HDFS¶
Es la capa de almacenamiento de Hadoop, y como tal, es un sistema de ficheros distribuido y tolerante a fallos que puede almacenar gran cantidad de datos, escalar de forma incremental y sobrevivir a fallos de hardware sin perder datos. Se basa en el paper que publicó Google detallando su Google File System en 2003.
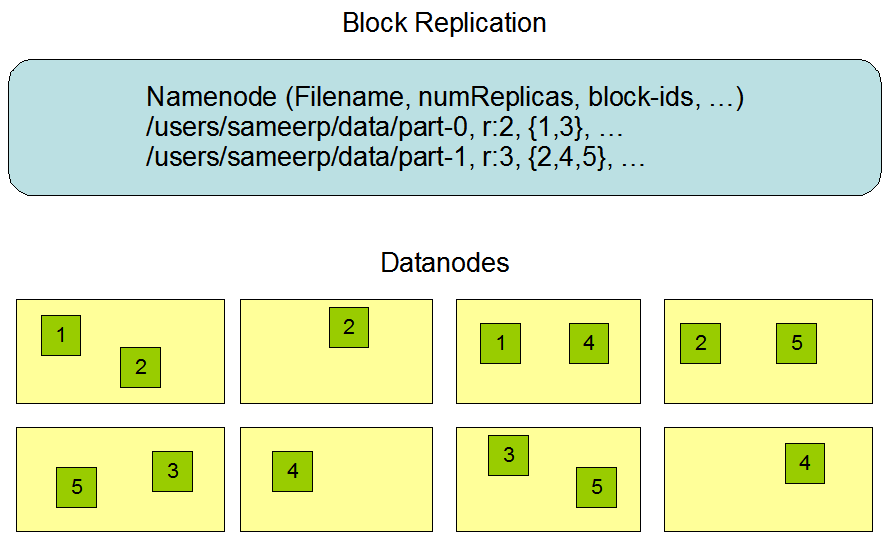
Es un sistema que reparte los datos entre todos los nodos del clúster de Hadoop, dividiendo los ficheros en bloques (cada bloque por defecto es de 128MB) y almacenando copias duplicadas a través de los nodos. Por defecto se replica en 3 nodos distintos (esto se conoce como el factor de replicación).
HDFS asegura que se puedan añadir servidores para incrementar el tamaño de almacenamiento de forma lineal, de manera que al introducir un nuevo nodo, se incrementa tanto la redundancia como la capacidad de almacenamiento.
Está planteado para escribir los datos una vez y leerlos muchos veces (WORM / Write Once, Read Many). Las escrituras se pueden realizar a mano, o desde herramientas como Spark, Flume o Sqoop, que estudiaremos más adelante.
No ofrece buen rendimiento para:
- Accesos de baja latencia. Realmente se utiliza para almacenar datos de entrada necesarios para procesos de computación.
- Ficheros pequeños (a menos que se agrupen). Funciona mejor con grandes cantidades de ficheros grandes, es decir, mejor millones de ficheros de 100MB que billones de ficheros de 1MB.
- Múltiples escritores.
- Modificaciones arbitrarias de ficheros.
Además, una vez escritos los datos en HDFS son immutables. Cada fichero de HDFS solo permite añadir contenido (append-only). Una vez se ha creado y escrito en él, solo podemos añadir contenido o eliminarlo. Es decir, a priori, no podemos modificar los datos.
HBase / Hive
Tanto HBase como Hive ofrecen una capa por encima de HDFS para dar soporte a la modificación de los datos, como en cualquier base de datos.
Bloques¶
Un bloque es la cantidad mínima de datos que puede ser leída o escrita. El tamaño predeterminado de HDFS son 128 MB, ya que como hemos comentado, Hadoop está pensado para trabajar con ficheros de gran tamaño.
Todos los ficheros están divididos en bloques. Esto quiere decir que si subimos un fichero de 600MB, lo dividirá en 5 bloques de 128MB. Estos bloques se distribuyen por todos los nodos de datos del clúster de Hadoop.
Si un fichero de HDFS es menor que el tamaño de un bloque, es decir, menor de 128MB, ocupará un bloque lógico pero en disco únicamente ocupará el espacio necesario. Es decir, un archivo de 1MB ocupará un bloque de 128MB, pero utilizará 1MB en disco.
A partir del factor de replicación, cada bloque se almacena varias veces en máquinas distintas. El valor por defecto es 3. Por lo tanto, el archivo de 600MB que teníamos dividido en 5 bloques de 128MB, si lo replicamos tres veces, lo tendremos repartido en 15 bloques entre todos los nodos del clúster.
Respecto a los permisos de lectura y escritura de los ficheros, sigue la misma filosofía de asignación de usuarios y grupos que se realiza en los sistemas Posix. Es una buena práctica crear una carpeta /user/ en el raíz de HDFS, de forma similar al /home/ de Linux.
En HDFS se distinguen las siguientes máquinas:
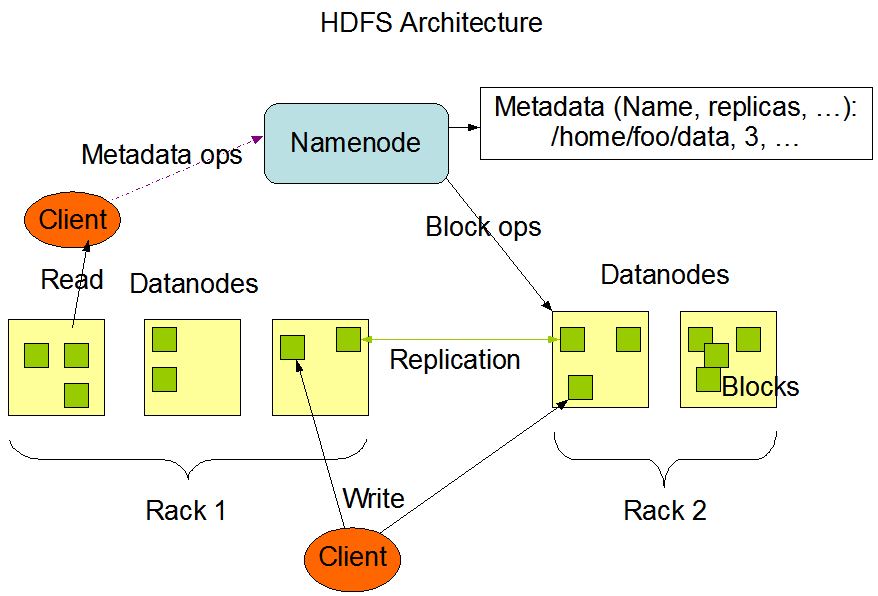
- Namenode: Actúa como máster y almacena todos los metadatos necesarios para construir el sistema de ficheros a partir de sus bloques. Tiene control sobre dónde están todos los bloques.
- Datanode: Son los esclavos, se limitan a almacenar los bloques que componen cada fichero.
- Secondary Namenode: Su función principal es tomar puntos de control de los metadatos del sistema de archivos presentes en el Namenode.
Trabajando con HDFS¶
Para interactuar con el almacenamiento desde un terminal, se utiliza el comando hdfs. Este comando admite un segundo parámetro con diferentes opciones.
Ante la duda, es recomendable consultar la documentación oficial
hdfs comando
hadoop fs
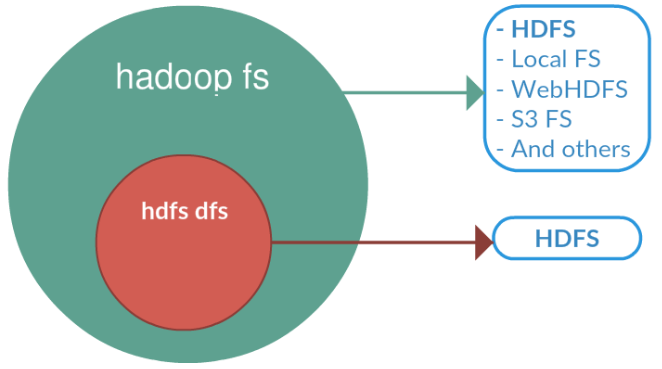
hadoop fs se relaciona con un sistema de archivos genérico que puede apuntar a cualquier otro, como local, HDFS, FTP, S3, etc. En versiones anteriores se utilizaba el comando hadoop dfs para acceder a HDFS, pero ha quedado obsoleto en favor de hdfs dfs.
En el caso concreto de interactuar con el sistema de ficheros de Hadoop se utiliza el comando dfs, el cual requiere de otro argumento (empezando con un guion) el cual será uno de los comandos Linux para interactuar con el shell. Podéis consultar la lista de comandos en la documentación oficial.
hdfs dfs -comandosLinux
Por ejemplo, para mostrar todos los archivos que tenemos en el raíz haríamos:
hdfs dfs -ls
Los comandos más utilizados son:
put(ocopyFromLocal): Coloca un archivo dentro de HDFSget(ocopyToLocal): Recupera un archivo de HDFS y lo lleva a nuestro sistema host.getmerge: fusiona varios archivos de una carpeta y lo lleva como un único archivo a nuestro sistema host.cat/text/head/tail: Visualiza el contenido de un archivo.mkdir/rmdir: Crea / borra una carpeta.count: Cuenta el número de elementos (número de carpetas, ficheros, tamaño y ruta).cp/mv/rm: Copia / mueve-renombra / elimina un archivo.
Durante la realización de los ejercicios, es muy común necesitar eliminar una carpeta y todo los archivos que contiene. Para ello, podemos hacer un borrado recursivo:
hdfs dfs -rm -r /user/iabd/datos
Autoevaluación
¿Sabes qué realiza cada uno de los siguientes comandos?
hdfs dfs -mkdir /user/iabd/datos
hdfs dfs -put ejemplo.txt /user/iabd/datos/
hdfs dfs -put ejemplo.txt /user/iabd/datos/ejemploRenombrado.txt
hdfs dfs -ls datos
hdfs dfs -count datos
hdfs dfs -mv datos/ejemploRenombrado.txt /user/iabd/datos/otroNombre.json
hdfs dfs -get /datos/otroNombre.json /tmp
CRC
Cuando recuperamos un archivo desde HDFS podemos indicarle que genere un fichero con el checksum CRC, y así poder comprobar la fiabilidad de los datos transmitidos.
hdfs dfs -get -crc /user/iabd/archivo archivoLocal
Namenodes y Datanodes¶
Si revisamos la arquitectura de HDFS, vemos que existen dos tipos de nodos principales: Namenode y Datanode:
Vamos a profundizar en sus elementos.
Namenode¶
El principal se conoce como Namenode:
- Solo existe uno y actúa como servidor principal.
- Nodo al que se tienen que conectar los clientes para realizar las lecturas / escrituras.
- Mantiene el árbol del sistema de archivos (espacio de nombre) y los metadatos para todos los ficheros y directorios en el árbol, de manera que sabe en qué nodo del clúster está cada bloque de información (mapa de bloques)
- Los metadatos se almacenan tanto en memoria (para acelerar su uso) como en disco a la vez, por lo que es un nodo que requiere de mucha memoria RAM.
- Los bloques nunca pasan por el Namenode, se transfieren entre Datanodes y/o el cliente. Es decir, el Namenode no es responsable de almacenar o transferir los datos.
- Si se cae, no hay acceso a HDFS, por lo que es crítico el mantenimiento de copias de seguridad.
El segundo tipo es el Secondary Namenode:
- Su función principal es guardar una copia de FsImage y EditLog:
- FsImage: instantánea de los metadatos del sistema de archivos.
- EditLog: registro de transacciones que contiene los registros de cada cambio (deltas) que se produce en los metadatos del sistema de archivos.
- No se trata de un nodo de respaldo
- Por lo general se ejecuta en una máquina distinta
Además de distribuir los bloques entre distintos nodos de datos, también los replica (con un factor de replicación igual a tres, los replicaría en 3 nodos diferentes, 2 en el mismo rack y 1 en otro diferente) para evitar pérdidas de información si alguno de los nodos falla.
Cuando una aplicación cliente necesita leer o modificar un bloque de datos, el Namenode le indica en qué nodo se localiza esa información. También se asegura de que los nodos no estén caídos y que la información esté replicada, para asegurar su disponibilidad aún en estos casos.
Para hacernos una idea, independientemente del cloud, Facebook utiliza un clúster de 1100 máquinas, con 8800 nodos y cerca de 12 PB de almacenamiento.
Datanode¶
- De este tipo de nodo habrá más de uno en cada clúster. Por cada Namenode podemos tener miles de Datanodes.
- Almacena y lee bloques de datos.
- Recuperado por Namenode clientes.
- Reportan al Namenode la lista de bloques que están almacenando.
- Pueden ir en distintos discos.
- Guarda un checksum (CRC) del bloque.
Los Datanodes están organizados en racks (armarios físicos), por ejemplo Rack 1, Rack 2, etc. Cada rack contiene varios nodos (servidores físicos). Por ejemplo: Rack 2 contiene Nodo 5, Nodo 6 y Nodo 7. Es una buena práctica colocar réplicas en racks distintos para evitar perder datos si se cae un rack entero (por ejemplo, un switch).
Procesos de lectura¶
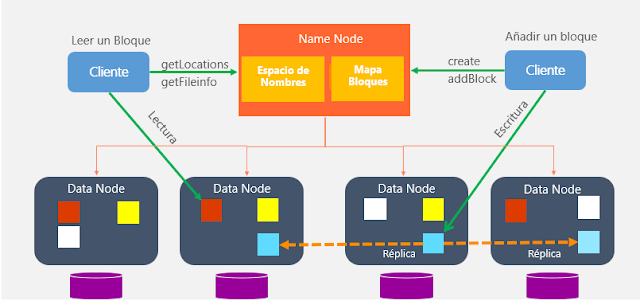
Vamos a revisar como fluyen los datos en un proceso de lectura entre el cliente y HDFS a partir de la siguiente imagen:
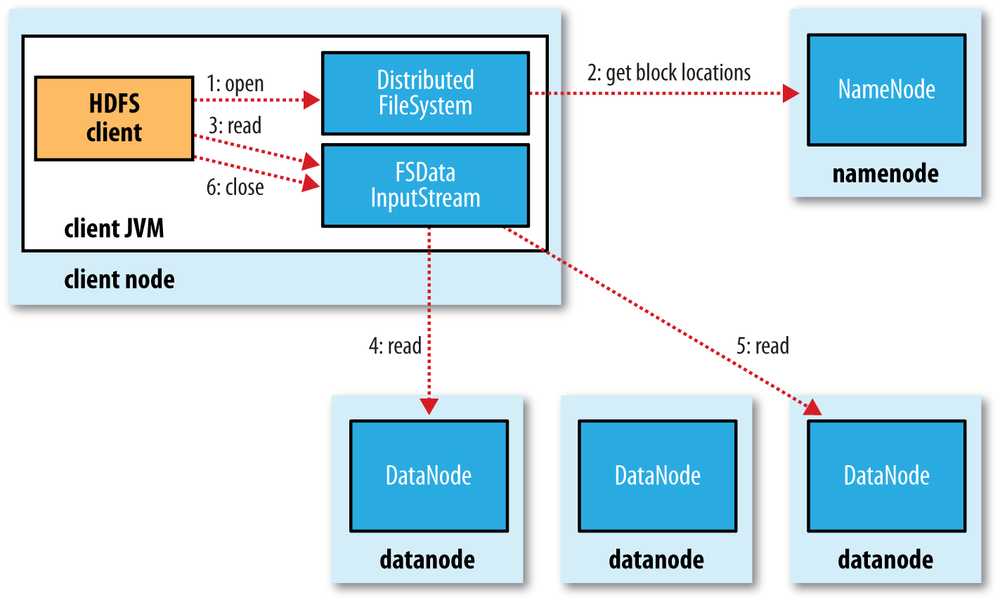
- El cliente abre el fichero que quiere leer mediante el método
open()del sistema de archivos distribuido. - Éste llama al namenode mediante una RPC (llamada a procedimiento remoto) el cual le indica la ubicación del primer bloque del fichero. Para cada bloque, el namenode devuelve la dirección de los datanodes que tienen una copia de ese bloque. Además, los datanodes se ordenan respecto a su proximidad con el cliente (depende de la topología de la red y despliegue en datacenter/rack/nodo). Si el cliente en sí es un datanode, la lectura la realizará desde su propio sistema local.
- El sistema de ficheros distribuido devuelve al cliente un FSDataInputStream (un flujo de entrada que soporta la búsqueda de ficheros), sobre el cual se invoca la lectura mediante el método
read(). Este flujo, que contiene las direcciones de los datanodes para los primeros bloques del fichero, conecta con el datanode más cercano para la lectura del primer bloque. - Los datos se leen desde el datanode con llamadas al método
read(). Cuando se haya leído el bloque completo, el flujo de entrada cerrará la conexión con el datanode actual y buscará el mejor datanode para el siguiente bloque. - Se repite el paso anterior (siempre de manera transparente para el cliente, el cual solo está leyendo datos desde un flujo de datos continuo).
- Cuando el cliente finaliza la lectura, cierra la conexión con el flujo de datos.
Durante la lectura, si el flujo encuentra un error al comunicarse con un datanode (o un error de checksum), intentará el proceso con el siguiente nodo más cercano (además, recordará los nodos que han fallado para no realizar reintentos en futuros bloques y/o informará de los bloque corruptos al namenode)
Namenode sin datos
Recordad que los datos nunca pasan por el namenode. El cliente que realiza la conexión con HDFS es el que hace las operaciones de lectura/escritura directamente con los datanodes. Este diseño permite que HDFS escale de manera adecuada, ya que el tráfico de los clientes se esparce por todos los datanodes de nuestro clúster.
Proceso de escritura¶
El proceso de escritura en HDFS sigue un planteamiento similar. Vamos a analizar la creación, escritura y cierre de un archivo con la siguiente imagen:
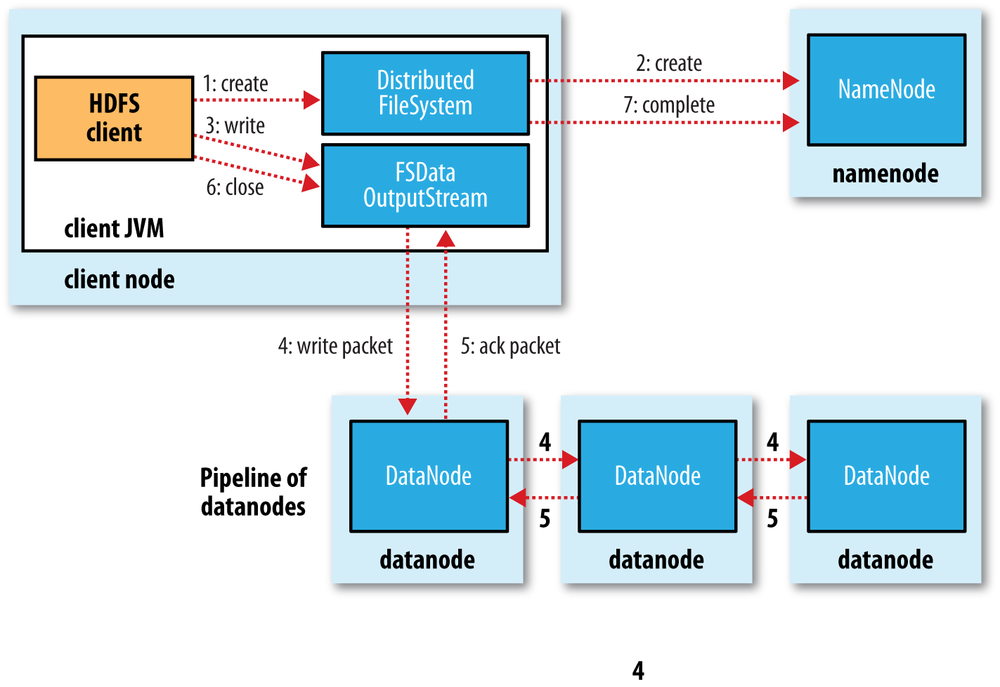
- El cliente crea el fichero mediante la llamada al método
create()del DistributedFileSystem. - Este realiza una llamada RPC al namenode para crear el fichero en el sistema de ficheros del namenode, sin ningún bloque asociado a él. El namenode realiza varias comprobaciones para asegurar que el fichero no existe previamente y que el usuario tiene los permisos necesarios para su creación. Tras ello, el namenode determina la forma en que va a dividir los datos en bloques y qué datanodes utilizará para almacenar los bloques.
- El DistributedFileSystem devuelve un FSDataOutputStream el cual gestiona la comunicación con los datanodes y el namenode para que el cliente comience a escribir los datos de cada bloque en el namenode apropiado.
- Conforme el cliente escribe los datos, el flujo obtiene del namenode una lista de datanodes candidatos para almacenar las réplicas. La lista de nodos forman un pipeline, de manera que si el factor de replicación es 3, habrá 3 nodos en el pipeline. El flujo envía los paquete al primer datanode del pipeline, el cual almacena cada paquete y los reenvía al segundo datanode del pipeline. Y así sucesivamente con el resto de nodos del pipeline.
- Cuando todos los nodos han confirmado la recepción y almacenamiento de los paquetes, envía un paquete de confirmación al flujo.
- Cuando el cliente finaliza con la escritura de los datos, cierra el flujo mediante el método
close()el cual libera los paquetes restantes al pipeline de datanodes y queda a la espera de recibir las confirmaciones. Una vez confirmado, le indica al namenode que la escritura se ha completado, informando de los bloques finales que conforman el fichero (puede que hayan cambiado respecto al paso 2 si ha habido algún error de escritura).
HDFS por dentro¶
HDFS utiliza un conjunto de ficheros que gestionan los cambios que se producen en el clúster.
Para saber donde se almacenan los datos, primero hemos de entrar en $HADOOP_HOME/etc/hadoop y averiguar la carpeta de datos que tenemos configurada en hdfs-site.xml para el namenode:
<property>
<name>dfs.name.dir</name>
<value>file:///opt/hadoop-data/hdfs/namenode</value>
</property>
Desde nuestro sistema de archivos, accedemos a dicha carpeta y vemos que existe una carpeta current que contendrá un conjunto de ficheros cuyos prefijos son:
edits_000NNN: histórico de cambios que se van produciendo.edits_inprogress_NNN: cambios actuales en memoria que no se han persistido.fsimagen_000NNN: snapshot en el tiempo del sistema de ficheros.
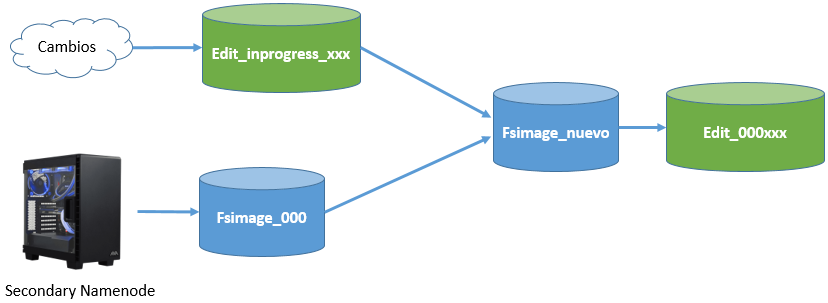
Al arrancar HDFS se carga en memoria el último fichero fsimage disponible junto con los edits que no han sido procesados. Mediante el secondary namenode, cuando se llena un bloque, se irán sincronizando los cambios que se producen en edits_inprogress creando un nuevo fsimage y un nuevo edits.
Así pues, cada vez que se reinicie el namenode, se realizará el merge de los archivos fsimage y edits log.
Bloques¶
A continuación vamos a ver cómo trabaja internamente HDFS con los bloques. Para el siguiente ejemplo, vamos a trabajar con un archivo que ocupe más de un bloque, como pueden ser los datos de 25 millones de películas. Una vez descargado y descomprimido, colocaremos el archivo ratings.csv dentro de HDFS.
Comenzaremos creando un directorio dentro de HDFS llamado prueba-hdfs:
hdfs dfs -mkdir /user/iabd/prueba-hdfs
Una vez creado subimos el archivo con las calificaciones de las películas:
hdfs dfs -put ratings.csv /user/iabd/prueba-hdfs
Si queremos saber cuantos bloques ha creado y cuanto ocupa cada uno de ellos, por ejemplo, podemos utilizar la utilidad fsck que permite comprobar la salud del sistema de archivos. Si le pasamos las opciones -files y -blocks nos mostrará información tanto de los archivos como de los bloques contenidos:
iabd@iabd-virtualbox:$ hdfs fsck /user/iabd/prueba-hdfs -files -blocks
Connecting to namenode via http://iabd-virtualbox:9870/fsck?ugi=iabd&files=1&blocks=1&path=%2Fuser%2Fiabd%2Fprueba-hdfs
FSCK started by iabd (auth:SIMPLE) from /127.0.0.1 for path /user/iabd/prueba-hdfs at Sun Jan 22 18:11:45 CET 2023
/user/iabd/prueba-hdfs <dir>
/user/iabd/prueba-hdfs/ratings.csv 678260987 bytes, replicated: replication=1, 6 block(s): OK
0. BP-481169443-127.0.1.1-1639217848073:blk_1073750565_9750 len=134217728 Live_repl=1
1. BP-481169443-127.0.1.1-1639217848073:blk_1073750566_9751 len=134217728 Live_repl=1
2. BP-481169443-127.0.1.1-1639217848073:blk_1073750567_9752 len=134217728 Live_repl=1
3. BP-481169443-127.0.1.1-1639217848073:blk_1073750568_9753 len=134217728 Live_repl=1
4. BP-481169443-127.0.1.1-1639217848073:blk_1073750569_9754 len=134217728 Live_repl=1
5. BP-481169443-127.0.1.1-1639217848073:blk_1073750570_9755 len=7172347 Live_repl=1
Status: HEALTHY
Number of data-nodes: 1
Number of racks: 1
Total dirs: 1
Total symlinks: 0
...
Si queremos utilizar el interfaz gráfico de Hadoop (http://iabd-virtualbox:9870/explorer.html#/), tras localizar el archivo, obtenemos el Block Pool ID del block information:
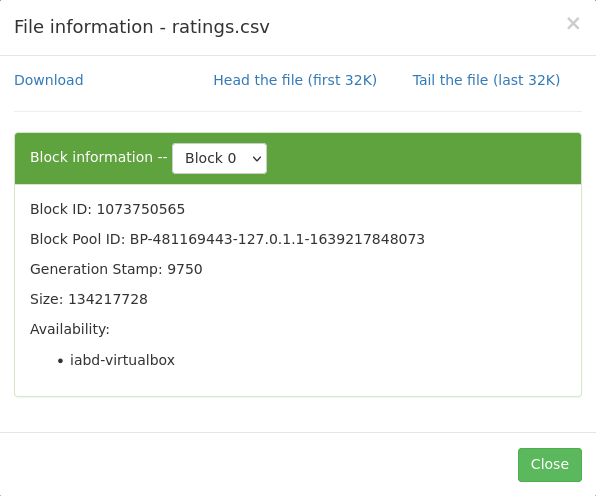
Si desplegamos el combo de block information, podremos ver cómo ha partido el archivo CSV en 6 bloques (650 MB aproximadamente que ocupa el fichero CSV / 128 del tamaño del bloque).
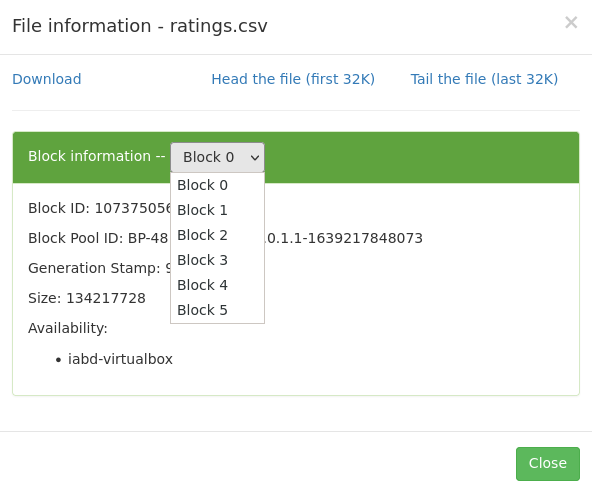
Así pues, con el código del Block Pool Id, podemos confirmar que debe existir el directorio current del datanode donde almacena la información nuestro servidor (en `/opt/hadoop-data/):
iabd@iabd-virtualbox:~$ ls /opt/hadoop-data/hdfs/datanode/current
BP-481169443-127.0.1.1-1639217848073 VERSION
El valor que aparece coincide con el que hemos recuperado tanto en la imagen como mediante fsck.
Dentro de este subdirectorio existe otro finalized, donde Hadoop irá creando una estructura de subdirectorios subdir donde albergará los bloques de datos:
iabd@iabd-virtualbox:~$ ls /opt/hadoop-data/hdfs/datanode/current/BP-481169443-127.0.1.1-1639217848073/current/finalized/subdir0
total 172
drwxrwxr-x 2 iabd iabd 20480 dic 22 2021 subdir0
drwxrwxr-x 2 iabd iabd 20480 dic 22 2021 subdir1
drwxrwxr-x 2 iabd iabd 20480 dic 22 2021 subdir2
...
Una vez en este nivel, vamos a buscar el archivo que coincide con el block id poniéndole como prefijo blk_:
iabd@iabd-virtualbox:~$ cd /opt/hadoop-data/hdfs/datanode/current/BP-481169443-127.0.1.1-1639217848073/current/finalized/subdir0
iabd@iabd-virtualbox:/opt/hadoop-data/hdfs/datanode/current/BP-481169443-127.0.1.1-1639217848073/current/finalized/subdir0$ \
> find -name blk_1073750565
En mi caso devuelve ./subdir2/blk_1073750565. De manera que ya podemos comprobar como el inicio del documento se encuentra en dicho archivo:
iabd@iabd-virtualbox:/opt/hadoop-data/hdfs/datanode/current/BP-481169443-127.0.1.1-1639217848073/current/finalized/subdir0$ \
> cd subdir2
iabd@iabd-virtualbox:/opt/hadoop-data/hdfs/datanode/current/BP-481169443-127.0.1.1-1639217848073/current/finalized/subdir0/subdir9$ \
> head blk_1073750565
userId,movieId,rating,timestamp
1,296,5.0,1147880044
1,306,3.5,1147868817
1,307,5.0,1147868828
1,665,5.0,1147878820
1,899,3.5,1147868510
1,1088,4.0,1147868495
1,1175,3.5,1147868826
1,1217,3.5,1147878326
1,1237,5.0,1147868839
Ejecución de una aplicación en YARN y HDFS
Ahora que ya conocemos HDFS, ya podemos entender cómo se realiza el proceso completo desde que se envía una aplicación hasta que los resultados se escriben en HDFS, incluyendo todos los componentes de YARN, destacando como YARN gestiona dónde y cómo se ejecuta el código, mientras HDFS gestiona dónde están los datos, y la coordinación entre ambos optimiza el rendimiento mediante data locality:
-
Envío de la aplicación. El cliente envía una aplicación (por ejemplo, un job de Spark o MapReduce) al ResourceManager.
-
Negociación de recursos para Application Master. El ResourceManager consulta al Scheduler para asignar un contenedor inicial donde ejecutar el Application Master. Por ejemplo:
- ResourceManager → Scheduler: "¿Dónde puedo lanzar un Application Master?"
- Scheduler → ResourceManager: "Hay recursos disponibles en NodeManager-3"
- ResourceManager → NodeManager-3: "Lanza un contenedor para Application Master"
-
El NodeManager inicia el Application Master en un contenedor. Por ejemplo:
- NodeManager-3 → Container: Crea contenedor con recursos asignados
- NodeManager-3 → Application Master: Inicia AM dentro del contenedor
- Application Master: "Estoy listo, necesito analizar qué recursos necesito"
-
Application Master analiza el job y solicita recursos al ResourceManager para ejecutar las tareas. Por ejemplo:
- Application Master → ResourceManager: "Necesito 10 contenedores con 4GB RAM y 2 cores cada uno"
- ResourceManager → Scheduler: "Asigna recursos para estos contenedores"
A continuación, Application Master también consulta al Namenode de HDFS para conocer dónde están los datos:
- Application Master → Namenode: "¿Dónde están los bloques del archivo
input.txt?" - Namenode → Application Master: "Bloque 1 en Datanode-2, Bloque 2 en Datanode-5, Bloque 3 en Datanode-7..."
-
Scheduler intenta asignar contenedores en nodos donde ya están los datos (data locality). Por ejemplo:
- Scheduler: "Bloque 1 está en Datanode-2, asignaré contenedor en NodeManager-2"
- Scheduler → ResourceManager: "Contenedores asignados en NodeManager-2, 5, 7..."
- ResourceManager → Application Master: "Aquí están tus contenedores asignados"
Los niveles de data locality son:
NODE_LOCAL: Contenedor en el mismo nodo que los datos (óptimo)RACK_LOCAL: Contenedor en el mismo rackOFF_SWITCH: Contenedor en diferente rack (requiere transferencia por red)
-
Application Master solicita a los NodeManagers que lancen los contenedores:
- Application Master → NodeManager-2: "Lanza contenedor y ejecuta Tarea-1"
- Application Master → NodeManager-5: "Lanza contenedor y ejecuta Tarea-2"
- Application Master → NodeManager-7: "Lanza contenedor y ejecuta Tarea-3"
A continuación, los NodeManagers crean los contenedores:
- NodeManager-2 → Container-Tarea1: Crea contenedor con recursos
- NodeManager-2 → Container-Tarea1: Ejecuta código de la tarea
-
Ejecución de tareas y lectura de HDFS, de manera que cada Task, en su contenedor, lee datos de HDFS:
- Tarea-1 (en NodeManager-2) → Datanode-2: "Dame el Bloque-1"
- Datanode-2 → Tarea-1: [Datos del bloque]
- Tarea-1: Procesa los datos...
Como Tarea-1 corre en el mismo nodo que Datanode-2, la lectura es local en lugar de por red.
-
Monitoreo y heartbeats (mensajes periódicos para monitorizar el estado), ya que, durante la ejecución, hay comunicación constante:
- NodeManager → ResourceManager: Heartbeat cada 3 segundos
- "Estoy vivo"
- "Contenedor-X usa 2GB RAM, 50% CPU"
- "Tarea-1 completada al 60%"
- Application Master → ResourceManager: Heartbeat
- "Mi aplicación está al 45%"
- "Necesito 2 contenedores más"
- Datanode → Namenode: Heartbeat
- "Estoy vivo"
- "Tengo Bloques 1, 5, 8, 12..."
- NodeManager → ResourceManager: Heartbeat cada 3 segundos
-
Shuffle y procesamiento intermedio
En aplicaciones MapReduce, hay una fase de shuffle donde los datos se redistribuyen:
- Tarea-Map-1 (en NodeManager-2): Termina, genera resultados intermedios
-
Tarea-Map-1 → Disco local: Escribe resultados en disco local del nodo
-
Application Master: "Mappers completados, lanzar Reducers"
-
Application Master → NodeManager-4: "Lanza Reducer-1"
-
Tarea-Reducer-1 → Tarea-Map-1, Map-2, Map-3: "Dame tus datos intermedios"
- [Transferencia de datos por red - shuffle]
- Tarea-Reducer-1: Procesa y reduce datos...
-
Cuando las tareas se completan, escriben los resultados a HDFS:
- Tarea-Reducer-1 → Namenode: "Quiero escribir archivo
output/part-00001" -
Namenode → Tarea-Reducer-1: "Escribe en Datanode-3, Datanode-6, Datanode-9"
- Tarea-Reducer-1 → Datanode-3: Escribe bloque (réplica 1)
- Tarea-Reducer-1 → Datanode-6: Escribe bloque (réplica 2)
- Tarea-Reducer-1 → Datanode-9: Escribe bloque (réplica 3)
-
Datanode-3, 6, 9 → Namenode: "Bloque escrito exitosamente"
- Namenode: Actualiza metadatos del archivo
El pipeline de escritura en HDFS es:
- El cliente (la tarea) contacta con el Namenode
- El Namenode devuelve la lista de Datanodes
- El cliente escribe al primer Datanode
- El primer Datanode replica al segundo
- Y finalmente, el segundo Datanode replica al tercero (suponiendo un factor de replicación de 3)
- Tarea-Reducer-1 → Namenode: "Quiero escribir archivo
-
Finalización y limpieza
- Tarea-Reducer-1 → Application Master: "Tarea completada exitosamente"
- Application Master: "Todas las tareas completadas"
-
Application Master → ResourceManager: "Job completado, libero recursos"
- ResourceManager → NodeManager-2, 5, 7, 4: "Liberen contenedores"
- NodeManager → Containers: Termina y libera recursos (RAM, CPU)
-
Application Master → Cliente: "Job completado exitosamente"
- Application Master: Se termina a sí mismo
-
Cliente verifica resultados
- Cliente → Namenode: "¿Dónde están los archivos
output/*?" - Namenode → Cliente: "
output/part-00001en Datanodes 3,6,9..." - Cliente → Datanode-3: "Dame
output/part-00001" - Cliente: Lee y verifica resultados
- Cliente → Namenode: "¿Dónde están los archivos
En resumen, los componentes implicados son:
YARN (Gestión de Recursos) HDFS (Almacenamiento)
================================ ========================
ResourceManager (Master) Namenode (Master)
├── Scheduler └── Metadata Manager
└── ApplicationsManager
NodeManager (Workers) Datanode (Workers)
├── Container Manager └── Block Storage
└── Ejecuta Containers
Application Master (Por job)
└── Coordina tareas específicas
Donde cada uno de ellos tiene las siguientes responsabilidades:
- ResourceManager: Orquestador global, asigna recursos del cluster
- Scheduler: Componente interno del ResourceManager que decide la asignación de recursos (ejemplos: CapacityScheduler, FairScheduler), tanto qué como dónde.
- NodeManager: Ejecutor local en cada nodo worker, gestionando los contenedores en ese nodo
- Application Master: Coordinador específico de cada aplicación.
- Container: Unidad de ejecución con recursos asignados (CPU, RAM)
- Task: Unidad de trabajo individual (ej: un mapper o reducer en MapReduce)
- Namenode: Directorio de archivos que mantiene metadatos de manera que sabe dónde están los bloques.
- Datanode: Nodos que almacenan y sirven bloques de datos en HDFS.
Administración¶
Algunas de las opciones más útiles para administrar HDFS son:
hdfs dfsadmin -report: Realiza un resumen del sistema HDFS, similar al que aparece en el interfaz web, donde podemos comprobar el estado de los diferentes nodos.hdfs fsck: como acabamos de ver, comprueba el estado del sistema de ficheros. Si queremos comprobar el estado de un determinado directorio, lo indicamos mediante un segundo parámetro:hdfs fsck /datos/pruebahdfs dfsadmin -printTopology: Muestra la topología, identificando los nodos que tenemos y al rack al que pertenece cada nodo.hdfs dfsadmin -listOpenFiles: Comprueba si hay algún fichero abierto.hdfs dfsadmin -safemode enter: Pone el sistema en modo seguro, el cual evita la modificación de los recursos del sistema de archivos.hdfs dfsadmin -safemode leave: Sale del modo seguro.
Snapshots¶
Mediante las snapshots podemos crear una instantánea que almacena cómo está en un determinado momento nuestro sistema de ficheros, a modo de copia de seguridad de los datos, para en un futuro poder realizar una recuperación.
El primer paso es activar el uso de snapshots, mediante el comando de administración indicando sobre qué carpeta vamos a habilitar su uso:
hdfs dfsadmin -allowSnapshot /user/iabd/datos
El siguiente paso es crear una snapshot, para ello se indica tanto la carpeta como un nombre para la captura (es un comando que se realiza sobre el sistema de archivos):
hdfs dfs -createSnapshot /user/iabd/datos snapshot1
Esta captura se creará dentro de una carpeta oculta dentro de la ruta indicada (en nuestro caso creará la carpeta /user/iabd/datos/.snapshot/snapshot1/ la cual contendrá la información de la instantánea).
A continuación, vamos a borrar uno de los archivo creados anteriormente y comprobar que ya no existe:
hdfs dfs -rm /user/iabd/datos/ejemplo.txt
hdfs dfs -ls /user/iabd/datos
Para comprobar el funcionamiento de los snapshots, vamos a recuperar el archivo desde la captura creada anteriormente.
hdfs dfs -cp \
/user/iabd/datos/.snapshot/snapshot1/ejemplo.txt \
/user/iabd/datos
Si queremos saber que carpetas soportan las instantáneas:
hdfs lsSnapshottableDir
Finalmente, si queremos deshabilitar las snapshots de una determinada carpeta, primero hemos de eliminarlas y luego deshabilitarlas:
hdfs dfs -deleteSnapshot /user/iabd/datos snapshot1
hdfs dfsadmin -disallowSnapshot /user/iabd/datos
HDFS UI¶
En la sesión anterior ya vimos que podíamos acceder al interfaz gráfico de Hadoop (http://iabd-virtualbox:9870/explorer.html#/) y navegar por las carpetas de HDFS.
Si intentamos crear una carpeta o eliminar algún archivo recibimos un mensaje del tipo Permission denied: user=dr.who, access=WRITE, inode="/":iabd:supergroup:drwxr-xr-x. Por defecto, los recursos via web los crea el usuario dr.who.
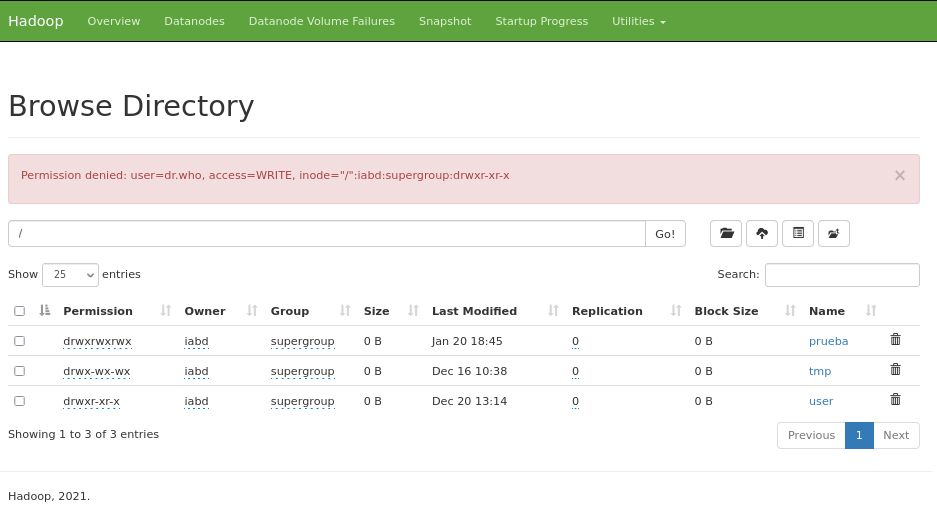
Si queremos habilitar los permisos para que desde este IU podamos crear/modificar/eliminar recursos, podemos cambiar permisos a la carpeta:
hdfs dfs -mkdir /user/iabd/pruebas
hdfs dfs -chmod 777 /user/iabd/pruebas
Si ahora accedemos al interfaz, sí que podremos trabajar con la carpeta pruebas via web, teniendo en cuenta que las operaciones las realiza el usuario dr.who que pertenece al grupo supergroup.
Otra posibilidad es modificar el archivo de configuración core-site.xml y añadir una propiedad para modificar el usuario estático:
<property>
<name>hadoop.http.staticuser.user</name>
<value>iabd</value>
</property>
Tras reiniciar Hadoop, ya podremos crear los recursos como el usuario iabd.
HDFS y Python¶
Para el acceso mediante Python a HDFS podemos utilizar la librería HdfsCLI.
Primero hemos de instalarla mediante pip:
pip install hdfs
Vamos a ver un sencillo ejemplo de lectura y escritura en HDFS:
from hdfs import InsecureClient
# Datos de conexión
HDFS_HOSTNAME = 'iabd-virtualbox'
HDFS_PORT = 9870
HDFSCLI_CONNECTION_STRING = f'http://{HDFS_HOSTNAME}:{HDFS_PORT}'
# En nuestro caso, al no usar Kerberos, creamos una conexión no segura
hdfs_client = InsecureClient(HDFSCLI_CONNECTION_STRING)
# Leemos el fichero de 'El quijote' que tenemos en HDFS
fichero = '/user/iabd/el_quijote.txt'
with hdfs_client.read(fichero) as reader:
texto = reader.read()
print(texto)
# Creamos una cadena con formato CSV y la almacenamos en HDFS
datos="nombre,apellidos\nAitor,Medrano\nPedro,Casas"
hdfs_client.write("/user/iabd/datos.csv", datos)
Actualmente la librería PyArrow es la más utilizada para trabajar con HDFS desde Python, ya que ofrece un alto rendimiento y soporte para los formatos de datos más comunes en el mundo del Big Data (como Parquet y Avro).
Así pues, si queremos utilizarla, primero hemos de instalarla:
pip install pyarrow
Classpath
Es probable que el classpath de Hadoop no esté correctamente configurado para que PyArrow pueda encontrar las librerías nativas de Hadoop. Para ello, hemos de exportar la variable de entorno HADOOP_CLASSPATH con el contenido del classpath de Hadoop:
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob)
Y luego, utilizar la clase HadoopFileSystem para conectarnos a HDFS. Así pues, podemos repetir el ejemplo anterior:
from pyarrow import fs
HDFS_HOSTNAME = 'iabd-virtualbox'
HDFS_PORT = 9000 # Puerto nativo de HDFS (no WebHDFS)
hdfs = fs.HadoopFileSystem(host=HDFS_HOSTNAME, port=HDFS_PORT)
# Leemos el fichero de 'El quijote' que tenemos en HDFS
fichero = '/user/iabd/el_quijote.txt'
with hdfs.open_input_stream(fichero) as reader:
texto = reader.read().decode('utf-8')
print(texto)
# Creamos una cadena con formato CSV y la almacenamos en HDFS
datos = "nombre,apellidos\nAitor,Medrano\nPedro,Casas"
with hdfs.open_output_stream("/user/iabd/datos.csv") as writer:
writer.write(datos.encode('utf-8'))
En el mundo real, los formatos de los archivos normalmente serán Avro y/o Parquet, y el acceso lo realizaremos en gran medida mediante la librería de Pandas:
import pandas as pd
import pyarrow.parquet as pq
from pyarrow import fs
HDFS_HOSTNAME = 'iabd-virtualbox'
HDFS_PORT = 9000
hdfs = fs.HadoopFileSystem(host=HDFS_HOSTNAME, port=HDFS_PORT)
datos_dict = {
'nombre': ['Aitor', 'Pedro'],
'apellidos': ['Medrano', 'Casas']
}
df = pd.DataFrame(datos_dict)
df.to_parquet('/user/iabd/datos.parquet', filesystem=hdfs, index=False)
# Si queremos hacerlo mediante PyArrow directamente sin Pandas:
# tabla = pa.table(datos_dict)
# pq.write_table(tabla, '/user/iabd/datos.parquet', filesystem=hdfs)
Otras librerías
Python ofrece muchas más librerías para trabajar con Hadoop y HDFS:
Hue¶
Hue (Hadoop User Experience) es una interfaz gráfica de código abierto basada en web para su uso con Apache Hadoop. Hue actúa como front-end para las aplicaciones que se ejecutan en el clúster, lo que permite interactuar con las aplicaciones mediante una interfaz más amigable que el interfaz de comandos.
En nuestra máquina virtual ya lo tenemos instalado y configurado para que funcione con HDFS y Hive.
La ruta de instalación es /opt/hue-4.10.0 y desde allí, arrancaremos Hue:
./build/env/bin/hue runserver
Docker
Si queremos ejecutarlo desde Docker, la propia Hue dispone de una imagen oficial, la cual podemos lanzar mediante:
docker run -it -p 8888:8888 gethue/hue:latest
Para su configuración se recomienda consultar la documentación oficial de la imagen.
Tras arrancarlo, nos dirigimos a http://127.0.0.1:8000/y visualizaremos el formulario de entrada, el cual entraremos con el usuario iabd y la contraseña iabd:
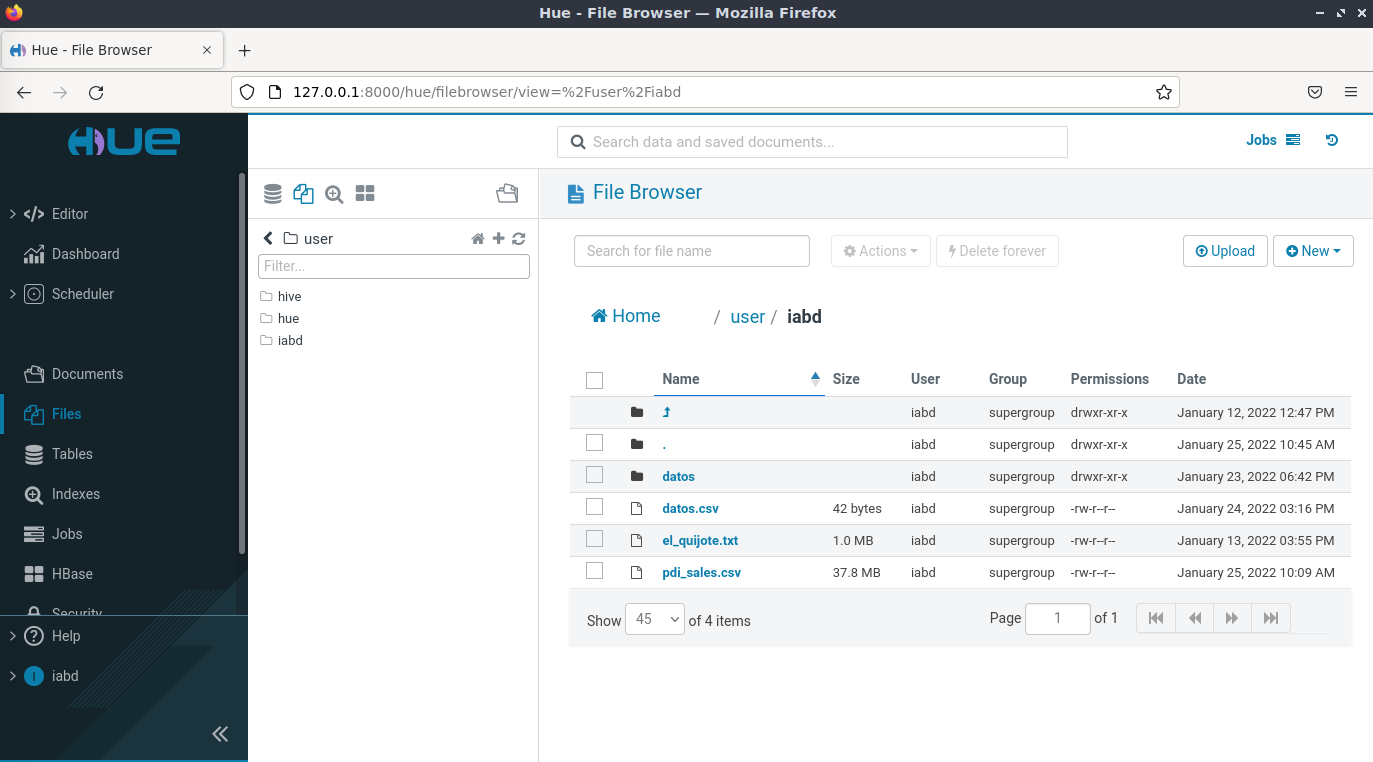
Una vez dentro, por ejemplo, podemos visualizar e interactuar con HDFS:
Referencias¶
- Documentación de Apache Hadoop.
- Hadoop: The definitive Guide, 4th Ed - de Tom White - O'Reilly
- HDFS Commands, HDFS Permissions and HDFS Storage
- Native Hadoop file system (HDFS) connectivity in Python
Actividades¶
Para los siguientes ejercicios, copia el comando y/o haz una captura de pantalla donde se muestre el resultado de cada acción.
-
(RABDA.3 / CEBDA.3a y CEBDA.3c / 1.5p) En este ejercicio vamos a practicar los comandos básicos de HDFS. Una vez arrancado Hadoop:
- Crea la carpeta
/user/iabd/ejercicios. - Sube el archivo
el_quijote.txta la carpeta creada. - Crea una copia en HDFS y llámala
el_quijote2.txt. - Recupera el principio del fichero
el_quijote2.txt. - Renombra
el_quijote2.txtael_quijote_copia.txt. - Descarga en local
el_quijote_copia.txtcon su código CRC. - Adjunta una captura desde el interfaz web donde se vean ambos archivos.
- Vuelve al terminal y elimina la carpeta con los archivos contenidos mediante un único comando.
- Crea la carpeta
-
(RABDA.3 / CEBDA.3a / 1p) Explica paso a paso el proceso de lectura (indicando qué bloques y los datanodes empleados) que realiza HDFS si queremos leer el archivo
/logs/101213.log: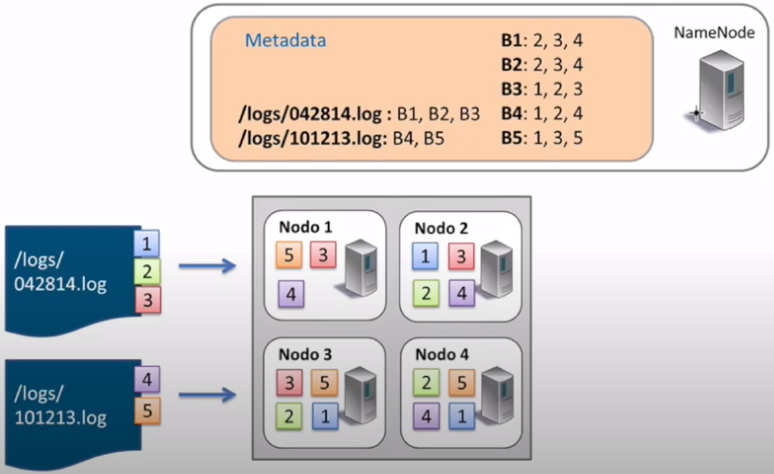
Proceso de lectura HDFS -
(RABDA.4 / CEBDA.4e y CEBDA.4f / opcional) Vamos a practicar los comandos de gestión de instantáneas y administración de HDFS. Para ello:
- Crea la carpeta
/user/iabd/snaps. - Habilita las snapshots sobre la carpeta creada.
- Sube el archivo
el_quijote.txta la carpeta creada. - Crea una copia en HDFS y llámala
el_quijote_snapshot.txt. - Crea una instantánea de la carpeta llamada
ss1. - Elimina ambos ficheros del quijote.
- Comprueba que la carpeta está vacía.
- Recupera desde
ss1el archivoel_quijote.txt. - Crea una nueva instantánea de la carpeta llamada
ss2. - Muestra el contenido de la carpeta
/user/iabd/snapsasí como de sus snapshots, justificando la información que aparece.
- Crea la carpeta
-
(RABDA.4 / CEBDA.4e y CEBDA.4f / opcional) HDFS por dentro
- Accede al archivo de configuración
hdfs-site.xmly averigua la carpeta donde se almacena el namenode. - Muestra los archivos que contiene la carpeta
currentdentro del namenode - Comprueba el id del archivo
VERSION. - En los siguientes pasos vamos a realizar un checkpoint manual para sincronizar el sistema de ficheros. Para ello entramos en modo safe con el comando
hdfs dfsadmin -safemode enter, de manera que impedamos que se trabaje con el sistema de ficheros mientras lanzamos el checkpoint. - Comprueba mediante el interfaz gráfico que el modo seguro está activo (Safe mode is ON).
- Ahora realiza el checkpoint con el comando
hdfs dfsadmin -saveNamespace - Vuelve a entrar al modo normal (saliendo del modo seguro mediante
hdfs dfsadmin -safemode leave) - Accede a la carpeta del namenode y comprueba si los fsimage del namenode son iguales.
- Accede al archivo de configuración
-
(RABDA.3 / CEBDA.3a / 1.5p) Haciendo uso de PyArrow, escribe un script en Python que realice las siguientes acciones:
- Conecta con HDFS.
- Lea el archivo
el_quijote.txtque tenemos en HDFS - Muestra las primeras 100 letras del archivo.
-
Crea un DataFrame de Pandas con los siguientes datos:
nombre apellidos edad Aitor Medrano 18 Tu nombre Tus apellidos 19 Bruce Wayne 20 -
Almacena el DataFrame en formato Parquet en la ruta
/user/iabd/nombres.parquetde HDFS.