Reaprendiendo
¿Es necesario tener un dataset enorme y preciso y realizar una arquitectura compleja con un proceso de entrenamiento costoso al realizarlo desde cero? Si no disponemos de suficientes datos para realizar un entrenamiento desde cero, la transferencia de conocimiento y el fine-tuning pueden ser la solución a nuestros problemas.
Estas técnicas se basan en emplear arquitecturas y modelos de IA ya entrenados con un resultado notable y aprovechar dicho conocimiento para nuestro propósito.
Aprendizaje por Transferencia¶
La transferencia de conocimiento o aprendizaje por transferencia (transfer learning) es la técnica según la cual un modelo entrenado para una tarea se emplea como punto de partida en la resolución de un problema diferente. Es una técnica de gran utilidad cuando no se cuenta con una gran dataset de entrenamiento.
Las principales ventajas a la hora de utilizar transferencia de conocimiento en nuestros modelos de IA son:
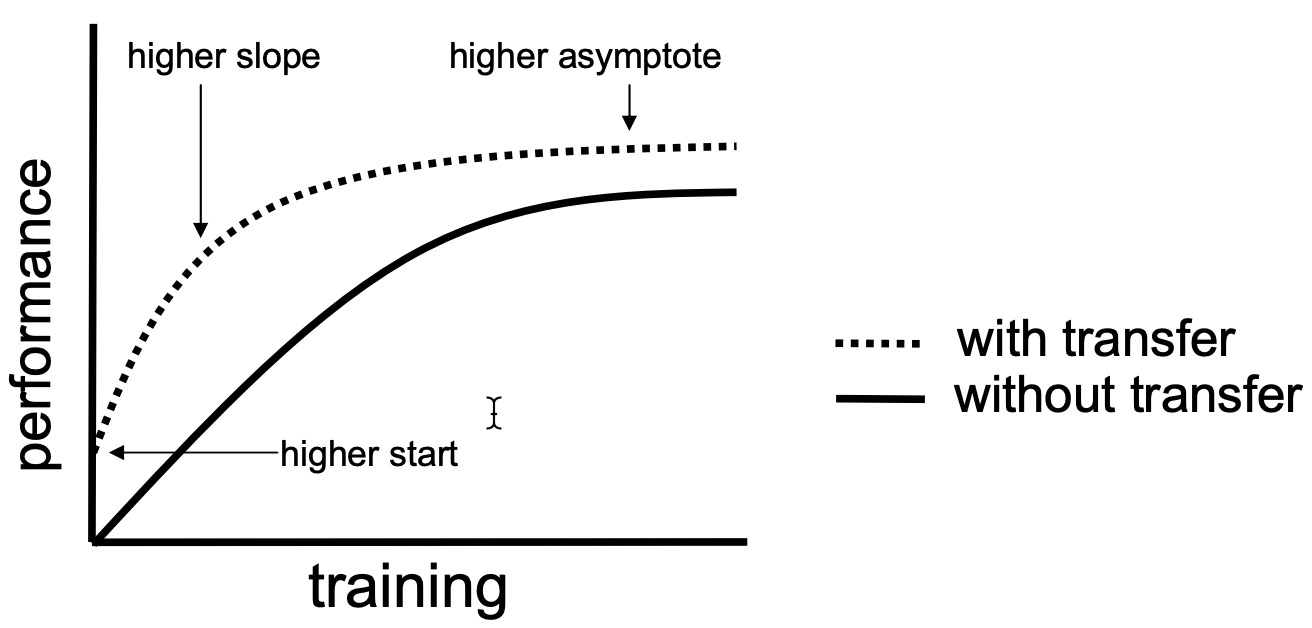
- Mayor punto de inicio: el rendimiento del modelo al inicio de entrenamiento es mayor, al utilizar un modelo que ya tiene un conocimiento previo que puede ayudar a aprender completamente la tarea objetivo en comparación con un modelo que aprende desde cero.
- Mayor pendiente: convergencia del entrenamiento más rápida.
- Mayor asíntota: mejor rendimiento del modelo al final del entrenamiento.
Aprendizaje por Transferencia vs Fine-tuning¶
Es importante diferenciar lo que es el fine-tuning del aprendizaje por transferencia, ya que aunque sus enfoques son similares, conviene conocer sus diferencias.
En el aprendizaje por transferencia, se toma un modelo entrenado en una tarea para reutilizarlo en la resolución de otra, pero congelando los parámetros del modelo existente. El proceso es el siguiente:
- Se carga el modelo entrenado y se congelan las capas preentrenadas para evitar la pérdida de información.
- Se añaden nuevas capas entrenables sobre las congeladas, que se entrenan con otro conjunto de datos.
En el fine-tuning (ajuste fino), en cambio, se toman los parámetros de la red existente para entrenarlos aún más y así realice la segunda tarea. Básicamente, se adapta la estructura del modelo y se entrena. Para ello:
- Al modelo existente se le eliminan y añaden las capas necesarias para la resolución de la nueva tarea.
- En la nueva arquitectura se congelan solo aquellas capas que provienen de la red original, cuyo conocimiento se desea conservar para el nuevo entrenamiento.
- Se procede a entrenar el modelo con los nuevos datos para la nueva tarea. Solo se actualizan los pesos de las capas nuevas.
Aumento de datos
Es muy común utilizar diversas técnicas sobre los dataset para aumentar el tamaño del mismo. En el caso de las imágenes, se pueden realizar transformaciones como rotaciones, traslaciones, zoom, etc.. para generar nuevas versiones de las imágenes existentes. En el caso de audios, podemos modificar el tono, la velocidad, etc...
Transferencia en Redes Neuronales¶
Si nos centramos en entrenamientos basados en redes neuronales y dependiendo del tamaño del dataset existente y la similitud de los nuevos datos con los antiguos de pueden dar los siguientes contextos de uso:
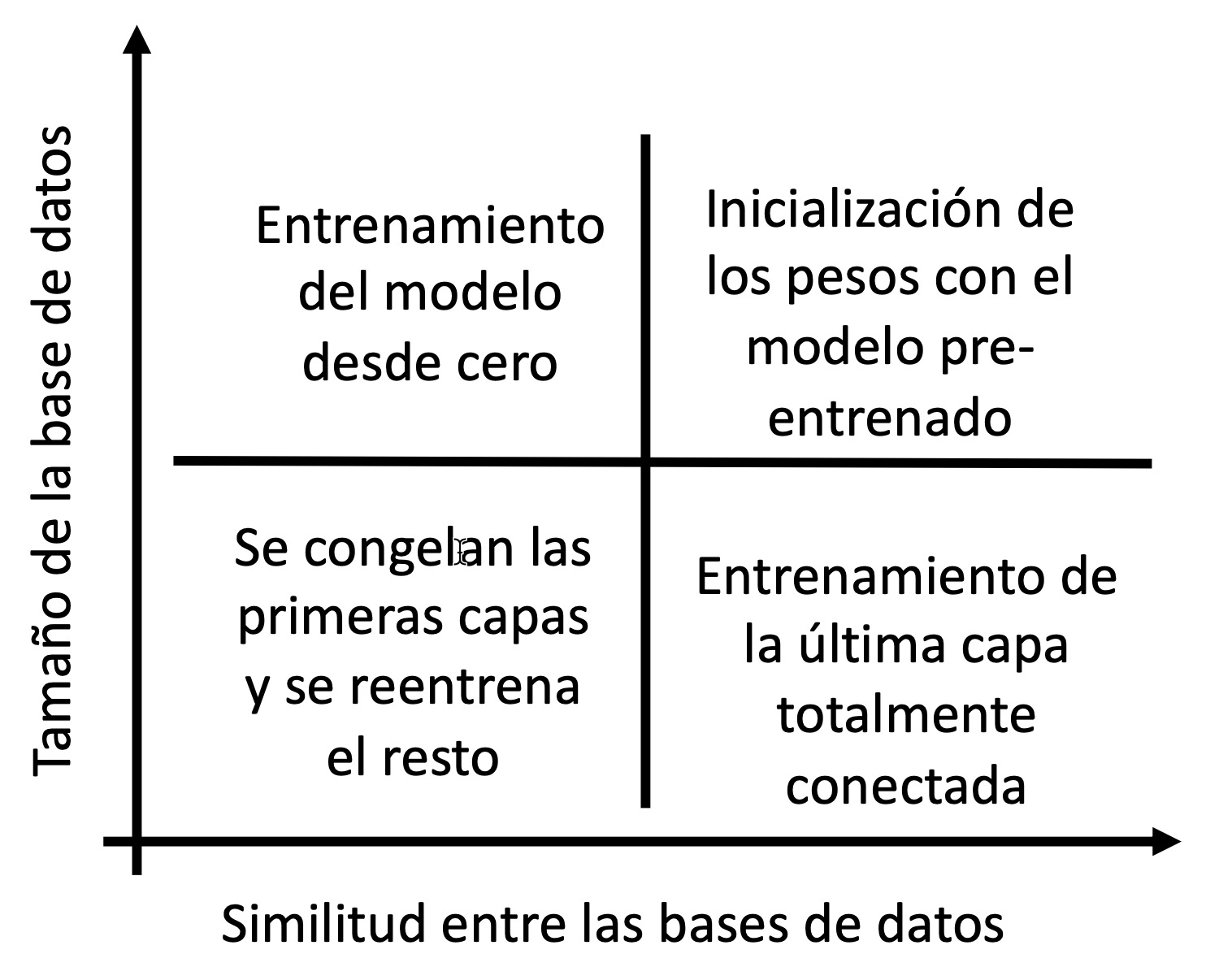
El caso más básico es cuando el tamaño del nuevo dataset es grande y completamente diferentes al de nuestros modelos. En ese caso, dejamos de lado la transferencia de conocimiento y realizaremos el entrenamiento desde cero.
El segundo caso es cuando tenemos un nuevo dataset grande y similar al original deberíamos inicializar los pesos con el modelo pre-entrenado mediante los siguientes pasos:
- Eliminar la última capa totalmente conectada y sustituirla por una que tenga tantos nodos como clases tenga el nuevo problema.
- Inicializar de forma aleatoria la nueva capa totalmente conectada.
- Inicializar el resto de capas con los pesos del modelo pre-entrenado.
- Re-entrenamiento de la red neuronal.
En cambio, si la nueva base de datos es pequeña y pero es similar a la original, realizaremos únicamente el entrenamiento de la última capa totalmente conectada, lo que conoce como extractor de características (feature extraction). La idea es reutilizar una red pre-entrenada sin capa final. Esta nueva red funciona como un extractor de features fijas para realizar otras tareas. Para ello, se recomienda:
- Eliminar las capas totalmente conectadas y se sustituye por una que tenga tantos nodos como clases tenga el nuevo problema.
- Inicializar de forma aleatoria la nueva capa totalmente conectada.
- Bloquear los pesos del resto de capas.
- Re-entrenar de la nueva capa totalmente conectada.
Si la nueva base de datos es pequeña y diferente de la original, deberemos congelar las primeras capas y reentrenar el resto siguiendo los siguientes pasos:
- Se dejan únicamente las primeras capas convolucionales (características de bajo nivel) y se eliminan el resto.
- Se añaden capas totalmente conectadas a las capas anteriores.
- Se mantienen los pesos de las capas convolucionales.
- Se inicializan aleatoriamente los pesos de las capas totalmente conectadas.
- Re-entrenamiento de las capas totalmente conectadas.
Aumento de Datos¶
Una técnica habitual para aumentar la variedad del conjunto de datos, sobre todo cuando no disponemos de suficientes datos es aumentarlos artificialmente. Para ello, modificamos las muestras de datos existentes con pequeños detalles.
Por ejemplo, en el caso de las imágenes, podemos girarlas ligeramente, recortarlas o escalarlas, modificar los colores o la iluminación, o añadir ruido a la imagen. Como la semántica de la imagen no ha cambiado materialmente, la misma etiqueta de la muestra original seguirá aplicándose a la muestra aumentada. Por ejemplo, si la imagen estaba etiquetada como "gato", la imagen aumentada también será un "gato".
Pero, desde el punto de vista del modelo, parece una nueva muestra de datos. Esto ayuda a que el modelo se generalice a una gama más amplia de entradas de imágenes.