WAF
Dentro de las diferentes plataformas cloud, a la hora de diseñar e implementar una aplicación, podemos tener en mente, desde un inicio, que se va a desplegar en la nube, haciendo uso de la gran mayoría de servicios que hemos estudiado en las sesiones anteriores.
De forma complementaria, estas plataformas cloud ofrecen un marco buenas prácticas, principios y decisiones que hemos de tomar a la hora de diseñar nuestros sistemas, sean big data o no.
Marco de buena arquitectura (WAF)¶
El marco de buena arquitectura (AWS Well-Architected Framework / Azure Well-Architected Framework) es una guía diseñada para ayudar a crear la infraestructura con más seguridad, alto rendimiento, resiliencia y eficacia posibles para las aplicaciones y cargas de trabajo en la nube. Proporciona un conjunto de preguntas y prácticas recomendadas que facilitan la evaluación e implementación de nuestras arquitecturas en la nube.
Se organiza en cinco pilares que estudiaremos a continuación: excelencia operativa, seguridad, fiabilidad, eficacia del rendimiento y optimización de costes.
Excelencia operativa¶
Se centra en la habilidad de ejecutar y monitorizar sistemas para proporcionar valor de negocio, mejorando de forma continua los procesos y procedimientos de soporte.
Comprende la capacidad para dar soporte al desarrollo y ejecutar cargas de trabajo de manera eficaz, obtener información acerca de las operaciones y mejorar continuamente el soporte a los procesos y los procedimientos para ofrecer valor de negocio. Para ello se recomienda:
-
Realizar operaciones como código: podemos definir toda la carga de trabajo (aplicaciones, infraestructura) como código y actualizarla con código, sin necesidad de utilizar el interfaz gráfico. De esta manera, podemos automatizar la ejecución en respuesta a eventos, además de limitar la posibilidad de error humano.
-
Realizar cambios pequeños, reversibles (por si se producen errores) y frecuentes.
-
Refinar los procedimientos de las operativos con frecuencia, revisando de forma periódica su efectividad y conocimiento por parte de los equipos.
-
Prever los errores: realizar simulacros de fallos, probando los procedimientos de respuesta.
-
Aprender de los errores y eventos operativos: promover mejoras a partir de las lecciones aprendidas de todos los eventos y los errores operativos.
Seguridad¶
Antes de diseñar cualquier sistema, es imprescindible aplicar prácticas de seguridad. Debemos poder controlar quién puede hacer qué. Además, debe de identificar incidentes de seguridad, proteger los sistemas y servicios, y mantener la confidencialidad y la integridad de los datos mediante la protección de la información.
Así pues, este pilar se centra en la capacidad de proteger la información, los sistemas y los recursos, al mismo tiempo que se aporta valor de negocio mediante evaluaciones de riesgo y estrategias de mitigación, siguiendo los siguientes principios:
- Implementar una base sólida de credenciales: mediante el principio de mínimo privilegio y aplicando la separación de obligaciones con la autorización apropiada para cada interacción con los recursos de AWS.
- Habilitar la trazabilidad: Integrando registros y métricas con sistemas para responder y tomar medidas de manera automática, que facilitan la monitorización y el uso de alertar.
- Aplicar seguridad en todas las capas: por ejemplo, a la red de borde, a la nube virtual privada, a la subred y al balanceador de carga, y a cada instancia, sistema operativo y aplicación.
- Automatizar las prácticas recomendadas de seguridad.
- Proteger los datos en tránsito y en reposo: mediante el cifrado, el uso de tokens y el control de acceso cuando corresponda, asegurando la confidencialidad e integridad de los datos.
- Mantener a las personas alejadas de los datos: reducir o eliminar el acceso directo o el procesamiento manual de los datos.
- Prepararse para eventos de seguridad: mediante procesos de administración de incidencias con automatización que dé respuesta a incidentes.
Fiabilidad¶
Se centra en:
- la capacidad de un sistema de recuperarse de interrupciones en la infraestructura o el servicio.
- incorporar dinámicamente recursos informáticos para satisfacer la demanda
- mitigar las interrupciones, como errores de configuración o problemas de red temporales.
Se recomiendan los siguientes principios para aumentar la fiabilidad:
- Probar los procedimientos de recuperación: usar la automatización para simular diferentes errores o para volver a crear situaciones que hayan dado lugar a errores antes.
- Recuperarse automáticamente de los errores: monitorizar los sistemas en busca de indicadores clave de rendimiento y configurar los sistemas para desencadenar procesos de recuperación automatizado cuando se supere un límite.
- Escalar horizontalmente para aumentar la disponibilidad total del sistema: sustituir un recurso grande por varios recursos más pequeños, distribuyendo las solicitudes para reducir el impacto de un único punto de error.
- Evitar asumir estimaciones sobre capacidad: monitorizando la demanda y el uso del sistema, y automatizando la incorporación o eliminación de recursos para mantener el nivel óptimo.
- Administrar los cambios mediante la automatización.
Eficiencia del rendimiento¶
Se centra en la capacidad de utilizar recursos informáticos de forma eficiente (sólo cuando sean necesarios) para satisfacer los requisitos del sistema y mantener esa eficiencia a medida que cambia la demanda o evolucionan las tecnologías.
Entre los temas principales se incluyen la selección de los tipos y tamaños de recursos adecuados en función de los requisitos de la carga de trabajo, el monitoreo del rendimiento y la toma de decisiones fundamentadas para mantener la eficiencia a medida que evolucionan las necesidades de la empresa.
Se recomiendan los siguientes principios para mejorar la eficiencia del rendimiento:
- Democratizar las tecnologías avanzadas: usando tecnologías como servicio (como son los servicios de IA que ofrecen tanto AWS como Azure), que simplifican su uso.
- Adquirir escala mundial en cuestión de minutos: desplegando sistemas en varias regiones para ofrecer una menor latencia.
- Utilizar arquitecturas sin servidor: las arquitecturas sin servidor eliminan la carga operativa que supone ejecutar y mantener servidores.
- Experimentar más a menudo: mediante pruebas comparativas de diferentes tipos de instancias, almacenamiento y/o configuraciones.
- Disponer de compatibilidad mecánica: utilizando el enfoque tecnológico que se ajuste mejor a lo que intenta conseguir (por ejemplo, mediante los patrones de acceso a los datos cuando accedamos a bases de datos o almacenamiento).
Optimización de costes¶
Se centra en la capacidad de ejecutar sistemas para ofrecer valor de negocio al precio más bajo. Entre los temas principales se incluyen la comprensión y el control de cuándo se está gastando el dinero, la selección de los tipos de recursos más adecuados en la cantidad correcta, el análisis de los gastos a lo largo del tiempo y el escalado para satisfacer las necesidades de la empresa sin gastos excesivos.
Se recomiendan los siguientes principios para optimizar los costes:
- Adoptar un modelo de consumo: pagando solo por los recursos informáticos que necesitamos.
- Medir la eficacia general: midiendo la producción comercial de la carga de trabajo y los costes asociados a la entrega.
- Dejar de gastar dinero en las operaciones de centros de datos: la nube elimina los costes de aprovisionamiento, electricidad, aire acondicionado, seguridad física, etc...
- Analizar y asignar gastos: la nube facilita la identificación precisa del uso y los costes del sistema, así como el coste de las cargas de trabajo individuales, lo que facilita medir el retorno de la inversión (ROI).
- Utilizar los servicios administrados para reducir el coste de propiedad: reducen la carga operativa que supone mantener servidores para tareas como el envío de email o la administración de bases de datos.
Todo falla constantemente
Hemos de diseñar nuestras arquitecturas con el axioma que en un momento u otro algo fallará. Para que nuestros sistemas resistan los errores, los dos factores más críticos son la fiabilidad y la disponibilidad.
Una forma de medir la fiabilidad es el MTBF: tiempo promedio entre errores, es decir tiempo total en servicio respecto a la cantidad de errores. Otra forma es mediante el porcentaje de tiempo durante el cual el sistema funcional correctamente. Este porcentaje se suele medir en la cantidad de nueves, así pues seis nueves implica una disponibilidad del 99,9999%.
Un sistema de alta disponibilidad (HA) es aquel que puede soportar cierta medida de degradación sin dejar de estar disponible. Los tres factores que influyen en la disponibilidad son la tolerancia a errores (gracias a la redundancia, cambiar de recurso cuando uno falla), la escalabilidad (la aplicación se adaptar a los aumentos de carga) y la capacidad de recuperación (el servicio se restaura rápidamente sin perder datos).
AWS Trusted Advisor¶
AWS dispone de la herramienta en línea AWS Trusted Advisor que ofrece asesoramiento en tiempo real con las prácticas recomendadas de AWS. Examina todo el entorno AWS y ofrece recomendaciones en cinco categorías:
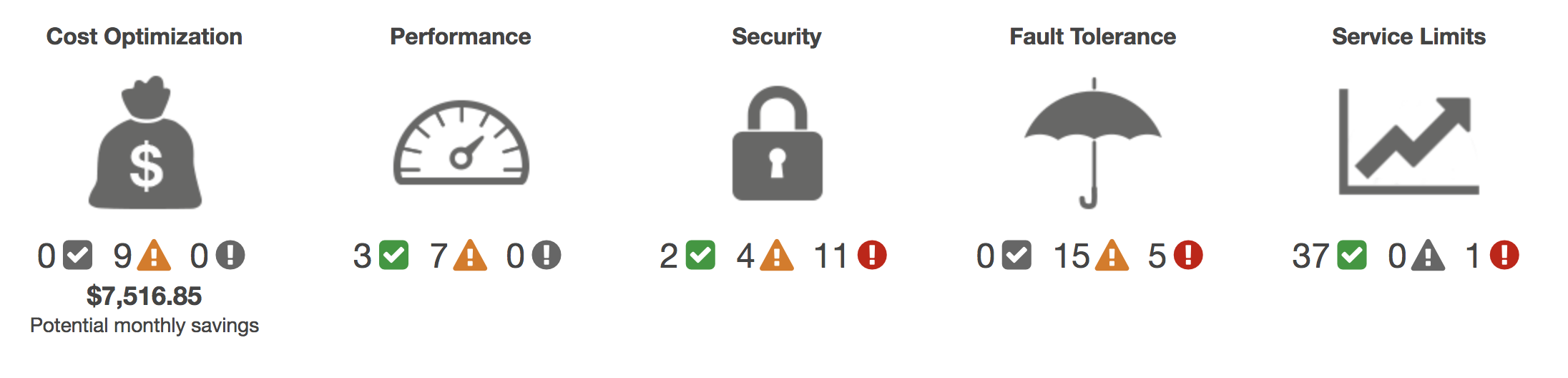
- Optimización de costes: sugiere recursos no utilizados e inactivos, o bien, posibilidad de realiza una reserva de capacidad.
- Rendimiento: comprueba los límites del servicio y monitoriza para detectar instancias que se estén utilizando por encima de su capacidad.
- Seguridad: examina los permisos para mejorar el nivel de seguridad de la aplicación.
- Tolerancia a errores: revisa las capacidades de escalado automático, las comprobaciones de estado, la implementación Multi-AZ y las capacidades de copia de seguridad.
- Límites del servicio: realiza verificaciones para detectar usos que superen el 80% del límite del servicio.
Azure Advisor y Azure Score
Microsoft, del forma similar, ofrece un par herramientas que nos ayudan a optimizar las implementaciones, como son Azure Advisor, y dentro de ella Advisor Score que puntúa las recomendaciones para con un simple vistazo poder priorizar las mejoras sugeridas.
Referencias¶
Actividades¶
- (opcional) Realizar el módulo 9 (Arquitectura en la nube) del curso ACF de AWS.