MongoDB¶
Propuesta didáctica¶
En la última unidad terminaremos de trabajar el siguiente resultado de aprendizaje (RA):
- RA7: Gestiona la información almacenada en bases de datos no relacionales, evaluando y utilizando las posibilidades que proporciona el sistema gestor.
Criterios de evaluación¶
- CE7c: Se han identificado los elementos utilizados en estas bases de datos.
- CE7d: Se han identificado distintas formas de gestión de la información según el tipo de base de datos no relacionales.
- CE7e: Se han utilizado las herramientas del sistema gestor para la gestión de la información almacenada.
Contenidos¶
Bases de datos no relacionales:
- Elementos de las bases de datos no relacionales.
- Sistemas gestores de bases de datos no relacionales.
- Herramientas de los sistemas gestores de bases de datos no relacionales para la gestión de la información almacenada.
Cuestionario inicial
- ¿Qué es MongoDB y cuáles son sus principales características como base de datos NoSQL?
- ¿Cuáles son las ventajas y desventajas de utilizar MongoDB como sistema de almacenamiento en memoria frente a otros sistemas de almacenamiento persistente?
- ¿Cómo se diferencian las bases de datos documentales de las bases de datos relacionales tradicionales?
- ¿Qué formato utiliza MongoDB para almacenar los documentos internamente?
- ¿Qué comando se utiliza para insertar un documento en una colección en MongoDB?
- ¿Cómo se accede a una base de datos específica en el shell de MongoDB?
- ¿Qué operador se utiliza para seleccionar documentos que cumplen múltiples condiciones en una consulta?
- ¿Qué operador se emplea para realizar consultas sobre campos que son arrays?
- ¿Cómo se proyectan campos específicos en los resultados de una consulta?
- ¿Qué operador permite realizar comparaciones entre campos dentro de un mismo documento?
- ¿Qué función se utiliza para contar el número de documentos que cumplen una condición específica?
- ¿Qué operador se utiliza para actualizar múltiples documentos que cumplen una condición?
- ¿Cómo se realiza una búsqueda utilizando expresiones regulares en MongoDB?
- ¿Qué operador se utiliza para agregar un elemento a un array dentro de un documento?
- ¿Cómo se reemplaza completamente un documento en una colección?
- ¿Qué operador permite actualizar un elemento específico dentro de un array?
-
¿Cómo se eliminan documentos que cumplen una condición específica?
-
¿Cuáles son las dos formas principales de representar relaciones entre documentos en MongoDB?
- ¿En qué casos es preferible usar datos embebidos en lugar de referencias manuales?
- ¿Cómo se modela una relación 1:N en MongoDB?
- ¿Qué ventajas ofrece el uso de datos embebidos en términos de rendimiento?
-
¿Qué consideraciones deben tenerse en cuenta al decidir entre embebido y referenciado?
-
¿Qué es el pipeline de agregación en MongoDB y cómo funciona?
- ¿Qué función cumple el operador
$groupen una consulta agregada? - ¿Cómo se utiliza el operador
$projecten el pipeline de agregación? - ¿Qué permite hacer el operador
$lookupen una consulta agregada? - ¿Cómo se pueden limitar y ordenar los resultados en una consulta agregada?
Programación de Aula (11h)¶
Esta unidad es la segunda del bloque de soluciones NoSQL, la cual se imparte a final de curso, con una duración estimada de 11 horas:
| Sesión | Contenidos | Actividades | Criterios trabajados |
|---|---|---|---|
| 1 | MongoDB | AC1301 | CE7c, CE7d, CE7e |
| 2 | Consultas sencillas | AC1302 | CE7d, CE7e |
| 3 | Consultas avanzadas | AC1303 | CE7d, CE7e |
| 4 | Consultas con arrays | AC1305 | CE7d, CE7e |
| 5 | Modificaciones y borrados | AC1307 | CE7d, CE7e |
| 6 | Trabajando con arrays | AC1309 | CE7d, CE7e |
| 7 | Administración | ||
| 8 | Modelado documental | AC1311 | CE7d, CE7e |
| 9 | Consultas agregadas | AC1312 | CE7d, CE7e |
| 10 | Filtrando agregaciones y realizando joins | ||
| 11 | Supuesto | PR1314 | CE7d, CE7e |
MongoDB¶
MongoDB es una de las bases de datos NoSQL más conocidas y empleadas. Sigue un modelo de datos documental, donde los documentos se basan en el formato JSON.
MongoDB destaca porque:
- Soporta esquemas dinámicos: diferentes documentos de una misma colección pueden tener atributos diferentes.
- Aunque inicialmente tenía un soporte limitado de joins, desde la versión 5.2 se pueden realizar incluso entre colecciones particionadas.
- Soporte de transacciones sólo a nivel de aplicación. Lo que en un SGBD relacional puede suponer múltiples operaciones, con MongoDB se puede hacer en una sola operación al insertar/actualizar todo un documento de una sola vez, pero si queremos crear una transacción entre dos documentos, la gestión la debe realizar el driver.
huMONGOus
Como curiosidad, su nombre viene de la palabra inglesa humongous, que significa gigantesco/enorme.
Hay una serie de conceptos que conviene conocer antes de entrar en detalle:
- MongoDB tiene el mismo concepto de base de datos que un SGBD relacional. Dentro de una instancia de MongoDB podemos tener 0 o más bases de datos, actuando cada una como un contenedor de alto nivel.
- Una base de datos tendrá 0 o más colecciones. Una colección es muy similar a lo que entendemos como tabla dentro de una base de datos relacional. MongoDB ofrece diferentes tipos de colecciones, desde las normales cuyo tamaño crece conforme lo hace el número de documentos, como las colecciones capped, las cuales tienen un tamaño predefinido y que pueden contener una cierta cantidad de información que se sustituirá por nueva cuando se llene.
- Las colecciones contienen 0 o más documentos, por lo que es similar a una fila o registro de una tabla relacional.
- Cada documento contiene 0 o más atributos, compuestos de parejas clave/valor. Cada uno de estos documentos no sigue ningún esquema, por lo que dos documentos de una misma colección pueden contener todos los atributos diferentes entre sí. Todo documento contiene un campo
_idque hace la función de atributo identificador del documento.
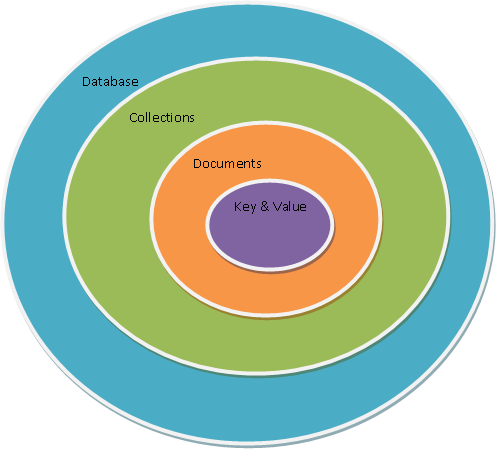
Así pues, tenemos que una base de datos va a contener varias colecciones, donde cada colección contendrá un conjunto de documentos.
Además, MongoDB soporta índices, igual que cualquier RDBMS, para acelerar la búsqueda de datos. Al realizar cualquier consulta, se devuelve un cursor, con el cual podemos realizar operaciones como contar, ordenar, limitar o saltar documentos.
BSON¶
Mediante JavaScript podemos crear objetos que se representan con JSON. Internamente, MongoDB almacena los documentos mediante BSON (Binary JSON). Podemos consultar la especificación en https://BSONSpec.org
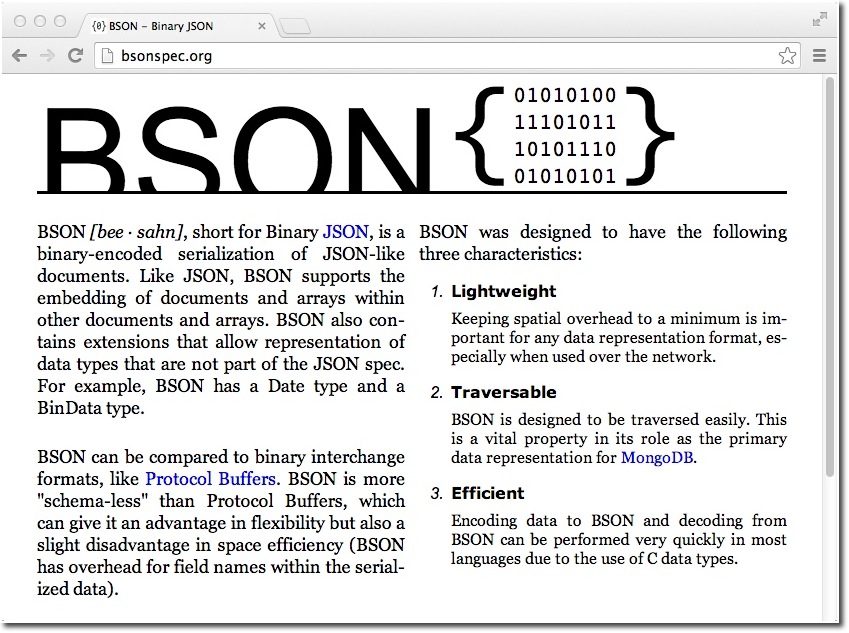
BSON representa un superset de JSON ya que:
- Permite almacenar datos en binario
- Incluye un conjunto de tipos de datos no incluidos en JSON, como pueden ser
ObjectId,DateoBinData. - Diseñado para ser más eficiente en espacio y realizar búsquedas de forma más rápida.
Podemos consultar todos los tipos que soporta un objeto BSON en https://docs.mongodb.org/manual/reference/bson-types/
Un ejemplo de un objeto BSON podría ser:
var yo = {
nombre: "Aitor",
apellidos: "Medrano",
fnac: new Date("Oct 3, 1977"),
hobbies: ["programación", "videojuegos", "baloncesto"],
casado: true,
hijos: 2,
contacto: {
bsky: "@aitormedrano.bsky.social",
email: "a.medrano@edu.gva.es"
},
fechaCreacion: new Timestamp()
}
Los documentos BSON tienen las siguientes restricciones:
- No pueden tener un tamaño superior a 16 MB.
- El atributo
_idqueda reservado para la clave primaria. - Desde MongoDB 5.0 los nombres de los campos pueden empezar por
$y/o contener el., aunque en la medida de lo posible, es recomendable evitar su uso.
Además, MongoDB:
- No asegura que el orden de los campos se respete.
- Es sensible a los tipos de los datos
- Es sensible a las mayúsculas.
Por lo que estos documentos son distintos:
{"edad": "18"}
{"edad": 18}
{"Edad": 18}
Si queremos validar si un documento JSON es válido, podemos usar https://jsonlint.com/. Hemos de tener en cuenta que sólo valida JSON y no BSON, por tanto nos dará errores en los tipos de datos propios de BSON.
Puesta en marcha¶
En la actualidad, MongoDB se comercializa mediante tres productos:
- Mongo Atlas, como plataforma cloud, con una opción gratuita mediante un clúster de 512MB.
- MongoDB Community Edition, versión gratuita para trabajar on-premise, con versiones para Windows, MacOS y Linux.
- MongoDB Enterprise Advanced, versión de pago con soporte, herramientas avanzadas de monitorización y seguridad, y administración automatizada.
En nuestro caso, por comodidad, trabajaremos con la versión cloud de Mongo Atlas. Los pasos necesarios para su creación, configuración y uso, así como la conexión mediante MongoDBCompass los puedes encontrar en la sección de Entorno
Uso del shell¶
Una vez ya tenemos en marcha MongoDB, llega el momento de conectarnos. Aunque utilizaremos MongoDB Compass, durante esta unidad vamos a practicar los diferentes comandos haciendo uso del cliente mongosh (en versiones anteriores el comando utilizado era mongo). Para ello, en la parte superior derecha, tenemos la opción de >_ Open MongoDB shell.
El shell de MongoDB utiliza JavaScript como lenguaje de interacción con la base de datos, y como buen shell, mediante la flecha hacia arriba visualizaremos el último comando.
Si queremos ver las bases de datos que existen ejecutaremos el comando show dbs:
Atlas atlas-pxc2m9-shard-0 [primary] pruebas> show dbs
pruebas 216.00 KiB
sample_airbnb 52.52 MiB
sample_analytics 8.93 MiB
sample_geospatial 1.29 MiB
sample_guides 40.00 KiB
sample_mflix 47.23 MiB
sample_restaurants 6.72 MiB
sample_supplies 1.05 MiB
sample_training 52.50 MiB
sample_weatherdata 3.32 MiB
admin 40.00 KiB
local 40.00 KiB
Uso externo
Si nos queremos conectar únicamente desde un terminal, podemos instalar únicamente el shell desde https://www.mongodb.com/try/download/shell
Hola MongoDB¶
Pues una vez que ya nos hemos conectado a MongoDB mediante mongosh, vamos a empezar a interactuar con los datos.
En cualquier momento podemos cambiar la base de datos activa mediante use nombreBaseDatos. Si la base de datos no existiese, MongoDB creará dicha base de datos. Esto es una verdad a medias, ya que la base de datos realmente se crea al insertar datos dentro de alguna colección.
Así pues, vamos a crear nuestra base de datos s8a:
use s8a
Una vez creada, podemos crear nuestra primera colección, que llamaremos personas, e insertaremos una persona con nuestros datos personales mediante el método insertOne, al que le pasamos un objeto JSON:
db.personas.insertOne({ nombre: "Aitor Medrano", edad: 47, profesion: "Profesor" })
Tipos de datos
Cuidado con los tipos, ya que no es lo mismo insertar un atributo con edad:47 (se considera el campo como entero) que con edad:"47", ya que considera el campo como texto.
Tras ejecutar el comando, veremos que nos devuelve un objeto JSON con su ACK y el identificador del documento insertado:
{
acknowledged: true,
insertedId: ObjectId('67fa9f27d152b48c68424418')
}
Una vez insertado el documento, sólo nos queda realizar una consulta para recuperar los datos y comprobar que todo funciona correctamente mediante el método findOne:
db.personas.findOne()
Lo que nos dará como resultado un objeto JSON que contiene un atributo _id con el mismo identificador mostrado anteriormente, además de los que le añadimos al insertar la persona:
{
_id: ObjectId('67fa9f27d152b48c68424418'),
nombre: 'Aitor Medrano',
edad: 47,
profesion: 'Profesor'
}
Como podemos observar, todas las instrucciones van a seguir el patrón de db.nombreColeccion.operacion().
ObjectId¶
En MongoDB, el atributo _id es único dentro de la colección, y hace la función de clave primaria. Se le asocia un ObjectId, el cual es un tipo BSON de 12 bytes que se crea mediante:
- el timestamp actual (4 bytes)
- un valor aleatorio y único por máquina y proceso (5 bytes)
- un contador inicializado a número aleatorio (3 bytes).
Este objeto lo crea el driver y no MongoDB, por lo cual no deberemos considerar que siguen un orden concreto, ya que clientes diferentes pueden tener timestamps desincronizados. Lo que sí que podemos obtener a partir del ObjectId es la fecha de creación del documento, mediante el método getTimestamp() del atributo _id.
Obteniendo la fecha de creación de un documento
db.personas.findOne()._id
// ObjectId('67fa9f27d152b48c68424418')
db.personas.findOne()._id.getTimestamp()
// 2025-04-12T17:13:11.000Z
Este identificador es global, único e inmutable. Esto es, no habrá dos repetidos y una vez un documento tiene un _id, éste no se puede modificar.
Si en la definición del objeto a insertar no ponemos el atributo identificador, MongoDB creará uno de manera automática. Si lo ponemos nosotros de manera explícita, MongoDB no añadirá ningún ObjectId. Eso sí, debemos asegurarnos de que sea único (podemos usar números, cadenas, etc…).
Por lo tanto, podemos asignar un identificador al insertar:
db.personas.insertOne({_id:4, nombre:"Marina", edad:17 })
// { acknowledged: true, insertedIds: { '0': 4 } }
O también, si queremos podemos hacer que el _id de un documento sea un documento en sí, y no un entero, para ello, al insertarlo, podemos asignarle un objeto JSON al atributo identificador:
db.personas.insertOne({_id:{nombre:'Aitor', apellidos:'Medrano', bsky:'@aitormedrano.bsky.social'}, ciudad:'Elx'})
// {
// acknowledged: true,
// insertedId: {
// nombre: 'Aitor',
// apellidos: 'Medrano',
// bsky: '@aitormedrano.bsky.social'
// }
// }
CRUD¶
Antes de entrar en detalles en las instrucciones necesarias para realizar las operaciones CRUD, veamos algunos comandos que nos serán muy útiles al interactuar con el shell:
| Comando | Función |
|---|---|
show dbs |
Muestra el nombre de las bases de datos |
show collections |
Muestra el nombre de las colecciones |
db |
Muestra el nombre de la base de datos que estamos utilizando |
db.dropDatabase() |
Elimina la base de datos actual |
db.help() |
Muestra los comandos disponibles |
db.version() |
Muestra la versión actual del servidor |
Y las operaciones básicas para realizar un CRUD, siguiendo la sintaxis db.nombreColeccion.operacion(), son:
insertOne: permite insertar un documentofindyfindOne: recupera los documentos (o el primero) de una coleccióncountDocuments: obtiene la cantidad de documentos de una colección
En el resto de la sesión vamos a hacer un uso intenso del shell de MongoDB. Por ejemplo, si nos basamos en el objeto definido en el apartado de BSON, podemos ejecutar las siguientes instrucciones:
db.personas.insertOne(yo) // (1)!
// {
// acknowledged: true,
// insertedId: ObjectId('67fbe737b496860bf5c3679e')
// }
db.personas.find() // (2)!
// [
// {
// _id: ObjectId('67fa9f27d152b48c68424418'),
// nombre: 'Aitor Medrano',
// edad: 47,
// profesion: 'Profesor'
// }
// {
// _id: ObjectId('67fbe737b496860bf5c3679e'),
// nombre: 'Aitor',
// apellidos: 'Medrano',
// fnac: 1977-10-02T23:00:00.000Z,
// hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
// casado: true,
// hijos: 2,
// contacto: {
// bsky: "@aitormedrano.bsky.social",
// email: 'a.medrano@edu.gva.es'
// },
// fechaCreacion: Timestamp({ t: 1744561974, i: 5 })
// }
// ]
yo.profesion = "Profesor"
// Profesor
db.personas.insertOne(yo) // (3)!
// {
// acknowledged: true,
// insertedId: ObjectId('67fbe851b496860bf5c3679f')
// }
db.personas.find() // (4)!
// [
// {
// _id: ObjectId('67fa9f27d152b48c68424418'),
// nombre: 'Aitor Medrano',
// edad: 47,
// profesion: 'Profesor'
// }
// {
// _id: ObjectId('67fbe737b496860bf5c3679e'),
// nombre: 'Aitor',
// apellidos: 'Medrano',
// fnac: 1977-10-02T23:00:00.000Z,
// hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
// casado: true,
// hijos: 2,
// contacto: {
// bsky: "@aitormedrano.bsky.social",
// email: 'a.medrano@edu.gva.es'
// },
// fechaCreacion: Timestamp({ t: 1744561974, i: 5 })
// }
// {
// _id: ObjectId('67fbe851b496860bf5c3679f'),
// nombre: 'Aitor',
// apellidos: 'Medrano',
// fnac: 1977-10-02T23:00:00.000Z,
// hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
// casado: true,
// hijos: 2,
// contacto: {
// bsky: "'@aitormedrano.bsky.social",
// email: 'a.medrano@edu.gva.es'
// },
// fechaCreacion: Timestamp({ t: 1744562256, i: 4 }),
// profesion: 'Profesor'
// }
// ]
db.personas.countDocuments() // (5)!
// 3
- Si queremos insertar un documento en una colección, hemos de utilizar el método
insertOnepasándole como parámetro el documento que queremos insertar, ya sea a partir de una variable o el propio documento en sí. findrecupera todos los documentos de la colección- Al volver a insertar el documento con un nuevo atributo
profesion, obtenemos un nuevoObjectId, ya que es un documento diferente al ya existente en la colección (y no por tener un atributo distinto, sino porque como no tiene atributo _id, le genera uno nuevo). - Modificamos nuestro documento y los volvemos a insertar. Realmente va a crear un nuevo documento, y no se va a quejar de que ya exista, porque nuestro documento no contiene ningún atributo identificador, por lo que considera que se trata de una nueva persona.
- Obtenemos la cantidad de documentos de la colección mediante
countDocuments.
Con este ejemplo, hemos podido observar cómo los documentos de una misma colección no tienen por qué tener el mismo esquema, ni hemos necesitado definirlo explícitamente antes de insertar datos. Así pues, el esquema se irá generando y actualizando conforme se inserten documentos. Más adelante veremos que podemos definir un esquema para validar que los datos que insertamos cumplan restricciones de tipos de datos o elementos que obligatoriamente deben estar rellenados.
Consultas¶
Para recuperar los datos de una colección o un documento en concreto usaremos el método find().
Para los siguientes ejemplos nos vamos a centrar en la colección zips de la base de datos de ejemplo sample_trainings que tenemos cargada en MongoAtlas, la cual contiene cerca de 29.000 documentos con información de códigos postales de USA:
use sample_training
db.zips.find()
// {
// _id: ObjectId('5c8eccc1caa187d17ca6ed40'),
// city: 'MORRIS',
// zip: '35116',
// loc: { y: 33.739172, x: 86.772551 },
// pop: 3622,
// state: 'AL'
// }
// ...
// Type "it" for more
El método find() sobre una colección devuelve un cursor a los datos obtenidos, el cual se queda abierto con el servidor y que se cierra automáticamente a los 30 minutos de inactividad o al finalizar su recorrido. Si hay muchos resultados, la consola nos mostrará un subconjunto de los datos (20). Si queremos seguir obteniendo resultados, solo tenemos que introducir it, para que continúe iterando el cursor.
En cambio, si sólo queremos recuperar un documento hemos de utilizar findOne():
db.zips.findOne()
// {
// _id: ObjectId('5c8eccc1caa187d17ca6ed40'),
// city: 'MORRIS',
// zip: '35116',
// loc: { y: 33.739172, x: 86.772551 },
// pop: 3622,
// state: 'AL'
// }
Criterios en consultas¶
Si queremos indicar un criterio para filtrar los datos, tanto a find como a findOne le pasaremos un documento JSON con los criterios a cumplir. El caso más sencillo es filtrar por el valor de un determinado campo.
db.zips.find({city: "TITUS"})
{
_id: ObjectId('5c8eccc1caa187d17ca6ee50'),
city: 'TITUS',
zip: '36080',
loc: {
y: 32.690019,
x: 86.239334
},
pop: 2683,
state: 'AL'
}
Si queremos acceder a campos de subdocumentos, siguiendo la sintaxis de JSON, se utiliza la notación punto. Esta notación permite acceder al campo de un documento anidado, da igual el nivel en el que esté y su orden respecto al resto de campos.
Para acceder a la coordenada x usaremos la propiedad loc.x, la cual obligatoriamente deberemos rodear mediante comillas:
db.zips.find({"loc.x": 86.239334})
En cambio, si queremos indicar más de un criterio, el documento con las condiciones contendrá tantos campos como elementos a filtrar. Así pues, para obtener aquellas poblaciones del estado AL dentro de la ciudad DELTA, haríamos:
db.zips.find({city: "DELTA", state: "AL"})
{
_id: ObjectId('5c8eccc1caa187d17ca6ee6e'),
city: 'DELTA',
zip: '36258',
loc: {
y: 33.457303,
x: 85.679279
},
pop: 1405,
state: 'AL'
}
Consejo de Rendimiento
Las consultas conjuntivas, es decir, con varios criterios u operador $and, deben filtrar el conjunto más pequeño cuanto más pronto posible.
Supongamos que vamos a consultar documentos que cumplen los criterios A, B y C. Digamos que el criterio A lo cumplen 40.000 documentos, el B lo hacen 9.000 y el C sólo 200. Si filtramos A, luego B, y finalmente C, el conjunto que trabaja cada criterio es muy grande.
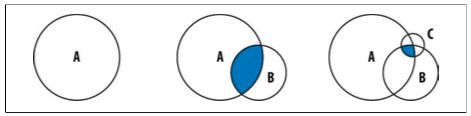
En cambio, si hacemos una consulta que primero empiece por el criterio más restrictivo, el resultado con lo que se intersecciona el siguiente criterio es menor, y por tanto, se realizará más rápido.

Esto es relevante en ausencia de índices o cuando ningún índice cubre la consulta. Con índices adecuados, el optimizador de MongoDB reorganiza los criterios automáticamente.
MongoDB también ofrece operadores lógicos para los campos numéricos:
| Comparador | Operador |
|---|---|
menor que (<) |
$lt |
menor o igual que (≤) |
$lte |
mayor que (>) |
$gt |
mayor o igual que (≥) |
$gte |
Estos operadores se pueden utilizar de forma simultánea sobre un mismo campo o sobre diferentes campos, sobre campos anidados o que forman parte de un array, y se colocan como un nuevo documento en el valor del campo a filtrar, compuesto del operador y del valor a comparar mediante la siguiente sintaxis:
db.<coleccion>.find({ <campo>: { <operador>: <valor> } })
Por ejemplo, para recuperar las poblaciones con menos de 1000 habitantes, o aquellas que tienen entre 2000 y 3000 personas, podemos hacer:
db.zips.find({pop: {$lt:1000} })
db.zips.find({pop: {$gt:2000, $lte:3000} })
Cuidado al repetir campos
Podemos pensar que la consulta anterior donde filtramos las poblaciones que tienen entre 2000 y 3000 personas, también la podríamos expresar mediante:
db.zips.find({pop: {$gt:2000}, pop: {$lte:3000}})
Pero no es así. Cuando repetimos el mismo campo, MongoDB únicamente evalúa el último, y por lo tanto, en esta consulta, recuperaría todos los documentos cuya población fuera menor o igual a 3000 habitantes (incluidos los menores de 2000), siendo equivalente a:
db.zips.find({pop: {$lte:3000}})
Para los campos de texto, además de la comparación directa, podemos usar el operador $ne para obtener los documentos cuyos campos no tienen un determinado valor (not equal). Así pues, podemos usarlo para averiguar todas las poblaciones que no pertenecen al estado de PA:
db.zips.find({state: {$ne:"PA"} })
Por supuesto, podemos tener diferentes operadores en campos distintos. Por ejemplo, si queremos recuperar las poblaciones del estado de AL con menos de 100 habitantes haríamos:
db.zips.find({pop: {$lt:100}, state: "AL" })
Case sensitive
Las comparaciones de cadenas se realizan siguiendo el orden UTF8, similar a ASCII, con lo cual no es lo mismo buscar un rango entre mayúsculas que minúsculas.
Con cierto parecido a la condición de valor no nulo de las BBDD relacionales y teniendo en cuenta que la libertad de esquema puede provocar que un documento tenga unos campos determinados y otro no lo tenga, podemos utilizar el operador $exists si queremos averiguar si un campo existe (y por tanto tiene algún valor).
use s8a
db.personas.find({edad: {$exists:true}})
Polimorfismo
Mucho cuidado al usar polimorfismo y almacenar en un mismo campo un entero y una cadena, ya que, al hacer comparaciones para recuperar datos, no vamos a poder mezclar cadenas con valores numéricos. Se considera un antipatrón el mezclar tipos de datos en un campo.
Pese a que ciertos operadores contengan su correspondiente operador negado, MongoDB ofrece el operador $not. Éste puede utilizarse conjuntamente con otros operadores para negar el resultado de los documentos obtenidos.
Por ejemplo, si queremos obtener todas las personas cuya edad no sea múltiplo de 5, podríamos hacerlo así:
db.personas.find({edad: {$not: {$mod: [5,0]}}})
Proyección de campos¶
Las consultas realizadas hasta ahora devuelven los documentos completos. Si queremos que devuelva un campo determinado o varios campos en concreto, operación conocida como proyección, hemos de pasar un segundo parámetro de tipo JSON con aquellos campos que deseamos mostrar con el valor true o 1. Destacar que si no se indica nada, por defecto siempre mostrará el campo _id
db.zips.find({city: "TITUS"}, {pop: 1})
// {
// _id: ObjectId('5c8eccc1caa187d17ca6ee50'),
// pop: 2683
// }
Por lo tanto, si queremos que no se muestre el _id, lo podremos a false o 0:
db.zips.find({city: "TITUS"}, {pop: 1, _id:0})
// { pop: 2683 }
No mezcles
Al hacer una proyección, no podemos mezclar campos que se vean (1) con los que no ( 0). Es decir, hemos de hacer algo similar a:
db.<coleccion>.find({ <consulta> }, {<campo1>: 1, <campo2>: 1})
db.<coleccion>.find({ <consulta> }, {<campo1>: 0, <campo2>: 0})
Así pues, sólo se mezclará la visibilidad de los campos cuando queramos ocultar el _id.
Finalmente, si queremos renombrar un campo como resultado de la consulta, a modo de alias, podemos hacerlo referenciando el campo mediante $ (a la izquierda de los dos puntos ponemos el nuevo nombre (alias) y a la derecha va el campo original con el prefijo $ entre comillas):
db.zips.find({city: "TITUS"}, {poblacion: "$pop", _id:0})
// { poblacion: 2683 }
Condiciones compuestas¶
Para usar la conjunción o la disyunción, tenemos los operadores $and y $or. Son operadores prefijo, de modo que se ponen antes de las subconsultas que se van a evaluar. Estos operadores trabajan con arrays, donde cada uno de los elementos es un documento con la condición a evaluar, de modo que se realiza la unión entre estas condiciones, aplicando la lógica asociada a AND y a OR.
db.zips.find({ $or:[{city: "TITUS"}, {pop: 3}] })
db.zips.find({ $or:[{city: "TITUS"}, {pop: {$lte:10}}] })
Realmente el operador $and no se suele usar porque podemos anidar en la consulta dos criterios, al poner uno dentro del otro. Así pues, estas dos consultas hacen lo mismo:
db.zips.find({city: "OXFORD", state: "AL"})
db.zips.find({ $and:[ {city: "OXFORD"}, {state: "AL"} ] })
Consejo de Rendimiento
Las consultas disyuntivas, es decir, con varios criterios excluyentes u operador $or, deben filtrar el conjunto más grande cuanto más pronto posible.
Supongamos que vamos a consultar los mismos documentos que cumplen los criterios A (40.000 documentos), B (9.000 documentos) y C (200 documentos).
Si filtramos C, luego B, y finalmente A, el conjunto de documentos que tiene que comprobar MongoDB es muy grande.
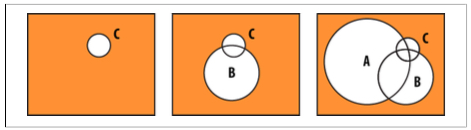
En cambio, si hacemos una consulta que primero empiece por el criterio menos restrictivo, el conjunto de documentos sobre el cual va a tener que comprobar siguientes criterios va a ser menor, y por tanto, se realizará más rápido.

Esto es relevante en ausencia de índices o cuando ningún índice cubre la consulta. Con índices adecuados, el optimizador de MongoDB reorganiza los criterios automáticamente
También podemos utilizar el operador $nor, que no es más que la negación de $or y que obtendrá aquellos documentos que no cumplan ninguna de las condiciones.
Autoevaluación
¿Qué obtendríamos al ejecutar la siguiente consulta?
db.zips.find({ city: "OXFORD", $nor:[ {state: "AL"}, {pop: 1306} ] })
Finalmente, si queremos indicar mediante un array los diferentes valores que puede cumplir un campo, podemos utilizar el operador $in:
db.zips.find({ state: {$in: ["AL", "AR"]} })
Por supuesto, también existe su negación mediante $nin.
Consultas avanzadas¶
Una vez sabemos realizar consultas con diferentes operadores, vamos a detallar casos concretos donde podemos realizar filtrados de datos más específicos.
Preparando los ejemplos
Para los siguientes ejemplos, vamos a utilizar una colección de 10.000 documentos sobre los viajes realizados por los usuarios de una empresa de alquiler de bicicletas, los cuales han sido extraídos de https://ride.citibikenyc.com/system-data.
Esta colección (trips) está cargada en los datos de ejemplo del clúster de MongoAtlas, dentro de la base de datos sample_training.
Un ejemplo de viaje sería el siguiente (puedes comprobar como para los campos que contienen espacios se indican entre comillas):
use sample_training
// switched to db sample_training
db.trips.findOne()
// {
// _id: ObjectId('572bb8222b288919b68abf81'),
// tripduration: 265,
// 'start station id': 376,
// 'start station name': 'John St & William St',
// 'end station id': 152,
// 'end station name': 'Warren St & Church St',
// bikeid: 24119,
// usertype: 'Subscriber',
// 'birth year': 1962,
// 'start station location': {
// type: 'Point',
// coordinates: [ -74.00722156, 40.70862144 ]
// },
// 'end station location': {
// type: 'Point',
// coordinates: [ -74.00910627, 40.71473993
// ]
// },
// 'start time': 2016-01-01T00:14:26.000Z,
// 'stop time': 2016-01-01T00:18:52.000Z
// }
Cursores¶
Al hacer una consulta en el shell, se devuelve un cursor. Este cursor lo podemos guardar en una variable, y a partir de ahí trabajar con él como haríamos mediante cualquier lenguaje de programación. Si cur es la variable que referencia al cursor, podremos utilizar los siguientes métodos:
| Método | Uso | Lugar de ejecución |
|---|---|---|
cur.hasNext() |
true/false para saber si quedan elementos |
Cliente |
cur.next() |
Pasa al siguiente documento | Cliente |
cur.limit(cantidad) |
Restringe el número de resultados a cantidad |
Servidor |
cur.sort({campo:1}) |
Ordena los datos por campo: 1 ascendente o -1 descendente |
Servidor |
cur.skip(cantidad) |
Permite saltar cantidad elementos con el cursor |
Servidor |
La consulta no se ejecuta hasta que el cursor comprueba o pasa al siguiente documento (next/hasNext), por ello que tanto limit como sort (ambos modifican el cursor) sólo se pueden realizar antes de recorrer cualquier elemento del cursor.
Como tras realizar una consulta con find realmente se devuelve un cursor, un uso muy habitual es encadenar una operación de find con sort y/o limit para ordenar el resultado por uno o más campos y posteriormente limitar el número de documentos a devolver.
Así pues, si quisiéramos obtener los tres viajes que más han durado (recuperando sólo el identificador de la bicicleta y la duración del viaje), podríamos hacerlo así:
db.trips.find({},{"bikeid":1, "tripduration":1}).sort({"tripduration":-1}).limit(3)
// [
// {
// _id: ObjectId('572bb8222b288919b68ac07c'),
// tripduration: 326222,
// bikeid: 18591
// },
// {
// _id: ObjectId('572bb8232b288919b68b0f0d'),
// tripduration: 279620,
// bikeid: 17547
// },
// {
// _id: ObjectId('572bb8232b288919b68b0593'),
// tripduration: 173357,
// bikeid: 15881
// }
// ]
También podemos filtrar previamente a ordenar y limitar:
db.trips.find({usertype:"Customer"}).sort({"tripduration":-1}).limit(3)
Finalmente, podemos paginar utilizando el método skip. Conviene destacar, que independientemente del orden en el que indiquemos las operaciones con cursores, se ejecuta así:
find()sort()skip()limit()
Es decir, MongoDB siempre aplicará primero el filtro, luego el ordenamiento, después el salto y finalmente el límite.
Es por ello por lo que, para mostrar viajes de 10 en 10 a partir de la tercera página, podríamos hacer algo así, obteniendo los mismos resultados:
db.trips.find({usertype:"Customer"}).sort({"tripduration":-1}).limit(10).skip(20)
db.trips.find({usertype:"Customer"}).sort({"tripduration":-1}).skip(20).limit(10)
Autoevaluación
A partir de la colección trips, escribe una consulta que recupere los viajes realizados por suscriptores ordenados descendentemente por su duración y que obtenga los documentos de 15 al 20.
Contando¶
Para contar el número de documentos, en vez de find usaremos el método countDocuments. Por ejemplo:
db.trips.countDocuments({"birth year":1977})
// 186
db.trips.countDocuments({"birth year":1977, "tripduration":{$lt:600}})
// 116
count
Desde la versión 4.0, los métodos count a nivel de colección y de cursor están caducados (deprecated), y no se recomienda su utilización. Aun así, es muy común utilizarlo como método de un cursor:
db.trips.find({"birth year":1977, "tripduration":{$lt:600}}).count()
Cuando tenemos muchísimos datos, si no necesitamos exactitud, pero queremos un valor estimado el cual tarde menos en conseguirse (utiliza los metadatos de las colecciones), podemos usar estimatedDocumentCount
db.trips.estimatedDocumentCount()
// 10.000
Conjunto de valores¶
Igual que en SQL, a partir de un colección, si queremos obtener todos los diferentes valores que existen en un campo, utilizaremos el método distinct:
db.trips.distinct('usertype')
[ 'Customer', 'Subscriber' ]
Si queremos filtrar los datos sobre los que se obtienen los valores, le pasaremos un segundo parámetro con el criterio a aplicar:
db.trips.distinct('usertype', { "birth year": { $gt: 1990 } } )
[ 'Subscriber' ]
Como el comando distinct no devuelve un cursor, sino un array, podemos obtener la cantidad de elementos mediante la propiedad length:
db.trips.distinct('usertype').length
// 2
Trabajando con fechas¶
Cuando hemos estudiado la estructura de BSON hemos comprobado que podemos utilizar tipos de datos asociados a fechas como Timestamp o Date.
Por ejemplo, si creamos un documento con diferentes campos con fechas:
let fechas = {
hoy: new Date(),
cumple: new Date("Oct 3, 1977"),
inicioCurso: new Date("2024-10-01"),
ahora: new Timestamp(),
ahoraISO: ISODate(),
nochevieja: ISODate("2024-12-31T00:00:00.000Z")
}
Al mostrarlo en la consola de mongosh podemos ver cómo ha generado las fechas:
fechas
// {
// hoy: 2025-04-23T08:53:26.186Z,
// cumple: 1977-10-02T23:00:00.000Z,
// inicioCurso: 2024-10-01T00:00:00.000Z,
// ahora: Timestamp({ t: 0, i: 0 }),
// ahoraISO: 2025-04-23T08:53:26.186Z,
// nochevieja: 2024-12-31T00:00:00.000Z
// }
A la hora de realizar consultas, utilizaremos los campos de fecha de forma similar al resto de tipos de datos.
Por ejemplo, podemos ordenar por fechas:
db.trips.find({"bikeid": 24119}, {"start time":1,"stop time":1})
.sort({"start time":1}).limit(3)
// [
// {
// _id: ObjectId('572bb8222b288919b68abf81'),
// 'start time': ISODate('2016-01-01T00:14:26.000Z'),
// 'stop time': ISODate('2016-01-01T00:18:52.000Z')
// },
// {
// _id: ObjectId('572bb8222b288919b68ac20a'),
// 'start time': ISODate('2016-01-01T02:02:40.000Z'),
// 'stop time': ISODate('2016-01-01T02:15:58.000Z')
// },
// {
// _id: ObjectId('572bb8222b288919b68ac3d4'),
// 'start time': ISODate('2016-01-01T03:49:38.000Z'),
// 'stop time': ISODate('2016-01-01T03:54:21.000Z')
// }
// ]
O utilizar un rango:
db.trips.find({"bikeid": 24119,
"start time": {$gt:ISODate("2016-01-01T00:00:00.000Z"),
$lte:ISODate("2016-01-01T12:00:00.000Z")}}).count()
// 5
También podemos utilizar las fechas y formatearlas al proyectar los campos (por ejemplo, utilizando el operador $dateToString pasamos un campo de tipo fecha a una cadena con el formato deseado):
db.trips.find({"bikeid": 24119,
"start time": {$gt: ISODate("2016-01-01T00:00:00.000Z"),
$lte: ISODate("2016-01-01T06:00:00.000Z")}},
{bikeid:1,
fechaInicio: {$dateToString: {date: "$start time", format: "%Y-%m-%d %H:%M"}},
fechaConsulta: {$dateToString: {date: new Date(), format: "%Y-%m-%d"}},
})
// [
// {
// _id: ObjectId('572bb8222b288919b68abf81'),
// bikeid: 24119,
// fechaInicio: '2016-01-01 00:14',
// fechaConsulta: '2025-04-23'
// },
// {
// _id: ObjectId('572bb8222b288919b68ac20a'),
// bikeid: 24119,
// fechaInicio: '2016-01-01 02:02',
// fechaConsulta: '2025-04-23'
// },
// {
// _id: ObjectId('572bb8222b288919b68ac3d4'),
// bikeid: 24119,
// fechaInicio: '2016-01-01 03:49',
// fechaConsulta: '2025-04-23'
// }
// ]
Expresiones regulares¶
Finalmente, si queremos realizar consultas sobre partes de un campo de texto, hemos de emplear expresiones regulares. Para ello, tenemos el operador $regex o, de manera más sencilla, indicando como valor la expresión regular a cumplir:
Por ejemplo, para buscar la cantidad de viajes que salen de alguna estación cuyo nombre contenga Tree podemos hacer:
db.zips.find({city: /Tree/}).count()
db.zips.find({city: /tree/i}).count()
db.zips.find({city: {$regex:/tree/i}}).count()
Búsquedas sobre textos
Si vamos a realizar búsquedas intensivas sobre texto, desde MongoDB han creado un producto específico dentro del ecosistema de Mongo Atlas el cual ofrece un mejor rendimiento y mayor funcionalidad que el uso de expresiones regulares, conocido con Mongo Atlas Search.
Si usamos una solución on-premise, mediante índices de texto y el operador $text podemos realizar búsquedas.
Operador $expr¶
El operador $expr es un operador de consulta expresiva que permite utilizar expresiones de agregación dentro de las consultas.
Permite utilizar variables y sentencias condicionales, así como comparar campos dentro de un documento. Así pues, si queremos comparar valores entre dos campos, podemos hacerlo mediante $expr referenciando a los campos anteponiendo un dólar ($) delante del campo, de manera que si queremos obtener los viajes que comienzan y finalizan en la misma estación podemos hacer:
db.trips.find({ "$expr": { "$eq": [ "$end station id", "$start station id" ]}})
Al poner el $ delante de un campo, en vez de referenciar al campo, lo que hace es referenciar a su valor, por lo que $end station id está referenciando al valor del campo end station id.
Expresiones disponibles
Dentro de $expr se puede emplear cualquier operador de expresión del pipeline (aritméticos, de cadena, de conversión como $toInt, condicionales con $cond, etc.). La referencia completa está en https://www.mongodb.com/docs/manual/reference/operator/aggregation/.
Otros operadores
El operador $type permite recuperar documentos que dependan del tipo de campo que contiene.
db.trips.find({"start station name":{$type:"string"}})
El operador $where permite introducir una expresión JavaScript. No se recomienda su uso al no utilizar los índices existentes, a no ser que no haya manera de expresar un criterio mediante los operadores existentes.
Consultas sobre arrays¶
Preparando los ejemplos
Para los siguientes ejemplos sobre documentos anidados y arrays, vamos a utilizar una colección de 500 documentos sobre mensajes de un blog.
Esta colección (posts) está cargada tanto en el clúster de MongoAtlas como en el contenedor de Docker (si has seguido las instrucciones) de la base de datos sample_training.
Un ejemplo de mensaje sería:
use sample_training
// switched to db sample_training
db.posts.findOne()
// { _id: ObjectId("50ab0f8bbcf1bfe2536dc3f9"),
// body: 'Amendment I\n<p>Congress shall make ...."\n<p>\n',
// permalink: 'aRjNnLZkJkTyspAIoRGe',
// author: 'machine',
// title: 'Bill of Rights',
// tags: [
// 'santa',
// 'xylophone',
// 'math',
// 'dream',
// 'action' ],
// comments:
// [ { body: 'Lorem ipsum dolor ...',
// email: 'HvizfYVx@pKvLaagH.com',
// author: 'Santiago Dollins' },
// { body: 'Lorem ipsum dolor sit...',
// email: 'WpOUCpdD@hccdxJvT.com',
// author: 'Jaclyn Morado' },
// { body: 'Lorem ipsum dolor sit amet...',
// email: 'OgDzHfFN@cWsDtCtx.com',
// author: 'Houston Valenti' }],
// date: 2012-11-20T05:05:15.231Z }
Si trabajamos con arrays, vamos a poder consultar el contenido de una posición del mismo modo como si fuera un campo normal, siempre que sea un campo de primer nivel, es decir, no sea un documento embebido dentro de un array.
Si hacemos una consulta sobre si un array contiene un determinado elemento, obtendremos todos los documentos que contengan dicho valor:
db.posts.find({tags:"santa"}, {tags:1})
// { _id: ObjectId('50ab0f8bbcf1bfe2536dc3f9'),
// tags: ['watchmaker', 'santa', 'xylophone', 'math', 'handsaw', 'dream', 'undershirt', 'dolphin', 'tanker', 'action'] }
// { _id: ObjectId('50ab0f8bbcf1bfe2536dc43b'),
// tags: ['cup', 'community', 'santa', 'height', 'peen', 'beer', 'criminal', 'cousin', 'refund', 'clover'] }
// { _id: ObjectId('50ab0f8bbcf1bfe2536dc50d'),
// tags: ['santa', 'spear', 'opinion', 'rainbow', 'century', 'puffin', 'romanian', 'scent', 'river', 'supermarket'] }
Si queremos que coincida exactamente (mismos elementos en el mismo orden), debemos indicarlo pasando el propio array
db.posts.find({tags:["santa"]}, {tags:1})
// No encuentra ningún elemento
Si queremos filtrar teniendo en cuenta el número de ocurrencias del array, podemos utilizar:
$allpara filtrar ocurrencias que tienen todos los valores especificados, es decir, los valores pasados a la consulta serán un subconjunto del resultado. Puede que devuelva los mismos, o un array con más campos (el orden no importa)$in, igual que SQL, para obtener las ocurrencias que cumplen con alguno de los valores pasados (similar a usar$orsobre un conjunto de valores de un mismo campo). Si queremos su negación, usaremos$nin, para obtener los documentos que no cumplen ninguno de los valores.
Por ejemplo, si queremos obtener los mensajes que contenga las etiquetas dream y action tendríamos:
db.posts.find( {tags: {$all: ["dream", "action"]}}, {tags:1})
// { "_id": ObjectId('50ab0f8bbcf1bfe2536dc3f9'),
// "tags": ["watchmaker", "santa", "xylophone", "math", "handsaw", "dream", "undershirt", "dolphin", "tanker", "action"] }
En cambio, si queremos los mensajes que contengan alguna de esas etiquetas haríamos:
db.posts.find( {tags: {$in: ["dream", "mongodb"]}}, {tags:1})
// { "_id": ObjectId('50ab0f8bbcf1bfe2536dc3f9'),
// "tags": ["watchmaker", "santa", "xylophone", "math", "handsaw", "dream", "undershirt", "dolphin", "tanker", "action"] }
Si lo que nos interesa es la cantidad de elementos que contiene un array, emplearemos el operador $size. Por ejemplo, para obtener los mensajes que tienen 10 etiquetas haríamos:
db.posts.find( {tags : {$size : 10}} )
Finalmente, si queremos buscar por un valor en una posición específica del array, sabiendo que el primer índice es el elemento 0, podemos hacerlo mediante la notación punto:
db.posts.find({"tags.0": "santa"}, {tags:1})
// { _id: ObjectId('50ab0f8bbcf1bfe2536dc50d'),
// tags: ['santa', 'spear', 'opinion', 'rainbow', 'century', 'puffin', 'romanian', 'scent', 'river', 'supermarket'] }
Arrays de documentos¶
Si el array contiene documentos y queremos filtrar la consulta sobre los campos de los documentos del array, tenemos que utilizar $elemMatch, de manera que obtengamos aquellos que al menos encuentre un elemento que cumpla el criterio. Dicho de otra manera, el operador elemMatch garantiza que todas las condiciones se cumplan en el mismo elemento del array.
Así pues, si queremos recuperar los mensajes que tienen un comentario cuyo autor sea Santiago Dollins el cual tiene como email xnZKyvWD@jHfVKtUh.com haríamos:
db.posts.find( {comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}} )
Criterio con notación punto
En el ejemplo anterior, si sólo hubiéramos tenido un campo para el filtrado, podríamos haber utilizado la notación punto comments.author.
De forma similar a antes, si queremos filtrar por un elemento que ocupa una determinada posición, usaremos la notación punto sabiendo que el primer índice comienza por 0. Así pues, si queremos recuperar aquellos mensajes donde el primer mensaje tenga un valor determinado, podemos hacer:
db.posts.find( {"comments.0.author": "Santiago Dollins"} )
Proyección de arrays¶
A la hora de proyectar los datos, si no estamos interesados en todos los valores de un campo que es un array, podemos restringir el resultado mediante el operador $slice. Así pues, si quisiéramos obtener los mensajes titulados US Constitution y que, de esos mensajes, mostrara sólo tres etiquetas y dos comentarios, haríamos:
db.posts.find( {title : "US Constitution"}, {comments: {$slice:2}, tags: {$slice:3}} )
// { _id: ObjectId("50ab0f8bbcf1bfe2536dc416"),
// body: 'We the personas ...',
// permalink: 'NhWDUNColpvxFjovsgqU',
// author: 'machine',
// title: 'US Constitution',
// tags: [ 'engineer', 'granddaughter', 'sundial' ],
// comments:
// [ { body: 'Lorem ipsum dolor ...',
// email: 'ftRlVMZN@auLhwhlj.com',
// author: 'Leonida Lafond' },
// { body: 'Lorem ipsum dolor sit...',
// email: 'dsoLAdFS@VGBBuDVs.com',
// author: 'Nobuko Linzey' } ],
// date: 2012-11-20T05:05:15.276Z }
En cuanto a las proyecciones sobre subdocumentos contenidos dentro de un array, además de filtrar mediante elemMatch hemos de indicarlo en la proyección. Así pues, si sólo queremos los comentarios escritos por un determinado autor, haríamos:
db.posts.find(
{comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}},
{comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}} )
// {
// _id: ObjectId('50ab0f8bbcf1bfe2536dc45e'),
// comments: [
// {
// body: 'Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum',
// email: 'xnZKyvWD@jHfVKtUh.com',
// author: 'Santiago Dollins'
// }
// ]
// }
Si sólo nos interesa el primer elemento que coincida podemos emplear el operador posicional $ (lo estudiaremos más profundamente cuando trabajemos las operaciones DML sobre arrays):
db.posts.find(
{comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}},
{"comments.$": 1} )
Modificando documentos¶
Ya hemos visto que podemos añadir datos mediante la operación insertOne. Además, si queremos insertar más de un documento a la vez, podemos hacer uso de la operación insertMany, la cual admite un array de documentos.
Preparando una persona
Para este apartado, vamos a insertar dos veces la misma persona sobre la cual realizaremos las modificaciones:
use s8a;
db.personas.insertMany([{nombre: "Aitor Medrano", edad: 47, profesion: "Profesor"},
{nombre: "Aitor Medrano", edad: 47, profesion: "Profesor"},
{nombre: "Andreu Medrano", edad: 14, profesion: "Estudiante"}])
// {
// acknowledged: true,
// insertedIds: {
// '0': ObjectId('6808cf1d0c0cbe759bb5f899'),
// '1': ObjectId('6808cf1d0c0cbe759bb5f89a'),
// '2': ObjectId('6808cf1d0c0cbe759bb5f89b')
// }
// }
Para actualizar (y fusionar datos), se utilizan los métodos updateOne / updateMany dependiendo de cuántos documentos queremos que modifique. Ambos métodos requieren 2 parámetros: el primero es la consulta para averiguar sobre qué documentos, y en el segundo parámetro, los campos a modificar utilizando los operadores de actualización (en este ejemplo comenzaremos usando $set):
db.personas.updateOne(
{nombre:"Aitor Medrano"},
{$set:{nombre:"Marina Medrano", profesion:"Estudiante", salario: 123456}})
Al realizar la modificación, el shell nos devolverá información sobre cuántos documentos ha encontrado, modificado y más información:
{ acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0 }
Como hay más de una persona con el mismo nombre, al haber utilizado updateOne sólo modificará el primer documento que ha encontrado.
¡Cuidado!
En versiones antiguas de MongoDB, además de utilizar los operadores de actualización, podíamos pasarle como parámetro un documento, de manera que MongoDB realizaba un reemplazo de los campos, es decir, si en el origen había 100 campos y en la operación de modificación sólo poníamos 2, el resultado únicamente contendría 2 campos. Es por ello, que ahora es obligatorio utilizar los operadores.
Si cuando vamos a actualizar, en el criterio de selección no encuentra el documento sobre el que hacer los cambios, no se realiza ninguna acción.
Si quisiéramos que en el caso de no encontrar nada insertase un nuevo documento, acción conocida como upsert (update + insert), hay que pasarle un tercer parámetro al método con el objeto {upsert:true}. Si encuentra el documento, lo modificará, pero si no, creará uno nuevo:
db.personas.updateOne({nombre:"Andreu Medrano"},
{$set:{name:"Andreu Medrano", bsky: "@andreumedrano"}},
{upsert: true})
Operadores de actualización¶
MongoDB ofrece un conjunto de operadores para simplificar la modificación de campos.
El operador más utilizado es el operador $set, el cual admite los campos que se van a modificar. Si el campo no existe, lo creará.
Por ejemplo, para modificar el salario haríamos:
db.personas.updateOne({nombre:"Aitor Medrano"}, {$set:{salario: 1000000}})
Mediante $inc podemos incrementar (o decrementar en negativo) el valor de una variable:
db.personas.updateOne({nombre:"Aitor Medrano"}, {$inc:{salario: 1000}})
db.personas.updateOne({nombre:"Marina Medrano"}, {$inc:{salario: -500}})
Para eliminar un campo de un documento, usaremos el operador $unset.
De este modo, para eliminar el campo bsky de una persona haríamos:
db.personas.updateOne({nombre:"Aitor Medrano"}, {$unset:{bsky:''}})
Otros operadores que podemos utilizar son $mul, $min, $max y $currentDate. Podemos consultar todos los operadores disponibles en https://www.mongodb.com/docs/manual/reference/operator/update/
Autoevaluación
Tras realizar la siguiente operación sobre una colección vacía:
db.personas.updateOne(
{nombre:'yo'},
{'$set':{'hobbies':['gaming', 'sofing']}},
{upsert: true} );
¿Cuál será el estado de la colección?
Finalmente, un caso particular de las actualizaciones es la posibilidad de renombrar un campo mediante el operador $rename:
db.personas.updateMany( {_id:1},
{$rename:{'nickname':'alias', 'cell':'movil'}})
Podemos consultar todas las opciones de configuración de una actualización en https://www.mongodb.com/docs/manual/reference/method/db.collection.update/.
Reemplazando un documento¶
Desde Mongo 3.2, podemos emplear la operación replaceOne para sustituir todo el contenido por el documento que le pasamos como parámetro.
Así pues, si queremos sustituir el documento de Andreu Medrano, borrando los campos que tuviese y remplazándolos por nuevos podríamos hacer:
db.personas.replaceOne({nombre:"Andreu Medrano"},
{nombre:"Andreu", apellidos:"Medrano",
hobbies:["baloncesto","videojuegos","spiderman"]})
Control de la concurrencia¶
Cuando se hace una actualización múltiple, MongoDB no realiza la operación de manera atómica (a no ser que utilicemos transacciones desde el driver), lo que provoca que se puedan producir pausas (pause yielding). Cada documento en sí es atómico, por lo que ninguno se va a quedar a la mitad.
MongoDB ofrece un conjunto de métodos para encontrar y modificar (o reemplazar, o eliminar) un documento de manera atómica, evitando que entre la búsqueda y la modificación el estado del documento se vea afectado por otra operación concurrente. Además, devuelven el documento afectado, por lo que con una única operación obtenemos el resultado y aplicamos el cambio. Un caso de uso muy común es la implementación de contadores y casos similares.
| Método | Propósito |
|---|---|
findOneAndUpdate |
Busca un documento y le aplica los operadores de actualización indicados |
findOneAndReplace |
Busca un documento y lo sustituye por completo |
findOneAndDelete |
Busca un documento y lo elimina |
Por ejemplo, para incrementar el salario y reducir la edad de Marina Medrano de manera atómica, recibiendo el documento ya modificado, haríamos:
db.personas.findOneAndUpdate(
{nombre:"Marina Medrano"},
{$inc:{salario:100, edad:-30}},
{returnDocument: "after"}
)
// {
// _id: ObjectId('6808cf1d0c0cbe759bb5f899'),
// nombre: 'Marina Medrano',
// edad: 17,
// profesion: 'Estudiante',
// salario: 123556
// }
Por defecto, el documento devuelto será el que ha encontrado la consulta antes de aplicar la modificación. Si queremos recibir el documento ya modificado, debemos pasar la opción returnDocument: "after". El valor por defecto es before, equivalente al comportamiento de no indicar nada.
Además del filtro y la actualización, estos métodos admiten otras opciones útiles:
upsert: true: si no encuentra el documento, lo crea (igual que enupdateOne).sort: cuando varios documentos cumplen el filtro, permite indicar cuál se modifica primero.projection: igual que enfind, para devolver solo un subconjunto de campos.
Por ejemplo, para obtener y eliminar de manera atómica el documento más antiguo de una cola de tareas:
db.tareas.findOneAndDelete(
{estado: "pendiente"},
{sort: {fechaCreacion: 1}}
)
findAndModify
En versiones anteriores a MongoDB 5.0, la operación que se utilizaba para estos casos era findAndModify, con una sintaxis ligeramente distinta:
db.personas.findAndModify({
query: {nombre:"Marina Medrano"},
update: {$inc:{salario:100, edad:-30}},
new: true
})
Esta operación sigue funcionando, pero se recomienda emplear findOneAndUpdate / findOneAndReplace / findOneAndDelete, que son los métodos oficiales de la API de CRUD y los que utilizan los drivers de los distintos lenguajes de programación. Cabe destacar que el parámetro new: true de findAndModify se corresponde con returnDocument: "after" en los nuevos métodos.
Borrando documentos¶
Para borrar, usaremos los métodos deleteOne o deleteMany, los cuales funcionan de manera similar a findOne y find. Si no pasamos ningún parámetro, deleteOne borrará el primer documento, o en el caso de deleteMany toda la colección documento a documento. Si le pasamos un parámetro, éste será el criterio de selección de documentos a eliminar.
db.personas.deleteOne({nombre:"Marina Medrano"})
db.personas.deleteMany({nombre:"Marina Medrano"})
Al eliminar un documento, no podemos olvidar que cualquier referencia al documento que exista en la base de datos seguirá existiendo. Por este motivo, manualmente también hay que eliminar o modificar esas referencias.
Eliminar un campo
Recordad que eliminar un determinado campo de un documento no se considera una operación de borrado, sino una actualización mediante el operador $unset.
Si queremos borrar toda la colección, es más eficiente usar el método drop, ya que también elimina los índices.
db.personas.drop()
Finalmente, para eliminar una base de datos usaremos el comando db.dropDatabase(), que eliminará la base de datos sobre la que nos encontremos (en nuestro caso, en s8a):
db.dropDatabase()
Trabajando con Arrays¶
Para trabajar con arrays necesitamos nuevos operadores que nos permitan tanto introducir como eliminar elementos de una manera más sencilla que sustituir todos los elementos del array.
Los operadores que podemos emplear para trabajar con arrays son:
| Operador | Propósito |
|---|---|
$push |
Añade uno o varios elementos |
$addToSet |
Añade un elemento sin duplicados |
$pull |
Elimina un elemento |
$pullAll |
Elimina varios elementos |
$pop |
Elimina el primer o el último |
Preparando los ejemplos
Para trabajar con los arrays, vamos a suponer que tenemos una colección de enlaces donde vamos a almacenar un documento por cada site, con un atributo tags con etiquetas sobre el enlace en cuestión
db.enlaces.insertOne({titulo:"www.google.es", tags:["mapas", "videos"]})
De modo que tendríamos el siguiente documento:
{ _id: ObjectId("633c60e8ac452ac9d7f9fe74"),
titulo: 'www.google.es',
tags: [ 'mapas', 'videos' ] }
Añadiendo elementos¶
Si queremos añadir uno o varios elementos, usaremos el operador $push. Cuando queremos añadir varios elementos a la vez, mediante el operador $each le pasamos un array con los datos:
db.enlaces.updateMany({titulo:"www.google.es"},
{$push: {tags:"blog"}} )
db.enlaces.updateMany({titulo:"www.google.es"},
{$push: {tags:{$each:["calendario", "email", "mapas"]}}})
Al hacer esta modificación, el resultado del documento sería:
{ _id: ObjectId("633c61b5ac452ac9d7f9fe75"),
titulo: 'www.google.es',
tags: [ 'mapas', 'videos', 'blog', 'calendario', 'email', 'mapas' ] }
Al utilizar $push no se tiene en cuenta lo que contiene el array, por tanto, si un elemento ya existe, se repetirá y tendremos duplicados. Si queremos evitar los duplicados, usaremos $addToSet:
db.enlaces.updateMany({titulo:"www.google.es"},
{$addToSet:{tags:"buscador"}})
Si queremos añadir más de un campo a la vez sin duplicados, debemos anidar el operador $each igual que hemos hecho antes:
db.enlaces.updateMany({titulo:"www.google.es"},
{$addToSet:{tags:{$each:["drive", "traductor"]}}})
En cambio, si queremos eliminar elementos de un array, usaremos el operador $pull:
db.enlaces.updateMany({titulo:"www.google.es"},
{$pull:{tags:"traductor"}})
Similar al caso anterior, con $pullAll, eliminaremos varios elementos de una sola vez:
db.enlaces.updateMany({titulo:"www.google.es"},
{$pullAll:{tags:["calendario", "email"]}})
Otra manera de eliminar elementos del array es mediante $pop, el cual elimina el primero (-1) o el último (1) elemento del array:
db.enlaces.updateMany({titulo:"www.google.es"}, {$pop:{tags:-1}})
Operador posicional¶
Por último, tenemos el operador posicional, el cual se expresa con el símbolo $ y nos permite modificar el elemento que ocupa una determinada posición del array sin saber exactamente cuál es esa posición.
Supongamos que tenemos las calificaciones de los estudiantes (colección students) en un documento con una estructura similar a la siguiente:
{ "_id" : 1, "notas" : [ 80, 85, 90 ] }
y queremos cambiar la calificación de 80 por 82. Mediante el operador posicional haremos:
db.students.updateOne( { _id: 1, notas: 80 }, { $set: { "notas.$" : 82 } } )
De manera similar, si queremos modificar parte de un documento el cual forma parte de un array, debemos usar la notación punto tras el $.
Por ejemplo, supongamos que tenemos estas calificaciones de un determinado alumno, las cuales forman parte de un objeto dentro de un array:
{ "_id" : 4, "notas" :
[ { nota: 80, media: 75 },
{ nota: 85, media: 90 },
{ nota: 90, media: 85 } ] }
Podemos observar cómo tenemos cada calificación como parte de un objeto dentro de un array. Si queremos cambiar el valor de media a 89 de la calificación cuya nota es 85, haremos:
db.students.updateOne( { _id: 4, "notas.nota": 85 }, { $set: { "notas.$.media" : 89 } } )
Es decir, el $ referencia al documento que ha cumplido el filtro de búsqueda.
Más operadores posicionales
Además del operador posicional $, tenemos disponible el operador posicional $[] que indica que afecta a todos los elementos del array, y el operador posicional $[identificador] que identifica que elementos del array cumplen una condición para su filtrado.
Podemos consultar toda la documentación disponible sobre estos operadores en https://docs.mongodb.org/manual/reference/operator/update-array/
Administración¶
Empleando JavaScript¶
Ya hemos comentado que el shell utiliza JavaScript como lenguaje de interacción, por lo que podemos almacenar los comandos en un script externo y ejecutarlo mediante load():
load("scripts/misDatos.js");
load("/data/db/scripts/misDatos.js");
MongoDB Compass
Si utilizamos mongosh desde MongoDB Compass, no podemos hacer uso del comando load.
Sí que podemos crear variables y fragmentos de código en Javascript, sabiendo que para añadir un salto de línea emplearemos Shift+Enter.
Si hacemos una referencia relativa, lo hace respecto a la ruta desde la cual se ejecuta el shell mongosh.
Otra manera de lanzar un script es hacerlo desde la línea de comandos, pasándole como segundo parámetro el script a ejecutar:
mongosh pruebas misDatos.js
Si el código a ejecutar no necesita almacenarse en un script externo, el propio shell permite introducir instrucciones en varias líneas:
for (var i=0;i<10;i++) {
db.espias.insertOne({"nombre":"James Bond " + i, "agente":"00" + i});
}
// {
// acknowledged: true,
// insertedId: ObjectId('67fbf408b496860bf5c367a9')
// }
db.espias.find()
// [
// {
// _id: ObjectId('67fbf408b496860bf5c367a0'),
// nombre: 'James Bond 0',
// agente: '000'
// }
// {
// _id: ObjectId('67fbf408b496860bf5c367a1'),
// nombre: 'James Bond 1',
// agente: '001'
// }
// ...
// {
// _id: ObjectId('67fbf408b496860bf5c367a9'),
// nombre: 'James Bond 9',
// agente: '009'
// }
// ]
Importando y exportando¶
Además del propio servidor de MongoDB y el cliente para conectarse a él, MongoDB ofrece un conjunto de herramientas para interactuar con las bases de datos, permitiendo crear y restaurar copias de seguridad.
Si estamos interesados en introducir o exportar una colección de datos mediante JSON, podemos emplear los comandos mongoimport y mongoexport:
mongoimport -d nombreBaseDatos -c coleccion --file nombreFichero.json
mongoexport -d nombreBaseDatos -c coleccion nombreFichero.json
Estas herramientas interactúan con datos JSON y no sobre toda la base de datos.
Un caso particular y muy común es importar datos que se encuentran en formato CSV/TSV. Para ello, emplearemos el parámetro --type csv o --type tsv según el separador de los campos sea la coma o el tabulador:
mongoimport --type tsv -d test -c micoleccion --headerline --drop documento.tsv
En vez de realizar un export, es más conveniente realizar un backup en binario mediante mongodump, el cual genera ficheros BSON. Estos archivos posteriormente se restauran mediante mongorestore:
mongodump -d nombreBaseDatos nombreFichero.bson
mongorestore -d nombreBaseDatos nombreFichero.bson
Autoevaluación
Intenta exportar los datos de la base de datos sample_training desde MongoAtlas. Verás que ha creado una carpeta que contiene dos archivos ¿Cuáles son? ¿Qué contiene cada uno de ellos y cuál es su formato?
Si necesitamos transformar un fichero BSON a JSON (de binario a texto), tenemos el comando bsondump:
bsondump file.bson > file.json
Info
Más información sobre copias de seguridad en https://www.mongodb.com/docs/manual/core/backups/.
Para poder trabajar con MongoDB desde cualquier aplicación necesitamos un driver. MongoDB ofrece drivers oficiales para casi todos los lenguajes de programación actuales.
Monitorización
Tanto mongostat como mongotop permiten visualizar el estado del servidor MongoDB, así como algunas estadísticas sobre su rendimiento. Si trabajamos con MongoAtlas estas herramientas están integradas en las diferentes herramientas de monitorización de la plataforma.
Modelado documental¶
Una de las características más importantes al utilizar un sistema documental es que mediante un documento podemos mantener toda la información que se utiliza junta en un único documento, sin necesidad de separar los datos en diferentes colecciones.
Dependiendo del tipo de relación entre dos documentos, normalizaremos los datos para minimizar la redundancia, pero manteniendo en la medida de lo posible que mediante operaciones atómicas se mantenga la integridad de los datos. Para ello, bien crearemos referencias entre dos documentos o embeberemos un documento dentro de otro, pero intentando que la información más utilizada quepa en un único documento.
MongoDB es una base de datos documental, no relacional, donde el esquema no se debe basar en el uso de claves ajenas/joins, ya que realmente no existen. A la hora de diseñar un esquema, si nos encontramos que el esquema está en 3FN o si cuando hacemos consultas estamos teniendo que realizar varias consultas de manera programática (primero acceder a una tabla, con ese _id ir a otra tabla, etc… o hacemos un uso extensivo del operador $lookup mediante el framework de agregación) es que no estamos siguiendo el enfoque adecuado.
En resumen, diseñar un buen modelo de datos documental supondrá que nuestro código será más legible y mantenible, así como tener un mayor rendimiento de nuestras aplicaciones, aunque conlleve la redundancia de datos.
Las aplicaciones que emplean MongoDB utilizan dos técnicas para relacionar documentos:
- Crear referencias
- Embeber documentos
Referencias manuales¶
De manera similar a una base de datos relacional, se almacena el campo _id de un documento en otro documento a modo de clave ajena. De este modo, la aplicación realiza una segunda consulta para obtener los datos relacionados. Estas referencias son sencillas y suficientes para la mayoría de casos de uso.
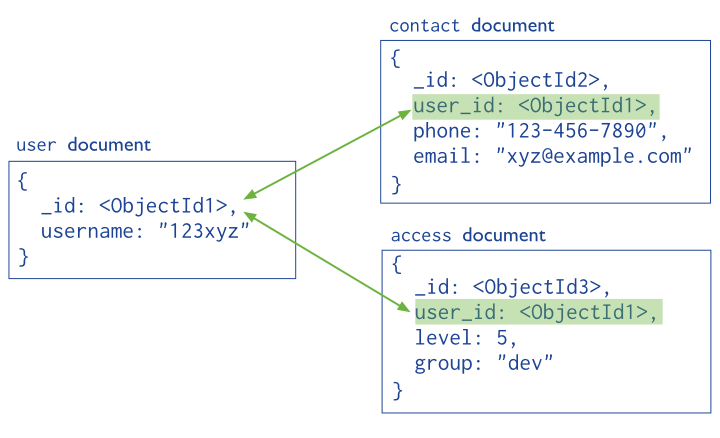
Por ejemplo, si nos basamos en el gráfico anterior, podemos conseguir referenciar manualmente estos objetos del siguiente modo:
var idUsuario = ObjectId();
db.usuario.insertOne({
_id: idUsuario,
nombre: "123xyz"
});
db.contacto.insertOne({
usuario_id: idUsuario,
telefono: "123 456 7890",
email: "xyz@ejemplo.com"
});
Para relacionar los dos documentos, haremos uso de la operación $lookup para hacer el join, o haremos una segunda consulta para la segunda colección. Un ejemplo de join mediante $lookup:
db.usuario.aggregate([ {
$lookup: {
from: "contacto",
localField: "_id",
foreignField: "usuario_id",
as: "contacto_data"
}
} ])
Y como resultado obtenemos un documento con el usuario y la información del contacto dentro de un array embebido (aunque en este ejemplo sólo tenemos un contacto para el usuario)
{ _id: ObjectId("634589696e96ece54fbcbca2"),
nombre: '123xyz',
contacto_data:
[ { _id: ObjectId("634589696e96ece54fbcbca3"),
usuario_id: ObjectId("634589696e96ece54fbcbca2"),
telefono: '123 456 7890',
email: 'xyz@ejemplo.com' } ] }
El operador $lookup lo estudiaremos en profundidad en el apartado de Consultas agregadas.
Datos embebidos¶
En cambio, si dentro de un documento almacenamos los datos mediante subdocumentos, ya sea dentro de un atributo o un array, podremos obtener todos los datos mediante un único acceso, sin necesidad de claves ajenas ni comprobaciones de integridad referencial.

Generalmente, emplearemos datos embebidos cuando tengamos:
- relaciones "contiene" entre entidades, entre relaciones de documentos "uno a uno" o "uno a pocos".
- relaciones "uno a muchos" entre entidades. En estas relaciones los documentos hijo (o "muchos") siempre aparecen dentro del contexto del padre o del documento "uno".
Los datos embebidos/incrustados ofrecen mejor rendimiento al permitir obtener los datos mediante una única operación, así como modificar datos relacionados en una sola operación atómica de escritura (sin necesidad de transacciones)
Un aspecto a tener en cuenta es que un documento BSON puede contener un máximo de 16MB. Si quisiéramos que un atributo contenga más información, tendríamos que utilizar el API de GridFS.
Vamos a estudiar en detalle cada uno de los tipos de relaciones, para intentar clarificar cuando es conveniente utilizar referencias o datos embebidos.
Relaciones 1:1¶
Cuando existe una relación 1:1, como pueda ser entre Persona y Curriculum, o Persona y Direccion hay que embeber un documento dentro del otro, como parte de un atributo.
-
Estructura

Relación 1:1 persona-dirección -
Documento de ejemplo
persona.json{ nombre: "Aitor", edad: 18, direccion: { calle: "Secreta", ciudad: "Elx" } }
La principal ventaja de este planteamiento es que mediante una única consulta podemos obtener tanto los detalles del usuario como su dirección.
Un par de aspectos que nos pueden llevar a no embeberlos son:
- la frecuencia de acceso. Si a uno de ellos se accede raramente, puede que convenga tenerlos separados para liberar memoria.
- el tamaño de los elementos. Si hay uno que es mucho más grande que el otro, o uno lo modificamos muchas más veces que el otro, para que cada vez que hagamos un cambio en un documento no tengamos que modificar el otro será mejor separarlos en documentos separados.
Pero siempre teniendo en cuenta la atomicidad de los datos, ya que si necesitamos modificar los dos documentos al mismo tiempo, tendremos que embeber uno dentro del otro.
Relaciones 1:N¶
Vamos a distinguir tres tipos:
-
1 a pocos (1:F) (one to few), como, por ejemplo, dentro de un blog, la relación entre
MensajeyComentario. En este caso, la mejor solución es crear un array dentro de la entidad 1 (en nuestro caso,Mensaje). De este modo, elMensajecontiene un array deComentario:-
Estructura
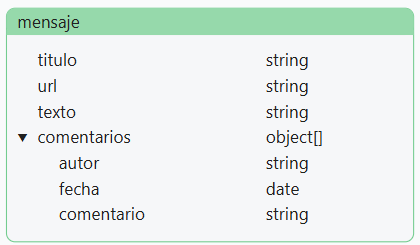
Relación 1:F mensaje-comentarios -
Documento de ejemplo
mensaje.json{ "titulo": "La broma asesina", "url": "http://es.wikipedia.org/wiki/Batman:_The_Killing_Joke", "texto": "La dualidad de Batman y Joker", "comentarios": [ { "autor": "Bruce Wayne", "fecha": ISODate("2022-10-11T09:31:32Z"), "comentario": "A mí me encantó" }, { "autor": "Bruno Díaz", "fecha": ISODate("2022-10-11T10:07:28Z"), "comentario": "El mejor" } ] }
Vigilar el tamaño
Hay que tener siempre en mente la restricción de los 16 MB de BSON. Si vamos a embeber muchos documentos y estos son grandes, hay que vigilar no llegar a dicho límite.
Si queremos saber cuánto ocupa un documento, en el shell podemos obtener su tamaño mediante el comando
bsonsize:> var p = db.people.findOne() > bsonsize(p) < 96 -
-
1 a muchos (1:N) (one to many), como puede ser entre
EditorialyLibro. Para este tipo de relación es mejor usar referencias entre los documentos colocando la referencia en el lado del muchos:-
Estructura

Relación 1:N editorial-libro
-
Documento de ejemplo
editorial.json{ _id: 1, nombre: "O'Reilly", pais: "EE.UU." }libros.json{ _id: 1234, titulo: "MongoDB: The Definitive Guide", autor: [ "Kristina Chodorow", "Mike Dirolf" ], numPaginas: 216, editorial_id: 1, }, { _id: 1235, titulo: "50 Tips and Tricks for MongoDB Developer", autor: "Kristina Chodorow", numPaginas: 68, editorial_id: 1, }
Si cada vez que recuperamos un libro queremos tener el nombre de la editorial y con una sola consulta recuperar todos los datos, en vez de poner la referencia a la editorial, podemos embeber toda la información (esto se conoce como el patrón referencia extendida), a costa de que un futuro cambio en el nombre de la editorial conlleve modificar muchos libros:
-
Estructura
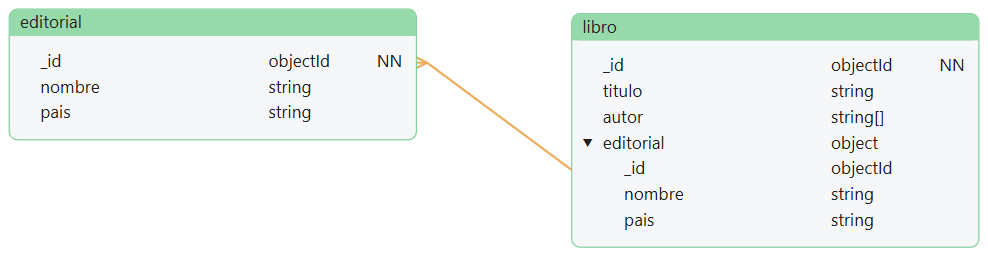
Relación 1:N editorial-libro extendido
-
Documento de ejemplo
libros-extendido.json{ _id: 1234, titulo: "MongoDB: The Definitive Guide", autor: [ "Kristina Chodorow", "Mike Dirolf" ], numPaginas: 216, editorial: { _id: 1, nombre: "O'Reilly", pais: "EE.UU." } },{ _id: 1235, titulo: "50 Tips and Tricks for MongoDB Developer", autor: "Kristina Chodorow", numPaginas: 68, editorial: { _id: 1, nombre: "O'Reilly", pais: "EE.UU." } }
Un caso particular en las relaciones uno a muchos que se traducen en documentos embebidos es cuando la información que nos interesa tiene un valor concreto en un momento determinado. Por ejemplo, dentro de un pedido, el precio de los productos debe embeberse, ya que si en un futuro se modifica el precio de un producto determinado debido a una oferta, el pedido realizado no debe modificar su precio total.
Del mismo modo, al almacenar la dirección de una persona, también es conveniente embeberla. No queremos que la dirección de envío de un pedido ya enviado se modifique si un usuario cambia sus datos personales.
En cambio, si necesitamos acceder por separado a los diferentes objetos de una relación, puede que nos convenga separarlo en dos colecciones distintas, aunque luego tengamos que hacer un join.
-
-
1 a muchísimos/tropecientos (1:S) (one to squillions/zillions), como puede ser entre una aplicación y los mensajes del log, los cuales pueden llegar a tener un volumen de millones de mensajes por aplicación. Teniendo siempre en mente la restricción de los 16MB de BSON, podemos modelar estas relaciones mediante un array de referencias:
aplicacion.json{ _id: ObjectId("111111"), nombre: "Gestión de clientes", }logs.json{ _id: ObjectId("123456"), app: ObjectId("111111"), actividad: "Alta Cliente", mensaje: "El cliente XXX se ha creado correctamente", date: ISODate("2022-10-12") },{ _id: ObjectId("123457"), app: ObjectId("111111"), actividad: "Modificación Cliente", mensaje: "No se ha podido modificar el XXX por un error del sistema", date: ISODate("2022-10-12") },De esta manera, pasamos la relación de 1 a muchos a realmente ser de muchos a 1, donde cada mensaje de log almacena la aplicación a la que pertenecen, y ya no tenemos que mantener un array de logs dentro de cada aplicación.
Relaciones N:M¶
Más que relaciones muchos a muchos, suelen ser relaciones pocos a pocos, como por ejemplo, Libro y Autor, o Profesor y Estudiante.
Supongamos que tenemos libros modelados de la siguiente manera:
{
_id: 1,
titulo: "La historia interminable",
anyo: 1979
}
Y autores con la siguiente estructura:
{
_id: 1,
nombre: "Michael Ende",
pais: "Alemania"
}
Podemos resolver esta relación de tres maneras:
-
Siguiendo un enfoque relacional, empleando un documento como la entidad que agrupa con referencias manuales a los dos documentos.
libro-autor.json{ _id: 1, autor_id: 1, libro_id: 1 }Este enfoque se desaconseja porque necesita acceder a tres colecciones para obtener toda la información.
-
Mediante 2 documentos, cada uno con un array que contenga los identificadores del otro documento (2 Way Embedding). Hay que tener cuidado porque podemos tener problemas de inconsistencia de datos si no actualizamos correctamente.
libro-con-autores.json{ _id: 1, titulo: "La historia interminable", anyo: 1979, autores: [1] },{ _id: 2, titulo: "Momo", anyo: 1973, autores: [1] }autor-con-libros.json{ _id: 1, nombre: "Michael Ende", pais: "Alemania", libros: [1, 2] }Aunque tenemos información redundante
Al utilizar referencias para representar una relación muchos a muchos, realmente sólo necesitamos un array de referencias en sólo una de las colecciones. Si nos fijamos en el atributo
librosde la colecciónautor-con-libros¿Podríamos obtener todos los libros de un autor? Por supuesto. Y sí quisiéramos obtener todos los libros de autores alemanes, aunque nos tocase realizar un join, también lo podríamos conseguir.Dicho esto, aunque podemos tener un array en ambas colecciones, dependiendo del caso, puede conllevar una sobrecarga extra innecesaria.
-
Embeber un documento dentro de otro (One Way Embedding). Por ejemplo:
libro-con-autores-embebidos.json{ _id: 1, titulo: "La historia interminable", anyo: 1979, autores: [{nombre:"Michael Ende", pais:"Alemania"}] },{ _id: 2, titulo: "Momo", anyo: 1973, autores: [{nombre:"Michael Ende", pais:"Alemania"}] }En principio este enfoque no se recomienda porque el documento puede crecer mucho y provocar anomalías de modificaciones donde la información no es consistente. Si se opta por esta solución, hay que tener en cuenta de si un documento depende de otro para su creación. Por ejemplo, en una colección que relacione profesor con alumnos, si metemos los profesores dentro de los estudiantes, no vamos a poder dar de alta a profesores sin haber dado de alta previamente a un alumno.
A modo de resumen, en las relaciones N:M, hay que establecer el tamaño de N y M. Si N como máximo vale 3 y M 500000, entonces deberíamos seguir un enfoque de embeber la N dentro de la M (One Way Embedding).
En cambio, si N vale 3 y M vale 5, entonces podemos hacer que ambos embeban al otro documento (Two Way Embedding).
Rendimiento e Integridad
A modo de resumen, embeber documentos ofrece un mejor rendimiento que referenciar, ya que con una única operación (ya sea una lectura o una escritura) podemos acceder a varios documentos.
Cuidado con los arrays
Los array no pueden crecer de forma descontrolada. Si hay un par de cientos de documentos en el lado de N, no hay que embeberlos. Si hay más de unos pocos miles de documentos en el lado de N, no hay que usar un array de referencias. Arrays con una alta cardinalidad son una clara pista para no embeber.
Autoevaluación
A partir del siguiente supuesto, realiza el modelo documental necesario.
Tenemos almacenes, de los cuales, además de su nombre, necesitamos guardar su dirección, con su calle, ciudad, provincia y país. No tendremos más de 200 almacenes. Cada uno de los almacenes almacenará productos, hasta un máximo de 10 millones por almacén. De cada producto, además de su código, nombre y descripción, guardaremos los últimos 200 precios a los cuales se ha vendido cada producto. Además, cada producto puede tener opiniones creadas por usuarios, hasta un máximo de 1.000. Para estas opiniones, además de los datos del usuario, almacenaremos la fecha y el texto de la opinión.
Respecto a los usuarios, el sistema espera almacenar un máximo de 10 millones de usuarios, y de estos, además del nombre, guardaremos la dirección completa (calle, ciudad y código postal) donde enviar los productos, así como hasta un máximo de 10 tarjetas de crédito con la que realiza los pagos. De las tarjetas, almacenaremos su tipo, número bancario, fecha de expedición y código de seguridad.
¿Cuántas colecciones crearías?
Consultas agregadas¶
Las agregaciones usan un pipeline, conocido como Aggregation Pipeline, de ahí que el método aggregate use un array con [ ] donde cada elemento es una fase del pipeline, de modo que la salida de una fase es la entrada de la siguiente:
db.coleccion.aggregate([fase1, fase2, ... faseN])
Cuidado con el tamaño
El resultado del pipeline es un documento y por lo tanto está sujeto a la restricción de BSON, que limita su tamaño a 16MB.
En la siguiente imagen se resumen los pasos de una agrupación donde primero se eligen los elementos que vamos a agrupar mediante $match, el resultado saliente se agrupa con $group, y sobre lo agrupado mediante $sum se calcula el total:
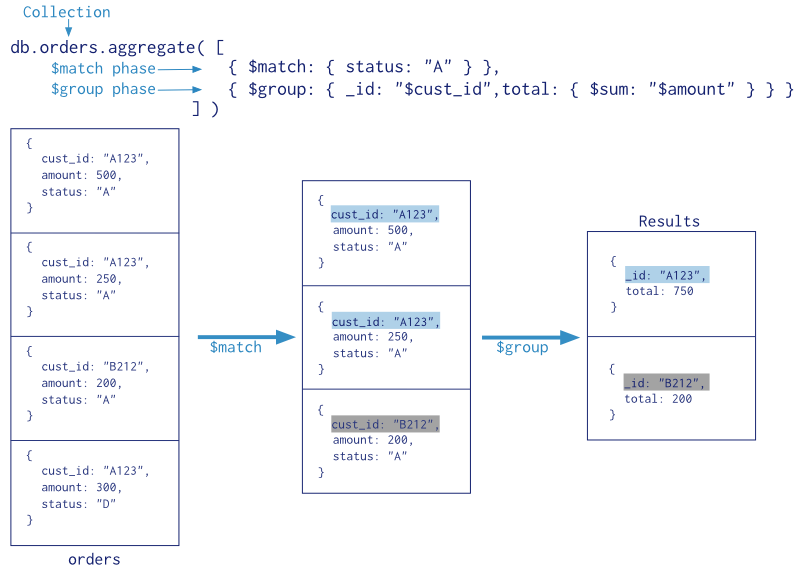
Al realizar un pipeline dividimos las consultas en fases, donde cada fase utiliza un operador para realizar una transformación. Aunque no hay límite en el número de fases en una consulta, es importante destacar que el orden importa, y que hay optimizaciones para ayudar a que el pipeline tenga un mejor rendimiento (por ejemplo, hacer un $match al principio para reducir la cantidad de datos)
Fases del pipeline¶
Antes de nada, cabe destacar que las fases se pueden repetir, por lo que una consulta puede repetir etapas para encadenar diferentes acciones.
A continuación, vamos a estudiar todos estos operadores:
| Operador | Descripción | Cardinalidad |
|---|---|---|
$project |
Proyección de campos, es decir, propiedades en las que estamos interesados. También nos permite modificar un documento, o crear un subdocumento (reshape) | 1:1 |
$match |
Filtrado de campos, similar a where |
N:1 |
$group |
Para agrupar los datos, similar a group by |
N:1 |
$sort |
Ordenar | 1:1 |
$skip |
Saltar | N:1 |
$limit |
Limitar los resultados | N:1 |
$unwind |
Separa los datos que hay dentro de un array | 1:N |
Operadores de expresión¶
Dentro de las etapas del pipeline (especialmente $project, $addFields, $group y $match con $expr) se pueden emplear operadores de expresión que transforman, comparan o calculan valores. Los más habituales se agrupan en familias:
- Aritméticos:
$add,$subtract,$multiply,$divide,$mod,$round… - Cadenas:
$concat,$substr,$toLower,$toUpper,$split,$trim… - Conversión de tipos:
$toInt,$toDouble,$toString,$toBool,$toDate,$toObjectId, o el genérico$convert. - Condicionales y lógicos:
$cond,$ifNull,$switch. - Fechas:
$year,$month,$dayOfWeek,$dateToString,$dateFromString,$dateDiff. - Arrays:
$size,$arrayElemAt,$filter,$map,$reduce.
Por ejemplo, para convertir una cadena "47" a entero al proyectar, usaríamos { $toInt: "$edad" }.
Preparando los ejemplos
Para los siguientes ejemplos, vamos a utilizar una colección de productos (productos.js) de una tienda de electrónica con las características y precios de los mismos.
Un ejemplo de un producto sería:
> db.productos.findOne()
{
"_id" : ObjectId("5345afc1176f38ea4eda4787"),
"nombre" : "iPad 16GB Wifi",
"fabricante" : "Apple",
"categoria" : "Tablets",
"precio" : 499
}
Para cargar este archivo desde la consola nos podemos conectar a nuestro clúster y realizar la carga:
mongosh mongodb+srv://<usuario>:<contraseña>@cluster0.dfaz5er.mongodb.net/s8a < productos.js
O si ya nos hemos conectado previamente, cargarlo mediante load:
load("productos.js")
O copiar el contenido y pegarlo directamente en el shell de MongoDB Compass (son pocos datos).
$group¶
La fase group agrupa los documentos con el propósito de calcular valores agregados de una colección de documentos. Por ejemplo, podemos usar $group para calcular la media de páginas visitadas de manera diaria.
Cuidado
La salida de $group esta desordenada
La salida de $group depende de cómo se definan los grupos. Se empieza especificando un identificador (por ejemplo, un campo _id) para el grupo que creamos con el pipeline. Para este campo _id, podemos especificar varias expresiones, incluyendo un único campo proveniente de un documento del pipeline, un valor calculado de una fase anterior, un documento con muchos campos y otras expresiones válidas, tales como constantes o campos de subdocumentos. También podemos usar operadores de $project para el campo _id.
Cuando referenciemos al valor de un campo lo haremos poniendo entre comillas un $ delante del nombre del campo. Así pues, para referenciar al fabricante de un producto lo haremos mediante $fabricante.
> db.productos.aggregate([
{ $group: {
_id: "$fabricante",
total: { $sum:1 }
}
}])
< { _id: 'Apple', total: 4 }
{ _id: 'Samsung', total: 2 }
{ _id: 'Sony', total: 1 }
{ _id: 'Google', total: 1 }
{ _id: 'Amazon', total: 2 }
Si lo que queremos es que el valor del identificador contenga un objeto, lo podemos hacer asociándolo como valor:
> db.productos.aggregate([
{ $group: {
_id: { "empresa": "$fabricante" },
total: { $sum:1 }
}
}])
<
{ _id: { empresa: 'Sony' }, total: 1 }
{ _id: { empresa: 'Apple' }, total: 4 }
{ _id: { empresa: 'Google' }, total: 1 }
{ _id: { empresa: 'Samsung' }, total: 2 }
{ _id: { empresa: 'Amazon' }, total: 2 }
También podemos agrupar más de un atributo, de tal modo que tengamos un _id compuesto. Por ejemplo:
> db.productos.aggregate([
{ $group: {
_id: {
"empresa": "$fabricante",
"tipo": "$categoria" },
total: {$sum:1}
}
}])
< { _id: { empresa: 'Apple', tipo: 'Tablets' }, total: 3 }
{ _id: { empresa: 'Sony', tipo: 'Portátiles' }, total: 1 }
{ _id: { empresa: 'Apple', tipo: 'Portátiles' }, total: 1 }
{ _id: { empresa: 'Samsung', tipo: 'Smartphones' }, total: 1 }
{ _id: { empresa: 'Amazon', tipo: 'Tablets' }, total: 2 }
{ _id: { empresa: 'Google', tipo: 'Tablets' }, total: 1 }
{ _id: { empresa: 'Samsung', tipo: 'Tablets' }, total: 1 }
Siempre _id
Cada expresión de $group debe especificar un campo _id.
Acumuladores¶
Además del campo _id, la expresión $group puede incluir campos calculados. Estos otros campos deben utilizar uno de los siguientes acumuladores:
| Nombre | Descripción |
|---|---|
$addToSet |
Devuelve un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones) |
$first |
Devuelve el primer valor del grupo. Se suele usar después de ordenar. |
$last |
Devuelve el último valor del grupo. Se suele usar después de ordenar. |
$max |
Devuelve el mayor valor de un grupo |
$min |
Devuelve el menor valor de un grupo. |
$avg |
Devuelve el promedio de todos los valores de un grupo |
$push |
Devuelve un array con todos los valores del campo seleccionado entre cada documento del grupo (puede haber repeticiones) |
$sum |
Devuelve la suma de todos los valores del grupo |
A continuación, vamos a ver ejemplos de algunos de estos acumuladores.
$sum¶
El operador $sum acumula los valores y devuelve la suma.
Por ejemplo, para obtener el montante total de los productos agrupados por fabricante, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"empresa": "$fabricante"
},
totalPrecio: {$sum:"$precio"}
}
}])
< { _id: { empresa: 'Apple' }, totalPrecio: 2296 }
{ _id: { empresa: 'Samsung' }, totalPrecio: 1014.98 }
{ _id: { empresa: 'Sony' }, totalPrecio: 499 }
{ _id: { empresa: 'Google' }, totalPrecio: 199 }
{ _id: { empresa: 'Amazon' }, totalPrecio: 328 }
$avg¶
Mediante $avg podemos obtener el promedio de los valores de un campo numérico.
Por ejemplo, para obtener el precio medio de los productos agrupados por categoría, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"}
}
}])
< { _id: { categoria: 'Smartphones' }, precioMedio: 563.99 }
{ _id: { categoria: 'Portátiles' }, precioMedio: 499 }
{ _id: { categoria: 'Tablets' }, precioMedio: 396.4271428571428 }
$addToSet¶
Mediante $addToSet obtendremos un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones).
Por ejemplo, para obtener para cada empresa las categorías en las que tienen productos, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"fabricante":"$fabricante"
},
categorias: {$addToSet:"$categoria"}
}
}])
< { _id: { fabricante: 'Apple' }, categorias: [ 'Portátiles', 'Tablets' ] }
{ _id: { fabricante: 'Amazon' }, categorias: [ 'Tablets' ] }
{ _id: { fabricante: 'Sony' }, categorias: [ 'Portátiles' ] }
{ _id: { fabricante: 'Google' }, categorias: [ 'Tablets' ] }
{ _id: { fabricante: 'Samsung' }, categorias: [ 'Tablets', 'Smartphones' ] }
$push¶
Mediante $push también obtendremos un array con todos los valores para los campos seleccionados entre cada documento del grupo, pero con repeticiones. Es decir, funciona de manera similar a $addToSet pero permitiendo elementos repetidos.
Por ello, si reescribimos la consulta anterior, pero haciendo uso de $push, obtendremos categorías repetidas:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
categorias: {$push:"$categoria"}
}
}])
< { _id: { empresa: 'Sony' }, categorias: [ 'Portátiles' ] }
{ _id: { empresa: 'Apple' }, categorias: [ 'Tablets', 'Tablets', 'Tablets', 'Portátiles' ] }
{ _id: { empresa: 'Google' }, categorias: [ 'Tablets' ] }
{ _id: { empresa: 'Samsung' }, categorias: [ 'Smartphones', 'Tablets' ] }
{ _id: { empresa: 'Amazon' }, categorias: [ 'Tablets', 'Tablets' ] }
$max y $min¶
Los operadores $max y $min permiten obtener el mayor y el menor valor, respectivamente, del campo por el que se agrupan los documentos.
Por ejemplo, para obtener el precio del producto más caro y más barato que tiene cada empresa haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
precioMaximo: {$max:"$precio"},
precioMinimo: {$min:"$precio"},
}
}])
{ "_id" : { "empresa" : "Amazon" }, "precioMaximo" : 199, "precioMinimo" : 129 }
{ "_id" : { "empresa" : "Sony" }, "precioMaximo" : 499, "precioMinimo" : 499 }
{ "_id" : { "empresa" : "Samsung" }, "precioMaximo" : 563.99, "precioMinimo" : 450.99 }
{ "_id" : { "empresa" : "Google" }, "precioMaximo" : 199, "precioMinimo" : 199 }
{ "_id" : { "empresa" : "Apple" }, "precioMaximo" : 699, "precioMinimo" : 499 }
Doble $group¶
Si queremos obtener el resultado de una agrupación podemos aplicar el operador $group sobre otro $group.
Por ejemplo, para obtener el precio medio de los precios medios de los tipos de producto por empresa (es decir, una media de medias) haríamos:
> db.productos.aggregate([
{$group: {
_id: {
"empresa":"$fabricante",
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"} // (1)!
}
},
{$group: {
_id: "$_id.empresa",
precioMedio: {$avg: "$precioMedio"} // (2)!
}
}
])
< { _id: 'Google', precioMedio: 199 }
{ _id: 'Sony', precioMedio: 499 }
{ _id: 'Samsung', precioMedio: 507.49 }
{ _id: 'Apple', precioMedio: 549 }
{ _id: 'Amazon', precioMedio: 164 }
- Precio medio por empresa y categoría
- Precio medio por empresa en base al precio medio anterior
$project¶
Si queremos realizar una proyección sobre el conjunto de resultados y quedarnos con un subconjunto de los campos usaremos el operador $project. Como resultado obtendremos el mismo número de documentos, y en el orden indicado en la proyección.
La proyección dentro del framework de agregación es mucho más potente que dentro de las consultas normales. Se emplea para:
- renombrar campos.
- introducir campos calculados en el documento resultante mediante
$add,$subtract,$multiply,$divideo$mod - transformar campos a mayúsculas
$toUppero minúsculas$toLower, concatenar campos mediante$concatu obtener subcadenas con$substr. - transformar campos en base a valores obtenidos a partir de una condición mediante expresiones lógicas con los operadores de comparación vistos en las consultas.
> db.productos.aggregate([
{$project:
{
_id: 0, // (1)!
"empresa": { "$toUpper": "$fabricante" }, // (2)!
"detalles": { // (3)!
"categoria": "$categoria",
"precio": { "$multiply": ["$precio", 1.1] } // (4)!
},
"elemento": "$nombre" // (5)!
}
}
])
< { empresa: 'APPLE',
detalles: { categoria: 'Tablets', precio: 548.9000000000001 },
elemento: 'iPad 16GB Wifi' }
{ empresa: 'APPLE',
detalles: { categoria: 'Tablets', precio: 658.9000000000001 },
elemento: 'iPad 32GB Wifi' }
...
- Ocultamos el campo
_id - Transforma un campo y lo pasa a mayúsculas
- Crea un documento anidado
- Incrementa el precio el 10%
- Renombra el campo
Convirtiendo tipos al proyectar
Si un campo está almacenado como cadena pero queremos operar con él como número (situación habitual al importar CSV), podemos convertirlo en el propio $project:
db.zips.aggregate([
{ $project: {
city: 1,
poblacion: { $toInt: "$pop" },
densidad: { $divide: [ { $toDouble: "$pop" }, 100 ] }
}}
])
Si la conversión puede fallar (por ejemplo, una cadena no numérica), conviene usar $convert, que admite los parámetros onError y onNull para controlar los casos problemáticos.
$match¶
El operador $match se utiliza principalmente para filtrar los documentos que pasarán a la siguiente etapa del pipeline o a la salida final.
Por ejemplo, para seleccionar sólo las tablets haríamos:
db.productos.aggregate([{$match:{categoria:"Tablets"}}])
Aparte de igualar un valor a un campo, podemos emplear los operadores usuales de consulta, como $gt, $lt, $in, etc…
Se recomienda poner el operador $match al principio del pipeline para limitar los documentos a procesar en siguientes fases. Si usamos este operador como primera fase podremos hacer uso de los índices de la colección de una manera eficiente.
Así pues, para obtener la cantidad de tablets de menos de 500 euros que tiene cada empresa haríamos:
> db.productos.aggregate([
{$match:
{categoria:"Tablets",
precio: {$lt: 500}}},
{$group:
{_id: {"empresa":"$fabricante"},
cantidad: {$sum:1}}
}
])
< { _id: { empresa: 'Samsung' }, cantidad: 1 }
{ _id: { empresa: 'Amazon' }, cantidad: 2 }
{ _id: { empresa: 'Google' }, cantidad: 1 }
{ _id: { empresa: 'Apple' }, cantidad: 1 }
Autoevaluación
En la consulta anterior, si cambiamos el orden y hacemos el $group antes que el $match, ¿qué estamos obteniendo?
$sort¶
El operador $sort ordena los documentos recibidos por el campo, y el orden indicado por la expresión indicada al pipeline.
Por ejemplo, para ordenar los productos por precio descendentemente haríamos:
db.productos.aggregate({$sort:{precio:-1}})
El operador $sort ordena los datos en memoria, por lo que hay que tener cuidado con el tamaño de los datos. Por ello, se emplea en las últimas fases del pipeline, cuando el conjunto de resultados es el menor posible.
Si retomamos el ejemplo anterior, y ordenamos los datos por el precio total tenemos:
> db.productos.aggregate([
{$match:{categoria:"Tablets"}},
{$group:
{_id: {"empresa":"$fabricante"},
totalPrecio: {$sum:"$precio"}}
},
{$sort:{totalPrecio:-1}} // (1)!
])
< { _id: { empresa: 'Apple' }, totalPrecio: 1797 }
{ _id: { empresa: 'Samsung' }, totalPrecio: 450.99 }
{ _id: { empresa: 'Amazon' }, totalPrecio: 328 }
{ _id: { empresa: 'Google' }, totalPrecio: 199 }
- Al ordenar los datos, referenciamos al campo que hemos creado en la fase de $group
Un operador muy relacionado es $sortByCount. Este operador es similar a realizar las siguientes operaciones:
{ $group: { _id: <expresion>, cantidad: { $sum: 1 } } },
{ $sort: { cantidad: -1 } }
Así pues, podemos reescribir la consulta que hemos hecho en el operador $group:
db.productos.aggregate([
{ $group: {
_id: "$fabricante",
total: { $sum:1 }
}
},
{$sort: {"total": -1}}
])
Y hacerla con:
db.productos.aggregate([{ $sortByCount: "$fabricante"}])
{ _id: 'Apple', count: 4 }
{ _id: 'Samsung', count: 2 }
{ _id: 'Amazon', count: 2 }
{ _id: 'Sony', count: 1 }
{ _id: 'Google', count: 1 }
$skip y $limit¶
El operador $limit únicamente limita el número de documentos que pasan a través del pipeline.
El operador recibe un número como parámetro:
db.productos.aggregate([{$limit:3}])
Este operador no modifica los documentos, sólo restringe quien pasa a la siguiente fase.
De manera similar, con el operador $skip, saltamos un número determinado de documentos:
db.productos.aggregate([{$skip:3}])
El orden en el que empleemos estos operadores importa y mucho, ya que no es lo mismo saltar y luego limitar, donde la cantidad de elementos la fija $limit:
> db.productos.aggregate([{$skip:2}, {$limit:3}])
< { _id: ObjectId("635194b32e6059646a8e7fee"),
nombre: 'iPad 64GB Wifi',
categoria: 'Tablets',
fabricante: 'Apple',
precio: 699 }
{ _id: ObjectId("635194b32e6059646a8e7fef"),
nombre: 'Galaxy S3',
categoria: 'Smartphones',
fabricante: 'Samsung',
precio: 563.99 }
{ _id: ObjectId("635194b32e6059646a8e7ff0"),
nombre: 'Galaxy Tab 10',
categoria: 'Tablets',
fabricante: 'Samsung',
precio: 450.99 }
En cambio, si primero limitamos y luego saltamos, la cantidad de elementos se obtiene de la diferencia entre el límite y el salto:
> db.productos.aggregate([{$limit:3}, {$skip:2}])
> { _id: ObjectId("635194b32e6059646a8e7fee"),
nombre: 'iPad 64GB Wifi',
categoria: 'Tablets',
fabricante: 'Apple',
precio: 699 }
$sample
Si tenemos un dataset muy grande, y queremos probar las consultas con un número reducido de documentos, podemos emplear el operador $sample y reducir la cantidad de documentos de manera aleatoria:
db.productos.aggregate([ { $sample: { size: 3 } } ])
$lookup¶
Si necesitamos unir los datos de dos colecciones, emplearemos el operador $lookup, el cual realiza un left outer join a una colección de la misma base de datos para filtrar los documentos de la colección joineada.
El resultado es un nuevo campo array para cada documento de entrada, el cual contiene los documentos que cumplen el criterio del join.
El operador $lookup utiliza cuatro parámetros:
from: colección con la que se realiza el join.localField: campo de la colección origen, la que viene de la agregacióndb.origen.aggregate, que hace la función de clave ajena.foreignField: campo en la colección indicada enfromque permite la unión (sería la clave primaria de la colección sobre la que se realiza el join).as: nombre del array que contendrá los documentos enlazados.
Preparando los datos
Vamos a utilizar la colección zips empleada en anteriores sesiones la cual tiene una estructura similar a:
{ _id: ObjectId("5c8eccc1caa187d17ca6ed18"),
city: 'ACMAR',
zip: '35004',
loc: { y: 33.584132, x: 86.51557 },
pop: 6055,
state: 'AL' }
A continuación, vamos a crear una nueva colección llamada state con el nombre de los estados (states.js), la cual cargaremos en la base de datos sample_training:
db.states.insertMany([
{
"name": "Alabama",
"abbreviation": "AL"
},
{
"name": "Alaska",
"abbreviation": "AK"
},
...
])
Vamos a analizar cómo funciona el operador $lookup mediante un ejemplo. Primero vamos a recuperar los tres estados más poblados. Para ello, podríamos hacer la siguiente consulta agregada:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3}
])
{ _id: 'CA', totalPoblacion: 29760021 }
{ _id: 'NY', totalPoblacion: 17990455 }
{ _id: 'TX', totalPoblacion: 16986510 }
Si ahora queremos recuperar el nombre de esos tres estados, añadimos una nueva fase:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
])
Y ahora obtenemos para cada documento, un array con los documentos que coinciden (en este caso es una relación 1:1, y por eso cada array sólo contiene un elemento):
{ _id: 'CA',
totalPoblacion: 29760021,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0cd5"),
name: 'California',
abbreviation: 'CA' } ] }
{ _id: 'NY',
totalPoblacion: 17990455,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0cf4"),
name: 'New York',
abbreviation: 'NY' } ] }
{ _id: 'TX',
totalPoblacion: 16986510,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0d02"),
name: 'Texas',
abbreviation: 'TX' } ] }
Como la relación siempre va a provocar la creación de un array, mediante $unwind, lo podemos deshacer:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"}
])
{ _id: 'CA',
totalPoblacion: 29760021,
estados:
{ _id: ObjectId("63565cd82889ecee358e0cd5"),
name: 'California',
abbreviation: 'CA' } }
{ _id: 'NY',
totalPoblacion: 17990455,
estados:
{ _id: ObjectId("63565cd82889ecee358e0cf4"),
name: 'New York',
abbreviation: 'NY' } }
{ _id: 'TX',
totalPoblacion: 16986510,
estados:
{ _id: ObjectId("63565cd82889ecee358e0d02"),
name: 'Texas',
abbreviation: 'TX' } }
Así pues, para finalmente obtener el nombre de cada estado, mediante $project recuperamos el campo name:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"},
{$project: {
"estado": "$estados.name",
"poblacion": "$totalPoblacion"
}}
])
Obteniendo el resultado deseado:
{ _id: 'CA', estado: 'California', poblacion: 29760021 }
{ _id: 'NY', estado: 'New York', poblacion: 17990455 }
{ _id: 'TX', estado: 'Texas', poblacion: 16986510 }
Persistiendo los resultados¶
Una vez hemos realizado nuestras consultas mediante el framework de agregación, es muy posible que queramos almacenar el resultado en una nueva colección para poder volver a consultar el resultado sin necesidad de ejecutar todas las fases.
Para ello, podemos emplear los operadores:
$outrecoge los documentos de una agregación y los persiste en una colección, sobrescribiendo los datos existentes.$mergesimilar a$out, pero permite añadir el resultado a la misma colección y además soporta trabajar con colecciones particionadas.
Por ejemplo, vamos a basarnos en las consultas con join, para crear una nueva colección con la población total de todos los estados, y la vamos a almacenar en una nueva colección denominada states_population:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"},
{$project: {
"estado": "$estados.name",
"poblacion": "$totalPoblacion"
}},
{$out: "states_population"}
])
Tras su ejecución, podemos recuperar los datos:
> db.states_population.findOne()
< { _id: 'WY', estado: 'Wyoming', poblacion: 453588 }
De SQL al Pipeline de agregaciones¶
Ya hemos visto que el pipeline ofrece operadores para realizar la misma funcionalidad de agrupación que ofrece SQL.
Si relacionamos los comandos SQL con el pipeline de agregaciones tenemos las siguientes equivalencias:
| SQL | Pipeline de Agregaciones |
|---|---|
WHERE |
$match |
GROUP BY |
$group |
HAVING |
$match |
SELECT |
$project |
ORDER BY |
$sort |
LIMIT |
$limit |
SUM() |
$sum |
COUNT() |
$sum / $sortByCount |
| join | $lookup |
Podemos encontrar ejemplos de consultas SQL transformadas al pipeline en https://www.mongodb.com/docs/manual/reference/sql-aggregation-comparison/
Limitaciones
Hay que tener en cuenta las siguientes limitaciones:
- En versiones anteriores a la 2.6, el pipeline devolvía en cada fase un objeto BSON, y por tanto, el resultado estaba limitado a 16MB
- Actualmente, sólo cada documento que forme parte del resultado final debe ocupar menos de 16MB.
- Las fases tienen un límite de 100MB en memoria. Antes de la versión 6.0, si una consulta superaba el límite se producía un error, a no ser que se habilitara el uso de disco de manera explícita mediante
{allowDiskUse: true}en cada consulta. Desde la versión 6.0, a partir de los 100MB se utilizan ficheros temporales en disco por defecto.
Más información en https://www.mongodb.com/docs/manual/core/aggregation-pipeline-limits/
Referencias¶
- Manual de MongoDB
- Cheatsheet oficial
- Comparación entre SQL y MongoDB
- Cursos gratuitos de Mongo University
- Consultas solucionadas sobre la colección
sample_restaurants.restaurantsen w3resource - Consultas solucionada (en castellano) sobre la colección
sample_restaurants.restaurantsen www.apuntesinformaticafp.com
Actividades¶
-
AC1301. (RABD.7 // CE7c, CE7d, CE7e // 3p) Crea un clúster en MongoAtlas, carga los datos de ejemplo y
-
Adjunta capturas de pantalla del:
- Dashboard del clúster
- Bases de datos / colecciones creadas
-
Conéctate mediante MongoDB Compass y adjunta una captura de pantalla tras conectar con el clúster.
- En la base de datos
s8a, crea un documento con tus datos personales en la colecciónac1301. Tras insertarlo, realiza una consulta para recuperarlo. - Recupera las colecciones existentes en la base de datos.
Adjunta un documento con las capturas realizadas, así como los comandos necesarios y la salida obtenida tras su ejecución.
-
-
AC1302. (RABD.7 // CE7d, CE7e // 3p) Haciendo uso de
mongosh, escribe los comandos necesarios y adjunta el resultado de las consultas para:- Obtener las bases de datos creadas.
- Sobre la base de datos
sample_training- Recuperar todas las colecciones
- Recuperar qué base de datos está activa.
- Sobre la colección
sample_training.zips:- Recuperar todos los documentos.
- Recuperar el primer documento.
- Recuperar los documentos de la ciudad de
SAN DIEGO. - Recuperar los códigos postales (
zip) cuya ciudad seaSAN DIEGOy el estado seaCA. - Recuperar los documentos cuya ciudad sea
SAN DIEGOpero no pertenezcan al estado deCA. - Recuperar los documentos cuya ciudad sea
SAN DIEGOy el estado seaCAoTX. - Recuperar los documentos cuya ciudad sea
SAN DIEGOo el estado seaTX. - Recuperar los documentos donde el
zipsea92135,92136o92137. - ¿Cuál es el código postal de la ciudad de
ALLENque no tiene habitantes (sólo recupera elzip, no nos interesa ningún otro campo, ni el_id)?.
-
AC1303. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes consultas sobre la colección
zipsde la base de datossample_training:- Recupera los documentos que tienen menos de 50 personas (campo
pop). - Recupera los documentos que tienen entre 50 y 100 personas.
- Averigua cuántos documentos hay de la ciudad de
SAN DIEGO. - Averigua cuántos documentos tienen menos de 100 personas.
- Recupera los documentos donde el nombre de la ciudad contenga la palabra
BEACH. - Obtén los estados de la ciudad de
SAN DIEGO(Solución:[ 'CA', 'TX' ]). - Listado con los 5 códigos postales más poblados (muestra los documentos completos).
- Cantidad de documentos que no tienen menos de 5.000 habitantes ni más de 1.000.000 (debes utilizar el operador
$nor). - Cuántos documentos tienen más habitantes que su propio código postal (campo
zip).
- Recupera los documentos que tienen menos de 50 personas (campo
-
AR1304. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes consultas sobre la colección
tripsde la base de datossample_training:- Recupera los viajes realizados con la bicicleta con ID
14785 - Encuentra los viajes que duraron más de 1 hora.
- Mostrar solo el ID de la bicicleta, la duración del viaje y los nombres de las estaciones de los viajes realizados por usuarios nacidos después de 1990.
- Recupera los viajes realizados desde la estación
Huron St & Franklin Sty con duración menor a 500 segundos - Encontrar los 10 viajes más largos, ordenados de mayor a menor duración.
- Encontrar viajes con estaciones que contengan
Aveen su nombre. - ¿Cuántos viajes han realizado los usuarios de tipo
Customer?. - Recuperar los viajes realizados entre el 1 de enero y el 31 de marzo de 2016.
- Encontrar viajes con duración entre 10 y 20 minutos, hechos por usuarios nacidos antes de 1980.
- Encontrar los viajes que duraron más de una hora o que fueron realizados por usuarios nacidos después del año 2000.
- Mostrar los 5 viajes más recientes, pero saltando los primeros 10 resultados.
- Recupera los viajes realizados con la bicicleta con ID
-
AC1305. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes consultas sobre la colección
salesde la base de datossample_supplies:- Recupera los documentos que han vendido algún producto (forma parte del array
items) de nombrenotepad. - Recupera los documentos donde el primer producto sea
notepad. - Recupera los documentos donde el primer producto sea
notepady haya vendido un mínimo de 5 (quantity) unidades. - Recupera los documentos que han vendido exactamente dos productos.
- Averiguar las ventas y sus productos donde el precio de los productos es superior a 20€ pero inferior a 40€ (muestra solo los productos que tengan dichos precios).
- Recupera las ventas donde sus productos tengan las etiquetas
stationary,officeygeneral. - Recupera las ventas donde sus productos tengan las etiquetas
writing,officeoelectronics. - Para las ventas que sean
notepadolaptop, recuperar el primer producto. - Recupera la ventas realizadas por hombres de más de 40 años que hayan comprado dos productos.
- Para las ventas realizadas por mujeres y realizadas por teléfono (
purchaseMethod), recupera dos de los productos adquiridos.
- Recupera los documentos que han vendido algún producto (forma parte del array
-
AR1306. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes consultas sobre la colección
posts:- Recupera los mensajes que tienen la etiqueta
club. - Recupera los mensajes que tienen la etiqueta
clubyspy. - Recupera los mensajes que tienen la etiqueta
clubospy. - Cuántos mensajes no tienen la etiqueta
restaurant. - Cuántos mensajes tienen únicamente un comentario.
- Cuántos mensajes tienen al menos un comentario.
- Los mensajes que tienen algún comentario que ha escrito el usuario
Salena Olmos. - Los comentarios (con su cuerpo y email) que ha escrito el usuario
Salena Olmos. - Recupera los mensajes que en
bodycontengan la palabraearth, y devuelve el título, 3 comentarios y 5 etiquetas.
- Recupera los mensajes que tienen la etiqueta
-
AC1307. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes operaciones DML sobre la colección
zips:-
Crea una entrada con los siguientes datos:
{ city: 'ELX', zip: '03206', loc: { x: 38.265500, y: -0.698459 }, pop: 230224, state: 'España' } -
Crea una entrada con los datos del código postal donde vives (si es el mismo código postal, crea uno diferente), con el valor de
stateaEspaña. - Modifica la población de tu código postal a
1.000.000. - Incrementa la población de todos los documentos de
Españaen 666 personas. - Añade un campo
prova ambos documentos con valorAlicante. - Renombra en los documentos de la provincia de
Alicanteel atributoprovporprovincia - Elimina las coordenadas del zip
03206. - Elimina tu entrada.
-
-
AR1308. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes operaciones sobre la colección
sample_restaurants.restaurants:- Insertar un nuevo restaurante de comida española con tu nombre, pero sin ninguna calificación.
- Añade una calificación al restaurante
- Cambiar el nombre del restaurante por
Severo manjar. - Modifica el número del edificio de la dirección.
- Modifica el tipo de cocina para que sea
Mediterránea. - Añade una segunda calificación.
- Modifica las coordenadas de la ubicación para que coincidan con las de tu ciudad.
- Modifica el barrio con el barrio donde vives.
- Añade una tercera calificación que sea excelente.
- Modifica la calle y el código postal mediante una única operación.
- Elimina la calificación más antigua.
- Añade un nuevo campo
horariocon el valor que consideres. - Incrementa todas las calificaciones en un punto.
-
AC1309. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes operaciones de arrays sobre la colección
zips:- Modifica los documentos de
Españay añade un atributotagsque contenga un array vacío. - Añade a todos los documentos que tenga el atributo
tagsel valorlifedentro del array. - Modifica todos los documentos de la provincia de
Alicantey añade al atributotagsel valorsun. - Añade al final de
tagsel atributofooda todas las ciudades deEspaña. - Mediante una operación, añade un nuevo atributo
tourismcon los valoressunyfooda todos los documentos deEspaña. - Añade en la segunda posición de todos los documentos de
Españael valors8aen la propiedadtags. - Modifica el valor de
sundetagsde tu código postal y sustitúyelo porhouse. - Elimina el valor
housedetagsde tu código postal. - Elimina el último valor de
tags. - Elimina el primer valor de
tourism.
- Modifica los documentos de
-
AP1310. (RABD.7 // CE7d, CE7e // 3p) Utilizando las herramientas de administración de MongoDB (las cuales puedes utilizarlas desde dentro de Docker o bien descargar las MongoTools), se pide:
- Exporta los datos de la colección
zipsens8a_zips.json - Importa la colección recién exportada dentro de la base de datos
pruebasen la coleccións8a_zips. - Realiza una consulta y comprueba que los datos se han importado correctamente.
- Exporta la base de datos de
sample_trainingsy muestra el resultado. - Importa la base de datos recién exportada en
s8a_trainings - Realiza una consulta y comprueba que los datos se han importado correctamente.
- Importa el archivo
clientes.csvdentro de la base de datospruebasen la colecciónclientes. - Realiza una consulta y comprueba que los datos se han importado correctamente.
- Importa el archivo
poblacion.tsvdentro de la base de datospruebasen la colecciónpoblacion. - Realiza una consulta y comprueba que los datos se han importado correctamente.
- Exporta los datos de la colección
-
AC1311. (RABD.7 // CE7d, CE7e // 3p) Transforma el siguiente modelo entidad-relación a un modelo documental, teniendo en cuenta que la aplicación se va a encargar de mostrar la información del alumnado y los cursos en los que está matriculado. Para ello, entrega un documento JSON por cada colección con un documento a modo de ejemplo:
Modelo entidad relación escolar ¿Qué cambiaría si nos interesase el punto de vista del docente y los cursos que imparte? Y si nuestra aplicación tuviera que darles cabida a ambos casos, ¿qué solución propones?
-
AC1312. (RABD.7 // CE7d, CE7e // 6p) Escribe los comandos necesarios para realizar las siguientes consultas agregadas sobre la colección
sample_supplies.sales:- Cantidad total de ventas registradas.
- Cantidad total de ventas por método de compra (
purchaseMethod). - Investiga el operador
$unwindy calcula el ingreso total de cada producto (namedentro deitems) - Calcular el promedio de elementos por venta.
- A partir de todos los elementos, calcula el ingreso total por ventas, teniendo en cuenta el precio y la cantidad de cada elemento.
- Encontrar los 3 productos más vendidos (por cantidad de unidades vendidas).
- Averiguar cuántas ventas se han realizado del producto
notepad. - Averiguar cuántos
notepadse han vendido y cuánto se ha recaudado por sus ventas. - Averiguar los tres productos con un precio medio más alto.
- Averiguar la cantidad de hombres y mujeres que han realizado compras, así como sus edades medias.
- Recuperar el nombre y el email de los 5 clientes que más han gastado.
- Para cada email, mostrar la cantidad de ventas realizadas, así como la cantidad de productos adquiridos.
- Recupera cual es el producto que más se ha vendido en
London. - Obtener el nombre y el email del cliente, y el total gastado, pero solo para aquellos clientes que han gastado más de 1000$.
- Averiguar cuáles han sido los tres años que más ventas se han realizado.
-
AR1313. (RABD.7 // CE7d, CE7e // 3p) Escribe los comandos necesarios para realizar las siguientes consultas agregadas sobre la colección
sample_restaurants.restaurants:- Cantidad total de restaurantes.
- Cantidad de restaurantes por barrio (propiedad
borough). - Recupera los cinco barrios con mayor cantidad de restaurantes.
- Investiga el operador
$unwind, y recupera la calificación media del restaurantePalm Restauran. - Recupera la fecha de la última calificación de cada restaurante.
- Encuentra todos los restaurantes que al menos tienen una calificación de
A. - Mediante
$unwind, cuenta cuántas calificaciones de tipoA,B,C, etc... existen en total en todos los restaurantes. - Mostrar los restaurantes que tienen más de tres calificaciones.
- Mostrar los restaurantes que tienen más de cuatro calificaciones y que hagan cocina
American. - Encontrar el restaurante con la calificación
Amás alta (mayorscore). - Calcular la diferencia entre el
scoremás alto y más bajo para cada restaurante que tenga al menos dosgrades. - Obtener el nombre del restaurante, su dirección (
streetyzipcode) y la última fecha de inspección (grade.date) para los restaurantes delBronx. - Encontrar los 3 barrios tienen la mayor variedad de tipos de cocina.
-
PR1314. (RABD.7 // CE7d, CE7e // 10p) Importa el fichero
mongo_cities1000.jsonenpruebas.cities. Sobre dichos datos, resuelve las siguientes consultas:- Calcula el número total de ciudades.
- Recupera todos los datos de la ciudad cuyo nombre es
Elx. - Recupera únicamente la población de
Vergel. - Calcula el número de ciudades de España.
- Datos de las ciudades españolas con más de un millón de habitantes.
- Recupera la cantidad total de ciudades que hay entre
Andorra(AD) yEspaña. - Listado con el nombre y la población de las 10 ciudades más pobladas.
- Nombre de las distintas zonas horarias en
España. - Ciudades españolas que su zona horaria no sea
Europe/Madrid. - Mostrar las ciudades españolas que comiencen por
Ben - Devolver las ciudades que su zona horaria sea
Atlantic/CanaryoAfrica/Ceuta. - Obtén el nombre y la población de las tres ciudades europeas más pobladas
-
Calcula la cantidad de ciudades españolas cuya coordenadas de longitud estén comprendidas entre
-0.1y0.1. -
Mostrar los 3 países con mayor número de ciudades.
- Devolver los 3 países con mayor número de habitantes.
- Calcular y devolver la población total de España, Francia e Italia, en orden descendente.
- Calcular la latitud y longitud media para cada zona horaria europea.
- Devolver los países en la posición 5ª y 6ª si ordenamos su población total en orden descendente.
- Calcular las zonas horarias con mayor y menor número de habitantes para España y Rusia. Añade también un campo extra que indique cuántas zonas horarias tiene cada país.
- Calcular qué porcentaje de la población representa la ciudad más poblada de España.
- Utilizando
unwind, devuelve los pares únicos (país y timezone) con un campo que indique la suma total de población del país. - Averigua qué nombres de ciudades se repiten entre distintos países.
- AR1315. (RABD.7 // CE7c, CE7d, CE7e // 3p) Una vez finalizada la unidad, responde todas las preguntas del cuestionario inicial, con al menos un par de líneas para cada una de las cuestiones.