Sqoop¶
Dentro del ecosistema de Hadoop, las dos herramientas principales utilizadas para importar/exportar datos en HDFS son Sqoop y Flume. En esta sesión nos vamos a centrar en la primera. Fuera del ecosistema Hadoop, otras herramientas que podemos utilizar para ingestar datos en HDFS son Apache Nifi o Apache Spark.
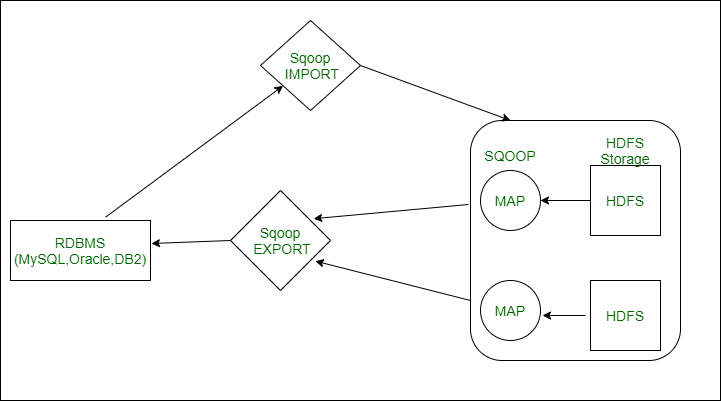
Apache Sqoop es una herramienta diseñada para transferir de forma eficiente datos crudos entre un cluster de Hadoop y un almacenamiento estructurado, como una base de datos relacional.
Sin continuidad
Desde junio de 2021, el proyecto Sqoop ha dejado de mantenerse como proyecto de Apache y forma parte del ático. Aún así, creemos conveniente conocer su uso en el estado actual.
Un caso típico de uso es el de cargar los datos en un data lake (ya sea en HDFS o en S3) con datos que importaremos desde una base de datos relacional, como MariaDB o PostgreSQL.
Sqoop utiliza una arquitectura basada en conectores, con soporte para plugins que ofrecen la conectividad a los sistemas externos, como pueden ser Oracle o SQL Server. Internamente, Sqoop utiliza los algoritmos MapReduce para importar y exportar los datos.
Por defecto, todos los trabajos Sqoop ejecutan cuatro mapas de trabajo, de manera que los datos se dividen en cuatro nodos de Hadoop.
Instalación
Aunque en la máquina virtual con la que trabajamos ya tenemos tanto Hadoop como Sqoop instalados, podemos descargar la última versión desde http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz.
Se recomienda seguir las instrucciones resumidas que tenemos en https://www.tutorialspoint.com/sqoop/sqoop_installation.htm o las de https://riptutorial.com/sqoop.
Un par de aspectos que hemos tenido que modificar en nuestra máquina virtual son:
- Copiar el driver de MySQL en
$SQOOP_HOME/lib - Copiar la librería commons-langs-2.6 en
$SQOOP_HOME/lib
Una vez configurado, podemos comprobar su funcionamiento, por ejemplo, consultando las bases de datos que tenemos en MariaDB (aparecen mensajes de warning por no tener instalados/configurados algunos productos) mediante sqoop list-databases:
sqoop list-databases --connect jdbc:mysql://localhost --username=iabd --password=iabd
Importando datos¶
La sintaxis básica de Sqoop para importar datos en HDFS mediante el comando sqoop import es:
sqoop import --connect jdbc:mysql://host/nombredb --table <nombreTabla> \
--username <usuarioMariaDB> --password <passwordMariaDB> -m 2
El único parámetro que conviene explicar es -m 2, el cual está indicando que utilice dos mappers en paralelo para importar los datos. Si no le indicamos este parámetro, como hemos comentado antes, Sqoop siempre utilizará cuatro mappers.
La importación se realiza en dos pasos:
- Sqoop escanea la base de datos y colecta los metadatos de la tabla a importar. Con esos datos, envía un job y transfiere los datos reales utilizando los metadatos necesarios.
- De forma paralela, cada uno de los mappers se encarga de cargar en HDFS una parte proporcional de los datos.
Los datos importados se almacenan en carpetas de HDFS, pudiendo especificar otras carpetas, así como los caracteres separadores o de terminación de registro. Además, podemos utilizar diferentes formatos, como son Avro, ORC, Parquet, ficheros secuenciales o de tipo texto, para almacenar los datos en HDFS.
Caso 1 - Importando datos desde MariaDB¶
En el siguiente caso de uso vamos a importar datos que tenemos en una base de datos de MariaDB a HDFS.
Sqoop y las zonas horarias
Cuando se lanza Sqoop captura los timestamps de nuestra base de datos origen y los convierte a la hora del sistema servidor por lo que tenemos que especificar en nuestra base de datos la zona horaria.
Para realizar estos ajustes simplemente editamos el fichero mysqld.cnf que se encuentra en /etc/mysql/my.cnf/ y añadimos la siguiente propiedad para asignarle nuestra zona horaria:
[mariadb]
default_time_zone = 'Europe/Madrid'
En nuestra máquina virtual este paso ya está realizado.
Primero, vamos a preparar nuestro entorno. Una vez conectados a MariaDB, por ejemplo, mediante mariadb -u iabd -p, creamos una base de datos que contenga una tabla con información sobre profesores:
create database sqoopCaso1;
use sqoopCaso1;
CREATE TABLE profesores(
id MEDIUMINT NOT NULL AUTO_INCREMENT,
nombre CHAR(30) NOT NULL,
edad INTEGER(30),
materia CHAR(30),
PRIMARY KEY (id) );
Insertamos datos en la tabla profesores:
INSERT INTO profesores (nombre, edad, materia) VALUES ("Carlos", 24, "Matemáticas"),
("Pedro", 32, "Inglés"), ("Juan", 35, "Tecnología"), ("Jose", 48, "Matemáticas"),
("Paula", 24, "Informática"), ("Susana", 32, "Informática"), ("Lorena", 54, "Informática");
A continuación, arrancamos HDFS y YARN:
start-dfs.sh
start-yarn.sh
Con el comando sqoop list-tables listamos todas las tablas de la base de datos sqoopCaso1:
sqoop list-tables --connect jdbc:mysql://localhost/sqoopCaso1 --username=iabd --password=iabd
Y finalmente importamos los datos mediante el comando sqoop import:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \ # (1)!
--username=iabd --password=iabd \ # (2)!
--table=profesores --driver=com.mysql.jdbc.Driver \ # (3)!
--target-dir=/user/iabd/sqoop/profesores_hdfs \ # (4)!
--fields-terminated-by=',' --lines-terminated-by '\n' # (5)!
- Indicamos que vamos a importar datos desde una conexión JDBC, donde se indica el SGBD (
mysql), el host (localhost) y el nombre de la base de datos (sqoopCaso1). - Se configura tanto el usuario como la contraseña del usuario (
iabd/iabd) que se conecta a la base de datos. - Indicamos la tabla que vamos a leer (
profesores) y el driver que utilizamos. - Configuramos el destino HDFS donde se van a importar los datos.
- Indicamos el separador de los campos y el carácter para separar las líneas.
Si queremos que en el caso de que ya exista la carpeta de destino la borre previamente, añadiremos la opción --delete-target-dir.
Unhealthy node
Nuestra máquina virtual tiene el espacio limitado, y es probable que en algún momento se llene el disco. Además de eliminar archivos no necesarios, una opción es configurar YARN mediante el archivo yarn-site.xml y configurar las siguientes propiedades para ser más permisivos con la falta de espacio:
<property>
<name>yarn.nodemanager.disk-health-checker.min-healthy-disks</name>
<value>0.0</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>100.0</value>
</property>
El resultado que aparece en consola es:
2021-12-14 17:19:04,684 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2021-12-14 17:19:04,806 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2021-12-14 17:19:05,057 WARN sqoop.ConnFactory: Parameter --driver is set to an explicit driver however appropriate connection manager is not being set (via --connection-manager). Sqoop is going to fall back to org.apache.sqoop.manager.GenericJdbcManager. Please specify explicitly which connection manager should be used next time.
2021-12-14 17:19:05,087 INFO manager.SqlManager: Using default fetchSize of 1000
2021-12-14 17:19:05,087 INFO tool.CodeGenTool: Beginning code generation
2021-12-14 17:19:05,793 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM profesores AS t WHERE 1=0
2021-12-14 17:19:05,798 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM profesores AS t WHERE 1=0
2021-12-14 17:19:05,877 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/hadoop-3.3.1
Note: /tmp/sqoop-iabd/compile/585dc8a5a92b80ebbd22c9f597dd1928/profesores.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
2021-12-14 17:19:12,153 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-iabd/compile/585dc8a5a92b80ebbd22c9f597dd1928/profesores.jar
2021-12-14 17:19:12,235 INFO mapreduce.ImportJobBase: Beginning import of profesores
2021-12-14 17:19:12,240 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2021-12-14 17:19:12,706 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2021-12-14 17:19:12,714 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM profesores AS t WHERE 1=0
2021-12-14 17:19:14,330 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2021-12-14 17:19:14,608 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at iabd-virtualbox/127.0.1.1:8032
2021-12-14 17:19:16,112 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/iabd/.staging/job_1639498733738_0001
2021-12-14 17:19:22,016 INFO db.DBInputFormat: Using read commited transaction isolation
2021-12-14 17:19:22,018 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(id), MAX(id) FROM profesores
2021-12-14 17:19:22,022 INFO db.IntegerSplitter: Split size: 1; Num splits: 4 from: 1 to: 7
2021-12-14 17:19:22,214 INFO mapreduce.JobSubmitter: number of splits:4
2021-12-14 17:19:22,707 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1639498733738_0001
2021-12-14 17:19:22,707 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-12-14 17:19:23,390 INFO conf.Configuration: resource-types.xml not found
2021-12-14 17:19:23,391 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-12-14 17:19:24,073 INFO impl.YarnClientImpl: Submitted application application_1639498733738_0001
2021-12-14 17:19:24,300 INFO mapreduce.Job: The url to track the job: http://iabd-virtualbox:8088/proxy/application_1639498733738_0001/
2021-12-14 17:19:24,303 INFO mapreduce.Job: Running job: job_1639498733738_0001
2021-12-14 17:19:44,015 INFO mapreduce.Job: Job job_1639498733738_0001 running in uber mode : false
2021-12-14 17:19:44,017 INFO mapreduce.Job: map 0% reduce 0%
2021-12-14 17:20:21,680 INFO mapreduce.Job: map 50% reduce 0%
2021-12-14 17:20:23,707 INFO mapreduce.Job: map 100% reduce 0%
2021-12-14 17:20:24,736 INFO mapreduce.Job: Job job_1639498733738_0001 completed successfully
2021-12-14 17:20:24,960 INFO mapreduce.Job: Counters: 34
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=1125124
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=377
HDFS: Number of bytes written=163
HDFS: Number of read operations=24
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
HDFS: Number of bytes read erasure-coded=0
Job Counters
Killed map tasks=1
Launched map tasks=4
Other local map tasks=4
Total time spent by all maps in occupied slots (ms)=139377
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=139377
Total vcore-milliseconds taken by all map tasks=139377
Total megabyte-milliseconds taken by all map tasks=142722048
Map-Reduce Framework
Map input records=7
Map output records=7
Input split bytes=377
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=1218
CPU time spent (ms)=5350
Physical memory (bytes) snapshot=560439296
Virtual memory (bytes) snapshot=10029588480
Total committed heap usage (bytes)=349175808
Peak Map Physical memory (bytes)=142544896
Peak Map Virtual memory (bytes)=2507415552
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=163
2021-12-14 17:20:24,979 INFO mapreduce.ImportJobBase: Transferred 163 bytes in 70,589 seconds (2,3091 bytes/sec)
2021-12-14 17:20:24,986 INFO mapreduce.ImportJobBase: Retrieved 7 records.
Vamos a repasar la salida del log para entender el proceso:
- En la línea 5 vemos cómo se lanza el generador de código.
- En las líneas 6, 7 y 15 vemos como ejecuta la consulta para obtener todos los metadatos de la tabla de profesores.
- En la línea 20 obtiene los valores mínimo y máximo para calcular cómo dividir los datos.
- De las líneas 29 a la 34 se ejecuta el proceso MapReduce, donde realmente recupera los datos.
- En el resto se puede observar un resumen estadístico.
Monitorizando Sqoop¶
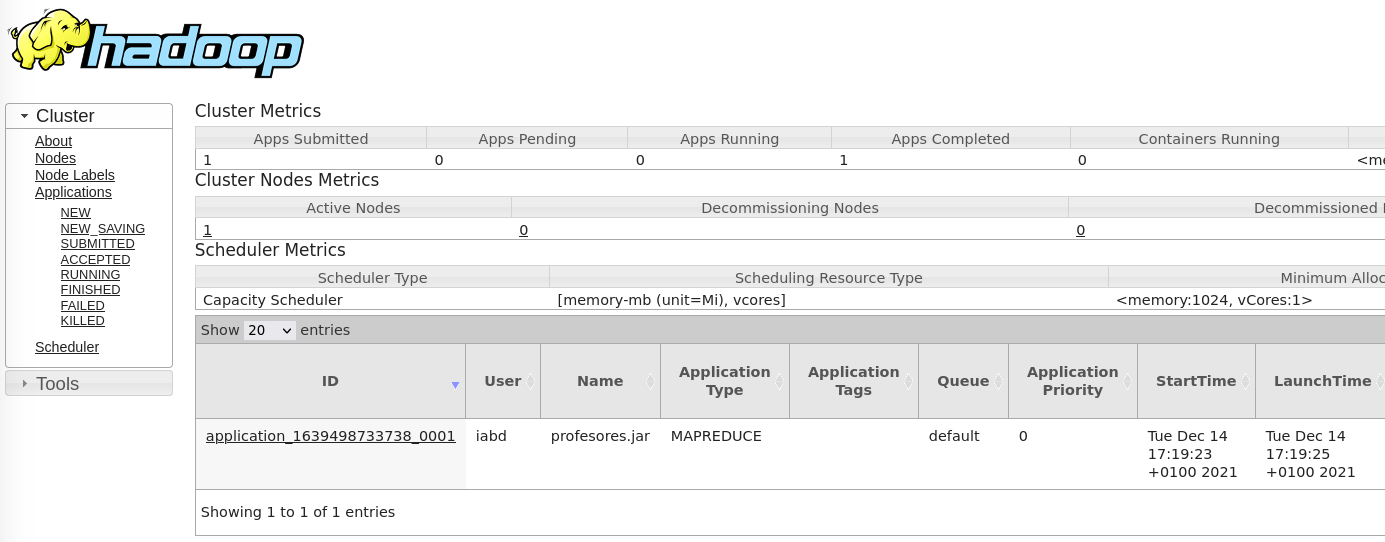
Si accedemos a la interfaz gráfica de YARN (en http://iabd-virtualbox:8088/cluster) podemos ver cómo aparece el proceso como realizado:
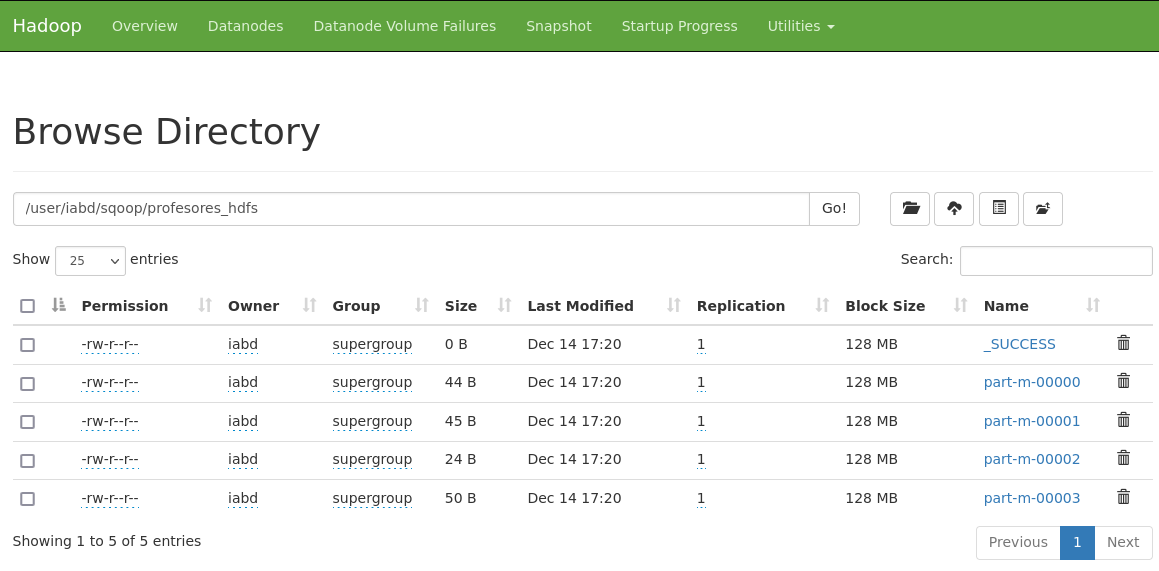
A su vez, si accedemos a la interfaz gráfica de Hadoop (recuerda que puedes acceder a él mediante http://iabd-virtualbox:9870) podremos comprobar en el directorio /user/iabd/sqoop que ha creado el directorio que hemos especificado junto con los siguientes archivos:
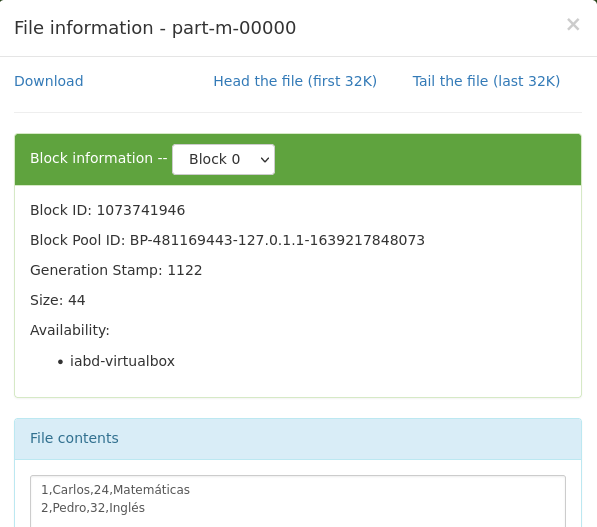
Si entramos a ver los datos, podemos visualizar el contenido del primer fragmento que contiene los primeros datos de la tabla:
Si queremos descargar el contenido de una carpeta de HDFS compuesta de varios archivos que contienen la información dividida, deberás emplear el parámetro -getmerge más la ruta de la carpeta a descargar. Por ejemplo, si queremos descargar los datos de los profesores y almacenarlos en nuestro sistema local como profesores.csv haríamos (cuidado que al fusionar los archivos su tamaño puede crecer de forma considerable):
hdfs dfs -getmerge /user/iabd/sqoop/profesores_hdfs profesores.csv
Importándolo todo
Si queremos importar todas las tablas de una base de datos, podemos emplear el comando sqoop import-all-tables, en el cual ya no indicamos la tabla a importar, sino la carpeta (warehouse-dir) donde creará una carpeta por cada tabla que encuentre en la base de datos:
sqoop import-all-tables --connect jdbc:mysql://localhost/mi_bd \
--username=iabd --password=iabd \
--driver=com.mysql.jdbc.Driver \
--warehouse-dir=/user/iabd/sqoop \
--fields-terminated-by=',' --lines-terminated-by '\n'
Caso 2 - Exportando datos a MariaDB¶
Tabla no existente
Si la tabla no existe previamente, recibiremos un error.
Ahora vamos a hacer el paso contrario, desde HDFS vamos a exportar los ficheros a otra tabla mediante el comando sqoop export. Así pues, primero vamos a crear la nueva tabla en una nueva base de datos (aunque podríamos haber reutilizado la base de datos):
create database sqoopCaso2;
use sqoopCaso2;
CREATE TABLE profesores2(
id MEDIUMINT NOT NULL AUTO_INCREMENT,
nombre CHAR(30) NOT NULL,
edad INTEGER(30),
materia CHAR(30),
PRIMARY KEY (id) );
Para exportar los datos de HDFS y cargarlos en esta nueva tabla lanzamos la siguiente orden:
sqoop export --connect jdbc:mysql://localhost/sqoopCaso2 \
--username=iabd --password=iabd \
--table=profesores2 --export-dir=/user/iabd/sqoop/profesores_hdfs
Si quisiéramos exportar los datos sobre la misma tabla del caso de uso anterior, nos daría error ya que tendríamos registros duplicados por la clave primaria. Para evitar el error, podemos indicarle una clave de actualización mediante --update-key, de manera que en el caso de que el registro ya existiese, modificara sus datos, realizando actualizaciones de datos en vez de inserciones. Si queremos que su comportamiento sea el de un upsert, le añadiremos la opción --update-mode allowinsert:
sqoop export --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --export-dir=/user/iabd/sqoop/profesores_hdfs \
--update-key id --update-mode allowinsert
Formatos Avro y Parquet¶
Sqoop permite trabajar con diferentes formatos, tanto Avro como Parquet.
Avro es un formato de almacenamiento basado en filas para Hadoop que se usa ampliamente como formato de serialización. Recuerda que Avro almacena la estructura en formato JSON y los datos en binario.
Parquet a su vez es un formato de almacenamiento binario basado en columnas que puede almacenar estructuras de datos anidados.
Avro y Hadoop
Para que funcione la serialización con Avro hay que copiar el fichero .jar que viene en el directorio de Sqoop para Avro como librería de Hadoop, mediante el siguiente comando:
cp $SQOOP_HOME/lib/avro-1.8.1.jar $HADOOP_HOME/share/hadoop/common/lib/
rm $HADOOP_HOME/share/hadoop/common/lib/avro-1.7.7.jar
En nuestra máquina virtual este paso ya está realizado.
Para importar los datos en formato Avro, añadiremos la opción --as-avrodatafile:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_avro --as-avrodatafile
Si en vez de Avro, queremos importar los datos en formato Parquet cambiamos el último parámetro por --as-parquetfile:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_parquet --as-parquetfile
Si queremos comprobar los archivos, podemos acceder via HDFS y la opción -ls:
hdfs dfs -ls /user/iabd/sqoop/profesores_avro
Obteniendo:
Found 5 items
-rw-r--r-- 1 iabd supergroup 0 2021-12-14 17:56 /user/iabd/sqoop/profesores_avro/_SUCCESS
-rw-r--r-- 1 iabd supergroup 568 2021-12-14 17:56 /user/iabd/sqoop/profesores_avro/part-m-00000.avro
-rw-r--r-- 1 iabd supergroup 569 2021-12-14 17:56 /user/iabd/sqoop/profesores_avro/part-m-00001.avro
-rw-r--r-- 1 iabd supergroup 547 2021-12-14 17:56 /user/iabd/sqoop/profesores_avro/part-m-00002.avro
-rw-r--r-- 1 iabd supergroup 574 2021-12-14 17:56 /user/iabd/sqoop/profesores_avro/part-m-00003.avro
Si queremos ver el contenido de una de las partes, utilizamos la opción -text:
hdfs dfs -text /user/iabd/sqoop/profesores_avro/part-m-00000.avro
Obteniendo el esquema y los datos en formato Avro:
{"id":{"int":1},"nombre":{"string":"Carlos"},"edad":{"int":24},"materia":{"string":"Matemáticas"}}
{"id":{"int":2},"nombre":{"string":"Pedro"},"edad":{"int":32},"materia":{"string":"Inglés"}}
Autoevaluación
¿Qué sucede si ejecutamos el comando hdfs dfs -tail /user/iabd/sqoop/profesores_avro/part-m-00000.avro? ¿Por qué aparece contenido en binario?
En el caso de ficheros Parquet, primero listamos los archivos generados:
hdfs dfs -ls /user/iabd/sqoop/profesores_parquet
Obteniendo:
Found 6 items
drwxr-xr-x - iabd supergroup 0 2021-12-15 16:13 /user/iabd/sqoop/profesores_parquet/.metadata
drwxr-xr-x - iabd supergroup 0 2021-12-15 16:14 /user/iabd/sqoop/profesores_parquet/.signals
-rw-r--r-- 1 iabd supergroup 1094 2021-12-15 16:14 /user/iabd/sqoop/profesores_parquet/12205ee4-6e63-4c0d-8e64-751882d60179.parquet
-rw-r--r-- 1 iabd supergroup 1114 2021-12-15 16:14 /user/iabd/sqoop/profesores_parquet/1e12aaad-98c6-4508-9c41-e1599e698385.parquet
-rw-r--r-- 1 iabd supergroup 1097 2021-12-15 16:14 /user/iabd/sqoop/profesores_parquet/6a803503-f3e0-4f2a-8546-a337f7f90e73.parquet
-rw-r--r-- 1 iabd supergroup 1073 2021-12-15 16:14 /user/iabd/sqoop/profesores_parquet/eda459b2-1da4-4790-b649-0f2f8b83ab06.parquet
Podemos usar las parquet-tools para ver su contenido. Si la instalamos mediante pip3 install parquet-tools podremos acceder a ficheros locales y almacenados en S3. Si queremos acceder de forma remota via HDFS, podemos descargar la versión Java y utilizarla mediante hadoop (aunque da problemas entre las versiones de Sqoop y Parquet):
hadoop jar parquet-tools-1.11.2.jar head -n5 hdfs://iabd-virtualbox:9000/user/iabd/sqoop/profesores_parquet/12205ee4-6e63-4c0d-8e64-751882d60179.parquet
Si queremos obtener información sobre los documentos, usaremos la opción meta:
hadoop jar parquet-tools-1.11.2.jar meta hdfs://iabd-virtualbox:9000/user/iabd/sqoop/profesores_parquet/12205ee4-6e63-4c0d-8e64-751882d60179.parquet
Más información sobre parquet-tools en https://pypi.org/project/parquet-tools/.
Trabajando con datos comprimidos¶
En un principio, vamos a trabajar siempre con los datos sin comprimir. Cuando tengamos datos que vamos a utilizar durante mucho tiempo (del orden de varios años) es cuando nos plantearemos comprimir los datos.
Por defecto, podemos comprimir mediante el formato gzip utilizando el parámetro --compress:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_gzip \
--compress
Si en cambio queremos comprimirlo con formato bzip2, hemos de añadir también el parámetro --compression-codec bzip2:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_bzip \
--compress --compression-codec bzip2
En la sesión sobre Formatos de datos en Big Data, estudiamos que Snappy es una biblioteca de compresión y descompresión de datos de gran rendimiento que se utiliza con frecuencia en proyectos Big Data. Así pues, para utilizarlo lo indicaremos mediante el codec snappy:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_snappy \
--compress --compression-codec snappy
Importando con filtros¶
Además de poder importar todos los datos de una tabla, podemos filtrar los datos. Por ejemplo, podemos indicar mediante la opción --where el filtro a ejecutar en la consulta:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_materia_info \
--where "materia='Informática'"
También podemos restringir las columnas que queremos recuperar mediante la opción --columns:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_cols \
--columns "nombre,materia"
Finalmente, podemos especificar una consulta con clave de particionado (en este caso, ya no indicamos el nombre de la tabla):
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_query \
--query "select * from profesores where edad > 40 AND \$CONDITIONS" \
--split-by "id"
En la consulta, hemos de añadir el token \$CONDITIONS, el cual Sqoop sustituirá por la columna por la que los mappers realizan el particionado.
Importación incremental¶
Si utilizamos procesos batch, es muy común realizar importaciones incrementales tras una carga de datos. Para ello, utilizaremos las opciones --incremental append junto con la columna a comprobar mediante --check-column y el último registro cargado mediante --last-value:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--target-dir=/user/iabd/sqoop/profesores_inc \
--incremental append \
--check-column id \
--last-value 4
Después de ejecutarlo, si vemos la información que nos devuelve, en las últimas líneas, podemos copiar los parámetros que tenemos que utilizar para posteriores importaciones.
...
2021-12-15 19:10:59,348 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
2021-12-15 19:10:59,348 INFO tool.ImportTool: --incremental append
2021-12-15 19:10:59,348 INFO tool.ImportTool: --check-column id
2021-12-15 19:10:59,348 INFO tool.ImportTool: --last-value 7
2021-12-15 19:10:59,349 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
Trabajando con Hive¶
Podemos importar los datos en HDFS para que luego puedan ser consultables desde Hive. Para ello hemos de utilizar el parámetro --hive-import e indicar el nombre de la base de datos mediante --hive-database así como la opción de --create-hive-table para que cree la tabla gestionada por Hive indicada en el parámetro hive-table.
Es importante destacar que ya no ponemos destino con target-dir:
sqoop import --connect jdbc:mysql://localhost/sqoopCaso1 \
--username=iabd --password=iabd \
--table=profesores --driver=com.mysql.jdbc.Driver \
--hive-import --hive-database default \
--create-hive-table --hive-table profesores_mariadb
Para comprobar el resultado, dentro de Hive ejecutaremos el comando:
describe formatted profesores_mariadb
Para exportar los datos, de forma similar haremos:
sqoop export --connect jdbc:mysql://localhost/sqoopCaso2 \
--username=iabd --password=iabd \
--table=profesores2 --driver=com.mysql.jdbc.Driver \
--h-catalog-table profesores_mariadb
Referencias¶
- Página oficial de Sqoop
- Sqoop User Guide
- Sqoop Tutorial en Tutorialspoint
- Apache Sqoop Cookbook, de Kathleen Ting, Jarek Jarcec Cecho
Actividades¶
Preparación MariaDB
Para estas actividades y futuras sesiones, vamos a utilizar la base de datos (retail_db) que contiene información sobre un comercio (clientes, productos, pedidos, etc...).
Para ello, descargaremos el archivo create_db.sql con las sentencias para crear la base de datos y los datos como instrucciones SQL.
Tras ello, si nos conectamos a MariaDB (mariadb -u iabd -p) desde la misma carpeta que hemos descargado el archivo, ejecutaremos los siguientes comando:
create database retail_db;
use retail_db;
source create_db.sql;
show tables;
En nuestra máquina virtual este paso ya está realizado.
-
(RASBD.3 / CESBD.3a y CESBD.3b / 2p) Haciendo uso de Sqoop y la base de datos retail_db, importa:
-
Todos los pedidos de la tabla
orderscuyo campoorder_statusseaCOMPLETE.Coloca los datos en
/user/iabd/sqoop/orders/datos_parqueten formato Parquet, utilizando el tabulador como delimitador de campos y la compresión Snappy. Deberás recuperar 22.899 registros. -
Mediante una importación incremental a partir del registro 100, recupera los clientes de la tabla
customerscuyo campostateseaCA.Coloca los datos en
/user/iabd/sqoop/customers/datos_avroen formato Avro, utilizando la compresión bzip2. Deberás recuperar las columnascustomer_id, customer_fname, customer_lname, customer_state. El resultado contendrá menos de 2012 registros.
Se pide entregar el comando empleado y una captura de la carpeta de HDFS, ya sea mediante el interfaz gráfico o por consola.
-