Tratamiento de audio
El sonido¶
El sonido es una señal continua que recibe nuestro cerebro de las vibraciones mecánicas que producen los cuerpos y que llegan a nuestro oído a través de un medio.
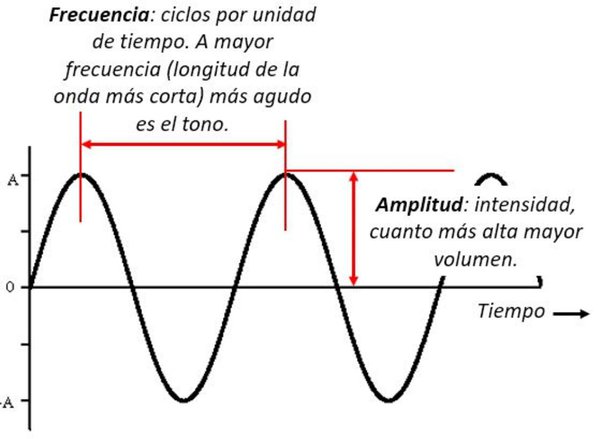
Las características del sonido son:
- la intensidad: depende de la amplitud de onda. A mayor amplitud, mayor intensidad del sonido.
- el timbre: depende de la forma de la onda, ya que los materiales de los cuerpos que generan el sonido vibran de modo diferente.
- el tono: relacionado con la frecuencia de la onda. A mayor frecuencia, se obtiene un sonido más agudo y a menor frecuencia, más grave.
El sonido es una señal continua que al digitalizarla se realiza un muestreo de la señal en una representación digital.
Cuando mediante un micrófono se graba el audio, la señal analógica del audio se digitaliza mediante un DAC (conversor analógico-digital) a través del muestreo.
Existen diferentes formatos como .wav (Waveform Audio File), .flac (Free Lossless Audio Codec) y .mp3 (MPEG-1 Audio Layer 3). Estos formatos se diferencian en cómo comprimen la representación digital de la señal de audio.
Frecuencia de muestreo¶
El muestreo es el proceso de medir el valor de una señal continua en intervalos de tiempo fijos. La señal sampleada es discreta, ya que contiene un número finito de valores de la señal.
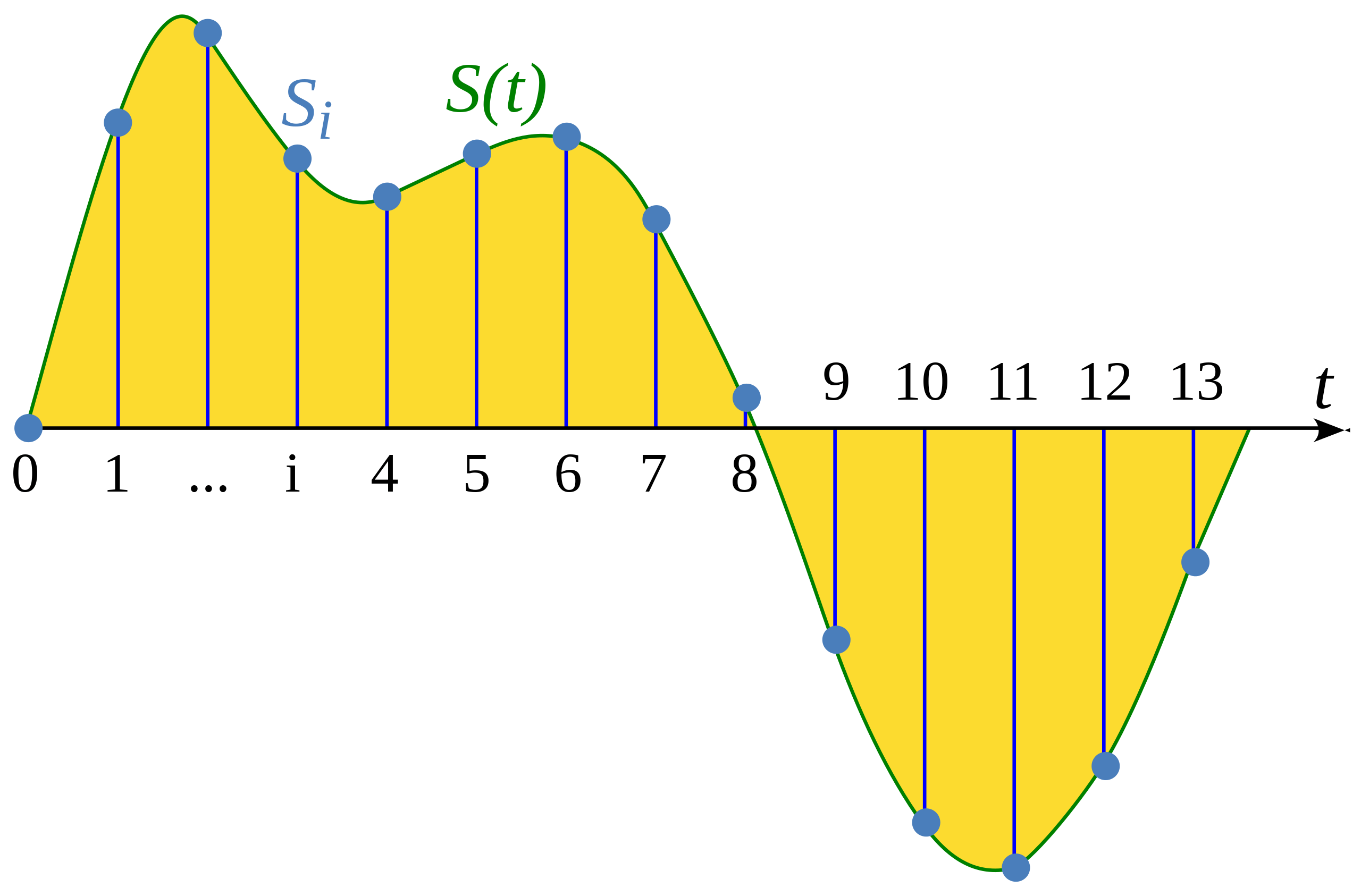
La tasa de muestreo (también llamada frecuencia de muestreo) es el número de muestras capturadas en un segundo y se mide en hertzios (Hz) (recordad que un hertzio es igual a un segundo elevado a menos 1). Como referencia, un audio con calidad de CD tiene una frecuencia de muestreo de 44 kHz. La frecuencia de muestreo más utilizada para entrenar modelos de voz es de 16 kHz.
Frecuencia y tiempo
Por ejemplo, un audio de 10 segundos a 16kHz se representará mediante 160.000 valores. En cambio, el mismo audio a 8kHz lo hará con 80.000.
Los modelos de transformers para audio tratan los audios como secuencias y se basan en mecanismos de atención para aprender del audio. Ya que la longitud de las secuencias difiere al usar diferentes frecuencias de muestreo, necesitamos que todos los audios tengan la misma frecuencia. Este proceso de convertir una señal de audio a otro con diferente frecuencia se conoce como Resamplear.
Amplitud de onda¶
El sonido se produce por cambios en la presión del aire a frecuencias audibles para los humanos. La amplitud de un sonido describe el nivel de presión sonora en un momento dado y se mide en decibelios (dB). Percibimos la amplitud como volumen o intensidad del sonido. Por ejemplo, una voz normal al hablar está por debajo de los 60 dB, mientras que un concierto de rock puede llegar a los 125 dB, alcanzando los límites de la audición humana.
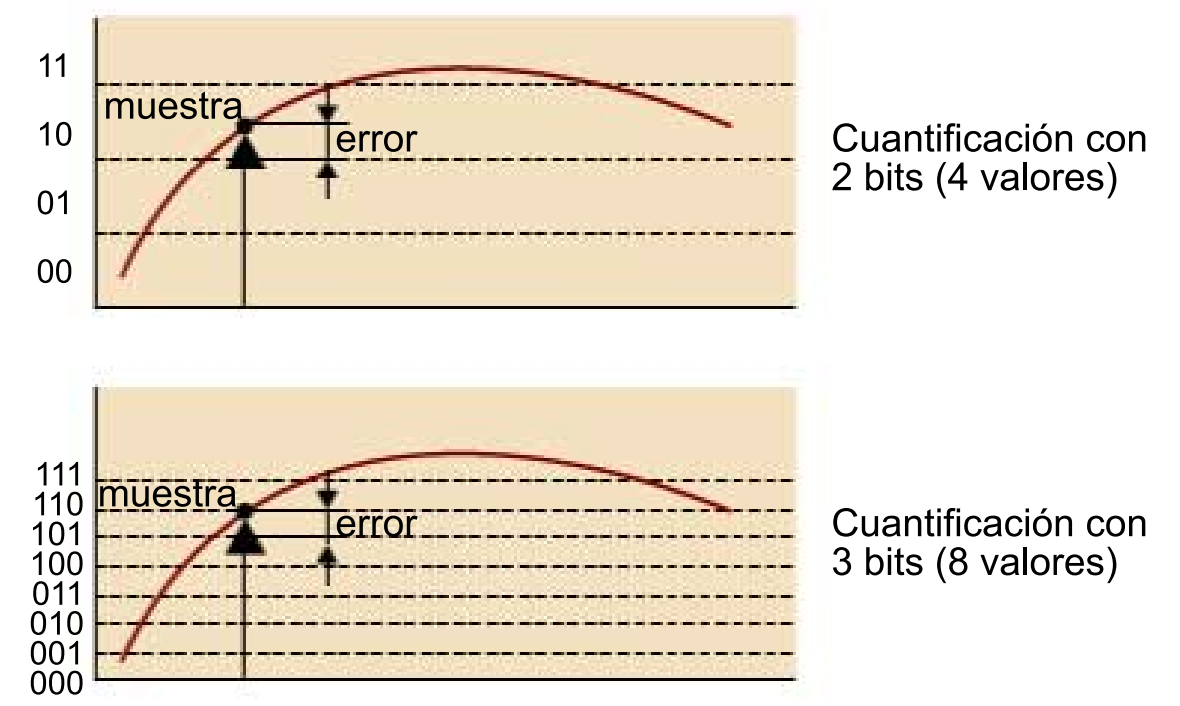
En el audio digital, cada muestra de audio registra la amplitud de la onda de audio en un momento específico. La profundidad de bits de la muestra determina con qué precisión se puede describir este valor de amplitud. Cuanto mayor sea la profundidad de bits, más fiel será la representación digital a la onda de sonido original.
Las profundidades de bits de audio más comunes son 16 bits y 24 bits. Cada una es una medida binaria que representa el número de pasos posibles en los que se puede cuantificar el valor de amplitud al convertirlo de continuo a discreto: 65.536 pasos para el audio de 16 bits y 16.777.216 pasos para el audio de 24 bits.
El proceso de muestreo introduce ruido al redondear el valor continuo a un valor discreto. Cuanto mayor sea la profundidad de bits, menor será este ruido de cuantificación. En la práctica, el ruido de cuantificación del audio de 16 bits ya es lo suficientemente pequeño como para ser audible, por lo que generalmente no es necesario utilizar profundidades de bits más altas.
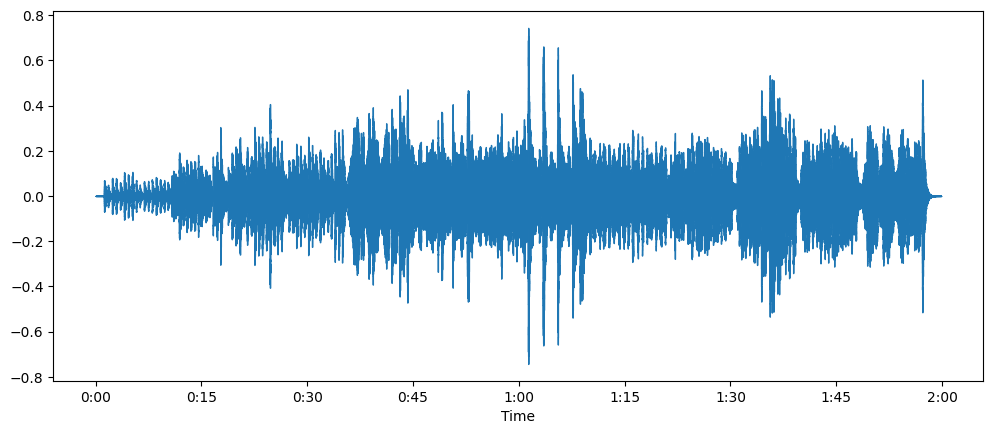
Forma de onda¶
Es muy común representar el sonido mediante un gráfico como una forma de onda (waveform), que representa los valores de las muestras a lo largo del tiempo y muestra los cambios en la amplitud del sonido.
De la misma forma que con las señales de audio continuas, la amplitud del audio digital se expresa típicamente en decibelios (dB).
La escala de decibelios para el audio real comienza en 0 dB, que representa el sonido más silencioso posible que los humanos pueden escuchar, y los sonidos más fuertes tienen valores más grandes.
Edición de sonido con Audacity¶
Para entender mejor los diferentes conceptos, vamos a utilizar Audacity como editor de sonido, al tratar de, probablemente, el editor multiplataforma y gratuito más conocido.
Este apartado lo vamos a realizar de manera práctica en el aula, ya que existen multitud de cursos y tutoriales sobre su uso, tanto en Youtube como en la web, como por ejemplo el Tutorial Audacity: guía para principiantes de clavepodcast.com.
En clase nos vamos a centrar en:
- Visualizar la onda obtenida a partir del muestreo
- Aplicar efectos de cambios de tono, velocidad y amplitud de onda y observar el resultado obtenido
Conversión de formatos con PyDub¶
Para convertir entre formatos de audios, una librería muy utilizada es PyDub
Tras instalarla mediante:
pip install pydub
Podemos cargar un archivo mediante diferentes operaciones from_file, from_mp3, from_wav...:
from pydub import AudioSegment
audio = AudioSegment.from_wav("mi_audio.wav")
Y realizar diferentes transformaciones:
mas_fuerte = audio + 5
mas_flojo = audio - 3.5
juntos = mas_fuerte + mas_flojo
repetido = juntos * 3
duracion_ms = len(repetido)
duracion_seg = audio.duration_seconds
sr = audio.frame_rate
audio_nuevo_sr = audio.set_frame_rate(8000)
Finalmente, para convertir el audio a otro formato haremos un export:
audio.export("mi_audio.ogg", format="ogg")
Más información en https://github.com/jiaaro/pydub/ y en la propia API.
Procesando audios con Librosa¶
Librosa es una librería para procesamiento de audio y música mediante Python.
En Librosa, por defecto se utilizan los siguientes valores:
- Todos los datos son tipos NumPy básicos.
- Los búferes de audio se denominan
yodata. - La frecuencia de muestreo se nombra con
sr, y por defecto, su valor el22050.
Antes de utilizarla, hemos de instalarla:
pip install librosa
Hola Librosa¶
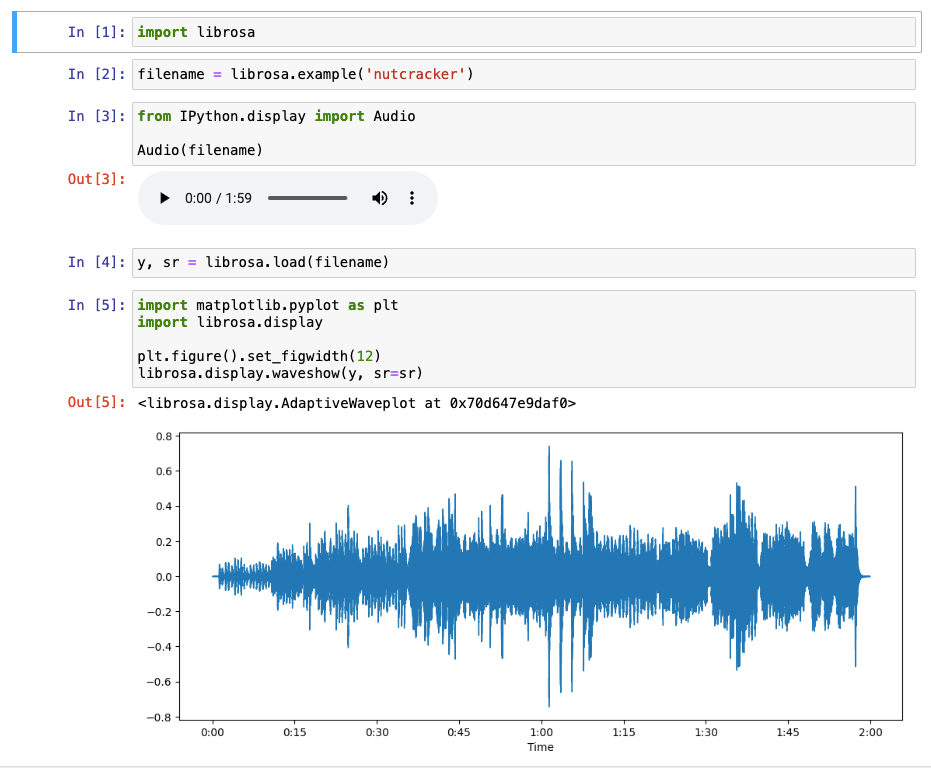
Vamos a comenzar cargando un audio y escuchándolo:
import librosa
filename = librosa.example('nutcracker')
Si estamos trabajando con un cuaderno de Jupyter, podemos generar un control que lo muestre mediante:
from IPython.display import Audio
Audio(filename)
A continuación, cargamos el audio, recuperando el array con los datos (en y) y la frecuencia de muestreo (en sr):
y, sr = librosa.load(filename)
Y dibujamos su gráfico de ondas:
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(y, sr=sr)
Espectrograma de Mel¶
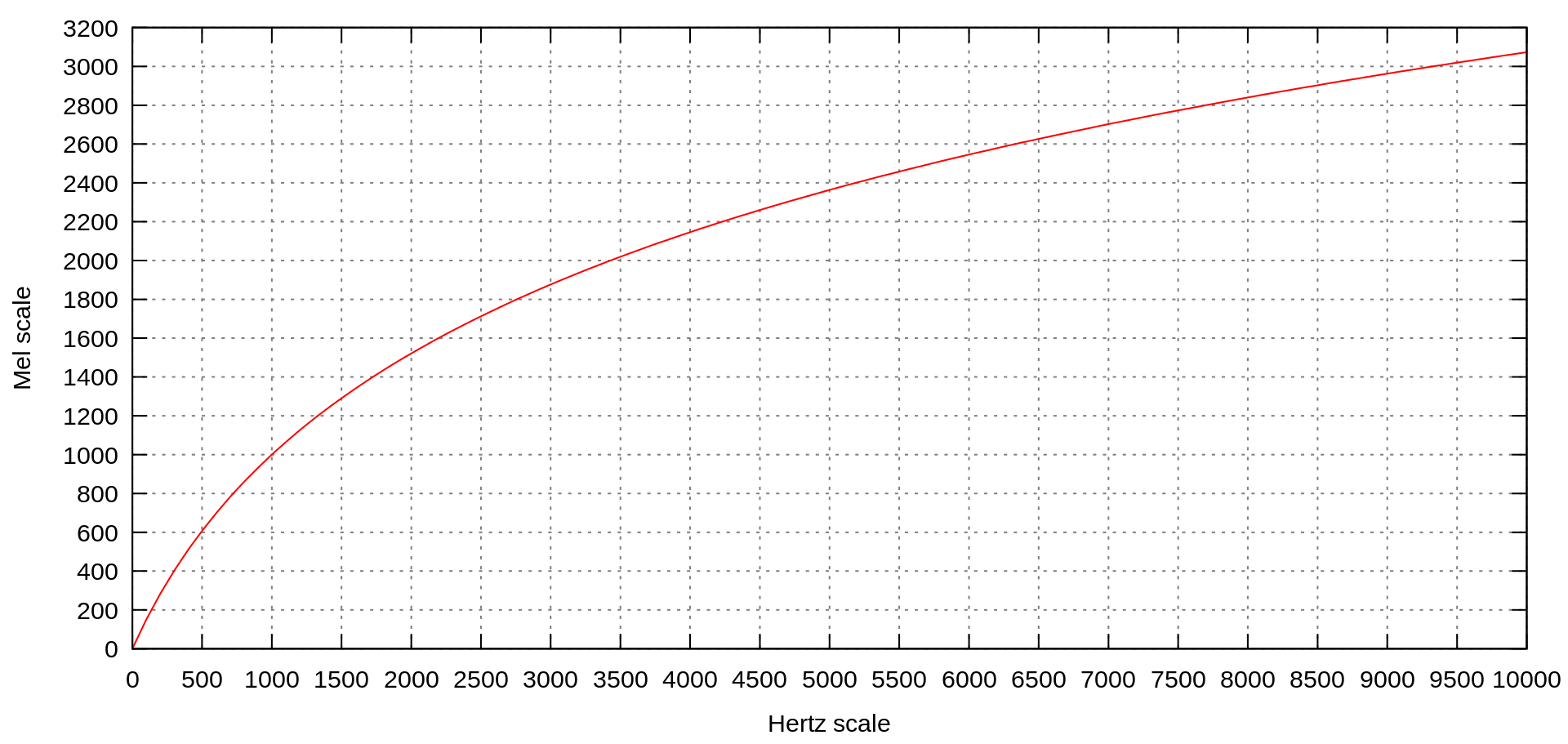
Un Mel es un número que corresponde a un tono, de forma similar a como una frecuencia describe un tono. Si consideramos una nota, por ejemplo, un La en cuarta, su frecuencia es 440 Hz. Si subimos una octava hasta La en quinta, su frecuencia se duplica a 880 hz, y vuelve a duplicarse a 1760 en La en sexta. Es un salto de 440 entre la cuarta y quinta octava y de 880 entre la quinta y la sexta, pero el problema es que el oído humano no oye así. La diferencia entre dos notas se siente igual si saltamos de Do a Re o de Fa a Sol.
Por ello, mediante la relación logarítmica, obtenemos valores de hz diferentes para diferentes intervalos. El término Mel viene de la palabra melódico para indicar que se basa en la percepción humana de los sonidos y, por lo tanto, la escala Mel pretende regularizar los intervalos entre notas para que, en vez de duplicar los Hz entre escalas, su diferencia sea estable tal cual lo sentimos nosotros:
Librosa incluye una función para extraer el espectrograma de potencia (amplitud al cuadrado) para cada Mel a lo largo del tiempo, así como una función para visualizar fácilmente el espectrograma Mel resultante:
spec = librosa.feature.melspectrogram(y=y, sr=sr)
librosa.display.specshow(spec,y_axis='mel', x_axis='s', sr=sr)
plt.colorbar()
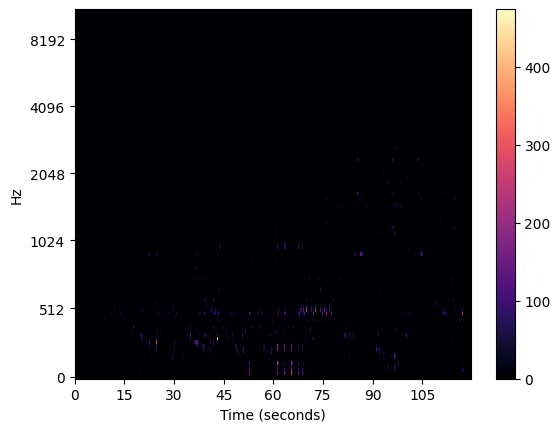
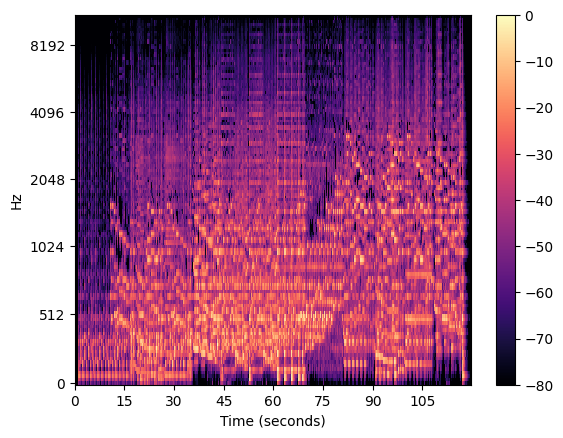
Este gráfico no nos da mucha información. Otro enfoque es representarlo en base a los decibelios, con lo que obtenemos mucha más información:
import numpy as np
spec = librosa.feature.melspectrogram(y=y, sr=sr)
db_spec = librosa.power_to_db(spec, ref=np.max,)
librosa.display.specshow(db_spec,y_axis='mel', x_axis='s', sr=sr)
plt.colorbar()
Por ejemplo, podemos ver como el inicio suena más grave con las frecuencias bajas, y conforme empiezan las campanillas y los instrumentos de aire, se vuelve más aguda (subiendo las notas en la escala musical), y como del segundo 35 al 60 (aprox) suenan elementos más agudos (frecuencias más altas):
Separando armónicos y percusión¶
Podemos descomponer una serie de tiempo de audio en componentes armónicos y percusivos mediante la función effects.hpss():
# Otenemos las muestras armónicas y de percusión
y_h, y_p = librosa.effects.hpss(y)
# Obtenemos los espectrogramas para cada
spec_h = librosa.feature.melspectrogram(y=y_h, sr=sr)
spec_p = librosa.feature.melspectrogram(y=y_p, sr=sr)
# Pasamos a decibelios
db_spec_h = librosa.power_to_db(spec_h,ref=np.max)
db_spec_p = librosa.power_to_db(spec_p,ref=np.max)
Y los pintamos:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# Dibujamos el primer espectrograma
img1 = librosa.display.specshow(db_spec_h, y_axis='mel', x_axis='s', sr=sr, ax=ax1)
ax1.set(title='Espectrograma Mel de Armónicos')
fig.colorbar(img1, ax=ax1, format="%+2.f dB")
# Dibujamos el segundo espectrograma
img2 = librosa.display.specshow(db_spec_p,y_axis='mel', x_axis='s', sr=sr, ax=ax2)
ax2.set(title='Espectrograma Mel de Percusión')
fig.colorbar(img2, ax=ax2, format="%+2.f dB")
# Mostramos la figura
plt.tight_layout()
plt.show()
Y observamos las diferencias:
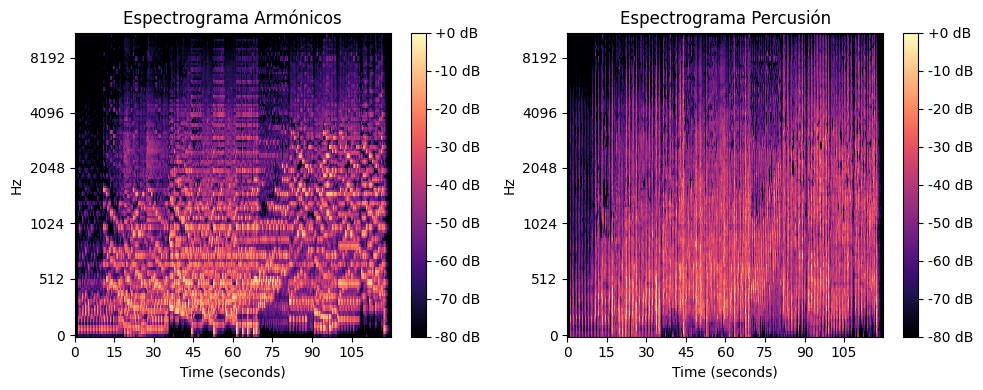
Y a partir de los armónicos, podemos extraer qué tonos están presentes como notas a partir de las características armónicas mediante la función feature.chroma_cqt(), la cual crea un cromagrama (permite diferenciar las diferentes notas musicales) a partir de las muestras:
chroma = librosa.feature.chroma_cqt(y=y_h, sr=sr)
plt.figure(figsize=(18,5))
librosa.display.specshow(chroma, sr=sr, x_axis='time', y_axis='chroma', vmin=0, vmax=1)
plt.title('Cromagrama')
plt.colorbar()
Obteniendo:
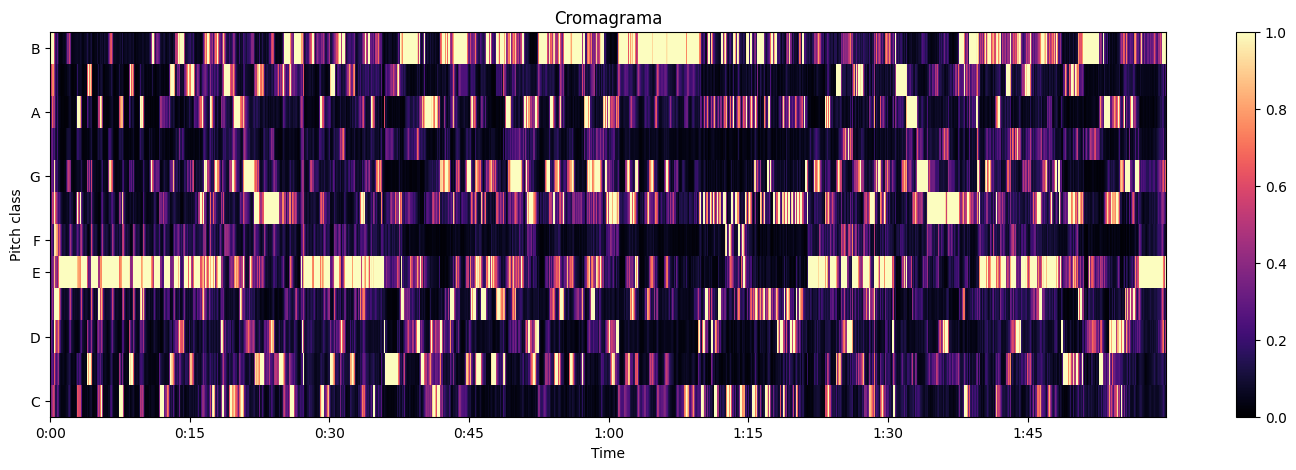
Tempo¶
A partir de un audio, podemos obtener más datos, como su tempo expresado en bpm (beats por minuto) o los instantes de cada tiempo, mediante la función beat.beat_track():
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print('Tempo estimado: {:.2f} bpm'.format(tempo))
# Tempo estimado: 107.67 bpm
Si queremos saber justo el instante temporal de cada beat, podemos convertir cada compás a instante mediante la función frames_to_time():
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
# array([ 1.18421769, 1.71827664, 2.32199546, 2.87927438,
# 3.45977324, 4.01705215, 4.59755102, 5.13160998,...
Transformaciones¶
La transformación que más vamos a emplear es remuestrear un audio para ajustarlo a los diferentes modelos de IA. Así pues, mediante Librosa emplearemos el método resample:
y_resampled = librosa.resample(y, orig_sr=sr, target_sr=9600)
Otra operación que nos puede ser muy útil es limpiar los silencios que tengamos delante y detrás del sonido. Para ello, usaremos el método trim:
y_trimmed, index = librosa.effects.trim(y)
Aumento de datos de audio (ADA)¶
Del mismo modo que con las imágenes, existen varias técnicas para aumentar los datos de audio. Este aumento puede realizarse tanto en el audio bruto antes de producir el espectrograma, como en el espectrograma generado. Si entrenamos un modelo desde cero, aumentar el espectrograma suele producir mejores resultados.
A la hora de aumentar los datos de audio, tenemos varias posibilidades:
- Añadir silencios delante y/o detrás (Silence Addition)
- Añadir ruido delante y/o detrás (Noise Addition)
- Aplicar diferentes efectos, como la reverberación o el eco.
- Modificar de forma aleatoria la intensidad (Amplitude Scaling)
- Modificar de forma aleatoria el tono (Pitch Shifting)
- Modificar (de forma aleatoria) la velocidad (Time Stretching), tanto aumentar como reducirla sin modificar su tono o intensidad.
Por ejemplo, mediante la librería Audiomentations podemos aplicar varias transformaciones a la vez (recuerda instalarla previamente mediante pip install audiomentations):
from audiomentations import Compose, AddGaussianNoise, TimeStretch, PitchShift, Shift
import librosa
import soundfile as sf
augment = Compose([
AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5), #ruido
TimeStretch(min_rate=0.9, max_rate=1.25, p=0.5), # velocidad
PitchShift(min_semitones=-4, max_semitones=4, p=0.5) # tono
])
y, sr = librosa.load(librosa.example('nutcracker'))
# Aplicamos los filtros
augmented = augment(samples=y, sample_rate=sr)
# Persistimos el audio
sf.write('audio_augmented.wav', augmented, sr)
Si quieres probar, puedes hacerlo mediante el siguiente cuaderno.
Referencias¶
- Artículos sobre Audio Deep Learning Made Simple - Parte 1 State-of-the-Art Techniques / Parte 2 - Why Mel Spectrograms perform better
- Tutorial sobre Librosa
- Aumento de datos para audio: técnicas y métodos
Actividades¶
FFmpeg
Es posible que para realizar las diferentes actividades tengas que instalar el paquete de utilidades de FFmpeg para codificar y decodificar los diferentes formatos de audio.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / opcional) Mediante Audacity, carga los archivos
Nutcracker.oggymensaje.wavy modifica la intensidad y el tono y comprueba los resultados. Almacena los audios modificados en formato MP3. -
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2p) Mediante un script Python y la librería PyDub, una vez cargados ambos archivos (
Nutcracker.oggymensaje.wav), muestra por consola su frecuencia de muestreo y duración, y posteriormente cambia la frecuencia de muestro a 16000 y vuelve a almacenar ambos en formato MP3. -
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2p) Haciendo uso de la librería Librosa y un cuaderno de Jupyter, carga un nuevo archivo de audio (el que tú quieras) y:
- Muestra un gráfico de ondas.
- Obtén y compara los espectrogramas de Mel, indicando alguna particularidad del audio utilizado.
- Crea el cromagrama y justifica qué elementos aparecen en amarillo.
- Averigua el tempo del audio.
Adjunta el cuaderno de Jupyter creado y el fichero de audio empleado. Si no tienes ningún audio, puedes utilizar cualquiera de los audios de ejemplo que incluye Librosa.