrado
Aunque podemos emplear SELECT para cambiar de base de datos, es recomendable utilizar prefijos en las claves del tipo usuario:1:nombre o producto:1:nombre para diferenciar espacios de nombres, utilizando los dos puntos (:) como separador de los prefijos.
De esta manera, posteriormente podremos filtrar las claves por un subconjunto de los prefijos de las claves.
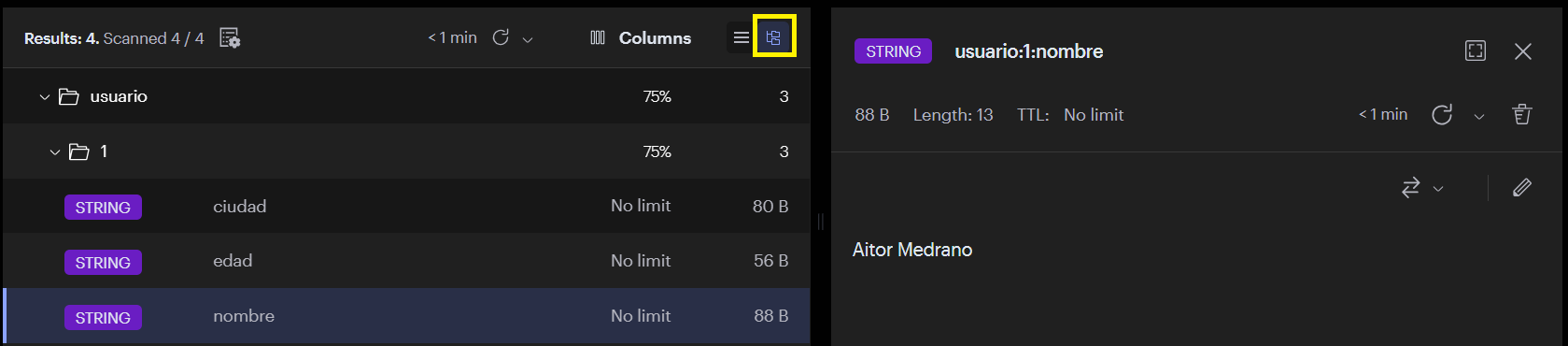
Mediante Redis Insight, si utilizamos esta convención, al mostrar las claves podemos visualizarlas de forma jerárquica. Si insertamos estos datos:
set usuario:1:nombre "Aitor Medrano"
set usuario:1:edad 47
set usuario:1:ciudad "Elche"
Al pulsar en el botón de vista en forma de árbol, tendríamos:
Algunos patrones comunes para nombrar las claves son:
# Para datos de usuario
usuario:{id}:{campo}
# Para sesiones
sesion:{token}:{campo}
# Para datos por entorno
{entorno}:{tipo}:{id}
# Para caché
cache:{servicio}:{recurso}:{id}
A pesar de sus limitaciones, el comando SELECT puede ser útil en varios escenarios:
- Entornos de desarrollo/pruebas: Usar diferentes bases de datos para separar datos de prueba de datos de producción en la misma instancia.
- Migración de datos: Mover datos temporalmente a otra base de datos durante procesos de migración.
- Caché multi-nivel: Usar diferentes bases de datos para diferentes niveles de caché con políticas de expiración distintas.
- Aplicaciones simples: Para aplicaciones pequeñas donde no se justifica tener múltiples instancias de Redis.
Expiración¶
Una de las características más útiles es la capacidad de establecer un tiempo de vida (TTL, Time-To-Live) para las claves, lo que permite gestionar la caducidad automática de los datos, sin necesidad de implementar mecanismos de limpieza manuales. Así pues, existen dos tipos de claves, las que hemos utilizado hasta ahora, que se conocen como persistentes y las que caducan, que las llamaremos volátiles.
Para eliminar claves expiradas, Redis utiliza dos estrategias:
- Eliminación pasiva: Cuando se accede a una clave, Redis comprueba si ha expirado y, en caso afirmativo, la elimina.
- Eliminación activa: Redis tiene un proceso que periódicamente muestrea claves aleatorias con tiempo de expiración y elimina las que han caducado.
Esto permite que Redis mantenga un buen rendimiento incluso con millones de claves con expiración.
Para convertir una clave persistente en volátil usaremos el comando EXPIRE clave segundos, el cual permite asignar un tiempo de vida (en segundos) a una clave existente. Una vez transcurrido el tiempo especificado, la clave se eliminará automáticamente.
EXPIRE aitor-blog 3600 # establecemos una clave con una hora de expiración
# (integer) 1 # cuando devuelve 1, indica que la expiración se ha asignado exitosamente
Otras posibilidades son utilizar EXPIREAT clave timestamp que permite establecer un tiempo de expiración basado en una fecha y hora específica, expresada en timestamp UNIX (segundos desde 1 de enero de 1970), o PEXPIRE que permite definir la expiración en milisegundos:
EXPIREAT aitor-blog 1742751722
PEXPIRE aitor-blog 30000
Si queremos saber cuánto tiempo le queda a una clave, usaremos el comando TTL clave:
TTL aitor-blog # Comprobamos el tiempo restante
# (integer) 3283
TTL aitor-bd
# (integer) -1 # La clave es persistente, no volátil
TTL clave-no-existe
# (integer) -2 # La clave no existe
Si la clave no tiene expiración asignada, devolverá -1. En el caso de que la clave no exista, devolverá -2, bien sea porque ya ha expirado o que nunca se creó.
Otra posibilidad para asignar la expiración es hacerlo al mismo tiempo que se asigna un valor. Así pues, en las operaciones tipo SET podemos indicar el parámetro EX con la cantidad de segundos (o PX para la cantidad de milisegundos):
SET aitor-blog aitor-medrano.github.io/iabd/blog EX 3600
# (integer) 3283
Finalmente, si queremos cambiar el estado para que una clave ya no caduque y deje de ser volátil, debemos persistirla mediante PERSIST:
PERSIST aitor-blog
# (integer) 1
La expiración de las claves se emplea para:
- Gestión de sesiones: expirar claves de sesión de usuarios tras un tiempo de inactividad.
- Caché temporal: almacenar datos temporalmente para evitar accesos frecuentes a bases de datos tradicionales.
- Colas de mensajes: eliminar mensajes antiguos automáticamente.
- Control de rate-limiting: implementar restricciones de uso por usuario con expiración automática.
Transacciones¶
De la misma forma que hemos visto en MariaDB, necesitamos de alguna manera poder agrupar dos o más operaciones como si fuera una operación atómica. Para ello, usaremos el comando MULTI para iniciar el bloque de instrucciones, y EXEC para confirmar la transacción. En el caso de querer hacer un rollback, usaremos el comando DISCARD:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> SET aitor-dwes aitor-medrano.github.io/dwes2122
QUEUED
127.0.0.1:6379(TX)> INCR contador
QUEUED
127.0.0.1:6379(TX)> EXEC
1) OK
2) (integer) 5
Cabe destacar que, al comenzar una transacción, en el CLI se mostrará el sufijo (TX) tras el prompt para indicar que las operaciones forman parte de una misma transacción.
Estructuras de datos¶
La estructura de datos básica de Redis está formada por las llamadas Strings, es decir, cadenas simples de caracteres, las cuales hemos utilizado en el apartado anterior.
El uso de Strings permite almacenar datos de forma genérica, por ejemplo, serializando cualquier dato en una cadena o utilizando documentos JSON. Conviene destacar que el tamaño máximo es de 512 MB.
Hash¶
-
Estructura
Un mapa o Hash en Redis es una colección de parejas campo-valor, similar a un documento JSON. Para evitar confusiones, el concepto clave lo utilizaremos para los elementos de Redis, mientras que campo para las "claves" de los hashes. Además, cabe destacar que sus valores siempre serán cadenas, es decir, no puede anidar otros mapas o conjuntos.
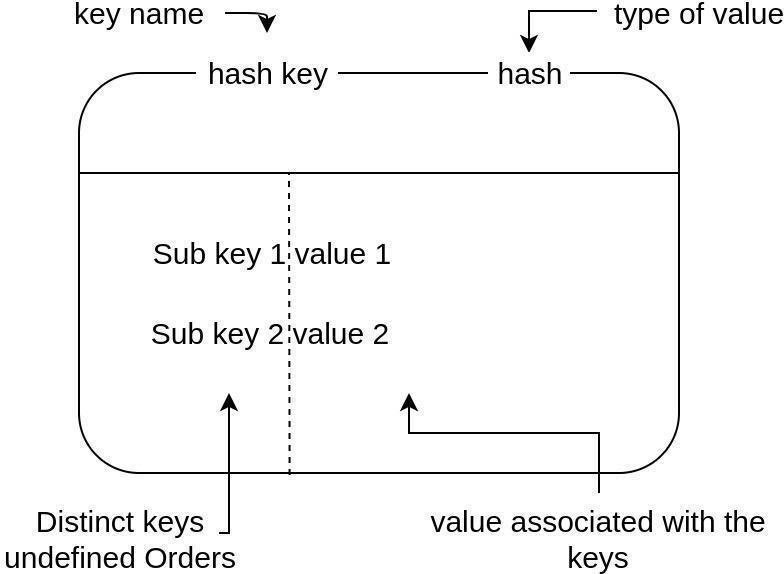
Hashes en Redis Se utiliza para almacenar objetos ligeros, como las sesiones de usuario, los propios datos del usuario (su perfil), visitantes o incluso el carrito de la compra.
Todas sus operaciones comienzan por la letra
H:HGET,HSET,HMGET,HKEYS,HVALS,HINCRBY,HDEL, etc...
-
Comandos
Para interactuar con un Hash utilizaremos los comandos
HSETpara asignar valores,HKEYSpara recuperar todos los campos yHVALSpara recuperar todos los valores, oHGETpara recuperar un campo concreto:HSET usuario:aitor nombre "Aitor Medrano" pwd "123456" # (integer) 2 # número de campos insertados HVALS usuario:aitor # 1) "Aitor Medrano" # 2) "123456" HKEYS usuario:aitor # 1) "nombre" # 2) "pwd" HGET usuario:aitor nombre # "Aitor Medrano"Otros comandos más específicos son
HDELpara elimina campos,HINCRBYpara incrementar un campo cierta cantidad,HLENpara obtener la cantidad de campos,HGETALLpara recuperar todas las claves y valores yHSETNXpara asignar un valor sólo si la clave no existe (ya que si existe, medianteHSETsiempre la sustituye).
Lista¶
-
Estructura
Las listas en Redis son como un array de cadenas, teniendo en cuenta que los elementos se ordenan por orden de inserción. Es decir, son una estructura que respeta el orden de los elementos. Pueden funcionar como colas FIFO (first in, first out) o como pilas LIFO (last in, first out). Desde un punto de vista terminológico, las inserciones son push y las extracciones son pop.
Se implementan mediante listas enlazadas, lo que provoca que las operaciones en la cabeza y en la cola tengan complejidad constante, independientemente del tamaño de la lista. En cambio, acceder a un elemento determinado, supone recorrer la lista elemento por elemento. En este caso, es mejor utilizar conjuntos ordenados.
En Redis, la cabeza (head) es el extremo izquierdo y la cola (tail) el derecho.
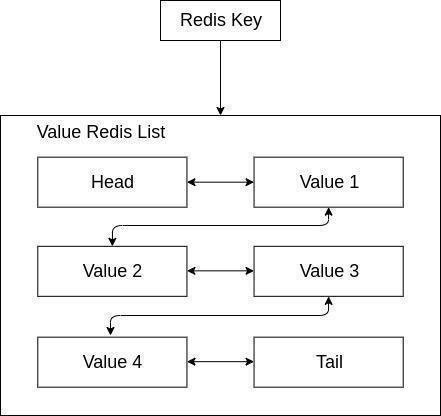
Listas en Redis Casos de uso:
- Implementar colas como estructuras de datos.
- Cronogramas de mensajes (feed de una red social, logs recientes, etc...).
- Listado de tareas, para su procesamiento en el orden de inserción.
Todas sus operaciones comienzan por la letra
L:LINDEX,LRANGE,LLEN,LREM,LTRIM,LMOVE, etc... además de las operaciones PUSH y POP que llevan delante el lado por el que se realizan.
-
Comandos
Para interactuar con un lista utilizaremos los comandos
LPUSHpara insertar valores por la izquierda yLPOPpara sacarlos, y sus homónimosRPUSHyRPOPpara hacerlo por la derecha. El uso como una cola implica insertar por la izquierda y sacar por la derecha.
Operaciones con listas en Redis Si queremos recuperar un elemento concreto usaremos
LINDEX. En cambio, si nos interesa un subconjunto de elementos, utilizaremosLRANGE, mientras que para averiguar la longitud de la lista emplearemosLLEN.Supongamos que queremos asignarles a nuestros usuarios una lista de URL favoritas. Para ello, podríamos hacer:
LPUSH aitor:enlaces aitor-bd aitor-iabd aitor-blog # (integer) 3 LLEN aitor:enlaces # (integer) 3 LINDEX aitor:enlaces 0 # "aitor-blog" LINDEX aitor:enlaces -1 # "aitor-bd" LRANGE aitor:enlaces 0 -1 # 1) "aitor-blog" # 2) "aitor-iabd" # 3) "aitor-bd"Todas las operaciones de listas utilizan un acceso 0-index, donde un valor negativo indica el número de pasos desde el final.
Para eliminar y recuperar cada valor en el orden en el que se añadieron (de forma similar a una cola FIFO), al insertarlos por la izquierda, debemos sacarlos por la derecha (la cola) de la lista:
RPOP aitor:enlaces # "aitor-bd"Para sacar elementos, también podemos emplear
LREM clave cantidad elementopara a partir de una clave, permite indicar cuantos elementos queremos quitar de un determinado valor (si ponemos 0, borrará todos los que coincidan, y si ponemos un número negativo, borrará los indicados, pero empezando a buscar desde el final):LREM aitor:enlaces 0 aitor-blog # (integer) 1 LLEN aitor:enlaces # (integer) 1Si queremos reducir una lista y quedarnos con una cantidad concreta de elementos, podemos emplear
LTRIM clave inicio finpara, por ejemplo, asegurarnos que nuestra lista no contiene más de 10 elementos:LTRIM aitor:enlaces 0 9 # OKSi en cambio queremos que funcione como una pila LIFO, tras insertarlos con
LPUSH, utilizaremosLPOPpara sacarlos. Estas operaciones tienen un coste computacional constante (lo que significa que el tamaño de la lista no impacta en el rendimiento).Si queremos sacar, con un único comando, valores de la cola para insertarla en la cabeza de otra, antiguamente podíamos hacerlo mediante el comando
RPOPLPUSH(right pop, left push):RPOPLPUSH aitor:enlaces pedro:visitados # "aitor-iabd"Con esta operación el problema es doble. Por un lado, el comando se ha marcado como obsoleto, y por el otro, solo permite sacar por la derecha e insertar por la izquierda. Por suerte, desde la versión 6.2, podemos emplear el comando
LMOVE origen destino <LEFT | RIGHT> <LEFT | RIGHT>, el cual es más flexible al permitir sacar el elemento tanto de la izquierda como de la derecha y a su vez, volver a insertarlo a la izquierda o la derecha del destino. Así pues, podemos conseguir el mismo resultado mediante:LMOVE aitor:enlaces pedro:visitados RIGHT LEFT
Conjunto¶
-
Estructura
Los conjuntos se parecen a las listas en que almacenan una colección de cadenas, pero los elementos no están ordenados ni repetidos. Dicho de otro modo, los elementos son únicos.

Sets en Redis Además de añadir y eliminar elementos de un conjunto, podemos realizar varias operaciones de conjuntos, como la unión, la intersección, la diferencia etc.... Estas operaciones se realizan dentro de Redis y son muy rápidas. Lo que no podemos realizar es un acceso secuencial.
¿Cuándo debemos considerar el uso de conjuntos? Siempre que no nos importe la cardinalidad o cuántos elementos tenemos de una misma clave. Es más, en ocasiones necesitamos realizar un almacenamiento de elementos únicos, sin requerir la sobrecarga de tener que realizar una búsqueda para saber si el elemento existía previamente.
Por ejemplo, podemos emplear conjuntos para almacenar la lista de usuarios únicos de una web, elegir el ganador de un sorteo así como encontrar usuarios o elementos que pertenecen a dos grupos distintos.
Todas sus operaciones comienzan por la letra
S:SADD,SMEMBERS,SISMEMBER,SRANDMEMBER,SINTER,SDIFF,SUNION,SCARD,SPOP,SREM, etc...
-
Comandos
Para añadir elementos a un conjunto utilizaremos SADD, de manera que podemos añadir diversos valores a una clave,
SMEMBERSpara recuperar todos los valores,SISMEMBERpara averiguar si un valor forma parte de un determinado conjunto:SADD noticias elpais.com eldiario.es xataka.com # (integer) 3 # Devuelve la cantidad de elementos añadidos SADD noticias xataka.com # (integer) 0 # Como ya existe, devuelve 0, ya que no ha insertado el elemento SMEMBERS noticias # Devuelve todos los elementos # 1) "elpais.com" # 2) "eldiario.es" # 3) "xataka.com" SISMEMBER noticias "xataka.com" # Comprueba si "xataka.com" está en el conjunto # (integer) 1 SISMEMBER noticias "eurogamer.es" # (integer) 0Si queremos recuperar una cantidad de elementos aleatorios de un conjunto usaremos
SRANDMEMBER clave cantidad, donde sicantidades positiva devolverá elementos sin repetir, pero si es negativa, permitirá elementos repetidos:SRANDMEMBER noticias 2 # 1) "elpais.com" # 2) "xataka.com" SRANDMEMBER noticias -2 # 1) "xataka.com" # 2) "xataka.com"También podemos emplear las operaciones matemáticas de conjuntos, mediante
SINTERpara la intersección,SDIFFpara la diferencia ySUNIONpara la unión:SADD tech xataka.com eurogamer.es # (integer) 3 SINTER noticias tech # Enlaces que aparecen en los dos conjuntos # 1) "xataka.com" SDIFF noticias tech # Noticias que no son de tecnología # 1) "elpais.com" # 2) "eldiario.es" SUNION noticias tech # Todas las noticias, sin enlaces repetidos # 1) "elpais.com" # 2) "eldiario.es" # 3) "xataka.com" # 4) "eurogamer.es"Todas las operaciones sobre conjuntos ofrecen la posibilidad de almacenar el resultado en uno nuevo, así pues, podemos emplear
SINTERSTORE,SDIFFSTOREySUNIONSTORErespectivamente:SUNIONSTORE sitiosweb noticias tech # (integer) 4 SMEMBERS sitiosweb # 1) "elpais.com" # 2) "eldiario.es" # 3) "xataka.com" # 4) "eurogamer.es"Igual que usamos
LMOVEpara mover elementos entre listas, podemos emplearSMOVEpara mover valores entre conjuntos. Otras operaciones muy útiles sonSCARD clavepara averiguar su tamaño (cardinalidad),SPOPpara sacar un elemento cualquiera (al no estar ordenados) oSREM clave valorsi queremos eliminar un valor concreto.SCARD sitiosweb # (integer) 4 SREM sitiosweb eldiario.es # (integer) 1 SCARD sitiosweb # (integer) 3
Conjunto ordenado¶
-
Estructura
Un conjunto ordenado también es una colección de cadenas únicas. A diferencia de un conjunto normal, los valores de un conjunto ordenado están ordenados (elemental, querido Watson), por lo que son una estructura que une el concepto de lista como conjunto de elementos ordenados, con el de conjunto, donde no permite elementos repetidos.
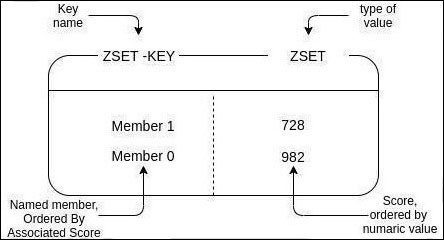
Sets ordenados en Redis ¿Cómo se realiza la ordenación? Cada elemento de un conjunto ordenado se compone a su vez de dos partes, un miembro almacenado como una cadena y una calificación. La ordenación se basa en las puntuaciones y el orden léxico (orden alfabético) de las cadenas. Así, cada miembro es único, aunque las puntuaciones pueden coincidir. ¿Cómo se realiza la puntuación de estos valores? Redis proporciona operaciones para que los usuarios puedan manipular una puntuación para un elemento del conjunto.
Los conjuntos ordenados son preferibles a las listas cuando el acceso a un miembro concreto es más importante que la rapidez de inserción/eliminación, es decir, son más importantes las lecturas que las escrituras. Es por ello, que la complejidad temporal de la inserción/eliminación en un conjunto ordenado es O(N), donde N es el número de elementos del conjunto, ya que mantiene los valores ordenados, en vez de la complejidad O(1) que tienen las listas. Así pues, podemos considerar un conjunto ordenado como una cola prioritaria de acceso aleatorio.
Los conjuntos ordenados de Redis son ideales para casos de uso como rankings de productos más comprados, visitados, etc... así como sistemas con puntuación, tipo las preguntas de Stack Overflow o posts en Reddit.
Todas sus operaciones comienzan por la letra
Z:ZADD,ZREM,ZRANGE,ZSCORE,ZCOUNT,ZINCRBY, etc...
-
Comandos
Para añadir elementos a un conjunto ordenado usaremos la operación
ZADD clave puntuación valor,ZREMpara eliminarlos,ZSCORE clave miembropara recuperar la puntuación de un valor, mientras que medianteZRANGE clave inicio finpodemos recuperar las claves entre un rango inclusivo (si queremos que no entren inicio o fin en el rango, les pondremos un paréntesis delante) por posición o puntuación (BYSCORE), pudiendo recuperarlo en orden inverso (REV) y/o con su puntuaciónWITHSCORES:ZADD visitas 1000 aitor-bd 5000 aitor-iabd 66 aitor-blog # (integer) 3 ZSCORE visitas aitor-bd # "1000" ZRANGE visitas 0 -1 WITHSCORES # Todos los elementos con puntuaciones # 1) "aitor-blog" # 2) "66" # 3) "aitor-bd" # 4) "1000" # 5) "aitor-iabd" # 6) "5000" ZRANGE visitas 50 1500 BYSCORE # Filtrado por puntuaciones # 1) "aitor-blog" # 2) "aitor-bd" ZRANGE visitas (66 1500 BYSCORE # No incluye el 66 # 1) "aitor-bd" ZRANGE visitas (5000 66 REV BYSCORE WITHSCORES # No incluye el 5000, en orden descendente # 1) "aitor-bd" # 2) "1000" # 3) "aitor-blog" # 4) "66"Han caído en desuso las operaciones
ZREVRANGE,ZRANGEBYSCORE,ZREVRANGEBYSCORE, etc... ya que conZRANGEy los parámetros adecuados podemos obtener los mismos resultados.Si lo que queremos es averiguar cuántos valores tienen una puntuación entre un rango determinado, usaremos
ZCOUNT clave inicio fin:ZCOUNT visitas 50 1500 # (integer) 2También podemos averiguar qué posición ocupa un determinado miembro mediante
ZRANK clave miembro(la primera posición es la posición 0):ZRANK visitas aitor-bd # (integer) 1Para incrementar la puntuación de un miembro, podemos volver a añadirlo con la nueva puntuación, lo cual modifica la puntuación, pero no añade un nuevo valor, o incrementarlo por un determinado valor (o reducirlo mediante un valor negativo) mediante
ZINCRBY, el cual devolverá un nuevo valor:ZINCRBY visitas 1 aitor-bd # "1001"
JSON¶
-
Estructura
Redis permite el uso de JSON como un tipo de datos, permitiendo almacenar, modificar y recuperar valores JSON, lo que en parte la convierte en una base de datos documental.
Un documento JSON está formado por pares de clave-valor, donde las claves son cadenas, pero los valores pueden ser de diferentes tipos, los cuales pueden ser:
- numéricos: enteros y decimales
- cadenas de texto
- valores booleanos:
trueofalse null(valor nulo)- objetos (conjuntos de pares clave-valor anidados)
- y arrays (listas ordenadas de valores, que pueden incluir cualquier combinación de los tipos anteriores).
Toda la interacción de Redis con estructuras JSON se realizan con el prefijo
JSON..
-
Comandos
Los comandos que más vamos a emplear son
JSON.SETpara asignar una cadena JSON a una clave yJSON.GETpara recuperar un valor, pudiendo realizar selección y filtrado de elementos.Como hemos comentado, para asignar un elemento usaremos el comando
JSON.SET clave ruta valor, donderutaserá$para indicar el raíz o una expresión JSONPATH si queremos añadir contenido en un lugar específico, y mediantevalorle asignamos una cadena en formato JSON. Además, podemos pasar el parámetroNXpara indicar que lo cree si no existe oXXpara sobrescribir en caso de que ya exista. Veamos algunos ejemplos:JSON.SET usuario:1 $ '{"nombre": "Aitor Medrano", "altura": 182, "hobbies": ["baloncesto", "videojuegos"]}' # OK JSON.SET usuario:2 $ '{"nombre": "José Manuel Pérez"}' NX # NX: Lo crea si no existe # OK JSON.SET usuario:2 $ '{"nombre": "Andreu Medrano"}' XX # XX: Lo sobrescribe, sólo si ya existe. Si no, ni lo insertaSi queremos modificar un documento, además de
JSON.SETpara campos sencillos, podemos emplearJSON.TOGGLEpara cambiar el estado de un campo booleano,JSON.NUMINCRBYpara incrementar un campo numérico, yJSON.ARRAPPENDyJSON.ARRINSERTpara trabajar con arrays para añadir, respectivamente, elementos al final o en una posición determinada:JSON.SET usuario:1 '$.altura' 183 # Modificamos un campo # OK JSON.NUMINCRBY usuario:1 '$.altura' 10 # Incrementamos un campo # "[193]" JSON.SET usuario:1 '$.ciudad' '"Elche"' # Agregamos un nuevo campo # OK JSON.ARRAPPEND usuario:1 '$.hobbies' '"big data"' # 1) (integer) 3 JSON.ARRINSERT usuario:1 '$.hobbies' 1 '"música"' # 1) (integer) 4Para recuperar documentos usaremos
JSON.GET clave [ruta], donderutaes una expresión JSONPath:JSON.GET usuario:1 # "{\"nombre\":\"Aitor Medrano\",\"altura\":183,\"hobbies\":[\"baloncesto\",\"m\xc3\xbasica\",\"videojuegos\",\"big data\"],\"ciudad\":\"Elche\"}" JSON.GET usuario:1 '$.nombre' # Un campo sencillo # "[\"Aitor Medrano\"]" JSON.GET usuario:1 '$.hobbies' # Un campo array # "[[\"baloncesto\",\"m\xc3\xbasica\",\"videojuegos\",\"big data\"]]" JSON.GET usuario:1 '$.hobbies[0]' # El primer elemento del array # "[\"baloncesto\"]" JSON.GET usuario:1 '$.nombre' '$.ciudad' # Varias rutas # "{\"$.nombre\":[\"Aitor Medrano\"],\"$.ciudad\":[\"Elche\"]}"También podemos emplear
JSON.MGETpara recuperar la misma ruta de varias claves:JSON.MGET usuario:1 usuario:2 '$.nombre' # 1) "[\"Aitor Medrano\"]" # 2) "[\"Andreu Medrano\"]"Finalmente, para eliminar elementos disponemos de
JSON.DELy para vaciarlosJSON.CLEAR(vacía los arrays y los objetos y pone a cero los valores enteros). En el caso de arrays, podemos emplearJSON.ARRPOPpara sacar un elemento de una posición oJSON.ARRTRIMpara recortar el array a un subconjunto de los elementos:JSON.DEL usuario:1 '$.ciudad' # (integer) 1 JSON.CLEAR usuario:1 '$.altura' # Ponemos la altura a 0 # (integer) 1 JSON.ARRPOP usuario:1 '$.hobbies' 0 # Sacamos el primer elemento # 1) "\"baloncesto\"" JSON.GET usuario:1 # "{\"nombre\":\"Aitor Medrano\",\"altura\":0,\"hobbies\":[\"m\xc3\xbasica\",\"videojuegos\",\"big data\"]}" JSON.ARRTRIM usuario:1 '$.hobbies' 1 2 # Nos quedamos con los elementos del 1 al 2 # 1) (integer) 2 JSON.GET usuario:1 # "{\"nombre\":\"Aitor Medrano\",\"altura\":0,\"hobbies\":[\"videojuegos\",\"big data\"]}"Otras operaciones comunes son
JSON.ARRLENpara averiguar el tamaño de un array oJSON.TYPEpara obtener el tipo de un determinado campo.
JSONPath¶
En el módulo de lenguaje de marcas ya habéis utilizado JSONPath para hacer consultas sobre documentos JSON. Aun así, vamos a repasar su sintaxis, la cual se basa en el uso de selectores:
| Símbolo | Significado | Ejemplo | Explicación |
|---|---|---|---|
$ |
Raíz del documento | $.nombre |
Selecciona el campo "nombre" en la raíz |
. |
Acceso a propiedades | $.usuario.nombre |
Accede a propiedades anidadas |
[] |
Indexación de arrays | $.hobbies[0] |
Selecciona el primer elemento del array |
* |
Comodín para todos los elementos | $.usuario.* |
Selecciona todas las propiedades de usuario |
.. |
Búsqueda recursiva | $..nombre |
Busca "nombre" en cualquier nivel |
Preparando datos
Vamos a crear un documento JSON complejo, con datos de dos usuarios con elementos anidados y uso de arrays, para ilustrar diferentes consultas:
JSON.SET usuarios $ '{
"usuarios": [
{
"id": 1,
"nombre": "Aitor Medrano",
"edad": 21,
"contacto": {
"email": "a.medrano@edu.gva.es",
"telefonos": ["636 123456", "686 567890"]
},
"hobbies": ["programación", "música", "viajes"],
"direcciones": [
{"tipo": "casa", "ciudad": "Elche"},
{"tipo": "trabajo", "ciudad": "Elche"}
]
},
{
"id": 2,
"nombre": "Juani Moya",
"edad": 18,
"contacto": {
"email": "j.moya@edu.gva.es",
"telefonos": ["696 543210"]
},
"hobbies": ["lectura", "música", "deporte"],
"direcciones": [
{"tipo": "casa", "ciudad": "Murcia"},
{"tipo": "trabajo", "ciudad": "Elche"}
]
}
]
}'
Para poder ejecutar la instrucción, bien necesitamos que esté en una única línea:
redis-cli JSON.SET usuarios $ '{"usuarios":[{"id":1,"nombre":"Aitor Medrano","edad":21,"contacto":{"email":"a.medrano@edu.gva.es","telefonos":["636 123456","686 567890"]},"hobbies":["programación","música","viajes"],"direcciones":[{"tipo":"casa","ciudad":"Elche"},{"tipo":"trabajo","ciudad":"Elche"}]},{"id":2,"nombre":"Juani Moya","edad":18,"contacto":{"email":"j.moya@edu.gva.es","telefonos":["696 543210"]},"hobbies":["lectura","música","deporte"],"direcciones":[{"tipo":"casa","ciudad":"Murcia"},{"tipo":"trabajo","ciudad":"Elche"}]}]}'
O podemos almacenar los datos en un archivo JSON (por ejemplo, usuarios.json) y ejecutarlo desde fuera del CLI mediante:
redis-cli JSON.SET usuarios $ "$(cat usuarios.json)"
Para nuestras primeras consultas, usaremos los selectores básicos:
JSON.GET usuarios '$.usuarios[0]' # Recuperamos el primer usuario
# "[{\"id\":1,\"nombre\":\"Aitor Medrano\",\"edad\":21,\"contacto\":{\"email\":\"a.medrano@edu.gva.es\",\"telefonos\":[\"636 123456\",\"686 567890\"]},\"hobbies\":[\"programaci\xc3\xb3n\",\"m\xc3\xbasica\",\"viajes\"],\"direcciones\":[{\"tipo\":\"casa\",\"ciudad\":\"Elche\"},{\"tipo\":\"trabajo\",\"ciudad\":\"Elche\"}]}]"
JSON.GET usuarios '$.usuarios[*].nombre' # Obtenemos el nombre de todos los usuarios
# "[\"Aitor Medrano\",\"Juani Moya\"]"
JSON.GET usuarios '$.usuarios[*].contacto.telefonos[0]' # Primer teléfono de cada usuario
# "[\"636 123456\",\"696 543210\"]"
Datos sin escapar
Si queremos recuperar los datos sin escapar las llaves, corchetes, etc..., desde fuera del cliente, podemos invocarlo pasándole la consulta y el parámetro --raw:
redis-cli --raw JSON.GET usuarios '$.usuarios[0]'
# [{"id":1,"nombre":"Aitor Medrano","edad":21,"contacto":{"email":"a.medrano@edu.gva.es","telefonos":["636 123456","686 567890"]},"hobbies":["programación","música","viajes"],"direcciones":[{"tipo":"casa","ciudad":"Elche"},{"tipo":"trabajo","ciudad":"Elche"}]}]
Por ejemplo, podemos filtrar los datos haciendo uso de expresiones de filtrado mediante ?() para restringir los documentos.
Las rutas dentro de la condición de filtro utilizan la notación de punto con @ para indicar el elemento actual del array o el valor actual del objeto, o $ para indicar el elemento de nivel superior. Es importante destacar que Redis no soporta el operador ?() para filtrar arrays directamente en la consulta.
Por ejemplo:
# Nombre de los usuarios menores de 20 años
JSON.GET usuarios '$.usuarios[?(@.edad < 20)].nombre'
# "[\"Juani Moya\"]"
# Nombre del usuario cuyo email es a.medrano@edu.gva.es
JSON.GET usuarios '$.usuarios[?(@.contacto.email == "a.medrano@edu.gva.es")].nombre'
# "[\"Aitor Medrano\"]"
También podemos emplear .. para realizar búsquedas recursivas:
JSON.GET usuarios '$..nombre' # Encontrar todos los elementos llamados "nombre"
# "[\"Aitor Medrano\",\"Juani Moya\"]"
JSON.GET usuarios '$..ciudad' # Encontrar todas las ciudades
# "[\"Elche\",\"Elche\",\"Murcia\",\"Elche\"]"
Una vez vistas estas operaciones, cabe destacar que:
- Redis tiene soporte limitado para JSONPath complejo, por lo que si necesitamos hacer consultas avanzadas, bien necesitaremos hacerlas mediante un lenguaje de programación para realizar el procesamiento adicional u optar por una solución documental como MongoDB.
- La eficiencia depende del tamaño y complejidad del documento
Otras estructuras de datos menos comunes son:
- Bitmaps: estructura compacta que permite operaciones a nivel de bit.
- HyperLogLog: estimación según valores unívocos.
- Stream: lista de strings o pares complejos de clave-valor.
-
Vector set (desde Redis 8): conjunto de elementos asociados a un vector (lista de números en coma flotante) que permite búsquedas por similitud. Es la pieza con la que Redis se posiciona como base de datos vectorial para aplicaciones de IA generativa (almacén de embeddings, RAG, sistemas de recomendación).
Vector sets y bases de datos vectoriales
Los Vector Sets funcionan conceptualmente como un conjunto ordenado, pero en lugar de una puntuación numérica, cada miembro lleva asociado un vector multidimensional. La búsqueda no es por puntuación, sino por proximidad entre vectores (vecinos más cercanos), usando un índice HNSW.
Los comandos comienzan por la letra
V:VADDpara insertar un elemento con su vector,VSIMpara buscar elementos similares,VCARDpara la cardinalidad,VDIMpara la dimensionalidad yVEMBpara recuperar el vector de un elemento.VADD productos VALUES 3 0.10 0.20 0.30 portatil # (integer) 1 VADD productos VALUES 3 0.11 0.21 0.31 ultrabook # (integer) 1 VADD productos VALUES 3 0.90 0.10 0.05 sandalias # (integer) 1 VSIM productos ELE portatil COUNT 2 WITHSCORES # 1) "portatil" # 2) "1" # 3) "ultrabook" # 4) "0.9998..."Profundizaremos en bases de datos vectoriales en cursos de especialización en IA y Big Data. Para más información, consulta la documentación oficial de Vector Sets.
Puesto que Redis es un sistema de código abierto, hay muchos desarrolladores trabajando para ampliar el sistema. Los llamados módulos o ampliaciones aumentan el rango de funciones de la base de datos, que por lo demás es bastante sencilla, y adaptan el software a ámbitos de uso específicos.
Mensajería¶
Existen diferentes sistemas de mensajería que permiten desacoplar el emisor de datos del receptor, como pueden ser RabbitMQ, Celery o incluso Apache Kafka en sistemas de Big Data. Si no necesitamos una solución tan potente, Redis ofrece un mecanismo de Publicación-Suscripción que permite a los clientes enviar y recibir mensajes en tiempo real desacoplando a unos de otros, lo que se traduce en un procesamiento asíncrono de los datos.
El modelo Pub/Sub es un patrón de comunicación donde los emisores (publicadores) no programan los mensajes para ser enviados directamente a receptores específicos (suscriptores). En su lugar, los mensajes publicados se colocan en canales, sin conocimiento de qué suscriptores pueden existir.
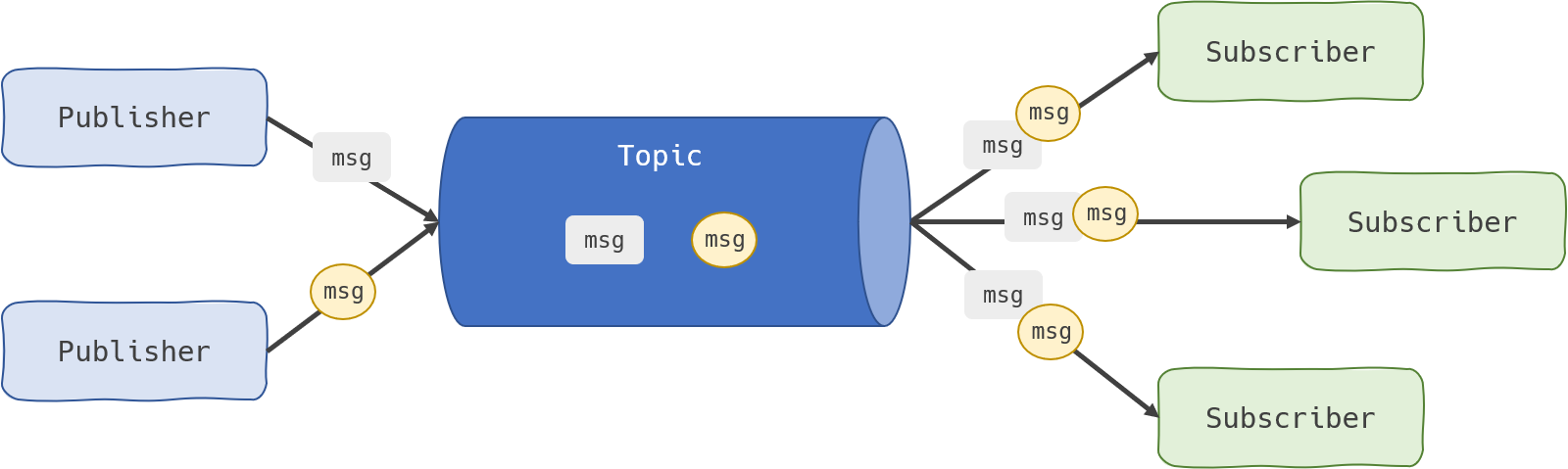
Los clientes pueden suscribirse a canales y recibir mensajes publicados en esos canales por otros clientes. Este mecanismo es útil para implementar sistemas de mensajería, notificaciones en tiempo real, actualizaciones en tiempo real, etc...
Para ello, se emplean los siguientes comandos:
SUBSCRIBE canal [canal …]: Se suscribe a uno o más canales.UNSUBSCRIBE [canal [canal …]]: Se desuscribe de uno o más canales.PUBLISH canal mensaje: Publica un mensaje en un canal.
Vamos a comenzar creando un suscriptor que se suscribe a un canal de noticias. Al lanzarlo, el cliente se quedará a la espera de recibir mensajes:
SUBSCRIBE noticias
# 1) "subscribe"
# 2) "noticias"
# 3) (integer) 1
# Reading messages... (press Ctrl-C to quit or any key to type command)
En otro terminal, ahora creamos un publicador que publica un mensaje en el canal de deportes, y luego en el canal de noticias:
PUBLISH deportes "Nikola Jokic logra el triple-doble con mayor anotación de la historia"
# (integer) 0
PUBLISH noticias "Inteligencia Artificial y Data: la nueva familia de FP que se abre paso"
# (integer) 1
Justo en el momento de publicar en el canal noticias, el suscriptor recibe el mensaje.
SUBSCRIBE noticias
# 1) "subscribe"
# 2) "noticias"
# 3) (integer) 1
# 1) "message"
# 2) "noticias"
# 3) "Inteligencia Artificial y Data: la nueva familia de FP que se abre paso"
# Reading messages... (press Ctrl-C to quit or any key to type command)
Uso de patrones
Si nos queremos suscribir a más de un canal, podemos emplear PSUBSCRIBE que nos permite utilizar patrones en los nombres de los canales, tanto ? para sustituir un carácter, * para uno o más elementos o emplear [] para indicar el conjunto de caracteres.
Por ejemplo, si queremos suscribirnos a canales que acaben en s, haríamos:
PSUBSCRIBE *s
¿Y qué sucede si ahora creamos un suscriptor sobre el canal deportes? Pues que no recibirá ningún mensaje, ya que Redis distribuye los mensajes inmediatamente a todos los clientes que están activamente suscritos al canal. Si no hay ningún cliente suscrito, Redis simplemente descarta el mensaje. El comando PUBLISH devolverá 0, indicando que ningún cliente recibió el mensaje.
Cuando un nuevo cliente se suscribe posteriormente a un canal existente utilizando SUBSCRIBE canal, solo recibirá los mensajes que se publiquen después de que se haya establecido su suscripción. No hay ningún mecanismo integrado en Redis Pub/Sub para recuperar mensajes históricos o pendientes.
Esta característica diferencia Redis Pub/Sub de otros sistemas de mensajería como Kafka o RabbitMQ, que pueden almacenar mensajes hasta que sean consumidos. Redis Pub/Sub está diseñado para comunicación en tiempo real donde la persistencia de mensajes no es una prioridad.
Es por ello, que Redis Pub/Sub es ideal para aplicaciones que requieren comunicación en tiempo real con baja latencia donde la pérdida ocasional de mensajes es aceptable. Algunos casos de uso comunes incluyen notificaciones en tiempo real, actualizaciones de sensores en tiempo real, comunicación en sistemas distribuidos, aplicaciones de chat, actualizaciones de puntuaciones en vivo, etc...
Otras operaciones que podemos realizar sobre los canales son:
PUBSUB CHANNELS [patron]: Lista todos los canales activos (que cumplen algún patrón)PUBSUB NUMSUB [canal [canal …]]: Recupera la cantidad de suscriptores de los canales indicados.
Pub/Sub vs Streams
El mecanismo Pub/Sub que acabamos de ver es efímero: si un suscriptor no está conectado en el momento de la publicación, pierde el mensaje. Esto contrasta con sistemas como Kafka o RabbitMQ, donde los mensajes se persisten hasta ser consumidos.
Redis ofrece, desde la versión 5, un tipo de dato pensado para esos escenarios: los Streams, una estructura tipo log persistente con grupos de consumidores (consumer groups) que sí permite que cada mensaje se procese por un único consumidor de un grupo, mantener el desplazamiento de cada consumidor, releer mensajes antiguos, etc...
Sus comandos comienzan por la letra X: XADD para añadir, XREAD para leer, XRANGE para consultar por rango, XGROUP y XREADGROUP para grupos de consumidores. Aunque queda fuera del alcance de esta unidad, conviene saber que existe esta alternativa cuando Pub/Sub se nos quede corto.
Persistencia¶
Por defecto, la gestión de la persistencia en Redis implica que los datos no se almacenan instantáneamente en disco, sino que se realiza de forma periódica o a petición del cliente.
Si queremos, de forma explícita, provocar que se persistan los datos en disco, usaremos el comando SAVE:
SAVE
# OK
En cuanto a la configuración para que se realice de forma periódica, en redis.conf se especifica el número de cambios ocurridos antes de almacenar una instantánea de los datos en disco, lo que se conoce como la persistencia RDB (Redis DataBase). Los valores predeterminados son:
save 900 1 # Guarda cada 15 minutos si se modificó al menos 1 clave
save 300 10 # Guarda cada 5 minutos si al menos cambiaron 10 claves
save 60 10000 # Guarda cada 60 segundos si al menos cambiaron 10000 claves
Esto puede provocar pérdida de datos en caso de fallo. Para evitarlo, Redis dispone del archivo appendonly.aof que guarda un registro para cada operación de escritura, lo que se conoce como persistencia AOF (Append Only File). Si el servidor cae antes de escribir en disco, cuando vuelva a estar disponible incluirá lo que esté pendiente.
appendonly yes
appendfsync everysec # Sincroniza cada segundo (opciones: always, everysec, no)
La elección entre un mecanismo y otro va a depender de las necesidades de la aplicación, evaluando la criticidad de los datos y del rendimiento. RDB es más eficiente, al utilizar un archivo único compacto, ideal para copias de seguridad. En cambio, puede suponer una posible pérdida de datos entre instantáneas.
En cambio, como AOF registra todas las operaciones de escritura, ofrece mayor durabilidad y menor pérdida de datos, pero empleando archivos más grandes y con un peor rendimiento.
En resumen¶
Redis destaca por su velocidad extrema, permitiendo realizar operaciones en cuestión de microsegundos. Su flexibilidad no se limita a un simple sistema clave-valor, sino que ofrece estructuras de datos avanzadas, lo que lo convierte en una herramienta versátil para distintas aplicaciones.
Además, permite la ejecución de operaciones atómicas, como el incremento de valores con INCR, garantizando la coherencia de los datos. Otra de sus ventajas es la gestión nativa del tiempo de vida de las claves (TTL), lo que facilita la expiración automática de datos.
Sin embargo, Redis también presenta ciertas limitaciones. Su principal restricción es que los datos deben almacenarse en memoria RAM, lo que impone un límite de capacidad. Además, no impone una estructura de datos estricta, ya que no cuenta con validación de esquemas o tipos. Sus opciones de consulta son limitadas, ya que solo permite búsquedas por clave o patrones simples. A diferencia de las bases de datos relacionales, no soporta integridad referencial, por lo que no se pueden definir claves ajenas ni realizar uniones (JOIN). También, dependiendo de su configuración, la durabilidad de los datos no está garantizada, existiendo la posibilidad de pérdida de información. Sus transacciones, aunque permiten la ejecución de múltiples operaciones, no disponen de un mecanismo de reversión (rollback) real.
Redis es la opción ideal cuando se requiere acceso a los datos con latencias mínimas, especialmente en aplicaciones donde los datos pueden modelarse con estructuras simples. Sus casos de uso más comunes son sistemas de caché, contadores, colas y almacenamiento de información en tiempo real con alta concurrencia. Además, su capacidad de gestionar automáticamente la expiración de datos lo convierte en una herramienta valiosa en escenarios donde la información tiene un ciclo de vida determinado.
Referencias¶
- Redis University, portal formativo de Redis.io con diversos cursos sobre Redis.
- Redis Cheat Sheet
- Seminario de Redis por Manuel Torres, de la Universidad de Almería.
- Tutorial de Redis de Ionos.
- El libro Redis Deep Dive, de Suyog Dilip Kale y Chinmay Kulkarni.
Actividades¶
-
AC1207. (RABD.7 // CE7c, CE7d, CE7e // 3p) Una vez puesto en marcha Redis, y utilizando cadenas cuyas claves utilicen el prefijo
ac1207:pelis:, se pide:- Inserta 3 títulos de películas (por ejemplo, usando las claves
ac1207:pelis:1,ac1207:pelis:2, etc...). - Inserta 2 películas con una sola instrucción.
- Comprueba si existe la primera película que has insertado, así como una que no debería existir.
- Recupera mediante una sola instrucción las dos primeras películas.
- Recupera todas las claves.
- Recupera las dos primeras claves.
- Elimina la tercera película.
- Asigna un tiempo de vida de 30 minutos a la segunda película.
- Crea una nueva película con un tiempo de vida de dos horas.
- Comprueba el tiempo de vida de la segunda película.
- Inserta 3 títulos de películas (por ejemplo, usando las claves
-
AC1208. (RABD.7 // CE7d, CE7e // 3p) Utilizando las hashes en Redis con el prefijo
ac1208:pelis:, se pide:- Crea un hash para añadir a la película
ac1208:pelis:1la propiedadtitulo. - Para la misma película, mediante una única operación, añade las propiedades
anyoyplataforma(plataforma de streaming donde hemos visto la película, o biencineotvdependiendo del caso). - Recupera el año de la película.
- Recupera toda la información de la película.
- En otra clave, añade una nueva película con todas sus propiedades.
- Recupera todas las claves de la última película.
- Recupera todos los valores de la última película.
- En nuevas claves, añade dos películas más.
- Recupera los valores de la última película.
- Recupera todas las hashes existentes.
- Elimina el año de la última película.
- Averigua cuántos campos tiene la última película.
- Elimina la última película.
- Vuelve a recuperar todas las hashes existentes para comprobar que ya no existe.
- Crea un hash para añadir a la película
- AR1209. (RABD.7 // CE7d, CE7e // 3p) Utilizando clave sencillas pero utilizando los prefijos en forma de árbol, vuelve a rehacer la actividad anterior. Por ejemplo, para la primera película, debes utilizar el prefijo
ar1209:pelis:1, de manera que el titulo se almacenará en la clavear1209:pelis:1:titulo.
-
AC1210. (RABD.7 // CE7d, CE7e // 3p) Utilizando las listas en Redis, se pide:
- Crea una lista que permita almacenar las series que marca un usuario como
ac1210:watchlist, y añade 3 títulos de series a la lista por la izquierda. - Añade 2 series a la lista por la derecha.
- Recupera el tamaño de la lista.
- Recupera todas las series.
- Recupera la primera y la última.
- Saca el último elemento insertado por la derecha.
- Comprueba si la lista tiene un elemento menos.
- Crea una lista que permita almacenar las series que marca un usuario como
-
AP1211. (RABD.7 // CE7d, CE7e // 3p) Utilizando las listas de Redis, se pide simular una cola. Para ello:
- Crea una cola llamada
ap1211:emails:pendientes. - Añade 3 mensajes de email al final de la cola. Cada mensaje es una cadena con formato JSON con los campos
para,asuntoytexto. - Procesa el primer mensaje (extráelo).
- Verifica cuántos mensajes quedan.
- Añade un mensaje prioritario al inicio de la cola.
- Procesa los mensajes restantes.
- Comprueba que quedan 0 mensajes.
- Crea una cola llamada
-
AC1212. (RABD.7 // CE7d, CE7e // 3p) Utilizando los conjuntos en Redis, se pide:
- Crea un conjunto que permita almacenar bases de datos NoSQL dentro de
ac1212:nosqly añade los valoresRedis,MongoDByNeo4j. - Vuelve a añadir al conjunto el valor
Redis. - Recupera los elementos del conjunto. ¿Cuántas veces aparece
Redis? ¿Por qué? - Crea otro conjunto que permita almacenar bases de datos relacionales dentro de
ac1212:sql. - Añade al conjunto los valores
MariaDB,PostgreSQLyOracle. - Comprueba si el conjunto
ac1212:sqlcontieneRedis. - Crea el conjunto
ac1212:bdcon la union de los dos conjuntos. - Recupera cuántos elementos tiene el nuevo conjunto.
- Recupera los elementos del nuevo conjunto.
- Elimina del nuevo conjunto el valor
Neo4j. - Comprueba si hay algún elemento compartido entre los dos conjuntos iniciales.
- Recupera dos elementos aleatorios de cada conjunto (sin repetidos)
- Recupera dos elementos aleatorios de cada conjunto (con repetidos)
- Crea un conjunto que permita almacenar bases de datos NoSQL dentro de
-
AP1213. (RABD.7 // CE7d, CE7e // 3p) Utilizando los conjuntos ordenados en Redis, se pide:
- Crea el conjunto ordenado
ap1213:bdque permita almacenar bases de datos con una puntuación donde calificaremos nuestro conocimiento, y añade los valoresRediscon 50 puntos,Neo4jcon 5 puntos,MariaDBcon 90 puntos yMongoDBcon 20 puntos. - Recupera los elementos donde tengamos un conocimiento entre 30 y 95 puntos.
- Recupera los elementos donde tengamos un conocimiento entre 20 y 90 puntos, pero sin incluir esos valores.
- Recupera los elementos donde tengamos un conocimiento entre 5 y 100 puntos, con las puntuaciones asociadas.
- Recupera el número de elementos del conjunto ordenado.
- Recupera todos los elementos de menor a mayor conocimiento.
- Recupera todos los elementos de mayor a menor conocimiento.
- Elimina el elemento
Neo4j.
- Crea el conjunto ordenado
-
AC1214. (RABD.7 // CE7d, CE7e // 3p) Utilizando los comandos para gestionar documentos JSON en Redis, se pide:
- Crea un documento JSON con tus datos que represente un usuario con
nombre,edadyemail, y almacénalo en Redis en la claveac1214:usuario:yo. - Recupera y muestra el documento completo.
- Recupera y muestra solo el campo
nombredel documento. - Modifica el
emailcon un nuevo correo electrónico. - Añade un nuevo campo
direccioncon un subdocumento que contenga varios elementos (calle,ciudad,codPostal). - Incrementa numéricamente tu edad en 1.
- Añade un número de teléfono al documento en formato array.
- Añade otro número de teléfono al array (el resultado contendrá dos elementos).
- Recupera el documento y comprueba los elementos existentes.
- Crea un documento JSON con tus datos que represente un usuario con
-
AP1215. (RABD.7 // CE7d, CE7e // 3p) Utilizando los comandos para gestionar documentos JSON en Redis, y a partir del siguiente documento:
{ "nombre":"Electrónica Severa", "productos":[ {"id":1, "nombre":"Portátil", "precio":899.99}, {"id":2, "nombre":"Monitor", "precio":299.99} ] }Se pide:
- Inserta el documento en Redis con la clave
ap1215:tienda. - Añade una Tablet al array de
productoscon un precio de399.99. - Inserta un nuevo producto (el que tú quieras), pero añádelo en la segunda posición.
- Añade un campo
cantidadcuyo valor sea4. - Elimina el primer producto del array mediante su índice.
- Reduce el campo
cantidaden una unidad. - Recupera el último producto del array.
- Modifica el precio de la tablet a
299.99. - Recupera el tamaño del array de
productosy comprueba si concuerda concantidad. - Recupera todos los productos existentes.
- Inserta el documento en Redis con la clave
-
AC1216. (RABD.7 // CE7d, CE7e // 3p) Utilizando el mecanismo de publicación/suscripción en Redis, se pide:
- En un primer terminal, suscríbete al canal
canal.general. - En otro terminal, suscríbete a la vez a los canales
canal.generalycanal.alertas. - En un tercer terminal, publica mensajes diferentes en cada canal.
- Comprueba si los mensajes aparecen en los diferentes canales.
- En el tercer terminal, publica un mensaje en el canal
canal.importante. - Comprueba si el mensaje aparece en los diferentes canales.
- En un cuarto terminal, suscríbete a todos los canales usando el patrón
canal.*. ¿Ha recibido algún mensaje al suscribirse? - En el tercer terminal, averigua cuántos suscritores tiene cada canal.
- En un primer terminal, suscríbete al canal
- AR1217. (RABD.1, RABD.7 // CE7c, CE7d, CE7e // 3p) De forma similar a las cheatsheets técnicas, crea una tabla resumen con los comandos más importantes que hemos trabajado en esta sesión.
-
PR1218. (RABD.7 // CE7c, CE7d, CE7e // 6p) Vamos a modelar parte del backend de una plataforma de streaming de películas, eligiendo en cada caso la estructura de datos de Redis más adecuada. Todas las claves usarán el prefijo
pr1218:. Se pide:- Catálogo. Crea tres películas como documentos JSON en
pr1218:peli:1,pr1218:peli:2ypr1218:peli:3, cada una con los campostitulo,director,anyo,generos(array) yduracion(en minutos). - Sesión de usuario. Crea un hash en
pr1218:sesion:abc123con los camposusuario,ipyloginAt. Asígnale una expiración de 30 minutos. Comprueba el TTL. - Histórico de visualizaciones. Cada vez que el usuario reproduce una película, se inserta en
pr1218:user:usuario1:historicopor la izquierda. Haciendo uso de una lista, inserta tres reproducciones, recupera la última y limita la lista a las 10 más recientes. - Películas favoritas. Mediante un conjunto, añade dos películas favoritas a
pr1218:user:usuario1:favsy otras dos diferentes (con una en común) apr1218:user:usuario2:favs. Calcula qué películas tienen en común ambos usuarios y guarda el resultado enpr1218:recomendaciones. - Ranking de las más vistas. Mediante un conjunto ordenado, crea
pr1218:rankingy, medianteZINCRBY, simula una visualización para cada película. Recupera el top 3 con sus puntuaciones. - Simula un contador atómico mediante una transacción
MULTI/EXEC. Para ello, registra una nueva visualización: incrementa el ranking depr1218:peli:1, añádela al histórico depr1218:user:usuario2:historicoe incrementa el contador globalpr1218:visualizaciones:total. - Notificaciones. En un terminal aparte, suscríbete al canal
pr1218:novedadesy, desde el terminal principal, publica un mensaje anunciando una nueva película. Verifica la recepción. - Para terminar, y a modo de reflexión final, en un párrafo de 5-10 líneas, justifica los tipos de datos elegidos y qué problema habría supuesto usar uno distinto en cada apartado.
- Catálogo. Crea tres películas como documentos JSON en
-
AR1219. (RABD.7 // CE7c, CE7d, CE7e // 3p) Hasta esta unidad hemos trabajado con MariaDB para almacenar datos persistentes. Uno de los usos más habituales de Redis es acelerar el acceso a esos datos evitando consultas repetidas. Vamos a simular este patrón conocido como cache-aside. Trabaja con el prefijo
ar1219:. Se pide:-
Imagina que tienes la siguiente fila en
MariaDB(no hace falta lanzarla):SELECT id, nombre, salario FROM empleado WHERE id = 7; -- 7, "Aitor Medrano", 35000Almacena el resultado en Redis como un hash en
ar1219:empleado:7con TTL de 5 minutos. -
Comprueba que existe la clave y recupera el nombre. Esto simula una consulta resuelta desde caché (sin tocar
MariaDB). - Imagina ahora que se actualiza el salario de Aitor en
MariaDB. La clave en Redis ha quedado obsoleta; invalida la caché borrándola. - Vuelve a consultar
ar1219:empleado:7. Como ya no existe (en una aplicación real, este es el momento en que iríamos aMariaDB), recréala con el salario actualizado a38000y vuelve a poner TTL de 5 minutos. - Patrón de caché negativa. Para evitar que las consultas a IDs inexistentes saturen la base de datos, también se cachean los
nil. Creaar1219:empleado:99con valor"NOT_FOUND"y TTL de 60 segundos. -
Responde brevemente: ¿qué es la cache stampede? ¿Qué dos problemas resuelve poner TTL a las claves de caché? ¿En qué casos no tendría sentido usar Redis como caché de
MariaDB?Patrón cache-aside
El patrón cache-aside (también llamado lazy loading) es el más habitual con Redis: la aplicación primero consulta Redis; si la clave existe, se devuelve el valor; si no, se consulta la base de datos relacional, se almacena el resultado en Redis con un TTL y se devuelve a la aplicación.
-
- AR1220. (RABD.1, RABD.7 // CE7c, CE7d // 3p) Una vez finalizada la unidad, responde todas las preguntas del cuestionario inicial, con al menos un par de líneas para cada una de las cuestiones.