Ingesta de datos
Introducción¶
Formalmente, la ingesta de datos es el proceso mediante el cual se introducen datos, desde diferentes fuentes, estructura y/o características dentro de otro sistema de almacenamiento o procesamiento de datos.

La ingesta de datos es un proceso muy importante porque la productividad de un equipo va directamente ligada a la calidad del proceso de ingesta de datos. Estos procesos deben ser flexibles y ágiles, ya que una vez puesta en marcha, los analistas y científicos de datos puedan construir un pipeline de datos para mover los datos a la herramienta con la que trabajen. Entendemos como pipeline de datos un proceso que consume datos desde un punto de origen, los limpia y los escribe en un nuevo destino.
Es sin duda, el primer paso que ha de tenerse en cuenta a la hora de diseñar una arquitectura Big Data, para lo cual, hay que tener muy claro, no solamente el tipo y fuente de datos, sino cual es el objetivo final y qué se pretende conseguir con ellos. A la hora de diseñar un pipeline, se debe empezar desde el problema que negocio quiere solucionar, y retroceder con los datos hasta el origen de los mismos. Por lo tanto, en este punto, hay que realizar un análisis detallado, porque es la base para determinar las tecnologías que compondrán nuestra arquitectura Big Data.
Dada la gran cantidad de datos que disponen las empresas, toda la información que generan desde diferentes fuentes se deben integrar en un único lugar, al que actualmente se le conoce como data lake, asegurándose que los datos sean compatibles entre sí. Gestionar tal volumen de datos puede llegar a ser un procedimiento complejo, normalmente dividido en procesos distintos y de relativamente larga duración.
Pipeline de datos¶
Un pipeline es una construcción lógica que representa un proceso dividido en fases. Los pipelines de datos se caracterizan por definir el conjunto de pasos o fases y las tecnologías involucradas en un proceso de movimiento o procesamiento de datos. En su forma más simple, consisten en recoger los datos, almacenarlos y procesarlos, y construir algo útil con los datos.

Las pipelines de datos son necesarios ya que no debemos analizar los datos en los mismos sistemas donde se crean (principalmente para evitar problemas de rendimiento). El proceso de analítica es costoso computacionalmente, por lo que se separa para evitar perjudicar el rendimiento del servicio. De esta forma, tenemos sistemas OLTP (sistemas de procesamiento transaccional online, como un CRM), encargados de capturar y crear datos, y de forma separada, sistemas OLAP (sistemas de procesamiento analítico, como un Data Warehouse), encargados de analizar los datos.
Fases del pipeline¶
Los movimientos de datos entre estos sistemas involucran varias fases. Por ejemplo:
- Ingesta. Recogemos los datos y los enviamos a un topic de Apache Kafka.
-
Almacenamiento. Kafka actúa aquí como un buffer para el siguiente paso.
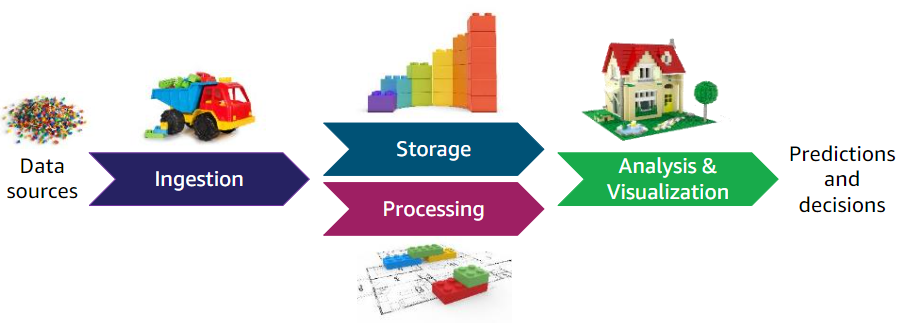
Fases en un pipeline de datos - AWS -
Procesamiento. Mediante una tecnología de procesamiento, que puede ser streaming o batch, leemos los datos del buffer.
- Análisis y Visualización. Por ejemplo, mediante Spark realizamos la analítica sobre estos datos (haciendo cálculos, filtrados, agrupaciones de datos, etc...). Finalmente, podemos visualizar los resultados obtenidos o almacenarlos en una base de datos NoSQL como MongoDB o Amazon DynamoDB o un sistema de almacenamiento distribuido como Amazon S3.
Antes de realizar el análisis de los datos, va a ser muy normal tener que limpiar o normalizar los datos, ya sea porque las fuentes de datos, al ser distintas, utilicen diferentes codificaciones o nomenclaturas, o bien que haya datos sin rellenar o incorrectos. Conforme los datos avanzan a través del pipeline, los datos se van a transformar (por ejemplo, poniendo ceros en los campos vacíos, o rellenando los huecos con valores que aporten valor). Estas transformaciones se conocen como Data Wrangling (manipulación o disputa de datos), término que engloba las acciones realizadas desde los datos en crudo hasta el estado final en el cual el dato cobra valor y sentido para los usuarios.
Pipeline iterativo¶
Este proceso de ingesta, almacenamiento, procesamiento y análisis es iterativo. Sobre una hipótesis que se nos plantee en negocio, comprobaremos los datos almacenados, y si no disponemos de la información necesaria, recogeremos nuevos datos. Estos nuevos datos pasaran por todo el pipeline, integrándose con los datos ya existentes. En la fase de analítica, si no obtenemos el resultado esperado, nos tocará volver a la fase de ingesta para obtener o modificar los datos recogidos, y así, de forma iterativa, hasta producir el resultado esperado.
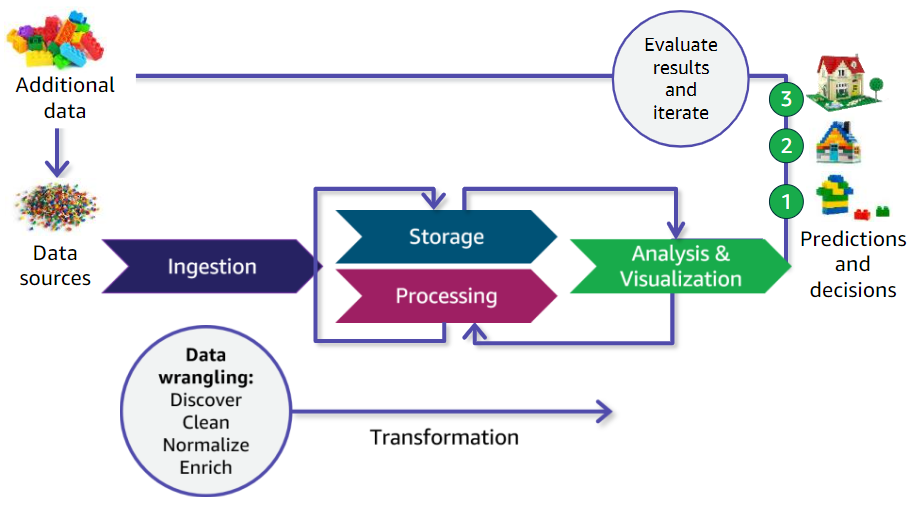
Aunque a menudo se intercambian los términos de pipeline de datos y ETL, no significan lo mismo. Las ETLs son un caso particular de pipeline de datos que involucran las fases de extracción, transformación y carga de datos. Las pipelines de datos son cualquier proceso que involucre el movimiento de datos entre sistemas.
ETL¶
Una ETL, entendida como un proceso que lleva la información de un punto A a un punto B, puede realizarse mediante diversas herramientas, scripts, Python, etc... Pero cuando nos metemos con Big Data no servirá cualquier tipo de herramienta, ya que necesitamos que sean:
- flexibles y soporten formatos variados (JSON, CSV, Parquet, etc...)
- escalables y tolerante a fallos.
- dispongan de conectores a múltiples fuentes y destinos de datos.
Los procesos ETL, siglas de extracción, transformación y carga (load), permiten a las organizaciones recopilar en un único lugar todos los datos de los que pueden disponer. Ya hemos comentado que estos datos provienen de diversas fuentes, por lo que es necesario acceder a ellos, y formatearlos para poder ser capaces de integrarlos. Además, es muy recomendable asegurar la calidad de los datos y su veracidad, para así evitar la creación de errores en los datos.
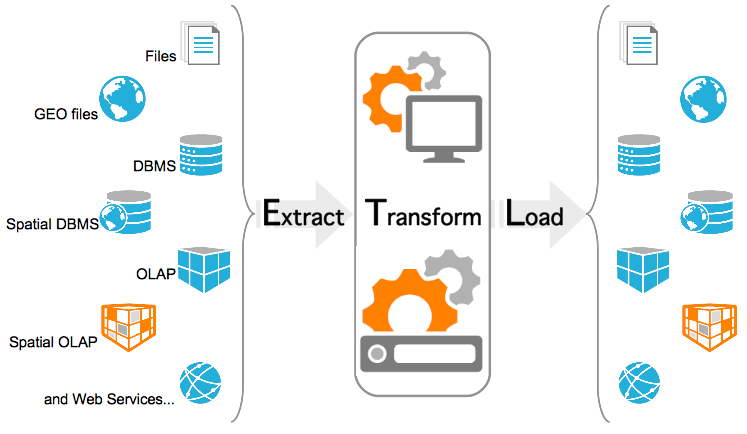
Una vez los datos están unificados en un data lake, otro tipo de herramientas de análisis permitirán su estudio para apoyar procesos de negocio.
Dada la gran variedad de posibilidades existentes para representar la realidad en un dato, junto con la gran cantidad de datos almacenados en las diferentes fuentes de origen, los procesos ETL consumen una gran cantidad de los recursos asignados a un proyecto.
Extracción¶
Encargada de recopilar los datos de los sistemas originales y transportarlos al sistema donde se almacenarán, de manera general suele tratarse de un entorno de Data Warehouse o almacén de datos. Las fuentes de datos pueden encontrarse en diferentes formatos, desde ficheros planos hasta bases de datos relacionales, pasando por mensajes de redes sociales como Twitter o Reddit.
Estrategias de ingesta
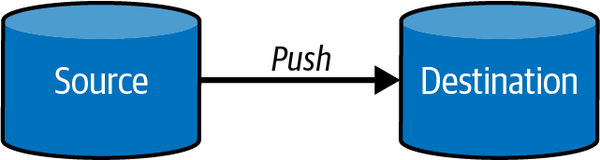
A la hora de obtener datos desde una fuente origen y llevaros a un destino, podemos seguir tres planteamiento:
| Push | Pull | Poll |
|---|---|---|
| El origen envía los datos al destino | El destino recupera los datos del origen | El destino comprueba de forma periódica el origen para ver si ha habido cambios. Si hubiera cambios, hace un pull de los mismos. |
 |
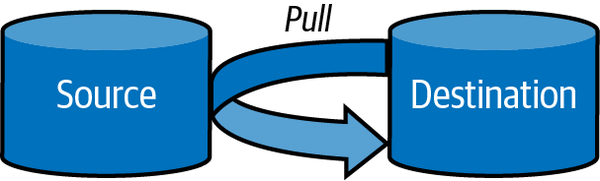 |
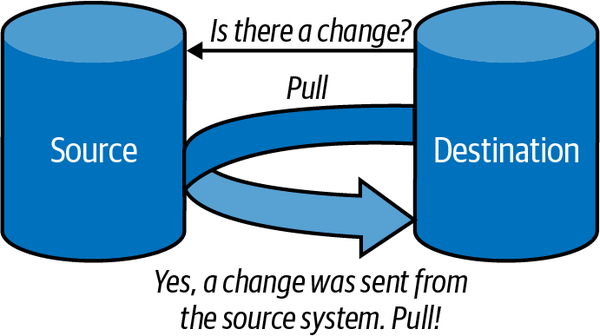 |
Un paso que forma parte de la extracción es la de analizar que los datos sean veraces, que contiene la información que se espera, verificando que siguen el formato que se esperaba. En caso contrario, esos datos se rechazan.
La primera característica deseable de un proceso de extracción es que debe ser un proceso rápido, ligero, causar el menor impacto posible, ser transparente para los sistemas operacionales e independiente de las infraestructuras.
La segunda característica es que debe reducir al mínimo el impacto que se genera en el sistema origen de la información. No se puede poner en riesgo el sistema original, generalmente operacional, ni perder ni modificar sus datos; ya que si colapsase esto podría afectar el uso normal del sistema y generar pérdidas a nivel operacional.
Así pues, la extracción convierte los datos a un formato preparado para iniciar el proceso de transformación.
Transformación¶
En esta fase se espera realizar los cambios necesarios en los datos de manera que estos tengan el formato y contenido esperado.
En concreto, la transformación puede comprender:
- Cambios de codificación.
- Eliminar datos duplicados.
- Cruzar diferentes fuentes de datos para obtener una fuente diferente.
- Agregar información en función de alguna variable.
- Tomar parte de los datos para cargarlos.
- Transformar información para generar códigos, claves, identificadores…
- Generar información.
- Estructurar mejor la información.
- Generar indicadores que faciliten el procesamiento y entendimiento.
Respecto a sus características, debe transformar los datos para mejorarlos, incrementar su calidad, integrarlos con otros sistemas, normalizarlos, eliminar duplicidades o ambigüedades. Además, no debe crear información, duplicar, eliminar información relevante, ser errónea o impredecible.
Una vez transformados, los datos ya estarán listos para su carga.
Carga¶
Fase encargada de almacenar los datos en el destino, un data warehouse o en cualquier tipo de base de datos. Por tanto la fase de carga interactúa de manera directa con el sistema destino, y debe adaptarse al mismo con el fin de cargar los datos de manera satisfactoria.
La carga debe realizarse buscando minimizar el tiempo de la transacción.
Cada BBDD puede tener un sistema ideal de carga basado en:
- SQL (Oracle, SQL Server, Redshift, Postgres, ...)
- Ficheros (Postgres, Redshift, ...)
- Cargadores Propios (HDFS, S3, ...)
Para mejorar la carga debemos tener en cuenta la:
- gestión de índices.
- gestión de claves de distribución y particionado.
- tamaño de las transacciones y commits.
ELT¶
ELT cambia el orden de las siglas y se basa en extraer, cargar y transformar. Es un técnica de ingestión de datos donde los datos que se obtienen desde múltiples fuentes se colocan sin transformar directamente en un data lake o almacenamiento de objetos en la nube. Desde ahí, los datos se pueden transformar dependiendo de los diferentes objetivos de negocio.
En principio un proceso ELT necesita menos ingenieros de datos necesarios. Con la separación de la extracción y la transformación, ELT permite que los analistas y científicos de datos realicen las transformaciones, ya sea con SQL o mediante Python. De esta manera, más departamentos se involucran en obtener y mejorar los datos.
Una de las principales razones de que ELT cueste menos de implementar es que permite una mayor generalización de la información que se almacena. Los ingenieros de datos generan un data lake con los datos obtenidos de las fuentes de datos más populares, dejando que la transformación la realicen los expertos en el negocio. Esto también implica que los datos estén disponibles antes, ya que mediante un proceso ETL los datos no están disponibles para los usuarios hasta que se han transformado, lo que suele implicar un largo proceso de trabajo.
En resumen, el mercado se está moviendo desde un desarrollo centralizado mediante ETL a uno más orientado a servicios como ELT, que permite automatizar la carga del data lake y la posterior codificación de los flujos de datos.
Herramientas ETL¶
Las características de las herramientas ETL son:
-
Permiten conectividad con diferentes sistemas y tipos de datos
- Excel, BBDD transaccionales, XML, ficheros CSV / JSON, HDFS, Hive, S3, ...
- Peticiones HTTP, servicios REST...
- APIs de aplicaciones de terceros, logs…
-
Permiten la planificación mediante batch, eventos o en streaming.
-
Capacidad para transformar los datos:
- Transformaciones simples: tipos de datos, cadenas, codificaciones, cálculos simples.
- Transformaciones intermedias: agregaciones, lookups.
- Transformaciones complejas: algoritmos de IA, segmentación, integración de código de terceros, integración con otros lenguajes.
-
Metadatos y gestión de errores
- Permiten tener información del funcionamiento de todo el proceso.
- Permiten el control de errores y establecer acciones a realizar cuando se producen.
Las soluciones más empleadas son:
- Pentaho Data Integration (PDI)
- Oracle Data Integrator
- Talend Open Studio
- Mulesoft
- Informatica Data Integration

La tendencia actual es un uso híbrido de dichas herramientas con scripts Python mediante el uso de librerías como Pandas, PySpark o DuckDB para pipelines nuevos, procesamiento de datos no estructurados, ML y automatizaciones complejas, de la mano de Apache Airflow para la orquestación de los flujos de datos.
Hola ETL¶
Vamos a realizar un ejemplo muy sencillo a partir de los ficheros de datos que contienen información sobre productos y sus fabricantes (estos archivos los utilizamos también en la sesión de Pentaho). El objetivo es obtener un fichero con los productos y el nombre de su fabricante.
Si comprobamos ambos archivos, además de ver que no utilizan el mismo separador de campos, podemos observar como los productos tienen un campo manufacturer_id, que es el identificador del fabricante, y en el fichero de fabricantes, tenemos el campo id que es el identificador del fabricante, junto con su nombre en el campo name:
-
Productos
pdi_product.csvProductID,Product,Category,Segment,ManufacturerID 1,Abbas MA-01,Mix,All Season,1 2,Abbas MA-02,Mix,All Season,1 3,Abbas MA-03,Mix,All Season,1 ... 46,Abbas RP-01,Rural,Productivity,1 47,Abbas RP-02,Rural,Productivity,1 48,Abbas RP-03,Rural,Productivity,1 ... 2410,Aliqui YY-19,Youth,Youth,2 2411,Aliqui YY-20,Youth,Youth,2 2412,Aliqui YY-21,Youth,Youth,2 -
Fabricantes
pdi_manufacturer.csvManufacturerID;Manufacturer 1;Abbas 2;Aliqui 3;Barba ... 12;Quibus 13;Salvus 14;Victoria
Por lo tanto, el proceso ETL que vamos a realizar es:
- Extracción: leer ambos ficheros CSV.
- Transformación: realizar un join entre ambos ficheros utilizando el campo
manufacturer_iddel fichero de productos y el campoiddel fichero de fabricantes, y crear una nueva columnaProductAndManufacturerque contenga el nombre del producto junto con el nombre del fabricante, y además, quedarnos únicamente con los productos de la categoríaM - Carga: escribir el resultado en un nuevo fichero JSON denominado
pdi_product_mix.json.
Si nos centramos en el uso de Pandas, una posible solución sería la siguiente:
import pandas as pd
# ========== E ==========
df_products = pd.read_csv("pdi_product.csv")
df_manufacturers = pd.read_csv("pdi_manufacturer.csv", sep=";")
# ========== T ==========
# Filtramos los productos de la categoría Mix
df_products_filtered = df_products.where(df_products["Category"] == "Mix")
# Join de productos con fabricantes
df_joined = df_products_filtered.merge(
df_manufacturers,
on="ManufacturerID",
how="left"
)
# Limpieza y transformaciones
df_joined["ProductAndManufacturer"] = (
df_joined["Product"] + " (" + df_joined["Manufacturer"] + ")"
)
# ========== L ==========
df_joined.to_json("pdi_product_mix.json")
Hola DuckDB¶
DuckDB es una base de datos analítica en proceso embebida, que permite ejecutar consultas SQL directamente sobre ficheros locales sin necesidad de cargar los datos en una base de datos. Soporta múltiples formatos de ficheros como CSV, Parquet, JSON, etc... y es capaz de manejar grandes volúmenes de datos gracias a su motor columnar y a su capacidad para trabajar con memoria externa. Hablando de ETL, DuckDB permite realizar operaciones de transformación y carga de datos directamente desde ficheros, lo que facilita la creación de pipelines ETL eficientes y escalables.
Para recuperar los ficheros, DuckDB permite crear vistas virtuales sobre los ficheros CSV, de manera que podemos tratarlos como si fueran tablas de una base de datos. A partir de ahí, podemos realizar consultas SQL para transformar los datos, y finalmente, exportar el resultado a un nuevo fichero JSON.
Tras instalar la librería mediante pip install duckdb, podemos realizar el mismo proceso ETL anterior utilizando DuckDB y una sintaxis SQL mediante el código siguiente:
import duckdb
# ========== E ==========
duckdb.execute("""
CREATE VIEW productos AS
SELECT * FROM read_csv('pdi_product.csv', header=true);
""")
#duckdb.read_csv('pdi_product.csv', header=True).create_view('productos')
duckdb.execute("""
CREATE VIEW fabricantes AS
SELECT * FROM read_csv('pdi_manufacturer.csv', header=true, delim=';');
""")
#duckdb.read_csv('pdi_manufacturer.csv', header=True, delim=';').create_view('fabricantes')
# ========== T ==========
duckdb.execute("""
CREATE VIEW productos_plus AS
SELECT
p.ProductID,
p.Product,
p.Category,
p.Segment,
p.ManufacturerID,
f.Manufacturer,
p.Product || ' (' || f.Manufacturer || ')' AS ProductNombreCompleto
FROM productos p
LEFT JOIN fabricantes f
ON p.ManufacturerID = f.ManufacturerID
WHERE p.Category = 'Mix';
""")
# ========== L ==========
duckdb.execute("""
COPY productos_plus
TO 'pdi_product_mix_ddb.json'
""")
Para más información, consulta su documentación oficial y el API de Python.
La ingesta por dentro¶
La ingesta extrae los datos desde la fuente donde se crean o almacenan originalmente y los carga en un destino o zona temporal. Un pipeline de datos sencillo puede que tenga que aplicar uno o más transformaciones ligeras para enriquecer o filtrar los datos antes de escribirlos en un destino, almacén de datos o cola de mensajería. Se pueden añadir nuevos pipelines para transformaciones más complejas como joins, agregaciones u ordenaciones para analítica de datos, aplicaciones o sistema de informes.
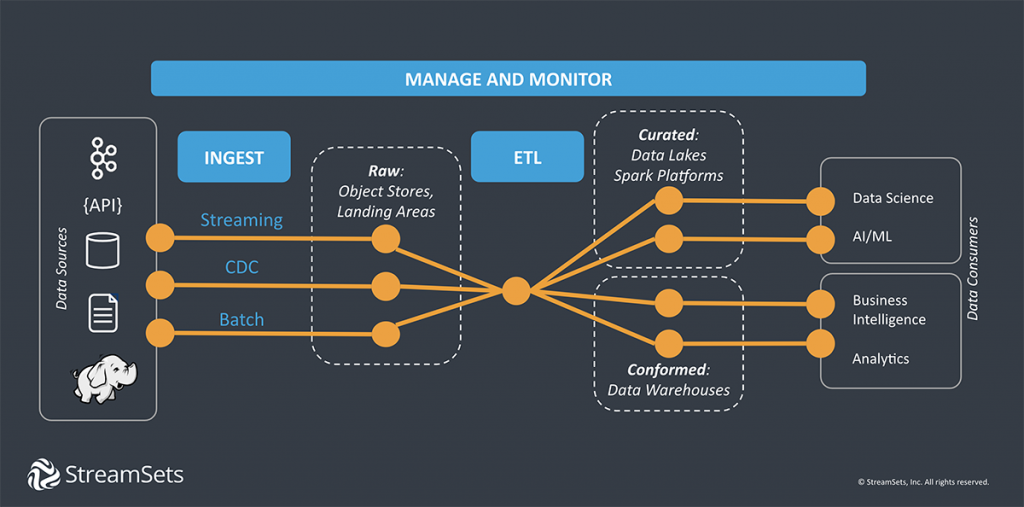
Las fuentes más comunes desde las que se obtienen los datos son:
- servicios de mensajería como Apache Kafka, los cuales han obtenido datos desde fuentes externas, como pueden ser dispositivos IOT o contenido obtenido directamente de las redes sociales.
- bases de datos relacionales, las cuales se acceden, por ejemplo, mediante JDBC.
- servicios REST que devuelven los datos en formato JSON.
- servicios de almacenamiento distribuido como HDFS o S3.
Los destinos donde se almacenan los datos son:
- servicios de mensajería como Apache Kafka.
- bases de datos relacionales.
- bases de datos NoSQL.
- servicios de almacenamiento distribuido como HDFS o S3.
- plataformas de datos como Snowflake o Databricks.
Servicios de mensajería
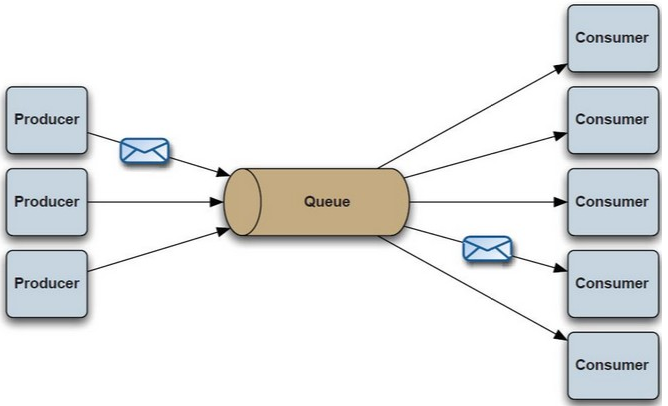
Aunque los estudiaremos en mayor profundidad en el bloque de flujo de datos, y en especial, al trabajar con Kafka o Nifi, los sistemas de mensajería ofrecen un mecanismo de comunicación e integración entre sistemas heterogéneos mediante el paso de mensajes. Estos sistemas permiten desacoplar el envío de la recepción de los datos así como el back pressure por una recepción incontrolada de datos.
Un caso muy común es cuando un productor envía un mensaje a una cola de mensajes que posteriormente recibe un consumidor de la cola. Cuando el consumidor recibe el mensaje, éste desaparece de la cola. También podemos emplear un bus de mensajes u otro tipo de patrones de mensajería.
Cuando utilizamos sistemas de mensajería distribuidos como Kafka se complica su funcionamiento, ya que hemos de tener en cuenta que el orden de los mensajes puede no respetarse entre diferentes colas, así como la tolerancia a fallos o su escalabilidad.
Batch vs Streaming¶
El movimiento de datos entre los orígenes y los destinos se puede hacer, tal como vimos en la sesión de Arquitecturas de Big Data, mediante un proceso:
- Batch: el proceso se ejecuta de forma periódica (normalmente en intervalos fijos) a partir de unos datos estáticos. Muy eficiente para grandes volúmenes de datos, y donde la latencia (del orden de minutos) no es el factor más importante. Algunas de las herramientas utilizadas son Apache Sqoop, trabajos en MapReduce, scripts de Python o Spark jobs, etc...
- Streaming: también conocido como en tiempo real, donde los datos se leen, modifican y cargan tan pronto como llegan a la capa de ingesta (la latencia es crítica). Algunas de las herramientas utilizadas son Apache Storm, Spark Streaming, Apache Nifi, Apache Kafka, etc...
Arquitectura¶
Si nos basamos en la arquitectura por capas, podemos ver como la capa de ingesta es la primera de las capas, la cual recoge los datos que provienen de fuentes diversas. Los datos se categorizan y priorizan, facilitando el flujo de éstos en posteriores capas:
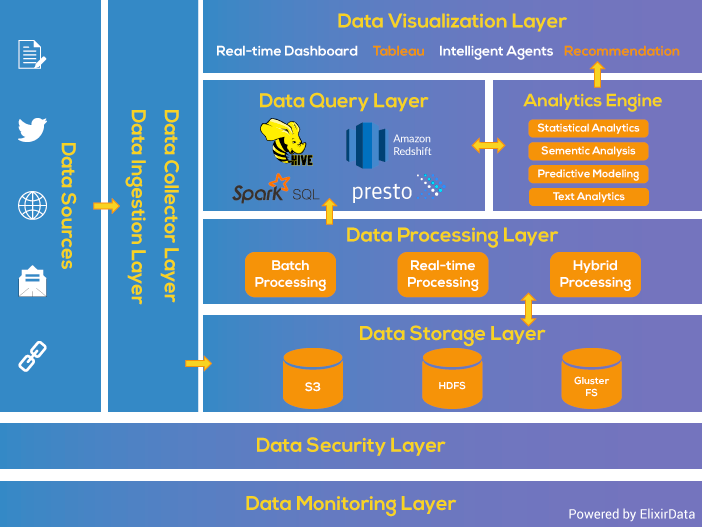
En el primer paso de la ingesta es el paso más pesado, por tiempo y cantidad de recursos necesarios. Es normal realizar la ingesta de flujos de datos desde decenas a cientos de fuentes de datos, los cuales se obtiene a velocidades variables y en diferentes formatos.
Para ello, es necesario:
- priorizar las fuentes de datos.
- validar de forma individual cada fichero.
- enrutar cada elemento a su destino correcto.
Resumiendo, los cuatro parámetros en los que debemos centrar nuestros esfuerzos son:
- Velocidad de los datos: cómo fluyen los datos entre máquinas, interacción con usuario y redes sociales, si el flujo es continuo o masivo, si la ingesta es síncrona o asíncrona.
- Tamaño de los datos: la ingesta de múltiples fuentes puede incrementarse con el tiempo, en consecuencia, la cantidad de datos ingestados.
- Frecuencia de los datos: ¿batch, micro-batch o en "tiempo real" / streaming?
- Formato de los datos: estructurado (tablas, Parquet), desestructurado (imágenes, audios, vídeos, ...) o semi-estructurado (JSON).
Herramientas de Ingesta de datos¶
Las herramientas de ingesta de datos para ecosistemas Big Data se clasifican en los siguientes bloques:

- Apache Sqoop: permite la transferencia bidireccional de datos entre HDFS/Hive/HBase y una bases de datos SQL (datos estructurados). Aunque principalmente se interactúa mediante comandos, proporciona una API Java. La estudiaremos en profundidad en la sesión sobre Sqoop.
- Apache Flume: sistema de ingesta de datos semiestructurados o no estructurados sobre HDFS o HBase mediante una arquitectura basada en flujos de datos en streaming. La estudiaremos en profundidad en la sesión sobre Flume.
- Apache Nifi: herramienta que facilita un interfaz gráfico que permite cargar datos de diferentes fuentes (tanto batch como streaming), los pasa por un flujo de procesos (mediante grafos dirigidos) para su tratamiento y transformación, y los vuelca en otra fuente. La estudiaremos en profundidad en la sesión sobre Nifi.
- Elastic Logstash: Pensada inicialmente para la ingesta de logs en Elasticsearch, admite entradas y salidas de diferentes tipos (incluso AWS).
- AWS Glue: servicios gestionado para realizar tareas ETL desde la consola de AWS. Facilita el descubrimiento de datos y esquemas. También se utiliza como almacenamiento de servicios como Amazon Athena o AWS Data Pipeline.
Por otro lado existen sistemas de mensajería con funciones propias de ingesta asíncrona, tales como:
- Apache Kafka: sistema de intermediación de mensajes basado en el modelo publicador/suscriptor. La estudiaremos en profundidad en la sesión sobre Kafka.
- RabbitMQ: sistema de colas de mensajes (MQ) que actúa de middleware entre productores y consumidores.
- Amazon Kinesis: homólogo de Kafka para la infraestructura Amazon Web Services.
- Microsoft Azure Event Hubs: homólogo de Kafka para la infraestructura Microsoft Azure.
- Google Pub/Sub: homólogo de Kafka para la infraestructura Google Cloud.
Finalmente, existe un tendencia hacia conectores de datos que facilitan la ingesta, como pueden ser:
- Fivetran: plataforma de movimiento de datos automatizados, con más de 300 conectores.
- Airbyte: motor de integración para ELT y sincronización de datos disponible tanto una version open source como otra gestionada en el cloud.
Consideraciones¶
A la hora de analizar cual sería la tecnología y arquitectura adecuada para realizar la ingesta de datos en un sistema Big Data, hemos de tener en cuenta los siguientes factores:
- Origen y formato de los datos
- ¿Cuál va a ser el origen u orígenes de los datos? ¿Cuáles son sus características? ¿Es una aplicación, una API, un conjunto de dispositivos IoT?
- ¿Provienen de sistemas externos o internos a nuestra empresa?
- ¿Serán datos estructurados o datos sin estructurar?
- ¿Cuál es el volumen de los datos? ¿A qué ritmo se generan los datos? ¿Cuántos eventos por segundo? ¿Cuántos gigabytes por hora? Analizar el volumen diario y plantear como sería la primera carga de datos.
- ¿Existe la posibilidad de que más adelante se incorporen nuevas fuentes de datos?
- ¿Cual es el esquema de los datos? ¿Es necesario hacer un join de los datos entre varios sistemas para tener una foto completa de los datos?
- Latencia/Disponibilidad
- ¿Cómo de importante es la velocidad con la que se deben obtener los datos?
- Ventana temporal que debe pasar desde que los datos se ingestan hasta que puedan ser utilizables, desde horas/días (mediante procesos batch) o ser real-time (mediante streaming)
- Si los datos llegan tarde, ¿hasta cuando se consideran válidos?
- Actualizaciones
- ¿Las fuentes de origen se modifican habitualmente?
- Si se añade un nueva columna a un origen, ¿cómo es la comunicación desde origen para informarnos del cambio?
- ¿Podemos almacenar toda la información y guardar un histórico de cambios?
- ¿Podemos reutilizar los datos y evitar volver a ingestar mútiples versiones del mismo dataset?
- ¿Modificamos la información que tenemos? ¿mediante updates, o deletes + insert?
- Transformaciones
- ¿Son necesarias durante la ingesta?
- ¿Qué procesos de transformación se van a realizar una vez ingestados los datos?
- ¿Aportan latencia al sistema de origen? ¿Afecta al rendimiento?
- ¿Tiene consecuencias que la información sea transformada y no sea la original?
- Si la fuente de datos es en streaming, ¿Es necesario realizar transformaciones al vuelo?
- Destino de los datos
- ¿La solución de almacenamiento es compatible con los requisitos de velocidad y latencia de lecturas y escrituras?
- ¿Se utilizará una solución de almacenamiento pura (por ejemplo S3), o una solución compleja con soporte para consultas (por ejemplo, Snowflake o Databricks)?
- ¿Será necesario enviar los datos a más de un destino, por ejemplo, S3 y MongoDB?
- ¿Almacenaremos los datos con el mismo formato que los ingestamos? ¿Los almacenamos en formatos basados en filas (Avro) o columnares (Parquet)?
- ¿Cómo se van a utilizar los datos en el destino? ¿Cómo serán las consultas? ¿Es necesario particionar los datos? ¿Serán búsquedas aleatorias o no? ¿Utilizaremos Hive / Pig / Spark?
- Estudio de los datos
- ¿Se producen errores en la lectura de los datos?
- Calidad de los datos ¿Son fiables? ¿Contienen errores o valores anómalos? ¿Existen duplicados?
- ¿Se capturan metadatos de la evolución del esquema, flujos de datos, linaje de los datos, etc..?
- Respecto a la seguridad de los datos, si tenemos datos sensibles o confidenciales, ¿los enmascaramos o decidimos no realizar su ingesta? ¿Conocemos los requisitos de seguridad de nuestros datos? ¿Quién tiene que acceder y en qué estado?
Referencias¶
- Fundamentals of Data Engineering
- Ingesta, es más que una mudanza de datos
- ¿Qué es ETL?
- Building Big Data Storage Solutions (Data Lakes) for Maximum Flexibility
- Data Ingestion, Processing and Big Data Architecture Layers
Actividades¶
-
(RABDA.1 / CEBDA.1b / 1p) Contesta a las siguientes preguntas justificando tus respuestas:
- Cuando vamos a diseñar un pipeline para la ingesta de datos, ¿Cuál es el primer paso que debemos considerar?
- ¿Qué relación existe entre un pipeline de datos y una ETL?
- ¿Es lo mismo un proceso ETL que ELT? ¿Cuándo se realiza un ETL y cuando un ELT?
- Dentro de un contexto Big data, ¿Cuál crees que se utiliza más (ETL o ELT)? ¿Por qué?
-
(RABDA.1 / CEBDA.1b / 1p) Siguiendo el ejemplo de Hola ETL, realiza el mismo proceso utilizando Pandas y DuckDB, pero en este caso, uniendo los productos con las ventas realizadas, a partir del fichero de ventas. El resultado debe ser un fichero CSV con los productos cuya categoría sea una determinada (por ejemplo,
Mix,Rural,Urban, etc...), junto con el nombre del fabricante y la cantidad total vendida de cada producto. -
(RABDA.1 / CEBDA.1b / 1p) Supongamos que somos una empresa que va a sacar un producto al mercado, y queremos medir las reacciones de las comunidades en las redes sociales.
A partir del supuesto planteado, del apartado Consideraciones contesta al menos 3 preguntas de cada categoría.