Conectividad y catálogo
Changelog:
- Cluster docker con Spark, MySQL, MinIO y Kafka — Marzo 2026
- Cambio de Databricks Community Edition a Databricks Free Edition — Marzo 2026
- Añadimos FAQ — Marzo 2026
En esta sesión vamos a estudiar dos aspectos relacionados con el acceso a datos mediante Spark, por un lado, la conectividad con sistemas externos como bases de datos relacionales (MySQL/MariaDB) o no relacionales (MongoDB), y por otro lado, el catálogo de Spark SQL y su integración con el Hive Metastore para la gestión de metadatos, creación de bases de datos y tablas, y consultas a las mismas.
Spark JDBC¶
Para conectar desde Spark con una base de datos relacional (RDBMS) necesitamos:
- un driver JDBC compatible
- las propiedades de conexión a la base de datos.
En PySpark, el driver lo podemos añadir directamente a la carpeta jars disponible en $SPARK_HOME o en nuestro Docker (el cual ya está incluido), o a la hora de lanzar Spark utilizando la opción --jars <fichero1.jar>,<fichero2.jar> o --packages <groupId:artifactId:version>.
retail_db
Para esta sesión, vamos a utilizar la base de datos retail_db que tenemos configurada en la máquina virtual, y que contiene un conjunto de tablas con datos de clientes, productos, ventas, etc... Esta base de datos la hemos creado previamente en la sesión de Sqoop y se encuentra almacenada en MySQL.
En el caso de utilizar el entorno de Docker, no viene cargada previamente. Vamos a realizar los siguientes pasos:
-
Copiamos el script de creación de la base de datos en la carpeta
tmpdel contenedor de MySQL:docker cp create_db.sql mysql:/tmp/create_db.sql -
Nos conectamos al contenedor de Docker que contiene MySQL:
docker exec -it mysql bashY entramos a MySQL con el usuario
root(la contraseña la definimos en eldocker-composecomorootpass):mysql -u root -prootpass -
Una vez dentro de MySQL, creamos un usuario
iabdcon contraseñaiabd, sobre el cual crearemos la base de datosretail_dby le daremos permisos sobre ella.CREATE USER 'iabd'@'%' IDENTIFIED BY 'iabd'; CREATE DATABASE retail_db; GRANT ALL PRIVILEGES ON retail_db.* TO 'iabd'@'%';Cerramos la sesión de MySQL con CTRL+D.
-
Nos conectamos con el nuevo usuario, y cargamos los datos:
mysql -u iabd -piabd retail_db < /tmp/create_db.sql
El primer paso, al crear la SparkSession, es indicarle que queremos cargar los drivers:
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.master("spark://spark-master:7077")
.appName("spark-jdbc")
# --- Classpath ---
.config("spark.driver.extraClassPath", "/opt/spark/extra-jars/*")
.config("spark.executor.extraClassPath", "/opt/spark/extra-jars/*")
.getOrCreate()
)
El siguiente paso es configurar la conexión a la base de datos:
url_iabd = "jdbc:mysql://mysql-datos:3306/retail_db?useSSL=false&allowPublicKeyRetrieval=true"
propiedades = {
"driver": "com.mysql.cj.jdbc.Driver",
"user": "iabd",
"password": "iabd"
}
Leyendo datos¶
Para finalmente cargar los datos mediante el método read.jdbc:
df = spark.read.jdbc(url=url_iabd,\
table="customers",\
properties=propiedades)
Y sobre el dataframe, ya podemos obtener su esquema y realizar las transformaciones que necesitemos:
df.printSchema()
# root
# |-- customer_id: integer (nullable = true)
# |-- customer_fname: string (nullable = true)
# |-- customer_lname: string (nullable = true)
# |-- customer_email: string (nullable = true)
# |-- customer_password: string (nullable = true)
# |-- customer_street: string (nullable = true)
# |-- customer_city: string (nullable = true)
# |-- customer_state: string (nullable = true)
# |-- customer_zipcode: string (nullable = true)
df.show(2)
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# |customer_id|customer_fname|customer_lname|customer_email|customer_password| customer_street|customer_city|customer_state|customer_zipcode|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# | 1| Richard| Hernandez| XXXXXXXXX| XXXXXXXXX| 6303 Heather Plaza| Brownsville| TX| 78521|
# | 2| Mary| Barrett| XXXXXXXXX| XXXXXXXXX|9526 Noble Embers...| Littleton| CO| 80126|
# +-----------+--------------+--------------+--------------+-----------------+--------------------+-------------+--------------+----------------+
# only showing top 2 rows
Si necesitamos configurar en más detalle la forma de recoger los datos, es mejor acceder mediante el método format (cuidado con el nombre de la tabla que ahora utiliza el atributo dbtable):
df_format = spark.read.format("jdbc") \
.option("url", url_iabd) \
.option("dbtable", "customers") \
.option("user", "iabd") \
.option("password", "iabd") \
.load()
Un caso particular es cuando queremos asignarle a un dataframe el resultado de una consulta. Para ello, podemos indicarle en el parámetro query la consulta SQL con la información a recoger:
df_query = spark.read.format("jdbc") \
.option("url", url_iabd) \
.option("query", "(select customer_id, customer_fname, customer_lname from customers where customer_city='Las Vegas')") \
.option("user", "iabd") \
.option("password", "iabd") \
.load()
df_query.printSchema()
# root
# |-- customer_id: integer (nullable = true)
# |-- customer_fname: string (nullable = true)
# |-- customer_lname: string (nullable = true)
df_query.show(3)
# +-----------+--------------+--------------+
# |customer_id|customer_fname|customer_lname|
# +-----------+--------------+--------------+
# | 99| Betty| Munoz|
# | 204| Mary| Smith|
# | 384| Mildred| Cunningham|
# +-----------+--------------+--------------+
# only showing top 3 rows
Más opciones
Más información sobre todas las opciones disponibles en la documentación oficial.
Escribiendo datos¶
Si lo que queremos es almacenar el resultado en una base de datos, utilizaremos el método write.jdbc o write.format('jdbc') finalizando con save:
df.write.jdbc(url=url, \
table="<nueva_tabla>", \
properties=propiedades)
df.write.format("jdbc") \
.option("url", "<jdbc_url>") \
.option("dbtable", "<nueva_tabla>") \
.option("user", "<usuario>") \
.option("password", "<contraseña>") \
.save()
Por ejemplo, vamos a crear una copia del DataFrame de clientes con sólo tres columnas, y almacenaremos este DataFrame en una nueva tabla:
jdbcSelectDF = jdbcDF.select("customer_id", "customer_fname", "customer_lname")
jdbcSelectDF.show(3)
# +-----------+--------------+--------------+
# |customer_id|customer_fname|customer_lname|
# +-----------+--------------+--------------+
# | 1| Richard| Hernandez|
# | 2| Mary| Barrett|
# | 3| Ann| Smith|
# +-----------+--------------+--------------+
# only showing top 3 rows
jdbcSelectDF.count()
# 12435
jdbcSelectDF.write.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", url_iabd) \
.option("dbtable", "retail_db.clientes") \
.option("user", "iabd") \
.option("password", "iabd") \
.save()
Si accedemos a MySQL, podremos comprobar cómo se han insertado 12435 registros.
Si volvemos a realizar la persistencia de los datos, obtendremos un error porque la tabla ya existe. Para evitar este error, podemos añadir los datos a una tabla existente mediante el método mode con valor append, o para machacarlos con el valor overwrite:
jdbcSelectDF.write \
.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", url_iabd) \
.option("dbtable", "clientes2") \
.option("user", "iabd") \
.option("password", "iabd") \
.mode("append") \
.save()
overwrite borra la tabla
Mediante mode("overwrite"), la tabla se elimina y se vuelven a cargar los datos desde cero.
Si queremos que se vuelvan a cargar los datos pero no se cree de nuevo la tabla (porque no queremos que se borren las claves ni los índices existentes), hemos de añadirle la opción option("truncate", "true") para que limpie la tabla pero sin eliminarla ni volver a crearla.
Utilizando Databricks¶
Si trabajamos con Databricks y queremos recuperar o almacenar datos via JDBC, ya tenemos parte del trabajo hecho porque tiene los drivers instalados (pero utiliza los drivers de MariaDB en vez de MySQL).
Así pues, por ejemplo, para recuperar los datos de una base de datos remota (por ejemplo, la base de datos que creamos en la sesión de cloud con RDS) haríamos:
driver = "org.mariadb.jdbc.Driver"
database_host = "rds-retaildb.cwlnhhfuyb7j.us-east-1.rds.amazonaws.com"
database_port = "3306"
database_name = "retail_db"
table = "customers"
user = "admin"
password = "adminadmin"
driver = "org.mariadb.jdbc.Driver"
database_host = "ensembldb.ensembl.org"
database_port = "3306"
database_name = "homo_sapiens_core_110_38"
table = "gene"
user = "anonymous"
password = ""
Independientemente del origen de la base de datos, el proceso es el mismo, sólo tenemos que configurar correctamente los parámetros de conexión:
url = f"jdbc:mysql://{database_host}:{database_port}/{database_name}"
df_remoto = (spark.read
.format("jdbc")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.load()
)
Desde la versión 12 de Databricks, podemos utilizar directamente el formato mysql (o postgresql si fuera el caso):
df_remoto_mysql = (spark.read.format("mysql")
.option("dbtable", table)
.option("host", database_host)
.option("port", 3306)
.option("database", database_name)
.option("user", user)
.option("password", password)
.load()
)
Spark MongoDB¶
Para conectar desde Spark con MongoDB debemos utilizar el conector oficial y a la hora de leer o escribir datos indicar que el formato es mongodb:
df = spark.read.format("mongodb").load()
df.write.format("mongodb").mode("append").save()
Mongo Spark Connector¶
Si nos centramos en nuestra instalación de la máquina virtual, cuando lanzamos pyspark tenemos que indicarle que vamos a conectarnos a MongoDB mediante la opción packages:
pyspark --packages org.mongodb.spark:mongo-spark-connector_2.13:11.0.1
Instalación driver Java
Para que funcione correctamente, si partes desde una instalación propia de Spark, debes descargar el driver Java de MongoDB y colocarlo en la carpeta /$SPARK_HOME/jars
En cambio, si utilizamos nuestra instalación mediante Docker, únicamente al instanciar la sesión de Spark debemos indicarle que queremos cargar el conector de MongoDB:
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.master("spark://spark-master:7077")
.appName("spark-mongodb")
.config("spark.jars.packages", "org.mongodb.spark:mongo-spark-connector_2.13:11.0.1")
.getOrCreate()
)
MongoDB y Databricks
Antiguamente, en Databricks Community Edition, sí que podíamos añadir librerías via Maven. Como ahora se trabaja en modo serverless, dicha posibilidad ha desaparecido, y para añadir librerías externas, hay que hacerlo a través de la pestaña de librerías del cluster, añadiendo la librería vía Maven o subiendo el jar directamente. Si utilizas una cuenta de pago, puedes crear un cluster y configurarlo con el conector de MongoDB (org.mongodb.spark:mongo-spark-connector_2.13:10.4.1). Para ello, se recomienda leer el siguiente artículo: Interact with MongoDB on Databricks e instalar la librería adecuada.
Una vez recuperada la sesión de Spark, a la hora de leer datos le debemos indicar que el formato es mongodb y a continuación configurar tanto la connection.uri (si queremos acceder a la base de datos local usaremos como cadena de conexión mongodb://127.0.0.1:27017), como los parámetros databasey collection con la base de datos y colección a la que queremos acceder:
df = spark.read.format("mongodb") \
.option("connection.uri","mongodb+srv://<usuario>:<contraseña>@cluster0.dfaz5er.mongodb.net") \
.option("database","iabd") \
.option("collection","espias").load()
df.printSchema()
# root
# |-- _id: string (nullable = true)
# |-- edad: integer (nullable = true)
# |-- nombre: string (nullable = true)
df.show()
# +--------------------+----+---------------+
# | _id|edad| nombre|
# +--------------------+----+---------------+
# |63629b950e8c3f48d...| 0| James Bond 000|
# |63629b950e8c3f48d...| 1| James Bond 001|
# |63629b950e8c3f48d...| 2| James Bond 002|
# |63629b950e8c3f48d...| 3| James Bond 003|
# ...
MongoDB en local
Si quieres utilizar el MongoDB instalado en la máquina virtual (es la versión 4.4), debes arrancarlo mediante mongod y luego puedes arrancar un cliente mediante mongosh.
Del mismo modo, para escribir utilizamos el método write:
# Añadimos un atributo nuevo
from pyspark.sql.functions import col
df = df.withColumn("edad_doble", col("edad")*2)
df.write.format("mongodb").mode("append") \
.option("connection.uri","mongodb+srv://<usuario>:<contraseña>@cluster0.dfaz5er.mongodb.net") \
.option("database","iabd") \
.option("collection","espias_nuevo") \
.save()
Más información en la documentación oficial en https://www.mongodb.com/docs/spark-connector/current/
Spark SQL Catalog¶
Los catálogos de datos son un elemento esencial dentro de una organización, al ofrecer una vista de los datos disponibles, los cuales se pueden extender para describir su creación (persona, equipo u organización). Este catálogo lo gestionan los data stewards, un rol muy específico de los equipos big data que no solo se encargan de administrar el uso y los enfoques de los datos en la empresa, sino que tratan de asegurar la calidad de la información, el cumplimiento de las políticas de privacidad, la correcta comunicación entre los diferentes departamentos y la educación informática y tecnológica de los empleados relacionada con el mundo del dato.
Volviendo al catálogo de datos, el cual al final es un conjunto de metadatos, actúa como un contrato público que se establece durante la vida del dato, definiendo el cómo, cuándo y el porqué se consume un determinado dato, por ejemplo, indicando la disponibilidad de cada campo (por ejemplo, si tendrá un valor por defecto o nulo), así como reglas sobre la gobernanza y acceso de cada campo, etc...
El catálogo de datos por excelencia es el que forma parte de Apache Hive, y se conoce como el Hive Metastore, el cual ofrece una fuente veraz para describir la localización, codificación de los datos (texto, Parquet, ORC, ...), el esquema de las columnas, y estadísticas de las tablas almacenadas para facilitar su uso a todos los roles que interactúan con los datos (ingenieros de datos, analistas, ingenieros de ML, ...)
Almacenamiento del data warehouse
El catálogo guarda dos cosas distintas: los metadatos (en una base de datos relacional, normalmente MySQL) y los ficheros de datos (en un sistema de almacenamiento distribuido). En la máquina virtual los metadatos viven en MySQL y los ficheros en HDFS. En el entorno Docker los metadatos siguen viviendo en MySQL (contenedor mysql, base de datos hive_metastore), pero los ficheros viven en MinIO, un almacén compatible con S3 que sustituye a HDFS. Puedes consultar los ficheros desde la consola web de MinIO en http://localhost:9001.
Bases de datos¶
El catálogo se organiza, en su primer nivel, en bases de datos, la cuales agrupan y categorizan las tablas que utiliza nuestro equipo de trabajo, permitiendo identificar su propietario y restringir el acceso. Dentro del Hive Metastore, una base de datos funciona como un prefijo dentro de una ruta física de nuestro data warehouse, evitando colisiones entre nombres de tablas.
Una base de datos por equipo
Es conveniente que cada equipo de trabajo o unidad de negocio utilice sus propias bases de datos en Spark.
Configurando Spark con Hive¶
En el entorno Docker el catálogo está integrado de serie. Cuando levantamos los contenedores con docker compose up, ocurren dos cosas relevantes para el catálogo:
- El contenedor
iabd-mysql-metastorearranca con la base de datoshive_metastoreya creada y un usuariohive/hivepasscon permisos sobre ella. - El contenedor
iabd-hive-initejecutaschematool -initSchemasobre esa base de datos, dejando el esquema del Hive Metastore listo (todas las tablas tipoDBS,TBLS,COLUMNS_V2, etc.). Una vez termina, el contenedor finaliza (es un job de inicialización, no un servicio permanente).
A partir de ese momento, Spark se conecta directamente a MySQL mediante DataNucleus (sin necesidad de un servicio Hive Metastore en modo thrift), y todas las tablas gestionadas se almacenan en el bucket warehouse de MinIO.
Esta configuración la cargamos automáticamente al arrancar Spark mediante el archivo spark-defaults.conf que se monta como volumen en los contenedores spark-master, spark-worker-* y jupyter:
spark.sql.catalogImplementation hive
spark.sql.warehouse.dir s3a://warehouse/hive
spark.hadoop.javax.jdo.option.ConnectionURL jdbc:mysql://mysql-metastore:3306/hive_metastore?useSSL=false&allowPublicKeyRetrieval=true
...
Las propiedades del bloque Hive Metastore indican a Spark dónde está MySQL y con qué credenciales conectarse. Las del bloque MinIO / S3A permiten que Spark lea y escriba en MinIO utilizando el cliente S3A de Hadoop, tratándolo como si fuera un S3 de AWS pero contra el endpoint local.
JARs necesarios en ./jars
Para que esta configuración funcione, en la carpeta ./jars (montada como /opt/spark/extra-jars dentro de los contenedores) deben estar presentes:
mysql-connector-j-*.jar— para que DataNucleus pueda conectarse al MySQL del metastore.hadoop-aws-*.jaryaws-java-sdk-bundle-*.jar— para el cliente S3A que habla con MinIO.
Las versiones deben ser compatibles con la versión de Hadoop embebida en Spark 4.1.1.
¿Por qué no usamos HDFS en Docker?
Mantener un clúster de Hadoop (NameNode + DataNodes) consume bastante RAM. MinIO ofrece exactamente la misma API que S3, que hoy en día es el estándar de facto para almacenamiento en la nube, y se integra de forma nativa con Spark mediante el conector S3A. Es además la arquitectura habitual en entornos cloud modernos (lo que se conoce como separation of storage and compute).
En nuestra máquina virtual ya tenemos configurado el uso del Hive Metastore como catálogo de Spark. Para ello, hemos colocado dentro de $SPARK_HOME/conf una copia del archivo hive-site.xml con la información de acceso:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>iabd</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>iabd</value>
</property>
</configuration>
Y en el archivo de configuración de Spark, en $SPARK_HOME/conf/spark-defaults.conf hemos añadido dos propiedades para indicarle que vamos a utilizar la implementación del catálogo de Hive y que queremos que almacene las bases de datos que creemos en /opt/spark-3.3.1/warehouse/:
# The default location to read and write distributed SQL tables.
# This location can be located on the local file system and on any HDFS compatible file system.
spark.sql.warehouse.dir /opt/spark-3.3.1/warehouse/
# Defines the backing SQL catalog for the Spark session.
spark.sql.catalogImplementation hive
Si hubiésemos querido que las bases de datos que creemos desde Spark también lo hicieran dentro de HDFS (que sería lo recomendable, pero en nuestro caso implicaría tener que arrancar también los servicios de Hadoop al utilizar Spark, y por cuestiones de RAM hemos decidido desacoplarlo), deberíamos indicar la ruta:
spark.sql.warehouse.dir hdfs://iabd-virtualbox:9000/user/hive/warehouse/
Accediendo al catálogo¶
A partir de la SparkSession, podemos acceder al objeto catalog que contiene un conjunto de métodos para interactuar con los metadatos.
Podemos comprobar su uso mediante una consulta a show databases o accediendo al método listDatabases() del catalog:
spark.sql("show databases").show()
# +---------+
# |namespace|
# +---------+
# | default|
# | demo|
# +---------+
spark.catalog.listDatabases()
# [Database(name='default', catalog='spark_catalog', description='Default Hive database', locationUri='s3a://warehouse/hive'),
# Database(name='demo', catalog='spark_catalog', description='', locationUri='s3a://warehouse/hive/demo.db')]
spark.sql("show databases").show()
# +---------+
# |namespace|
# +---------+
# | default|
# | iabd|
# +---------+
spark.catalog.listDatabases()
# [Database(name='default', description='Default Hive database', locationUri='hdfs://iabd-virtualbox:9000/user/hive/warehouse'),
# Database(name='iabd', description='', locationUri='hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db')]
De manera que obtenemos las bases de datos que está utilizando actualmente (como puedes observar, son las bases de datos que hemos creado previamente en la sesión de Hive).
Si queremos ver cual es nuestra base de datos activa, utilizaremos el método currentDatabase:
spark.catalog.currentDatabase()
# 'default'
Creando una base de datos¶
De la misma manera que hemos creado sentencias SQL en Spark, podemos generar sentencias DDL y DML. Así pues, para crear una base de datos, hemos de hacer uso del API SQL y utilizar la sentencia DDL de CREATE DATABASE. Por ejemplo, vamos a crear una base de datos s8a donde colocaremos las tablas que crearemos en esta sesión:
spark.sql("create database if not exists s8a")
Una vez creada, la activamos mediante use:
spark.sql("use s8a")
Si comprobamos la ruta, podemos ver cómo la ha creado en el almacén de Spark que hemos indicado previamente en la configuración:
spark.catalog.listDatabases()
# [Database(name='default', catalog='spark_catalog', description='Default Hive database', locationUri='s3a://warehouse/hive'),
# Database(name='demo', catalog='spark_catalog', description='', locationUri='s3a://warehouse/hive/demo.db'),
# Database(name='s8a', catalog='spark_catalog', description='', locationUri='s3a://warehouse/hive/s8a.db')]
spark.catalog.listDatabases()
# [Database(name='default', description='Default Hive database', locationUri='hdfs://iabd-virtualbox:9000/user/hive/warehouse'),
# Database(name='iabd', description='', locationUri='hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db'),
# Database(name='s8a', description='', locationUri='file:/opt/spark-3.3.1/warehouse/s8a.db')]
Trabajando con tablas¶
Vamos a suponer que tenemos el DataFrame de clientes que hemos cargado previamente desde JDBC, y creamos una vista sobre él:
jdbcDF = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://mysql-datos:3306/retail_db") \
.option("dbtable", "customers") \
.option("user", "iabd") \
.option("password", "iabd") \
.load()
jdbcDF.createOrReplaceTempView("clientes")
Si comprobamos las tablas de nuestra base de datos mediante el método listTables, aparecerá la vista como una tabla temporal (TEMPORARY), lo que significa que sólo está disponible en memoria:
spark.catalog.listTables()
# [Table(name='clientes', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
Al ser temporal, al detener Spark, dicha tabla desaparecerá. Si queremos que la tabla esté disponible en nuestro data lake y que podamos consultarla desde el catálogo del Hive Metastore, necesitamos persistirla.
Persistiendo tablas¶
Cuando tenemos un DataFrame lo podemos persistir como una tabla, lo que en terminología de Hive sería una tabla interna o gestionada, mediante saveAsTable:
jdbcDF.write.mode("errorIfExists").saveAsTable("clientes_t") # (1)!
- Aunque es el modo por defecto, lo indicamos explícitamente para hacer visible en el código que no queremos sobrescribir datos. Si la tabla ya existiera, se lanzaría un error.
Si volvemos a comprobar las tablas, podemos ver como la nueva tabla ahora forma parte de la base de datos s8a y que su tipo es MANAGED:
spark.catalog.listTables()
# [Table(name='clientes_t', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='MANAGED', isTemporary=False),
# Table(name='clientes', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
Por último, si queremos consultar la estructura de una tabla, podemos utilizar el método del catálogo listColumns:
spark.catalog.listColumns("clientes_t")
# [Column(name='customer_id', description=None, dataType='int', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_fname', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_lname', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_email', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_password', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_street', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_city', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_state', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_zipcode', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False)]
Por último, podemos configurar diferentes opciones a la hora de persistir las tablas. Por ejemplo, si queremos persistir la tabla en formato JSON sobrescribiendo los datos hemos de indicarlo con format('json') y mode('overwrite'):
jdbcDF.write.format("json").mode("overwrite").saveAsTable("clientes_j")
Por defecto en formato Parquet
Por defecto, al persistir una tabla, se realiza en formato Parquet y comprimido mediante Snappy.
Tablas externas¶
Si queremos crear una tabla no gestionada, también conocida como tabla externa, la cual se almacena como tablas en Hive, necesitamos indicar la ruta de los datos en el momento de la creación mediante la claúsula LOCATION.
Primero vamos a almacenar los datos de clientes que tenemos en un archivo CSV (el cual ya utilizamos en la sesión de AWS Athena) en el bucket raw-data/customers de MinIO. Para ello, subiremos el archivo customers_small.csv a la ruta s3a://raw-data/customers/ utilizando la consola web de MinIO (disponible en http://localhost:9001/).
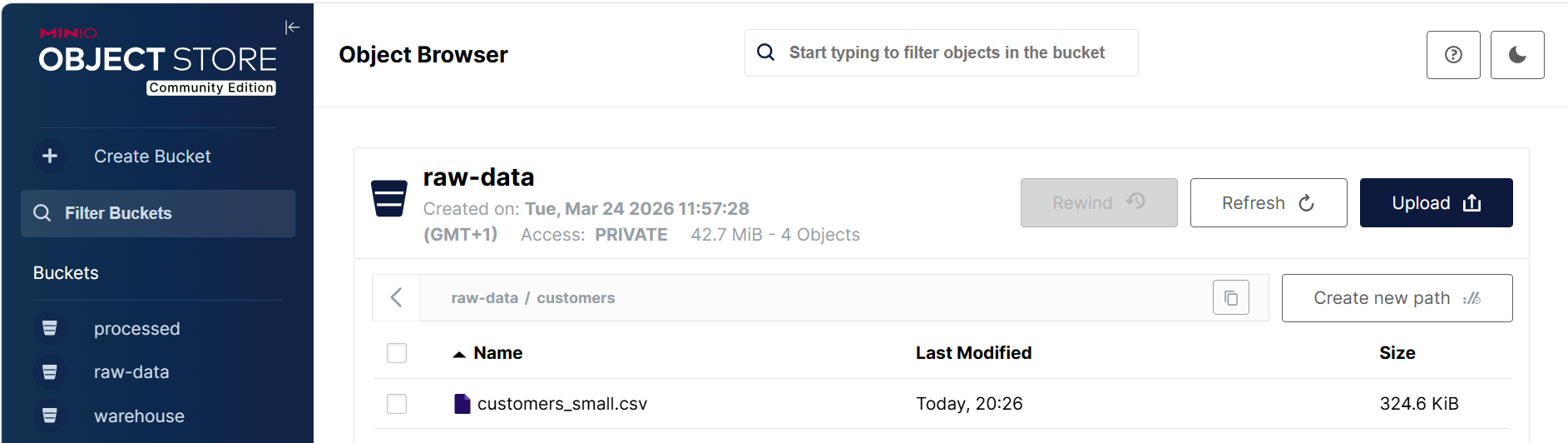
A continuación, creamos la tabla externa indicando la ruta del bucket:
spark.sql("""
CREATE EXTERNAL TABLE IF NOT EXISTS clientes_e
(
custId INT,
fName STRING,
lName STRING,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3a://raw-data/customers'""")
Vamos a crear una tabla de clientes con los datos que tenemos almacenados en HDFS que cargamos mediante Sqoop en la sesión de Hive en la ruta /user/iabd/hive/customer.
Así pues, nuestra sentencia DDL sería:
spark.sql("""
CREATE EXTERNAL TABLE IF NOT EXISTS clientes_e
(
custId INT,
fName STRING,
lName STRING,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 'hdfs://iabd-virtualbox:9000/user/iabd/hive/customer'""")
Si volvemos a comprobar las tablas, veremos que la ha marcado EXTERNAL:
spark.catalog.listTables()
# [Table(name='clientes_e', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='EXTERNAL', isTemporary=False),
# Table(name='clientes_j', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='MANAGED', isTemporary=False),
# Table(name='clientes_t', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='MANAGED', isTemporary=False),
# Table(name='clientes', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
Y si realizamos una consulta, obtenemos los mismos datos que hay almacenados en HDFS/MinIO:
spark.sql("select * from clientes_e limit 3").show();
# +------+-------+---------+-----------+
# |custId| fName| lName| city|
# +------+-------+---------+-----------+
# | 1|Richard|Hernandez|Brownsville|
# | 2| Mary| Barrett| Littleton|
# | 3| Ann| Smith| Caguas|
# +------+-------+---------+-----------+
También podemos crear una tabla externa indicando la opción path, de manera que nos creará los datos en HDFS (recuerda que por defecto almacena los datos en formato Parquet):
jdbcDF.write.option("path", "s3a://processed/customers_jdbc").saveAsTable("clientes_ext")
De manera, que si accedemos a la consola web de MinIO y nos vamos a la ruta processed/customers_jdbc, podremos ver los datos que se han almacenado en formato Parquet:
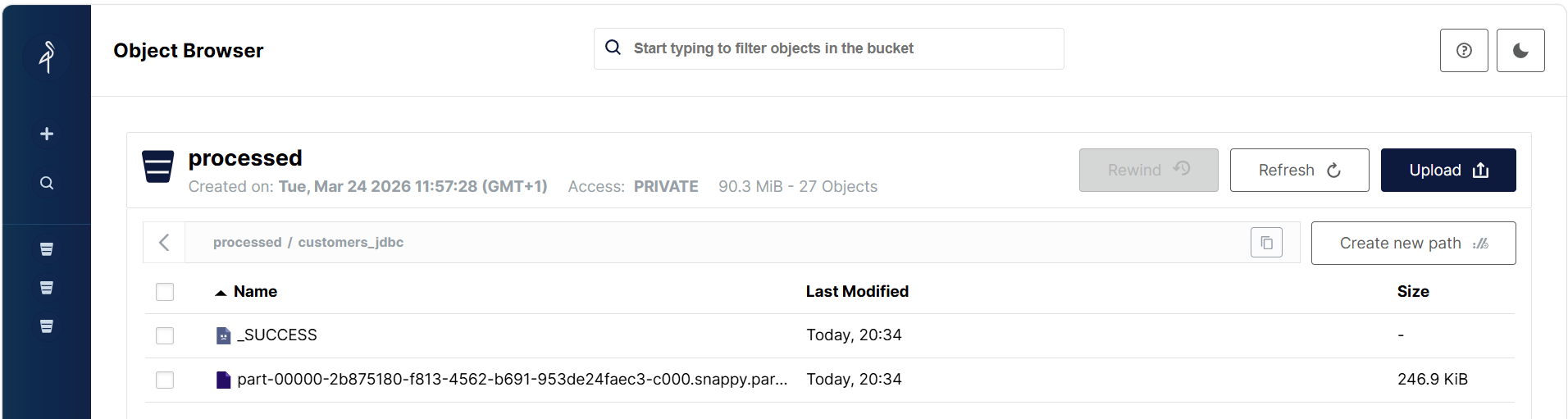
jdbcDF.write.option("path", "hdfs://iabd-virtualbox:9000/user/iabd/spark/customer").saveAsTable("clientes_ext")
Cargando tablas¶
Una vez las tablas ya están persistidas, en cualquier momento podemos recuperarlas y asociarlas a un nuevo DataFrame mediante el método table:
df_clientes = spark.table("clientes_t")
df_clientes.printSchema()
# root
# |-- customer_id: integer (nullable = true)
# |-- customer_fname: string (nullable = true)
# |-- customer_lname: string (nullable = true)
# |-- customer_email: string (nullable = true)
# |-- customer_password: string (nullable = true)
# |-- customer_street: string (nullable = true)
# |-- customer_city: string (nullable = true)
# |-- customer_state: string (nullable = true)
# |-- customer_zipcode: string (nullable = true)
Cacheando tablas¶
En la sesión anterior estudiamos cómo persistir los DataFrames y vimos como también podemos persistir una vista, incluso cómo comprobar su estado en el Spark UI.
Para cachear tablas, usaremos el método cacheTable:
spark.catalog.cacheTable("clientes_t")
Si por el contrario, queremos liberar la memoria de una tabla que ha sido cacheada, usaremos el método uncacheTable:
spark.catalog.uncacheTable("clientes_t")
Si queremos limpiar toda la caché, disponemos del método clearCache:
spark.catalog.clearCache()
Refrescando la caché
Un caso muy común al trabajar con datos cacheados es que desde una aplicación externa se actualicen los datos y la caché contenga una copia obsoleta.
Para refrescar los datos, podemos utilizar el método refreshTable:
spark.catalog.refreshTable("clientes_t")
Un punto a destacar es que si una aplicación Spark sobrescribe una tabla que habíamos cacheado, Spark directamente invalidará la caché local, de manera que no será necesario que en nuestra lógica de aplicación refresquemos las tablas de forma explícita.
Sólo lo haremos si la sobrescritura de los datos la realiza una aplicación ajena a Spark sobre una tabla externa.
Borrando tablas¶
Si dejamos de utilizar una tabla y la queremos eliminar del Metastore, podemos realizarlo directamente mediante su sentencia de DDL DROP TABLE:
spark.sql("DROP TABLE IF EXISTS clientes_j")
Spark y el Metastore¶
Para comprender cómo se almacenan los metadatos de las bases de datos y las tablas gestionadas es importante conocer donde se almacenan los metadatos.
Si abrimos un terminal y nos conectamos al contenedor del Hive Metastore (por ejemplo, mediante docker exec -it iabd-mysql-metastore bash), podemos ver todas las tablas que utiliza el Hive Metastore:
$ mysql -uhive -phivepass
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 306
Server version: 8.0.45 MySQL Community Server - GPL
Copyright (c) 2000, 2026, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use hive_metastore;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
mysql> show tables;
+-------------------------------+
| Tables_in_hive_metastore |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_METRICS_CACHE |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| CTLGS |
| DATABASE_PARAMS |
| DATACONNECTORS |
| DATACONNECTOR_PARAMS |
| DBS |
| ... |
| WRITE_SET |
+-------------------------------+
83 rows in set (0.00 sec)
Si abrimos un terminal y accedemos al servidor de MySQL de nuestra máquina virtual, podemos ver todas las tablas que utiliza el Hive Metastore:
$ mysql -uiabd -piabd
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 143
Server version: 10.3.37-MariaDB-0ubuntu0.20.04.1 Ubuntu 20.04
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> use hive
Database changed
MariaDB [hive]> show tables;
+-------------------------------+
| Tables_in_hive |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| CTLGS |
| DATABASE_PARAMS |
| DBS |
...
| WRITE_SET |
+-------------------------------+
74 rows in set (0,000 sec)
MariaDB [hive]>
De todas las tablas, nos vamos a centrar en la tabla DBS, que almacena las bases de datos creadas, donde podemos observar, además de su nombre, la localización de cada base de datos y su propietario:
mysql> select * from DBS;
# +-------+-----------------------+------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
# | DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME | CREATE_TIME | DB_MANAGED_LOCATION_URI | TYPE | DATACONNECTOR_NAME | REMOTE_DBNAME |
# +-------+-----------------------+------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
# | 1 | Default Hive database | s3a://warehouse/hive | default | public | ROLE | hive | NULL | NULL | NATIVE | NULL | NULL |
# | 2 | | s3a://warehouse/hive/demo.db | demo | spark | USER | hive | NULL | NULL | NATIVE | NULL | NULL |
# | 6 | | s3a://warehouse/hive/s8a.db | s8a | spark | USER | hive | NULL | NULL | NATIVE | NULL | NULL |
# +-------+-----------------------+------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
# 3 rows in set (0.00 sec)
MariaDB [hive]> select * from DBS;
# +-------+-----------------------+---------------------------------------------------------+---------+------------+------------+-----------+
# | DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME |
# +-------+-----------------------+---------------------------------------------------------+---------+------------+------------+-----------+
# | 1 | Default Hive database | hdfs://iabd-virtualbox:9000/user/hive/warehouse | default | public | ROLE | hive |
# | 21 | NULL | hdfs://iabd-virtualbox:9000/user/hive/warehouse/iabd.db | iabd | iabd | USER | hive |
# | 31 | | file:/opt/spark-3.3.1/warehouse/s8a.db | s8a | iabd | USER | hive |
# +-------+-----------------------+---------------------------------------------------------+---------+------------+------------+-----------+
# 3 rows in set (0,001 sec)
Si nos quedamos con el identificador de cada base de datos (DB_ID), el cual actúa como clave primaria, vamos a poder consultar las tablas de una determinada base de datos consultando la tabla TBLS:
mysql> select * from TBLS where DB_ID = 6;
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+--------------+----------------+--------------------+--------------------+----------------------------------------+----------+
# | TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED | WRITE_ID |
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+--------------+----------------+--------------------+--------------------+----------------------------------------+----------+
# | 6 | 1777658469 | 6 | 0 | spark | NULL | 0 | 6 | clientes_t | MANAGED_TABLE | NULL | NULL | 0x00 | 0 |
# | 7 | 1777658556 | 6 | 0 | spark | NULL | 0 | 7 | clientes_j | MANAGED_TABLE | NULL | NULL | 0x00 | 0 |
# | 10 | 1777660300 | 6 | 0 | spark | NULL | 0 | 10 | clientes_e | EXTERNAL_TABLE | NULL | NULL | 0x00 | 0 |
# | 12 | 1777660485 | 6 | 0 | spark | NULL | 0 | 12 | clientes_ext | EXTERNAL_TABLE | NULL | NULL | 0x00 | 0 |
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+--------------+----------------+--------------------+--------------------+----------------------------------------+----------+
# 4 rows in set (0.00 sec)
MariaDB [hive]> select * from TBLS where DB_ID = 31;
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+------------+---------------+--------------------+--------------------+--------------------+
# | TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED |
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+------------+---------------+--------------------+--------------------+--------------------+
# | 61 | 1673256646 | 31 | 0 | iabd | NULL | 0 | 111 | clientes_t | MANAGED_TABLE | NULL | NULL | |
# | 62 | 1673256649 | 31 | 0 | iabd | NULL | 0 | 112 | clientes_j | MANAGED_TABLE | NULL | NULL | |
# +--------+-------------+-------+------------------+-------+------------+-----------+-------+------------+---------------+--------------------+--------------------+--------------------+
Y repetimos el proceso, ahora nos quedamos con el identificador de la tabla, y consultamos la tabla TABLE_PARAMS, donde podemos ver donde se almacena toda la información que utiliza Spark para leer las tablas de forma automática:
mysql> select * from TABLE_PARAMS where TBL_ID = 7;
# +--------+----------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# | TBL_ID | PARAM_KEY | PARAM_VALUE |
# +--------+----------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# | 7 | numFiles | 1 |
# | 7 | spark.sql.create.version | 4.1.1 |
# | 7 | spark.sql.sources.provider | json |
# | 7 | spark.sql.sources.schema | {"type":"struct","fields":[{"name":"customer_id","type":"integer","nullable":true,"metadata":{"isSigned":true,"scale":0,"isTimestampNTZ":false,"jdbcClientType":"INT"}},{"name":"customer_fname","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_lname","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_email","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_password","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_street","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(255)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_city","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_state","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}},{"name":"customer_zipcode","type":"string","nullable":true,"metadata":{"isSigned":false,"scale":0,"__CHAR_VARCHAR_TYPE_STRING":"varchar(45)","isTimestampNTZ":false,"jdbcClientType":"VARCHAR"}}]} |
# | 7 | totalSize | 3104780 |
# | 7 | transient_lastDdlTime | 1777658556 |
# +--------+----------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# 6 rows in set (0.00 sec)
MariaDB [hive]> select * from TABLE_PARAMS where TBL_ID = 61;
# +--------+----------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# | TBL_ID | PARAM_KEY | PARAM_VALUE |
# +--------+----------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# | 61 | numFiles | 1 |
# | 61 | spark.sql.create.version | 3.3.1 |
# | 61 | spark.sql.sources.provider | parquet |
# | 61 | spark.sql.sources.schema | {"type":"struct","fields":[{"name":"customer_id","type":"integer","nullable":true,"metadata":{"scale":0}},{"name":"customer_fname","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_lname","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_email","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_password","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_street","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_city","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_state","type":"string","nullable":true,"metadata":{"scale":0}},{"name":"customer_zipcode","type":"string","nullable":true,"metadata":{"scale":0}}]} |
# | 61 | totalSize | 251792 |
# | 61 | transient_lastDdlTime | 1673256646 |
# +--------+----------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
# 6 rows in set (0,001 sec)
Facilitando el descubrimiento de datos¶
Una vez sabemos cómo se almacenan los metadatos, podemos consultarlos para descubrir los datos, proceso que se conoce como data discovery.
Volviendo a nuestros cuadernos Jupyter, si nos centramos en la base de datos s8a y consultamos sus tablas mediante listTables, observamos que no tienen descripción, lo cual a la hora de poder descubrir datos no es nada positivo:
spark.sql("use s8a")
spark.catalog.listTables()
# [Table(name='clientes_e', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='EXTERNAL', isTemporary=False),
# ...
# Table(name='clientes', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
Para poder añadirle la descripción a las tablas, mediante DDL modificamos las propiedades de la tabla, en concreto la propiedad comment:
spark.sql(
"""
ALTER TABLE clientes_t
SET TBLPROPERTIES (
'comment' = 'Datos de clientes obtenidos desde retail_db.customers',
'active' = 'true'
)
""")
Si volvemos a consultar las tablas, ya podemos ver su descripción:
spark.catalog.listTables()
# [Table(name='clientes_e', catalog='spark_catalog', namespace=['s8a'], description=None, tableType='EXTERNAL', isTemporary=False),
# ...
# Table(name='clientes_t', catalog='spark_catalog', namespace=['s8a'], description='Datos de clientes obtenidos desde retail_db.customers', tableType='MANAGED', isTemporary=False),
# Table(name='clientes', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
Vamos a comprobar ahora las columnas de las tablas mediante listColumns:
spark.catalog.listColumns("clientes_t")
# [Column(name='customer_id', description=None, dataType='int', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_fname', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_lname', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# ...
# Column(name='customer_zipcode', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False)]
Igual que antes, tenemos la descripción en blanco (valor None), por lo que mediante DML modificamos el comentario de cada columna:
spark.sql("ALTER TABLE clientes_t ALTER COLUMN customer_id COMMENT 'Identificador unívoco (PK) del cliente'")
spark.sql("ALTER TABLE clientes_t ALTER COLUMN customer_fname COMMENT 'Nombre del cliente'");
Y comprobamos como han cambiado ambos campos:
spark.catalog.listColumns("clientes_t")
# [Column(name='customer_id', description='Identificador unívoco (PK) del cliente', dataType='int', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_fname', description='Nombre del cliente', dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# Column(name='customer_lname', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False),
# ...
# Column(name='customer_zipcode', description=None, dataType='string', nullable=True, isPartition=False, isBucket=False, isCluster=False)]
FAQ¶
A continuación se recogen preguntas habituales sobre los conceptos de esta sesión que suelen realizarse en entrevistas de trabajo para puestos de ingeniería o ciencia de datos.
Despliega cada pregunta para ver una respuesta orientativa; no hay una única respuesta correcta, pero sí aspectos clave que conviene mencionar.
¿Cuáles son los modos de escritura (SaveMode) disponibles en Spark?
Al persistir un DataFrame con .write, se puede especificar el comportamiento si ya existen datos en el destino:
| Modo | Comportamiento |
|---|---|
overwrite |
Borra los datos existentes y escribe los nuevos. |
append |
Añade los datos nuevos sin borrar los existentes. |
ignore |
Si ya existen datos, no hace nada (no lanza error). |
error / errorIfExists |
Lanza un error si ya existen datos. Es el comportamiento por defecto. |
df.write.mode("overwrite").parquet("ruta/destino")
¿Cuál es la diferencia entre una tabla gestionada (managed) y una tabla externa (external)?
En una tabla gestionada (managed), Spark controla tanto los metadatos (en el Metastore) como los ficheros físicos. Al hacer DROP TABLE, se eliminan también los datos del disco. En una tabla externa (external), Spark solo gestiona los metadatos; los datos residen en una ruta definida por el usuario. Al hacer DROP TABLE, solo se eliminan los metadatos, los datos permanecen intactos. Las tablas externas son más seguras en producción.
¿Qué es el Metastore de Hive y qué papel juega en Spark?
El Metastore de Hive es un repositorio central de metadatos (esquemas, ubicaciones de tablas, definiciones de particiones) que Spark puede usar para persistir la definición de tablas entre sesiones. Sin él, las tablas creadas en Spark solo existen durante la vida de la SparkSession actual. Configurando Spark con soporte Hive, las tablas son permanentes y accesibles desde otras herramientas del ecosistema como Presto, Trino o Hive.
¿Cuándo es más eficiente leer desde JDBC con particionado?
Por defecto, Spark lee una tabla JDBC con un único hilo (una sola partición), lo que no aprovecha el paralelismo del clúster. Para paralelizar la lectura, se deben especificar los parámetros partitionColumn, lowerBound, upperBound y numPartitions. Esto hace que Spark divida la lectura en numPartitions rangos sobre la columna indicada, lanzando una consulta por rango en paralelo.
df = spark.read.jdbc(
url=url, table="ventas",
column="id", lowerBound=1, upperBound=1000000, numPartitions=10,
properties=props
)
¿Qué diferencia hay entre una vista temporal y una tabla persistida en el catálogo?
Una vista temporal solo existe en memoria durante la sesión actual (createOrReplaceTempView). Una tabla persistida en el catálogo (mediante df.write.saveAsTable("nombre") o CREATE TABLE) queda registrada en el Metastore y es accesible en futuras sesiones o desde otras aplicaciones Spark. Las tablas del catálogo también pueden estar particionadas a nivel de Metastore, lo que permite a Spark hacer partition pruning sin leer todos los datos.
Referencias¶
Actividades¶
(RASBD.1 / CESBD.1b y CESBD.1d) En las siguientes actividades vamos a familiarizarnos con el uso del API de Spark JDBC y el acceso al catálogo.
- (1p) Vamos a repetir una actividad que realizamos durante la sesión de Hive. Para ello, se pide recuperar desde la base de datos
retail_dblas tablascustomersyordersen dos dataframes tal como hemos hecho en el apartado Leyendo Datos, y a continuación, realizar un join de manera que contenga la información de cada pedido y la ciudad del cliente. - (1p) Conecta con MongoDB y persiste el resultado del join en una colección llamada
pedidos_ciudad. Conéctate a MongoDB desdemongoshy comprueba que se han almacenado los datos. -
(2p) Además, sobre el dataframe anterior, y mediante el Spark Catalog, en una base de datos llamada
iabd(créala si no existe), crea una tabla gestionada en el catálogo cuyo nombre seapedidos_ciudad, y añade comentarios tanto a la tabla como a sus columnas (al menos las más importantes). Ejecuta las sentencias que permita recuperar tanto los comentarios de las tablas como de las columnas de la tablapedidos_ciudad. -
(opcional) Conéctate a MySQL y recupera la información de las tablas creadas en estos ejercicios y sus parámetros.