Formatos de datos
En la primera unidad de trabajo ya vimos una pequeña introducción a los diferentes formatos de datos.
Conforme los datos viajan a través de los diferentes pipelines, los ingenieros de datos deben gestionar la serialización en diferentes formatos y ser capaces de convertir unos en otros.
Las propiedades que ha de tener un formato de datos son:
- independiente del lenguaje
- expresivo, con soporte para estructuras complejas y anidadas
- eficiente, rápido y reducido
- dinámico, de manera que los programas puedan procesar y definir nuevos tipos de datos.
- formato de fichero standalone y que permita dividirlo y comprimirlo.
Para que Hadoop/Spark o cualquier herramienta de analítica de datos pueda procesar documentos, es imprescindible que el formato del fichero permita su división en fragmentos (splittable in chunks).
Si los clasificamos respecto al formato de almacenamiento tenemos formatos de tipo:
- texto (más lentos, ocupan más pero son más expresivos y permiten su interoperabilidad): CSV, XML, JSON, etc...
- binario (mejor rendimiento, ocupan menos, menos expresivos): Avro, Parquet, ORC, etc...
Si comparamos los formatos más empleados a partir de las propiedades descritas tenemos:
| Característica | CSV | XML / JSON | Avro | Parquet | ORC |
|---|---|---|---|---|---|
| Independencia del lenguaje | 👍 | 👍 | 👍 | 👍 | 👍 |
| Expresivo | 👍 | 👍 | 👍 | 👍 | |
| Eficiente | 👍 | 👍 | 👍 | ||
| Dinámico | 👍 | 👍 | 👍 | ||
| Standalone | ❔ | 👍 | 👍 | 👍 | 👍 |
| Divisible | ❔ | ❔ | 👍 | 👍 | 👍 |
| Orientado a columnas | 👍 | 👍 | |||
| Evolución de esquema | 👍 | ❔ | |||
| Integración con Hive | ❔ | 👍 | 👍 |
Las ventajas de elegir el formato correcto son:
- Mayor rendimiento en la lectura y/o escritura
- Ficheros troceables (splittables)
- Soporte para esquemas que evolucionan
- Soporte para compresión de los datos (por ejemplo, mediante Snappy).
Filas vs Columnas¶
Los formatos con los que estamos más familiarizados, como son CSV, XML o JSON, son formatos basados en filas, donde cada registro se almacena en una fila o documento. Estos formatos son más lentos en ciertas consultas y su almacenamiento no es óptimo.
JSON vs JSONL
Un documento JSON contiene diferentes pares de clave-valor con los elementos que lo componen ocupando varias líneas.
Un tipo específico de JSON es JSON (JSON Lines), el cual almacena una secuencia de objetos JSON delimitando cada objeto por un saldo de línea.
{ "empleados": [
{"nombre": "Carlos", "altura": 180, "edad": 44},
{"nombre": "Juan", "altura": 175, "edad": None}
]
}
{"nombre": "Carlos", "altura": 180, "edad": 44}
{"nombre": "Juan", "altura": 175, "edad": None}
En un formato basado en columnas, cada columna se almacena en su conjunto de ficheros, es decir, cada registro almacena toda la información de una columna. Al basarse en columnas, ofrece mejor rendimiento para consultas de determinadas columnas y/o agregaciones, y el almacenamiento es más óptimo (como todos los datos de una columna son del mismo tipo, la compresión es mayor).
Supongamos que tenemos los siguientes datos:
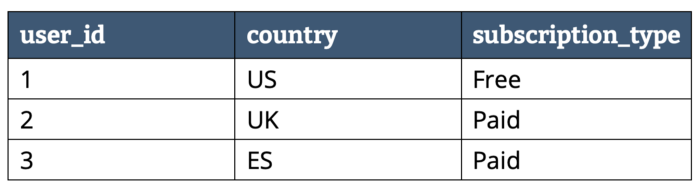
Dependiendo del almacenamiento en filas o columnas tendríamos la siguiente representación:

Como hemos comentado previamente, en un formato columnar los datos del mismo tipo se agrupan, lo que mejora el rendimiento de acceso y reduce el tamaño:
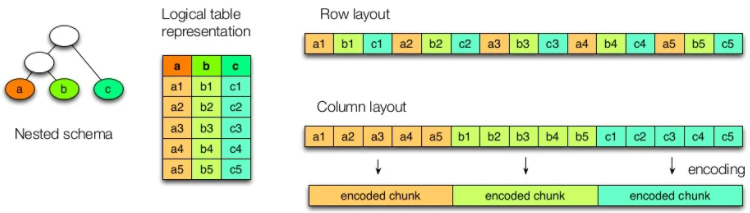
El almacenamiento en columnas y la compresión también presentan algunas desventajas, ya que no podemos acceder fácilmente a registros de datos individuales. Para ello, debemos reconstruir registros leyendo datos de varios archivos de columnas.
Del mismo modo, la actualización de registros supone descomprimir el archivo de columnas, modificarlo, volver a comprimirlo y escribirlo de nuevo en el almacenamiento.
Para evitar reescribir columnas completas en cada actualización, las columnas se dividen en varios archivos, normalmente utilizando estrategias de particionado y clustering que organizan los datos según los patrones de consulta y modificación de la tabla. Aun así, la sobrecarga computacional que implica actualizar una sola fila es muy alta.
Por esto, las bases de datos columnares no se adaptan bien a las cargas de trabajo transaccionales, por lo que las bases de datos transaccionales (OLTP) suelen utilizar algún tipo de almacenamiento orientado a filas o registros.
Hablemos de tamaño¶
El artículo Apache Parquet: How to be a hero with the open-source columnar data format compara un formato basado en filas, como CSV, con uno basado en columnas como Parquet, en base al tiempo y el coste de su lectura en AWS (por ejemplo, AWS Athena cobra 5$ por cada TB escaneado):

En la tabla podemos observar como 1TB de un fichero CSV en texto plano pasa a ocupar sólo 130GB mediante Parquet, lo que provoca que las posteriores consultas tarden menos y, en consecuencia, cuesten menos.
En la siguiente tabla comparamos un fichero CSV compuesto de cuatro columnas almacenado en S3 mediante tres formatos cuando sólo nos interesa los datos de una única columna:

Queda claro que la elección del formato de los datos y la posibilidad de elegir el formato dependiendo de sus futuros casos de uso puede conllevar un importante ahorro en tiempo y costes.
Avro¶
Apache Avro es un formato de almacenamiento basado en filas que es más rápido y ocupa menos espacio que JSON, debido a que la serialización de los datos se realiza en un formato binario compacto, con los metadatos del esquema especificados en JSON.
Tiene soporte para la compresión de bloques y es un formato que permite la división de los datos (splittable).
Avro es muy popular en el ecosistema de Hadoop y tiene soporte en la mayoría de herramientas cloud.
Formato¶
El formato Avro se basa en el uso de esquemas, los cuales definen los tipos de datos y protocolos mediante JSON. Cuando los datos .avro son leídos siempre está presente el esquema con el que han sido escritos.
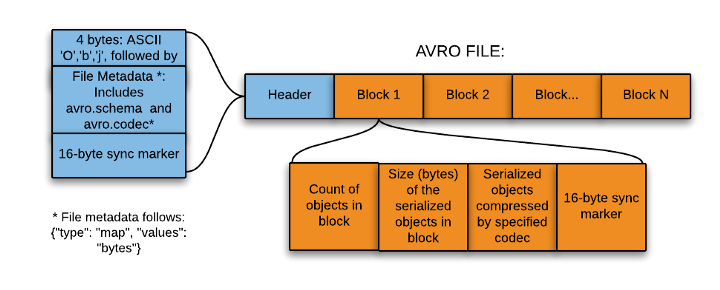
Cada fichero Avro almacena el esquema en la cabecera del fichero y luego están los datos en formato binario.
Los esquemas se componen de tipos primitivos (null, boolean, int, long, float, double, bytes, y string) y compuestos (record, enum, array, map, union, y fixed).
Un ejemplo de esquema podría ser:
{
"type" : "record",
"namespace" : "SeveroOchoa",
"name" : "Empleado",
"fields" : [
{ "name" : "Nombre" , "type" : "string" },
{ "name" : "Altura" , "type" : "float" }
{ "name" : "Edad" , "type" : "int" }
]
}
Avro y Python¶
Para poder serializar y deserializar documentos Avro mediante Python, previamente debemos instalar la librería avro:
pip install avro
# o si utilizamos Anaconda
conda install -c conda-forge avro
avro-python3 está deprecado
A partir de la versión 1.11 de Apache Avro, el paquete avro-python3 ha sido marcado como obsoleto y ha sido absorbido por el paquete avro, que ya incluye soporte nativo para Python 3.
Si ves ejemplos en internet que instalan avro-python3, actualiza la instrucción.
Vamos a realizar un ejemplo donde primero leemos un esquema de un archivo Avro, y con dicho esquema, escribiremos nuevos datos en un fichero. A continuación, abrimos el fichero escrito y leemos y mostramos los datos:
import avro
import copy
import json
from avro.datafile import DataFileReader, DataFileWriter
from avro.io import DatumReader, DatumWriter
# abrimos el fichero en modo binario y leemos el esquema
schema = avro.schema.parse(open("empleado.avsc", "rb").read())
# escribimos un fichero a partir del esquema leído
with open('empleados.avro', 'wb') as f:
writer = DataFileWriter(f, DatumWriter(), schema)
writer.append({"nombre": "Carlos", "altura": 180, "edad": 44})
writer.append({"nombre": "Juan", "altura": 175})
writer.close()
# abrimos el archivo creado, lo leemos y mostramos línea a línea
with open("empleados.avro", "rb") as f:
reader = DataFileReader(f, DatumReader())
# copiamos los metadatos del fichero leído
metadata = copy.deepcopy(reader.meta)
# obtenemos el schema del fichero leído
schemaFromFile = json.loads(metadata['avro.schema'])
# recuperamos los empleados
empleados = [empleado for empleado in reader]
reader.close()
print(f'Schema de empleado.avsc:\n {schema}')
print(f'Schema del fichero empleados.avro:\n {schemaFromFile}')
print(f'Empleados:\n {empleados}')
Schema de empleado.avsc:
{"type": "record", "name": "empleado", "namespace": "SeveroOchoa", "fields": [{"type": "string", "name": "nombre"}, {"type": "int", "name": "altura"}, {"type": ["null", "int"], "name": "edad", "default": null}]}
Schema del fichero empleados.avro:
{'type': 'record', 'name': 'empleado', 'namespace': 'SeveroOchoa', 'fields': [{'type': 'string', 'name': 'nombre'}, {'type': 'int', 'name': 'altura'}, {'type': ['null', 'int'], 'name': 'edad', 'default': None}]}
Empleados:
[{'nombre': 'Carlos', 'altura': 180, 'edad': 44}, {'nombre': 'Juan', 'altura': 175, 'edad': None}]
Accede al cuaderno en Google Colab y adjunta el archivo del empleado.avsc.
Fastavro¶
Para trabajar con Avro y grandes volúmenes de datos, es mejor utilizar la librería Fastavro (https://github.com/fastavro/fastavro) la cual ofrece un rendimiento mayor (en vez de estar codificada en Python puro, tiene algunos fragmentos realizados mediante Cython).
Primero, hemos de instalar la librería:
pip install fastavro
# o si utilizamos Anaconda
conda install -c conda-forge fastavro
Como podéis observar a continuación, hemos repetido el ejemplo y el código es muy similar:
import fastavro
import copy
import json
from fastavro import reader
# abrimos el fichero en modo binario y leemos el esquema
with open("empleado.avsc", "rb") as f:
schemaJSON = json.load(f)
schemaDict = fastavro.parse_schema(schemaJSON)
empleados = [{"nombre": "Carlos", "altura": 180, "edad": 44},
{"nombre": "Juan", "altura": 175}]
# escribimos un fichero a partir del esquema leído
with open('empleadosf.avro', 'wb') as f:
fastavro.writer(f, schemaDict, empleados)
# abrimos el archivo creado, lo leemos y mostramos línea a línea
with open("empleadosf.avro", "rb") as f:
reader = fastavro.reader(f)
# copiamos los metadatos del fichero leído
metadata = copy.deepcopy(reader.metadata)
# obtenemos el schema del fichero leído
schemaReader = copy.deepcopy(reader.writer_schema)
schemaFromFile = json.loads(metadata['avro.schema'])
# recuperamos los empleados
empleados = [empleado for empleado in reader]
print(f'Schema de empleado.avsc:\n {schemaDict}')
print(f'Schema del fichero empleadosf.avro:\n {schemaFromFile}')
print(f'Empleados:\n {empleados}')
Schema de empleado.avsc:
{'type': 'record', 'name': 'SeveroOchoa.empleado', 'fields': [{'name': 'nombre', 'type': 'string'}, {'name': 'altura', 'type': 'int'}, {'default': None, 'name': 'edad', 'type': ['null', 'int']}], '__fastavro_parsed': True, '__named_schemas': {'SeveroOchoa.empleado': {'type': 'record', 'name': 'SeveroOchoa.empleado', 'fields': [{'name': 'nombre', 'type': 'string'}, {'name': 'altura', 'type': 'int'}, {'default': None, 'name': 'edad', 'type': ['null', 'int']}]}}}
Schema del fichero empleadosf.avro:
{'type': 'record', 'name': 'SeveroOchoa.empleado', 'fields': [{'name': 'nombre', 'type': 'string'}, {'name': 'altura', 'type': 'int'}, {'default': None, 'name': 'edad', 'type': ['null', 'int']}]}
Empleados:
[{'nombre': 'Carlos', 'altura': 180, 'edad': 44}, {'nombre': 'Juan', 'altura': 175, 'edad': None}]
Accede al cuaderno en Google Colab y adjunta el archivo del empleado.avsc.
Fastavro y Pandas¶
Finalmente, vamos a realizar un último ejemplo con las dos librerías más utilizadas.
Vamos a leer un fichero CSV de ventas mediante Pandas, y tras limpiar los datos y quedarnos únicamente con las ventas de Alemania, almacenaremos el resultado del procesamiento en Avro.
import pandas as pd
from fastavro import writer, parse_schema
# Leemos el csv mediante pandas
df = pd.read_csv('pdi_sales.csv',sep=';')
# Limpiamos los datos (strip a los códigos postales) y nos quedamos con Alemania
df['Zip'] = df['Zip'].str.strip()
filtro = df.Country=="Germany"
df = df[filtro]
# 1. Definimos el esquema
schema = {
'name': 'Sales',
'namespace' : 'SeveroOchoa',
'type': 'record',
'fields': [
{'name': 'ProductID', 'type': 'int'},
{'name': 'Date', 'type': 'string'},
{'name': 'Zip', 'type': 'string'},
{'name': 'Units', 'type': 'int'},
{'name': 'Revenue', 'type': 'float'},
{'name': 'Country', 'type': 'string'}
]
}
schemaParseado = parse_schema(schema)
# 2. Convertimos el Dataframe a una lista de diccionarios
records = df.to_dict('records')
# 3. Persistimos en un fichero avro
with open('sales.avro', 'wb') as f:
writer(f, schemaParseado, records)
Accede al cuaderno en Google Colab y adjunta el archivo de ventas pdi_sales.csv.
Acceso HDFS
También podemos conectarnos a HDFS para leer y persistir datos en formato Avro:
import pandas as pd
from fastavro import parse_schema
from hdfs import InsecureClient
from hdfs.ext.avro import AvroWriter
from hdfs.ext.dataframe import write_dataframe
# 1. Nos conectamos a HDFS
HDFS_HOSTNAME = 'iabd-virtualbox'
HDFSCLI_PORT = 9870
HDFSCLI_CONNECTION_STRING = f'http://{HDFS_HOSTNAME}:{HDFSCLI_PORT}'
hdfs_client = InsecureClient(HDFSCLI_CONNECTION_STRING)
# 2. Leemos el Dataframe
with hdfs_client.read('/user/iabd/pdi_sales.csv') as reader:
df = pd.read_csv(reader,sep=';')
# Limpiamos los datos (strip a los códigos postales) y nos quedamos con Alemania
df['Zip'] = df['Zip'].str.strip()
filtro = df.Country=="Germany"
df = df[filtro]
# 3. Definimos el esquema
schema = {
'name': 'Sales',
'namespace' : 'SeveroOchoa',
'type': 'record',
'fields': [
{'name': 'ProductID', 'type': 'int'},
{'name': 'Date', 'type': 'string'},
{'name': 'Zip', 'type': 'string'},
{'name': 'Units', 'type': 'int'},
{'name': 'Revenue', 'type': 'float'},
{'name': 'Country', 'type': 'string'}
]
}
schemaParseado = parse_schema(schema)
# 4a. Persistimos en un fichero avro dentro de HDFS mediante la extension AvroWriter de hdfs
with AvroWriter(hdfs_client, '/user/iabd/sales.avro', schemaParseado) as writer:
records = df.to_dict('records') # diccionario
for record in records:
writer.write(record)
# 4b. O directamente persistimos el Dataframe mediante la extension write_dataframe de hdfs
write_dataframe(hdfs_client, '/user/iabd/sales2.avro', df) # infiere el esquema
write_dataframe(hdfs_client, '/user/iabd/sales3.avro', df, schema=schemaParseado)
Para el acceso HDFS, dentro de la librería HdfsCLI que vimos en la sesión sobre HDFS, hemos utilizado las extensiones Fastavro y Pandas.
Comprimiendo los datos¶
¿Y si...
¿Y sí comprimimos los datos para ocupen menos espacio en nuestro clúster y por tanto, nos cuesten menos dinero?
La compresión de datos es compleja, pero la idea básica es fácil de entender, ya que los algoritmos de compresión buscan redundancia y repetición en los datos, recodificando los datos para reducir la redundancia.
Al comprimir los datos, además de ocupar menos espacio, la lectura de éstos será más rápida y se enviarán menos datos a través de la red, mejorando los tiempos de trabajo. Eso sí, no hemos de olvidar que comprimir y descomprimir los archivos conlleva un tiempo extra y consumo de recursos para leer o escribir los datos.
Fastavro soporta dos tipos de compresión: gzip (mediante el algoritmo deflate) y snappy. Snappy es una biblioteca de compresión y descompresión de datos de gran rendimiento que se utiliza con frecuencia en proyectos Big Data, la cual prioriza la velocidad sobre el tamaño resultante.
Antes de nada la hemos de instalar mediante:
pip install python-snappy
Para indicar el tipo de compresión, únicamente hemos de añadir un parámetros extra con el algoritmo de compresión en la función/constructor de persistencia:
writer(f, schemaParseado, records, 'deflate')
with AvroWriter(hdfs_client, '/user/iabd/sales.avro', schemaParseado, 'snappy') as writer:
write_dataframe(hdfs_client, '/user/iabd/sales3.avro', df, schema=schemaParseado, codec='snappy')
Comparando algoritmos de compresión
Respecto a la compresión, sobre un fichero de 100GB, podemos considerar media si ronda los 50GB y alta si baja a los 40GB.
| Algoritmo | Velocidad | Compresión | Uso habitual |
|---|---|---|---|
| Gzip / deflate | Media | Media | Avro, Parquet |
| Bzip2 | Lenta | Alta | HDFS (archivado) |
| Snappy | Alta | Media | Avro, Parquet, ORC |
| Zstandard (zstd) | Alta | Alta | Parquet moderno |
Zstandard (desarrollado por Facebook/Meta) combina una velocidad comparable a Snappy con ratios de compresión similares a gzip, lo que lo convierte en la opción preferida en los entornos Parquet más recientes. Para usarlo con PyArrow:
pq.write_table(tabla, 'empleados_zstd.parquet', compression='zstd')
Y con pandas:
df.to_parquet('pdi_sales_zstd.parquet', compression='zstd')
Más que un tema de espacio, necesitamos que los procesos sean eficientes y por eso priman los algoritmos que son más rápidos. Si te interesa el tema, es muy interesante el artículo Data Compression in Hadoop.
Por ejemplo, si realizamos el ejemplo de Fast Avro y Pandas con acceso local obtenemos los siguientes tamaños:
- Sin compresión: 6,9 MiB
- Gzip: 1,9 MiB
- Snappy: 2,8 MiB
Arrow¶
Apache Arrow es una especificación de formato columnar en memoria diseñada para el procesamiento analítico eficiente de datos. A diferencia de Avro, Parquet u ORC —que son formatos de almacenamiento en disco—, Arrow define cómo representar datos en RAM de forma que diferentes herramientas y lenguajes puedan compartirlos sin copiarlos ni serializarlos.
Hoy en día Arrow se ha convertido en la capa de interoperabilidad estándar del ecosistema de datos en Python: pandas (a partir de la versión 2.0), Polars, DuckDB, Spark y muchas otras herramientas lo utilizan como formato interno o como mecanismo de intercambio.
Sus principales ventajas son:
- Zero-copy: dos procesos distintos pueden leer los mismos datos en memoria sin duplicarlos.
- Vectorización: el formato columnar facilita las operaciones SIMD que aceleran los cálculos analíticos.
- Interoperabilidad: la misma representación en memoria funciona en Python, R, Java, C++, Rust, etc.
- Ecosistema: es la base sobre la que se construyen Parquet, ORC (lectura/escritura) y el formato Feather.
PyArrow¶
PyArrow es la librería Python que implementa Apache Arrow. Se instala mediante:
pip install pyarrow
La estructura de datos central de PyArrow es la tabla (pa.Table), equivalente a un DataFrame pero con tipado estricto y representación columnar:
import pyarrow as pa
# Definimos el esquema
schema = pa.schema([
('nombre', pa.string()),
('altura', pa.int32()),
('edad', pa.int32())
])
# Creamos una tabla a partir de un diccionario (columnas)
datos = {
'nombre': ['Carlos', 'Juan'],
'altura': [180, 175],
'edad': [44, None]
}
tabla = pa.Table.from_pydict(datos, schema=schema)
print(tabla)
# pyarrow.Table
# nombre: string
# altura: int32
# edad: int32
# nombre: [["Carlos","Juan"]]
# altura: [[180,175]]
# edad: [[44,null]]
PyArrow como backend de pandas¶
A partir de pandas 2.0, es posible usar Arrow como motor subyacente del DataFrame. Esto mejora el rendimiento en operaciones analíticas y reduce el uso de memoria, especialmente con cadenas de texto y valores nulos:
import pandas as pd
# Leemos el CSV usando Arrow como backend
df = pd.read_csv('pdi_sales.csv', sep=';', dtype_backend='pyarrow')
print(df.dtypes)
La diferencia respecto al comportamiento tradicional es que los tipos de columna pasan a ser tipos Arrow (string[pyarrow], int64[pyarrow], etc.) en lugar de los tipos NumPy habituales.
¿Cuándo interesa usar el backend Arrow en pandas?
El backend Arrow es especialmente útil cuando trabajamos con columnas de texto, valores nulos frecuentes o datos de tipo fecha/hora, ya que los tipos Arrow gestionan estos casos de forma más eficiente que NumPy. Para operaciones numéricas puras, la diferencia es menor.
El formato Feather / Arrow IPC¶
Además de ser un formato en memoria, Arrow define un formato de fichero denominado Feather (o Arrow IPC), pensado para persistir datos de forma rápida entre etapas de un pipeline. No está optimizado para archivado a largo plazo (como sí lo está Parquet), sino para serialización temporal de alta velocidad:
import pyarrow as pa
import pyarrow.feather as feather
import pandas as pd
df = pd.read_csv('pdi_sales.csv', sep=';')
# Persistimos en formato Feather
feather.write_feather(df, 'pdi_sales.feather')
# Leemos el fichero
df2 = feather.read_feather('pdi_sales.feather')
Parquet¶
Apache Parquet es un formato de almacenamiento basado en columnas para Hadoop, con soporte para todos los frameworks de procesamiento de datos, así como lenguajes de programación. De la misma forma que Avro, se trata de un formato de datos auto-descriptivo, de manera que embebe el esquema o estructura de los datos con los propios datos en sí. Parquet es idóneo para analizar datasets que contienen muchas columnas, es decir, para lecturas de grandes cargas de trabajo.
Tiene un ratio de compresión muy alto (mediante Snappy ronda el 75%), y además, solo se recorren las columnas necesarias en cada lectura, lo que reduce las operaciones de entrada/salida en disco.
Formato¶
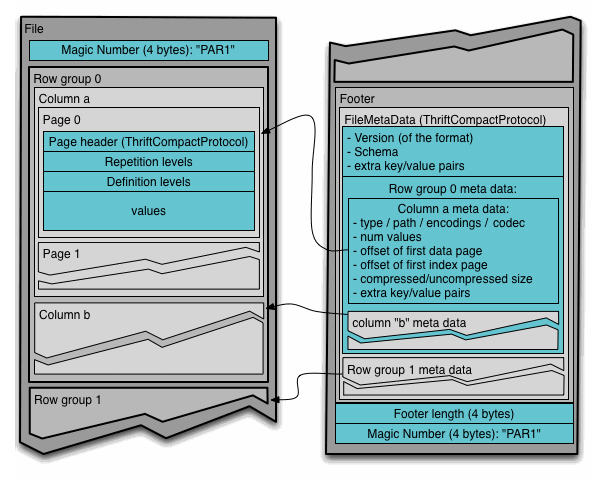
Cada fichero Parquet almacena los datos en binario organizados en grupos de filas. Para cada grupo de filas (row group), los valores de los datos se organizan en columnas, lo que facilita la compresión a nivel de columna.
La columna de metadatos de un fichero Parquet se almacena al final del fichero, lo que permite que las escrituras sean rápidas con una única pasada. Los metadatos pueden incluir información como los tipos de datos, esquemas de codificación/compresión, estadísticas, nombre de los elementos, etc...
Parquet y Python¶
Para interactuar con el formato Parquet mediante Python, la librería más utilizada es la que ofrece Apache Arrow, en concreto la librería PyArrow.
Así pues, la instalamos mediante pip:
pip install pyarrow
Apache Arrow usa un tipo de estructura denominada tabla para almacenar los datos bidimensional (sería muy similar a un Dataframe de Pandas). La documentación de PyArrow dispone de un libro de recetas con ejemplos con código para los diferentes casos de uso que se nos puedan plantear.
Vamos a simular el mismo ejemplo que hemos realizado previamente mediante Avro, y vamos a crear un fichero en formato JSON con empleados, y tras persistirlo en formato Parquet, lo vamos a recuperar:
import pyarrow.parquet as pq
import pyarrow as pa
# 1.- Definimos el esquema
schema = pa.schema([ ('nombre', pa.string()),
('altura', pa.int32()),
('edad', pa.int32()) ])
# 2.- Almacenamos los empleados por columnas
empleados = {"nombre": ["Carlos", "Juan"],
"altura": [180, 44],
"edad": [None, 34]}
# 3.- Creamos una tabla Arrow y la persistimos mediante Parquet
tabla = pa.Table.from_pydict(empleados, schema)
pq.write_table(tabla, 'empleados.parquet')
# 4.- Leemos el fichero generado
table2 = pq.read_table('empleados.parquet')
schemaFromFile = table2.schema
print(f'Schema del fichero empleados.parquet:\n{schemaFromFile}\n')
print(f'Tabla de Empleados:\n{table2}')
Para que pyarrow pueda leer los empleados como documentos JSON, a día de hoy sólo puede hacerlo leyendo documentos individuales almacenados en fichero:
Por lo tanto, creamos el fichero empleados.json con la siguiente información:
{ "nombre": "Carlos", "altura": 180, "edad": 44 }
{ "nombre": "Juan", "altura": 175 }
De manera que podemos leer los datos JSON y persistirlos en Parquet del siguiente modo:
import pyarrow.parquet as pq
import pyarrow as pa
from pyarrow import json
# 1.- Definimos el esquema
schema = pa.schema([ ('nombre', pa.string()),
('altura', pa.int32()),
('edad', pa.int32()) ])
# 2.- Leemos los empleados
tabla = json.read_json("empleados.json")
# 3.- Persistimos la tabla en Parquet
pq.write_table(tabla, 'empleados-json.parquet')
# 4.- Leemos el fichero generado
table2 = pq.read_table('empleados-json.parquet')
schemaFromFile = table2.schema
print(f'Schema del fichero empleados-json.parquet:\n{schemaFromFile}\n')
print(f'Tabla de Empleados:\n{table2}')
En ambos casos obtendríamos algo similar a:
Schema del fichero empleados.parquet:
nombre: string
altura: int32
edad: int32
Tabla de Empleados:
pyarrow.Table
nombre: string
altura: int32
edad: int32
----
nombre: [["Carlos","Juan"]]
altura: [[180,44]]
edad: [[null,34]]
Parquet y Pandas¶
En el caso del uso de Pandas el código todavía se simplifica más.
Si reproducimos el mismo ejemplo que hemos realizado con Avro tenemos que los Dataframes ofrecen el método to_parquet para exportar a un fichero Parquet:
import pandas as pd
df = pd.read_csv('pdi_sales.csv',sep=';')
df['Zip'] = df['Zip'].str.strip()
filtro = df.Country=="Germany"
df = df[filtro]
# A partir de un DataFrame, persistimos los datos
df.to_parquet('pdi_sales.parquet')
Para leer un archivo utilizaremos el método read_parquet:
df_parquet = pd.read_parquet("pdi_sales.parquet")
Parquet y HDFS
Si quisiéramos almacenar el archivo directamente en HDFS, necesitamos indicarle a Pandas la dirección del sistema de archivos que tenemos configurado en core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://iabd-virtualbox:9000</value>
</property>
Así pues, únicamente necesitamos modificar el nombre del archivo donde serializamos los datos a Parquet:
df.to_parquet('hdfs://iabd-virtualbox:9000/sales.parquet')
Parquet y DuckDB¶
DuckDB es un motor analítico SQL embebido (sin servidor, similar a SQLite pero orientado a OLAP) que se ha convertido en una herramienta de referencia para explorar y transformar datos localmente. Una de sus características más prácticas es la capacidad de consultar ficheros Parquet directamente mediante SQL, sin necesidad de cargarlos en memoria ni levantar ningún servidor.
Se instala mediante:
pip install duckdb
El uso más sencillo es lanzar una consulta SQL directamente sobre un fichero .parquet:
import duckdb
# Consulta directa sobre un fichero Parquet
resultado = duckdb.sql("SELECT * FROM 'pdi_sales.parquet' WHERE Country = 'Germany' LIMIT 5")
print(resultado)
También podemos integrarlo con pandas para aprovechar lo mejor de ambos mundos:
import duckdb
import pandas as pd
# Cargamos el fichero en un DataFrame
df = pd.read_parquet('pdi_sales.parquet')
# Ejecutamos una consulta SQL sobre el DataFrame directamente
resultado = duckdb.sql("SELECT Country, SUM(Revenue) AS total FROM df GROUP BY Country ORDER BY total DESC")
print(resultado.df()) # .df() convierte el resultado en un DataFrame de pandas
DuckDB puede consultar simultáneamente múltiples ficheros Parquet mediante patrones glob, lo que resulta muy útil cuando los datos están particionados:
# Leer todos los ficheros parquet de un directorio
resultado = duckdb.sql("SELECT * FROM 'ventas/*.parquet' WHERE año = 2024")
DuckDB y el ecosistema Arrow
DuckDB usa Apache Arrow internamente como formato de intercambio, lo que significa que la conversión entre tablas DuckDB, DataFrames de pandas y tablas PyArrow es prácticamente instantánea y sin copia de datos.
ORC¶
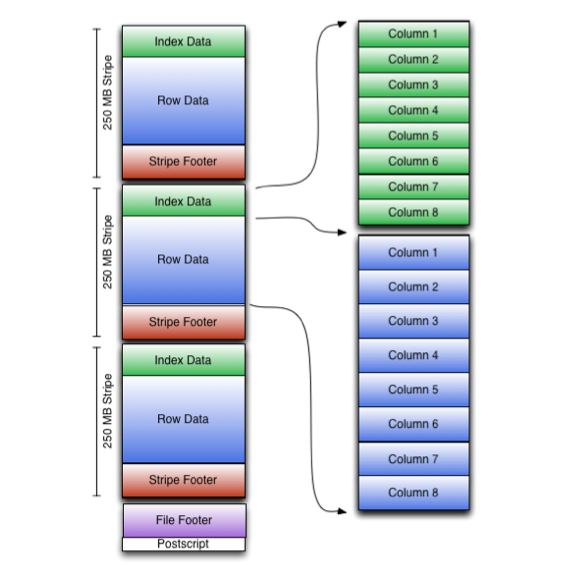
Apache ORC es un formato de datos columnar (Optimized Row Columnar) similar a Parquet pero optimizado para la lectura, escritura y procesamiento de datos en Hive. ORC tiene una tasa de compresión alta (utiliza zlib), y al basarse en Hive, soporta sus tipos de datos simples (datetime, decimal, etc...) y los tipos complejos (como struct, list, map y union), siendo totalmente compatible con HiveQL.
Los fichero ORC se componen de tiras de datos (stripes), donde cada tira contiene un índice, los datos de la fila y un pie (con estadísticas como la cantidad, máximos y mínimos y la suma de cada columna convenientemente cacheadas)
ORC y Python¶
Si queremos usar Pandas, para leer un fichero ORC emplearemos el método read_orc:
df_orc = pd.read_orc('pdi_sales.orc')
Y para persistirlo, desde la versión 1.5 de Pandas, a partir de un DataFrame, podemos persistir los datos mediante el método to_orc.
df_orc.to_orc('pdi_sales_pd.orc')
Por defecto, los archivos ORC se persisten sin comprimir. Si queremos comprimirlos, debemos pasarle los parámetros mediante el atributo engine_kwargs mediante un diccionario:
df_orc.to_orc('pdi_sales_zlib.orc', engine_kwargs={"compression":'zlib'})
Además, también podemos podemos hacerlo de nuevo desde la librería PyArrow. Así pues, para la escritura de datos, por ejemplo, desde un Dataframe, haríamos:
import pandas as pd
import pyarrow as pa
import pyarrow.orc as orc
df = pd.read_csv('pdi_sales.csv',sep=';')
# Limpiamos los datos (strip a los códigos postales) y nos quedamos con Alemania
df['Zip'] = df['Zip'].str.strip()
filtro = df.Country=="Germany"
df = df[filtro]
table = pa.Table.from_pandas(df, preserve_index=False)
orc.write_table(table, 'pdi_sales.orc')
Formatos de tabla abiertos¶
Los formatos que hemos visto (Avro, Parquet, ORC) resuelven el problema de cómo almacenar los datos en ficheros. Sin embargo, en entornos de producción surge una necesidad adicional: gestionar cambios sobre esos datos (actualizaciones, borrados, versionado, transacciones ACID) sin las limitaciones de un sistema de ficheros simple.
Para eso existen los denominados formatos de tabla abiertos (open table formats), que son básicamente Parquet + un registro de transacciones encima:
| Formato | Base | Mantenido por | Integración destacada |
|---|---|---|---|
| Delta Lake | Parquet + log JSON | Linux Foundation / Databricks | Spark, Databricks |
| Apache Iceberg | Parquet / ORC / Avro + catálogo | Apache / Netflix | Spark, Flink, Trino, AWS Athena |
| Apache Hudi | Parquet + índice | Apache / Uber | Spark, Flink, AWS EMR |
La idea central es la misma en los tres casos: los ficheros de datos (normalmente Parquet) no se modifican directamente. En su lugar, cada operación de escritura genera un nuevo fichero y registra el cambio en un log de transacciones. Esto permite:
- Consultas time travel: leer el estado de la tabla en un momento anterior.
- Transacciones ACID: garantías de atomicidad e integridad, incluso con escrituras concurrentes.
- Evolución del esquema: añadir o renombrar columnas sin reescribir los datos.
- Compactación: combinar muchos ficheros pequeños en menos ficheros grandes de forma transparente.
¿Cuándo nos los encontraremos?
En entornos Spark (especialmente con Databricks) es muy frecuente trabajar sobre tablas Delta Lake. En AWS, Iceberg es el formato preferido por servicios como Athena o Glue. Si continúas el itinerario con Spark, encontrarás una sesión dedicada a Delta Lake.
Un ejemplo mínimo con Delta Lake y PySpark sería:
# Escritura en formato Delta
df.write.format("delta").save("/ruta/ventas_delta")
# Lectura con time travel (versión anterior)
df_v0 = spark.read.format("delta").option("versionAsOf", 0).load("/ruta/ventas_delta")
No es necesario profundizar en estos formatos aquí ya que más adelante estudiaremos en profundidad el formato Delta, pero conviene tener presente que Parquet es el formato de fichero subyacente en la mayoría de los casos, y que los formatos de tabla abiertos añaden la capa de gestión que Parquet por sí solo no proporciona.
Comparando formatos¶
Acabamos de ver que cada uno de los formatos tiene sus puntos fuertes.
Los formatos basados en filas ofrecen un rendimiento mayor en las escrituras que en las lecturas, ya que añadir nuevos registros en más sencillo. Si sólo vamos a hacer consultas sobre un subconjunto de las columnas, entonces un formato columnar se comportará mejor, ya que no necesita recuperar los registros enteros (cosa que sí hacen los formatos basados en filas).
Respecto a la compresión, entendiendo que ofrece una ventaja a la hora de almacenar y transmitir la información, es útil cuando trabajamos con un gran volumen de datos. Los formatos basado en columnas ofrecen un mejor rendimiento ya que todos los datos del mismo tipo se almacenan de forma contigua lo que permite una mayor eficiencia en la compresión (además, cada tipo de columna tiene su propia codificación).
Respecto a la evolución del esquema, con operaciones como añadir o eliminar columnas o cambiar su nombre, la mejor decisión es decantarse por Avro. Además, al tener el esquema en JSON facilita su gestión y permite que tengan más de un esquema.
Si nuestros documentos tienen una estructura compleja compuesta por columnas anidadas y normalmente realizamos consultas sobre un subconjunto de las subcolumnas, la elección debería ser Parquet, por la estructura que utiliza.
Finalmente, recordar que ORC está especialmente enfocado a su uso con Hive, mientras que Spark tiene un amplio soporte para Parquet y que si trabajamos con Kafka, Avro es una buena elección.
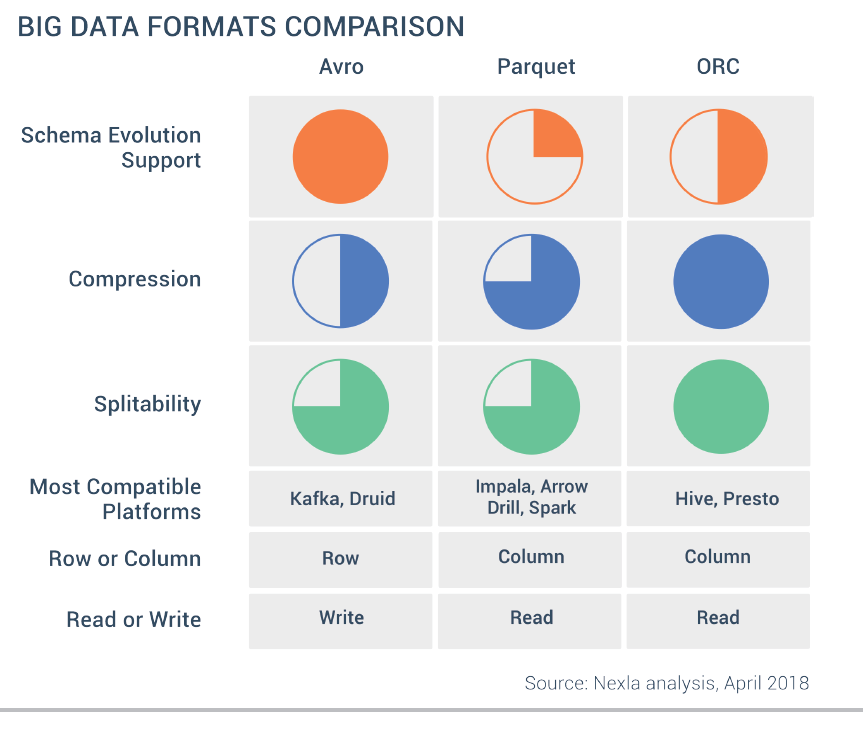
Si nos centramos en los formatos modernos aparecidos en los últimos años, como Arrow y Feather, Feather es generalmente el más rápido tanto en lectura como en escritura, a costa de producir ficheros algo más grandes que Parquet comprimido.
| Formato | Velocidad escritura | Velocidad lectura | Tamaño |
|---|---|---|---|
| CSV | Lenta | Lenta | Grande |
| Feather / Arrow | Muy rápida | Muy rápida | Medio |
| Parquet (snappy) | Rápida | Rápida | Pequeño |
| Avro | Rápida | Rápida | Medio |
| ORC | Media | Media | Pequeño |
¿Feather o Parquet?
Usa Feather para ficheros intermedios que se leen y escriben frecuentemente dentro de un mismo pipeline (por ejemplo, guardar el resultado de una transformación para la siguiente fase). Usa Parquet para almacenamiento definitivo, especialmente si va a ser leído por Spark, Athena u otras herramientas de análisis.
Si comparamos los tamaños de los archivos respecto al formato de datos empleado con únicamente las ventas de Alemania tendríamos:
ger_sales.csv: 9,7 MiBger_sales.avro: 6,9 MiBger_sales-gzip.avro: 1,9 MiBger_sales-snappy.avro: 2,8 MiB
ger_sales.parquet: 2,3 MiBger_sales-gzip.parquet: 1,6 MiBger_sales-snappy.parquet: 2,3 MiB
ger_sales.orc: 6,98 MiB
Referencias¶
- Introduction to Big Data Formats
- Introduction to Data Serialization in Apache Hadoop
- Handling Avro files in Python
- Big Data File Formats Demystified
Actividades¶
-
(RABDA.1 / CEBDA.1c / 1.5p) Mediante Python y utilizando Kaggle, crea un notebook a partir de los datos del dataset de retrasos en los vuelos y a partir de uno de los ficheros (el que más te guste), y teniendo en cuenta que los campos están separados por comas (
,), transforma los datos y persiste los siguientes archivos:air<anyo>.parquet: el archivo CSV en formato Parquet.air<anyo>.orc: el archivo CSV en formato ORC.air<anyo>_snappy.orc: el archivo CSV comprimido en formato Snappy en formato ORC.-
air<anyo>_small.avro: la fecha (FL_DATE), el identificador de la aerolínea (OP_CARRIER) y el retraso de cada vuelo (DEP_DELAY) en formato Avro.Seleccionando columnas
Mediante Pandas, cuando tenemos un DataFrame, podemos seleccionar un subconjunto de las columnas de la siguiente forma:
# df es un DataFrame que contiene todas las columnas df_small = df[['FL_DATE', 'OP_CARRIER', 'DEP_DELAY']] -
air<anyo>_small.parquet: con los mismos atributos pero en Parquet.
Adjunta una captura del cuaderno, anota los tamaños de los ficheros creados y el tiempo necesario para su creación (agrupa todos los datos en una celda a modo de tabla para poder compararlos visualmente, por ejemplo, mediante una celda de tipo Markdown), y finalmente, comparte el notebook con el usuario Aitor Medrano de Kaggle.
Compartir el notebook
Si a la hora de compartir el notebook Kaggle te pide confirmar la cuenta y solicita datos personales que no quieres que tenga, puedes descargar el cuaderno y adjuntar el mismo en la entrega.
Para el tamaño de los archivos, puedes comprobarlo en el panel lateral derecho de Kaggle dentro de Output, o utilizar el método
os.path.getsize(ruta):import os os.path.getsize("/kaggle/working/air20XX.parquet)Respecto al tiempo, por ejemplo puedes obtenerlo así:
import time inicio = time.time() # operación a medir fin = time.time() print(fin - inicio)Kaggle
Para poder realizar el ejercicio, es necesario crear una cuenta en Kaggle para que, al ejecutar el cuaderno, la instancia de la máquina pueda cargar tantos datos.
Al estar registrado, de forma gratuita, las instancias permiten almacenar hasta 73 GB de datos y emplear 30GB de RAM durante 12 horas. Si no, sólo dispondremos de 1GB de RAM.
-
(RABDA.1 / CEBDA.1c / 1p) A partir del mismo fichero CSV de vuelos que acabas de emplear en la actividad anterior, realiza las siguientes operaciones sin usar pandas como capa principal, trabajando directamente con PyArrow:
- Lee el fichero CSV mediante
pyarrow.csv.read_csv()y muestra el esquema inferido. - Persiste los datos en formato Feather (
pyarrow.feather.write_feather). - Vuelve a leer el fichero Feather y compara el tiempo de lectura con el del CSV original
(usa
time.time()o la magia%%timede Jupyter). - Compara los tamaños de ambos ficheros e incluye los resultados en una celda Markdown.
- Lee el fichero CSV mediante
-
(RABDA.1 / CEBDA.1c / 0.5p) Usando el fichero
air<anyo>.parquetgenerado en la actividad 1 y DuckDB, responde a las siguientes preguntas mediante consultas SQL directas sobre el fichero (sin cargarlo en pandas):- ¿Cuántos vuelos hay por aerolínea (
OP_CARRIER)? Ordénalos de mayor a menor. - ¿Cuál es el retraso medio de salida (
DEP_DELAY) por aerolínea, excluyendo los valores nulos y los retrasos negativos (adelantos)?
- ¿Cuántos vuelos hay por aerolínea (