Audio en Hugging Face
Tal como vimos en la sesión de Hugging Face, existen múltiples modelos tanto para el reconocimiento del audio (ASR - Automatic Speech Recognition), como para el paso de texto a audio (TTS - Text-to-Speech), así como nuevos modelos centrados en la generación de audio y música.
En esta sesión vamos a realizar algunos casos de uso sencillos sobre los dos primeros tipo de modelos de audio mediante Hugging Face.
Caso 1: ASR con Whisper¶
A día de hoy, uno de los modelos que mejor funciona reconociendo la voz humana es Whisper, de Open AI, el cual podemos utilizar desde Hugging Face
Tamaños y parámetros
El modelo está disponible en 5 tamaños. Los cuatro más pequeños se entrenan con datos en inglés o multilingües, mientras que el más grandes sólo multilingües:
| Tamaño | Parámetros |
|---|---|
| tiny | 39M |
| base | 74M |
| small | 244M |
| medium | 769M |
| large | 1550M |
| large-v2 | 1550M |
Whisper es un modelo codificador-decodificador basado en transformers, también conocido como modelo secuencia a secuencia. Se entrenó con 680.000 horas de datos de voz etiquetados y anotados mediante una supervisión débil a gran escala.
Los modelos se entrenaron con datos en inglés y con datos multilingües. Los modelos en inglés se entrenaron para la tarea de reconocimiento del habla. Los modelos multilingües se entrenaron tanto para el reconocimiento como para la traducción. Para el reconocimiento de voz, el modelo predice transcripciones en el mismo idioma que el audio. Para la traducción del habla, el modelo predice transcripciones a un idioma distinto al del audio.
Haciendo uso de Gradio, vamos a utilizar Whisper para transcribir un audio. El primer paso es instalar las librerías necesarias:
pip install torch torchaudio
Y a continuación, haciendo uso de un pipeline, vamos a cargar el modelo base y realizar la inferencia. La función transcribe toma un único parámetro un audio como un array NumPy del audio grabado por el usuario. El objeto pipeline lo espera en formato float32, así que primero lo convertimos y luego extraemos el texto transcrito.
import torch
from transformers import pipeline
import numpy as np
import gradio as gr
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base"
)
def transcribe(audio):
sr, y = audio
# Pasamos el array de muestras a tipo NumPy de 32 bits
y = y.astype(np.float32)
y /= np.max(np.abs(y))
return pipe({"sampling_rate": sr, "raw": y})["text"]
demo = gr.Interface(
transcribe,
gr.Audio(sources=["microphone"]),
"text",
)
demo.launch()
Para ponerlo en marcha, lanzamos el gradio:
gradio gradio-whisper.py
Obteniendo:
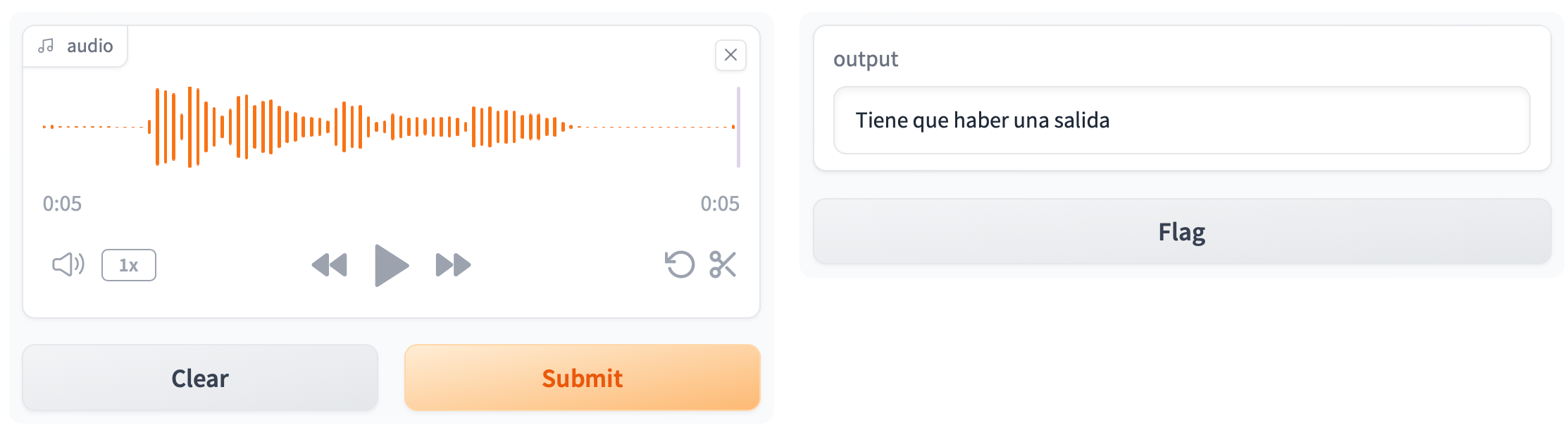
Podemos probar a cambiar el tamaño del modelo y, en el caso de tener GPU, podemos indicarle que la queremos utilizar mediante el parámetro device=0:
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-medium", device=0
)
Caso 2: Whisper en streaming¶
¿Y podemos hacer que en vez de esperar a tener todo un audio, se dedique a transcribir el texto conforme vayamos hablando?
Para que el caso anterior funcione en streaming, necesitamos:
- Indicar
streaming=Trueen el componente deAudio - Indicar
live=TrueenInterface - Añadir un estado en el interfaz para almacenar el audio grabado por el usuario, a modo de historial
A medida que se ejecuta la interfaz, se llama a la función transcribe, con un registro de todo el audio hablado previamente en stream, así como el nuevo trozo de audio como nuevo_fragmento, y devuelve el nuevo audio completo para que pueda ser almacenado de nuevo en el estado, y la nueva transcripción (*no es la solución más optima, ya que no hace falta volver la transcripción de todo el audio almacenado - probablemente, con los últimos 5 segundos sería suficiente):
from transformers import pipeline
import numpy as np
import gradio as gr
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base"
)
def transcribe(stream, nuevo_fragmento):
sr, y = nuevo_fragmento
y = y.astype(np.float32)
y /= np.max(np.abs(y))
if stream is not None:
stream = np.concatenate([stream, y])
else:
stream = y
return stream, pipe({"sampling_rate": sr, "raw": stream})["text"]
demo = gr.Interface(
transcribe,
["state", gr.Audio(sources=["microphone"], streaming=True)],
["state", "text"],
live=True,
)
demo.launch()
Podemos observar como en un primer momento, realiza una inferencia del idioma, y a continuación, conforme hablamos, va generando el texto:
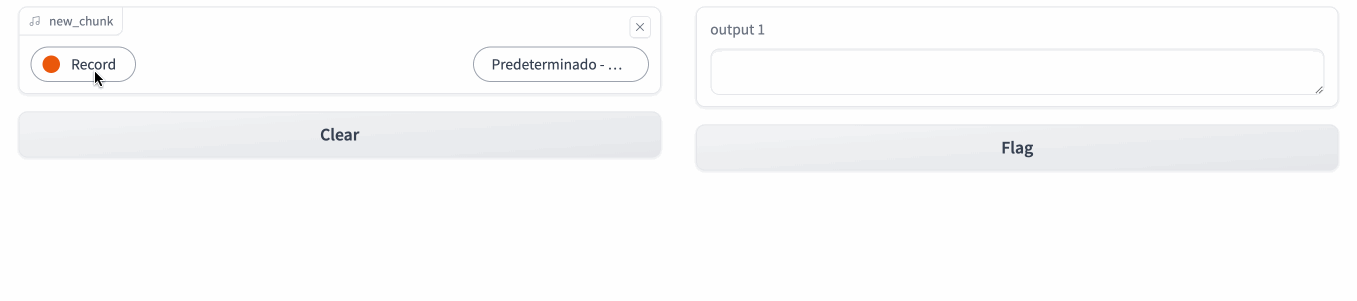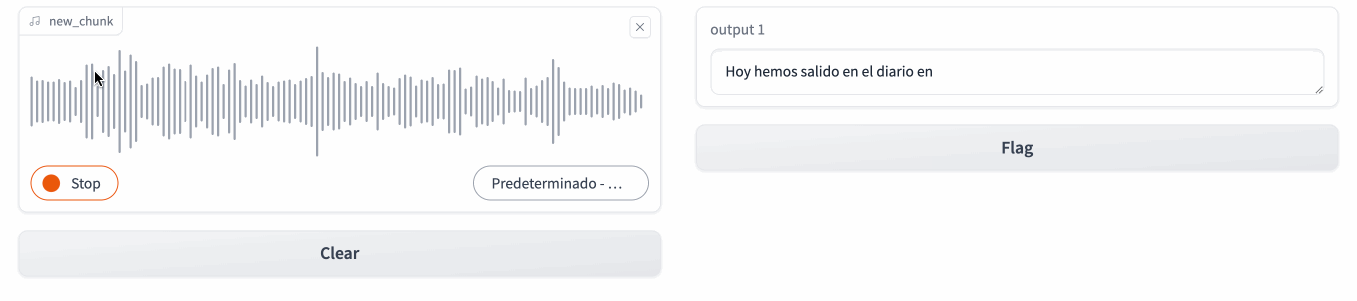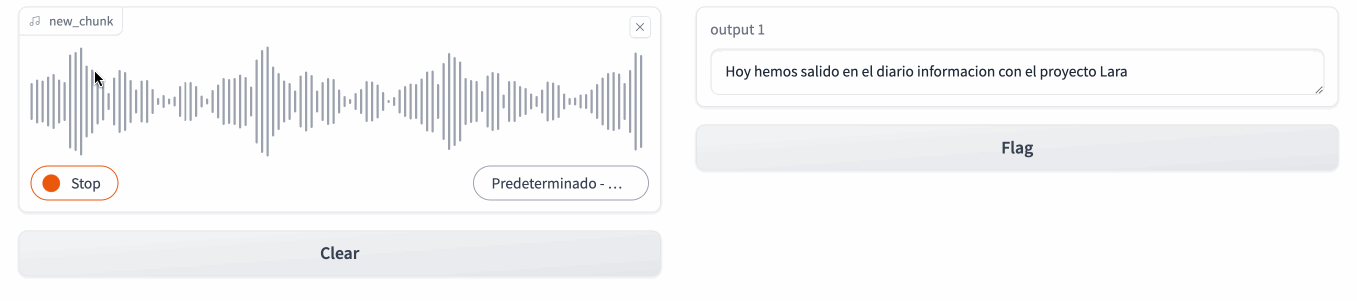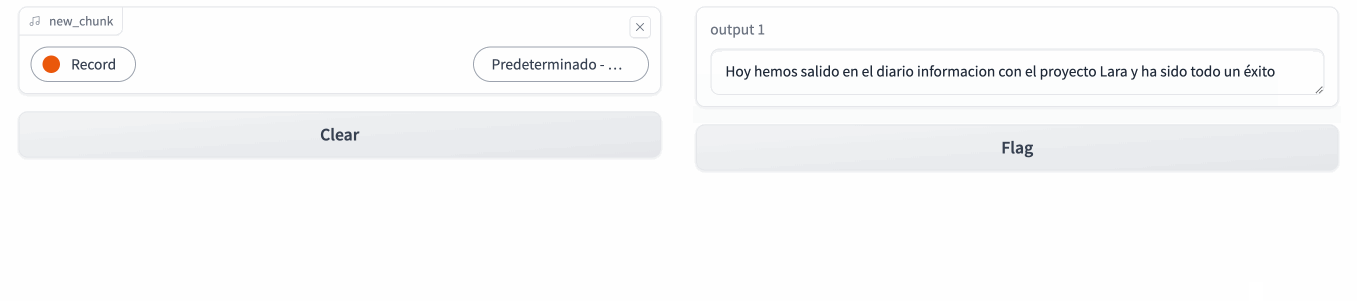
Caso 3: De Whisper a Bark¶
Para cerrar el circulo, vamos a realizar un ejemplo donde la salida del primer modelo, sea la entrada de un segundo modelo que genere un audio a partir del texto saliente de Whisper.
Caso 3a: TTS mediante Bark¶
Como TTS, vamos a utilizar el modelo Bark, el cual, además de ser multi-idioma, también permite incluir sonidos como música, sonrisas, tos, etc... Puedes probarlo en el siguiente Space.
A la hora de usarlo, tras inferir el texto, obtendremos el audio generado, tanto la tasa de muestreo como el propio audio:
from transformers import pipeline
import gradio as gr
pipe = pipeline("text-to-speech", model="suno/bark-small")
def tts(frase):
audio_generated = pipe(frase)
return audio_generated["sampling_rate"],audio_generated["audio"][0]
demo = gr.Interface(
tts,
inputs=gr.Text(label="Teclea el texto a pronunciar"),
outputs=gr.Audio(label="audio generado"),
title="De texto a voz",
)
demo.launch()
Así pues, ahora tras introducir un texto, por ejemplo Hola, ¿Cómo estás? ... ¡De lujo! [laughs], obtenemos un audio con la voz generada, donde se puede comprobar la entonación, la elipsis, y las risas finales:
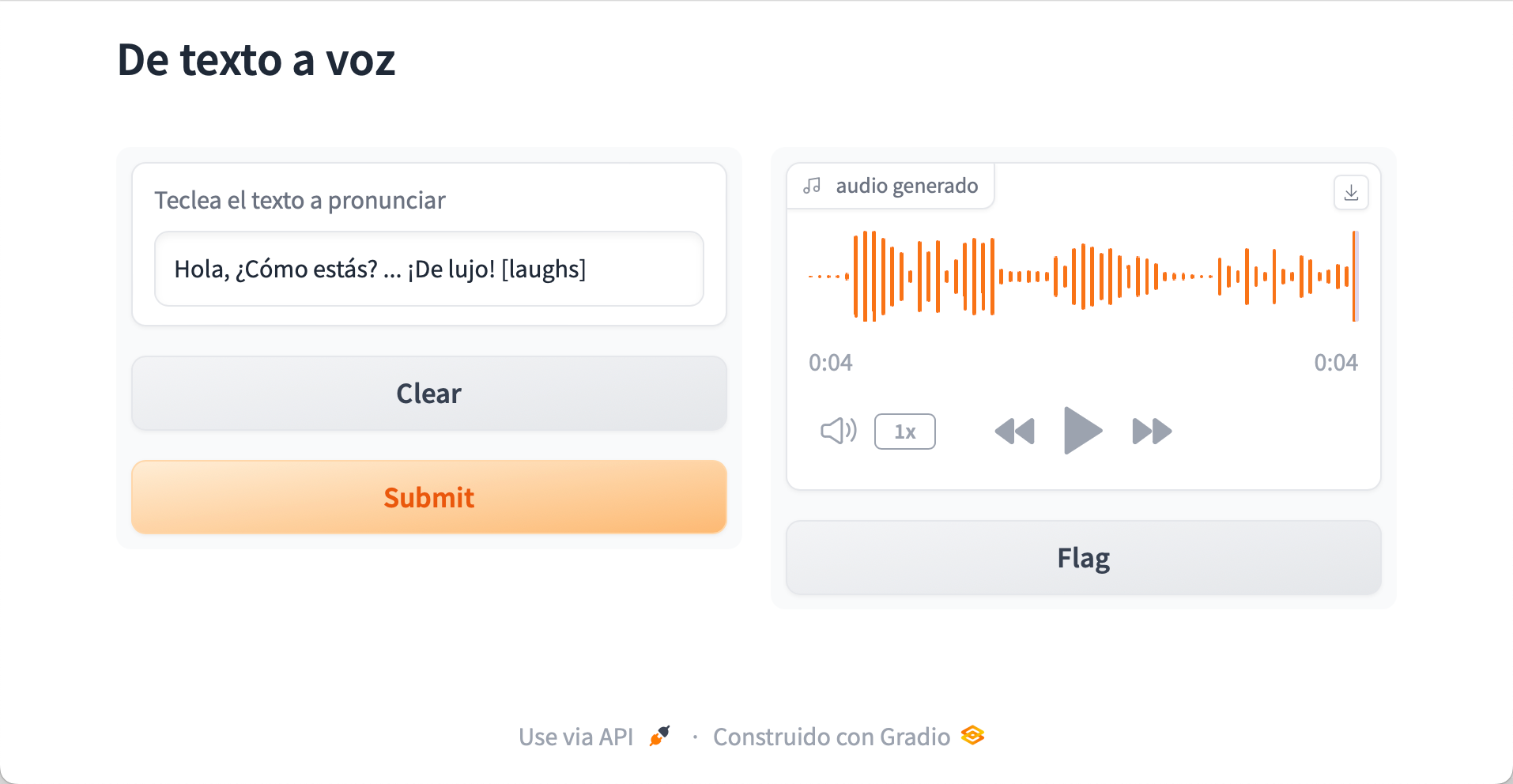
Configurando Bark¶
Si queremos configurar el tono de la voz, si es un hombre o una mujer, incluso "ayudarle" con el idioma a emplear, en vez de acceder via un Pipeline, accederemos mediante un AutoProcessor y el BarkModel:
from transformers import AutoProcessor, BarkModel
import gradio as gr
model_name="suno/bark-small"
processor = AutoProcessor.from_pretrained(model_name)
model = BarkModel.from_pretrained(model_name)
# Selección de voz - Valores: https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683
voice_preset = "v2/es_speaker_0"
def tts(frase):
# Obtenemos el procesador
inputs = processor(frase, voice_preset=voice_preset)
# Realiza la inferencia a partir de procesador y el modelo
audio_array = model.generate(**inputs, pad_token_id=100)
audio_array = audio_array.cpu().numpy().squeeze()
sample_rate = model.generation_config.sample_rate
return sample_rate,audio_array
demo = gr.Interface(
tts,
inputs=gr.Text(label="Teclea el texto a pronunciar"),
outputs=gr.Audio(label="audio generado"),
title="De texto a voz",
)
demo.launch()
Caso 3b: Uniendo Whisper con Bark¶
En nuestro caso, necesitamos crear dos pipelines, y en la salida hemos indicado dos componentes, y por lo tanto, la función transcribe devuelve una tupla de valor (el texto y el audio generado):
from transformers import pipeline
import numpy as np
import gradio as gr
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base")
tts = pipeline("text-to-speech", model="suno/bark-small")
def transcribe(audio):
sr, y = audio
y = y.astype(np.float32)
y /= np.max(np.abs(y))
text_generated = transcriber({"sampling_rate": sr, "raw": y})["text"]
audio_generated = tts(text_generated)
audio_returned = audio_generated["sampling_rate"],audio_generated["audio"][0]
return [text_generated, audio_returned]
demo = gr.Interface(
transcribe,
inputs=gr.Audio(sources=["microphone"]),
outputs=[
gr.Text(label="texto generado"),
gr.Audio(label="audio generado")
],
title="De audio a Whisper y TTS",
description="Transcribe el audio y luego sintetiza el texto en audio"
)
demo.launch()
Así pues, ahora tras la entrada del audio, se genera un texto y un nuevo audio:
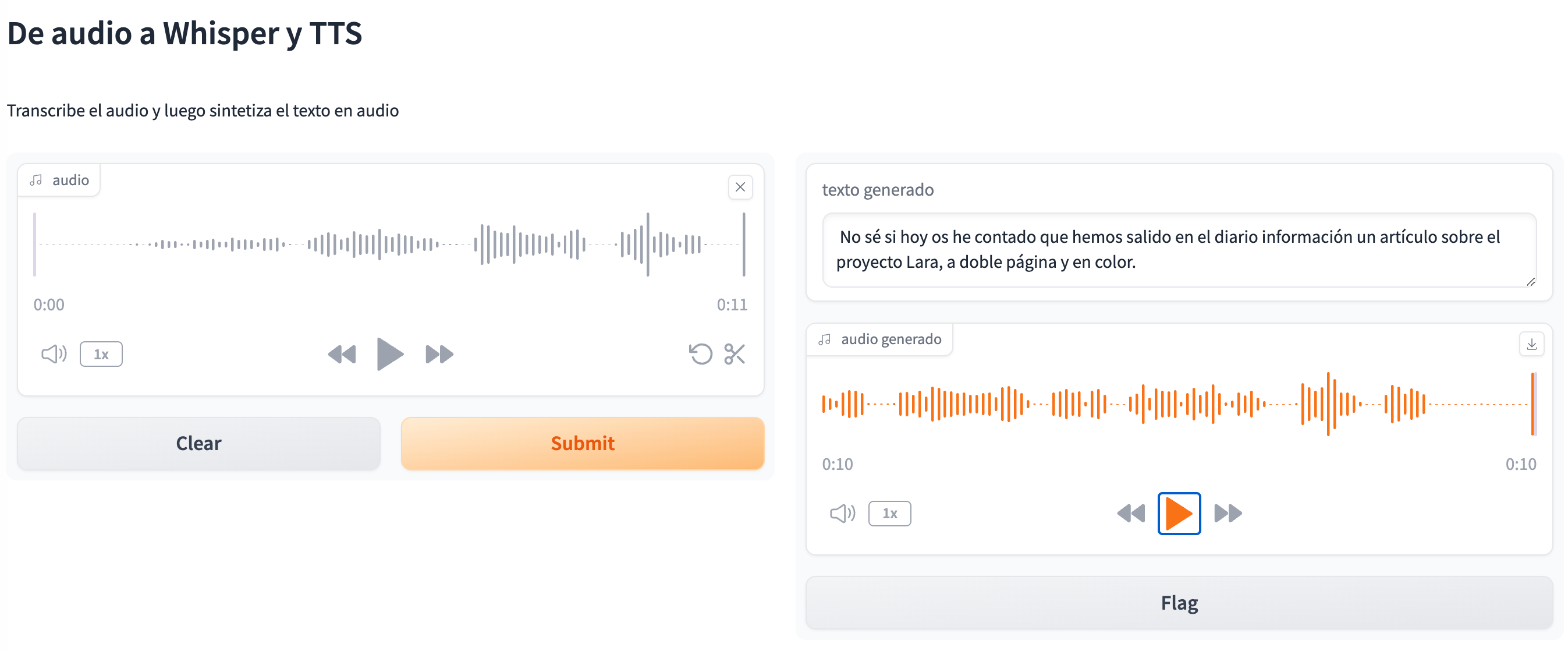
Referencias¶
Actividades¶
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2p) Realiza los tres casos de uso, ya sea en un entorno local mediante un entorno virtual como en espacios diferentes de Hugging Face. Adjunta el código fuente y capturas de pantalla donde en el texto de entrada o en el generado, aparezca tu nombre.
Error en streaming
Si no te funciona el caso de uso 2 de procesamiento en streaming, al menos adjunta una captura con el espacio creado, donde se vea el código fuente del Gradio.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2p) A partir del ejercicio de la sesión anterior donde creamos un traductor bidireccional, crea un nuevo Gradio que como entrada reciba un audio, lo pase a texto, lo traduzca, y a partir del texto traducido, genere un nuevo audio. Como salida, debe mostrar tanto el texto traducido como el audio generado.