Delta Lake
Changelog:
- Cluster docker con Spark, MySQL, MinIO y Kafka — Mayo 2026
- Añadimos FAQ — Mayo 2026
En la sesión de Data Lakes ya estudiamos qué ofrece un Data lake y sus diferencias respecto a los Data warehouses, así como una pequeña introducción al concepto de Data lakehouse.
Delta Lake es un producto que ofrece transaccionalidad y soporte para upserts y merges en data lakes manteniendo una escalabilidad horizontal y ofreciendo la separación del almacenamiento y la computación que necesita el big data. Así pues, podemos considerar a Delta Lake como una implementación del concepto de data lakehouse, el cual combina lo mejor de los data warehouses y data lakes, ofreciendo transacciones ACID, gestión escalable de los metadatos, un modelo unificado para procesar datos tanto por lotes como en streaming, histórico auditable con viajes en el tiempo (time travel) y soporte para sentencias DML sobre los datos, los cuales pueden estar almacenados en formatos como Parquet.
Podemos ejecutarlo sobre data lakes ya existentes y es completamente compatible con varios motores de procesamiento como es el caso de Apache Spark, y de ahí, el motivo de estudiarlo en esta sesión.
Data Lakehouse por dentro
El almacenamiento de un data lakehouse se cede a servicios de almacenamiento de objetos, los cuales son muy económicos, como son Amazon S3 o Azure ADLs, almacenando los datos en formatos abiertos como Apache Parquet.
Sin embargo, para ser un data lakehouse, necesitamos soporte para transacciones ACID. Para ello, debemos tener una capa de metadatos transaccionales sobre el almacenamiento cloud, que defina qué objetos forman parte de qué versión de tabla.
Para conseguir un gran rendimiento en las consultas SQL es necesario ofrecer servicios de caché, estructuras de datos auxiliares como índices y estadísticas para poder optimizar la capa de datos.
La herramienta final es el desarrollo de un API estándar, como es la DataFrame API, la cual soportan herramientas como TensorFlow o Spark MLlib, la cual permite, de forma declarativa, la construcción de un grafo DAG con su ejecución.
Otros productos alternativos como implementación del concepto de data lakehouse son Apache Iceberg y Apache Hudi.
Formalmente, podemos decir que Delta Lake ofrece una capa de metadatos, caché e indexación sobre el almacenamiento de un data lake, de manera que ofrece un nivel de abstracción con soporte para transacciones ACID y versionado de los datos.
Se trata de un proyecto open-source desde que en 2019 Databricks lo liberó. Por supuesto, Databricks ofrece soporte completo de Delta Lake como capa de persistencia de datos.
Características¶
Delta Lake ofrece las siguientes características:
- Transacciones ACID. Todas las transacciones realizadas con Spark se realizan de manera persistente y se exponen a otros consumidores de forma atómica, gracias al Delta Transaction Log.
- Soporte completo de DML, pudiendo realizar borrados y modificados, pero también fusiones complejas de datos o escenarios upserts, lo que simplifica la creación de dimensiones y tablas de hechos al construir un MDW (modern data warehouse), así como cumplir la RGPD respecto a la modificación y/o borrado de datos.
- Time travel. El fichero de log de transacciones de Delta Lake guarda cada cambio realizado sobre los datos en el orden en el que se han realizado. Este log se convierte en una herramienta de auditoría completa, lo que facilita que administradores y desarrolladores puedan revertir a una versión anterior de los datos, ya sea para auditorías, rollbacks o la realización de pruebas.
- Unificación del procesamiento batch y streaming en un único modelo, ya que puede realizar merges de los flujos de datos (requisito muy común al trabajar con IoT).
- Evolución y aplicación de esquemas, al provocar el cumplimiento de un esquema a la hora de leer o escribir datos desde el lago, permitiendo una evolución segura del esquema para casos de uso donde los datos necesitan evolucionar.
- Soporte de metadatos ricos y escalables, ya que los metadatos pueden crecer y convertirse en big data y no escalar correctamente, de manera que Delta Lake facilita el escalado y procesamiento eficiente mediante Spark pudiendo manejar petabytes de datos.
Del dato al lago¶
Arquitectura Medallion¶
La arquitectura Medallion es un patrón de diseño de datos que se utiliza para organizar los datos en un lakehouse, con el objetivo de mejorar progresivamente la estructura y calidad de los datos conforme fluyen a través de las diferentes capas de la arquitectura (de la capa raw/bronce a la plata, y de ahí a la de oro).
Las tres (más una opcional) capas son:
- Bronze (Bronce): Representa el punto de entrada de datos. Aquí se almacenan los datos crudos exactamente como se reciben de las fuentes originales, sin ninguna transformación significativa. Esta capa funciona como un "sistema de registro" que preserva los datos en su estado original, incluyendo datos inconsistentes, duplicados o erróneos. Su principal propósito es garantizar que ningún dato se pierda durante la ingesta y proporcionar un punto de recuperación en caso de problemas en las capas superiores. Los formatos comunes incluyen archivos Delta Lake, Parquet o JSON con metadatos adicionales como timestamps de ingesta y fuentes de origen.
- Silver (Plata): Representa datos que han pasado por un primer nivel de procesamiento y limpieza. En esta capa, los datos bronce son validados, limpiados y conformados a un esquema consistente. Se eliminan duplicados, se corrigen errores de formato, se aplican reglas de validación básicas y se estandarizan los formatos. La capa Silver también incluye tareas como la normalización de valores, enriquecimiento con datos de referencia básicos y aplicación de reglas de negocio sencillas. Los datos en esta capa son más confiables que los de la capa Bronze, pero aún mantienen una granularidad detallada y están optimizados principalmente para procesamiento, no para consultas analíticas complejas.
- Gold (Oro): Representa el nivel más refinado de datos, optimizados específicamente para análisis, reporting y consumo por usuarios de negocio. Esta capa contiene modelos de datos completamente transformados, agregados y optimizados para casos de uso específicos. Los datos Gold están organizados típicamente como tablas dimensionales (modelos en estrella o copo de nieve), vistas materializadas, o conjuntos de datos altamente agregados. Aquí se implementan métricas de negocio complejas, KPIs, y cálculos específicos del dominio. Los datos en esta capa son de alta calidad, están documentados con metadatos de negocio, y están modelados para ofrecer rendimiento óptimo en consultas analíticas. Esta capa es la que típicamente se expone a herramientas de BI y a usuarios de negocio.
- Capa Platinum (Platino) - Opcional: En algunas implementaciones extendidas de la arquitectura Medallion, existe una cuarta capa llamada Platinum. Esta capa representa datos para usos específicos de alto valor, como modelos de machine learning, análisis predictivos, o cuadros de mando ejecutivos. La capa Platinum contiene datos altamente curados, que a menudo combinan múltiples conjuntos de datos Gold para crear perspectivas de negocio integradas. El acceso a esta capa suele estar más restringido y sus esquemas se optimizan para casos de uso muy específicos y de alto valor para la organización.
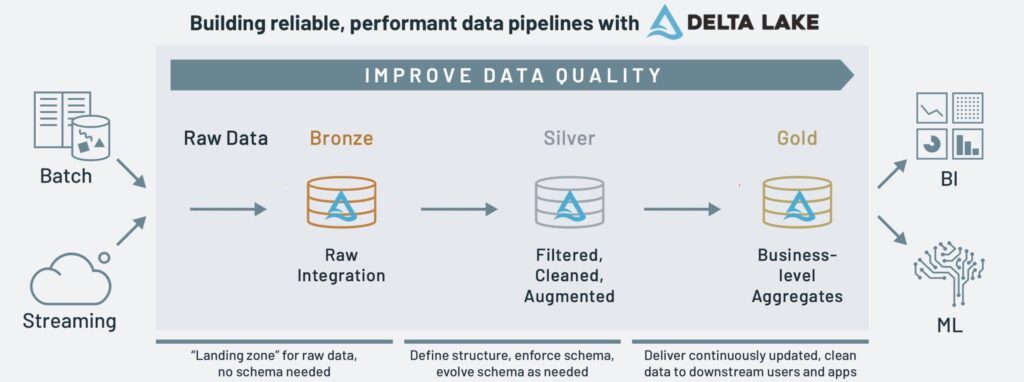
Conforme los datos transitan de la capa bronce y plata a la de oro (cuanto más evolucionan, más valen, y de ahí su material precioso) obtenemos datos más precisos. Cuando realizamos la ingesta de datos mediante procesos batch o en streaming los almacenamos en la capa de bronce en su formato crudo (raw). Tras limpiarlos, normalizarlos y realizar el procesado necesario para realizar nuestras consultas, los volvemos a almacenar en la capa de plata (curated). Finalmente, en la capa de oro almacenamos los datos agregados, con las tablas de sumario que contienen los KPI o las tablas necesarias para la visualización de los datos por parte de las herramientas de negocio como PowerBI o Tableau.
Para este flujo de datos entre capas, Databricks ofrece las tablas Delta Live y el uso de pipelines (esta opción no está habilitada en la versión educativa y no la vamos a poder probar). Tenéis un ejemplo completo en Getting Started with Delta Live Tables.
Arquitectura de un Lakehouse¶
El uso de la arquitectura que propone Delta Lake permite el procesamiento simultáneo de los datos batch y en streaming, de manera que podemos escribir los datos batch y los flujos en streaming en la misma tabla, y a su vez, se escriben de manera progresiva en otras tablas más limpias y refinadas.
La arquitectura de un lakehouse se compone de tres capas, y en nuestro caso, se concreta en:
- la capa de almacenamiento, por ejemplo, sobre S3.
- la capa transaccional, que la implementa Delta Lake.
- la capa de procesamiento, que la aporta Spark.
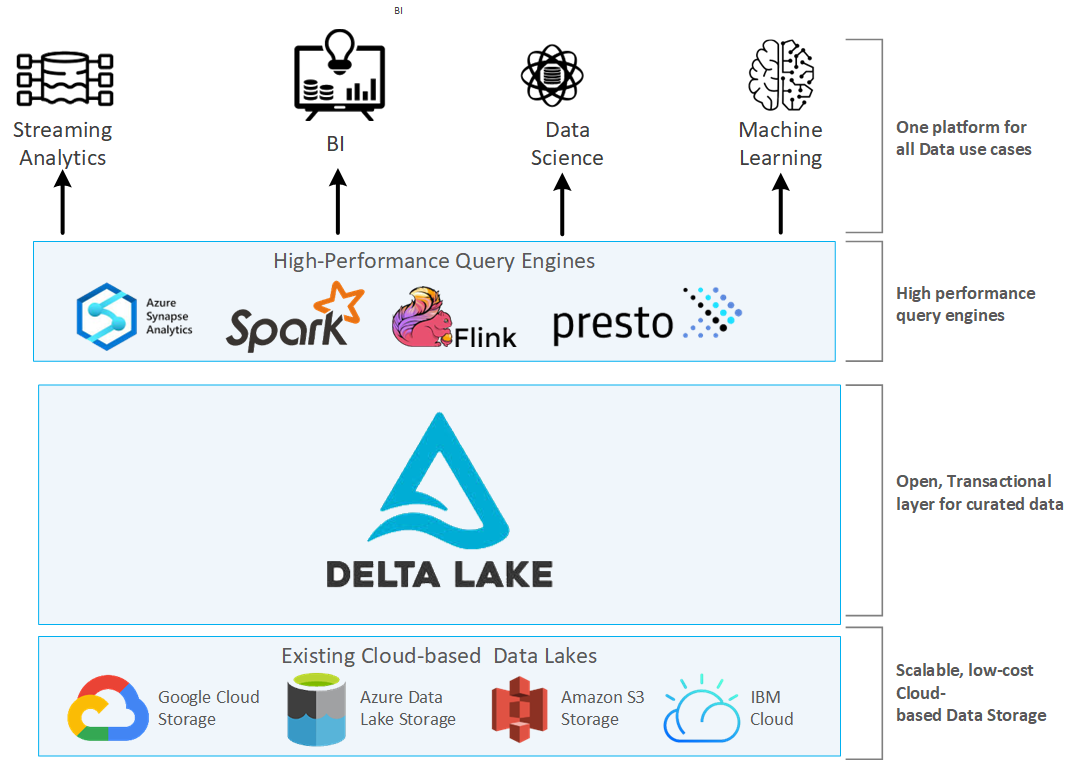
Arquitectura Delta Lake¶
Delta Lake almacena los datos en archivos Parquet, pero añade un registro de transacciones (transaction log) que permite realizar el seguimiento de todos los cambios. Este registro está compuesto por archivos JSON.
Los componentes clave son:
- Archivos de datos: Archivos en formato Parquet
- Registro de transacciones: Archivos JSON que registran todas las operaciones
- Tabla Delta: Combinación del registro de transacciones y los archivos de datos
- Compaction y Z-Ordering: Optimizaciones para mejorar el rendimiento
Aunque lo comprobaremos más adelante cuando veamos en detalle su funcionamiento, la estructura de almacenamiento es similar a la siguiente:
/ruta/a/tabla_delta/
/_delta_log/ # Directorio para el registro de transacciones
00000000000000000000.json # Primer archivo de transacción
00000000000000000001.json # Segunda transacción
...
/part-00000-...-c000.snappy.parquet # Archivos de datos en formato Parquet
/part-00001-...-c000.snappy.parquet
...
El ecosistema Delta¶
Delta Lake se utiliza en su mayor medida como lakehouse por más de 7000 empresas, procesando exabytes de datos por día.
Sin embargo, los data warehouses y las aplicaciones de machine learning no son el único objetivo de Delta Lake, ya que el soporte transaccional ACID aporta confiabilidad al data lake y permite ingestar y consumir datos tanto en streaming como por lotes.
El ecosistema de Delta Lake se compone de un conjunto de componentes individuales entre los que destacan Delta Lake Storage, Delta Sharing, y Delta Connectors.
Delta Lake Storage¶
Se trata de una capa de almacenamiento que corre sobre los lagos de datos basados en el cloud, como son Azure Data Lake Storage (ADLS), AWS S3 o Google Cloud Storage (GCS), añadiendo transaccionalidad al lago de datos y las tablas, y por tanto, ofreciendo características de un data warehouse a un data lake.
Se trata del componente principal, ya que el resto de elementos del ecosistema dependen de él.
Delta Sharing¶
Todo lago de datos va a tener que compartir sus datos en algún momento, lo que requiere una solución segura y confiable que nos asegure la privacidad deseada en los datos.
Delta Sharing es un protocolo para compartir datos seguros para grandes conjuntos de datos almacenados en el data lake, de manera que podemos compartir los datos almacenados en S3 o ADLS y acceder mediante Spark o PowerBI sin necesidad de desplegar ningún componente adicional, facilitando compartir los datos incluso entre diferentes proveedores cloud sin necesidad de ningún desarrollo.

Por ejemplo, podemos:
- Procesar en AWS mediante Spark datos que están almacenados en Azure ADLS.
- Procesar en Google mediante Rust datos que están almacenados en S3.
Más información sobre el ecosistema de Delta Sharing en la página de Sharing de Delta Lake.
Delta Connectors¶
El principal objetivo de los conectores Delta es llevar Delta Lake a otros motores de procesamiento ajenos a Spark. Para ello, ofrece conectores open source que realizan la conexión directa a Delta Lake sin necesidad de pasar por Spark.
Los conectores más destacados son:
- Delta Standalone: librerías Java/Python/Rust/etc... para desarrollar aplicaciones que leen y escriben en Delta Lake. En el apartado de Delta Lake y Python veremos un ejemplo del acceso mediante Python.
- Hive. Lectura de datos desde Apache Hive.
- Flink. Lectura y escritura de datos desde Apache Flink.
- Sql-delta-import. Permite importar datos desde cualquier fuente de datos JDBC.
- Power BI. Función de Power Query que permite la lectura de una tabla Delta desde cualquier fuente de datos soportada por Power BI.
Más información sobre los conectores existentes, donde cada día hay más, en la página de Integrations de Delta Lake.
Hola Delta¶
Probando Delta Lake
Para poder realizar los ejemplos y practicar Delta Lake, en esta sesión nos vamos a centrar en la instalación de nuestra máquina virtual o mediante la cuenta creada previamente en DataBricks.
Además, puedes probar a realizarlo en tu propio equipo con la máquina virtual o mediante Docker
Si quieres probar con Docker sin usar el cluster hemos estado usando, puedes descargar la imagen deltaio/delta-docker desde https://hub.docker.com/r/deltaio/delta-docker o arrancar el contenedor mediante:
docker run --name deltalake -p 8888-8889:8888-8889 deltaio/delta-docker:latest
Si prefieres usar Docker con el cluster, ya están configuradas las propiedades necesarias en el fichero spark-defaults.conf para usar Delta Lake con Spark:
# --- Delta Lake ---
spark.sql.extensions io.delta.sql.DeltaSparkSessionExtension
spark.sql.catalog.spark_catalog org.apache.spark.sql.delta.catalog.DeltaCatalog
Si nos centramos en nuestra instalación de la máquina virtual, cuando lanzamos pyspark tenemos que indicarle que vamos a utilizar delta mediante la opción packages:
pyspark --packages io.delta:delta-core_2.12:2.1.0 --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
Para facilitar su uso, en nuestra máquina virtual hemos creado el alias pysparkdl:
pysparkdl
Persistiendo en Delta¶
Si partimos de los datos que creamos en la sesión anterior en el DataFrame de clientes, podemos persistirlos en Delta indicando su formato mediante format("delta") y a continuación la ruta mediante save("/ruta/a/tabla_delta"):
spark.sql("use s8a")
df = spark.table("clientes")
# DeltaLake en Local
df.write.format("delta").save("/tmp/raw/clientes")
# DeltaLake en DataBricks
df.write.format("delta").save("/delta/raw/clientes")
# DeltaLake en HDFS
df.write.format("delta").save("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
# DeltaLake en MinIO
df.write.format("delta").save("s3a://iabd/delta/raw/clientes")
Aunque no es obligatorio indicar la ruta, es recomendable hacerlo para evitar problemas de almacenamiento. Si no indicamos la ruta, Delta Lake almacenará los datos en la ruta del metastore que tenga configurada Spark, y cuando la ruta apunta a un sistema de archivos local, como es el caso de nuestra máquina virtual, puede generar problemas de almacenamiento al no ser un sistema de archivos distribuido, lo que puede provocar que los datos se pierdan o no se almacenen correctamente.
Dicho esto, es recomendable trabajar con tablas gestionadas, de manera que Spark registra la tabla en el metastore MySQL y escribe los ficheros en MinIO automáticamente. Es el patrón más limpio cuando el dato va a vivir en el lakehouse.:
df.write.format("delta").saveAsTable("clientes_delta")
Por últimos, podemos emplear tablas externas, de manera que Spark registra la tabla en el metastore MySQL pero no escribe los ficheros, sino que se los indicamos nosotros mediante la opción path:
df.write.format("delta").option("path", "s3a://raw-data/retail_db").saveAsTable("clientes_delta_ext")
¿Dónde se almacenan las tablas en las que no indicamos la ruta?
Dependerá de la ruta del metastore que utilice Spark, la cual configuramos en la sesión anterior en la propiedad spark.sql.warehouse.dir. Por ejemplo, en nuestra máquina virtual podemos poner /opt/spark-3.3.1/warehouse/ para almacenamiento local o hdfs://iabd-virtualbox:9000/user/hive/warehouse/ si queremos almacenar los metadatos en HDFS. En cambio, para el cluster de Spark tenemos configurada la ruta s3a://warehouse/hive para almacenar los metadatos en el sistema de archivos de MinIO.
Si intentamos volver a escribir los datos en la misma ruta, obtendremos un error. Si queremos sobrescribir los datos, necesitamos indicarle el modo overwrite:
df.write.format("delta").mode("overwrite").save("s3a://iabd/delta/raw/clientes")
Particionando los datos
Para particionar los datos utilizaremos partitionBy para indicar el campo que hace de clave:
# Como datos en el lago IABD
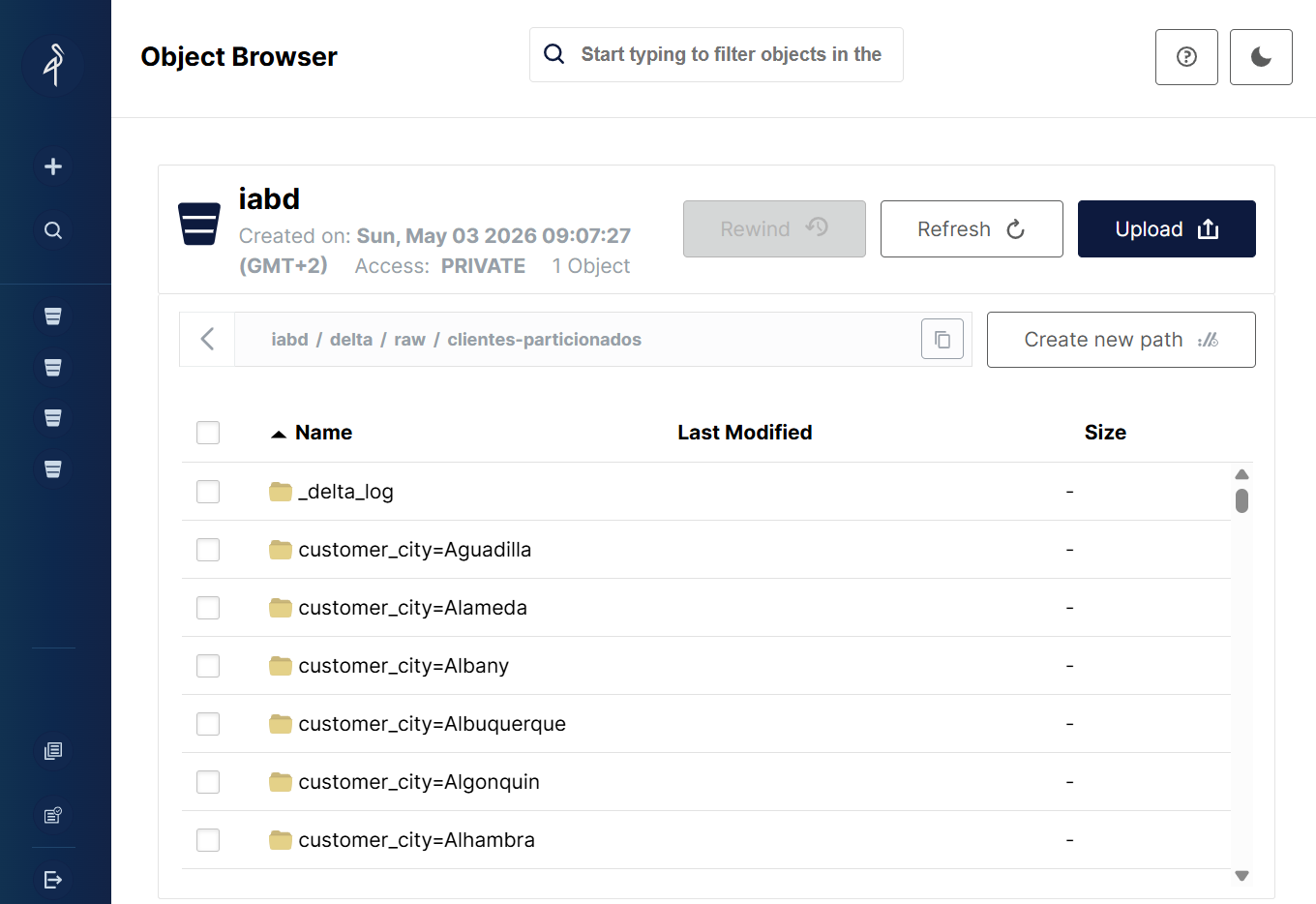
df.write.format("delta").partitionBy("customer_city").save("s3a://iabd/delta/raw/clientes-particionados")
# Como tabla en el warehouse
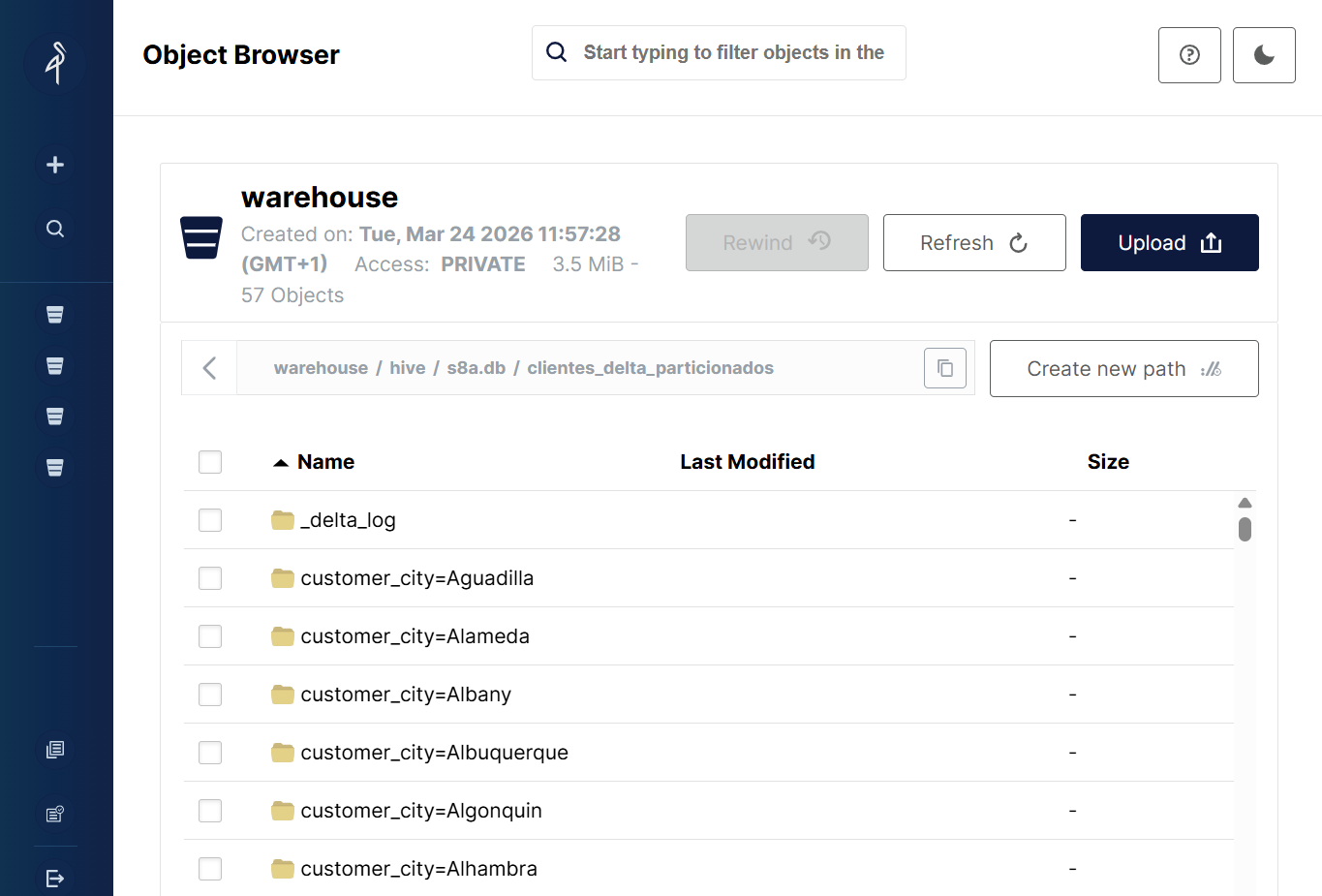
df.write.format("delta").partitionBy("customer_city").saveAsTable("clientes_delta_particionados")
# Como datos en sistema de archivos local (máquina virtual)
df.write.format("delta").partitionBy("customer_city").save("/tmp/raw/clientes-particionados")
De manera que creará una carpeta para cada ciudad:
Si usamos save para escribir los datos en el lago de datos, se creará una carpeta para cada ciudad dentro de la ruta indicada:
Si usamos saveAsTable para escribir los datos en el data warehouse, se creará una carpeta para cada ciudad dentro de la ruta del metastore que tenemos configurada:
ls -l /tmp/raw/clientes-particionados/
# total 2252
# drwxr-xr-x 2 iabd iabd 4096 feb 19 13:11 'customer_city=Aguadilla'
# drwxr-xr-x 2 iabd iabd 4096 feb 19 13:11 'customer_city=Alameda'
# drwxr-xr-x 2 iabd iabd 4096 feb 19 13:11 'customer_city=Albany'
# drwxr-xr-x 2 iabd iabd 4096 feb 19 13:11 'customer_city=Albuquerque'
# ...
Cargando desde Delta¶
Para recuperar los datos, realizamos una lectura indicando siempre el formato delta:
dfdeltal = spark.read.format("delta").load("/tmp/raw/clientes")
dfdeltadatabricks = spark.read.format("delta").load("/delta/raw/clientes")
dfdeltahdfs = spark.read.format("delta").load("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
dfdeltaminio = spark.read.format("delta").load("s3a://iabd/delta/raw/clientes")
# Uso de tablas
tabla_delta = spark.read.format("delta").table("clientes_delta")
tabla_delta_ext = spark.read.format("delta").table("clientes_delta_ext")
DML con Delta¶
Tal como hemos comentado, podemos realizar operaciones DML sobre los datos utilizando SQL. Para ello, hacemos referencia a la ruta del almacenamiento delta mediante delta. seguida de la ruta entre comillas simples invertidas:
spark.sql("""
UPDATE delta.`s3a://iabd/delta/raw/clientes`
SET customer_fname = 'Aitor'
WHERE customer_id = '1'
""")
spark.sql("""
DELETE FROM delta.`s3a://iabd/delta/raw/clientes`
WHERE customer_city = 'Elche'
""")
Si hemos guardado los tablas como datos (lo cual es lo más recomendable), en nuestro caso en la tabla clientes_delta, podemos hacer las mismas operaciones con código más legible:
spark.sql("""
UPDATE clientes_delta
SET customer_fname = 'Aitor'
WHERE customer_id = '1'
""")
spark.sql("""
DELETE FROM clientes_delta
WHERE customer_city = 'Elche'
""")
Cada una de estas operaciones genera automáticamente una nueva versión en el historial de la tabla, el cual veremos más adelante cómo lo podemos recuperar.
Delta Lake por dentro¶
Si accedemos al sistema de archivos local, HDFS o Databricks, podemos analizar la estructura de archivos que ha utilizado para almacenar la información.
Delta Lake almacena los datos en formato Parquet en la ruta indicada (y si hubiéramos indicado particiones, en sus subcarpetas), y luego crea una carpeta denominada _delta_log donde almacena el DeltaLog o registro transaccional mediante archivos en formato JSON, en los cuales se va registrando los cambios delta que se realizan sobre los datos.
Ejemplos con la máquina virtual
Para los ejemplos de esta sección, vamos a usar la máquina virtual y HDFS por comodidad para recorrer el sistema de archivos, aunque el funcionamiento es el mismo para los otros sistemas de archivos.
Vamos a comprobar qué datos se han almacenado en HDFS:
iabd@iabd-virtualbox:~/datos$ hdfs dfs -ls -R /user/iabd/delta/raw/clientes
# drwxr-xr-x - iabd supergroup 0 2023-01-29 12:23 /user/iabd/delta/raw/clientes/_delta_log
# -rw-r--r-- 1 iabd supergroup 2605 2023-01-29 12:23 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000000.json
# -rw-r--r-- 3 iabd supergroup 251875 2023-01-29 12:23 /user/iabd/delta/raw/clientes/part-00000-05cb7b9c-c529-4f5e-83ab-0dc79d0422bf-c000.snappy.parquet
Si realizamos otra operación, por ejemplo, sobrescribimos la tabla, generará nuevos datos y otro fichero de log:
df.write.format("delta").mode("overwrite").save("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
Lo comprobamos volviendo a listar los archivos almacenados:
iabd@iabd-virtualbox:~/datos$ hdfs dfs -ls -R /user/iabd/delta/raw/clientes
# drwxr-xr-x - iabd supergroup 0 2023-01-29 12:29 /user/iabd/delta/raw/clientes/_delta_log
# -rw-r--r-- 1 iabd supergroup 2605 2023-01-29 12:23 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000000.json
# -rw-r--r-- 1 iabd supergroup 1592 2023-01-29 12:29 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000001.json
# -rw-r--r-- 3 iabd supergroup 251875 2023-01-29 12:23 /user/iabd/delta/raw/clientes/part-00000-05cb7b9c-c529-4f5e-83ab-0dc79d0422bf-c000.snappy.parquet
# -rw-r--r-- 3 iabd supergroup 251875 2023-01-29 12:29 /user/iabd/delta/raw/clientes/part-00000-1f226209-881f-4ff7-af04-6eedd64e1581-c000.snappy.parquet
Ahora vamos a añadir nuevos datos, utilizando un nuevo Dataframe e indicando el modo de escritura con append:
cols = ['customer_id', 'customer_fname', 'customer_lname']
datos = [
(88888, "Aitor", "Medrano"),
(99999, "Pedro", "Casas")
]
nuevosClientes = spark.createDataFrame(datos, cols)
# cambiamos el tipo a int pq por defecto le asigna long
nuevosClientes = nuevosClientes.withColumn("customer_id", nuevosClientes.customer_id.cast("int"))
nuevosClientes.write.format("delta").mode("append").save("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
nuevosClientes.write.format("delta").mode("append").saveAsTable("clientes_delta")
Fusionando el esquema
Si los tipos de los datos no cuadran con el esquema almacenado en Delta Lake, tendremos un error. Para habilitar que fusione los esquemas podemos indicarlo con .option("mergeSchema", "true"):
nuevosClientes.write.format("delta").mode("append").option("mergeSchema", "true").save("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
Ahora podemos ver cómo ha creado un nuevo archivo de log pero dos archivos de datos. En concreto, el archivo de log ha registrado las dos inserciones, y cada archivo de Parquet contiene únicamente cada uno de los registros:
iabd@iabd-virtualbox:~/datos$ hdfs dfs -ls -R /user/iabd/delta/raw/clientes
# drwxr-xr-x - iabd supergroup 0 2023-01-29 12:39 /user/iabd/delta/raw/clientes/_delta_log
# -rw-r--r-- 1 iabd supergroup 2605 2023-01-29 12:23 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000000.json
# -rw-r--r-- 1 iabd supergroup 1592 2023-01-29 12:29 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000001.json
# -rw-r--r-- 1 iabd supergroup 1309 2023-01-29 12:39 /user/iabd/delta/raw/clientes/_delta_log/00000000000000000002.json
# -rw-r--r-- 3 iabd supergroup 251875 2023-01-29 12:23 /user/iabd/delta/raw/clientes/part-00000-05cb7b9c-c529-4f5e-83ab-0dc79d0422bf-c000.snappy.parquet
# -rw-r--r-- 3 iabd supergroup 251875 2023-01-29 12:29 /user/iabd/delta/raw/clientes/part-00000-1f226209-881f-4ff7-af04-6eedd64e1581-c000.snappy.parquet
# -rw-r--r-- 3 iabd supergroup 1035 2023-01-29 12:39 /user/iabd/delta/raw/clientes/part-00000-b7124036-ce26-4b95-a759-080e829b8de6-c000.snappy.parquet
# -rw-r--r-- 3 iabd supergroup 1020 2023-01-29 12:39 /user/iabd/delta/raw/clientes/part-00001-6164f53a-ca34-4b73-96ef-8d2f2cfbbb47-c000.snappy.parquet
Por ejemplo, si descargamos y visualizamos uno de los archivos de Parquet veremos sus datos:
iabd@iabd-virtualbox:~/Descargas$ parquet-tools show part-00000-b7124036-ce26-4b95-a759-080e829b8de6-c000.snappy.parquet
# +---------------+------------------+------------------+
# | customer_id | customer_fname | customer_lname |
# |---------------+------------------+------------------|
# | 88888 | Aitor | Medrano |
# +---------------+------------------+------------------+
Finalmente, si queremos comprobar los datos, a partir del dataframe que habíamos leído desde HDFS, podemos comprobar como los datos ya aparecen:
dfdeltahdfs.sort("customer_id", ascending=False).show(3)
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
# | 99999| Pedro| Casas| null| null| null| null| null| null|
# | 88888| Aitor| Medrano| null| null| null| null| null| null|
# | 12435| Laura| Horton| XXXXXXXXX| XXXXXXXXX|5736 Honey Downs| Summerville| SC| 29483|
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
# only showing top 3 rows
Optimizando las tablas
Tras realizar muchos cambios en una tabla, es muy probable que tengamos muchos archivos pequeños. Para mejorar la velocidad de las consultas de lectura, podemos utilizar OPTIMIZE para unir los ficheros pequeños en más grandes:
OPTIMIZE clientes_delta
Trabajando con Delta¶
A continuación vamos a trabajar sobre algunas de las características específicas de Delta Lake, como son el uso de tablas, la fusión de los esquemas, así como los viajes en el tiempo.
Uso de tablas desde el API de Python¶
Si no nos interesa recuperar el contenido de Delta Lake como un DataFrame ni realizar las operaciones mediante SQL, podemos trabajar directamente con tablas Delta. Para ello, Delta Lake ofrece un API para realizar modificaciones condicionales, borrados o upserts de datos en las tablas.
Para ello, el primer paso es obtener una tabla delta mediante el método DeltaTable.forPath:
from delta.tables import *
dtabla = DeltaTable.forPath(spark, "hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
dtablaDatabricks = DeltaTable.forPath(spark, "dbfs:/user/hive/warehouse/clientes_delta")
dtablaMinio = DeltaTable.forPath(spark, "s3a://iabd/delta/raw/clientes")
Una vez tenemos la tabla, ya podemos, por ejemplo, modificar las ciudades haciendo uso del método update(condición, valor):
dtabla.update("customer_city = 'Bruklyn'", {"customer_city": "'Brooklyn'"})
O borrar los clientes de Brownsville, mediante el método delete(condición):
dtabla.delete("customer_city = 'Brownsville'")
# borramos los últimos clientes insertados
dtabla.delete("customer_id > 33333")
Si queremos realizar operaciones sobre DataFrames, convertiremos la tabla mediante toDF():
df_tabla = dtabla.toDF()
df_tabla.sort("customer_id", ascending=False).show(3)
De la misma manera que cuando hicimos las operaciones DML mediante SQL, cada una de estas operaciones genera automáticamente una nueva versión en el historial de la tabla, el cual veremos más adelante cómo lo podemos recuperar.
Fusionando datos¶
Si queremos fusionar un conjunto de actualizaciones e inserciones en una tabla Delta existente, podemos emplear la sentencia MERGE INTO, que recoge los datos de una tabla origen y los fusiona con la tabla Delta destino.
Por ejemplo, vamos a crear una vista con los datos que queremos fusionar, de manera que los que tengan el mismo id serán actualizaciones, y los que no, inserciones:
CREATE OR REPLACE TEMP VIEW clientes_updates (
customer_id, customer_fname, customer_lname
) AS VALUES
(88888, 'Andreu', 'Medrano'),
(77777, 'Marina', 'Medrano'),
(77778, 'Javier', 'Hernández'),
(77779, 'Paola', 'Girona');
Si nos fijamos, nuestra vista no contiene todas las columnas de la tabla clientes_delta (customer_email, etc...) y por defecto, nos dará error. Para que fusione los esquemas, con Python utilizaríamos .option("mergeSchema", "true"), pero mediante Spark SQL, necesitamos configurar la siguiente propiedad:
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled","true")
Para fusionar los datos utilizaremos la operación MERGE INTO con la siguiente sintaxis:
MERGE INTO tablaDestino
USING tablaOrigen
ON condicionesMerge
WHEN MATCHED THEN accionCoinciden
WHEN NOT MATCHED THEN accionNoCoinciden;
Así pues, si seguimos con el ejemplo de fusionar los datos clientes_update en clientes_delta, haríamos:
MERGE INTO clientes_delta
USING clientes_updates
ON clientes_delta.customer_id = clientes_updates.customer_id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
-- +-----------------+----------------+----------------+-----------------+
-- |num_affected_rows|num_updated_rows|num_deleted_rows|num_inserted_rows|
-- +-----------------+----------------+----------------+-----------------+
-- | 4| 1| 0| 3|
-- +-----------------+----------------+----------------+-----------------+
Si nos fijamos en la sentencia, modificará la tabla clientes_delta con los registros de cliente_udpates, utilizando el customer_id de las dos tablas como clave primaria a comparar. A partir de aquí, le indicamos qué comportamiento debe realizar cuando las claves coinciden (WHEN MATCHED), que en nuestro caso le hemos dicho que modifique todos los campos, o cuando no coinciden (WHEN NOT MATCHED), que hemos decidido que inserte todos los registros.
Si queremos una granularidad más fina a la hora de decidir qué campos se insertan o modifican, en las acciones de las diferentes condiciones indicaremos los campos de forma individual:
MERGE INTO clientes_delta as destino
USING clientes_updates as origen
ON destino.customer_id = origen.customer_id
WHEN MATCHED THEN
UPDATE SET
destino.customer_fname = origen.customer_fname,
destino.customer_lname = origen.customer_lname
WHEN NOT MATCHED THEN
INSERT (customer_id, customer_fname, customer_lname)
VALUES (origen.customer_id, origen.customer_fname, origen.customer_lname);
Si en vez de SQL queremos hacerlo mediante Python, utilizando el DataFrame de nuevosClientes creado anteriormente y la tabla Delta dtabla del apartado anterior, haríamos algo similar a utilizando el método merge:
dtabla.alias("destino") \
.merge(
nuevosClientes.alias("origen"),
"destino.customer_id = origen.customer_id"
) \
.whenMatchedUpdate(
set={"customer_fname": "origen.customer_fname", "customer_lname": "origen.customer_lname"}
) \
.whenNotMatchedInsert(
values={
"customer_id": "origen.customer_id",
"customer_fname": "origen.customer_fname",
"customer_lname": "origen.customer_lname"
}
) \
.execute()
Viajando en el tiempo¶
Podemos realizar consultas sobre snapshots de nuestras tablas Delta mediante el time travel. Delta Lake permite viajar en el tiempo a versiones previas de las tablas a partir de una versión o timestamp, por ejemplo, para volver a realizar analíticas o informes que necesitemos depurar o auditar, corregir errores en los datos u obtener aislamiento sobre los datos en tablas que no paran de cambiar.
En cualquier momento podemos consultar el histórico de cambios de una tabla mediante describe history o el método history:
spark.sql("describe history clientes_delta").show(truncate=False);
-- +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
-- |version|timestamp |userId|userName|operation |operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics |userMetadata|engineInfo |
-- +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
-- |1 |2024-02-19 13:50:07.205|null |null |WRITE |{mode -> Append, partitionBy -> []} |null|null |null |0 |Serializable |true |{numFiles -> 2, numOutputRows -> 2, numOutputBytes -> 2055} |null |Apache-Spark/3.3.1 Delta-Lake/2.1.0|
-- |0 |2024-02-19 13:24:35.651|null |null |CREATE TABLE AS SELECT|{isManaged -> true, description -> null, partitionBy -> [], properties -> {}}|null|null |null |null |Serializable |true |{numFiles -> 1, numOutputRows -> 12435, numOutputBytes -> 251792}|null |Apache-Spark/3.3.1 Delta-Lake/2.1.0|
-- +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
cliente_dtable = DeltaTable.forName(spark,"clientes_delta")
historialDF = cliente_dtable.history()
historialDF.show(truncate=False)
# +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
# |version|timestamp |userId|userName|operation |operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics |userMetadata|engineInfo |
# +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
# |1 |2024-02-19 13:50:07.205|null |null |WRITE |{mode -> Append, partitionBy -> []} |null|null |null |0 |Serializable |true |{numFiles -> 2, numOutputRows -> 2, numOutputBytes -> 2055} |null |Apache-Spark/3.3.1 Delta-Lake/2.1.0|
# |0 |2024-02-19 13:24:35.651|null |null |CREATE TABLE AS SELECT|{isManaged -> true, description -> null, partitionBy -> [], properties -> {}}|null|null |null |null |Serializable |true |{numFiles -> 1, numOutputRows -> 12435, numOutputBytes -> 251792}|null |Apache-Spark/3.3.1 Delta-Lake/2.1.0|
# +-------+-----------------------+------+--------+----------------------+-----------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------+------------+-----------------------------------+
Si queremos acceder a datos que hemos sobrescrito, podemos viajar al pasado de la tabla antes de que se sobrescribieran los datos mediante la opción versionAsOf. Por ejemplo, vamos a recuperar todos los datos y los iniciales:
# tclientes_delta = spark.read.format("delta").table("clientes_delta")
tclientes_delta = spark.read.format("delta").load("hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
tclientes_delta.sort("customer_id", ascending=False).show(3)
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
# | 99999| Pedro| Casas| null| null| null| null| null| null|
# | 88888| Aitor| Medrano| null| null| null| null| null| null|
# | 12435| Laura| Horton| XXXXXXXXX| XXXXXXXXX|5736 Honey Downs| Summerville| SC| 29483|
# +-----------+--------------+--------------+--------------+-----------------+----------------+-------------+--------------+----------------+
tclientes_delta_inicial = spark.read.format("delta").option("versionAsOf", 0).table("clientes_delta")
tclientes_delta_inicial.sort("customer_id", ascending=False).show(3)
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# | 12435| Laura| Horton| XXXXXXXXX| XXXXXXXXX| 5736 Honey Downs| Summerville| SC| 29483|
# | 12434| Mary| Mills| XXXXXXXXX| XXXXXXXXX|9720 Colonial Parade| Caguas| PR| 00725|
# | 12433| Benjamin| Garcia| XXXXXXXXX| XXXXXXXXX|5459 Noble Brook ...| Levittown| NY| 11756|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
Otras formas de viajar con el tiempo es mediante la propiedad timestampAsOf, el cual aplicará todas las transformaciones previas a la fecha indicada:
tclientes_delta_inicial_ts = spark.read.format("delta").option('timestampAsOf', '2024-02-19 13:30:00').table("clientes_delta")
tclientes_delta_inicial_ts.sort("customer_id", ascending=False).show(3)
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# | 12435| Laura| Horton| XXXXXXXXX| XXXXXXXXX| 5736 Honey Downs| Summerville| SC| 29483|
# | 12434| Mary| Mills| XXXXXXXXX| XXXXXXXXX|9720 Colonial Parade| Caguas| PR| 00725|
# | 12433| Benjamin| Garcia| XXXXXXXXX| XXXXXXXXX|5459 Noble Brook ...| Levittown| NY| 11756|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
Si queremos interactuar mediante Spark SQL, podemos realizar las mismas operaciones:
-- Trabajando con diferentes versiones
SELECT * FROM clientes_delta VERSION AS OF 0
SELECT * FROM clientes_delta@v0 -- equivalente a VERSION AS OF 0
SELECT * FROM clientes_delta TIMESTAMP AS OF "2024-02-19"
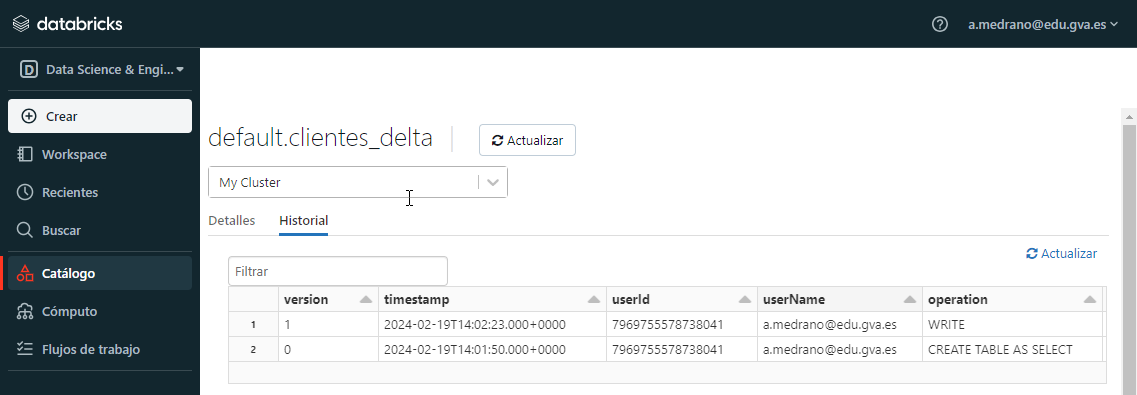
Historial y Databricks
Desde el catálogo de tablas de Databricks, podemos consultar el historial de cambios desde el Catálogo. Tras seleccionar la tabla en la que estamos interesados, en la pestaña Historial podemos obtener la misma información:
Diferencias entre versiones¶
Si queremos saber exactamente qué datos han cambiado entre dos versiones podemos hacer uso de las operaciones de conjuntos que realizan la sustracción mediante EXCEPT ALL:
-- Recuperando las diferencias entre dos versiones
SELECT * FROM clientes_delta VERSION AS OF 1
EXCEPT ALL SELECT * FROM clientes_delta VERSION AS OF 0
-- +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
-- |customer_id|customer_fname|customer_lname|customer_email|customer_password|customer_street|customer_city|customer_state|customer_zipcode|
-- +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
-- | 88888| Aitor| Medrano| null| null| null| null| null| null|
-- | 99999| Pedro| Casas| null| null| null| null| null| null|
-- +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
Y el equivalente en Python lo realizaremos a partir de dos DataFrames:
tclientes_delta.exceptAll(tclientes_delta_inicial).show()
# +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password|customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
# | 88888| Aitor| Medrano| null| null| null| null| null| null|
# | 99999| Pedro| Casas| null| null| null| null| null| null|
# +-----------+--------------+--------------+--------------+-----------------+---------------+-------------+--------------+----------------+
Restaurar una versión específica¶
Finalmente si queremos deshacer los cambios y volver a una versión determinada (similar a realizar un rollback) podemos utilizar RESTORE
RESTORE clientes_delta VERSION AS OF 0
-- +------------------------+--------------------------+-----------------+------------------+------------------+-------------------+
-- |table_size_after_restore|num_of_files_after_restore|num_removed_files|num_restored_files|removed_files_size|restored_files_size|
-- +------------------------+--------------------------+-----------------+------------------+------------------+-------------------+
-- | 251792| 1| 2| 0| 2055| 0|
-- +------------------------+--------------------------+-----------------+------------------+------------------+-------------------+
RESTORE clientes_delta TIMESTAMP AS OF "2024-02-19"
O mediante Python, una vez tenemos una tabla, mediante los métodos restoreToVersion o restoreToTimestamp:
dtabla = DeltaTable.forPath(spark, "hdfs://iabd-virtualbox:9000/user/iabd/delta/raw/clientes")
dtabla.restoreToVersion(0)
dtabla.restoreToTimestamp('2024-02-19')
Más información en https://docs.databricks.com/en/delta/history.html.
Pasando la aspiradora¶
Delta Lake permite eliminar ficheros de datos que no son referenciados por ninguna tabla y que tienen más antigüedad que un rango que definimos mediante el comando VACUUM, el cual por defecto es de 7 días.
VACUUM clientes_delta
Si queremos saber los archivos que se verían implicados podríamos hacer una limpieza "en seco":
VACUUM clientes_delta DRY RUN
Podríamos considerar que Delta Lake mantiene una papelera de reciclaje sobre los datos eliminados y modificados, y mediante VACUUM vaciaremos la papelera.
¿Y qué ventaja tiene eliminar estos archivos? Por un lado, reducir la cantidad de datos almacenados, y en consecuencia, pagar menos por ello. Además, nos asegura que aquellos datos que han sido eliminados, realmente desaparezcan de nuestro sistema.
Más información en https://docs.databricks.com/en/delta/vacuum.html.
Caso de Uso - COVID¶
Nos han enviado un dataset con datos de COVID (el cual está descrito com Bing COVID-19), y nos han pedido que lo carguemos en una tabla Delta para posteriormente realizar algunas consultas sobre él. Para ello, vamos a seguir los siguientes pasos:
Creando una tabla¶
El primer paso es descargar el archivo y a continuación, vamos a crear una tabla para almacenar los casos, en un principio, únicamente con una columna para la fecha:
spark.sql("CREATE DATABASE IF NOT EXISTS iabd")
spark.sql("""
CREATE TABLE IF NOT EXISTS iabd.covid (
fecha DATE
) USING DELTA
TBLPROPERTIES('delta.logRetentionDuration'='interval 7 days');
""")
Podemos comprobar como la tabla está vacía mediante:
spark.table("iabd.covid").inputFiles()
# []
Tras crear la tabla, la vamos a rellenar con los datos descargados:
from pyspark.sql.functions import to_date
df = spark.read.format("parquet").load("*.parquet")
df.printSchema()
Y obtenemos el esquema del archivo cargado:
root
|-- id: integer (nullable = true)
|-- updated: date (nullable = true)
|-- confirmed: integer (nullable = true)
|-- confirmed_change: integer (nullable = true)
|-- deaths: integer (nullable = true)
|-- deaths_change: short (nullable = true)
|-- recovered: integer (nullable = true)
|-- recovered_change: integer (nullable = true)
|-- latitude: double (nullable = true)
|-- longitude: double (nullable = true)
|-- iso2: string (nullable = true)
|-- iso3: string (nullable = true)
|-- country_region: string (nullable = true)
|-- admin_region_1: string (nullable = true)
|-- iso_subdivision: string (nullable = true)
|-- admin_region_2: string (nullable = true)
|-- load_time: timestamp (nullable = true)
Si intentamos persistir la tabla nos fallará porque la tabla ya existe:
df.write.format("delta").saveAsTable("iabd.covid")
# AnalysisException: Table iabd.covid already exists
Así pues, en vez de escribir mediante write, necesitamos realizar una operación de append, pero recibimos otro error porque el esquema del archivo Parquet (con varias columnas) no cuadra con la estructura de la tabla que habíamos creado previamente (con una única columna):
df.write.format("delta").mode("append").saveAsTable("iabd.covid")
AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID: 9c1b48b4-59b8-4712-b536-38d4c59513dd).
Así pues, además de añadir los datos sobre la tabla existente, debemos indicar de forma explicita que fusione los esquemas mediante la opción mergeSchema:
df.write.format("delta").mode("append") \
.option("mergeSchema", "true") \
.saveAsTable("iabd.covid")
Y ahora la tabla sí que tiene la misma estructura que el archivo cargado:
spark.sql("describe extended iabd.covid").show(truncate=False)
# +----------------+---------+-------+
# |col_name |data_type|comment|
# +----------------+---------+-------+
# |update |date | |
# |id |int | |
# |updated |date | |
# |confirmed |int | |
# |confirmed_change|int | |
# |deaths |int | |
# |deaths_change |smallint | |
# |recovered |int | |
# |recovered_change|int | |
# |latitude |double | |
# |longitude |double | |
# |iso2 |string | |
# |iso3 |string | |
# |country_region |string | |
# |admin_region_1 |string | |
# |iso_subdivision |string | |
# |admin_region_2 |string | |
# |load_time |timestamp| |
# | | | |
# |# Partitioning | | |
# +----------------+---------+-------+
# only showing top 20 rows
Y si comprobamos de nuevo los ficheros, veremos que ahora sí que existen:
spark.table("iabd.covid").inputFiles()
# ['file:/opt/spark/work-dir/spark-warehouse/iabd.db/covid/part-00005-9ad5b550-8ded-4177-8d89-66bd22062e2e-c000.snappy.parquet',
# 'file:/opt/spark/work-dir/spark-warehouse/iabd.db/covid/part-00001-50397be1-9510-4cd1-9d12-34e599a64cae-c000.snappy.parquet']
Hablemos con propiedad¶
Si queremos añadir una propiedad a una tabla, podemos emplear una sentencia ALTER TABLE... SET TBLPROPERTIES. Por ejemplo:
spark.sql("""
ALTER TABLE iabd.covid
SET TBLPROPERTIES (
'engineering.team_name'='iabd'
)
""")
Con cada modificación realizada sobre la tabla, incluso sobre sus metadatos, los cambios se almacenan en el historial de la tabla.
Tablas particionadas¶
Hemos visto que podemos crear una tabla a partir de una ruta. Si queremos definirla desde cero, podemos hacer uso de DeltaTable.createIfNotExists:
from pyspark.sql.types import DateType
from delta.tables import DeltaTable
(DeltaTable.createIfNotExists(spark)
.tableName("iabd.covid_por_fecha")
.addColumn("updated", DateType(), nullable=False) # la marcamos como VNN para el particionado
.partitionedBy("updated")
.addColumn("county", "STRING")
.addColumn("state", "STRING")
.addColumn("fips", "INT")
.addColumn("cases", "INT")
.addColumn("deaths", "INT")
.execute())
Una vez creada, vamos a realizar la carga con los datos de nuestra tabla anterior:
(spark.table("iabd.covid") # cargamos los datos de COVID
.write
.format("delta")
.mode("append")
.option("mergeSchema", "false")
.saveAsTable("iabd.covid_por_fecha"))
Si queremos consultar los metadatos de la tabla creada y comprobar la partición:
(DeltaTable.forName(spark, "iabd.covid_por_fecha")
.detail()
.toJSON()
.collect()[0])
Delta Lake y Python¶
Si queremos trabajar desde scripts de Python y Pandas sin utilizar Spark ni Databricks, tendremos que instalar la librería deltalake, la cual es una implementación en Rust/Python:
pip install deltalake
En el siguiente script probamos las diferentes características de Delta Lake, por ejemplo, mediante las operaciones write_deltalake, la clase DeltaTable y sus respectivos métodos, como por ejemplo, para obtener el histórico mediante history o viajar en el tiempo con load_as_version:
import pandas as pd
from deltalake.writer import write_deltalake
from deltalake import DeltaTable
df = pd.DataFrame({"datos": range(5)})
# Persistimos un DataFrame de Pandas
write_deltalake("/tmp/delta_table", df)
df = pd.DataFrame({"datos": range(6, 11)})
# Añadimos nuevos datos
write_deltalake("/tmp/delta_table", df, mode="append")
# Cargamos los datos como una tabla
dt = DeltaTable("/tmp/delta_table")
# Visualizamos los ficheros de la tabla
dt.files()
# ['0-ba28a612-6c57-4f25-b388-46d3a8cdf914-0.parquet', '1-0f732990-efd2-44da-853d-c08dc8d3d345-0.parquet']
# Histórico de revisiones
dt.history()
# [{'timestamp': 1706638235891, 'operation': 'CREATE TABLE', 'operationParameters': {'protocol': '{"minReaderVersion":1,"minWriterVersion":1}', 'location': 'file:///tmp/delta_table', 'mode': 'ErrorIfExists', 'metadata': '{"configuration":{},"created_time":1706638235887,"description":null,"format":{"options":{},"provider":"parquet"},"id":"cd66f777-a19c-4679-b5cc-a16ad57bbaf8","name":null,"partition_columns":[],"schema":{"fields":[{"metadata":{},"name":"datos","nullable":true,"type":"long"}],"type":"struct"}}'}, 'clientVersion': 'delta-rs.0.10.0'}, {'timestamp': 1706638245541, 'operation': 'WRITE', 'operationParameters': {'mode': 'Append', 'partitionBy': '[]'}, 'clientVersion': 'delta-rs.0.10.0'}]
# Time Travel a la versión inicial
dt.load_as_version(0)
# Mostramos la tabla inicial
dt.to_pandas()
# datos
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
Para comprobar los datos de la tabla creada, podemos ver el contenido de la carpeta y visualizar los diferentes archivos Parquet creados y el fichero de log con las transacciones:
ls -ls /tmp/delta_table
# -rw-r--r-- 1 NBuser NBuser 1694 Jan 30 18:10 0-ba28a612-6c57-4f25-b388-46d3a8cdf914-0.parquet
# -rw-r--r-- 1 NBuser NBuser 1696 Jan 30 18:10 1-0f732990-efd2-44da-853d-c08dc8d3d345-0.parquet
# drwxr-xr-x 2 NBuser NBuser 4096 Jan 30 18:10 _delta_log
FAQ¶
A continuación se recogen preguntas habituales sobre los conceptos de esta sesión que suelen realizarse en entrevistas de trabajo para puestos de ingeniería o ciencia de datos.
Despliega cada pregunta para ver una respuesta orientativa; no hay una única respuesta correcta, pero sí aspectos clave que conviene mencionar.
¿Qué propiedades ACID garantiza Delta Lake y cómo las implementa?
Delta Lake garantiza las cuatro propiedades ACID sobre un data lake:
- Atomicidad: una transacción se aplica completa o no se aplica en absoluto.
- Consistencia: el estado de la tabla siempre es válido tras cada commit.
- Aislamiento: las transacciones concurrentes no se interfieren entre sí (control de concurrencia optimista).
- Durabilidad: los commits son permanentes una vez escritos en el transaction log.
Se implementan mediante un transaction log (_delta_log/) en formato JSON que registra cada operación atómicamente. Si una escritura falla a mitad, el log no registra el commit y los ficheros huérfanos se limpian con VACUUM.
¿Cómo funciona el control de concurrencia optimista en Delta Lake?
Cuando dos escrituras concurrentes ocurren sobre la misma tabla Delta, cada una lee el estado actual del transaction log, realiza sus cambios en ficheros nuevos y luego intenta hacer el commit. Si entre tanto otro proceso ha hecho commit modificando los mismos datos, la operación conflictiva falla con un error de conflicto. Si los cambios afectan a datos distintos (por ejemplo, particiones diferentes), Delta resuelve el conflicto automáticamente y aplica ambos commits. Esto permite alto paralelismo sin necesidad de bloqueos pesimistas.
¿Qué es el time travel en Delta Lake y cómo se usa?
Delta Lake mantiene un historial de todas las versiones de una tabla gracias al transaction log. Esto permite consultar el estado de la tabla en un momento pasado (time travel) de dos formas:
# Por número de versión
df = spark.read.format("delta").option("versionAsOf", 3).load("ruta/tabla")
# Por marca de tiempo
df = spark.read.format("delta").option("timestampAsOf", "2024-01-15").load("ruta/tabla")
Es útil para auditorías, reproducibilidad de experimentos y recuperación ante errores.
¿Qué hace el comando VACUUM y qué precaución hay que tener?
VACUUM elimina los ficheros Parquet que ya no forman parte de ninguna versión activa de la tabla, liberando espacio en disco. Por defecto respeta un período de retención de 7 días (168 horas) para permitir el time travel a versiones recientes. Reducir ese período por debajo del valor por defecto puede imposibilitar la recuperación de versiones antiguas:
from delta.tables import DeltaTable
dt = DeltaTable.forPath(spark, "ruta/tabla")
dt.vacuum(retentionHours=168) # 7 días por defecto
¿Cuál es la diferencia entre Delta Lake, Apache Iceberg y Apache Hudi?
Los tres son formatos de tabla abiertos que añaden capacidades transaccionales a los data lakes, pero tienen enfoques distintos:
| Delta Lake | Apache Iceberg | Apache Hudi | |
|---|---|---|---|
| Origen | Databricks | Netflix / Apple | Uber |
| Motor principal | Spark (nativo) | Multi-engine | Spark / Flink |
| Punto fuerte | Integración Spark, madurez | Multi-engine, evolución de esquema avanzada | Upserts / CDC con baja latencia |
| Open source | Sí (Linux Foundation) | Sí (Apache) | Sí (Apache) |
Hoy los tres son compatibles con los principales motores de consulta (Spark, Trino, Flink, Hive).
¿Qué es la arquitectura Medallion y qué capas la componen?
La arquitectura Medallion organiza los datos de un lakehouse en tres capas de calidad creciente:
- Bronze (bronce): datos en crudo tal como llegan de las fuentes, sin transformar. Se conservan para poder reprocesar.
- Silver (plata): datos limpios, validados y enriquecidos, listos para análisis intermedios.
- Gold (oro): datos agregados y modelados para casos de uso específicos de negocio (dashboards, ML…).
Esta separación permite la trazabilidad completa del dato, la reutilización de cada capa y la recuperación ante errores reprocesando desde Bronze.
Referencias¶
- Construir data lakes fiables con Delta Lake - Carlos del Cacho
- Delta Lake. The definitive guide
- Delta Lake Cheat-sheet
- Delta Lake: Up and Running - Bennie Haelen - O'Reilly
- Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
- The Internals of Delta Lake
Actividades¶
(RASBD.1 / CESBD.1b y CESBD.1d) En las siguientes actividades vamos a practicar con el uso de Delta Lake y el concepto de Data Lakehouse. Para ello, vamos a utilizar los datos de ventas (salesdata.zip) de la actividad opcional de la sesión anterior, donde renombrábamos columnas y posteriormente una serie de agregaciones para visualizar en gráficos el resultado.
-
(2p) Haciendo uso del cluster de Docker o de Databricks y siguiendo la arquitectura Medallion, se pide:
-
Crea y utiliza una base de datos llamada
iabd. -
Capa Bronze:
-
Carga en un DataFrame todos los datos de ventas. Para ello, descomprime el zip en tu ordenador, y sube los archivos, bien a un bucket de Minio en la ruta
s3a://sales/rawo bien a un volumensalesdentro del catalogo de Databricks. Posteriormente, puedes leer todos los datos mediante:# Si usas Docker con MinIO df_ventas = spark.read.option("header", "true").csv("s3a://sales/raw") # Si usas Databricks df_ventas = spark.read.option("header", "true").csv("/Volumes/workspace/default/sales/*.csv") -
El primer paso será renombrar las columnas para eliminar los espacios en blanco.
- Añade una columna
ingestion_timecon la fecha actual, y otra columnasource_systemdonde le asignes el valor literalcarga inicial CSV. -
Almacena el DataFrame en:
- Si usas Docker con MinIO en la ruta
s3a://sales/bronze/con formato Delta. - Si usas Databricks en la tabla
sales_bronzecon formato Delta.
- Si usas Docker con MinIO en la ruta
-
-
Capa Silver:
-
Realiza las siguientes operaciones de limpieza:
- Elimina las filas que contengan algún campo nulo.
- Comprueba si las cabeceras de los archivos aparecen como datos del dataset (por ejemplo, un producto cuyo nombre sea
Product). Si fuera el caso, elimina dichas filas. - A partir del campo dirección, crea dos nuevas columnas para almacenar la ciudad (
City) y el estado (State). Por ejemplo, para la dirección136 Church St, New York City, NY 10001, la ciudad esNew York Cityy el estado esNY. - Modifica el campo con la fecha del pedido para que su formato sea timestamp.
- Sobre el campo anterior, crea dos nuevas columnas, con el mes (
Month) y el año (Year) del pedido.
-
Almacena el resultado en formato Delta particionando los datos por año, ya sea en
s3a://sales/silver/si usas MinIO o en la tablasales_silversi usas Databricks.
-
-
Capa Gold:
-
Nos piden realizar las siguientes consultas:
- Cantidad total recaudada cada mes durante el año 2019.
- Gráfico con las diez ciudades que más unidades han vendido.
-
Almacena sus resultados en formato Delta en la srutas que consideres oportunas, utilizando los nombres
ventas2019_deltaytop10ciudades_deltapara las tablas o rutas donde almacenes los resultados.
-
-
Adjunta capturas de pantalla de los resultados obtenidos en cada una de las capas, así como del esquema de las tablas creadas, donde se reflejen los archivos creados (por ejemplo, el particionado de la capa Silver, o el número de archivos creados en cada capa).
-
-
(2p) Tras una auditoria, hemos descubierto que había un libro oculto de contabilidad con ciertas ventas que no habían sido registradas en el sistema. Así pues, crea datos ficticios extra de ventas para el año 2019, colócalo en la capa Bronze, y a continuación, actualiza los datos del resto de capas, fusionando los nuevos datos con los ya existentes.
-
(1p) Obtén el histórico de la capa Bronze y las tablas Gold. Recupera la primera versión de la tabla que obtiene la recaudación mensual de 2019 y compara su contenido con el actual.