AWS Athena¶
Apuntes sin actualizar
Estos apuntes pertenecen al curso 22/23 y, por lo tanto, ya no se actualizan.
Puedes acceder a la última versión de esta sesión en https://aitor-medrano.github.io/iabd/cloud/athena.html.
Athena es una herramienta serverless que permite realizar consultas sobre datos los cuales están directamente en S3 y que provienen de fuentes dispares como bases de datos, un flujo de datos, contenido web desestructurado, etc.. Athena almacena metadatos sobre las fuentes de datos, así como las consultas para poder reutilizarlas o compartirlas con otros usuarios.
En el siguiente supuesto, vamos a crear una aplicación Athena, definiremos una base de datos, crearemos una tabla con sus columnas y tipos de datos, y ejecutaremos consultas sencillas y compuestas.
Los pasos a realizar son:
- Seleccionar el data set, identificando en S3 donde están los datos. Athena permite consultar los datos CSV, TSV, JSON, Parquet y formato ORC.
- Crear la tabla, mediante el asistente de crear tabla o utilizamos la sintaxis DDL de Hive.
- Consultar los datos, mediante SQL.
Preparando Athena¶
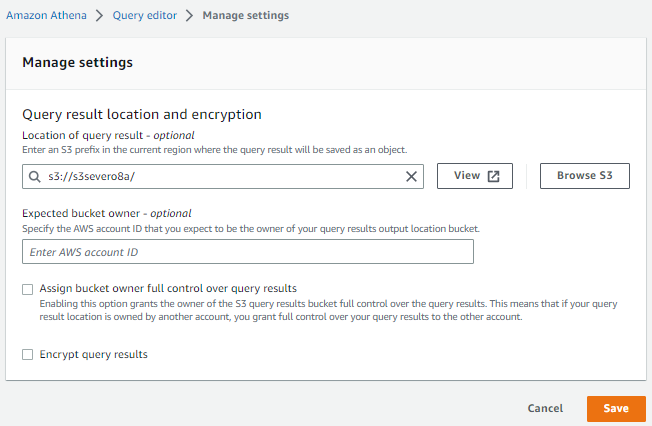
Antes de empezar con Athena, necesitamos indicar un bucket donde almacenar los resultados de nuestras consultas. Así pues, vamos a utilizar uno de los buckets que hemos creado en sesiones anteriores.
Tras acceder a Athena, en la pestaña de Settings del Query Editor, configuramos donde vamos a guardar los resultados:
Preparando los datos
Los datos que vamos a consultar son los datos de los clientes de la base de datos retail_db que hemos utilizando en la sesión de Hive, los cuales hemos exportado al archivo customers.csv.
Para poder leer estos datos, primero hemos de colocarlos en S3. En nuestro caso, hemos decidido crear una carpeta llamada customers dentro del bucket s3severo8a, y dentro de ella, hemos dejado el archivo con los datos:

Creando la estructura¶
En AWS Glue, o directamente en Athena, vamos a crear una base de datos y una tabla de forma similar a como se hace mediante Hive.
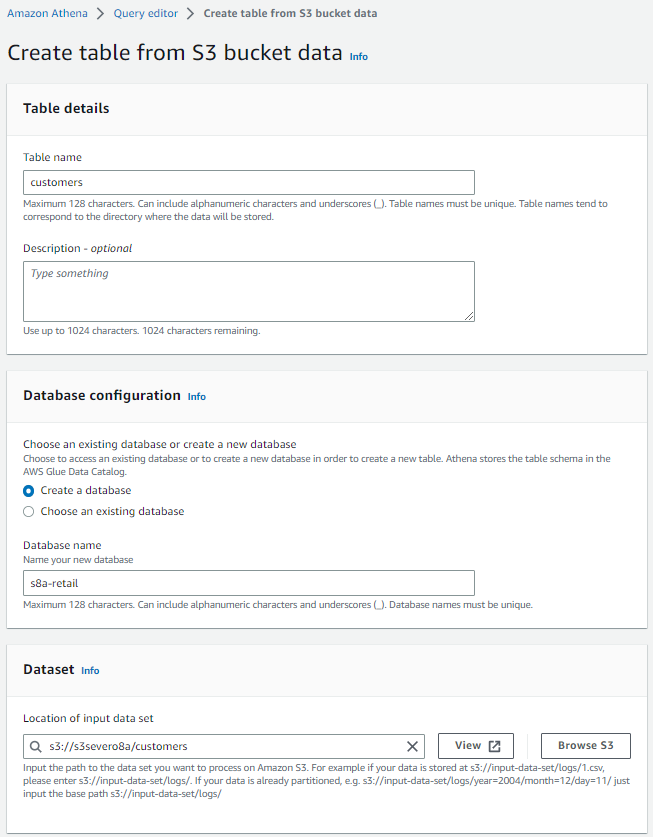
A continuación, entramos al Query editor, y a lado de la sección Tables and views, desplegamos el menú Create y creamos una tabla a partir de datos S3, indicándole un nombre para la tabla, otro para la base de datos (o elegimos una existente), así como la localización en S3 de la carpeta donde se encuentren nuestros datos:
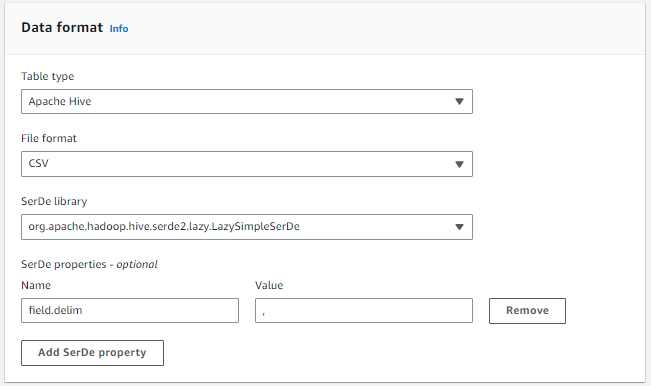
A continuación, le indicamos que vamos a cargar los datos en una tabla de tipo Hive en formato CSV, utilizando la coma como separador de campos:
Una vez tenemos el formato, debemos indicar la estructura de la tabla.
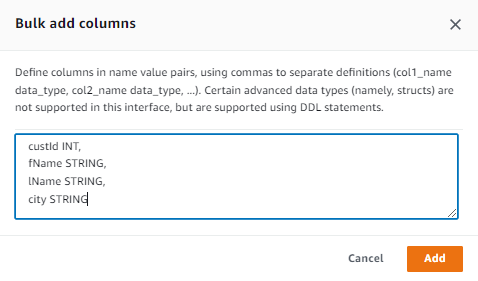
Para ello, podemos añadir cada columna de una en una, indicando su nombre y su tipo, o mediante la opción Bulk add columns, y le pegamos el nombre y el tipo de las columnas, que en nuestro caso son:
custId INT,
fName STRING,
lName STRING,
city STRING
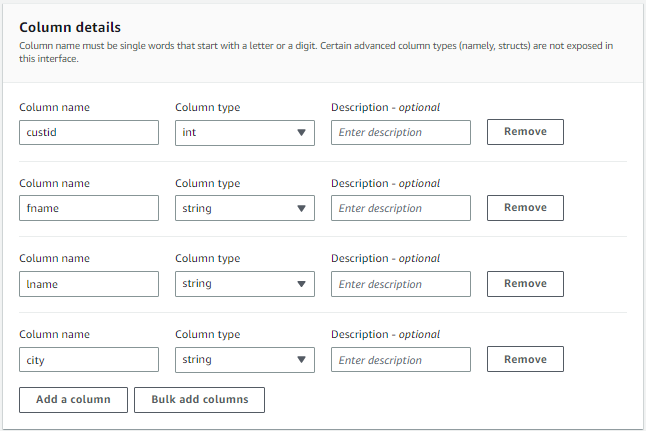
Cuando los hayamos introducido, veremos como se han creado dichas columnas:
Finalmente, veremos a modo de resumen una instrucción create table similar a la siguiente y ya podemos pulsar sobre Create table:
CREATE EXTERNAL TABLE IF NOT EXISTS `s8a-retail`.`customers` (
`custid` int,
`fname` string,
`lname` string,
`city` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://s3severo8a/customers/'
TBLPROPERTIES ('classification' = 'csv');
Realizando consultas¶
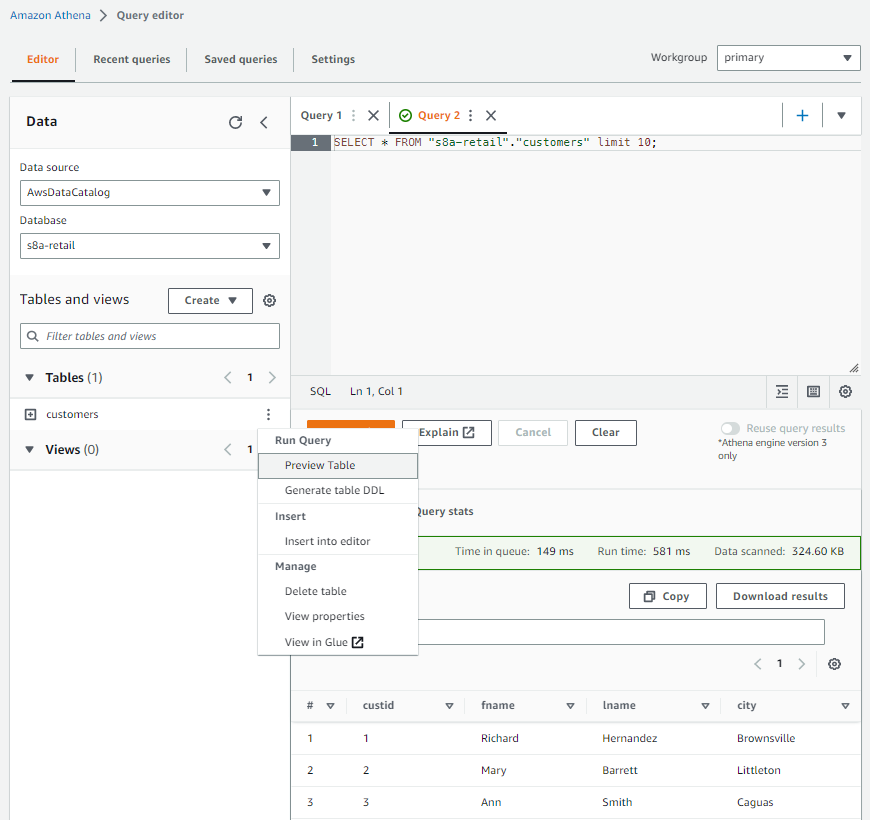
Si volvemos a la pantalla de Query Editor, si pinchamos sobre los tres puntos de la tabla customers, podemos hacer un preview de la tabla, y veremos que automáticamente realiza una consulta de tipo select * from customers