Elastic Map Reduce¶
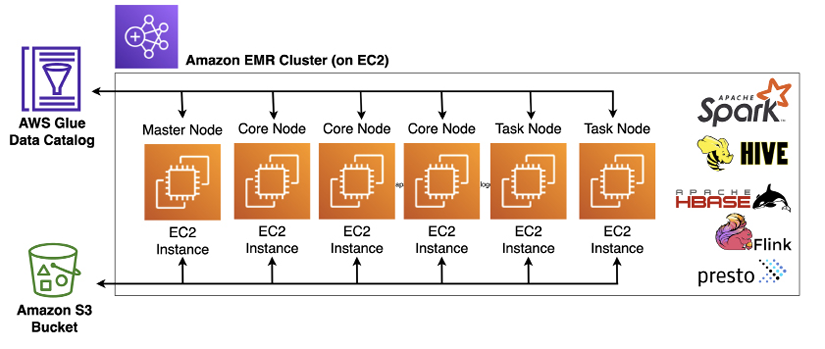
Amazon EMR es una plataforma administrada para ejecutar los servicios del ecosistema Hadoop como Apache Spark, Apache Hive, Apache Hudi, Apache HBase, Presto, Pig y otras. Amazon EMR se encarga de las complejidades de implementar estas herramientas y administrar los recursos informáticos en clúster subyacentes.
Así pues, EMR permite crear clusters para realizar analíticas sobre datos y cargas de BI, así como transformar y mover grandes volúmenes de datos, tanto cargando como almacenando datos en servicios de AWS como S3 y DynamoDB.
Del mismo modo que muchos otros servicios de AWS, Amazon EMR se puede ejecutar en modo aprovisionado (indicando los tipos de instancias a emplear) o en modo serverless.
Para ello, utiliza una distribución propia de AWS que permite seleccionar los componentes que van a lanzarse en el clúster (Hive, Spark, Presto, etc...)
Ofrece elasticidad sobre el cluster, pudiendo modificar dinámicamente el dimensionamiento del mismo según necesidades, tanto hacia arriba como hacia abajo de nodos que están en ejecución.
Respecto al hardware, se ejecuta sobre máquinas EC2 (IaaS), las cuales configuraremos según nuestros requisitos. Utiliza HDFS y S3 para el almacenamiento, de manera que podemos guardar los datos de entrada y los de salida en S3, mientras que los resultados intermedios los almacenamos en HDFS.
Los cluster de EMR se componen de:
- un nodo principal central (master), encargado de gestionar el cluster y ejecutar los servicios de coordinación de datos.
- varios nodos principales (core), los cuales ejecutan las tareas y almacenan los datos en el clúster HDFS. Siempre debe haber al menos un nodo principal, y el número máximo de nodos principales es de 128.
- nodos tareas (worker), los cuales son opcionales, y no almacenan datos, y podemos añadir a un cluster para incrementar la capacidad de procesamiento (e eliminarlos una vez no los necesitamos para reducir costes).
A nivel de servicios, podemos definir su arquitectura en cuatro capas:
- Almacenamiento: mediante HFDS, EMR FS o el sistema de archivos local (almacenamiento de las instancias EC2).
- Gestor de recursos del cluster: YARN, Tez.
- Frameworks de procesamiento de datos: Hadoop MapReduce y Apache Spark
- Aplicaciones: Apache Spark, Apache Hive, etc...
Lanzando EMR¶
Antes de lanzar EMR, necesitamos crear un repositorio de información donde guardar los datos de entrada y salida, así como los logs que EMR genere.
Para ello, en S3 generaremos un bucket al que llamaremos s3severo8a-emr.
Podemos lanzar un cluster de EMR de tres formas, mediante la consola, el CLI o con un API. Vamos a centrar en el uso de la consola.
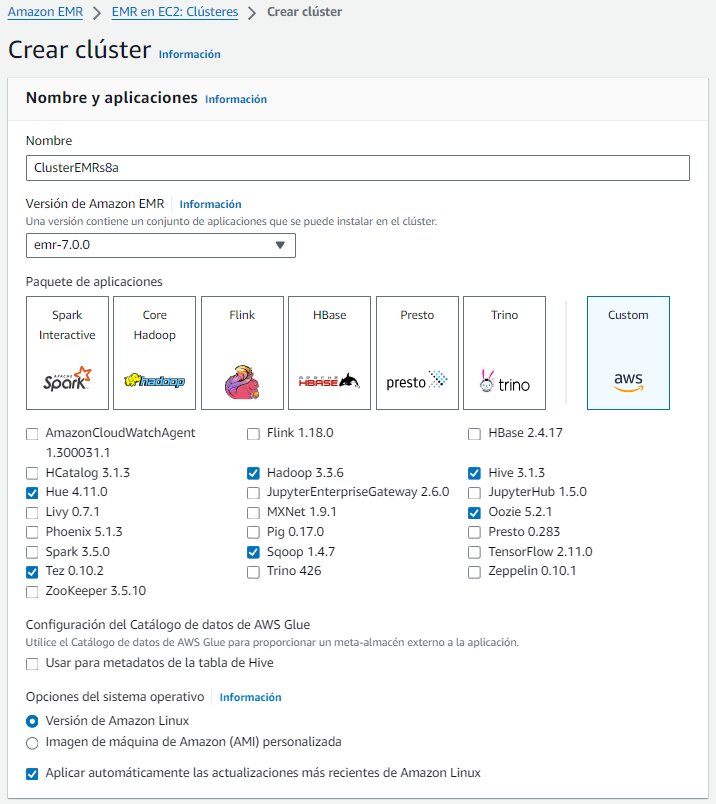
A continuación, accedemos al servicio de EMR, y creamos un clúster el cual hemos llamado ClusterEMRs8a, seleccionamos la última versión de EMR (en Enero de 2023 es la 7.0) y elegimos algunos de los paquetes ya definidos, o seleccionamos las aplicaciones en las que estamos interesados (en nuestro caso, vamos a seleccionar las aplicaciones que puedes ver en la imagen, que son los servicios que hemos trabajado en el bloque de Hadoop):
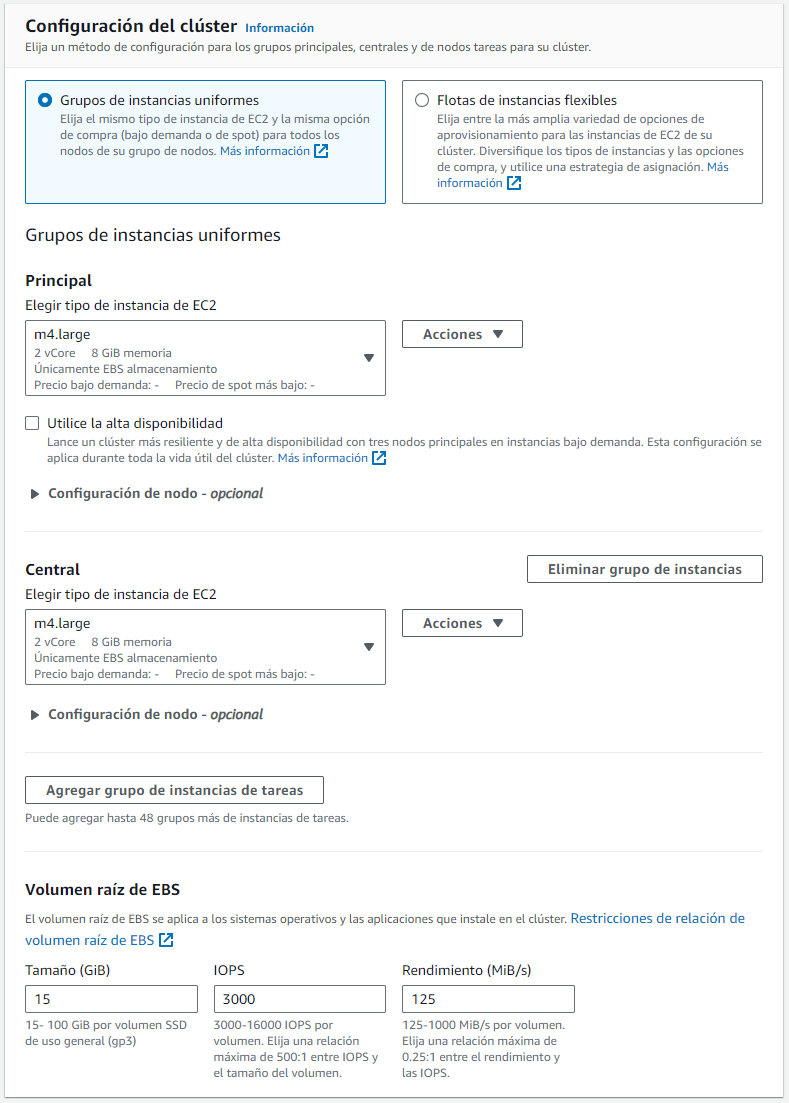
A continuación, vamos a seleccionar los tipos de instancias de nuestro clúster. Para ahorra costes, únicamente elegiremos un nodo principal y otro central (los nodos tareas como son opcionales, para este ejemplo, vamos a descartarlos). En cuanto al tipo de instancia, escogeremos las más económicas que nos permite AWS Academy, actualmente las instancias m4.large (2 CPU y 8 GiB RAM). Finalmente, escogemos el tamaño del almacenamiento del volumen EBS para las instancias EC2.
Tras la configuración de las instancias, podemos definir el tamaño del clúster. Lo normal es que los clúster de EMR se compongan de un gran número de instancias (sino, más que Big Data, será Small Data y probablemente habrá mejores soluciones que EMR). En nuestro caso, para probar el servicio, con una única instancia nos es suficiente. Otras opciones es que el redimensionado del clúster los gestione AWS mediante métricas o programar nosotros el escalado mediante políticas personalizadas:
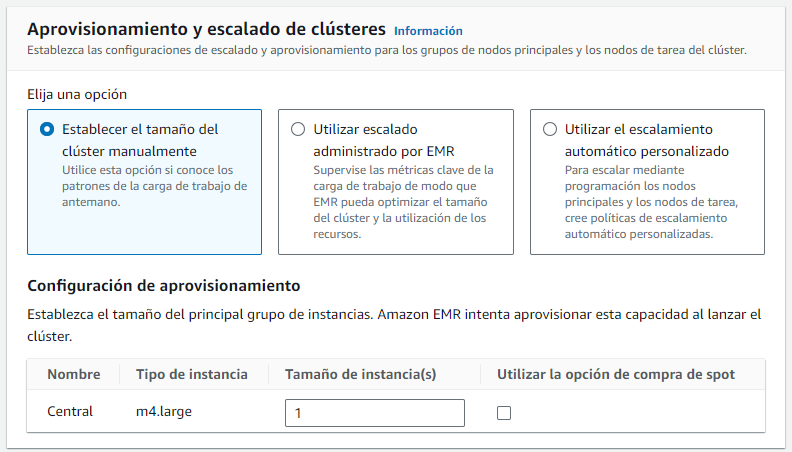
Apagado del clúster
Por defecto, EMR creará un cluster con una hora de inactividad. Si queremos modificar la duración o configurar el clúster para que se detenga tras la realización de los pasos que configuremos, podemos hacerlo mediante el panel de Cluster termination and node replacement:
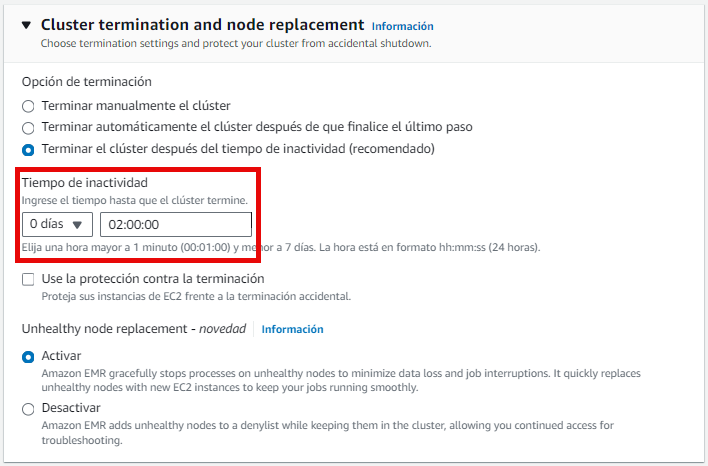
De los pasos siguientes, podemos dejar los valores por defecto y bajamos hasta los ajustes de seguridad, donde elegimos el par de claves vockey, las cuales podemos descargar desde AWS Details al lanzar nuestro Learner Lab y luego seleccionamos los roles IAM asociados a EMR_DefaultRoley EMR_EC2_LabRole respectivamente:
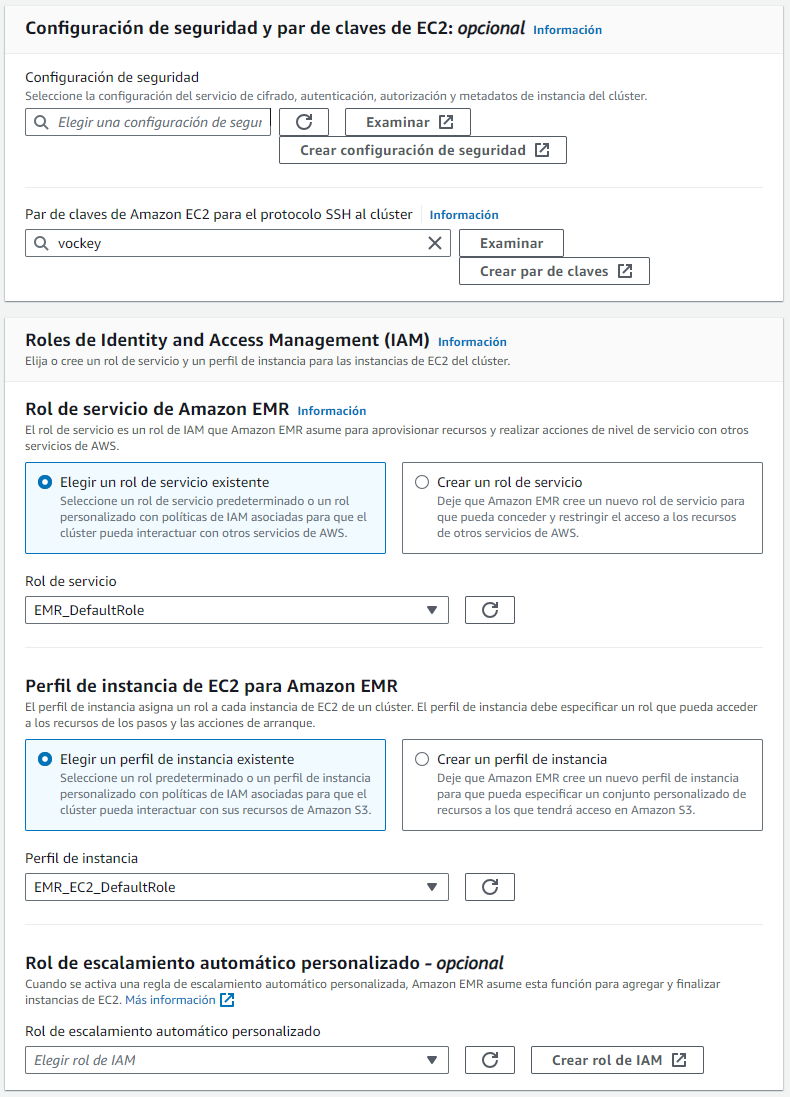
En el lado derecho podremos ver un resumen de las opciones seleccionadas, y tras darle a crear, a los 10 minutos aproximadamente, nuestro clúster estará listo para trabajar con él.
Modos de lanzamiento
Normalmente, cuando utilizamos un clúster para procesar analíticas, interactuar con aplicaciones de big data o procesamiento de datasets de forma periódica, el clúster está siempre corriendo, a no ser que lo detengamos nosotros de forma explícita. Pero si queremos que sólo exista durante la ejecución de uno o más trabajos, el cual se le conoce como clúster transient o de ejecución por pasos, al terminar de ejecutar los pasos indicados, el clúster se detendrá.
Preparando al clúster¶
En un cluster EMR, el nodo maestro es una instancia EC2 que coordina al resto de instancias EC2 que corren los nodos principales y de tareas. Este nodo expone un DNS público el cual podemos utilizar para conectarnos.
Por defecto, EMR bloquea el arranque de los clúster que permitan las conexiones del exterior (esto nos puede pasar si al crear el clúster le asignamos un grupo de seguridad que ya teníamos creado y que permitía el tráfico entrante).
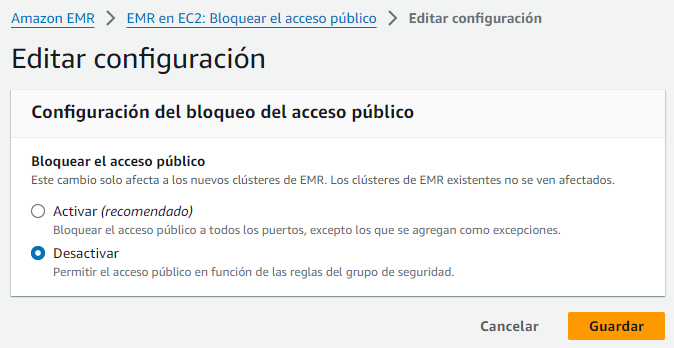
Desbloqueando el acceso público¶
Para permitir el acceso desde el exterior, podemos arrancar un clúster con el trafico cerrado, y una vez ya ha arrancado desactivar la opción de Bloquear el acceso público de EMR:
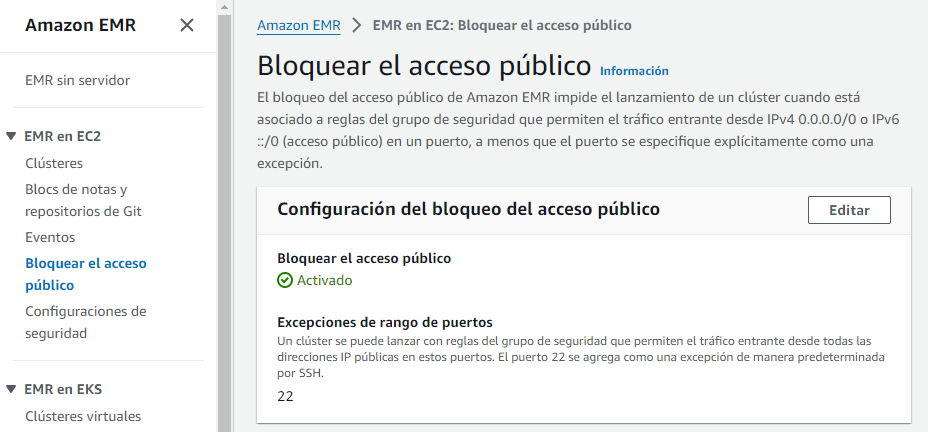
Si editamos las opciones, podemos desbloquear el acceso público:
Editando el grupo de seguridad¶
Por defecto, EMR crea un grupo de seguridad para el nodo maestro el cual determina el acceso. De inicio, ese grupo de seguridad no permite las conexiones SSH. Por ello, antes de poder conectarnos al cluster, también necesitamos modificar el grupo de seguridad del nodo principal para permitir todo el tráfico TCP (el tráfico SSH ya está abierto por defecto).
Para ello, en la pantalla de información del clúster que acabamos de crear, en la pestaña de Propiedades, en Red y Seguridad, editaremos el grupo de seguridad del nodo principal:
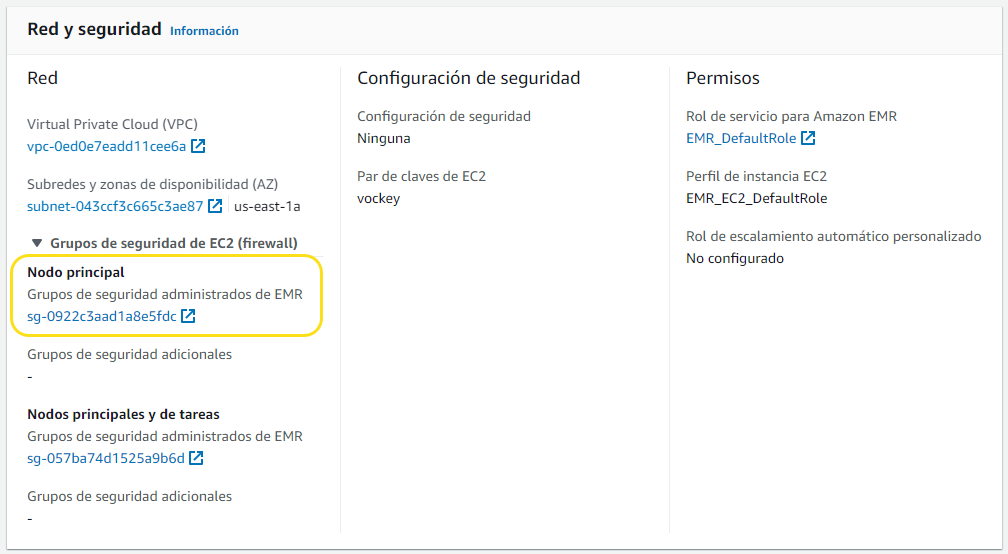
Tras Editar reglas de entrada, permitimos todo el tráfico entrante (cuidado que esta es una práctica de seguridad muy mala, sólo lo hacemos así por comodidad):

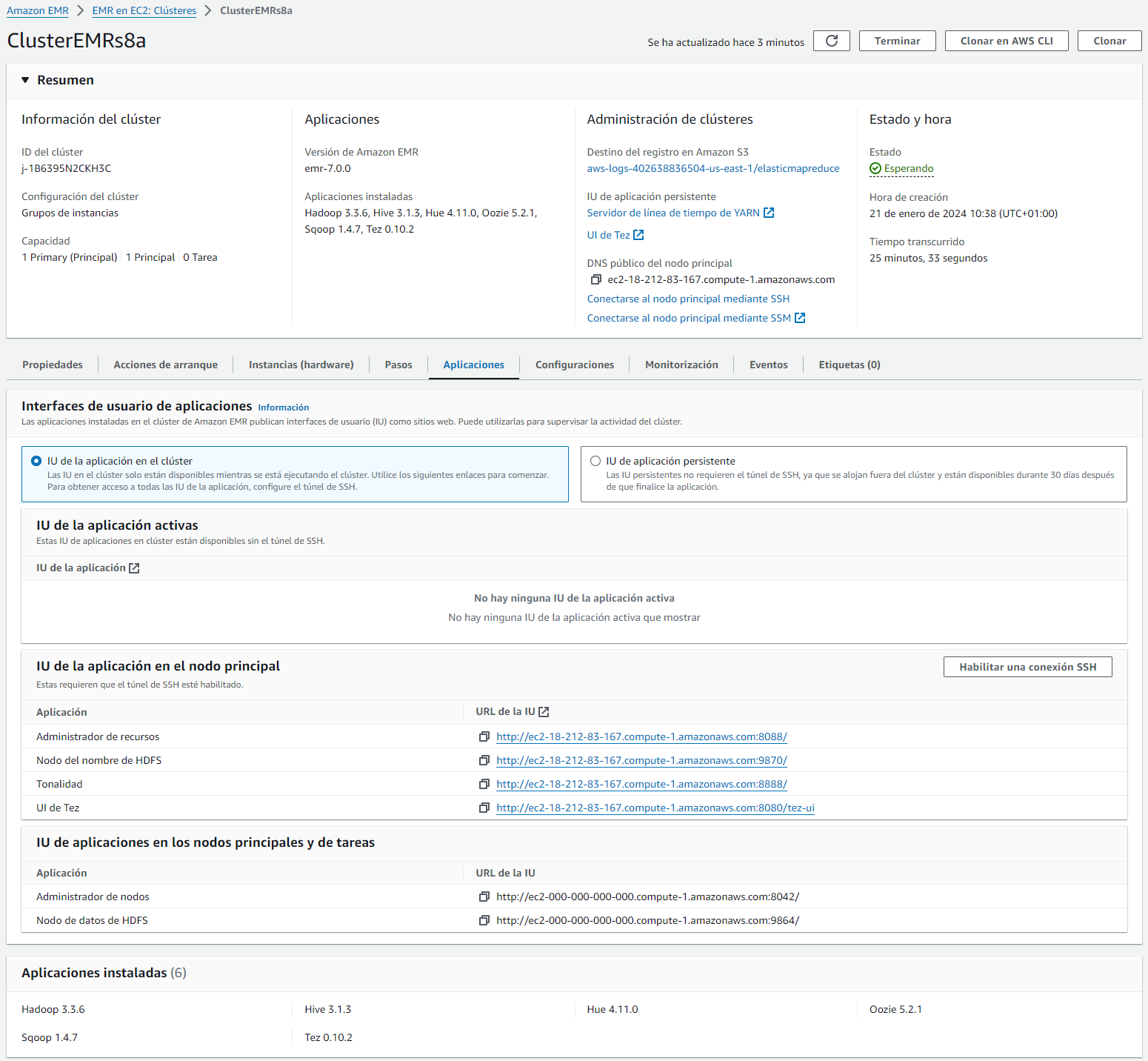
Conectándonos al clúster¶
Una vez arrancado, nos podemos conectar al nodo principal a algunas de las aplicaciones configuradas, por ejemplo a:
- El namenode de HDFS
- Hue (mal traducido a Tonalidad)
- El interfaz de Tez
- O la de YARN
Mediante SSH¶
Una vez desbloqueado el acceso público y el tráfico entrante, ya podemos conectarnos al nodo maestro del clúster. Para ello, necesitamos las claves de acceso que hemos descargado al crear el Learner Lab. Con nuestras claves labsuser.pem descargadas, nos conectamos al clúster (recuerda previamente configurar los permisos mediante chmod 400 labsuser.pem y luego poner hadoop@ delante de la URL del namenode):
Windows y SSH
En el caso de Windows, debes utilizar Putty y las claves ppk.
ssh -i labsuser.pem hadoop@ec2-18-212-83-167.compute-1.amazonaws.com
Al conectarnos, tanto EC2 como EMR nos darán la bienvenida:
, #_
~\_ ####_ Amazon Linux 2023
~~ \_#####\
~~ \###|
~~ \#/ ___ https://aws.amazon.com/linux/amazon-linux-2023
~~ V~' '->
~~~ /
~~._. _/
_/ _/
_/m/'
Last login: Sun Jan 21 10:08:18 2024
EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR
E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R
EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R
E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R
E::::E M::::::M:::M M:::M::::::M R:::R R::::R
E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R
E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR
E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R
E::::E M:::::M M:::M M:::::M R:::R R::::R
E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R
EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R
E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R
EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRR
[hadoop@ip-172-31-18-133 ~]$
Visualizando HDFS¶
AWR EMR 6x - Parece que funciona pero...
En versiones anteriores de EMR, el acceso a las aplicaciones no funcionaba, ya que el puerto de acceso estaba bloqueado. Aunque el acceso a las aplicaciones sí que funcionaba, pero el acceso a HDFS estaba bloqueado, y la ruta de HDFS en Hue mal configurada, por lo que no podíamos visualizar los archivos almacenados en HDFS.
Para poder visualizar el sistema de archivos de HDFS, primero le cambiamos los permisos al hdfs-site.xml para poder editarlo sin problemas:
sudo chmod 777 /usr/lib/hadoop/etc/hadoop/hdfs-site.xml
nano /usr/lib/hadoop/etc/hadoop/hdfs-site.xml
Editamos la propiedad dfs.webhdfs.enabled y la ponemos a true (podemos buscarla mediante CTRL + W, editarla, y luego guardar y salir mediante CTRL + X):
<property>
<name>dfs.webhdfs.enabled</name>
<value>false</value>
</property>
Sólo nos queda reiniciar el servicio de HDFS:
sudo systemctl restart hadoop-hdfs-namenode
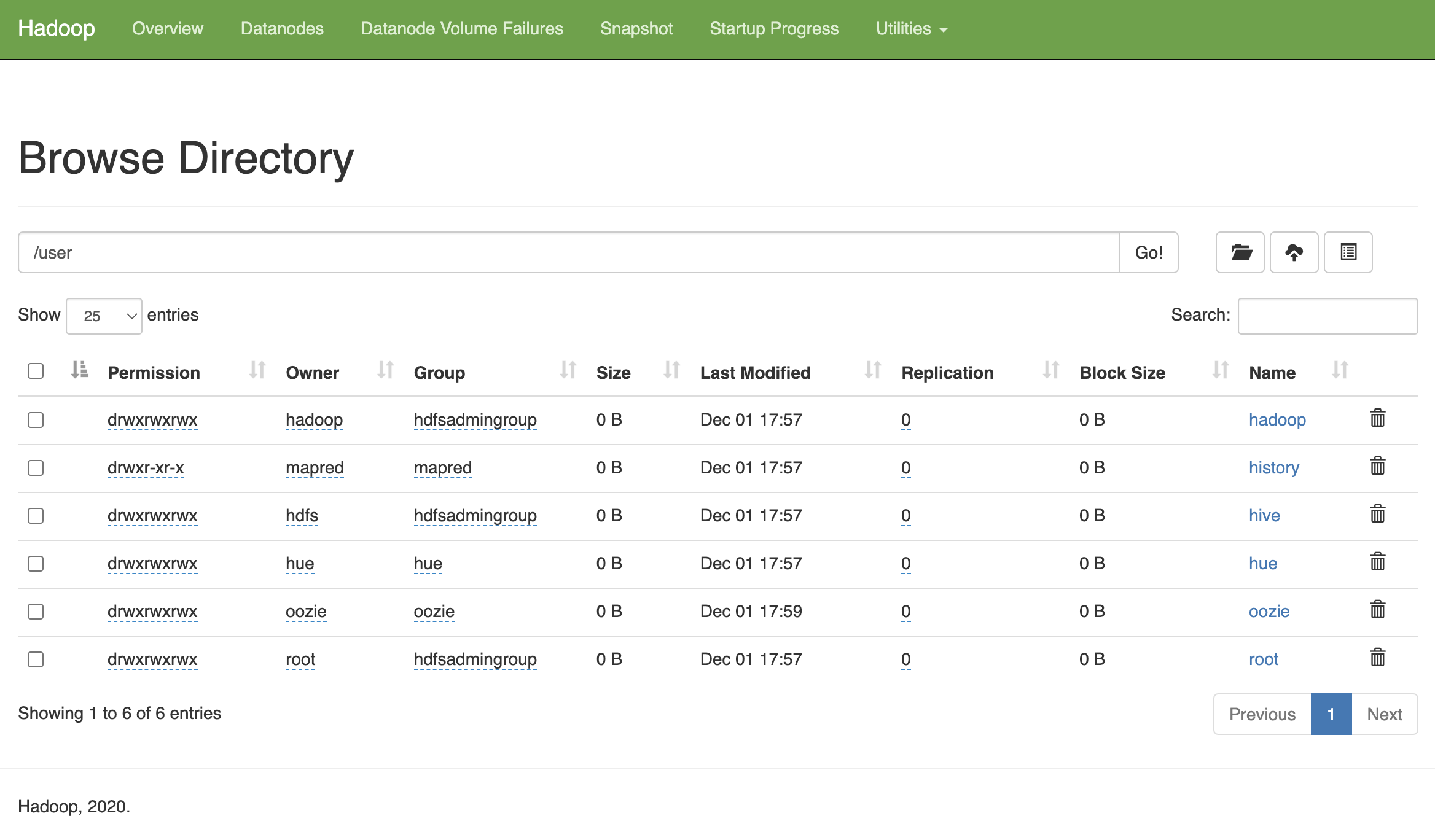
En la pestaña de Aplicaciones podemos ver la aplicación Nodo del nombre en HDFS, el cual nos abrirá la consola del del interfaz de HDFS, de manera que ya podemos navegar por las carpetas y ver el contenido, por ejemplo, accediendo a http://ec2-54-164-225-241.compute-1.amazonaws.com:9870:
Hue y HDFS¶
Cuando arranca Hue, la primera vez nos pide crear un usuario (en nuestro caso, hemos creado el usuario iabd con contraseña IABDiabd1.)
AWR EMR 6x - Parece que funciona pero...
Del mismo modo, en versiones anteriores de EMR, nos toca cambiar alguna propiedad más.
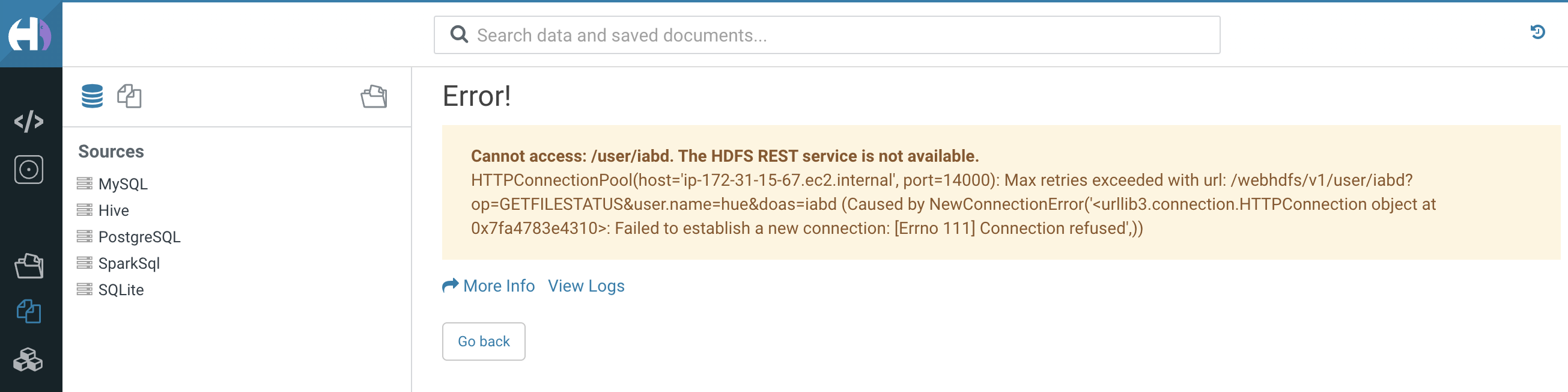
Si intentamos visualizar los archivos, de igual modo, Hue no tiene bien configurado el acceso a HDFS:
Para ello, igual que hemos realizado antes, cambiamos los permisos y editamos el fichero de configuración:
sudo chmod 777 /usr/lib/hue/desktop/conf/hue.ini
nano /usr/lib/hue/desktop/conf/hue.ini
Y configuramos bien el puerto de acceso (debe ser 9870), dentro del grupo [[hdfs_clusters]] de [hadoop] editamos la propiedad webhdfs_url (sólo debes cambiar el puerto de a 9870):
webhdfs_url = http://ip-172-31-18-133.ec2.internal:9870/webhdfs/v1
Y reiniciamos el servicio:
sudo systemctl restart hue
Sólo nos queda crear un carpeta para nuestro usuario en HDFS:
hdfs dfs -mkdir /user/iabd
hdfs dfs -chmod 777 /user/iabd
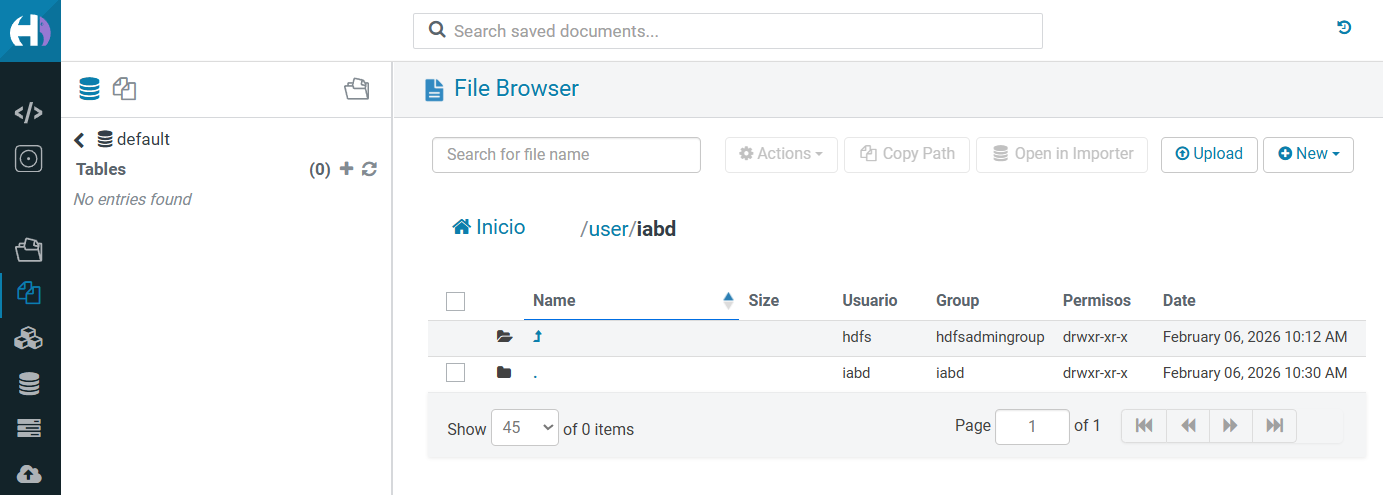
Una vez que entramos, si vamos a la opción de Files^, podremos visualizar el sistema de archivos de HDFS:
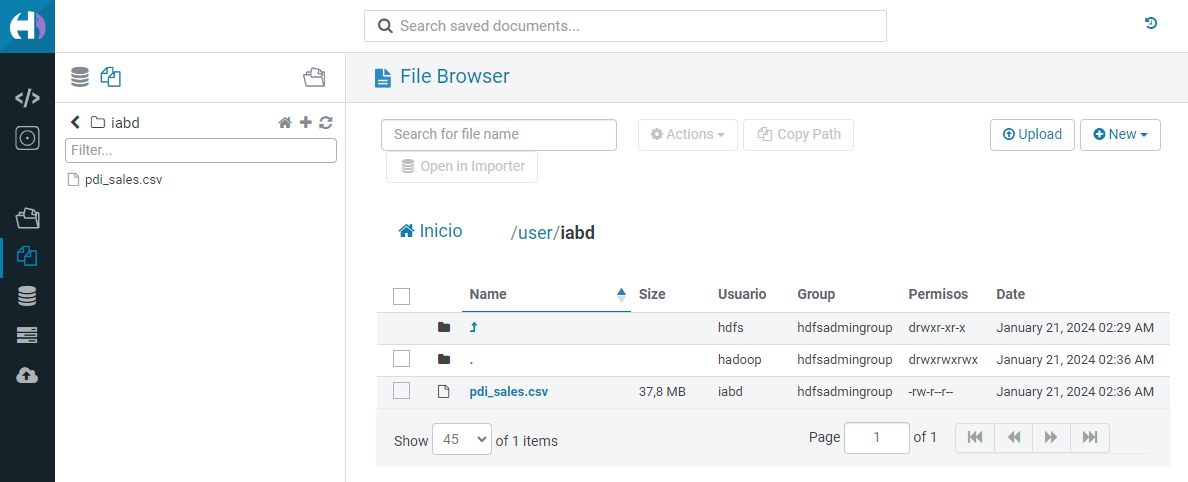
También podemos subir el archivo de ventas que hemos utilizado en varias sesiones desde la consola SSH que hemos abierto anteriormente:
wget http://aitor-medrano.github.io/iabd/de/resources/pdi_sales.csv
hdfs dfs -put pdi_sales.csv /user/iabd
Y a continuación visualizarlo desde Hue:
Procesando los datos¶
En EMR, podemos ejecutar los trabajos de procesamiento de datos mediante la ejecución de comandos desde la conexión SSH, o bien, como veremos a continuación, mediante la creación de pasos dentro del clúster.
Un paso (step) en Amazon EMR es una tarea individual que se ejecuta en un clúster de EMR. Puede ser una tarea de procesamiento de datos, como un trabajo de MapReduce, o una tarea de administración del sistema, como la instalación de software o la configuración de un servicio.
Los pasos se ejecutan en orden secuencial y se pueden agregar, modificar o eliminar según sea necesario.
Los pasos disponibles en EMR dependen directamente de los servicios que hemos seleccionado al crear nuestro clúster.
El servicio AWS Step Functions permite coordinar y orquestar tareas de AWS, por ejemplo, para crear flujos de trabajo que coordinen los pasos de Amazon EMR y otros servicios de AWS, como AWS Lambda.
Caso de Uso¶
En este caso de uso vamos a realizar una operación similar a la que hemos hecho en sesiones previas con Hadoop.
En este caso, mediante Sqoop, realizaremos una importación en HDFS de una tabla de una base de datos relacional que tenemos desplegada en RDS. Tras ello, desde Hue, crearemos una tabla con Hive sobre dicha tabla y realizaremos una consulta sobre los datos almacenados en HDFS.
De forma paralela, exportaremos los datos de HDFS a S3 y crearemos una nueva tabla cuyos datos apunten a S3 y repetiremos la consulta.
De RDS a HDFS¶
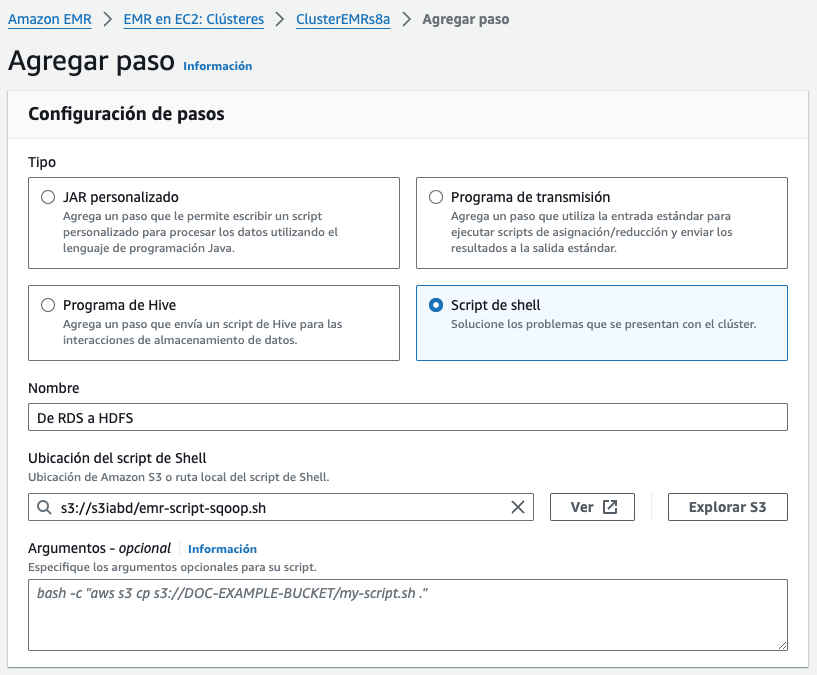
Para realizar la importación en HDFS haremos uso de Sqoop, pero en vez de hacerlo mediante un comando desde la conexión SSH, vamos a utilizar un Paso dentro de EMR para su ejecución.
Así pues, vamos a crear un script con las acciones a realizar (recuerda previamente editar la ruta de RDS para que apunte a la base de datos que creaste en la sesión de RDS):
Creando el script en AWS
Para subir el script a AWS, bien podemos crearlo en nuestro sistema local, y una vez configuradas las credenciales subirlo mediante AWS CLI o el interfaz gráfico de S3, o directamente desde Cloudshell podemos ejecutar nano y editar el fichero y copiar el contenido.
hdfs dfs -mkdir -p /user/iabd/sqoop
hdfs dfs -chmod 777 /user/iabd/sqoop
sqoop import --connect jdbc:mysql://rds-retaildb.cwlnhhfuyb7j.us-east-1.rds.amazonaws.com/retail_db \
--username=admin --password=adminadmin \
--table=customers --driver=org.mariadb.jdbc.Driver \
--target-dir=/user/iabd/sqoop/customers \
--fields-terminated-by=',' --lines-terminated-by '\n' \
--columns "customer_id,customer_fname,customer_lname,customer_city"
Antes de crear el paso, necesitamos preparar el bucket de S3 (puedes utilizar cualquier de los empleados en las sesiones anteriores; si no fuera el caso, crea el bucket y añade una carpeta).
Ahora sí, una vez ya tenemos el script y el bucket de S3, lo subimos al mismo:
aws s3 cp emr-script-sqoop.sh s3://s3iabd
Y finalmente creamos el paso dentro de EMR
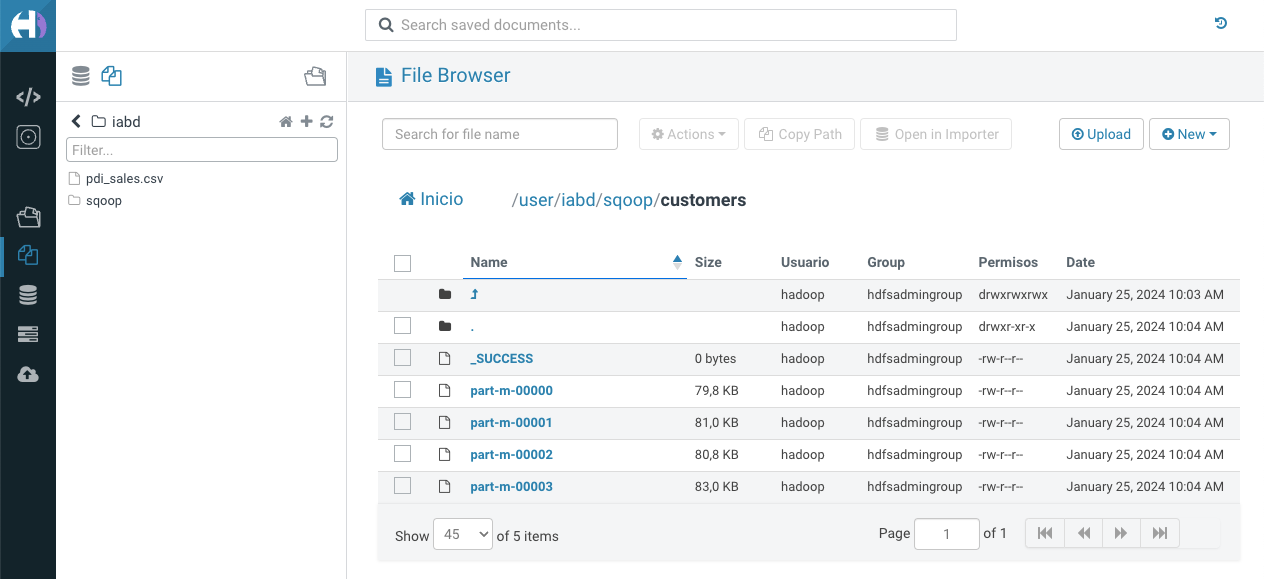
Creando las tablas desde Hue¶
Una vez cargados los datos, podemos visualizarlos, por ejemplo, desde Hue:
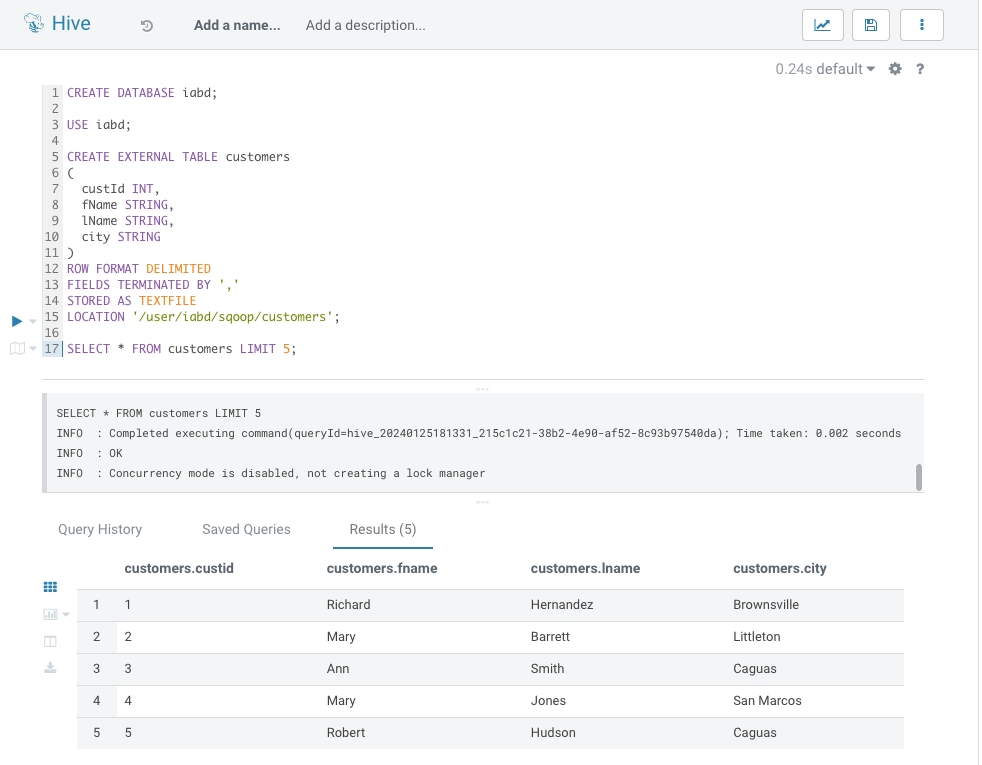
Y si abrimos un Editor de Hive (el primer icono < / > en la barra de la izquierda), podremos interactuar mediante SQL y crear tanto una base de datos como una tabla externa que apunte a la ruta de HDFS:
CREATE DATABASE iabd;
USE iabd;
CREATE EXTERNAL TABLE customers
(
custId INT,
fName STRING,
lName STRING,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/iabd/sqoop/customers';
SELECT * FROM customers LIMIT 5;
Y tras ejecutar las sentencias SQL, visualizar el resultado:
De HDFS a S3¶
Para poder trasladar la información de HDFS a S3 haremos uso de S3DistCp (s3-dist-cp), un herramienta open source que podemos añadirla como una paso dentro de nuestro clúster.
Así pues, vamos a añadir un paso de tipo JAR con la siguiente información:
- Nombre: por ejemplo,
hdsf2s3_customers_s3iabd - Librería:
command-runner.jar - Comando:
s3-dist-cp --src=hdfs:///user/iabd/sqoop/customers --dest=s3://s3iabd/emr(ten en cuenta las rutas de la carpeta en HDFS y el bucket de S3)
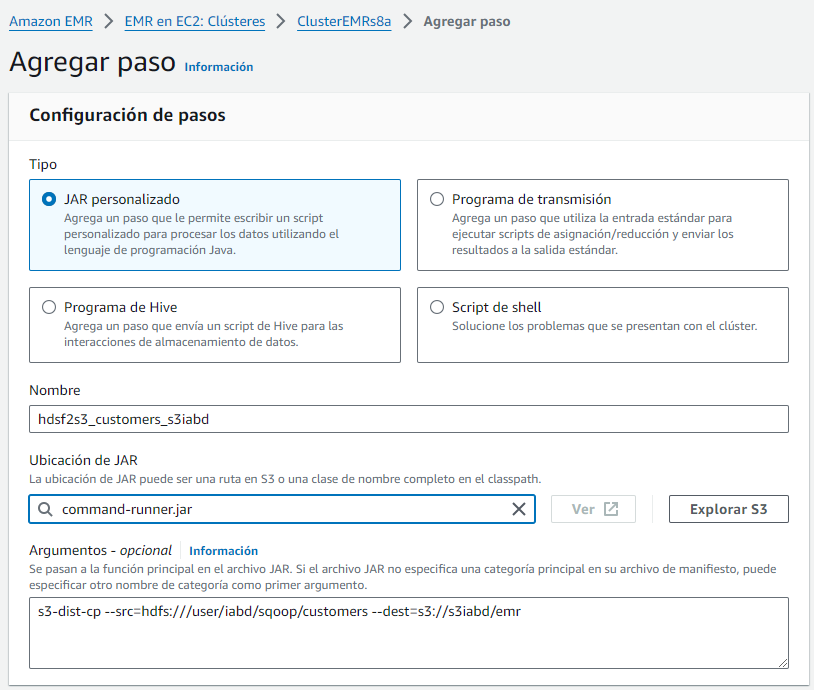
En nuestro caso ha tardado 1 minuto y 50 segundos en realizar el flujo de datos de HDFS a S3. En el caso de que fallase el paso (en nuestro caso, tuvimos algún fallo con el nombre del bucket e incluso con los guiones de los parámetros), podremos consultar la salida de error. Eso sí, hay que esperar algunos minutos a que AWS actualice los logs:

Una vez el paso se haya ejecutado exitosamente, si vamos a nuestro bucket veremos los archivos creados:
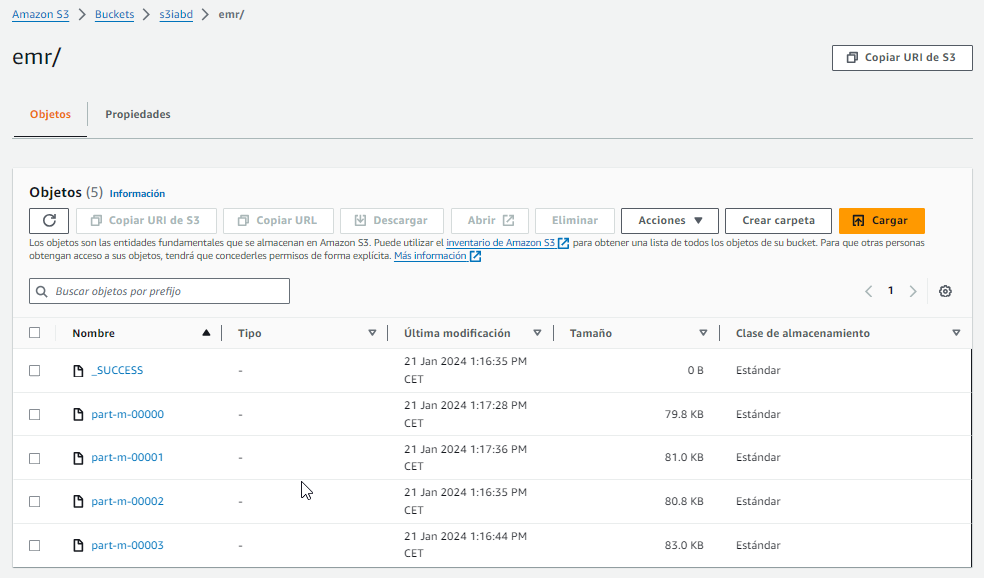
Una vez cargados los tablas en S3, podemos reproducir el caso de uso de la sesión de Athena y realizar consultas sobre los datos almacenados en el bucket o directamente crear una nueva tabla en Hive que obtenga los datos de S3 indicando la ruta con el prefijo s3n:
USE iabd;
CREATE EXTERNAL TABLE customers3
(
custId INT,
fName STRING,
lName STRING,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3n://s3iabd/emr';
SELECT * FROM customers3 LIMIT 5;
Escalando¶
Podemos ajustar el número de instancias EC2 con las que trabaja nuestro clúster de EMR, ya sea manualmente o de forma automática en respuesta a la demanda que reciba.
Para ello, en la pestaña de Instancias (hardware), tenemos la opción de Editar opción de escalado de clústeres:
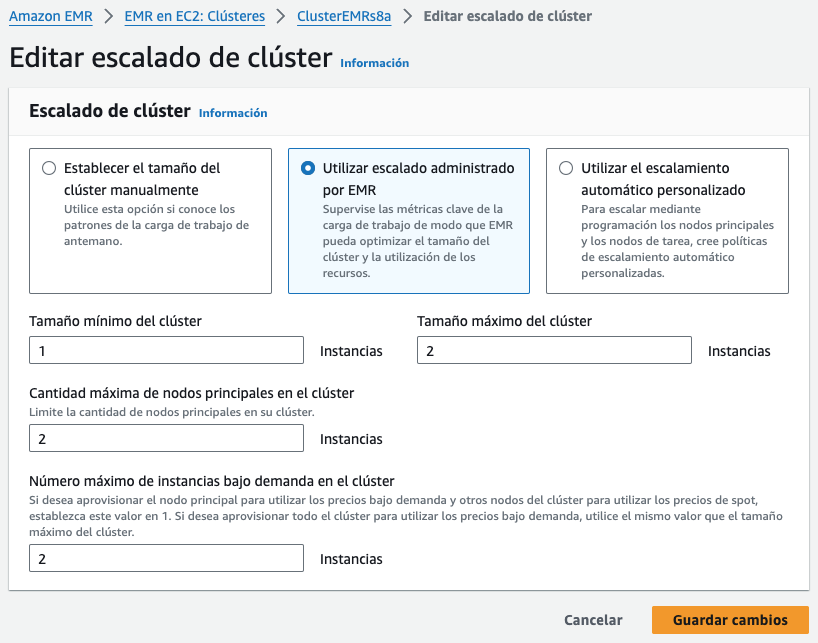
Para ello, podemos activar el escalado gestionado mediante EMR o crear una política de escalado a medida. Independiente del modo, hemos de considerar que siempre hemos de tener de uno a tres nodos maestros, y que una vez creado el clúster, este número no lo podemos cambiar. Lo que sí que podemos es añadir y eliminar nodos principales o de tareas.
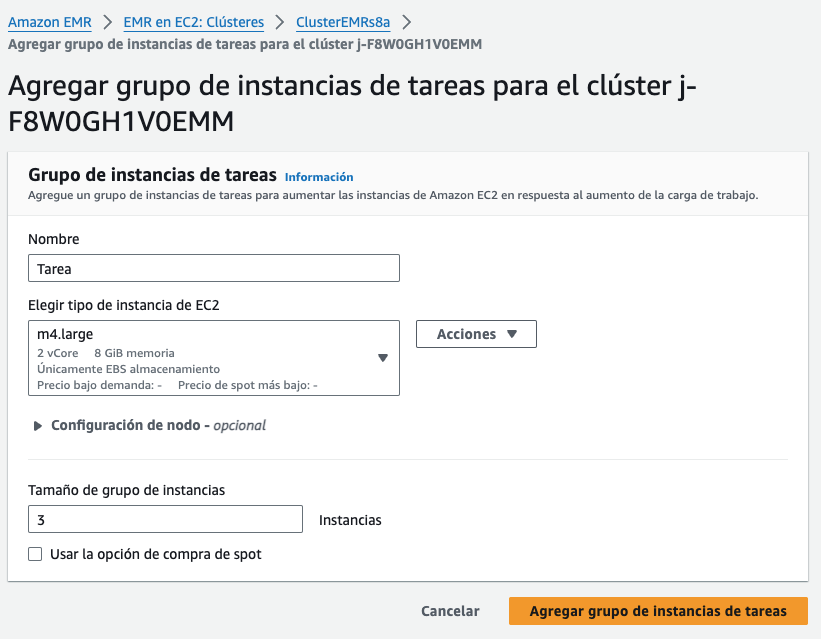
Conviene destacar que no podemos reconfigurar y redimensionar el clúster al mismo tiempo, de manera que hasta que no acabe la reconfiguración de un grupo de instancias no se puede iniciar el redimensionado.
Costes¶
Es muy importante ser conscientes de los costes que lleva utilizar EMR. A grosso modo, EMR supone un 25% de sobrecoste a las instancias EC2, es decir, pagaremos el coste del alquiler de las máquinas EC2 más un sobre un incremento del 25%.
Por ejemplo, para 20 nodos con 122 Gb RAM y 16 CPU, pagaríamos unos 32 €/h. En cambio, si sólo usamos las instancias que nos permite AWS Academy para practicar, pagaremos 0,13$/hora por instancia de m4.large (2 CPU y 8GB RAM).
Referencias¶
Actividades¶
- (RABDA.2 / CEBDA.2b / 1p) Arranca un clúster EMR con 2 máquinas, y sube el fichero
pdi_manufacturer.csva HDFS. Visualiza el contenido del fichero desde Hue y desde la consola de HDFS. - (RABDA.2 / CEBDA.2b / 1p) Basándote en el caso de uso, carga los datos clientes (
customers) y de pedidos (orders), haciendo uso de dos pasos diferentes. A continuación, traslada los datos de HDFS a un bucket de S3 (el nombre del bucket debe contener tus iniciales). -
(RABDA.2 / CEBDA.2b / 1p) Con los datos del ejercicio anterior, tras crear ambas tablas en Hive, recupera, para cada cliente (mostrando el id y su nombre completo), cuantos pedidos ha realizado.
Exportar a S3
Es importante que tanto para los clientes como para los pedidos realices el caso de uso completo, exportando los datos a S3 para poder realizar las actividades de la sesión de Athena.
-
(RABDA.2 / CEBDA.2e / 0.5p) A continuación, añade dos nodos más al clúster (de forma manual, no gestionada por AWS) y sube un archivo a HDFS. Comprueba si los nodos aparecen en la consola de Hadoop UI y vuelve a ejecutar la consulta del ejercicio anterior.