Hive II
Estructuras de datos en Hive¶
Hive organiza los datos almacenados en HDFS en tres niveles jerárquicos: tablas, particiones y buckets. Las tablas se corresponden con directorios de HDFS, las particiones son las divisiones de las tablas y los buckets son las divisiones de las particiones.
Acabamos de ver en el apartado anterior que Hive permite crear tablas externas, similares a las tablas en una base de datos, pero a la que se les proporciona una ubicación.
Particiones¶
Las particiones en Hive consisten en dividir las tablas en varios subdirectorios. Esta estructura permite aumentar el rendimiento cuando utilizamos consultas que filtran los datos mediante la cláusula where basada en la clave de particionado.
Por ejemplo, si estamos almacenado ficheros de log (tanto la línea del log como su timestamp), podemos pensar en agrupar por fecha los diferentes ficheros. Podríamos añadir otra partición para también dividirlos por países:
CREATE TABLE logs (ts BIGINT, linea STRING)
PARTITIONED BY (fecha STRING, pais STRING);
Por ejemplo, para cargar los datos en una partición:
LOAD DATA LOCAL INPATH 'input/hive/particiones/log1'
INTO TABLE logs
PARTITION (fecha='2022-01-01', pais='ES');
A nivel del sistema de fichero, las particiones se traducen en subdirectorios dentro de la carpeta de la tabla. Por ejemplo, tras insertar varios ficheros de logs, podríamos tener una estructura similar a:
/user/hive/warehouse/logs
├── fecha=2022-01-01/
│ ├── pais=ES/
│ │ ├── log1
│ │ └── log2
│ └── pais=US/
│ └── log3
└── fecha=2022-01-02/
├── pais=ES/
│ └── log4
└── pais=US/
├── log5
└── log6
Para averiguar las particiones en Hive, utilizaremos el comando SHOW PARTITIONS:
hive> SHOW PARTITIONS logs;
fecha=2022-01-01/pais=ES
fecha=2022-01-01/pais=US
fecha=2022-01-02/pais=ES
fecha=2022-01-02/pais=US
Hay que tener en cuenta que la definición de columnas de la clausula PARTITIONED BY forman parte de las columnas de la tabla, y se conocen como columnas de partición. Sin embargo, los ficheros de datos no contienen valores para esas columnas, ya que se deriva el nombre del subdirectorio.
Podemos utilizar las columnas de partición en las consultas igual que una columna ordinaria. Hive traduce la consulta en la navegación adecuada para sólo escanear las particiones relevantes. Por ejemplo, la siguiente consulta solo escaneará los ficheros log1, log2 y log4:
SELECT ts, fecha, linea
FROM logs
WHERE pais='ES';
Moviendo datos a una tabla particionada
Si queremos mover datos de una tabla ordinaria a una particionada (vaciando los datos de la partición existente):
INSERT OVERWRITE TABLE logs
PARTITION (fecha='2022-01-01')
SELECT col1, col2 FROM fuente;
Otra posibilidad es utilizar un particionado dinámico, de manera que las particiones se crean de forma relativa a los datos:
INSERT OVERWRITE TABLE logs
PARTITION (fecha)
SELECT fecha, col1, col2 FROM fuente;
Para ello, previamente hay que habilitarlo (por defecto está desactivado para evitar la creación de múltiples particiones sin querer) y configurar el modo no estricto para que no nos obligue a indicar al menos una partición estática:
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
Buckets¶
Otro concepto importante en Hive son los buckets. Son subdivisiones dentro de una partición en las que los datos se distribuyen en función del valor hash de una columna.
Mientras que las particiones son una división lógica y visible en el sistema de archivos, los buckets son una división física de datos en archivos basada en una función hash.
Existen dos razones por las cuales queramos organizar las tablas (o particiones) en buckets. La primera es para conseguir consultas más eficientes, ya que imponen una estructura extra en las tablas. Los buckets pueden acelerar las operaciones de tipo join si las claves de bucketing y de join coinciden, ya que una clave ajena busca únicamente en el bucket adecuado de la clave primaria. Debido a los beneficios de los buckets/particiones, se deben considerar siempre que puedan optimizar el rendimiento de las consultas realizadas.
Para indicar que nuestras tablas utilicen buckets, hemos de emplear la clausula CLUSTERED BY para indicar la columnas y el número de buckets (se recomienda que la cantidad de buckets sea potencia de 2, y aunque el número de buckets no tiene por qué coincidir entre tablas para hacer un join, sí es recomendable que sean múltiplos o divisores entre sí para aprovechar el map join entre buckets):
CREATE TABLE usuarios_bucketed (id INT, nombre STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
Bucketing está muy relacionado con el proceso de carga de datos. Para cargar los datos en una tabla con buckets, debemos bien indicar el número máximo de reducers para que coincida con el número de buckets, o habilitar el bucketing (esta es la opción más recomendada para evitar problemas de configuración):
set map.reduce.tasks = 4;
set hive.enforce.bucketing = true; -- mejor así
Una vez creada la tabla, se rellena con los datos que tenemos en otra tabla:
INSERT OVERWRITE TABLE usuarios_bucketed
SELECT * FROM usuarios;
Físicamente, cada bucket es un fichero de la carpeta con la tabla (o partición). El nombre del fichero no es importante, pero el bucket n es el fichero número n. Por ejemplo, si miramos el contenido de la tabla en HDFS tendremos:
hive> dfs -ls /user/hive/warehouse/usuarios_bucketed;
000000_0
000001_0
000002_0
000003_0
El segundo motivo es para obtener un sampling de forma más eficiente. Al trabajar con grandes datasets, normalmente obtenemos una pequeña fracción del dataset para comprender o refinar los datos. Por ejemplo, podemos obtener los datos de únicamente uno de los buckets:
SELECT * FROM usuarios_bucketed
TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
Mediante el id del usuario determinamos el bucket (el cual se utiliza para realizar el hash del valor y ubicarlo dentro de uno de los buckets), de manera que cada bucket contendrá de manera eficiente un conjunto aleatorio de usuarios.
Resumen¶
A continuación mostramos en una tabla puntos a favor y en contra de utilizar estas estructuras
| Particionado + | Particionado - | Bucketing + | Bucketing - |
|---|---|---|---|
| Distribuye la carga de ejecución horizontalmente. | Existe la posibilidad de crear demasiadas particiones que contienen muy poco datos | Proporciona una respuesta de consulta más rápida, al acceder a porciones. | El número de buckets se define durante la creación de la tabla -> Los programadores deben cargar manualmente un volumen equilibrado de datos. |
| En la partición tiene lugar la ejecución más rápida de consultas con el volumen de datos bajo. Por ejemplo, la población de búsqueda de la Ciudad del Vaticano devuelve muy rápido en lugar de buscar la población mundial completa. | La partición es eficaz para datos de bajo volumen. Pero algunas consultas como agrupar por un gran volumen de datos tardan mucho en ejecutarse. Por ejemplo, agrupar las consultas del mes de Enero tardará más que los viernes de Enero. | Al utilizar volúmenes similares de datos en cada partición, los map joins serán más rápidos. | Dificultad para cambiar el número de buckets una vez creada la tabla |
Supongamos que $HDFS_HIVE contiene la ruta con la raíz de las tablas internas de Hive, en nuestro caso /user/hive/warehouse. Respecto al nivel de estructura y representación en carpetas de HDFS tendríamos:
| ENTIDAD | EJEMPLO | UBICACIÓN |
|---|---|---|
| base de datos | iabd | $HDFS_HIVE/iabd.db |
| tabla | T | $HDFS_HIVE/iabd.db/T |
| partición | fecha='01012022' | $HDFS_HIVE/iabd.db/T/fecha=01012022 |
| bucket | columna id | $HDFS_HIVE/iabd.db/T/fecha=01012022/000000_0 |
Caso 6: Particionado y Bucketing¶
A continuación, vamos a coger los datos de las productos y las categorías de la base de datos retail_db, y colocarlos en una estructura de Hive particionada y que utilice bucketing.
La estructura de las tablas es la siguiente:
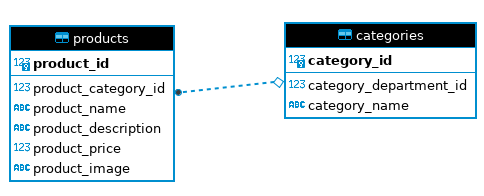
El primer paso es traernos los datos de MariaDB a tablas internas haciendo uso de Sqoop:
sqoop import --connect jdbc:mysql://localhost/retail_db \
--username=iabd --password=iabd \
--table=categories --driver=com.mysql.jdbc.Driver \
--hive-import --hive-database iabd \
--create-hive-table --hive-table categories
sqoop import --connect jdbc:mysql://localhost/retail_db \
--username=iabd --password=iabd \
--table=products --driver=com.mysql.jdbc.Driver \
--hive-import --hive-database iabd \
--create-hive-table --hive-table products
El siguiente paso que vamos a realizar es crear en Hive una tabla con el código del producto, su nombre, el nombre de la categoría y el precio del producto. Estos datos los vamos a particionar por categoría y clusterizado en 8 buckets:
CREATE TABLE IF NOT EXISTS productos (
id INT,
nombre STRING,
precio DOUBLE
)
PARTITIONED BY (categoria STRING)
CLUSTERED BY (id) INTO 8 BUCKETS;
Y cargamos los datos con una consulta que realice un join de las tablas categories y products con particionado dinámico (recuerda activarlo mediante set hive.exec.dynamic.partition.mode=nonstrict;), teniendo en cuenta que los datos que forman parte de la partición deben ser las últimas columnas de la consulta:
INSERT OVERWRITE TABLE productos
PARTITION (categoria)
SELECT p.product_id as id, p.product_name as nombre, p.product_price as precio, c.category_name as categoria FROM products p join categories c on (p.product_category_id = c.category_id);
Si queremos comprobar cómo se han creado las particiones y los buckets, desde un terminal podemos acceder a HDFS y observar cómo ha creado una carpeta por cada valor del campo categoria:
$ hdfs dfs -ls hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos
Found 52 items
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=As Seen on TV!
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Baseball & Softball
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Basketball
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Bike & Skate Shop
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Boating
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Boxing & MMA
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Boys%27 Apparel
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Camping & Hiking
drwxr-xr-x - iabd supergroup 0 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Cardio Equipment
...
Y si entramos a una categoría concreta, sus 8 buckets:
$ hdfs dfs -ls hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories
Found 8 items
-rw-r--r-- 1 iabd supergroup 391 2024-01-23 12:06 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000000_0
-rw-r--r-- 1 iabd supergroup 464 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000001_0
-rw-r--r-- 1 iabd supergroup 468 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000002_0
-rw-r--r-- 1 iabd supergroup 455 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000003_0
-rw-r--r-- 1 iabd supergroup 435 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000004_0
-rw-r--r-- 1 iabd supergroup 453 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000005_0
-rw-r--r-- 1 iabd supergroup 456 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000006_0
-rw-r--r-- 1 iabd supergroup 469 2024-01-23 12:07 hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000007_0
Y si ya entramos a un bucket concreto:
$ hdfs dfs -head hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db/productos/categoria=Accessories/000000_0
480Nike+ Fuelband SE99.0
488SOLE E25 Elliptical999.99
496SOLE F85 Treadmill1799.99
576Lotto Men's Zhero Gravity V 700 TF Soccer Cle59.99
584adidas Men's 2014 MLS All-Star Game Replica B85.0
592adidas Youth Germany Black Crest Tee18.0
888Team Golf Detroit Tigers Putter Grip24.99
896Team Golf New York Giants Putter Grip24.99
904Team Golf Wisconsin Badgers Putter Grip24.99
Si volvemos a Beeline, ahora podemos consultar los datos:
SELECT * FROM productos LIMIT 5;
Y vemos cómo aparecen 5 elementos que pertenecen a la primera partición.
+---------------+------------------------------------------------+-------------------+----------------------+
| productos.id | productos.nombre | productos.precio | productos.categoria |
+---------------+------------------------------------------------+-------------------+----------------------+
| 480 | Nike+ Fuelband SE | 99.0 | Accessories |
| 488 | SOLE E25 Elliptical | 999.99 | Accessories |
| 496 | SOLE F85 Treadmill | 1799.99 | Accessories |
| 576 | Lotto Men's Zhero Gravity V 700 TF Soccer Cle | 59.99 | Accessories |
| 584 | adidas Men's 2014 MLS All-Star Game Replica B | 85.0 | Accessories |
+---------------+------------------------------------------------+-------------------+----------------------+
Si quisiéramos, por ejemplo, 10 elementos de particiones diferentes deberíamos ordenarlos de manera aleatoria:
SELECT * FROM productos ORDER BY rand() LIMIT 10;
Y ya obtendríamos datos de diferentes particiones, eso sí, con una operación más costosa computacionalmente al tener que acceder a todas las particiones y buckets:
+---------------+------------------------------------------------+-------------------+----------------------+
| productos.id | productos.nombre | productos.precio | productos.categoria |
+---------------+------------------------------------------------+-------------------+----------------------+
| 1330 | Nike Men's Home Game Jersey Denver Broncos Pe | 100.0 | Fútbol |
| 29 | Nike Men's USA Away Stadium Replica Soccer Je | 90.0 | Baseball & Softball |
| 75 | Nike Women's Pro Core 3" Compression Shorts | 28.0 | Lacrosse |
| 827 | Bridgestone e6 Straight Distance NFL Seattle | 31.99 | Electronics |
| 9 | Nike Adult Vapor Jet 3.0 Receiver Gloves | 50.0 | Soccer |
| 976 | Columbia Women's Sandy River Shorts | 21.99 | Hunting & Shooting |
| 841 | SkyCaddie LINX Golf GPS Watch | 249.99 | Kids' Golf Clubs |
| 307 | Garmin Forerunner 910XT with HRM | 449.99 | Kids' Golf Clubs |
| 213 | Exerpeutic 900XL Magnetic Recumbent Bike with | 199.99 | Strength Training |
| 1071 | Pelican Apex 100 Kayak | 229.99 | Water Sports |
+---------------+------------------------------------------------+-------------------+----------------------+
Vistas¶
Además de las estructuras físicas para almacenar los datos, podemos crear estructuras lógicas como las vistas.
De la misma forma que en los sistemas de bases de datos tradicionales, mediante una vista podemos abstraer una consulta compleja que realiza diversos joins.
Por ejemplo, si queremos volver a crear la tabla de productos pero mediante una vista que siempre muestre los datos actualizados haríamos:
CREATE VIEW IF NOT EXISTS productos_view AS
SELECT p.product_id as id, p.product_name as nombre, p.product_price as precio, c.category_name as categoria FROM products p JOIN categories c ON (p.product_category_id = c.category_id);
Tras crear la vista, podemos consultar directamente los datos:
SELECT * FROM productos_view LIMIT 5;
Para consultar las vistas existentes, el metastore la almacena como una tabla de tipo VIRTUAL_VIEW, y por tanto, si hacemos un show tables también aparecerá, aunque si solo estamos interesados en las vistas podemos obtenerlas mediante:
SHOW VIEWS;
Se queremos eliminar la vista, de forma similar a SQL, realizaríamos:
DROP VIEW productos_view;
Vistas materializadas¶
Un tipo especial de vistas son las vistas materializadas, entendidas como una tabla de datos duplicada que se crea mediante la combinación de datos de varias tablas existentes para una recuperación de datos más rápida.
Este tipo de vistas no son exclusivas de Hive, ya que sistemas relacionales como PostreSQL u Oracle las soportan.
Con una vista ordinaria, al realizar una consulta, el motor de base de datos calcula dinámicamente los resultados ejecutando la consulta subyacente en las tablas de origen. Los datos de la vista están siempre actualizados porque se derivan directamente de las tablas de origen cada vez que se accede a ellos.
En cambio, con una vista materializada, los resultados de la consulta específica se almacenan como una tabla física en la base de datos. Los datos de la vista materializada se calculan con anterioridad y se almacenan, lo que significa que los resultados ya están disponibles sin necesidad de volver a calcular la consulta cada vez que se accede a la vista.
Desde la versión 3.0 de Apache Hive, se introducen las vistas materializadas y rescritura automática de consultas basadas en dichas materializaciones. A nivel de restricción, Hive requiere que las tablas subyacentes estén en formato ORC y sean transaccionales para que funcionen correctamente. Además, las vistas materializadas no pueden contener funciones de agregación, funciones de ventana, subconsultas o cláusulas GROUP BY o DISTINCT.
Dicho esto, para crear la vista materializada, debemos indicarla con la keyword MATERIALIZED. Por ejemplo:
CREATE MATERIALIZED VIEW productos_viewm AS
SELECT p.product_id as id, p.product_name as nombre, p.product_price as precio, c.category_name as categoria FROM products p join categories c on (p.product_category_id = c.category_id);
Esta vista ya no ha tardado menos de un segundo, sino cerca de 50 al persistir los datos en una tabla temporal. Si realizamos la siguiente consulta sobre la vista ordinaria y la vista materializada vemos que el rendimiento cambia:
SELECT sum(precio) FROM productos_view WHERE categoria = "Bike & Skate Shop" or categoria = "Basketball";
-- Resultado: 6888.6099 - Tiempo empleado: 45.148 segundos
SELECT sum(precio) FROM productos_viewm WHERE categoria = "Bike & Skate Shop" or categoria = "Basketball";
-- Resultado: 6888.6099 - Tiempo empleado: 34.929 segundos
Si hacemos una consulta más sencilla, las diferencias son todavía mucho más grandes:
select count(*) from productos_view;
-- Resultado: 1345 - Tiempo empleado: 43.529 segundos
select count(*) from productos_viewm;
-- Resultado: 1345 - Tiempo empleado: 0.467 segundos
Si insertamos un nuevo producto en la categoría 4 (Basketball):
INSERT INTO products VALUES ('66666', 4 , "Producto IABD", "Producto insertado para comprobar si cambian los datos", 3333, null);
Y volvemos a realizar las consultas agregadas, donde observamos que sólo la vista ordinaria está reflejando los cambios provocados por el nuevo producto recién insertado:
SELECT sum(precio) FROM productos_view WHERE categoria = "Bike & Skate Shop" or categoria = "Basketball";
-- Resultado: 10221.6099 - Tiempo empleado: 37,534 segundos
SELECT sum(precio) FROM productos_viewm WHERE categoria = "Bike & Skate Shop" or categoria = "Basketball";
-- Resultado: 6888.6099 - Tiempo empleado: 29,728 segundos
Por defecto, las vistas materializadas se deben actualizar cuando cambian los datos de origen. Hive no soporte la actualización automática, pero sí que nos permite forzar la regeneración de la vista materializada mediante la opción REBUILD:
ALTER MATERIALIZED VIEW productos_viewm REBUILD;
Una vez reconstruida la vista, si volvemos a ejecutar la consulta sobre la vista materializada, sí que veremos los datos actualizados.
Regeneración automática
Otra opción es automatizar la regeneración para que se realice periódicamente, por ejemplo, cada 10 minutos, independientemente de si los datos de origen han cambiado:
SET hive.materializedview.rewriting.time.window=10min;
Más información en https://hive.apache.org/docs/latest/language/materialized-views/
Caso 7: De Flume a Hive pasando por HDFS¶
En este caso de uso, vamos a crear un agente Flume que realice un spooling de una carpeta (por ejemplo, podría estar mapeada con una carpeta enlazada a un servidor FTP) donde se van a colocar datos de clientes, y los vamos a insertar en la tabla customersraw mediante un HDFS Sink. A continuación, crearemos una vista materializada con los datos que nos interesan.
Cargamos los datos¶
Así pues, el primer paso es crear el agente Flume, y colocarlo en la carpeta conf de Flume:
# Nombramos a los componentes del agente
SpoolHdfsAgent.sources = Spooldir
SpoolHdfsAgent.channels = MemChannel
SpoolHdfsAgent.sinks = HDFS
# Describimos el tipo de origen
SpoolHdfsAgent.sources.Spooldir.type = spooldir
SpoolHdfsAgent.sources.Spooldir.spoolDir = /home/iabd/hive/spoolDir
# Describimos el destino
SpoolHdfsAgent.sinks.HDFS.type = hdfs
SpoolHdfsAgent.sinks.HDFS.hdfs.path = hdfs://iabd-virtualbox:9000/user/iabd/flume/caso7
SpoolHdfsAgent.sinks.HDFS.hdfs.filePrefix = hive-caso7
SpoolHdfsAgent.sinks.HDFS.hdfs.rollInterval = 0
SpoolHdfsAgent.sinks.HDFS.hdfs.rollCount = 10000
SpoolHdfsAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describimos la configuración del canal
SpoolHdfsAgent.channels.MemChannel.type = memory
SpoolHdfsAgent.channels.MemChannel.capacity = 100000
SpoolHdfsAgent.channels.MemChannel.transactionCapacity = 10000
# Unimos el origen y el destino a través del canal
SpoolHdfsAgent.sources.Spooldir.channels = MemChannel
SpoolHdfsAgent.sinks.HDFS.channel = MemChannel
Antes de ejecutarlo, vamos a crear la carpeta en HDFS:
hdfs dfs -mkdir -r /user/iabd/flume/caso7
Y a continuación, ejecutamos el agente desde $FLUME_HOME:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/spool-hdfs.conf --name SpoolHdfsAgent
Tras copiar el archivo clientes.csv en /home/iabd/hive/spoolDir, se renombrará y se realizará la ingesta en HDFS.
Si comprobamos la carpeta, vemos que se han creado múltiples archivos:
$ hdfs dfs -ls flume/caso7
Found 309 items
-rw-r--r-- 1 iabd supergroup 1074 2024-01-22 13:04 flume/caso7/hive-caso7.1705925066214
-rw-r--r-- 1 iabd supergroup 1068 2024-01-22 13:04 flume/caso7/hive-caso7.1705925066215
-rw-r--r-- 1 iabd supergroup 1089 2024-01-22 13:04 flume/caso7/hive-caso7.1705925066216
-rw-r--r-- 1 iabd supergroup 1075 2024-01-22 13:04 flume/caso7/hive-caso7.1705925066217
-rw-r--r-- 1 iabd supergroup 1082 2024-01-22 13:04 flume/caso7/hive-caso7.1705925066218
...
Y si visualizamos uno de ellos, tenemos los datos de los clientes:
$ hdfs dfs -head flume/caso7/hive-caso7.1705925066214
1,Richard,Hernandez,Brownsville
2,Mary,Barrett,Littleton
3,Ann,Smith,Caguas
4,Mary,Jones,San Marcos
5,Robert,Hudson,Caguas
6,Mary,Smith,Passaic
...
Creamos la tabla externa¶
Cuando ya tenemos los datos en HDFS, crearemos en Hive una tabla externa en formato texto y que utiliza las comas como separadores de campo (formato CSV) que apunte a dichos datos:
CREATE EXTERNAL TABLE clientes7
(
custId INT,
fName STRING,
lName STRING,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/iabd/flume/caso7';
Una vez creada, ya podemos realizar consultas sobre los datos. Por ejemplo, si ejecutamos:
select * from clientes7 limit 5;
Obtendremos:
+-------------------+------------------+------------------+-----------------+
| clientes7.custid | clientes7.fname | clientes7.lname | clientes7.city |
+-------------------+------------------+------------------+-----------------+
| 1 | Richard | Hernandez | Brownsville |
| 2 | Mary | Barrett | Littleton |
| 3 | Ann | Smith | Caguas |
| 4 | Mary | Jones | San Marcos |
| 5 | Robert | Hudson | Caguas |
+-------------------+------------------+------------------+-----------------+
Caso 8: De Flume a Hive directamente¶
Caso de uso no funcional
Aunque en teoría está todo bien, no termina de funcionarme. Puedes leerlo para entender qué es lo que habría que hacer, pero me parece que el problema proviene de la configuración de mi máquina virtual.
22 ene 2024 13:39:44,464 WARN [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hive.HiveSink.drainOneBatch:325)
- Hive : Failed connecting to EndPoint {metaStoreUri='thrift://iabd-virtualbox:9083', database='iabd', table='customerstx', partitionVals=[] }
org.apache.flume.sink.hive.HiveWriter$ConnectException: Failed connecting to EndPoint
{metaStoreUri='thrift://iabd-virtualbox:9083', database='iabd', table='customerstx', partitionVals=[] }
La IA me dice que probablemente el Hive Sink de Flume requiere Hive en modo streaming (ACID + ORC + Metastore remoto activo), algo difícil de configurar en un entorno local mediante una máquina virtual.
Si consigues que te funcione siempre puedes mandarme un email a.medrano@edu.gva.es y comentarme qué has hecho o qué debo modificar. ¡Gracias!
Para el último caso de uso, vamos a crear un agente Flume que realice un spooling de una carpeta y los vamos a insertar directamente en la tabla customerstx (en formato ORC mediante 4 buckets y configurada como transaccional) creada en el caso 2 mediante un Hive Sink.
Antes de nada, vamos a comprobar cuantos datos tenemos en la tabla:
SELECT count(*) FROM customerstx;
--- Resultado 12435
SELECT * FROM customerstx ORDER BY custId DESC LIMIT 3;
--- Resultado:
--- +---------------------+--------------------+--------------------+-------------------+
--- | customerstx.custid | customerstx.fname | customerstx.lname | customerstx.city |
--- +---------------------+--------------------+--------------------+-------------------+
--- | 12435 | Laura | Horton | Summerville |
--- | 12434 | Mary | Mills | Caguas |
--- | 12433 | Benjamin | Garcia | Levittown |
--- +---------------------+--------------------+--------------------+-------------------+
Metastore
Para poder acceder a Hive desde Flume, necesitamos que la configuración del Metastore de Hive permita las conexiones remotas y la creación dinámica de las particiones.
Para ello, debemos editar el archivo de configuración de Hive y buscar estas propiedades y modificarlas:
<property>
<name>hive.metastore.uris</name>
<value>thrift://iabd-virtualbox:9083</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
Una vez configurado, volvemos a arrancar Hive mediante hiveserver2 y a continuación, cada vez que arranquemos Hive, necesitamos también arrancar el Metastore, ya que ahora funciona como un servicio totalmente desacoplado:
hive --service metastore
Creando el agente¶
El siguiente paso es crear el agente Flume y colocarlo en la carpeta conf de Flume. Destacar que debemos indicar la ruta remota del Metastore así como que los campos están delimitados y los nombres de sus campos:
# Nombramos a los componentes del agente
SpoolHiveAgent.sources = Spooldir
SpoolHiveAgent.channels = MemChannel
SpoolHiveAgent.sinks = Hive
# Describimos el tipo de origen
SpoolHiveAgent.sources.Spooldir.type = spooldir
SpoolHiveAgent.sources.Spooldir.spoolDir = /home/iabd/hive/spoolDir
# Describimos el destino
SpoolHiveAgent.sinks.Hive.type = hive
SpoolHiveAgent.sinks.Hive.hive.metastore = thrift://iabd-virtualbox:9083
SpoolHiveAgent.sinks.Hive.hive.database = iabd
SpoolHiveAgent.sinks.Hive.hive.table = customerstx
SpoolHiveAgent.sinks.Hive.hive.serializer = DELIMITED
SpoolHiveAgent.sinks.Hive.hive.serializer.fieldnames = custid,fname,lname,city
# Describimos la configuración del canal
SpoolHiveAgent.channels.MemChannel.type = memory
SpoolHiveAgent.channels.MemChannel.capacity = 1000
SpoolHiveAgent.channels.MemChannel.transactionCapacity = 100
# Unimos el origen y el destino a través del canal
SpoolHiveAgent.sources.Spooldir.channels = MemChannel
SpoolHiveAgent.sinks.Hive.channel = MemChannel
Probando el agente¶
Primero, arrancaremos el agente desde $FLUME_HOME:
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/spool-hive.conf --name SpoolHiveAgent
Y a continuación, vamos a la carpeta /home/iabd/hive/spoolDir (si no existe, la creamos) y colocamos el siguiente archivo en la carpeta:
6666, Aitor, Medrano, Elche
7777, Domingo, Gallardo, Alicante
8888, Fátima, Polo, Madrid
Si volvemos a ejecutar las consultas vemos como ahora ....
SELECT count(*) FROM customerstx;
--- Deberían aparecer 12438
SELECT * FROM customerstx ORDER BY custId DESC LIMIT 3;
--- Resultado: Deberían aparecer los clientes recibidos desde Flume
Funciones ventana¶
A continuación vamos a realizar diversas consultas utilizando las funciones ventana que soporta Hive. Más información en https://hive.apache.org/docs/latest/language/languagemanual-windowingandanalytics/.
Consultas con enteros que cuentan/ordenan¶
Consultas sobre categorías
Las siguientes consultas las vamos a realizar sobre sólo dos categorías para acotar los resultados obtenidos.
Además, hemos recortado el nombre del producto a 20 caracteres para facilitar la legibilidad de los resultados.
Las funciones rank y dense_rank permite obtener la posición que ocupan los datos. Se diferencia en que rank cuenta los elementos repetidos/empatados, mientras que dense_rank no.
Por ejemplo, vamos a obtener la posición que ocupan los productos respecto al precio agrupados por su categoría:
select substr(nombre, 1, 20) as nombre, categoria, precio,
rank() over (partition by categoria order by precio desc) as rank,
dense_rank() over (partition by categoria order by precio desc) as denseRank
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
En el caso de que tengamos más de un elemento con el mismo valor, tanto en rank como con dense_rank, todos los elementos ocuparán la misma posición.
Resultado:
+-----------------------+--------------------+----------+-------+------------+
| nombre | categoria | precio | rank | denserank |
+-----------------------+--------------------+----------+-------+------------+
| SOLE F85 Treadmill | Basketball | 1799.99 | 1 | 1 |
| SOLE E25 Elliptical | Basketball | 999.99 | 2 | 2 |
| Diamondback Adult Re | Basketball | 349.98 | 3 | 3 |
| Diamondback Adult Ou | Basketball | 309.99 | 4 | 4 |
| Diamondback Girls' C | Basketball | 299.99 | 5 | 5 |
| Diamondback Boys' In | Basketball | 299.99 | 5 | 5 |
| Diamondback Adult So | Basketball | 299.98 | 7 | 6 |
| Easton Mako Youth Ba | Basketball | 249.97 | 8 | 7 |
| Fitness Gear 300 lb | Basketball | 209.99 | 9 | 8 |
| Quik Shade Summit SX | Basketball | 199.99 | 10 | 9 |
| Easton XL1 Youth Bat | Basketball | 179.97 | 11 | 10 |
| Easton S1 Youth Bat | Basketball | 179.97 | 11 | 10 |
| adidas Brazuca 2014 | Basketball | 159.99 | 13 | 11 |
| Quest 12' x 12' Dome | Basketball | 149.99 | 14 | 12 |
| Fitbit Flex Wireless | Basketball | 99.95 | 15 | 13 |
| Nike+ Fuelband SE | Basketball | 99.0 | 16 | 14 |
| Elevation Training M | Basketball | 79.99 | 17 | 15 |
| MAC Sports Collapsib | Basketball | 69.99 | 18 | 16 |
| Quest Q64 10 FT. x 1 | Basketball | 59.98 | 19 | 17 |
| adidas Brazuca 2014 | Basketball | 39.99 | 20 | 18 |
| Kijaro Dual Lock Cha | Basketball | 29.99 | 21 | 19 |
| adidas Brazuca 2014 | Basketball | 29.99 | 21 | 19 |
| Nike Women's Pro Cor | Basketball | 28.0 | 23 | 20 |
| Nike Women's Pro Vic | Basketball | 21.99 | 24 | 21 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 179.99 | 1 | 1 |
| TaylorMade RocketBal | Bike & Skate Shop | 169.99 | 2 | 2 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 169.99 | 2 | 2 |
| Cleveland Golf Class | Bike & Skate Shop | 119.99 | 4 | 3 |
| Callaway X Hot Drive | Bike & Skate Shop | 0.0 | 5 | 4 |
+-----------------------+--------------------+----------+-------+------------+
La función row_number permite numerar los resultados, da igual que tengamos elementos que repiten valor:
select substr(nombre, 1, 20) as nombre, categoria, precio,
row_number() over (partition by categoria order by precio desc) as numfila
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
Resultado:
+-----------------------+--------------------+----------+----------+
| nombre | categoria | precio | numfila |
+-----------------------+--------------------+----------+----------+
| SOLE F85 Treadmill | Basketball | 1799.99 | 1 |
| SOLE E25 Elliptical | Basketball | 999.99 | 2 |
| Diamondback Adult Re | Basketball | 349.98 | 3 |
| Diamondback Adult Ou | Basketball | 309.99 | 4 |
| Diamondback Girls' C | Basketball | 299.99 | 5 |
| Diamondback Boys' In | Basketball | 299.99 | 6 |
| Diamondback Adult So | Basketball | 299.98 | 7 |
| Easton Mako Youth Ba | Basketball | 249.97 | 8 |
| Fitness Gear 300 lb | Basketball | 209.99 | 9 |
| Quik Shade Summit SX | Basketball | 199.99 | 10 |
| Easton XL1 Youth Bat | Basketball | 179.97 | 11 |
| Easton S1 Youth Bat | Basketball | 179.97 | 12 |
| adidas Brazuca 2014 | Basketball | 159.99 | 13 |
| Quest 12' x 12' Dome | Basketball | 149.99 | 14 |
| Fitbit Flex Wireless | Basketball | 99.95 | 15 |
| Nike+ Fuelband SE | Basketball | 99.0 | 16 |
| Elevation Training M | Basketball | 79.99 | 17 |
| MAC Sports Collapsib | Basketball | 69.99 | 18 |
| Quest Q64 10 FT. x 1 | Basketball | 59.98 | 19 |
| adidas Brazuca 2014 | Basketball | 39.99 | 20 |
| Kijaro Dual Lock Cha | Basketball | 29.99 | 21 |
| adidas Brazuca 2014 | Basketball | 29.99 | 22 |
| Nike Women's Pro Cor | Basketball | 28.0 | 23 |
| Nike Women's Pro Vic | Basketball | 21.99 | 24 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 179.99 | 1 |
| TaylorMade RocketBal | Bike & Skate Shop | 169.99 | 2 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 169.99 | 3 |
| Cleveland Golf Class | Bike & Skate Shop | 119.99 | 4 |
| Callaway X Hot Drive | Bike & Skate Shop | 0.0 | 5 |
+-----------------------+--------------------+----------+----------+
Consultas por posición¶
A continuación vamos a ver las funciones lead y lag. Estas funciones se encargan de obtener el valor posterior y anterior respecto a un valor.
select substr(nombre, 1, 20) as nombre, categoria, precio,
lead(precio) over (partition by categoria order by precio desc) as sig,
lag(precio) over (partition by categoria order by precio desc) as ant
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
Resultado:
+-----------------------+--------------------+----------+---------+----------+
| nombre | categoria | precio | sig | ant |
+-----------------------+--------------------+----------+---------+----------+
| SOLE F85 Treadmill | Basketball | 1799.99 | 999.99 | NULL |
| SOLE E25 Elliptical | Basketball | 999.99 | 349.98 | 1799.99 |
| Diamondback Adult Re | Basketball | 349.98 | 309.99 | 999.99 |
| Diamondback Adult Ou | Basketball | 309.99 | 299.99 | 349.98 |
| Diamondback Girls' C | Basketball | 299.99 | 299.99 | 309.99 |
| Diamondback Boys' In | Basketball | 299.99 | 299.98 | 299.99 |
| Diamondback Adult So | Basketball | 299.98 | 249.97 | 299.99 |
| Easton Mako Youth Ba | Basketball | 249.97 | 209.99 | 299.98 |
| Fitness Gear 300 lb | Basketball | 209.99 | 199.99 | 249.97 |
| Quik Shade Summit SX | Basketball | 199.99 | 179.97 | 209.99 |
| Easton XL1 Youth Bat | Basketball | 179.97 | 179.97 | 199.99 |
| Easton S1 Youth Bat | Basketball | 179.97 | 159.99 | 179.97 |
| adidas Brazuca 2014 | Basketball | 159.99 | 149.99 | 179.97 |
| Quest 12' x 12' Dome | Basketball | 149.99 | 99.95 | 159.99 |
| Fitbit Flex Wireless | Basketball | 99.95 | 99.0 | 149.99 |
| Nike+ Fuelband SE | Basketball | 99.0 | 79.99 | 99.95 |
| Elevation Training M | Basketball | 79.99 | 69.99 | 99.0 |
| MAC Sports Collapsib | Basketball | 69.99 | 59.98 | 79.99 |
| Quest Q64 10 FT. x 1 | Basketball | 59.98 | 39.99 | 69.99 |
| adidas Brazuca 2014 | Basketball | 39.99 | 29.99 | 59.98 |
| Kijaro Dual Lock Cha | Basketball | 29.99 | 29.99 | 39.99 |
| adidas Brazuca 2014 | Basketball | 29.99 | 28.0 | 29.99 |
| Nike Women's Pro Cor | Basketball | 28.0 | 21.99 | 29.99 |
| Nike Women's Pro Vic | Basketball | 21.99 | NULL | 28.0 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 179.99 | 169.99 | NULL |
| TaylorMade RocketBal | Bike & Skate Shop | 169.99 | 169.99 | 179.99 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 169.99 | 119.99 | 169.99 |
| Cleveland Golf Class | Bike & Skate Shop | 119.99 | 0.0 | 169.99 |
| Callaway X Hot Drive | Bike & Skate Shop | 0.0 | NULL | 119.99 |
+-----------------------+--------------------+----------+---------+----------+
Consultas de agregación¶
Las funciones de agregación que ya conocemos como count, sum, min y max también las podemos aplicar sobre particiones de datos y así poder mostrar los datos agregados para cada elemento:
select substr(nombre, 1, 20) as nombre, categoria,
count(precio) over (partition by categoria) as cantidad,
min(precio) over (partition by categoria) as menor,
max(precio) over (partition by categoria) as mayor
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
Resultado:
+-----------------------+--------------------+-----------+--------+----------+
| nombre | categoria | cantidad | menor | mayor |
+-----------------------+--------------------+-----------+--------+----------+
| Fitbit Flex Wireless | Basketball | 24 | 21.99 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 24 | 21.99 | 1799.99 |
| Fitness Gear 300 lb | Basketball | 24 | 21.99 | 1799.99 |
| Diamondback Adult Re | Basketball | 24 | 21.99 | 1799.99 |
| Nike+ Fuelband SE | Basketball | 24 | 21.99 | 1799.99 |
| Elevation Training M | Basketball | 24 | 21.99 | 1799.99 |
| Easton XL1 Youth Bat | Basketball | 24 | 21.99 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 24 | 21.99 | 1799.99 |
| Diamondback Girls' C | Basketball | 24 | 21.99 | 1799.99 |
| Easton S1 Youth Bat | Basketball | 24 | 21.99 | 1799.99 |
| Easton Mako Youth Ba | Basketball | 24 | 21.99 | 1799.99 |
| SOLE E25 Elliptical | Basketball | 24 | 21.99 | 1799.99 |
| Diamondback Adult Ou | Basketball | 24 | 21.99 | 1799.99 |
| Kijaro Dual Lock Cha | Basketball | 24 | 21.99 | 1799.99 |
| MAC Sports Collapsib | Basketball | 24 | 21.99 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 24 | 21.99 | 1799.99 |
| SOLE F85 Treadmill | Basketball | 24 | 21.99 | 1799.99 |
| Quest Q64 10 FT. x 1 | Basketball | 24 | 21.99 | 1799.99 |
| Diamondback Boys' In | Basketball | 24 | 21.99 | 1799.99 |
| Diamondback Adult So | Basketball | 24 | 21.99 | 1799.99 |
| Nike Women's Pro Cor | Basketball | 24 | 21.99 | 1799.99 |
| Quik Shade Summit SX | Basketball | 24 | 21.99 | 1799.99 |
| Quest 12' x 12' Dome | Basketball | 24 | 21.99 | 1799.99 |
| Nike Women's Pro Vic | Basketball | 24 | 21.99 | 1799.99 |
| Cleveland Golf Class | Bike & Skate Shop | 5 | 0.0 | 179.99 |
| TaylorMade RocketBal | Bike & Skate Shop | 5 | 0.0 | 179.99 |
| Callaway X Hot Drive | Bike & Skate Shop | 5 | 0.0 | 179.99 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 5 | 0.0 | 179.99 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 5 | 0.0 | 179.99 |
+-----------------------+--------------------+-----------+--------+----------+
Otras funciones ventana
Además de las funciones que hemos visto, Hive también soporta otras funciones ventana como percent_rank, cume_dist, ntile (divide los datos en n grupos de igual tamaño, muy útil para percentiles y cuartiles) o first_value y last_value entre otras. Puedes consultar la documentación oficial para más información.
Ventanas¶
Las consultas que hemos visto en este caso de uso también se conocen como funciones ventana, ya que se ejecutan sobre un subconjunto de los datos. La ventana viene dada por la partición o por la posición una vez ordenados los datos.
Los posibles valores son:
rows between current row and unbounded following: desde la fila actual hasta el final de la ventana/partición.rows between current row and N following: desde la fila actual hasta los N siguientes.rows between unbounded preceding and current row: desde el inicio de la ventana hasta la fila actual.rows between unbounded preceding and N following: desde el inicio de la ventana hasta los N siguientes.rows between unbounded preceding and unbounded following: desde el inicio de la ventana hasta el final de la ventana (caso por defecto)rows between N preceding and M following: desde N filas anteriores hasta M filas siguientes.
Por ejemplo, para obtener el máximo precio desde la fila actual hasta el resto de la partición:
select substr(nombre, 1, 20) as nombre, categoria, precio,
max(precio) over (
partition by categoria
rows between current row and unbounded following
) as mayor
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
Resultado:
+-----------------------+--------------------+----------+----------+
| nombre | categoria | precio | mayor |
+-----------------------+--------------------+----------+----------+
| Fitbit Flex Wireless | Basketball | 99.95 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 39.99 | 1799.99 |
| Fitness Gear 300 lb | Basketball | 209.99 | 1799.99 |
| Diamondback Adult Re | Basketball | 349.98 | 1799.99 |
| Nike+ Fuelband SE | Basketball | 99.0 | 1799.99 |
| Elevation Training M | Basketball | 79.99 | 1799.99 |
| Easton XL1 Youth Bat | Basketball | 179.97 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 29.99 | 1799.99 |
| Diamondback Girls' C | Basketball | 299.99 | 1799.99 |
| Easton S1 Youth Bat | Basketball | 179.97 | 1799.99 |
| Easton Mako Youth Ba | Basketball | 249.97 | 1799.99 |
| SOLE E25 Elliptical | Basketball | 999.99 | 1799.99 |
| Diamondback Adult Ou | Basketball | 309.99 | 1799.99 |
| Kijaro Dual Lock Cha | Basketball | 29.99 | 1799.99 |
| MAC Sports Collapsib | Basketball | 69.99 | 1799.99 |
| adidas Brazuca 2014 | Basketball | 159.99 | 1799.99 |
| SOLE F85 Treadmill | Basketball | 1799.99 | 1799.99 |
| Quest Q64 10 FT. x 1 | Basketball | 59.98 | 299.99 |
| Diamondback Boys' In | Basketball | 299.99 | 299.99 |
| Diamondback Adult So | Basketball | 299.98 | 299.98 |
| Nike Women's Pro Cor | Basketball | 28.0 | 199.99 |
| Quik Shade Summit SX | Basketball | 199.99 | 199.99 |
| Quest 12' x 12' Dome | Basketball | 149.99 | 149.99 |
| Nike Women's Pro Vic | Basketball | 21.99 | 21.99 |
| Cleveland Golf Class | Bike & Skate Shop | 119.99 | 179.99 |
| TaylorMade RocketBal | Bike & Skate Shop | 169.99 | 179.99 |
| Callaway X Hot Drive | Bike & Skate Shop | 0.0 | 179.99 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 179.99 | 179.99 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 169.99 | 169.99 |
+-----------------------+--------------------+----------+----------+
Si queremos comparar el precio y quedarnos con el mayor respecto al anterior y el posterior podríamos realizar la siguiente consulta:
select substr(nombre, 1, 20) as nombre, categoria, precio,
max(precio) over (
partition by categoria
rows between 1 preceding and 1 following
) as mayor
from productos
where categoria = "Bike & Skate Shop" or categoria = "Basketball";
Resultado:
+-----------------------+--------------------+----------+----------+
| nombre | categoria | precio | mayor |
+-----------------------+--------------------+----------+----------+
| Fitbit Flex Wireless | Basketball | 99.95 | 99.95 |
| adidas Brazuca 2014 | Basketball | 39.99 | 209.99 |
| Fitness Gear 300 lb | Basketball | 209.99 | 349.98 |
| Diamondback Adult Re | Basketball | 349.98 | 349.98 |
| Nike+ Fuelband SE | Basketball | 99.0 | 349.98 |
| Elevation Training M | Basketball | 79.99 | 179.97 |
| Easton XL1 Youth Bat | Basketball | 179.97 | 179.97 |
| adidas Brazuca 2014 | Basketball | 29.99 | 299.99 |
| Diamondback Girls' C | Basketball | 299.99 | 299.99 |
| Easton S1 Youth Bat | Basketball | 179.97 | 299.99 |
| Easton Mako Youth Ba | Basketball | 249.97 | 999.99 |
| SOLE E25 Elliptical | Basketball | 999.99 | 999.99 |
| Diamondback Adult Ou | Basketball | 309.99 | 999.99 |
| Kijaro Dual Lock Cha | Basketball | 29.99 | 309.99 |
| MAC Sports Collapsib | Basketball | 69.99 | 159.99 |
| adidas Brazuca 2014 | Basketball | 159.99 | 1799.99 |
| SOLE F85 Treadmill | Basketball | 1799.99 | 1799.99 |
| Quest Q64 10 FT. x 1 | Basketball | 59.98 | 1799.99 |
| Diamondback Boys' In | Basketball | 299.99 | 299.99 |
| Diamondback Adult So | Basketball | 299.98 | 299.99 |
| Nike Women's Pro Cor | Basketball | 28.0 | 299.98 |
| Quik Shade Summit SX | Basketball | 199.99 | 199.99 |
| Quest 12' x 12' Dome | Basketball | 149.99 | 199.99 |
| Nike Women's Pro Vic | Basketball | 21.99 | 149.99 |
| Cleveland Golf Class | Bike & Skate Shop | 119.99 | 169.99 |
| TaylorMade RocketBal | Bike & Skate Shop | 169.99 | 169.99 |
| Callaway X Hot Drive | Bike & Skate Shop | 0.0 | 179.99 |
| Nike VR_S Covert Dri | Bike & Skate Shop | 179.99 | 179.99 |
| Cobra AMP Cell Drive | Bike & Skate Shop | 169.99 | 179.99 |
+-----------------------+--------------------+----------+----------+
Referencias¶
- Página oficial de Hive
- Apache Hive Essentials - Second Edition de Dayong Du.
- Hive Cheatsheet
- Tutorial de Hive de TutorialsPoint.
Actividades¶
Siguiendo con los archivos cargados en HDFS en la sesión anterior y la base de datos hiveiabd:
-
(RASBD.3 / CESBD.3b y CESBD.3d / 1p) Crea una tabla interna transaccional llamada
ventasen formato ORC y a continuación, rellénala con el resultado de realizar un join entre las tablassalesyproductsymanufacturer, particionando los datos por el país de la venta.Crear y rellenar
Cuando utilizamos tablas particionadas, la sentencia
CREATE TABLE ventas AS SELECT ...no funciona, por lo tanto, para esta actividad, primero deberemos realizar unaCREATE TABLE ventas (...) PARTITIONED BY (...) STORED AS... TBLPROPERTIES ('transactional'='true');y a continuación unINSERT INTO ventas PARTITION (...) SELECT ...Particionado dinámico
Recuerda que antes de insertar los datos es necesario configurar las siguientes propiedades:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; SET hive.auto.convert.join = false;- ¿Qué aparece al ejecutar el siguiente comando
hdfs dfs -ls /user/hive/warehouse/hiveiabd.db/ventas?
- ¿Qué aparece al ejecutar el siguiente comando
-
(RASBD.3 / CESBD.3b y CESBD.3d / 1p) Sobre la tabla de
ventasrecién creada, crea una vista materializada llamadaventasPorFabricanteque obtenga la siguiente información de la recaudación obtenida por cada fabricante.+-----------------------------------+----------------------------------+ | ventasporfabricante.manufacturer | ventasporfabricante.recaudacion | +-----------------------------------+----------------------------------+ | Abbas | 8504830.70993042 | | Aliqui | 4.960930444169426E7 | | Barba | 4145604.8580932617 | | Currus | 3.4098148993003845E7 | | Fama | 3111286.106048584 | | Leo | 4981597.603515625 | | Natura | 7.659636524445343E7 | | Palma | 1141784.282775879 | | Pirum | 3.0881129688156128E7 | | Pomum | 2290935.590690613 | | Quibus | 7420492.980041504 | | Salvus | 342236.4960708618 | | VanArsdel | 2.5061688651968384E8 | | Victoria | 3820327.428833008 | +-----------------------------------+----------------------------------+-
Inserta el siguiente dato en la tabla
ventasy comprueba si aparece en la vistaventasPorFabricante(fíjate en el fabricante Natura) y en HDFS:insert into ventas values (725,"2/15/2024","03206",10,98765432.1,"Natura RP-13", "Rural", "Productivity", 8, "Natura", "Spain"); -
Provoca que la vista materializada actualice su estado y muestra cómo el dato del paso anterior ya repercute en el resultado en la vista.
-
-
(RASBD.3 / CESBD.3b y CESBD.3d / opcional) Ejecuta la siguiente consulta que utiliza funciones ventana y explica qué realiza:
SELECT manufacturer, country, sum(revenue*units), rank() OVER (partition by country ORDER BY sum(revenue*units) desc) FROM ventas GROUP BY manufacturer, country; -
(RASBD.3 / CESBD.3b y CESBD.3d / opcional) Basándote en el caso de uso 7:
- Crea un agente Flume que inserte datos de ventas en la ruta
/user/iabd/pdi/salesy tras su ejecución, comprueba que los datos aparecen al realizar una consulta sobre la tablasales. Para ello, crea un fichero CSV con el formato adecuado y algunos datos de muestra. - ¿Aparecen estos datos en la tabla
ventas? ¿Por qué? - En vez de la tabla
ventas, ¿qué estructura utilizarías si queremos tener siempre los datos actualizados (se envían de forma diaria)? Implementa la solución elegida.
- Crea un agente Flume que inserte datos de ventas en la ruta
-
(RASBD.3 / CESBD.3b y CESBD.3d / opcional) A partir de la base de datos
retail_db, importa las tablasordersyorder_items, en las cuales puedes obtener la cantidad de productos que contiene un pedido. Utilizando todas las tablas que ya hemos importado en los casos de uso de los apuntes, crea una tabla externa en Hive llamadapedidosutilizando 8 buckets con el código del cliente, que contenga:- Código y fecha del pedido.
- Precio del pedido (sumando las líneas de pedido).
- Código, nombre y apellidos del cliente.
Adjunta scripts y capturas de:
- la importación, creación y carga de datos de las tablas que necesites.
- la definición de la tabla:
describe formatted pedidos; - contenido de HDFS que demuestre la creación de los buckets.