Flume¶
Allá por el año 2010 Cloudera presentó Flume que posteriormente pasó a formar parte de Apache (https://flume.apache.org/) como un software para tratamiento e ingesta de datos masivo, facilitando crear desarrollos complejos que permiten el tratamiento de datos en streaming. Inicialmente se diseñó para recolectar ficheros de log de una granja de servidores web y mover los eventos almacenados en esos ficheros a HDFS para su posterior procesamiento.
Flume funciona como un buffer entre los productores de datos y el destino final. Al utilizar un buffer, evitamos que un productor sature a un consumidor, sin necesidad de preocuparnos de que algún destino esté inalcanzable o inoperable (por ejemplo, en el caso de que haya caído HDFS), etc...
Instalación
Aunque en la máquina virtual con la que trabajamos también tenemos instalado Flume, podemos descargar la última versión desde https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz.
A nivel de configuración sólo hemos definido la variable de entorno $FLUME_HOME que apunta a /opt/flume-1.11.0.
Algunas de sus características son:
- diseño flexible basado en flujos de datos de transmisión.
- resistente a fallos y robusto con múltiples conmutaciones por error y mecanismos de recuperación.
- lleva datos desde origen a destino: incluidos HDFS y HBase.
Arquitectura¶
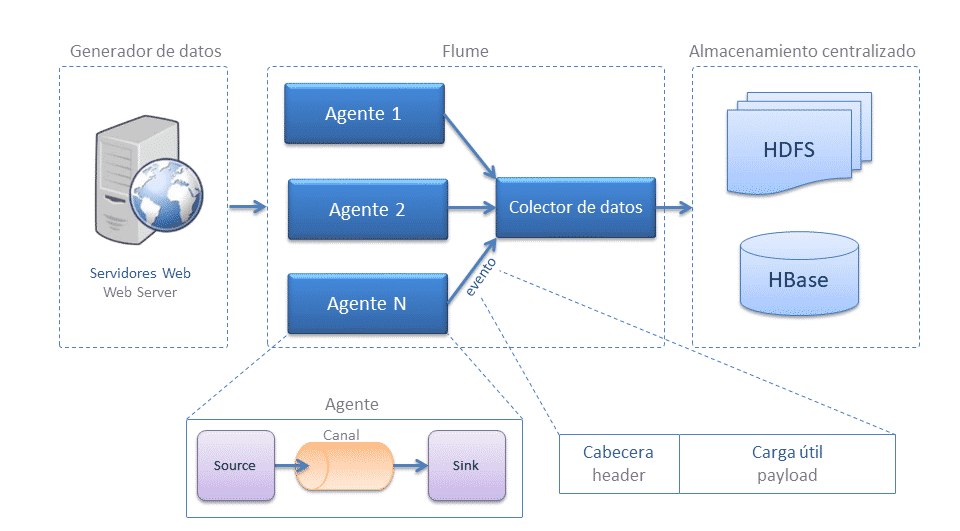
Su arquitectura es sencilla, y se basa en el uso de agentes que se dividen en tres componentes, los cuales podemos configurar:
- Source (fuente): Fuente de origen de los datos, ya sea Twitter, Kafka, una petición Http, etc...
Las fuentes son un componente activo que recibe datos desde otra aplicación que produce datos (aunque también existen fuentes que pueden producir datos por sí mismos, cuyo objetivo es poder probar ciertos flujos de datos). Las fuentes pueden escuchar uno o más puertos de red para recibir o leer datos del sistema de archivos. Cada fuente debe conectar con al menos un canal. Una fuente puede escribir en varios canales, replicando los eventos a todos o algunos canales en base a un determinado criterio que definamos. - Channel (canal): la vía por donde se tratarán los datos.
Un canal es un componente pasivo que almacena los datos como un buffer. Se comportan como colas, donde las fuentes publican y los sumideros consumen los datos. Múltiples fuentes pueden escribir de forma segura en el mismo canal y múltiples sumideros pueden leer desde el mismo canal. Sin embargo, cada sumidero sólo puede leer de un único canal. Si múltiples sumideros leen del mismo canal, sólo uno de ellos leerá el dato. - Sink (sumidero): persistencia/movimiento de los datos, a ficheros / base de datos.
Toma eventos del canal de manera continua leyendo y eliminando los eventos. A continuación, los transmite hacia el siguiente componente, ya sea a HDFS, Hive, etc... Una vez los datos han llegado al siguiente destino, el sumidero informa al canal mediante un commit transaccional para que elimine dichos eventos del canal.
Es muy recomendable acceder a la guía de usuario oficial para consultar todas las fuentes de datos, canales y sumideros disponibles en la actualidad. A continuación se nombran algunos de los más destacados:
| Sources | Channels | Sinks |
|---|---|---|
| Avro Source | Memory Channel | HDFS Sink |
| Thrift Source | JDBC Channel | Hive Sink |
| Exec Source | Kafka Channel | Logger Sink |
| JMS Source | File Channel | Avro Sink |
| Spooling Directory Source | Spillable Memory Channel | Thrift Sink |
| Twitter 1% firehose Source | Pseudo Transaction Channel | Kafka Sink |
| Kafka Source | File Roll Sink | |
| NetCat Source | Null Sink | |
| Sequence Generator Source | HBaseSink | |
| Syslog Sources | AsyncHBaseSink | |
| HTTP Source | MorphlineSolrSink | |
| Multiport Syslog TCP Source | ElasticSearchSink | |
| Syslog UDP Source | Kite Dataset Sink |
Una instalación de Flume consiste en una colección de agentes conectados los cuales se ejecutan en una arquitectura distribuida. Los agentes del borde del sistema (situados, por ejemplo, en los mismos servidores web que generan los datos) recogen los datos y los reenvían a los agentes responsables de agregar y ordenar los datos en el destino final.
Flume se complica cuando queremos utilizarlo para obtener datos de manera paralela (o multiplexada) y/o necesitamos crear nuestros propios sumideros o interceptores. Pero por lo general, su uso es sencillo y se trata de una herramienta muy recomendada como ayuda/alternativa a herramientas como Pentaho.
Agentes¶
Un agente es la unidad más sencilla con la que trabaja Flume, permitiendo conectar un agente Flume a uno o más agentes, encandenándolos. Además, un agente puede recibir datos de uno o más agentes. Conectando múltiples agentes entre sí podemos crear un flujo de datos para mover datos de un lugar a otro, de aplicaciones que producen datos a HDFS, HBase o donde necesitemos.
Para lanzar un tarea en Flume, debemos definir un agente, el cual funciona como un contenedor para alojar subcomponentes que permiten mover los datos.
Estos agentes tienen cuatro partes bien diferenciadas asociadas a la arquitectura de Flume. En la primera parte, definiremos los componente del agente (sources, channels y sinks), y luego, para cada uno de ellos, configuraremos sus propiedades:
sources: responsables de colocar los eventos/datos en el agentechannels: buffer que almacena los eventos/datos recibidos por los sources hasta que un sink lo saca para enviarlo al siguiente destino.sinks: responsable de sacar los eventos/datos del agente y reenviarlo al siguiente agente (HDFS, HBase, etc...)
Evento¶
El evento es la unidad más pequeña del procesamiento de eventos de Flume. Cuando Flume lee una fuente de datos, envuelve una fila de datos (es decir, encuentra los saltos de línea) en un evento.
Un evento es una estructura de datos que se compone de dos partes:
- Encabezado (header), se utiliza principalmente para registrar información mediante un mapa en forma de clave y valor. No transfieren datos, pero contienen información util para el enrutado y gestión de la prioridad o importancia de los mensajes.
- Cuerpo (payload): array de bytes que almacena los datos reales.
Probando Flume¶
Por ejemplo, vamos a crear un agente el cual llamaremos ExecLoggerAgent el cual va a ejecutar un comando y mostrará el resultado por el log de Flume, utilizando como canal la memoria.
Para ello, creamos la configuración del agente en el fichero agente.conf (todas las propiedades comenzarán con el nombre del agente):
# Nombramos los componentes del agente
ExecLoggerAgent.sources = Exec
ExecLoggerAgent.channels = MemChannel
ExecLoggerAgent.sinks = LoggerSink
# Describimos el tipo de origen
ExecLoggerAgent.sources.Exec.type = exec
ExecLoggerAgent.sources.Exec.command = ls /home/iabd/
# Describimos el destino
ExecLoggerAgent.sinks.LoggerSink.type = logger
# Describimos la configuración del canal
ExecLoggerAgent.channels.MemChannel.type = memory
ExecLoggerAgent.channels.MemChannel.capacity = 1000
ExecLoggerAgent.channels.MemChannel.transactionCapacity = 100
# Unimos el origen y el destino a través del canal
ExecLoggerAgent.sources.Exec.channels = MemChannel
ExecLoggerAgent.sinks.LoggerSink.channel = MemChannel
A continuación ya podemos lanzar Flume con el agente mediante el comando (la opción -n sirve para indicar el nombre del agente, y con -f indicamos el nombre del archivo de configuración):
flume-ng agent --name ExecLoggerAgent --conf ./conf/ --conf-file conf/agente.conf
Tras su ejecución, si consultamos el fichero flume.log que se encuentra en la carpeta de instalación de Flume (/opt/flume-1.11.0), podremos ver cómo ha creado primero el canal del agente MemChannel, así como la instancia de la fuente Exec y el sumidero LoggerSink y los conecta:
21 ene 2023 19:28:25,006 INFO [main] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:LoggerSink
21 ene 2023 19:28:25,014 INFO [main] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:MemChannel
...
21 ene 2023 19:28:25,041 INFO [main] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:154) - Creating channels
21 ene 2023 19:28:25,049 INFO [main] (org.apache.flume.channel.DefaultChannelFactory.create:42) - Creating instance of channel MemChannel type memory
21 ene 2023 19:28:25,054 INFO [main] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:208) - Created channel MemChannel
21 ene 2023 19:28:25,055 INFO [main] (org.apache.flume.source.DefaultSourceFactory.create:41) - Creating instance of source Exec, type exec
21 ene 2023 19:28:25,113 INFO [main] (org.apache.flume.sink.DefaultSinkFactory.create:42) - Creating instance of sink: LoggerSink, type: logger
21 ene 2023 19:28:25,127 INFO [main] (org.apache.flume.node.AbstractConfigurationProvider.getConfiguration:123) - Channel MemChannel connected to [Exec, LoggerSink]
A continuación, inicializa los componentes y los arranca:
21 ene 2023 19:28:25,128 INFO [main] (org.apache.flume.node.Application.initializeAllComponents:177) - Initializing components
21 ene 2023 19:28:25,173 INFO [main] (org.apache.flume.node.Application.startAllComponents:207) -
Starting new configuration:{
sourceRunners:{Exec=EventDrivenSourceRunner: { source:org.apache.flume.source.ExecSource{name:Exec,state:IDLE} }}
sinkRunners:{LoggerSink=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@4b7dc788 counterGroup:{ name:null counters:{} } }}
channels:{MemChannel=org.apache.flume.channel.MemoryChannel{name: MemChannel}} }
21 ene 2023 19:28:25,174 INFO [main] (org.apache.flume.node.Application.startAllComponents:214) - Starting Channel MemChannel
21 ene 2023 19:28:25,188 INFO [main] (org.apache.flume.node.Application.startAllComponents:229) - Waiting for channel: MemChannel to start. Sleeping for 500 ms
21 ene 2023 19:28:25,190 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) - Monitored counter group for type: CHANNEL, name: MemChannel: Successfully registered new MBean.
21 ene 2023 19:28:25,190 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) - Component type: CHANNEL, name: MemChannel started
21 ene 2023 19:28:25,692 INFO [main] (org.apache.flume.node.Application.startAllComponents:241) - Starting Sink LoggerSink
21 ene 2023 19:28:25,714 INFO [main] (org.apache.flume.node.Application.startAllComponents:252) - Starting Source Exec
Una vez arrancados, podemos ver cómo ha ejecutado el comando ls /home/iabd/ y mediante el LoggerSink, muestra cada uno de los archivos de la carpeta en un evento, donde podemos ver que tiene la cabecera vacía headers:{}, luego los datos en una representación en hexadecimal y por último el nombre del archivo/carpeta:
21 ene 2023 19:28:25,716 INFO [lifecycleSupervisor-1-2] (org.apache.flume.source.ExecSource.start:170) -
Exec source starting with command: ls /home/iabd/
21 ene 2023 19:28:25,722 INFO [lifecycleSupervisor-1-2] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) -
Monitored counter group for type: SOURCE, name: Exec: Successfully registered new MBean.
21 ene 2023 19:28:25,729 INFO [lifecycleSupervisor-1-2] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) -
Component type: SOURCE, name: Exec started
21 ene 2023 19:28:25,892 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 64 61 74 6F 73 datos }
21 ene 2023 19:28:25,893 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 44 65 73 63 61 72 67 61 73 Descargas }
21 ene 2023 19:28:25,893 INFO [pool-3-thread-1] (org.apache.flume.source.ExecSource$ExecRunnable.run:379) -
Command [ls /home/iabd/] exited with 0
21 ene 2023 19:28:25,900 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 44 65 73 6B 74 6F 70 Desktop }
21 ene 2023 19:28:25,905 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 44 6F 63 75 6D 65 6E 74 6F 73 Documentos }
21 ene 2023 19:28:25,906 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 66 6C 75 6D 65 flume }
21 ene 2023 19:28:25,908 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) -
Event: { headers:{} body: 49 6D C3 A1 67 65 6E 65 73 Im..genes }
...
Configurando un agente¶
Si te has fijado en el ejemplo anterior, los ficheros de configuración de los agentes siguen el mismo formato. Para definir un flujo dentro de un agente, necesitamos enlazar las fuentes y los sumideros con un canal. Para ello, listaremos las fuentes, sumideros y canales del agente, y entonces apuntaremos la fuente y el sumidero a un canal.
Así pues, el formato será similar al siguiente archivo:
# Listamos las fuentes, sumideros y canales
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# Configuramos los canales de la fuente
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# Configuramos el canal para el sumidero
<Agent>.sinks.<Sink>.channel = <Channel1>
channel y channels
Destacar que una fuente tiene una propiedad channels(en plural), pero un sumidero tiene la propiedad channel (en singular). Esto se debe a que una fuente puede alimentar más de un canal (fan out), pero un sumidero sólo puede obtener datos de un único canal.
También es posible que un canal alimente a varios sumideros.
En resumen, siguen una relación 1 - N - 1, de manera que una fuente puede indicar múltiples canales, pero un sumidero sólo puede indicar un único canal.
Además de definir el flujo, es necesario configurar las propiedades de cada fuente, sumidero y canal. Para elo se sigue la misma nomenclatura donde fijamos el tipo de componente (mediante la propiedad type) y el resto de propiedades específicas de cada componente:
# Propiedades de las fuentes
<Agent>.sources.<Source>.<someProperty> = <someValue>
# Propiedades de los canales
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# Propiedades de los sumideros
<Agent>.sources.<Sink>.<someProperty> = <someValue>
Para cada tipo de fuente, canal y sumidero es recomendable revisar la documentación para validar todas las propiedades disponibles.
Caso 1a - Almacenando en HDFS¶
En este caso de uso vamos generar datos de forma secuencial y los vamos a ingestar en HDFS.
Una buena práctica es colocar los archivos de configuración dentro de $FLUME_HOME/conf. Así pues, vamos a crear el agente SeqGenAgent y almacenar la configuración en el fichero seqgen.conf:
# Nombramos a los componentes del agente
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describimos el tipo de origen
SeqGenAgent.sources.SeqSource.type = seq
# Describimos el destino
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://iabd-virtualbox:9000/user/iabd/flume/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = flume-caso1a-seqgen
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 1000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describimos la configuración del canal
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Unimos el origen y el destino a través del canal
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannel
Arrancamos Hadoop
Antes de lanzar el agente Flume, recuerda que debes arrancar tanto Hadoop como YARN, por ejemplo, mediante el comando start-all.sh.
Ejecutamos el siguiente comando desde $FLUME_HOME y a los pocos segundo lo paramos mediante CTRL + C para que detenga la generación de números, ya que si no seguirá generando archivos en HDFS:
./bin/flume-ng agent --conf ./conf/ --conf-file conf/seqgen.conf \
--name SeqGenAgent \
-Dflume.root.logger=INFO,console
Vaciando HDFS
Si queremos eliminar los ficheros generados en HDFS, recuerda que puedes realizar un borrado recursivo mediante el comando:
hdfs dfs -rm -r /user/iabd/flume
Si comprobamos por ejemplo el contenido de la carpeta (hdfs dfs -ls /user/iabd/flume/seqgen_data) veremos que se han generado múltiples archivos:
Found 10 items
-rw-r--r-- 1 iabd supergroup 1402 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740933
-rw-r--r-- 1 iabd supergroup 1368 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740934
-rw-r--r-- 1 iabd supergroup 1350 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740935
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740936
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740937
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740938
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740939
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740940
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740941
-rw-r--r-- 1 iabd supergroup 1280 2021-12-22 16:42 /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740942
Y si comprobamos el contenido del primero (hdfs dfs -cat /user/iabd/flume/seqgen_data/flume-caso1a-seqgen.1640187740933) veremos como contiene la secuencia generada:
0
1
2
3
...
Caso 1b - De Netcat a HDFS¶
Ahora vamos a crear otro ejemplo de generación de información, pero esta vez, en vez de utilizar la memoria del servidor como canal, vamos a utilizar el sistema de archivos. Además, para generar la información nos basamos en una fuente Netcat, en la cual debemos especificar un puerto de escucha. Mediante esta fuente, Flume quedará a la escucha en dicho puerto y recibirá cada línea introducida como un evento individual que transferirá al canal especificado.
En este caso, vamos a utilizar un canal de tipo fichero para hacer los eventos durables, de manera que si se cayese Flume a mitad de una operación, no se perderían los datos, y al volver a funcionar, el agente finalizará la ingesta.
En el mismo directorio $FLUME_HOME\conf, creamos un nuevo fichero con el nombre netcat.conf y creamos otro agente que se va a encargar de generar información:
# Nombramos a los componentes del agente
NetcatAgent.sources = Netcat
NetcatAgent.channels = FileChannel
NetcatAgent.sinks = HdfsSink
# Describimos el origen netcat en localhost:44444
NetcatAgent.sources.Netcat.type = netcat
NetcatAgent.sources.Netcat.bind = localhost
NetcatAgent.sources.Netcat.port = 44444
NetcatAgent.sources.Netcat.channels = FileChannel
# Describimos el destino en HDFS
NetcatAgent.sinks.HdfsSink.type = hdfs
NetcatAgent.sinks.HdfsSink.hdfs.path = hdfs://iabd-virtualbox:9000/user/iabd/flume/net_data/
NetcatAgent.sinks.HdfsSink.hdfs.writeFormat = Text
NetcatAgent.sinks.HdfsSink.hdfs.fileType = DataStream
NetcatAgent.sinks.HdfsSink.channel = FileChannel
# Unimos el origen y el destino a través del canal de fichero
NetcatAgent.channels.FileChannel.type = file
NetcatAgent.channels.FileChannel.dataDir = /home/iabd/flume/data
NetcatAgent.channels.FileChannel.checkpointDir = /home/iabd/flume/checkpoint
Eventos, ficheros y HDFS
Al trabajar con HDFS, el fichero se mantendrá abierto durante un tiempo (normalmente 30 segundos, lo podemos configurar mediante la propiedad hdfs.rollInterval), hasta que llegue a un determinado tamaño (por defecto 1024b, configurado hdfs.rollSize) o que haya escrito un determinado número de eventos (por defecto 10, configurado mediante hdfs.rollCount).
Mientras está abierto, se renombrará con el prefijo _ y el sufijo .tmp. Al finalizar alguno de los criterios, volverá a su nombre original y se cierra el fichero.
Los nuevos eventos se escribirán en un nuevo fichero.
Lanzamos al agente:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/netcat.conf \
--name NetcatAgent \
-Dflume.root.logger=INFO,console
En una nueva pestaña introducimos el siguiente comando y escribimos
curl telnet://localhost:44444
Una vez conectados, escribimos varias frases con saltos de línea. Por cada vez que pulsamos Enter, nos aparecerá un OK.
Probando Netcat
OK
Esto parece que funciona más o menos
OK
A continuación, nos vamos al navegador web de HDFS (http://iabd-virtualbox:9870/explorer.html#/user/iabd/flume/net_data) y comprobamos que se ha creado el fichero:
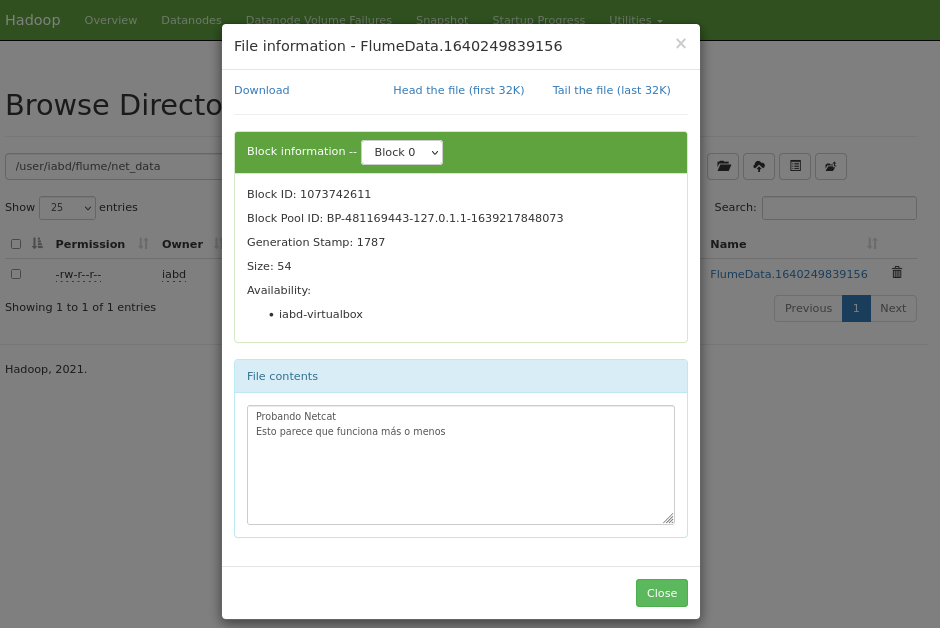
Caso 2 - Flujos encadenados¶
Es muy común definir un pipeline de flujos encadenados, uniendo la salida de un agente a la entrada de otro. Para ello, utilizaremos como enlace un sink-source de tipo Avro. Este diseño también se conoce como flujo Multi-hop:

En este caso, vamos a crear un primer agente (NetcatAvroAgent) que ingeste datos desde Netcat y los coloque en un sink de tipo Avro. Para ello, creamos el agente netcat-avro.conf:
# Nombramos a los componentes del agente
NetcatAvroAgent.sources = Netcat
NetcatAvroAgent.channels = FileChannel
NetcatAvroAgent.sinks = AvroSink
# Describimos el origen netcat en localhost:44444
NetcatAvroAgent.sources.Netcat.type = netcat
NetcatAvroAgent.sources.Netcat.bind = localhost
NetcatAvroAgent.sources.Netcat.port = 44444
# Describimos el destino como Avro en localhost:10003
NetcatAvroAgent.sinks.AvroSink.type = avro
NetcatAvroAgent.sinks.AvroSink.hostname = localhost
NetcatAvroAgent.sinks.AvroSink.port = 10003
# Unimos el origen y el destino a través del canal de fichero
NetcatAvroAgent.sources.Netcat.channels = FileChannel
NetcatAvroAgent.sinks.AvroSink.channel = FileChannel
NetcatAvroAgent.channels.FileChannel.type = file
NetcatAvroAgent.channels.FileChannel.dataDir = /home/iabd/flume/data
NetcatAvroAgent.channels.FileChannel.checkpointDir = /home/iabd/flume/checkpoint
A continuación, creamos un segundo agente (AvroHdfsAgent) que utilice como fuente Avro capturando los datos desde el mismo host y puerto que el sink anterior, y que almacene los eventos recibidos en HDFS. Para ello, creamos el agente avro-hdfs.conf:
# Nombramos a los componentes del agente
AvroHdfsAgent.sources = AvroSource
AvroHdfsAgent.channels = MemChannel
AvroHdfsAgent.sinks = HdfsSink
# Describimos el origen como Avro en localhost:10003
AvroHdfsAgent.sources.AvroSource.type = avro
AvroHdfsAgent.sources.AvroSource.bind = localhost
AvroHdfsAgent.sources.AvroSource.port = 10003
# Describimos el destino HDFS
AvroHdfsAgent.sinks.HdfsSink.type = hdfs
AvroHdfsAgent.sinks.HdfsSink.hdfs.path = /user/iabd/flume/avro_data/
AvroHdfsAgent.sinks.HdfsSink.hdfs.fileType = DataStream
AvroHdfsAgent.sinks.HdfsSink.hdfs.writeFormat = Text
# Unimos el origen y el destino
AvroHdfsAgent.sources.AvroSource.channels = MemChannel
AvroHdfsAgent.sinks.HdfsSink.channel = MemChannel
AvroHdfsAgent.channels.MemChannel.type = memory
Primero lanzamos este último agente, para que Flume quede a la espera de mensajes Avro en localhost:10003:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/avro-hdfs.conf \
--name AvroHdfsAgent \
-Dflume.root.logger=INFO,console
Una vez ha arrancado, en nueva pestaña, lanzamos el primer agente:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/netcat-avro.conf \
--name NetcatAvroAgent \
-Dflume.root.logger=INFO,console
Finalmente, en otro terminal, escribimos mensajes Netcat accediendo a curl telnet://localhost:44444. Si accedéis a la carpeta /user/iabd/flume/avro_data en HDFS podremos comprobar cómo se van creando archivos que agrupan los mensajes enviados.
Caso 3 - Flujo multi-agente¶
Para demostrar como varios agentes pueden conectarse entre sí, vamos a realizar un caso de uso donde leeremos información de tres fuentes distintas: una fuente de Netcat con un canal basado en ficheros, otra que realice spooling de una carpeta (vigila una carpeta y cuando haya algún archivo, lo ingesta y lo renombra añadiéndole el sufijo COMPLETED) utilizando un canal en memoria y un tercero que ejecute un comando utilizando también un canal en memoria.
Como agente de consolidación que una la información de las tres fuentes de datos, vamos a reutilizar el agente AvroHdfsAgent que hemos creado en el caso de uso anterior.
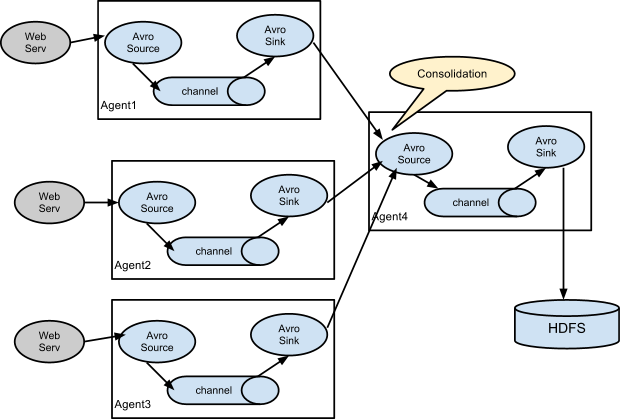
Para ello, vamos a definir los agentes en siguiente fichero de configuración multiagent-avro.conf):
# Nombramos las tres fuentes con sus tres sumideros
MultiAgent.sources = Netcat Spooldir Exec
MultiAgent.channels = FileChannel MemChannel1 MemChannel2
MultiAgent.sinks = AvroSink1 AvroSink2 AvroSink3
# Describimos el primer agente
MultiAgent.sources.Netcat.type = netcat
MultiAgent.sources.Netcat.bind = localhost
MultiAgent.sources.Netcat.port = 44444
# Describimos el segundo agente
MultiAgent.sources.Spooldir.type = spooldir
MultiAgent.sources.Spooldir.spoolDir = /home/iabd/flume/spoolDir
# Describimos el tercer agente
MultiAgent.sources.Exec.type = exec
MultiAgent.sources.Exec.command = cat /home/iabd/datos/empleados.txt
# Describimos los tres destinos como Avro en localhost:10003
MultiAgent.sinks.AvroSink1.type = avro
MultiAgent.sinks.AvroSink1.hostname = localhost
MultiAgent.sinks.AvroSink1.port = 10003
MultiAgent.sinks.AvroSink2.type = avro
MultiAgent.sinks.AvroSink2.hostname = localhost
MultiAgent.sinks.AvroSink2.port = 10003
MultiAgent.sinks.AvroSink3.type = avro
MultiAgent.sinks.AvroSink3.hostname = localhost
MultiAgent.sinks.AvroSink3.port = 10003
# Describimos los canales
MultiAgent.channels.FileChannel.type = file
MultiAgent.channels.FileChannel.dataDir = /home/iabd/flume/data
MultiAgent.channels.FileChannel.checkpointDir = /home/iabd/flume/checkpoint
MultiAgent.channels.MemChannel1.type = memory
MultiAgent.channels.MemChannel2.type = memory
# Unimos los orígenes y destinos
MultiAgent.sources.Netcat.channels = FileChannel
MultiAgent.sources.Spooldir.channels = MemChannel1
MultiAgent.sources.Exec.channels = MemChannel2
MultiAgent.sinks.AvroSink1.channel = FileChannel
MultiAgent.sinks.AvroSink2.channel = MemChannel1
MultiAgent.sinks.AvroSink3.channel = MemChannel2
Preparación
Antes de arrancar los agentes, asegúrate de tener creada la carpeta /home/iabd/flume/spoolDir y disponible el recurso /home/iabd/datos/empleados.txt.
Igual que en el caso de uso anterior, primero lanzamos el agente consolidador para que Flume quede a la espera de mensajes Avro en localhost:10003:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/avro-hdfs.conf \
--name AvroHdfsAgent \
-Dflume.root.logger=INFO,console
Una vez ha arrancado, en una nueva pestaña, lanzamos el multi agente:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/multiagent-avro.conf \
--name MultiAgent \
-Dflume.root.logger=INFO,console
Interceptores
Podemos utilizar interceptores para modificar o borrar eventos al vuelo a partir del timestamp, nombre del host, uuid, etc... incluso mediante el uso de una expresión regular. Si quieres profundizar en el tema, el siguiente artículo detalla los diferentes tipos y configuraciones: https://data-flair.training/blogs/flume-interceptors/
En este caso, para poder probarlo, además de enviar comandos Netstat en curl telnet://localhost:44444, prueba a colocar un archivo de texto (por ejemplo, un documento CSV) en /home/iabd/flume/spoolDir.
Referencias¶
- Página oficial de Flume
- Flume User Guide
Actividades¶
Realiza las siguientes actividades empleando Flume:
-
(RASBD.3 / CESBD.3a y CESBD.3b / 1 p) Realiza el caso de uso 1 (a y b), adjuntando capturas las fuentes y los destinos empleados. En el caso de Netcat, escribe alguna frase con tu nombre.
-
(RASBD.3 / CESBD.3a y CESBD.3b / 1 p) Realiza el caso de uso 2, adjuntando la misma información que en el ejercicio anterior, pero cambiando la frase.
-
(RASBD.3 / CESBD.3a y CESBD.3b / 2 p) Con la misma arquitectura de flujos que el caso 3, define un agente que simule la ingesta de datos de usuarios compuestos de
email;password;nombre;profesion, mediante los siguientes tres agentes:-
Ejecuta el siguiente script que genera datos sintéticos mediante la librería Faker.
flume-faker.pyfrom faker import Faker import csv, time fake = Faker('es_ES') # cambiamos el locale a español num = 1 # secuencia para los nombres de los ficheros while True: output = open(f'spool/datosFaker-{num}.csv', 'w') mywriter = csv.writer(output, delimiter=";") for r in range(100): mywriter.writerow([fake.free_email(), fake.password(), fake.name(), fake.job()]) output.close() num = num + 1 time.sleep(10) # espera 10 segundos y genera un nuevo archivo -
Realice un spooling sobre la carpeta donde se generan los datos sintéticos, teniendo en cuenta, que debes añadir la propiedad necesaria para que los archivos de la carpeta de spooling, en vez de renombrarse, se eliminen automáticamente una vez procesados.
- Permite la entrega de usuarios de forma individual mediante Netcat, de manera que tecleemos los datos de cada usuario separados por
;.
Una vez ejecutado el agente, comprueba que se van almacenando los datos de las diferentes fuentes en HDFS de forma dinámica.
-
Ejercicio no realizable
Hasta el año 2023, Twitter tenía soporte para su API v1.1 que es la que usa el Twitter Source. Desde entonces, la siguiente actividad ya no se puede realizar. Queda aquí escrita para el antiguo alumnado que tuvo la suerte de poder realizarla.
-
(RASBD.3 / CESBD.3a, CESBD.3b y CESBD.3c) Haciendo uso de Flume, recupera información de Twitter y almacénala en HDFS. Para ello, utiliza el Twitter 1% Firehouse source y el HDFS sink.
Para ello, necesitaréis las claves de desarrollo de Twitter. Adjunta una captura de pantalla donde se visualice el contenido de uno de los bloques de HDFS.
Cuidado con el espacio de almacenamiento
Una vez lances el agente, páralo a los tres segundos para no llenar de datos HDFS.
Cloudera tiene su propia librería para acceder a Twitter donde podemos configurar qué mensajes descargar. Puedes consultar un ejemplo completo aquí.