Athena
AWS Athena es una herramienta serverless que permite realizar consultas SQL sobre datos que están directamente en S3 y que provienen de fuentes dispares como bases de datos, un flujo de datos, contenido web desestructurado, etc... Para ello, Athena almacena metadatos sobre las fuentes de datos, así como las consultas, para poder reutilizarlas o compartirlas con otros usuarios.
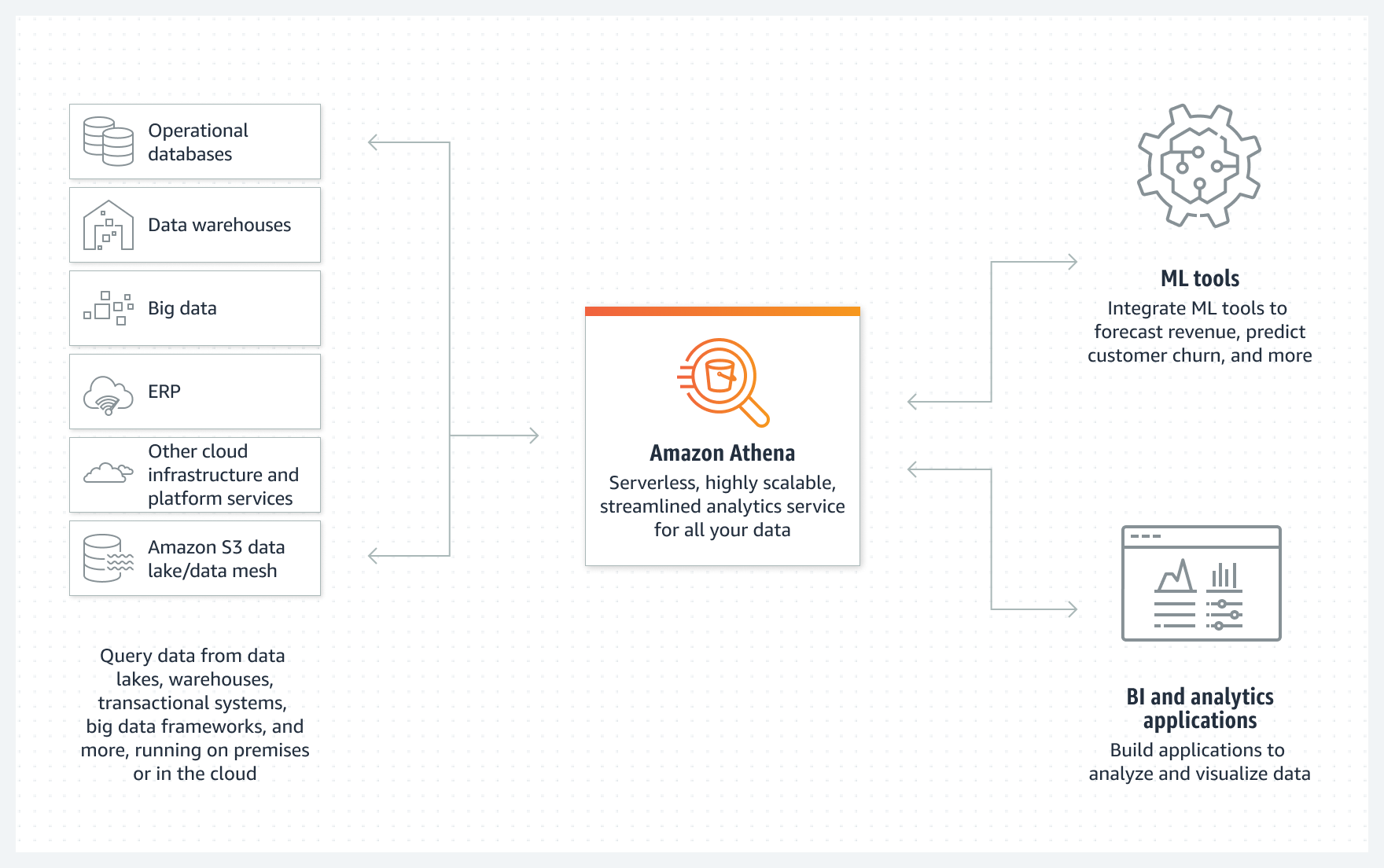
Como servicio serverless, no hay infraestructura que aprovisionar ni gestionar, y sólo pagaremos por el volumen de datos escaneados por las consultas que ejecutemos (actualmente su precio es de 5$ por TB escaneado), sin tener que preocuparnos por escalar o redimensionar los recursos necesarios, lo que implica que sea un servicio de consultas que facilita analizar petabytes de datos almacenados en S3 sin necesidad de un data warehouse o un clúster de máquinas que gestionar.
Athena escala las consultas automáticamente para ejecutarse en paralelo y obtener el resultado lo más rápido posible, incluso con grandes conjuntos de datos y consultas complejas. Conviene destacar que permite procesar datos desestructurados, semiestructurados o estructurados, soportando formatos de datos como CSV, JSON, Avro o formatos columnares como Parquet u ORC, tanto en crudo como comprimidos.
Consejos económicos
Al tratarse de un servicio de pago por uso, es importante tener en cuenta una serie de consejos para optimizar el coste de las consultas:
- Usar formato columnar (Parquet/ORC) en vez de CSV
- Usar compresión de los datos (por ejemplo, Snappy para Parquet)
- Particionar los datos
- Usar
SELECT col1, col2en vez deSELECT *
Presto¶
Para interactuar con los datos, Athena se basa en Presto (https://prestodb.io/), un motor distribuido de SQL creado por Facebook y liberado como proyecto open source. Tiene soporte para ANSI SQL, así como características propias de Presto como funciones geoespaciales o extensiones de consultas que permiten crear consultas mediante aproximación que estadísticamente casi son similares sobre grandes conjuntos de datos en solo una fracción de tiempo de lo que supondría una consulta real.
Además de realizar consultas, podemos utilizar sentencias de tipo DML para manipular datos y DDL para interactuar con los metadatos del lago de datos y modificar los esquemas y propiedades de las tablas, así como modificar sus particiones.
Dentro de DML, es muy común utilizar sentencias create-table-as-select (CTAS) para crear nuevas tablas así como insert into ... select para añadir nuevas particiones al metastore, eliminando la necesidad de gestionar las particiones de forma manual.
Respecto al dialecto SQL, igual que hemos visto en Hive, disponemos de tipos complejos como los mapas, las estructuras y los arrays/listas.
AWS Athena Federated Query
Athena también permite realizar consultas federadas a otras fuentes de datos, como bases de datos relacionales, NoSQL o incluso logs. Para ello, Athena se basa en el concepto de connectors, los cuales son componentes que permiten conectar con otras fuentes de datos y traducir las consultas SQL a la sintaxis específica de cada fuente. AWS proporciona una serie de connectors preconstruidos para conectar con servicios como DynamoDB, RDS o CloudWatch Logs, aunque también es posible crear nuestros propios connectors personalizados.
MetaStore¶
Además de acceder a los datos, Athena necesita almacenar metadatos para que el motor SQL entienda como interpretar los datos almacenados en S3 o cualquier otro lugar. Esta información extra mapea las colecciones de ficheros u objetos S3 para construir tablas, columnas y filas, de forma similar a cómo lo realiza el metastore de Hive. Es decir, ofrece una vista lógica (bases de datos que contienen tablas, que consisten en filas con sus columnas) que se mapean con los ficheros físicos almacenados en S3.
Por ello, Athena trabaja con metastores compatibles con Hive incluyendo el servicio de AWS Glue Data Catalog.
Los elementos que se almacenan son:
- Una lista de las tablas existentes
- La ruta de almacenamiento de cada tabla, ya sea la ruta en S3 o en nombre de la tabla de DynamoDB.
- El formato de los ficheros u objetos que contiene la tabla (por ejemplo, CSV, Parquet o JSON)
- El nombre de las columnas y los tipos de datos de cada tabla (por ejemplo, nombre es una cadena mientras que sueldo es un decimal (10,2))
SerDe¶
Un SerDe (Serializer/Deserializer) es el componente que indica a Athena cómo leer e interpretar los datos almacenados en S3. Cuando Athena escanea un archivo, necesita saber cómo convertir los bytes del fichero en filas y columnas con las que pueda trabajar el motor SQL. Para ello, en la definición de la tabla, se especifica un SerDe que se encarga de esta tarea., mediante la cláusula ROW FORMAT SERDE.
Los dos más habituales son:
-
LazySimpleSerDees el SerDe por defecto para ficheros de texto plano. Interpreta los campos separados por un delimitador simple (coma, tabulador, pipe...) y es adecuado cuando los valores no contienen el carácter delimitador ni están entrecomillados. Es el caso más habitual con CSVs sencillos.ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ('field.delim' = ',') -
OpenCSVSerdeestá diseñado para CSVs más complejos, donde los valores pueden estar entre comillas dobles y el propio texto puede contener comas o saltos de línea. Si los datos provienen de una exportación de base de datos o de una hoja de cálculo, es muy probable que necesites este SerDe.ROW FORMAT SERDE 'org.opensearch.hadoop.hive.OpenCSVSerde' WITH SERDEPROPERTIES ( 'separatorChar' = ',', 'quoteChar' = '"' )Como regla general, si al hacer un
SELECT, los valores aparecen con comillas en los resultados o que los campos se desplazan cuando un texto contiene comas, debemos cambiar deLazySimpleSerDeaOpenCSVSerde. -
JsonSerDees el SerDe adecuado cuando los ficheros almacenados en S3 contienen datos en formato JSON, con un objeto JSON por línea (JSONL). Es muy común cuando los datos provienen de logs de aplicaciones, eventos de IoT o exportaciones de APIs REST.ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'De este manera, podemos manejar de forma nativa tipos complejos como arrays, mapas y estructuras anidadas, mapeándolos directamente a los tipos equivalentes de Athena:
CREATE EXTERNAL TABLE eventos ( usuario_id INT, timestamp STRING, etiquetas ARRAY<STRING>, metadata MAP<STRING, STRING> ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' LOCATION 's3://mi-bucket/eventos/';Debemos tener en cuenta que si el JSON está mal formado o tiene campos que no coinciden exactamente con el esquema declarado,
JsonSerDedevuelveNULLpara esos campos en lugar de fallar, lo que puede dificultar la detección de errores en los datos.
Parquet / ORC
Para formatos binarios como Parquet u ORC no es necesario especificar un SerDe de texto, ya que Athena los gestiona directamente a través del INPUTFORMAT correspondiente.
Hola Athena¶
En el siguiente supuesto, vamos a crear una aplicación Athena, definiremos una base de datos, crearemos una tabla con sus columnas y tipos de datos, y ejecutaremos consultas sencillas y compuestas.
Los pasos a realizar son:
- Seleccionar el data set, identificando en S3 donde están los datos. Athena permite consultar los datos CSV, TSV, JSON, Parquet y formato ORC.
- Crear la tabla, mediante el asistente de crear tabla o utilizamos la sintaxis DDL de Hive.
- Consultar los datos, mediante SQL.
flowchart LR
subgraph Fuentes["📦 Fuentes de datos"]
A1[CSV / JSON]
A2[Parquet / ORC]
A3[Avro / TSV]
end
subgraph S3["☁️ Amazon S3"]
B1[("Bucket\ns3://s3severo8a-cli/customers/")]
B2[("Bucket resultados\ns3://s3severo8a-cli/athena-results/")]
end
subgraph Catalogo["🗂️ AWS Glue Data Catalog / MetaStore"]
C1["Base de datos\n(s8a_retail)"]
C2["Tabla\n(customers)"]
C3["Esquema\n(columnas + tipos)"]
C1 --> C2 --> C3
end
subgraph Athena["⚡ AWS Athena (Presto)"]
D1["Query Editor\nDDL / DML / SELECT"]
D2["Motor distribuido\n(ejecución paralela)"]
D1 --> D2
end
subgraph Cliente["💻 Cliente"]
E1[Consola AWS]
E2[AWS CLI]
E3[Python boto3 /\nawswrangler]
end
A1 & A2 & A3 -->|"subir archivos"| B1
B1 -->|"CREATE EXTERNAL TABLE\napunta a S3"| Catalogo
Catalogo -->|"metadatos\n(cómo leer los datos)"| D2
B1 -->|"escanea datos"| D2
E1 & E2 & E3 -->|"SQL query"| D1
D2 -->|"resultados CSV\n+ metadata"| B2
B2 -->|"descarga / lectura"| E1 & E2 & E3Preparando Athena¶
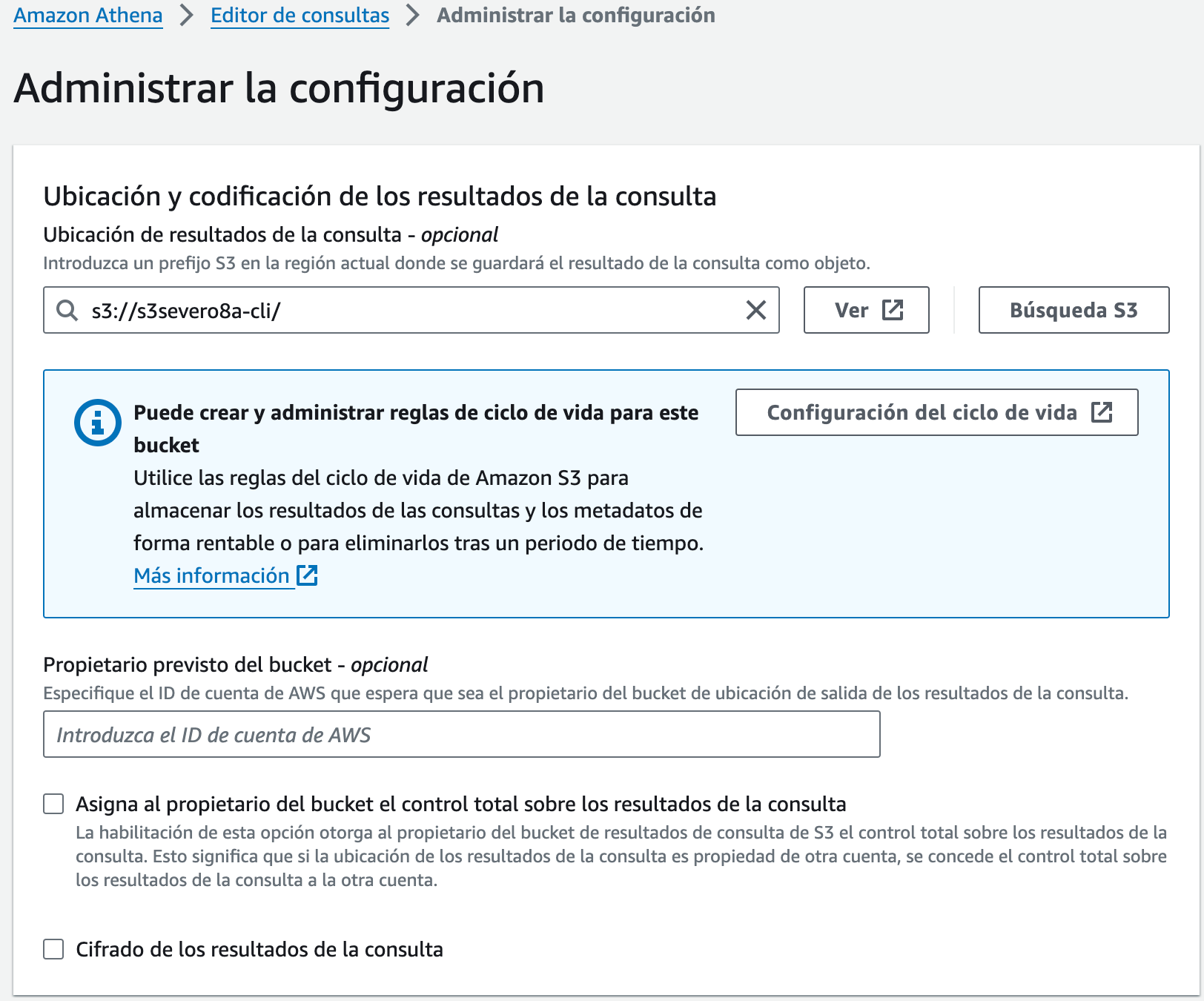
Antes de empezar con Athena, necesitamos indicar un bucket donde almacenar los resultados de nuestras consultas. Así pues, vamos a utilizar uno de los buckets que hemos creado en sesiones anteriores.
Tras acceder a Athena, en la pestaña de Settings del Query Editor, configuramos donde vamos a guardar los resultados:
Preparando los datos
Los datos que vamos a consultar son los datos de los clientes de la base de datos retail_db que hemos utilizado en la sesión de Hive, los cuales hemos exportado al archivo customers.csv.
Para poder leer estos datos, primero hemos de colocarlos en S3. En nuestro caso, hemos decidido crear una carpeta llamada customers dentro del bucket s3severo8a-cli, y dentro de ella, hemos dejado el archivo con los datos:

Creando la estructura¶
Tras cargar los datos, necesitamos crear la estructura de los datos en el Metastore.
En AWS Glue, o directamente en Athena, vamos a crear una base de datos y una tabla de forma similar a como se hace mediante Hive.
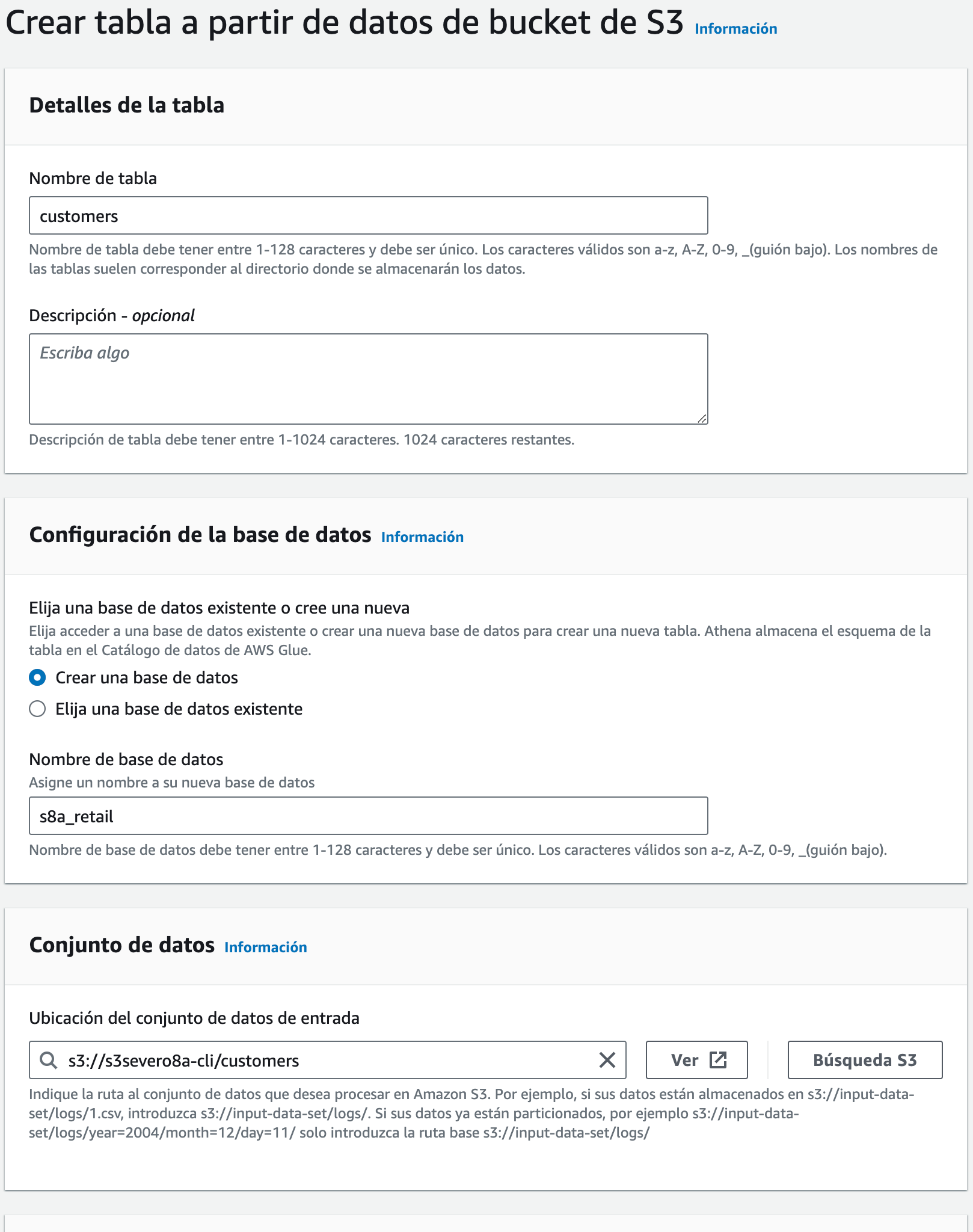
A continuación, entramos al Query editor, y a lado de la sección Tables and views, desplegamos el menú Create y creamos una tabla a partir de datos S3, indicándole un nombre para la tabla, otro para la base de datos (o elegimos una existente), así como la localización en S3 de la carpeta donde se encuentren nuestros datos:
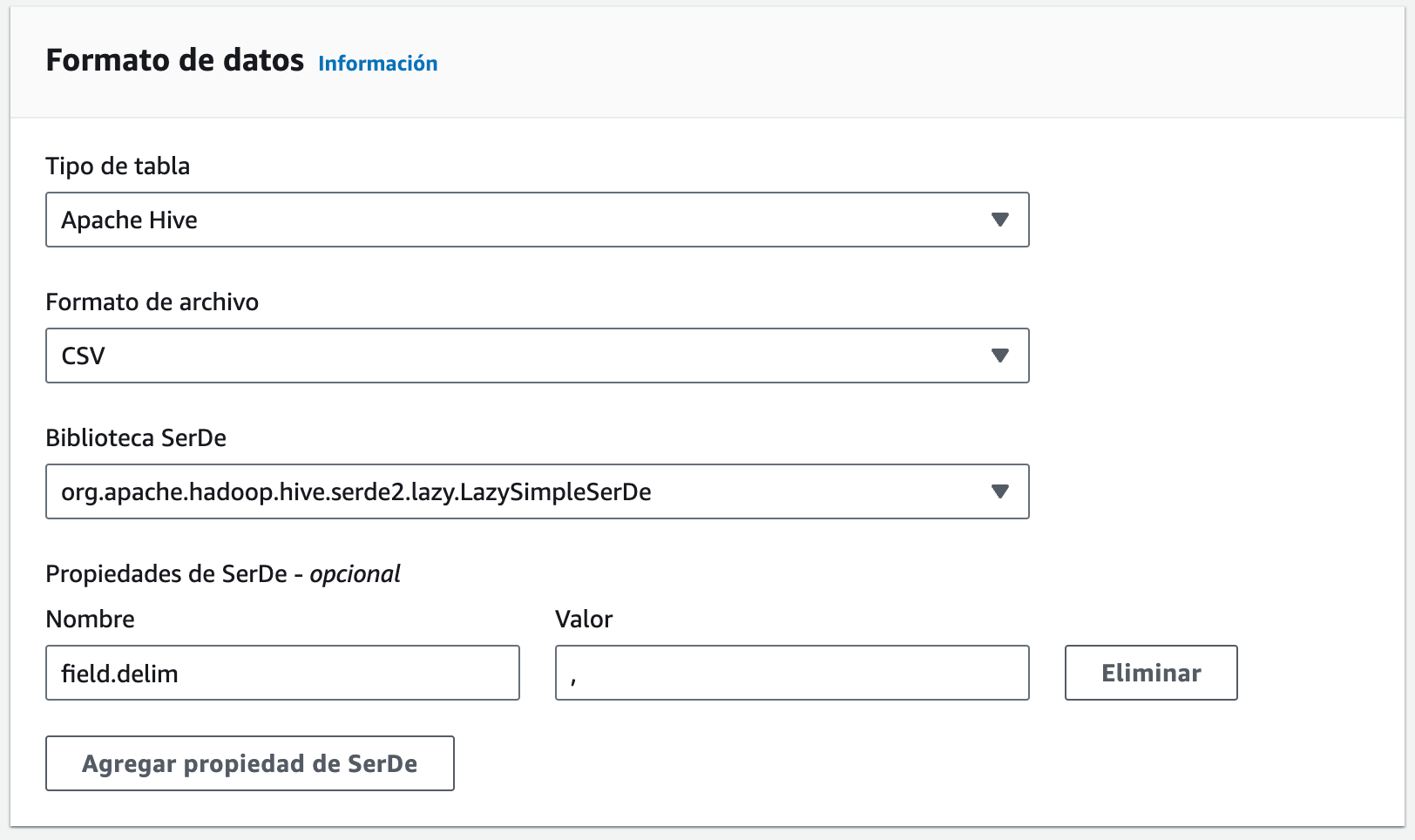
A continuación, le indicamos que vamos a cargar los datos en una tabla de tipo Hive en formato CSV, utilizando la coma como separador de campos:
Una vez tenemos el formato, debemos indicar la estructura de la tabla indicando qué columnas, con sus nombres y tipos de datos.
Para ello, podemos añadir cada columna de una en una, indicando su nombre y su tipo, o mediante la opción Agregar columnas en bloque, y le pegamos el nombre y el tipo de las columnas, que en nuestro caso son:
custId INT,
fName STRING,
lName STRING,
city STRING
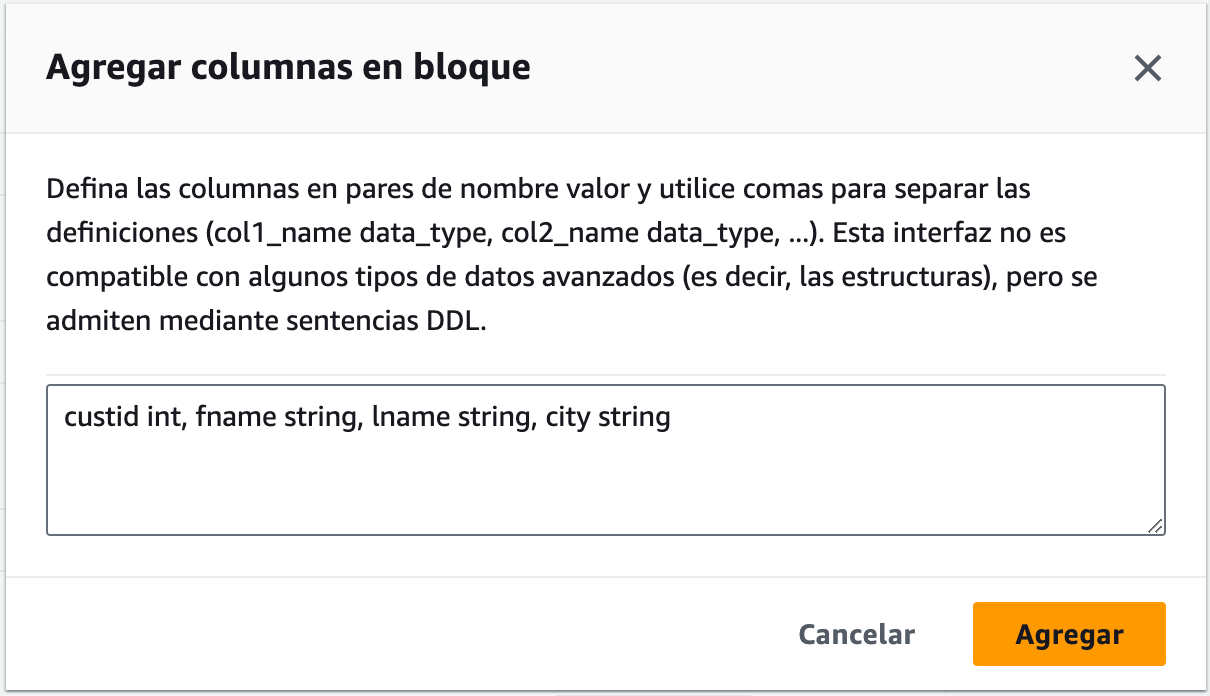
Cuando los hayamos introducido, veremos cómo se han creado dichas columnas:
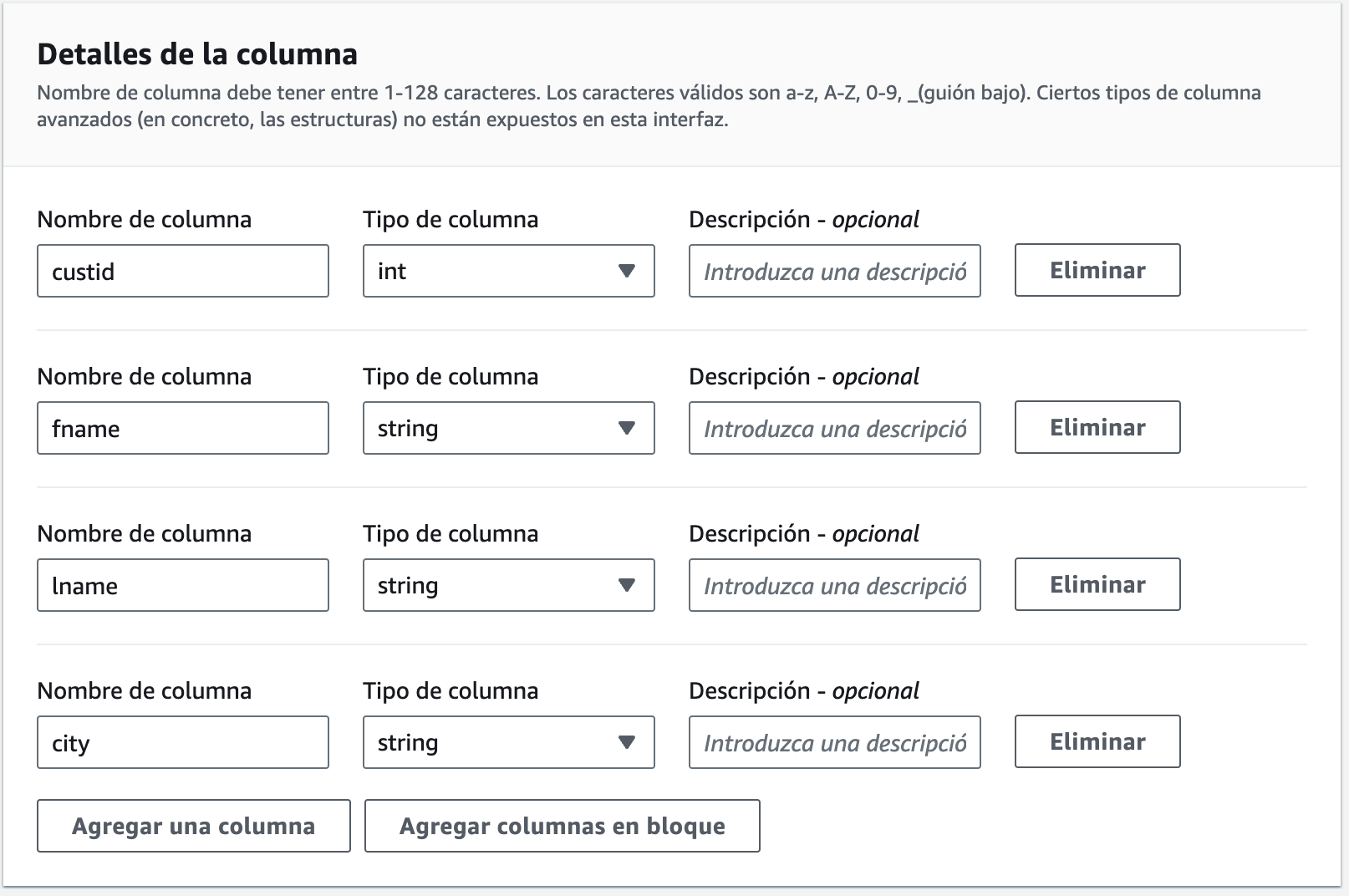
Finalmente, veremos a modo de resumen una instrucción CREATE TABLE similar a la siguiente y ya podemos pulsar sobre Crear tabla:
CREATE EXTERNAL TABLE IF NOT EXISTS `s8a_retail`.`customers` ( -- (1)!
`custid` int, -- (2)!
`fname` string,
`lname` string,
`city` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' -- (3)!
WITH SERDEPROPERTIES ('field.delim' = ',') -- (4)!
STORED AS
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' -- (5)!
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' -- (6)!
LOCATION 's3://s3severo8a-cli/customers/' -- (7)!
TBLPROPERTIES ('classification' = 'csv'); -- (8)!
EXTERNAL TABLE: Athena no gestiona los datos. Si borramos la tabla, los ficheros de S3 permanecen intactos.- Se definen nombre y tipo de dato. Los nombres en minúscula son la convención en Athena/Hive. Los tipos básicos disponibles son
int,string,double,boolean,timestamp, entre otros. ROW FORMAT SERDE: Indica cómo Athena interpreta los ficheros.LazySimpleSerDees el adecuado para CSVs sencillos donde los valores no contienen comas ni están entrecomillados. Para CSVs complejos usaríamosOpenCSVSerde.SERDEPROPERTIES: Propiedades del SerDe. Aquí indicamos que el separador de campos es la coma. Otros valores habituales:\tpara TSV o|para pipe-delimited.INPUTFORMAT: Define cómo se leen los ficheros.TextInputFormatlee ficheros de texto línea a línea, siendo el adecuado para CSV y JSON.OUTPUTFORMAT: Define cómo se escribirían los datos. Athena apenas lo utiliza al ser serverless, pero Hive lo requiere en el DDL.HiveIgnoreKeyTextOutputFormatescribe texto plano ignorando la clave interna de MapReduce.LOCATION: Ruta en S3 donde están los ficheros. Debe apuntar a una carpeta, no a un fichero concreto. Athena leerá todos los ficheros que haya dentro de esa ruta, incluidas subcarpetas.TBLPROPERTIES: Metadatos adicionales para el Glue Data Catalog.classificationindica el tipo de fichero.
¿Y si queremos crear la tabla con otro formato más óptimo para que las consultas sean más eficientes? Si no tenemos los datos almacenados en formato Parquet, podemos hacer uso de la sentencia CREATE TABLE ... AS SELECT:
CREATE TABLE IF NOT EXISTS s8a_retail.customers_parquet
WITH (
format = 'PARQUET',
parquet_compression = 'SNAPPY')
AS SELECT * FROM customers;
Realizando consultas¶
Si volvemos a la pantalla de Query Editor, al pinchar sobre los tres puntos de la tabla customers, podemos hacer un preview de la tabla, y veremos que automáticamente realiza una consulta de tipo select * from customers
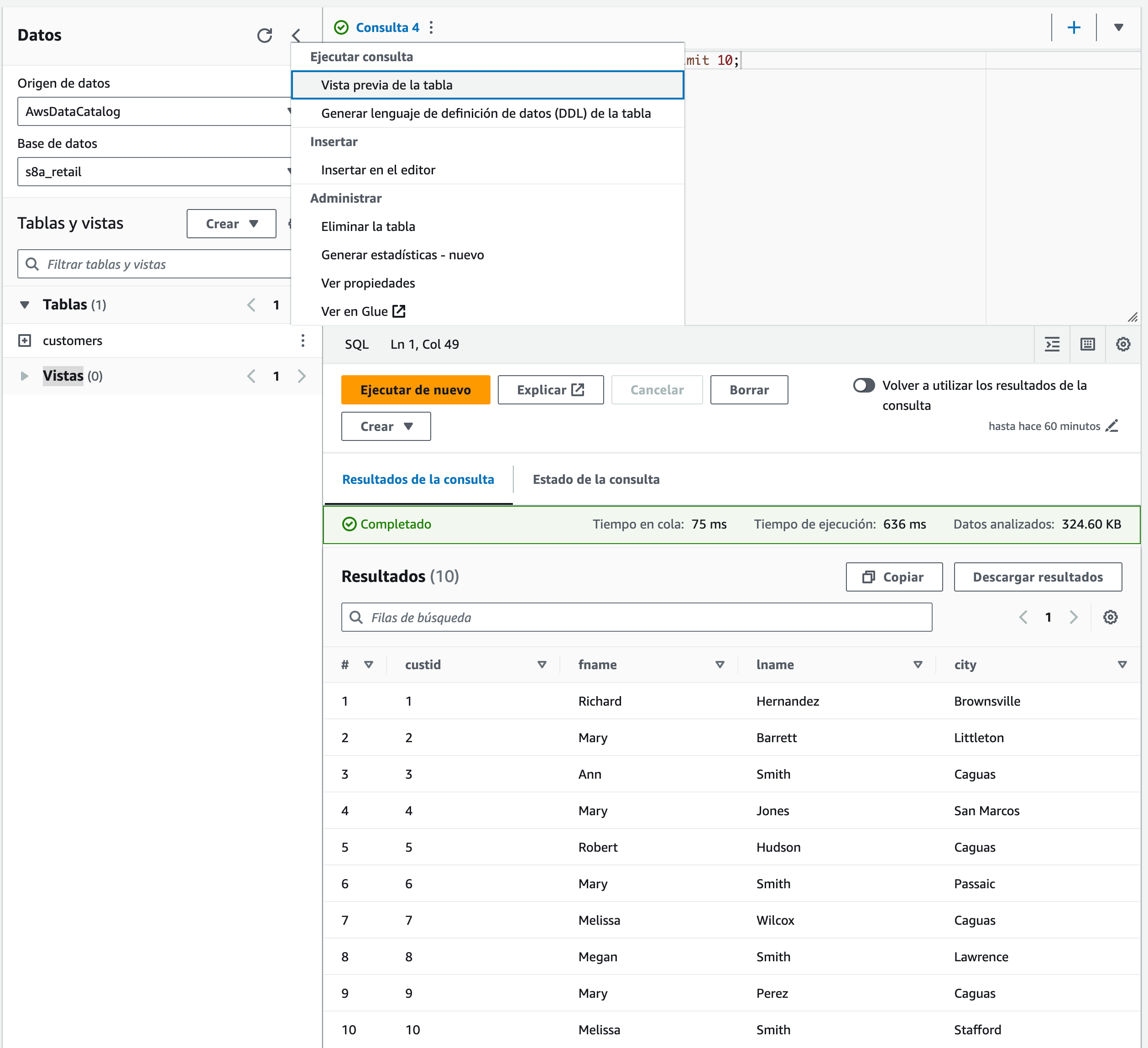
Consultas desde AWS CLI¶
Si queremos ejecutar una consulta mediante AWS CLI utilizaremos el parámetro athena start-query-execution indicando la consulta y donde almacenar el resultado:
aws athena start-query-execution \
--query-string "SELECT * FROM s8a_retail.customers_parquet WHERE city='Caguas' limit 10" \
--result-configuration "OutputLocation=s3://s3severo8a-cli/athena-results"
Que nos devolverá un identificador:
{
"QueryExecutionId": "f025b6cb-d262-4cce-a8fe-7e9d6ca73216"
}
A partir de dicho identificador, podemos averiguar el estado de la consulta mediante el parámetro get-query-results:
aws athena get-query-results --query-execution-id f025b6cb-d262-4cce-a8fe-7e9d6ca73216
Si la consulta ha fallado, recibiremos un mensaje similar a:
An error occurred (InvalidRequestException) when calling the GetQueryResults operation:
Query did not finish successfully. Final query state: FAILED
Si la consulta funciona correctamente, veríamos el resultado:
{
"ResultSet": {
"Rows": [
{
"Data": [
{ "VarCharValue": "custid" },
{ "VarCharValue": "fname" },
{ "VarCharValue": "lname" },
{ "VarCharValue": "city" }
]
},
{
"Data": [
{ "VarCharValue": "3" },
{ "VarCharValue": "Ann" },
{ "VarCharValue": "Smith" },
{ "VarCharValue": "Caguas" }
]
},
...
Finalmente, podemos comprobar la carpeta, donde crea un archivo con los datos y otro con los metadatos:
> aws s3 ls s3://s3severo8a-cli/athena-results/
2024-01-04 18:19:37 346 3206dcc2-ac48-4d7c-898c-92dea385dab3.csv
2024-01-04 18:19:37 197 3206dcc2-ac48-4d7c-898c-92dea385dab3.csv.metadata
Athena desde Python¶
Si queremos realizar consultas desde Python, de la misma forma que hemos trabajado con S3, necesitamos la librería boto3.
En este caso, usaremos el cliente de athena. Primero, vamos a definir una serie de funciones para interactuar con Athena. Hemos de destacar que la ejecución de Athena es asíncrona, y por tanto, al enviar una consulta, del mismo modo que hemos realizado mediante AWS CLI, obtendremos un identificador ( QueryExecutionId), el cual deberemos consultar posteriormente para comprobar si ya ha terminado ( QueryExecution.Status.State) la consulta y recuperar la información.
Así, la primera consulta es:
import boto3
import time
cliente_athena = boto3.client('athena')
def ejecutar_consulta_athena(consulta, basededatos, destino_salida):
response = cliente_athena.start_query_execution(
QueryString=consulta,
QueryExecutionContext={ 'Database': basededatos },
ResultConfiguration={ 'OutputLocation': destino_salida }
)
return response['QueryExecutionId']
def obtener_estado(query_execution_id):
response = cliente_athena.get_query_execution(
QueryExecutionId=query_execution_id
)
return response['QueryExecution']['Status']['State']
def obtener_resultado(query_execution_id):
response = cliente_athena.get_query_results(
QueryExecutionId=query_execution_id
)
# Process and print/query the results
for fila in response['ResultSet']['Rows']:
print([campo['VarCharValue'] for campo in fila['Data']])
Y con las funciones definidas, ejecutamos la consulta:
sql = "SELECT custId, fName, lName FROM customers_parquet WHERE city='Caguas' LIMIT 10;"
bd = "s8a_retail"
destino = "s3://s3severo8a-cli/athena-results/"
query_execution_id = ejecutar_consulta_athena(sql, bd, destino)
while obtener_estado(query_execution_id) == 'RUNNING' or obtener_estado(query_execution_id) == 'QUEUED':
print("La consulta se está ejecutando...")
time.sleep(3) # Esperamos unos segundos
if obtener_estado(query_execution_id) == 'SUCCEEDED':
print("!Consulta exitosa!")
obtener_resultado(query_execution_id)
else:
print("La consulta falló o ha sido cancelada")
Al ejecutar el script anterior obtendremos la siguiente salida:
La consulta se está ejecutando...
!Consulta exitosa!
['custid', 'fname', 'lname']
['3', 'Ann', 'Smith']
['5', 'Robert', 'Hudson']
['7', 'Melissa', 'Wilcox']
['9', 'Mary', 'Perez']
...
AWS Wrangler
Si nos salimos de la librería oficial boto3, podemos emplear la librería awswrangler que facilita el uso de AWS dotándole de la potencia y facilidad de Pandas.
Tras instalarla:
pip install awswrangler
podemos hacer una consulta a Athena de una forma más sencilla:
import awswrangler as wr
import pandas as pd
df = wr.athena.read_sql_query("SELECT * FROM customers", database="s8a_retail")
Más información en la documentación oficial.
Referencias¶
- Guía de usuario de AWS Athena
- Getting started with AWS Athena
- Libro Serverless Analytics with Amazon Athena
- Libro Data Engineering with AWS - Second Edition
Actividades¶
-
(RABDA.2 / CEBDA.2b, CEBDA.2d / 1p) Siguiendo el caso de uso de Hola Athena, tras cargar en S3 los datos de clientes y crear la tabla, se pide recuperar la cantidad de clientes que hay de cada ciudad. Sobre los resultados obtenidos, descarga los datos en formato CSV.
-
(RABDA.2 / CEBDA.2b, CEBDA.2d / 1p) A partir del archivo
orders.csvcrea también una tabla en Athena y recupera, para cada cliente (mostrando el id y su nombre completo) de la ciudadCaguas, cuantos pedidos ha realizado.Los campos del archivo csv son
order_id,order_date,order_customer_idyorder_status.Para ello, necesitarás utilizar el serializador
OpenCSVSerde, utilizando la coma como carácter separador, y las comillas dobles paraquoteChar. -
(RABDA.2 / CEBDA.2b / 2p) Tanto mediante AWS CLI como Python repite la consulta del ejercicio anterior y muestra el resultado por pantalla. Adjunto tanto los scripts de Python como los comandos de AWS CLI para cada consulta, junto a una captura de pantalla con el resultado obtenido.