Orquestación de flujos: Apache Airflow¶
Pipeline de datos¶
En la sesión sobre Ingesta de datos estudiamos en qué consiste un pipeline de datos entendiéndolo como el conjunto de pasos y las tecnologías involucradas en un proceso de movimiento o procesamiento de datos.
Por ejemplo, si queremos almacenar en un lago de datos las temperaturas que obtenemos de la AEMET para posteriormente crear un cuadro de mandos donde realizar algún tipo de predicción se entiende que deberemos realizar una petición REST, recuperar los datos y seleccionar los datos específicos que nos interesan y finalmente persistir los datos en el data lake (por ejemplo, en S3), para posteriormente poder leer dichos datos desde una herramienta de cuadro de mandos, como pueda ser Tableau o PowerBI.
DAG¶
Estos pasos siguen un orden determinado que no podemos alterar (es decir, no puedo almacenar los datos que no he recibido previamente). Este orden se puede representar mediante un grafo dirigido, donde los nodos representan las tareas mientras que las dependencias se representan mediante aristas que van de un nodo a otro.

Este tipo de grafos se conocen como grafos acíclicos dirigidos (directed acyclic graph - DAG), ya que contiene aristas dirigidas (las relaciones van en un único sentido) y no contiene ciclos (bucles). La propiedad acíclica es muy importante, ya que nos evita bloqueos por dependencias circulares entre tareas.
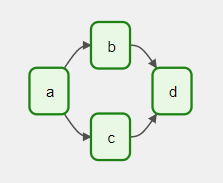
Si nos fijamos en el grafo de la figura lateral, tenemos una grafo que define cuatro tareas (A, B, C y D), donde una vez ha finalizado la tarea A, la B y C se pueden realizar de forma paralela, y hasta que no hayan acabado esas dos, no comenzará la tarea D.
Así pues, el grafo define las dependencias entre las tareas y condiciona la ejecución de una o más tareas a la finalización de las que la preceden. Lo que no hace es grafo es saber lo que se realiza dentro de las tareas, sólo le importa el orden de ejecución, la cantidad de reintentos, si tiene un duración de caducidad (timeout), etc...
Orquestación de flujos de trabajo¶
La planificación de los DAG antiguamente se realizaba mediante tareas cron que ejecutaban algún script que lanzaba el pipeline de datos. Conforme crecía la cantidad de pipelines era necesaria utilizar alguna herramienta que permita planificar y monitorizar los pipelines.
Las soluciones de orquestación de datos se utilizan hoy en día para:
- limpieza, organización y persistencia en un data lakehouse
- cálculo de KPIs
- preparación de datos y entrenamiento de modelos IA.
Orquestación vs Automatización
Conviene no confundir automatización, entendida como configurar una tarea para que se ejecute por sí sola, con la orquestación, donde tenemos múltiples tareas interrelacionadas con dependencias entre ellas.
Herramientas¶

Las principales herramientas para la orquestación de flujos (workflow management systems - WMS) de datos son:
- Apache Airflow: estándar de facto como herramienta de orquestación de flujos de datos, los cuales se definen mediante Python y ofrece un interfaz gráfico para su monitorización.
- Apache Nifi: ofrece un interfaz gráfico muy amigable para la definición de los flujos, así como un conjunto de conectores ya predefinidos para interactuar tanto con las fuentes de datos como los diferentes destinos.
- Apache Oozie: centrada en su uso dentro del ecosistema Hadoop definiendo los flujos mediante XML. Actualmente se encuentra en desuso.
Existen otras herramientas tan o más válidas como pueden ser Argo, Luigi, Prefect o Dagster.
Apache Airflow¶
Apache Airflow es un framework orientado a procesamiento batch para construir pipelines de datos, facilitando su planificación mediante código Python. Funciona como un orquestador de flujos, situándose en medio de los procesos de datos y coordinando cuándo y cómo los datos viajan de un lugar a otro.
A día de hoy (mayo de 2023) es la plataforma de orquestación open-source más popular, siendo la versión 2.5.3 la última disponible.
Nació como un proyecto interno en Airbnb a finales de 2014, con el propósito de solucionar la complejidad de los flujos de trabajo mediante una autoría programativa y planificando las tareas mediante un interfaz gráfico sencillo.
Para ello, definiremos un pipeline con su propia configuración y planificación dentro de un script Python, lo que otorga gran flexibilidad a la hora de definir los DAGs (grafos acíclicos dirigidos), permitiendo generar tareas opcionales que dependen de ciertas condiciones o incluso definir DAGs a partir de metadatos externos o ficheros de configuración.
Como las tareas pueden ejecutar cualquier operación que podamos codificar en Python, existen muchísimas extensiones que permiten ejecutar tareas en una gran variedad de sistemas, ya sean bases de datos externas, tecnologías big data, servicios cloud, etc... permitiendo definir complejos flujos de datos entre múltiples sistemas.
Las principales ventajas de utilizar Airflow son:
- poder crear pipelines mediante Python, permitiendo solucionar casi cualquier problema.
- amplia comunidad que ya ha desarrollado múltiples extension que facilitan la integración de Airflow con diferentes tipos de bases de datos, servicios cloud, etc...
- semántica rica para la planificación de los pipelines.
- características avanzadas como el backfilling para la ejecución de tareas que han fallado o el reprocesado de datos históricos, permitiendo regenerar cualquier conjunto de datos tras haber hecho cambios en nuestro código.
- interfaz gráfico rico que facilita la monitorización y depuración de los resultados de los grafos ejecutados.
Finalmente, al tratarse de un producto open source ya existen diferentes empresas que ofrecen una solución gestionada en el cloud con soporte, como puede ser Astronomer, el cual tiene su propia certificación y plataforma educativa o AWS Managed Workflows for Apache Airflow (MWAA)
Componentes¶
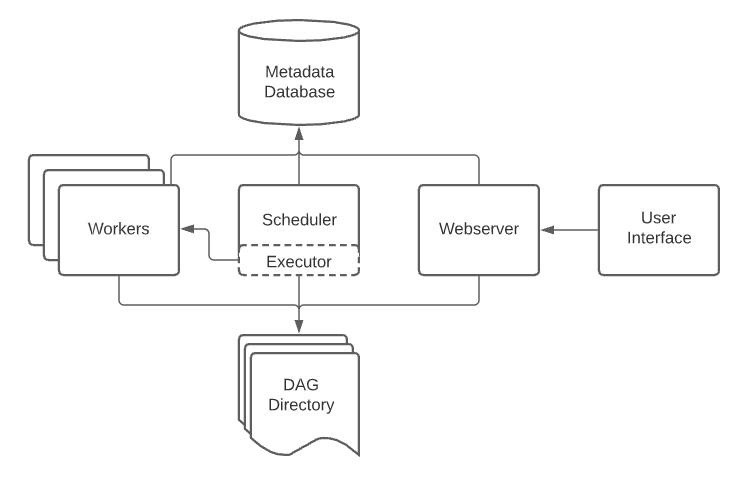
A nivel de arquitectura, Airflow se organiza en los siguientes componentes:
- El planificador (scheduler): parsea los DAGS, comprueba los intervalos de planificación y si se cumplen, planifica su ejecución pasándoselos a los workers.
- Los trabajadores (workers): recoge las tareas planificadas para ejecución y las ejecuta. Son los componentes encargados realmente de realizar el trabajo.
- El servidor web (webserver): visualiza los DAGs parseados por el planificador y ofrece un interfaz a los usuarios para ejecutar, depurar y monitorizar los flujos, así como sus resultados.
- Una carpeta con los ficheros Python con la definición de los flujos, a la cual acceden el planificador y los trabajadores.
- Una base de datos con metadatos (metastore).
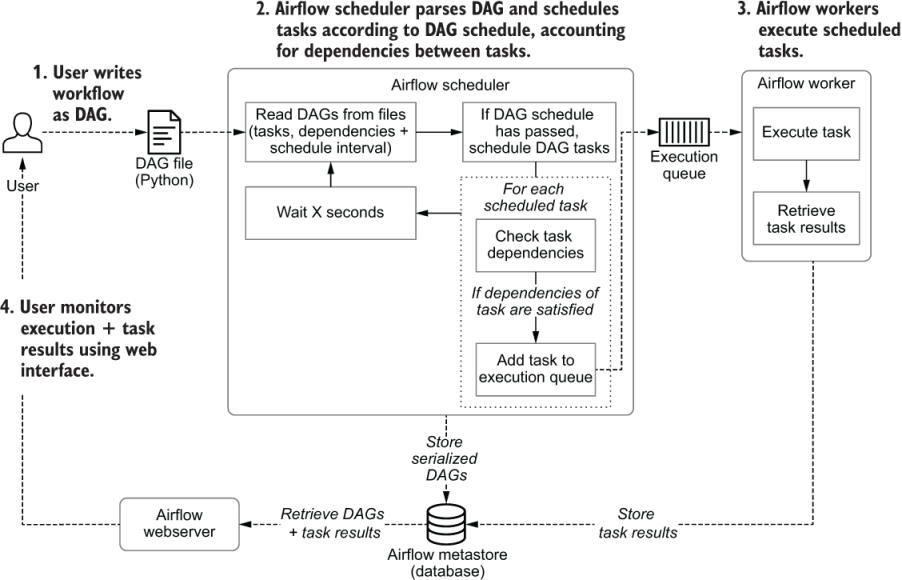
Vamos a explicar en un poco de más detalle como se comunican estos componentes paso a paso:
- El usuario codifica un DAG en Python y lo almacena en la carpeta con la definición de los flujos.
- El planificador lee el DAG y
- Extrae las tareas, dependencias e intervalo de ejecución.
- Comprueba si se cumple el intervalo de planificación desde la última que leyó el DAG. Si es así, las tareas del DAG se planifican para su ejecución.
- Para cada tarea, comprueba las dependencias (upstream tasks) de las tareas que ya han finalizado. Si las hay, las añade a la cola de ejecución.
- El planificador espera un momento y vuelve a comenzar con el paso 1.
- Una vez que las tareas se encolan, la consumen un pool de trabajadores que ejecutan en paralelo las tareas y guardan su resultado. Estos resultados se almacenan en el metastore
- El usuario monitoriza la ejecución del DAG y el progreso del resultado de las tareas (junto con sus logs) mediante el interfaz gráfico del servidor web de Airflow.
Airflow envía las tareas a los workers tan pronto como es posible, por lo que no hay garantías que todas las tareas de un DAG se ejecuten en el mismo worker en la misma máquina.
DAGs¶
Los DAGs se diseñan para ejecutarse muchas veces, y muchas de esas ejecuciones se pueden realizar en paralelo. Además, los DAGs se parametrizan, incluyendo siempre un intervalo de datos.
Conforme vayamos creando nuestro DAGs es muy común que se vayan complicando. Para ello, podemos reutilizar DAGs creando DAGs unos dentro de otros a modo de módulos (subdag), así como grupos de tareas (TaskGroups) para agruparlos visualmente en el interfaz gráfico.
Airflow por sí mismo es agnóstico de lo que está ejecutando, de manera que orquesta y ejecuta cualquier funcionalidad que ofrecen los proveedores, un comando mediante shell o cualquier operador de Python.
Planificación¶
Formato crontab
Las expresiones crontab utilizan el formato minuto, hora, dia del mes, mes, dia de la semana.
Así pues, el valor @yearly es similar a 0 0 1 1 *, ya que significa que se ejecuta de forma anual el 1 de Enero (1 1) a medianoche (0 0) cualquier día de la semana *.
Una vez hemos definido la estructura de nuestro pipeline como un DAG, Airflow nos permite definir el intervalo de planificación de cada DAG, determinando cuando se ejecutará el pipeline.
De esta manera, podemos decirle a Airflow que ejecute el DAG cada hora, día, semana, etc... o mediante intervalos de planificación más complejos basados en expresiones Cron:
| Valor de planificación | Expresión Cron |
|---|---|
@once |
|
@hourly |
0 * * * * |
@daily |
0 0 * * * |
@weekly |
0 0 * * 0 |
@monthly |
0 0 1 * * |
@yearly |
0 0 1 1 * |
Ejecutor¶
El ejecutor es el proceso responsable de lanzar las tareas a partir de la planificación del DAG. Para ello, espera que el planificador le notifique que el DAG está listo para su ejecución.
De hecho, el ejecutor corre dentro del proceso del planificador, lo que implica que sólo pueda haber un modo de ejecución por cluster.
Airflow dispone principalmente de dos tipos de ejecutores:
- Ejecutores locales: SequentialExecutor (por defecto) y LocalExecutor (mejor para pequeños clústers ya que permite la paralelización de los procesos).
- Ejecutores remotos: permiten la ejecución de múltiples DAGs de forma paralela mediante un red de nodos workers, por ejemplo, mediante CeleryExecutor para arquitecturas en clúster o KubernetesExecutor si utilizamos Kubernetes como orquestador de contenedores.
Tareas¶
Todo DAG ejecuta una o más tareas (todas heredan de la clase BaseOperator). Podemos considerar las tareas como la unidad de ejecución de Airflow. Destacan tres tipos de tareas:
- Operadores: tareas predefinidas (a modo de plantillas) que podemos encadenar para construir la mayoría de nuestros DAGs. Pueden ejecutarse de forma local o remota. Airflow tiene varios tipos de operadores ya predefinidos, como son los operadores bash, el operador python o los operadores para interactuar con bases de datos.
- Sensores: subclase de los operadores centrada en la escucha de eventos externos.
- Un flujo de tareas decoradas con
@task
Internamente, los conceptos de tarea y operador son intercambiables, pero conviene separa ambos conceptos teniendo en cuenta que los Operadores y los Sensores son plantillas, y cuando invocamos uno en un DAG, entonces estamos creado una Tarea.
Dependencias¶
Las tareas tienen dependencias que se declaran unas sobre otras, mediante los operadores >> y <<, dependiendo de si indicamos primero las dependencias antes o después:
primera_tarea >> [segunda_tarea, tercera_tarea]
cuarta_tarea << tercera_tarea
Esto mismo se puede definir mediante los métodos set_upstream y set_downstream:
primera_tarea.set_downstream([segunda_tarea, tercera_tarea])
cuarta_tarea.set_upstream(tercera_tarea)
Estas dependencias definen los nodos del grafo y cómo sabe Airflow el orden en el que debe ejecutar las tareas. Por defecto, una tarea esperará a que todas las tareas previas (upstream) hayan finalizado exitosamente antes de ejecutarse (aunque esto puede personalizarse mediante características como Branching, LatestOnly y reglas de Trigger).
Pasando datos entre tareas¶
Por defecto, los nodos de un DAG no transmiten información de uno a otro, pero en algún caso concreto puede ser necesario que un nodo necesite cierta información de alguno de sus predecesores.
Para pasar datos entre las tareas disponemos de tres opciones:
- XComs (Cross-communications), un sistema para que las tareas puedan hacer push y pull de una pequeña cantidad de metadatos.
- Cargar y descargar archivos grandes desde servicios de almacenamiento (como pueda ser S3 o un NAS)
- Utilizar el API TaskFlow que automáticamente pasa los datos entre tareas implícitamente mediante XComs.
Puesta en marcha¶
En nuestra máquina virtual ya tenemos instalada la versión 2.5 de Apache Airflow, la cual hemos instalado mediante pip en /opt/airflow-2.5.0. Puedes encontrar más información sobre su instalación en la documentación oficial.
Para arrancarlo, ejecutaremos en dos terminales diferentes los comandos para arrancar tanto el servidor web como el planificador:
airflow webserver
airflow scheduler
Si queremos crear un nuevo usuario, podemos hacerlo a través del comando airflow users create:
airflow users create \
--username airflow \
--firstname IA \
--lastname BD \
--role Admin \
--email iabd@s8a.com
A continuación nos pedirá que introduzcamos la contraseña, que en nuestro caso, hemos puesto airflow.
Airflow en Docker
Para ejecutar Airflow dentro de Docker se recomienda seguir las instrucciones de la documentación oficial.
Para facilitar su uso, se adjunto el archivo docker-compose.yml que hemos empleado en clase.
En un entorno de producción, en vez de tener todos los contenedores en una máquina, deberíamos repartirlo en diferentes máquinas, o incluso mejor, optar por el despliegue en un cluster de Kubernetes.
Interfaz web¶
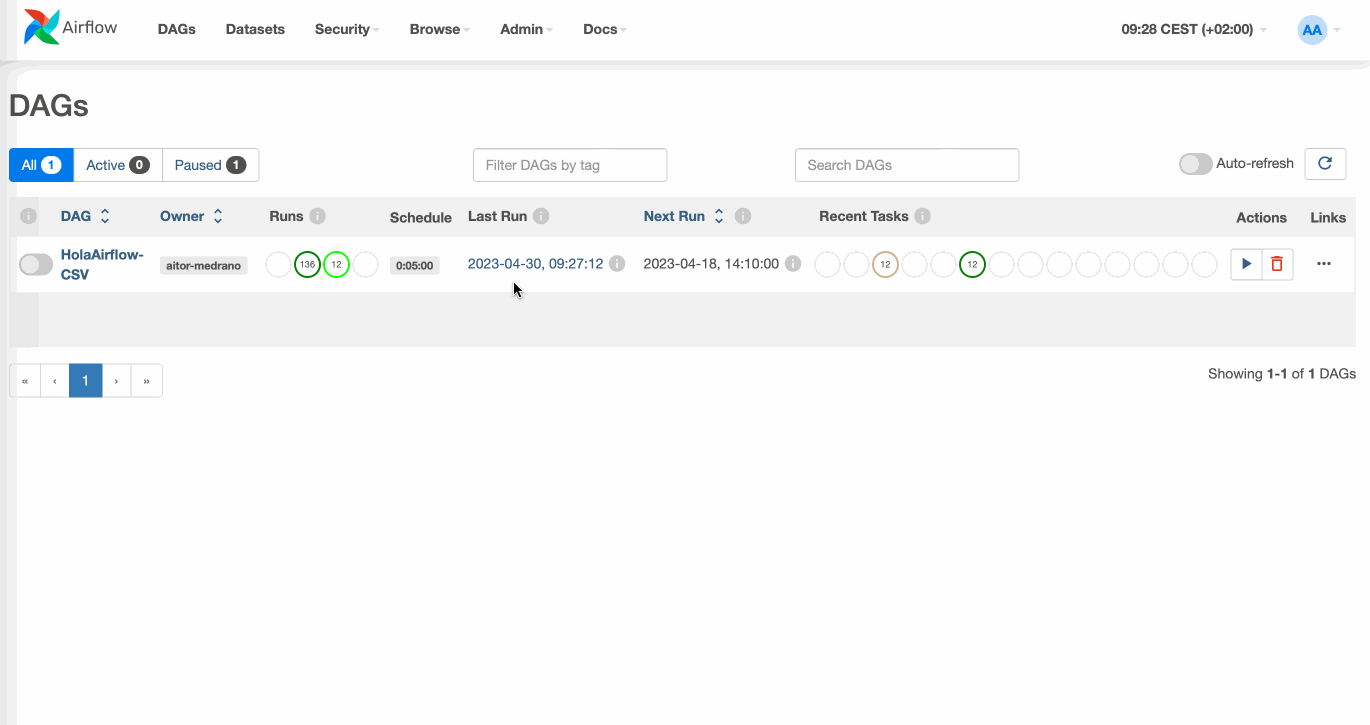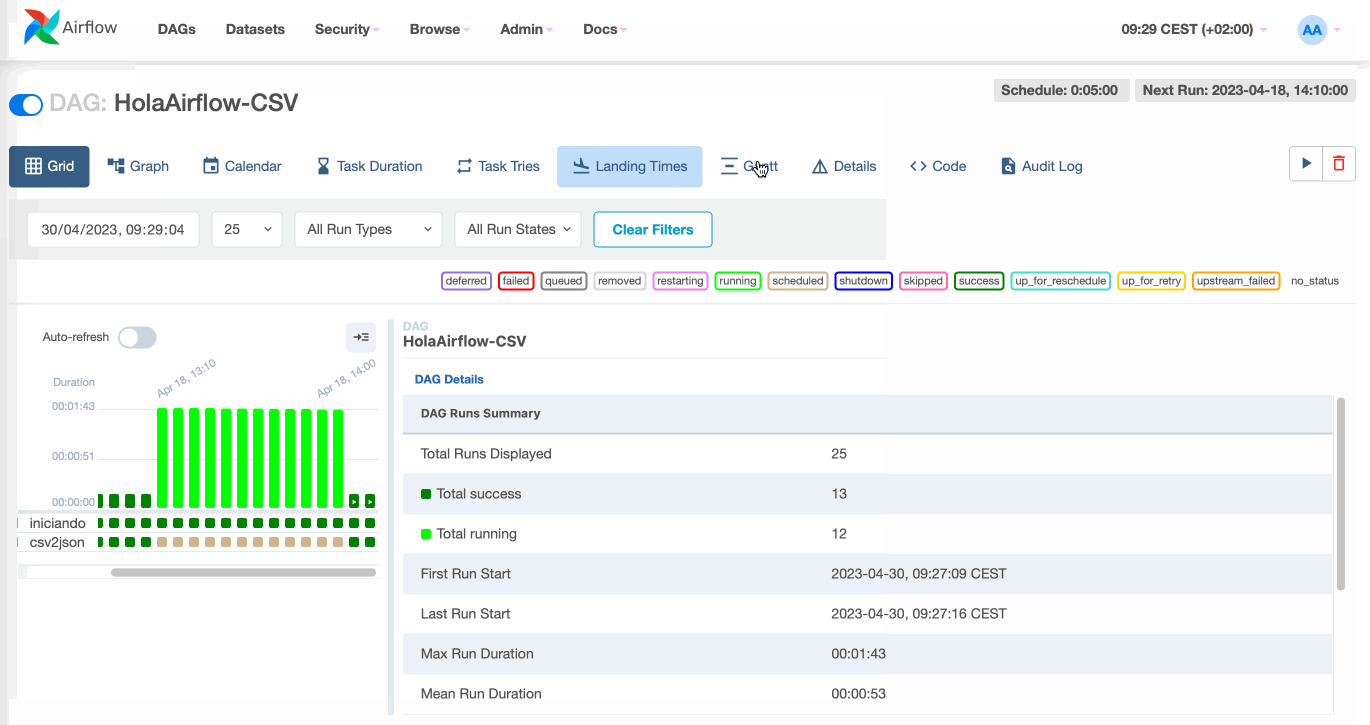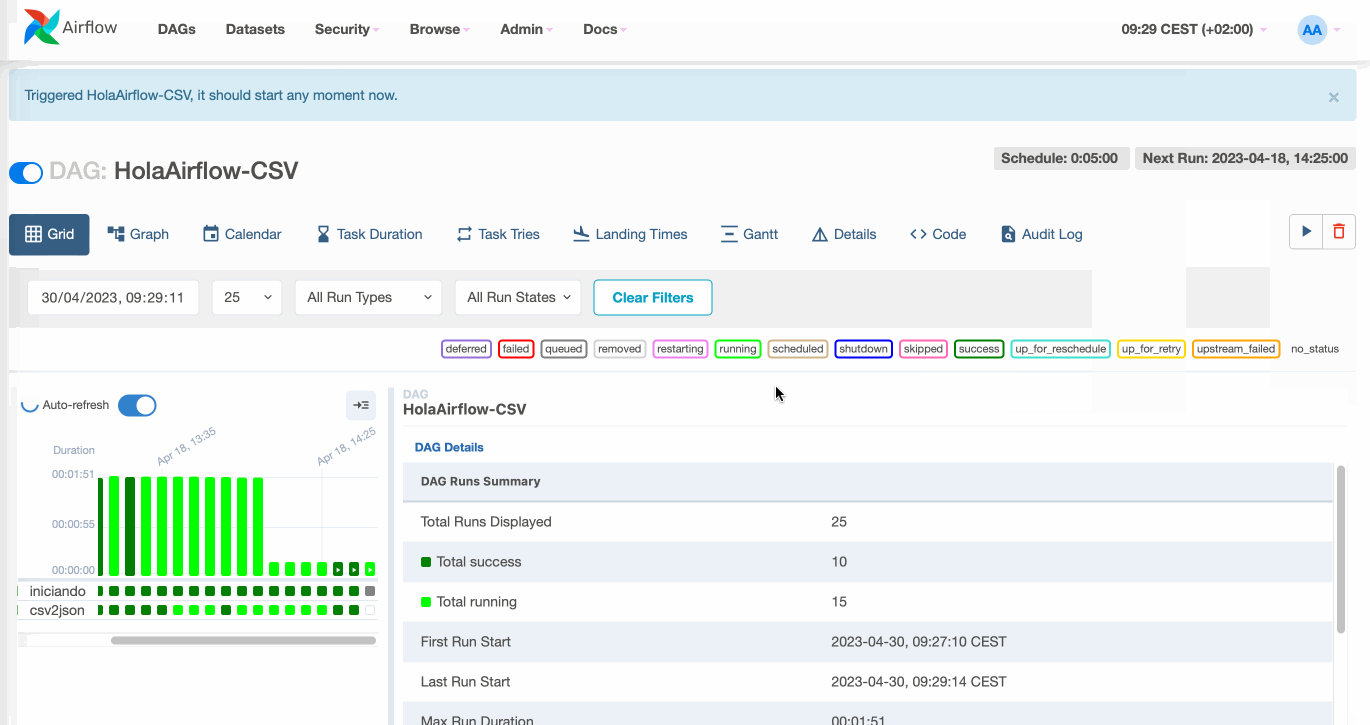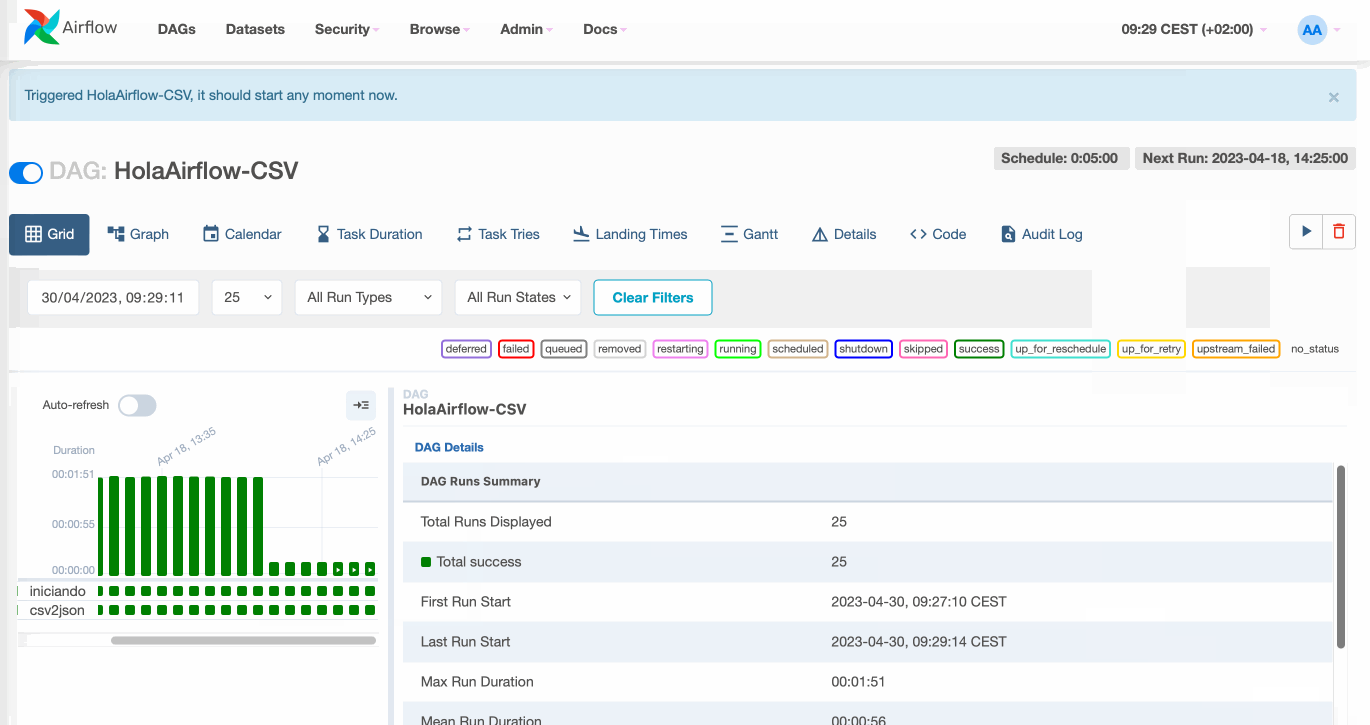
Al entrar a http://localhost:8080/, tras introducir el usuario airflow y contraseña airflow podemos ver el listado de DAGs cargados en Airflow:
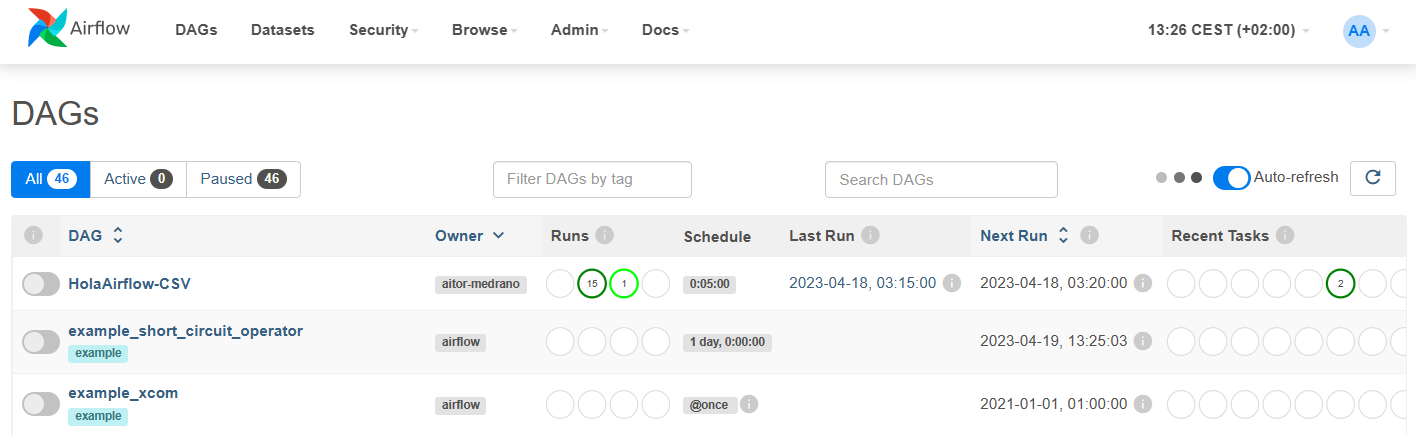
En esta pantalla podemos ver las definiciones de nuestros grafos, sus metadatos y estadísticas sobre las ejecuciones previas (si las hubiera). Además, en la parte superior disponemos de diferentes opciones de seguridad y herramientas comunes de administración, como puede ser preconfigurar el acceso a recursos centrales como almacenes de datos mediante la configuración de conexiones (Admin ⇨ Connections) así como limitar la concurrencia (Admin ⇨ Pools).
Hola Airflow¶
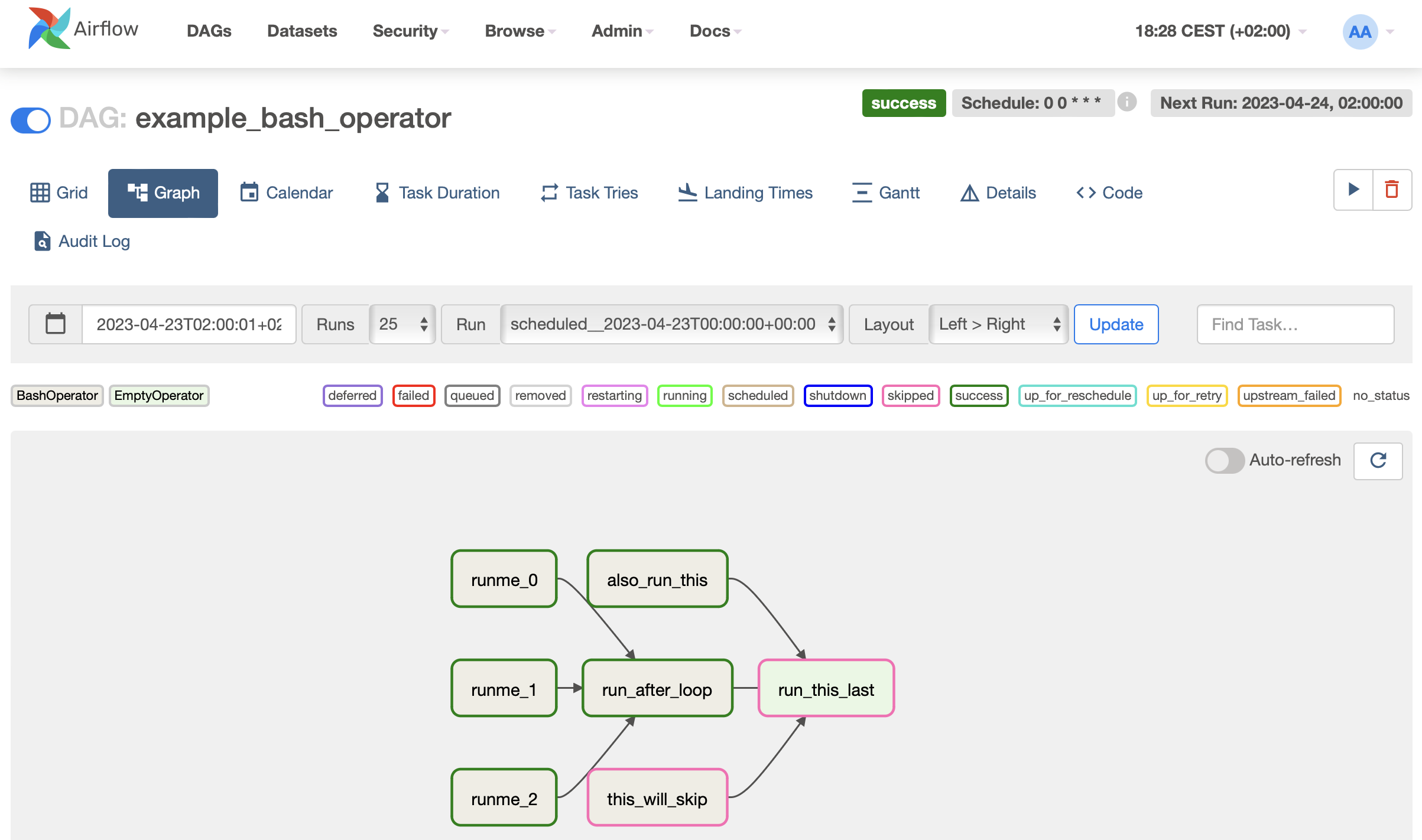
Para probar Airflow, vamos a ejecutar uno de los ejemplos instalados, en concreto example_bash_operator.
Si entramos a nuestro flujo, podemos lanzarlo mediante el slider situado a la izquierda (pause/unpause DAG) así como provocar una ejecución mediante los botones situado a la derecha (el play para hacer un trigger del DAG). En la siguiente imagen podemos ver la vista de grafo donde podemos observar las diferentes tareas y dependencias:
Si pulsamos sobre la opción de Source podemos ver el código Python que define el DAG:
with DAG(
dag_id="example_bash_operator",
schedule="0 0 * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
tags=["example", "example2"],
params={"example_key": "example_value"},
) as dag:
run_this_last = EmptyOperator(
task_id="run_this_last",
)
# [START howto_operator_bash]
run_this = BashOperator(
task_id="run_after_loop",
bash_command="echo 1",
)
# [END howto_operator_bash]
run_this >> run_this_last
for i in range(3):
task = BashOperator(
task_id="runme_" + str(i),
bash_command='echo "{{ task_instance_key_str }}" && sleep 1',
)
task >> run_this
# [START howto_operator_bash_template]
also_run_this = BashOperator(
task_id="also_run_this",
bash_command='echo "ti_key={{ task_instance_key_str }}"',
)
# [END howto_operator_bash_template]
also_run_this >> run_this_last
# [START howto_operator_bash_skip]
this_will_skip = BashOperator(
task_id="this_will_skip",
bash_command='echo "hello world"; exit 99;',
dag=dag,
)
# [END howto_operator_bash_skip]
this_will_skip >> run_this_last
Sin entrar todavía en detalle en el código podemos ver como utiliza los operadores BashOperator y EmptyOperator. El operador bash ejecuta una operación de línea de comandos (en este ejemplo estamos realizando operaciones echo) y el operador vacío sirve para crear un nodo final común.
Una vez lanzado, si cambiamos a la vista de Grid (antes se conocía como la vista de árbol), podemos ver todas las ejecuciones actuales e históricas. Esta vista es la más útil en el día a día, ya que nos permite obtener una visión general de cómo está funcionando el DAG así como visualizar las tareas que fallan y analizar su motivo.
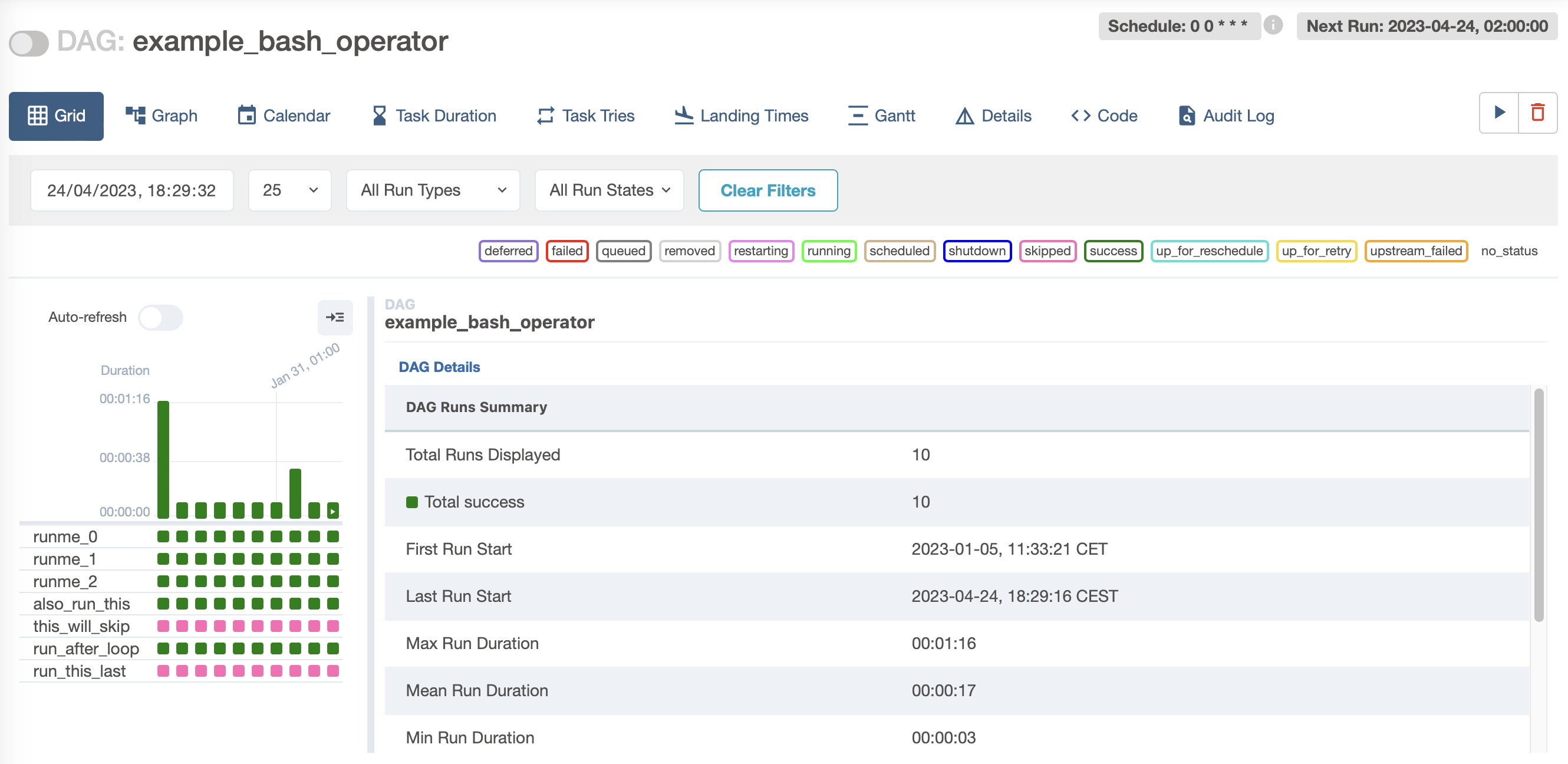
Podemos observar en el panel lateral de la izquierda como tenemos varias ejecuciones realizadas exitosamente (cada columna de cuadrados en verde es una ejecución, y cada cuadrado en sí representa el estado de una tarea). Si pulsamos sobre uno de los cuadrados, podemos obtener información sobre el estado de dicha ejecución (tanto del grafo completo como de las tareas individuales) y dependiendo de la instalación, tenemos la posibilidad de resetear el estado de una tarea para que pueda volver a ejecutarse:
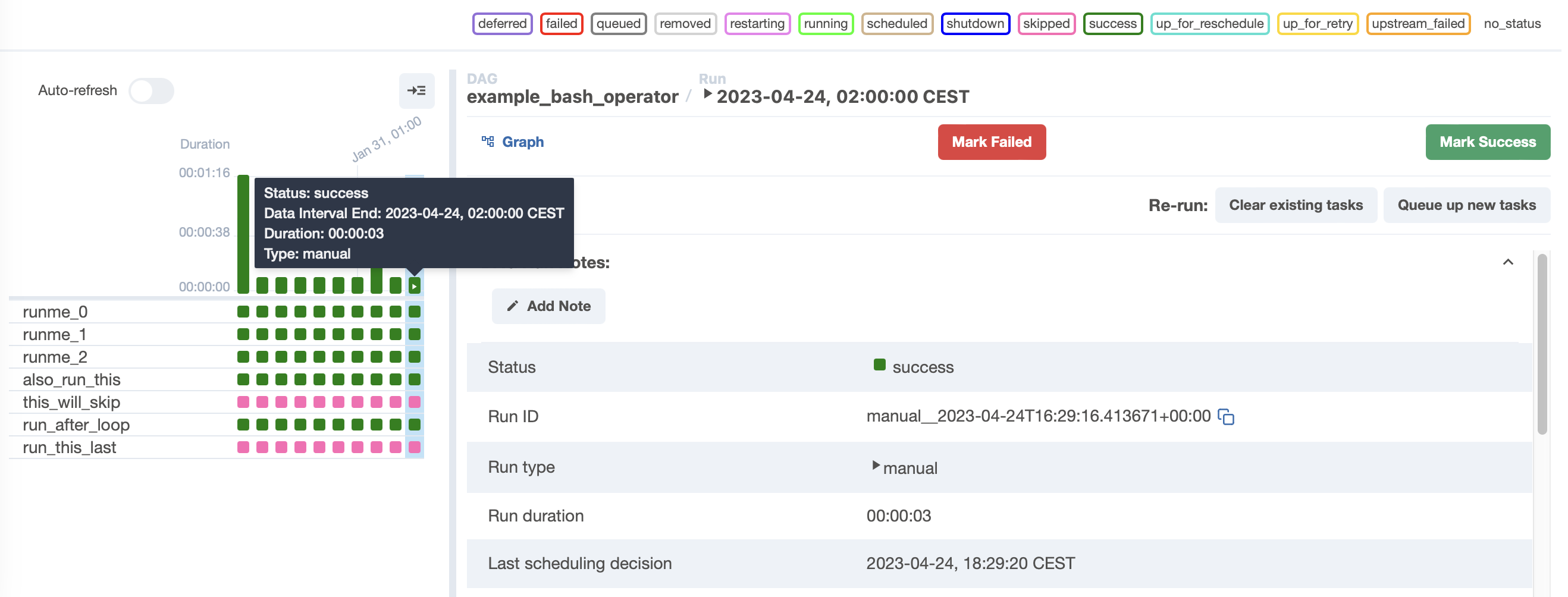
Por defecto, Airflow puede gestionar los fallos en las tareas mediante varios reintentos (opcionalmente podemos indicar un tiempo de espera entre cada intento), lo que puede facilitar la recuperación de fallos intermitentes. Si los reintentos no ayudan, Airflow registrará la tarea como fallida, y opcionalmente notificará (si así lo hemos configurado) del fallo. De esta manera, depurar fallos en las tareas es un proceso bastante directo, ya que la vista de grid nos permite analizar las tareas que han fallado y navegar por sus logs. Además, esta misma vista permite limpiar el estado de las tareas para volver a ejecutarla (la tarea en cuestión y todas las tareas que dependan de ella), lo que facilita volver a ejecutar cualquier tarea tras haber corregido el fallo en el código fuente.
Quitando los ejemplos
Si no queremos que nos aparezcan todos los grafos de ejemplo, hemos de modificar la variable de entorno AIRFLOW__CORE__LOAD_EXAMPLES.
export AIRFLOW__CORE__LOAD_EXAMPLES=False
En la máquina virtual, si no queremos fijar la variable de entorno, podemos modificar en el archivo airflow.cfg la propiedad load_examples = False y a continuación resetear el metastore:
airflow db reset
En Docker modificaremos la propiedad AIRFLOW__CORE__LOAD_EXAMPLES a false y volveremos a crear los contenedores:
AIRFLOW__CORE__LOAD_EXAMPLES: 'false'
Caso 1: De CSV a JSON¶
Vamos a crear nuestro primer grafo, y para ello, vamos a realizar un ejemplo muy sencillo para leer un fichero con datos en formato CSV y transformarlo a JSON.
Se adjunta el siguiente archivo en formato CSV generado mediante Faker que contiene datos de personas:
nombre,edad,calle,ciudad,provincia,cp,longitud,latitud
Amaro Gómez Berrocal,45,Alameda de Clementina Luque 370,Palencia,Granada,07784,17.978258,64.777519
Consuelo Lerma Camino,38,Acceso Genoveva Lobato 3,Ciudad,Lugo,31271,-54.709984,85.6336715
Francisco Javier Palacio-Carbó,43,Rambla de Dora Ángel 7,Sevilla,Valladolid,09521,-68.691636,-30.530751
...
Antes de crear nuestro primer DAG, vamos a crear la función para leer el archivo CSV y pasarlo a JSON haciendo uso de Pandas (las rutas pueden variar entre la máquina virtual y Dropbox). Para ello, crea el siguiente script dentro de la carpeta /opt/airflow-2.5.0/dags y coloca los datos en /opt/airflow-2.5.0/data (si es la primera vez, es probable que tengas que crear dichas carpetas en la máquina virtual):
import pandas as pd
def csvToJson():
df=pd.read_csv('/opt/airflow-2.5.0/data/datos-faker.csv')
for i,r in df.iterrows():
print(r['nombre'])
df.to_json('/opt/airflow-2.5.0/data/datos-airflow.json', orient='records')
Definición del DAG¶
A continuación vamos a definir un diccionario con las propiedades del DAG, como son el propietario, fecha de inicio, cantidad de reintentos y retraso entre cada reintento:
import datetime as dt
from datetime import timedelta
default_args = {
'owner': 'aitor-medrano',
'start_date': dt.datetime(2023, 4, 25),
'retries': 1,
'retry_delay': dt.timedelta(minutes=5),
}
A continuación definimos propiamente el DAG con sus tareas. Para ello, creamos un objeto DAG donde vamos a definir su identificador, pasarle el diccionario que acabamos de crear y configurar su planificación.
Para configurar la planificación completaremos el atributo schedule_interval, ya sea mediante timedelta para definir su periodicidad o haciendo uso de expresiones crontab:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
with DAG('HolaAirflow-CSV',
default_args=default_args,
schedule_interval=timedelta(minutes=5), # '0 * * * *',
) as dag:
imprime_iniciando = BashOperator(task_id='iniciando',
bash_command='echo "Leyendo el csv..."')
csvJson = PythonOperator(task_id='csv2json', python_callable=csvToJson)
A continuación, definimos la tarea imprime_iniciando mediante un operador bash que imprime una cadena para saber que se está ejecutando. El objetivo de esta tarea sólo es didáctica, para demostrar como conectar las tareas. La siguiente tarea csvJson utiliza el operador Python para llamar a la función que hemos definido previamente, encargada de transformar un archivo CSV a JSON.
Inicio del DAG
El inicio real de un DAG es start_date + schedule_interval.
Es decir, si planificar un DAG con hoy como valor de start_date y en schedule_interval le ponemos como valor daily, realmente el DAG no se ejecutará hasta mañana.
Dependencias entre tareas¶
Y finalmente configuramos las dependencias entre las tareas, de manera que primero imprimimos un mensaje informativo y a continuación realizamos el cambio de formato:
imprime_iniciando >> csvJson
Tal como hemos visto en el apartado de Dependencias también la podríamos haber definido así (son todas equivalentes):
imprime_iniciando.set_downstream(csvJson)
csvJson.set_upstream(imprime_iniciando)
csvJson << imprime_iniciando
Sé consistente
Independientemente de la forma que te guste más, siempre debes utilizar la misma y ser consistente. En mi caso, utilizaré siempre el operador de desplazamiento de bits a la derecha (>>)
Ejecución¶
Una vez tenemos todo el archivo codificado (en mi caso lo he llamado 01csv2json.py) lo colocaremos en la carpeta /opt/airflow-2.5.0/dags (la cual está configurada mediante la propiedad dags_folder).
Si ahora arrancamos airflow podremos ver como aparece el DAG y podemos ejecutarlo y ver su estado:
Probando desde el CLI¶
Además del interfaz gráfico, podemos utilizar el CLI para interactuar con Airflow. Por ejemplo, para mostrar todos los DAGs desplegados utilizaremos el comando airflow dags list:
airflow dags list
# dag_id | filepath | owner | paused
# ================+===============+===============+=======
# HolaAirflow-CSV | 01read-csv.py | aitor-medrano | False
Si queremos ver todas las tareas de nuestro DAG, ahora usaremos airflow tasks list y le pasamos el nombre del DAG:
airflow tasks list HolaAirflow-CSV
# csv2json
# iniciando
Y si queremos ver sus representación jerárquica:
airflow tasks list HolaAirflow-CSV --tree
# <Task(BashOperator): iniciando>
# <Task(PythonOperator): csv2json>
Para probarlo, podemos realizar pruebas de las tareas de forma independiente, mediante airflow tasks test, donde podemos ver el operador ejecutado, así como su salida y estado:
airflow tasks test HolaAirflow-CSV iniciando
# [2023-04-30 07:46:18,079] {dagbag.py:538} INFO - Filling up the DagBag from /opt/***/dags
# [2023-04-30 07:46:19,483] {taskinstance.py:1087} INFO - Dependencies all met for <TaskInstance: HolaAirflow-CSV.iniciando __***_temporary_run_2023-04-30T07:46:18.644346+00:00__ [None]>
# [2023-04-30 07:46:19,500] {taskinstance.py:1087} INFO - Dependencies all met for <TaskInstance: HolaAirflow-CSV.iniciando __***_temporary_run_2023-04-30T07:46:18.644346+00:00__ [None]>
# [2023-04-30 07:46:19,500] {taskinstance.py:1283} INFO -
# --------------------------------------------------------------------------------
# [2023-04-30 07:46:19,500] {taskinstance.py:1284} INFO - Starting attempt 1 of 2
# [2023-04-30 07:46:19,500] {taskinstance.py:1285} INFO -
# --------------------------------------------------------------------------------
# [2023-04-30 07:46:19,503] {taskinstance.py:1304} INFO - Executing <Task(BashOperator): iniciando> on 2023-04-30T07:46:18.644336+00:00
# [2023-04-30 07:46:19,764] {taskinstance.py:1513} INFO - Exporting the following env vars:
# AIRFLOW_CTX_DAG_OWNER=aitor-medrano
# AIRFLOW_CTX_DAG_ID=HolaAirflow-CSV
# AIRFLOW_CTX_TASK_ID=iniciando
# AIRFLOW_CTX_EXECUTION_DATE=2023-04-30T07:46:18.644336+00:00
# AIRFLOW_CTX_TRY_NUMBER=1
# AIRFLOW_CTX_DAG_RUN_ID=__***_temporary_run_2023-04-30T07:46:18.644346+00:00__
# [2023-04-30 07:46:19,766] {subprocess.py:63} INFO - Tmp dir root location: /tmp
# [2023-04-30 07:46:19,767] {subprocess.py:75} INFO - Running command: ['/bin/bash', '-c', 'echo "Leyendo el csv..."']
# [2023-04-30 07:46:19,786] {subprocess.py:86} INFO - Output:
# [2023-04-30 07:46:19,789] {subprocess.py:93} INFO - Leyendo el csv...
# [2023-04-30 07:46:19,789] {subprocess.py:97} INFO - Command exited with return code 0
# [2023-04-30 07:46:20,001] {taskinstance.py:1327} INFO - Marking task as SUCCESS. dag_id=HolaAirflow-CSV, task_id=iniciando, execution_date=20230430T074618, start_date=, end_date=20230430T074620
O probar todo el DAG mediante airflow dags test:
airflow dags test HolaAirflow-CSV
[2023-04-30 07:51:18,119] {dagbag.py:538} INFO - Filling up the DagBag from /opt/airflow-2.5.0/dags
[2023-04-30 07:51:18,843] {dag.py:3651} INFO - dagrun id: HolaAirflow-CSV
[2023-04-30 07:51:18,872] {dag.py:3668} INFO - created dagrun <DagRun HolaAirflow-CSV @ 2023-04-30T07:51:18.119560+00:00: manual__2023-04-30T07:51:18.119560+00:00, state:running, queued_at: None. externally triggered: False>
[2023-04-30 07:51:18,895] {dag.py:3618} INFO - *****************************************************
[2023-04-30 07:51:18,896] {dag.py:3622} INFO - Running task iniciando
[2023-04-30 07:51:19,237] {taskinstance.py:1513} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_OWNER=aitor-medrano
AIRFLOW_CTX_DAG_ID=HolaAirflow-CSV
AIRFLOW_CTX_TASK_ID=iniciando
AIRFLOW_CTX_EXECUTION_DATE=2023-04-30T07:51:18.119560+00:00
AIRFLOW_CTX_TRY_NUMBER=1
AIRFLOW_CTX_DAG_RUN_ID=manual__2023-04-30T07:51:18.119560+00:00
[2023-04-30 07:51:19,239] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2023-04-30 07:51:19,239] {subprocess.py:75} INFO - Running command: ['/bin/bash', '-c', 'echo "Leyendo el csv..."']
[2023-04-30 07:51:19,263] {subprocess.py:86} INFO - Output:
[2023-04-30 07:51:19,273] {subprocess.py:93} INFO - Leyendo el csv...
[2023-04-30 07:51:19,274] {subprocess.py:97} INFO - Command exited with return code 0
[2023-04-30 07:51:19,330] {taskinstance.py:1327} INFO - Marking task as SUCCESS. dag_id=HolaAirflow-CSV, task_id=iniciando, execution_date=20230430T075118, start_date=, end_date=20230430T075119
[2023-04-30 07:51:19,354] {dag.py:3626} INFO - iniciando ran successfully!
[2023-04-30 07:51:19,358] {dag.py:3618} INFO - *****************************************************
[2023-04-30 07:51:19,358] {dag.py:3622} INFO - Running task csv2json
[2023-04-30 07:51:19,392] {taskinstance.py:1513} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_OWNER=aitor-medrano
AIRFLOW_CTX_DAG_ID=HolaAirflow-CSV
AIRFLOW_CTX_TASK_ID=csv2json
AIRFLOW_CTX_EXECUTION_DATE=2023-04-30T07:51:18.119560+00:00
AIRFLOW_CTX_TRY_NUMBER=1
AIRFLOW_CTX_DAG_RUN_ID=manual__2023-04-30T07:51:18.119560+00:00
Amaro Gómez Berrocal
Consuelo Lerma Camino
...
Epifanio Vigil-Belmonte
[2023-04-30 07:51:19,546] {python.py:177} INFO - Done. Returned value was: None
[2023-04-30 07:51:19,564] {taskinstance.py:1327} INFO - Marking task as SUCCESS. dag_id=HolaAirflow-CSV, task_id=csv2json, execution_date=20230430T075118, start_date=, end_date=20230430T075119
[2023-04-30 07:51:19,581] {dag.py:3626} INFO - csv2json ran successfully!
[2023-04-30 07:51:19,581] {dag.py:3629} INFO - *****************************************************
[2023-04-30 07:51:19,586] {dagrun.py:606} INFO - Marking run <DagRun HolaAirflow-CSV @ 2023-04-30T07:51:18.119560+00:00: manual__2023-04-30T07:51:18.119560+00:00, state:running, queued_at: None. externally triggered: False> successful
[2023-04-30 07:51:19,595] {dagrun.py:672} INFO - DagRun Finished: dag_id=HolaAirflow-CSV, execution_date=2023-04-30T07:51:18.119560+00:00, run_id=manual__2023-04-30T07:51:18.119560+00:00, run_start_date=2023-04-30 07:51:18.119560+00:00, run_end_date=2023-04-30 07:51:19.586563+00:00, run_duration=1.467003, state=success, external_trigger=False, run_type=manual, data_interval_start=2023-04-30T07:51:18.119560+00:00, data_interval_end=2023-04-30T07:56:18.119560+00:00, dag_hash=None
Si en vez de probar, queremos lanzar un DAG, usaremos el comando aiflow dags trigger:
airflow dags trigger HolaAirflow-CSV
Caso 2: De MariaDB a S3¶
En este caso de uso, vamos a interactuar con una base de datos para recopilar datos y persistirlos en formato Parquet, para a continuar, subir dicho archivo a S3.
Así pues, lo primero que tenemos que dejar claro es que cada tarea debe ser atómica, de manera que si no se consigue acceder a la base de datos, no necesitamos conectar con S3. Además, las tareas siempre deben ser idempotentes, de manera que da igual la cantidad de veces que las ejecutemos, que el resultado siempre debe ser el mismo.
Así pues, vamos a crear una función que realice la lectura de los datos y otra que los persista en S3.
Conectando con la BD¶
Así pues, empezamos con la función de lectura de datos:
import pandas as pd
import mysql.connector
def consultaMariaDB():
conn = mysql.connector.connect(
user="admin",
password="adminadmin",
host="rdsiabd.cypxda1kh3tc.us-east-1.rds.amazonaws.com",
port=3306,
database="retail_db"
)
df=pd.read_sql("select customer_fname, customer_lname, customer_zipcode from customers",conn)
df.to_parquet('/tmp/customers.parquet')
print("-------Datos creados------")
Problemas con librerías
Si Airflow te da error, comprueba si la máquina virtual tiene instaladas las librerías para trabajar con MySQL:
pip3 install mysql-connector
pip3 install mysql-connector-python
Persistiendo en S3¶
Credenciales
Recuerda copiar las credencias de AWS Academy y copiarlas en ~/.aws/credentials.
A continuación, creamos una función que mediante boto3 transfiera el archivo recién creado a S3 (suponemos que ya tenemos creado el bucket con permisos para escribir en él):
def envioS3():
s3r = boto3.resource('s3', region_name='us-east-1')
nombreBucket = "iabd-s8a"
bucket = s3r.Object(nombreBucket, 'customers.parquet')
bucket.upload_file('/tmp/customers.parquet')
Definiendo el DAG¶
A continuación, ya podemos definir los parámetros por defecto y el propio DAG:
default_args = {
'owner': 'aitor-medrano',
'start_date': dt.datetime(2022, 5, 1),
'retries': 1,
'retry_delay': dt.timedelta(minutes=5),
}
with DAG('dag-mariadb-s3',
default_args=default_args,
schedule_interval=timedelta(minutes=5),
) as dag:
recuperaDatos = PythonOperator(task_id='QueryMariaDB',
python_callable=consultaMariaDB)
persisteDatos = PythonOperator(task_id='PersistDataS3',
python_callable=envioS3)
recuperaDatos >> persisteDatos
Tras copiar el DAG (nosotros lo hemos nombrado 02db2s3.py) a la carpeta $AIRFLOW_HOME/dags, ya podemos probar su funcionamiento.
Caso 3: De MariaDB a S3 mejorado¶
Vamos a repetir el mismo caso de uso, pero mejorando el código y añadiendo nueva funcionalidad.
Usando proveedores¶
Apache Airflow se puede extender mediante el uso de proveedores, entendidos como paquetes adicionales que podemos instalar para ofrecer un servicio externo. Existen múltiples proveedores, casi tanto como sistemas externos con los que podemos interactuar.
Así pues, vamos a utilizar un proveedor para que, en vez de dejar los datos de la conexión en el propio código, almacenemos las credenciales en una Connection, entendida como un conjunto de parámetros (usuario, contraseña, URL,...) a los que se le asocia un identificador.
Para ello, primero hemos instalar sus librerías como un proveedor de servicios, en nuestro caso, las de MySQL y Amazon:
pip3 install apache-airflow-providers-mysql
pip3 install apache-airflow-providers-amazon
A continuación, podemos crear la conexión desde Admin ⇨ Connections:
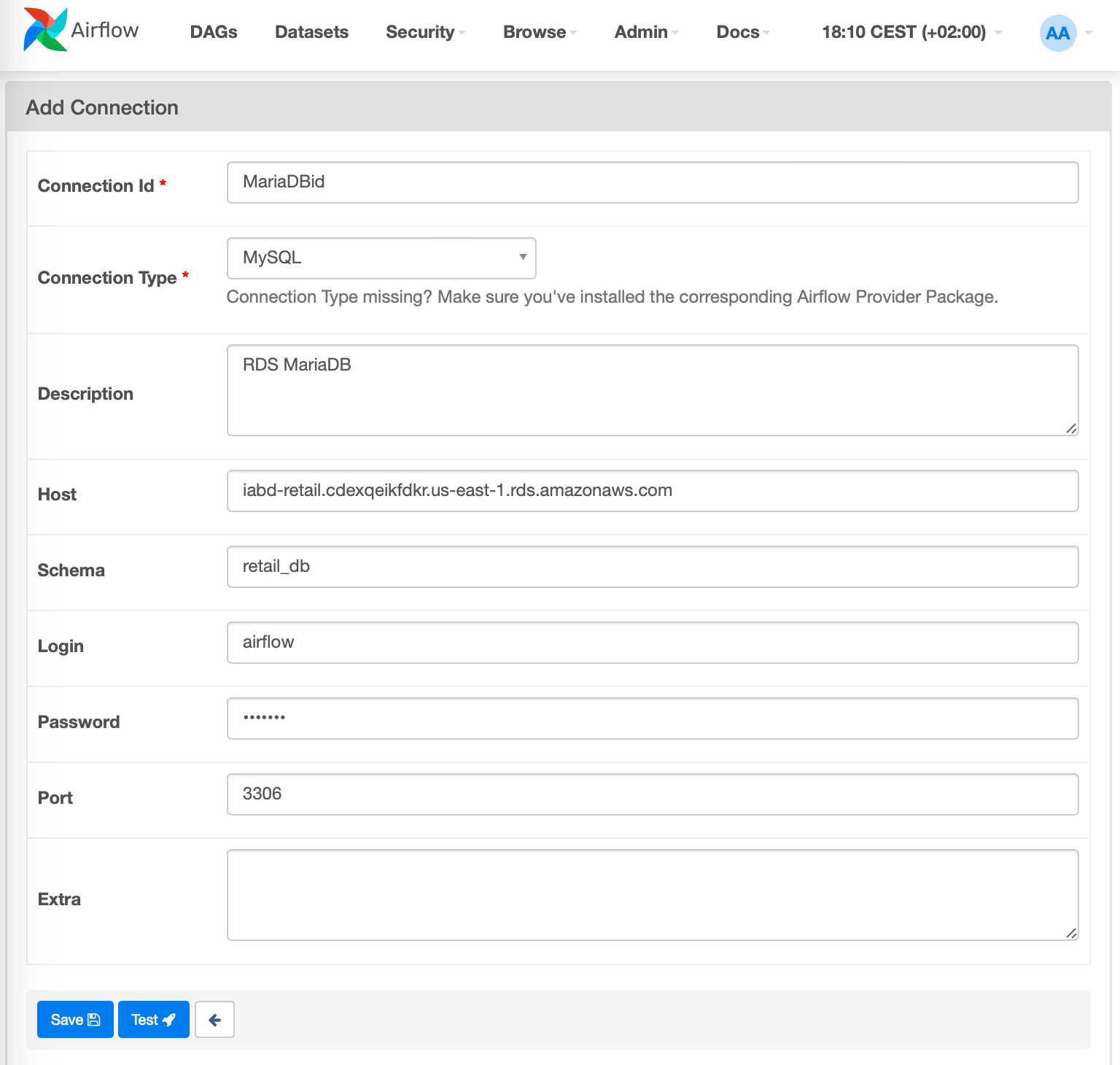
O desde el terminal:
airflow connections add 'mariaDBid' \
--conn-uri 'mysql://admin:adminadmin@rdsiabd.cypxda1kh3tc.us-east-1.rds.amazonaws.com:3306/retail_db'
Para utilizar el proveedor, hemos de emplear un Hook, entendido como un interfaz de alto nivel que nos facilitar interactuar con el proveedor sin necesidad de conocer su propia API.
Para utilizar el Hook, lo haremos a través del identificador de conexión que acabamos de crear. Así pues, cambiamos la función consultaMariaDB para acceder a la conexión almacenada mediante MySqlHook:
from airflow.hooks.mysql_hook import MySqlHook
def consultaMariaDBHook():
mysql_hook = MySqlHook(mysql_conn_id='MariaDBid')
conn = mysql_hook.get_conn()
df = pd.read_sql("select customer_fname, customer_lname, customer_zipcode from customers, conn)
df.to_parquet('customers.parquet')
print("-------Datos creados------")
Y volvemos a hacer lo mismo con S3 y el S3Hook. Primero creamos la conexión a AWS, teniendo en cuenta que el token de sesión lo hemos de poner en el campo Extra con la propiedad {"aws_session_token":"<token de sesión>"}:
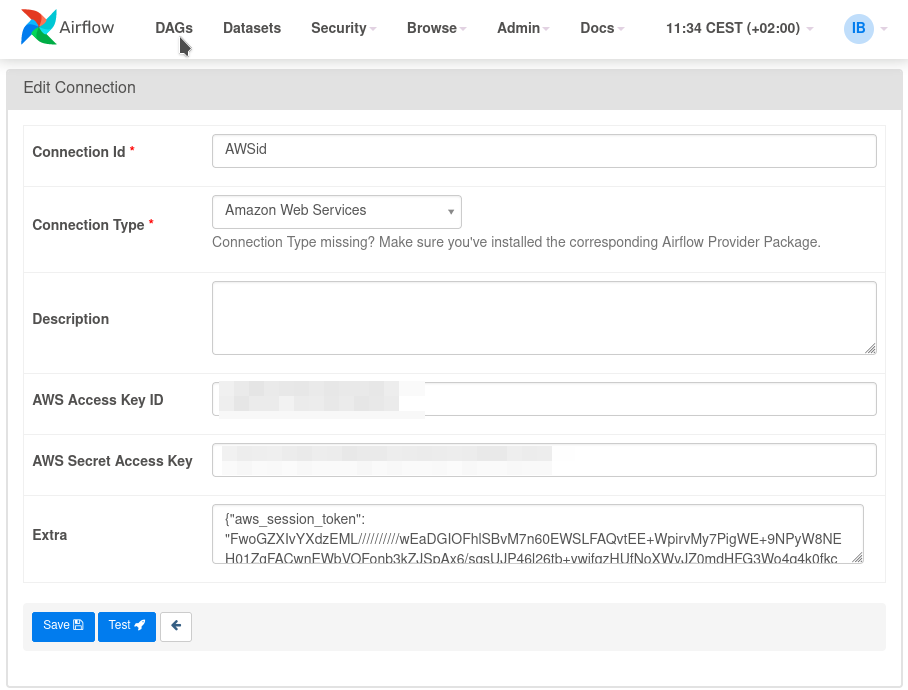
Y a continuación la usamos:
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
def envioS3Hook():
s3_hook = S3Hook(aws_conn_id='AWSid')
s3_hook.load_file(
filename='/tmp/customers.parquet',
key='customers.parquet',
bucket_name='iabd-s8a',
replace=True
)
Como hemos renombrado las funciones, cambiamos el callable de cada operador:
with DAG('dag-mariadb-s3',
default_args=default_args,
schedule_interval=timedelta(minutes=5),
) as dag:
recuperaDatos = PythonOperator(task_id='QueryMariaDB',
python_callable=consultaMariaDBHook)
persisteDatos = PythonOperator(task_id='PersistDataS3',
python_callable=envioS3Hook)
Utilizando variables¶
Cuando definimos las propiedades del DAG, podemos definir variables a las cuales podemos acceder desde todos los operadores y evitar duplicar código.
Por ejemplo, en vez de indicar que los datos se persistan y carguen desde /tmp/customers.parquet podemos definir una variable y luego acceder a ella desde los operadores.
El primer paso es definir la variable en Admin ⇨ Variables:
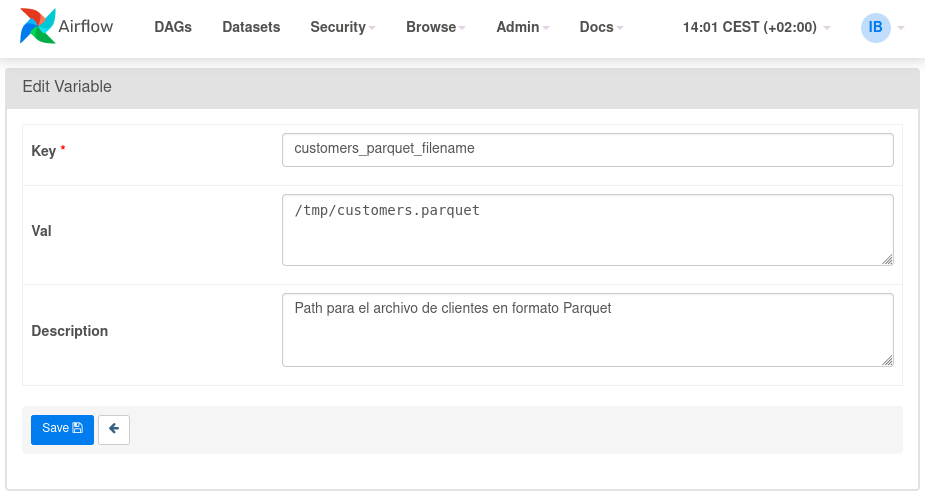
A continuación, modificamos nuestro DAG para acceder a la variable utilizando Variable.get():
from airflow.models import Variable
def consultaMariaDBHookVar():
mysql_hook = MySqlHook(mysql_conn_id='MySQLid')
conn = mysql_hook.get_conn()
df = pd.read_sql("select customer_fname, customer_lname, customer_zipcode from customers", conn)
df.to_parquet(Variable.get("customers_parquet_filename"))
print("-------Datos creados------")
Utilizando parámetros¶
Si no queremos definir variable a nivel de Airflow, podemos definir parámetros a nivel de DAG. De esta manera, acotamos el alcance del valor.
Podemos definir parámetros tanto a nivel de DAG como de tarea mediante la propiedad params con un valor o como un diccionario, y posteriormente, podemos acceder mediante plantillas o través del contexto:
with DAG('dag-mariadb-s3-param',
default_args=default_args,
schedule_interval=timedelta(minutes=5),
params={"customers_parquet_filename_param": "/tmp/customers.parquet"},
) as dag:
recuperaDatos = PythonOperator(task_id='QueryMariaDB',
python_callable=consultaMariaDBHookParam)
def consultaMariaDBHookParam(**context):
mysql_hook = MySqlHook(mysql_conn_id='MySQLid')
conn = mysql_hook.get_conn()
df = pd.read_sql("select customer_fname, customer_lname, customer_zipcode from customers", conn)
df.to_parquet(context["params"]["customers_parquet_filename_param"])
print("-------Datos creados------")
Uso de XCOM¶
Vamos a suponer que la primera tarea define el nombre con el que almacenar el archivo en S3. Para ello, necesitamos que se pasen datos de una tarea a otra. Como ya habíamos comentado, hemos de emplear XCOM.
Para ello, necesitamos pasar una instancia de tareas (task instance) como parámetro a la función llamándola ti y luego utilizar xcom_push para guardar una clave/valor:
def consultaMariaDBHookXCom(ti):
mysql_hook = MySqlHook(mysql_conn_id='MySQLid')
conn = mysql_hook.get_conn()
df = pd.read_sql("select customer_fname, customer_lname, customer_zipcode from customers", conn)
filename = '/tmp/customers.parquet'
ti.xcom_push(key='filename', value=filename)
df.to_parquet(filename)
print("-------Datos creados------")
Del mismo modo, en el segundo operador, volvemos a definir ti como parámetro de la función y recuperamos el valor mediante xcom_pull:
def envioS3HookXCom(ti):
s3_hook = S3Hook(aws_conn_id='AWSid')
s3_hook.load_file(
filename=ti.xcom_pull(key='filename', task_ids=['QueryMariaDB']),
key='customers.parquet',
bucket_name='iabd-s8a',
replace=True
)
Devolviendo valores
Si nuestras funciones de Python hacen un return de un valor, realmente está almacenándolo en un XCom cuya clave es return_value.
Todo en uno¶
Ya existen proveedores que directamente transfieren información desde una fuente SQL y la almacenan en S3.
Por ejemplo, con el proveedor que ya hemos instalado previamente, podemos utilizar el operador SqlToS3Operator el cual nos ahorra mucho código:
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
sql2s3_task = SqlToS3Operator(
task_id="sql_to_s3_task",
sql_conn_id='MariaDBid',
aws_conn_id='AWSid'
query='select customer_fname, customer_lname, customer_zipcode from customers',
s3_bucket='iabd-s8a',
s3_key='customers.parquet',
replace=True,
)
Referencias¶
- Documentación oficial de Apache Airflow
- Data Pipeline Tools: Airflow, Beam, Oozie, Azkaban, and Luigi
- Data Pipelines with Apache Airflow, de Julian de Ruiter y Bas Harenslak
- Webinar Introduction to Apache Airflow
Actividades¶
- (RA5075.2 / CE5.2c / 1p) Realiza el caso de uso 1 y prueba el DAG tanto a nivel de interfaz web como mediante el CLI, y copia el código fuente y añade comentarios al código.
Si quieres probar, en vez de realizar los ejecicios guiados 2 y 3, puedes realizar la actividad 4 que conlleva más investigación:
- (RA5075.4 / CE5.4a y CE5.4d / 0.5p) Realiza el caso de uso 2, añadiendo comentarios al código y ejecútalo únicamente desde el interfaz web.
- (RA5075.4 / CE5.4a y CE5.4e / 1.5p) Realiza el caso de uso 3, añadiendo comentarios al código y ejecútalo desde el CLI y comprueba su estado desde el interfaz web.
- (RA5075.4 / CE5.4a, CE5.4d y CE5.4e / 2p) Realiza el caso de uso 7 de la sesión de Nifi donde leemos datos de AEMET y terminamos guardando los datos en S3.
Para la siguiente actividad, copia el siguiente fragmento de código.
-
(RA5074.1 / CE4.1e / 1p) Explica que realiza el siguiente DAG y añade comentarios explicando qué hace cada fragmento, destacando para qué utiliza XCom:
from airflow import DAG from airflow.operators.bash import BashOperator from airflow.operators.python import PythonOperator from random import uniform from datetime import datetime default_args = { 'start_date': datetime(2023, 5, 1) } def _training_model(ti): accuracy = uniform(0.1, 10.0) print(f'model\'s accuracy: {accuracy}') ti.xcom_push(key='model_accuracy', value=accuracy) def _choose_best_model(ti): print('choose best model') accuracies = ti.xcom_pull(key='model_accuracy', task_ids=['training_model_A', 'training_model_B', 'training_model_C']) print(accuracies) with DAG('xcom_dag', schedule_interval='@daily', default_args=default_args, catchup=False) as dag: downloading_data = BashOperator( task_id='downloading_data', bash_command='sleep 3', do_xcom_push=False ) training_model_task = [ PythonOperator( task_id=f'training_model_{task}', python_callable=_training_model ) for task in ['A', 'B', 'C']] choose_model = PythonOperator( task_id='choose_model', python_callable=_choose_best_model ) downloading_data >> training_model_task >> choose_model