Hadoop¶
Si Big Data es la filosofía de trabajo para grandes volúmenes de datos, Apache Hadoop es la tecnología catalizadora. Hadoop puede escalar hasta miles de ordenadores creando un clúster con un almacenamiento del orden de petabytes de información.
Más que un producto, es un proyecto open source que aglutina una serie de herramientas para el procesamiento distribuido de grandes conjuntos de datos a través de clústers de ordenadores utilizando modelos de programación sencillos.
Sus características son:
- Confiable: crea múltiples copias de los datos de manera automática y, en caso de fallo, vuelve a desplegar la lógica de procesamiento.
- Tolerante a fallos: tras detectar un fallo aplica una recuperación automática. Cuando un componente se recupera, vuelve a formar parte del clúster. En Hadoop los fallos de hardware se tratan como una regla, no como una excepción.
- Escalable: los datos y su procesamiento se distribuyen sobre un clúster de ordenadores (escalado horizontal), desde un único servidor a miles de máquinas, cada uno ofreciendo computación y almacenamiento local.
- Portable: se puede instalar en todo tipos de hardware y sistemas operativos.
En la actualidad se ha impuesto Hadoop v3 (la última versión a día de hoy es la 3.4.2), aunque todavía existe mucho código para Hadoop v2.
Procesamiento distribuido¶
Hadoop está diseñado para ejecutar sistemas de procesamiento en el mismo clúster que almacena los datos (data local computing). Su filosofía es almacenar todos los datos en un lugar y procesarlos en el mismo lugar, esto es, mover el procesamiento hacia el almacén de datos y no mover los datos al sistema de procesamiento.
Esto lo logra mediante un entorno distribuido de datos y procesos. El procesamiento se realiza en paralelo a través de nodos de datos en un sistema de ficheros distribuidos (HDFS), donde se distingue entre:
- Nodos maestros: encargados de los procesos de gestión global, es decir, controlar la ejecución o el almacenamiento de los trabajos y/o datos. Normalmente se necesitan 3. Su hardware tiene mayores requisitos.
- Nodos workers: tratan con los datos locales y los procesos de aplicación. Su número dependerá de las necesidad de nuestros sistemas, pero pueden estar comprendido entre 4 y 10.000. Su hardware es relativamente barato (commodity hardware) mediante servidores x86.
- Nodos edge: hacen de puente entre el clúster y la red exterior, y proporcionan interfaces.

Commodity Hardware
A veces el concepto hardware commodity suele confundirse con hardware doméstico, cuando a lo que hace referencia es a hardware no específico, que no tiene unos requerimientos en cuanto a disponibilidad o resiliencia exigentes.
El hardware típico donde se ejecuta un cluster Hadoop es el siguiente:
- Nodos worker: 64 a 128 GB RAM – de 12 a 24 discos duros de 4-12 TB JBOD (just a bunch of drives), sin RAID – 2 CPU x 6-8 cores.
- Nodos master: 128 a 256 GB RAM – 2 discos duros SSD de 2-4 TB en RAID – 2 CPU x 8-16 cores. En estos nodos es más importante la capacidad de la CPU que la de almacenamiento.
- Nodos edge: 256 GB RAM – 2 discos duros de 2-3 TB en RAID – 2 CPU x 8 cores.
Cada vez que añadimos un nuevo nodo worker, aumentamos tanto la capacidad como el rendimiento de nuestro sistema.
Componentes y Ecosistema¶
El núcleo de Hadoop se compone de:
- un conjunto de utilidades comunes (Hadoop Common)
- un sistema de ficheros distribuidos (Hadoop Distributed File System ↔ HDFS).
- un gestor de recursos para el manejo del clúster y la planificación de procesos (YARN)
- un sistema para procesamiento paralelo de grandes conjuntos de datos (MapReduce)
Estos elementos permiten trabajar casi de la misma forma que si tuviéramos un sistema de fichero locales en nuestro ordenador personal, pero realmente los datos están repartidos entre miles de servidores.
Las aplicaciones se desarrollan a alto nivel, sin tener constancia de las características de la red. De esta manera, los científicos de datos se centran en la analítica y no en la programación distribuida.
Sobre este conjunto de herramientas existe un ecosistema "infinito" con tecnologías que facilitan el acceso, gestión y extensión del propio Hadoop.
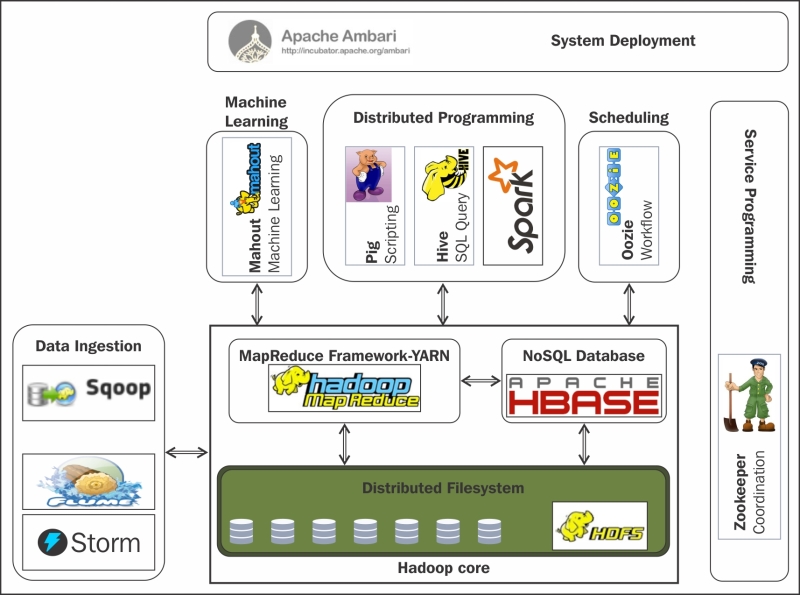
Las más utilizadas son:
- Hive: Permite acceder a HDFS como si fuera una Base de datos, ejecutando comandos muy parecidos a SQL para recuperar valores (HiveSQL). Simplifica enormemente el desarrollo y la gestión con Hadoop.
- HBase: Es el sistema de almacenamiento NoSQL basado en columnas para Hadoop.
- Es una base de datos de código abierto, distribuida y escalable para el almacenamiento de Big Data.
- Escrita en Java, implementa y proporciona capacidades similares sobre Hadoop y HDFS.
- El objetivo de este proyecto es el de trabajar con grandes tablas, de miles de millones de filas de millones de columnas, sobre un clúster Hadoop.
- Pig: Lenguaje de alto de nivel para analizar grandes volúmenes de datos. Trabaja en paralelo, lo que permite gestionar gran cantidad de información. Realmente es un compilador que genera comandos MapReduce, mediante el lenguaje textual denominado Pig Latin.
- Sqoop: Permite transferir un gran volumen de datos de manera eficiente entre Hadoop y sistemas gestores de base de datos relacionales.
- Flume: Servicio distribuido y altamente eficiente para distribuir, agregar y recolectar grandes cantidades de información. Es útil para cargar y mover información en Hadoop, como ficheros de logs, datos de Twitter/Reddit, etc. Utiliza una arquitectura de tipo streaming con un flujo de datos muy potente y personalizables
- ZooKeeper: Servicio para mantener la configuración, coordinación y aprovisionamiento de aplicaciones distribuidas. No sólo se utiliza en Hadoop, pero es muy útil en esa arquitectura, eliminando la complejidad de la gestión distribuida de la plataforma.
- Spark: Es un motor muy eficiente de procesamiento de datos a gran escala. Implementa procesamiento en tiempo real al contrario que MapReduce, lo que provoca que sea más rápido. Para ello, en vez de almacenar los datos en disco, trabaja de forma masiva en memoria. Puede trabajar de forma autónoma, sin necesidad de Hadoop.
- Ambari: Herramienta utilizada para instalar, configurar, mantener y monitorizar Hadoop.
Si queremos empezar a utilizar Hadoop y todo su ecosistema, disponemos de diversas distribuciones con toda la arquitectura, herramientas y configuración ya preparadas. Las más reseñables son:
- Amazon Elastic MapReduce (EMR) de AWS.
- CDH de Cloudera
- Azure HDInsight de Microsoft.
- DataProc de Google.
MapReduce¶
Se trata de un paradigma de programación funcional en dos fases, la de mapeo y la de reducción, y define el algoritmo que utiliza Hadoop para paralelizar las tareas. Un algoritmo MapReduce divide los datos, los procesa en paralelo, los reordena, combina y agrega de vuelta los resultados mediante un formato clave/valor.
Este enfoque permite el procesamiento eficiente y escalable de grandes volúmenes de datos, aprovechando la capacidad de cómputo distribuido del cluster. MapReduce es ampliamente utilizado en aplicaciones de Big Data para tareas como análisis de datos, minería de datos y procesamiento de registros. Sin embargo, este algoritmo no casa bien con el análisis interactivo o programas iterativos, ya que persiste los datos en disco entre cada uno de los pasos del mismo, lo que con grandes datasets conlleva una penalización en el rendimiento.
Un job de MapReduce se compone de múltiples tareas MapReduce, donde la salida de una tarea es la entrada de la siguiente.
El siguiente gráfico muestra un ejemplo de una empresa que fabrica juguetes de colores. Cuando un cliente compra un juguete desde la página web, el pedido se almacena como un fichero en Hadoop con los colores de los juguetes adquiridos. Para averiguar cuantas unidades de cada color debe preparar la fábrica, se emplea un algoritmo MapReduce para contar los colores:
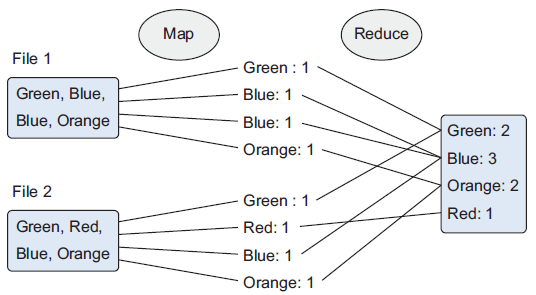
Como sugiere el nombre, el proceso se divide principalmente en dos fases:
- Fase de mapeo (Map) — Los documentos se parten en pares de clave/valor. Hasta que no se reduzca, podemos tener muchos duplicados.
- Fase de reducción (Reduce) — Es en cierta medida similar a un "group by" de SQL. Las ocurrencias similares se agrupan, y dependiendo de la función de reducción, se puede crear un resultado diferente. En nuestro ejemplo queremos contar los colores, y eso es lo que devuelve nuestra función.
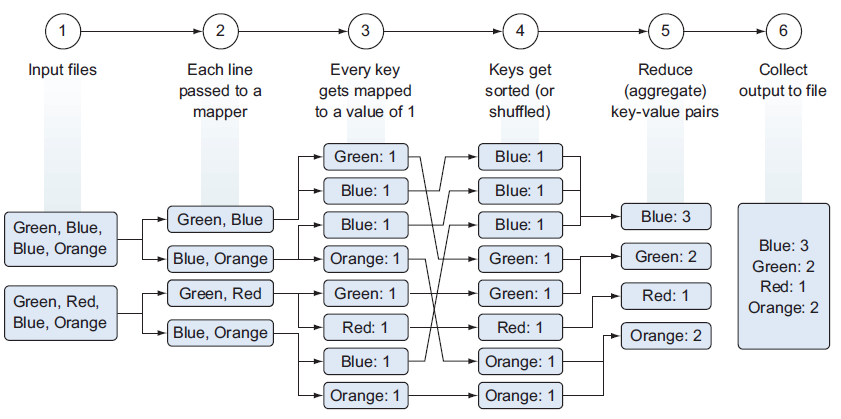
Realmente, es un proceso más complicado:
- Lectura desde HDFS de los ficheros de entrada como pares clave/valor.
- Pasar cada línea de forma separada al mapeador, teniendo tantos mapeadores como bloques de datos tengamos.
- El mapeador parsea los colores (claves) de cada fichero y produce un nuevo fichero para cada color con el número de ocurrencias encontradas (valor), es decir, mapea una clave (color) con un valor (número de ocurrencias).
- Para facilitar la agregación, se ordenan y/o barajan los datos a partir de la clave.
- La fase de reducción suma las ocurrencias de cada color y genera un fichero por clave con el total de cada color.
- Las claves se unen en un único fichero de salida que se persiste en HDFS.
No es oro todo lo que reluce
Hadoop facilita el trabajo con grandes volúmenes de datos, pero montar un clúster funcional no es una cosa trivial. Existen gestores de clústers que hacen las cosas un poco menos incómodas (como son Apache Ambari o Apache Mesos), aunque la tendencia es utilizar una solución cloud que nos evita toda la instalación y configuración.
Tal como comentamos al inicio, uno de los puntos débiles de Hadoop es el trabajo con algoritmos iterativos, los cuales son fundamentales en la parte de IA. La solución es el uso de Spark (que estudiaremos próximamente), que mejora el rendimiento por una orden de magnitud.
YARN¶
YARN (Yet Another Resource Negotiator) es un planificador de tareas y gestor de recursos distribuidos. Forma parte de Hadoop desde la versión 2, siendo un componente clave, y abstrae la gestión de recursos de los procesos MapReduce lo que implica una asignación de recursos más efectiva. YARN soporta varios frameworks de procesamiento distribuido, como MapReduce v2, Tez, Impala, Spark, etc..
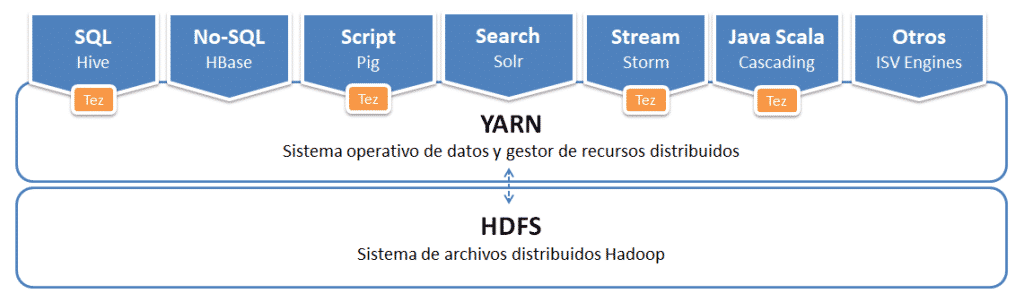
El objetivo principal de YARN es separar en dos servicios las funcionalidades de gestión de recursos de las funcionalidades de monitorización/planificación de tareas. Por un lado, un gestor de los procesos que se ejecutan en el clúster, que permite coordinar diferentes aplicaciones, asignar recursos y prioridades, permitir su convivencia, etc... Por otro lado, las aplicaciones, que pueden desarrollarse utilizando un marco de ejecución más ligero, no atado a un modelo estricto sobre cómo ejecutarse, lo que da más libertad para poder desarrollar las aplicaciones.
Así pues, YARN permite a múltiples aplicaciones y frameworks, como MapReduce, ejecutarse simultáneamente en el mismo cluster, optimizando el uso de los recursos disponibles. En concreto, YARN gestiona la asignación de recursos y la supervisión del estado de las aplicaciones y la recuperación ante fallos, facilitando así el procesamiento eficiente de grandes volúmenes de datos en entornos de Big Data.
Un ciclo típico de interacción entre HDFS y YARN consta de los siguientes pasos:
- Los datos se almacenan en HDFS
- Una aplicación (ej: Spark, MapReduce) solicita recursos a YARN.
- YARN asigna contenedores en los nodos donde están los datos.
- La aplicación procesa los datos de HDFS usando los recursos de YARN.
- Los resultados se escriben de vuelta a HDFS
Componentes¶
Se divide en tres componentes principales: un Resource Manager, múltiples Node Manager y varios Application Master.
La idea es tener un Resource Manager por clúster, que actúa como planificador, y un Application Master por aplicación, considerando una aplicación tanto un único job como un conjunto de jobs cíclicos.
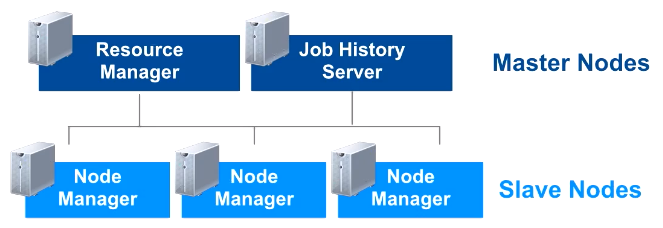
El Resource Manager y el Node Manager componen el framework de computación de datos. En concreto, el Resource Manager controla el arranque de la aplicación, siendo la autoridad que orquesta los recursos entre todas las aplicaciones del sistema. A su vez, tendremos tantos Node Manager como datanodes tenga nuestro clúster, siendo responsables de gestionar y monitorizar los recursos de cada nodo (CPU, memoria, disco y red) y reportar estos datos al Resource Manager.
El Application Master es una librería específica encargada de negociar los recursos con el Resource Manager y de trabajar con los Node Manager para ejecutar y monitorizar las tareas.
Finalmente, en nuestro clúster, tendremos corriendo un Job History Server encargado de archivar los fichero de log de los jobs. Aunque es un proceso opcional, se recomienda su uso para monitorizar los jobs ejecutados.
Resource Manager¶
El Resource Manager mantiene un listado de los Node Manager activos y de sus recursos disponibles. Dicho de otro modo, es el equivalente al Namenode de HDFS.
Cuando un cliente quiere ejecutar una aplicación en YARN, se comunica con el Resource Manager, que será el encargado de asignarle los recursos en base a las políticas de prioridad asignadas y los recursos disponibles, distribuir la aplicación (el ejecutable) por los diferentes nodos worker que realizarán la ejecución, controlar la ejecución para detectar si ha habido una caída de una de las tareas para relanzarla en otro nodo, y liberar los recursos una vez la ejecución haya finalizado.
El gestor de recursos, a su vez, se divide en dos componentes:
- El Scheduler o planificador es el encargado de gestionar la distribución de los recursos del clúster de YARN. Además, las aplicaciones usan los recursos que el Resource Manager les ha proporcionado en función de sus criterios de planificación. Este planificador no monitoriza el estado de ninguna aplicación ni les ofrece garantías de ejecución, ni recuperación por fallos de la aplicación o el hardware, sólo planifica. Este componente realiza su planificación a partir de los requisitos de recursos necesarios por las aplicaciones (CPU, memoria, disco y red).
- Application Manager: responsable de aceptar las peticiones de trabajos, negociar el contenedor con los recursos necesarios en el que ejecutar la Application Master y proporcionar reinicios de los trabajos en caso de que fuera necesario debido a errores.
Node Manager¶
El servicio NodeManager se ejecuta en cada nodo worker y realiza las siguientes funciones:
- Monitoriza y proporciona información sobre el consumo de recursos (CPU/memoria) por parte de los contenedores al Resource Manager.
- Envía mensajes para notificar al Resource Manager su actividad (no está caído) así como la información sobre su estado a nivel de recursos.
- Supervisa el ciclo de vida de los contenedores de aplicaciones.
- Supervisa la ejecución de las distintas tareas en contenedores y termina aquellas tareas que se han quedado bloqueadas.
- Almacena un log (fichero en HDFS) con todas las operaciones que se realizan en el nodo.
- Lanza procesos Application Master, que coordinan los trabajos para cada aplicación.
Contenedores
Es la unidad mínima de recursos de ejecución para las aplicaciones, y representa una cantidad específica de memoria, núcleos de procesamiento (cores) y otros recursos (disco, red), para procesar las aplicaciones. Por ejemplo, un contenedor puede representar 4 gigabytes de memoria y 1 núcleo de procesamiento.
Todas las tareas de las aplicaciones YARN se ejecutan en contenedores. Cada trabajo puede contener múltiples tareas y cada una de las tareas se ejecuta en su propio contenedor. Cuando una tarea va a arrancar, YARN le asigna un contenedor, y cuando la tarea termina, el contenedor se elimina y sus recursos se asignan a otras tareas.
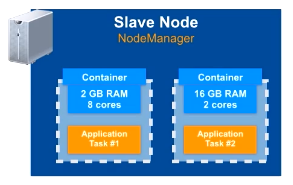
La cantidad de tareas y, por lo tanto, la cantidad de aplicaciones de YARN que puede ejecutar en cualquier momento, está limitada por la cantidad de contenedores que tiene un clúster. Por ejemplo, en un clúster de 20 nodos, con 256 GB de RAM y 12 cores por nodo, si se le ha asignado a YARN toda la capacidad existente, habrá un total de 5 TB de RAM y 240 cores disponibles. Si se ha definido un tamaño de contenedor de 32 gigabytes, habrá un máximo de 160 contenedores disponibles, es decir, se podrán ejecutar como máximo 160 tareas de forma concurrente.
Los contenedores YARN tienen una asignación de recursos (CPU, memoria, disco y red) fija de un host del clúster y el Node Manager es el encargado de monitorizar esta asignación. Si un proceso sobrepasase los recursos asignados, por ejemplo, sería el encargado de detenerlo. Además, mapean las variables de entorno necesarias, las dependencias y los servicios necesarios para crear los procesos.
Los Node Manager, al igual que los Datanodes en HDFS, son tolerantes a fallos, por lo que en caso de caída de alguno de ellos, el Resource Manager detectará que no funciona y redirigirá la ejecución de las aplicaciones al resto de nodos activos.
Application Master¶
El Application Master es el responsable de negociar los recursos apropiados con el Resource Manager y monitorizar su estado y su progreso. También coordina la ejecución de todas las tareas en las que puede dividirse su aplicación.
Existe un proceso Application Master por aplicación, y se ejecuta en uno de los nodos worker, para garantizar la escalabilidad de YARN, ya que si se ejecutaran todos los Application Master en el nodo maestro, junto con el Resource Manager, éste sería un cuello de botella para poder escalar o poder lanzar un gran número de aplicaciones sobre el clúster.
Asimismo, a diferencia del Resource Manager y los Node Manager, el Application Master es específico para una aplicación por lo que, cuando la aplicación finaliza, el proceso Application Master termina. En el caso de los servicios Resource Manager y Node Manager, siempre se están ejecutando aunque no haya aplicaciones activas en el clúster. Cada vez que se inicia una nueva aplicación, Resource Manager asigna un contenedor que ejecuta Application Master en uno de los nodos del clúster.
Funcionamiento¶
Podemos ver la secuencia de trabajo y colaboración de estos componentes en el siguiente gráfico:

- El cliente envía una aplicación YARN.
- Resource Manager reserva los recursos en un contenedor para su ejecución.
- El Application Manager se registra con el Resource Manager y pide los recursos necesarios.
- El Application Manager notifica al Node Manager la ejecución de los contenedores. Se ejecuta la aplicación YARN en el/los contenedor/es correspondiente.
- El Application Master monitoriza la ejecución y reporta el estado al Resource Manager y al Application Manager.
- Al terminar la ejecución, el Application Manager lo notifica al Resource Manager.
YARN soporta la reserva de recursos mediante el Reservation System, un componente que permite a los usuarios especificar un perfil de recurso y restricciones temporales (deadlines) y posteriormente reservar recursos para asegurar la ejecución predecibles de las tareas importantes. Este sistema registra los recursos a lo largo del tiempo, realiza control de admisión para las reservas, e informa dinámicamente al planificador para asegurarse que se produce la reserva.
Para conseguir una alta escalabilidad (del orden de miles de nodos), YARN ofrece el concepto de Federación. Esta funcionalidad permite conectar varios clústeres YARN y hacerlos visibles como un clúster único. De esta forma puede ejecutar trabajos muy pesados y distribuidos.
Hadoop v1
MapReduce en hadoop-2.x mantiene la compatibilidad del API con versiones previas (hadoop-1.x). De esta manera, todo los jobs de MapReduce funcionan perfectamente con YARN sólo recompilando el código.
En Hadoop v1 los componentes encargados de realizar el procesamiento eran el JobTracker (situado en el Namenode) y los TaskTracker (situados en los Datanodes).
Instalación¶
Para trabajar en esta y las siguientes sesiones, vamos a utilizar la máquina virtual que tenemos compartida en Aules. A partir de la OVA de VirtualBox, podrás entrar con el usuario iabd y la contraseña iabd.
Si quieres instalar el software del curso, se recomienda crear una máquina virtual con cualquier distribución Linux. En mi caso, yo lo he probado en la versión Lubuntu 22.04 LTS y la versión 3.3.1 de Hadoop. Puedes seguir las instrucciones del artículo Cómo instalar Apache Hadoop en Ubuntu 22.04.
Para trabajar en local tenemos montada una solución que se conoce como pseudo-distribuida, porque es al mismo tiempo maestro y esclavo. En el mundo real o si utilizamos una solución cloud tendremos un nodo maestro y múltiples nodos esclavos.
Hadoop y Docker
Desde mediados del 2023 ya existen imágenes oficiales de Hadoop para Docker.
Para ponerlo en marcha, necesitaremos un fichero docker-compose.yaml con la definición de los contenedores y un fichero de propiedades config con la configuración.
services:
namenode:
image: apache/hadoop:3
container_name: iabd-namenode
hostname: namenode
command: ["hdfs", "namenode"]
ports:
- 9870:9870
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
datanode:
image: apache/hadoop:3
container_name: iabd-datanode
command: ["hdfs", "datanode"]
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3
container_name: iabd-resourcemanager
hostname: resourcemanager
command: ["yarn", "resourcemanager"]
ports:
- 8088:8088
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3
hostname: nodemanager
container_name: iabd-nodemanager
command: ["yarn", "nodemanager"]
env_file:
- ./config
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
HDFS-SITE.XML_dfs.replication=1
MAPRED-SITE.XML_mapreduce.framework.name=yarn
MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
Si colocamos ambos ficheros en la misma carpeta, creamos los contenedores mediante docker-compose:
docker-compose -p iabd-hadoop up -d
Y podremos conectarnos, por ejemplo al namenode, mediante:
docker exec -it iabd-namenode /bin/bash
Configuración¶
Los archivos que vamos a revisar a continuación se encuentran dentro de la carpeta $HADOOP_HOME/etc/hadoop (tanto en la máquina virtual como mediante Docker el raíz de Hadoop es /opt/hadoop)
El archivo que contiene la configuración general del clúster es el archivo core-site.xml. En él se configura cual será el sistema de ficheros, que normalmente será hdfs, indicando el dominio del nodo que será el maestro de datos (namenode) de la arquitectura. Por ejemplo, su contenido será similar al siguiente:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://iabd-virtualbox:9000</value>
</property>
</configuration>
El siguiente paso es configurar el archivo hdfs-site.xml donde se indica tanto el factor de replicación como la ruta donde se almacenan tanto los metadatos (namenode) como los datos en sí (datanode):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-data/hdfs/datanode</value>
</property>
</configuration>
Recuerda
Si tuviésemos un clúster, en el nodo maestro sólo configuraríamos la ruta del namenode y en cada uno de los nodos esclavos, únicamente la ruta del datanode.
Para configurar YARN, primero editaremos el archivo yarn-site.xml para indicar quien va a ser el nodo maestro, así como el manejador y la gestión para hacer el MapReduce:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>iabd-virtualbox</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Y finalmente el archivo mapred-site.xml para indicar que utilice YARN como framework MapReduce:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
En la primera ejecución, hemos de formatear el sistema de ficheros distribuido HDFS mediante el comando (este paso ya está realizado en la máquina virtual):
hdfs namenode -format
Hadoop en AWS
Si no quieres (o puedes) ejecutar la máquina virtual o emplear Docker, puedes utilizar un servicio en la nube como AWS EMR (que veremos en una sesión más adelante).
Puesta en marcha¶
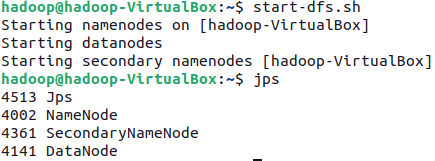
Para arrancar Hadoop/HDFS, hemos de ejecutar el comando start-dfs.sh. Al finalizar, veremos que ha arrancado el namenode, los datanodes, y el secondary namenode.
Si en cualquier momento queremos comprobar el estado de los servicios y procesos en ejecución, tenemos el comando jps.
Si accedemos a http://iabd-virtualbox:9870/ podremos visualizar su interfaz web.

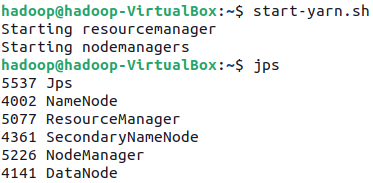
Para arrancar YARN utilizaremos el comando start-yarn.sh para lanzar el Resource Manager y el Node Manager:
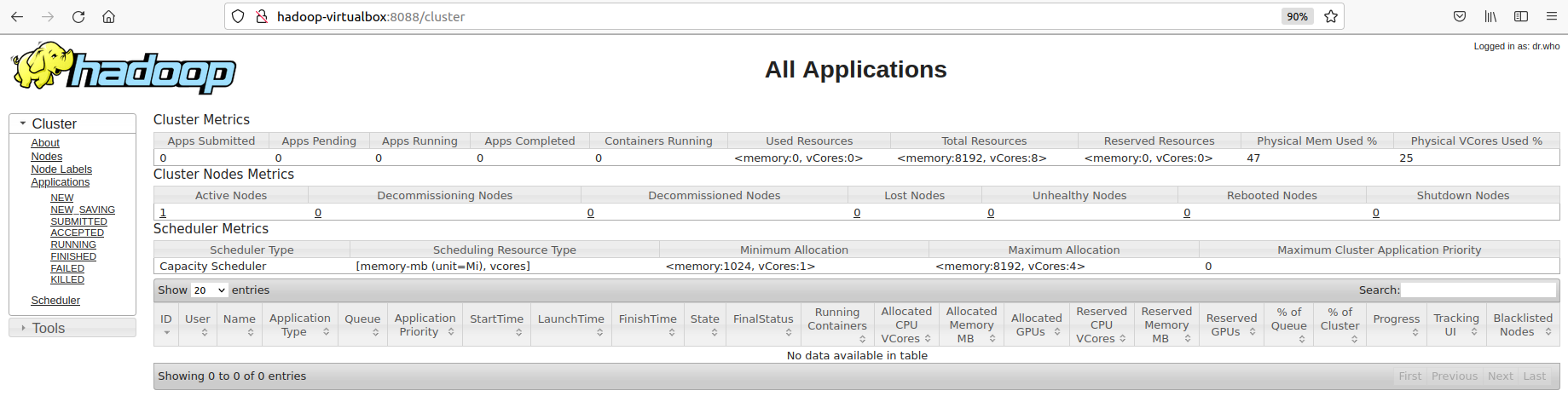
Y a su vez, YARN también ofrece un interfaz web para obtener información relativa a los jobs ejecutados. Nos conectaremos con el nombre del nodo principal y el puerto 8088. En nuestro caso lo hemos realizado a http://iabd-virtualbox:8088 obteniendo la siguiente página:
Hola Mundo¶
El primer ejemplo que se realiza como Hola Mundo en Hadoop suele ser una aplicación que cuente las ocurrencias de cada palabra que aparece en un documento de texto.
En nuestro caso, vamos a contar las palabras del libro de El Quijote, el cual podemos descargar desde https://gist.github.com/jsdario/6d6c69398cb0c73111e49f1218960f79.
Una vez arrancado Hadoop y YARN, vamos a colocar el libro dentro de HDFS (estos comandos los estudiaremos en profundidad en la siguiente sesión):
hdfs dfs -put el_quijote.txt /user/iabd/
Hadoop tiene una serie de ejemplos ya implementados para demostrar el uso de MapReduce en la carpeta $HADOOP_HOME/share/hadoop/mapreduce. Así pues, podemos ejecutar el programa wordcount de la siguiente manera:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar \
wordcount /user/iabd/el_quijote.txt /user/iabd/salidaWC
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar \
wordcount /user/iabd/el_quijote.txt /user/iabd/salidaWC
Si nos fijamos en la salida del comando podremos ver una traza del proceso MapReduce:
2022-11-28 09:24:02,763 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at iabd-virtualbox/127.0.1.1:8032
2022-11-28 09:24:03,580 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/iabd/.staging/job_1669623168732_0001
2022-11-28 09:24:04,473 INFO input.FileInputFormat: Total input files to process : 1
2022-11-28 09:24:04,623 INFO mapreduce.JobSubmitter: number of splits:1
2022-11-28 09:24:05,313 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1669623168732_0001
2022-11-28 09:24:05,313 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-11-28 09:24:05,820 INFO conf.Configuration: resource-types.xml not found
2022-11-28 09:24:05,821 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-11-28 09:24:06,483 INFO impl.YarnClientImpl: Submitted application application_1669623168732_0001
2022-11-28 09:24:06,644 INFO mapreduce.Job: The url to track the job: http://iabd-virtualbox:8088/proxy/application_1669623168732_0001/
2022-11-28 09:24:06,645 INFO mapreduce.Job: Running job: job_1669623168732_0001
2022-11-28 09:24:20,124 INFO mapreduce.Job: Job job_1669623168732_0001 running in uber mode : false
2022-11-28 09:24:20,126 INFO mapreduce.Job: map 0% reduce 0%
2022-11-28 09:24:28,406 INFO mapreduce.Job: map 100% reduce 0%
2022-11-28 09:24:35,623 INFO mapreduce.Job: map 100% reduce 100%
2022-11-28 09:24:36,687 INFO mapreduce.Job: Job job_1669623168732_0001 completed successfully
Podemos observar como se crea un job que se envía a YARN, el cual ejecuta el proceso MapReduce, el cual tarda alrededor de 40 segundos. A continuación aparecen estadísticas del proceso:
2022-11-28 09:24:36,824 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=347063
FILE: Number of bytes written=1241507
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1060376
HDFS: Number of bytes written=257233
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6848
Total time spent by all reduces in occupied slots (ms)=4005
Total time spent by all map tasks (ms)=6848
Total time spent by all reduce tasks (ms)=4005
Total vcore-milliseconds taken by all map tasks=6848
Total vcore-milliseconds taken by all reduce tasks=4005
Total megabyte-milliseconds taken by all map tasks=7012352
Total megabyte-milliseconds taken by all reduce tasks=4101120
Map-Reduce Framework
Map input records=2186
Map output records=187018
Map output bytes=1808330
Map output materialized bytes=347063
Input split bytes=117
Combine input records=187018
Combine output records=22938
Reduce input groups=22938
Reduce shuffle bytes=347063
Reduce input records=22938
Reduce output records=22938
Spilled Records=45876
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1173
CPU time spent (ms)=4890
Physical memory (bytes) snapshot=751063040
Virtual memory (bytes) snapshot=5099941888
Total committed heap usage (bytes)=675282944
Peak Map Physical memory (bytes)=520818688
Peak Map Virtual memory (bytes)=2548346880
Peak Reduce Physical memory (bytes)=230244352
Peak Reduce Virtual memory (bytes)=2551595008
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1060259
File Output Format Counters
Bytes Written=257233
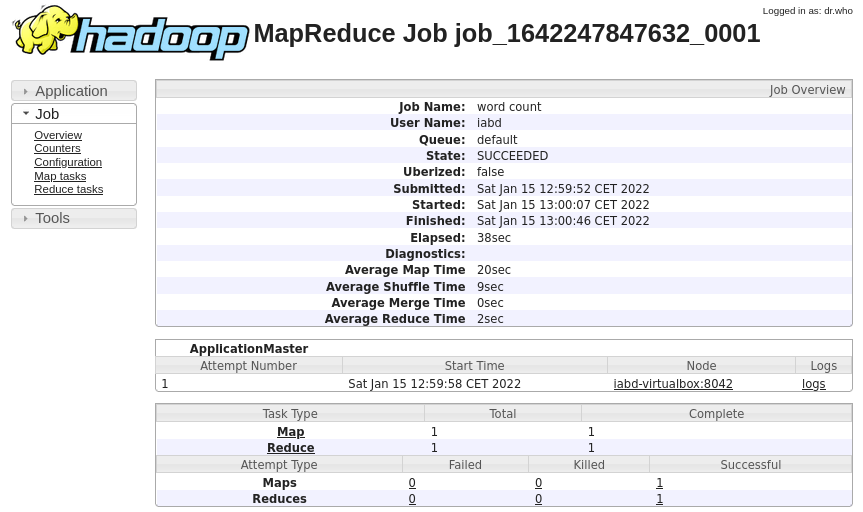
Para poder obtener toda la información de un job necesitamos arrancar el Job History Server:
mapred --daemon start historyserver
De manera que si accedemos a la URL que se visualiza en el log, podremos ver de forma gráfica la información obtenida:
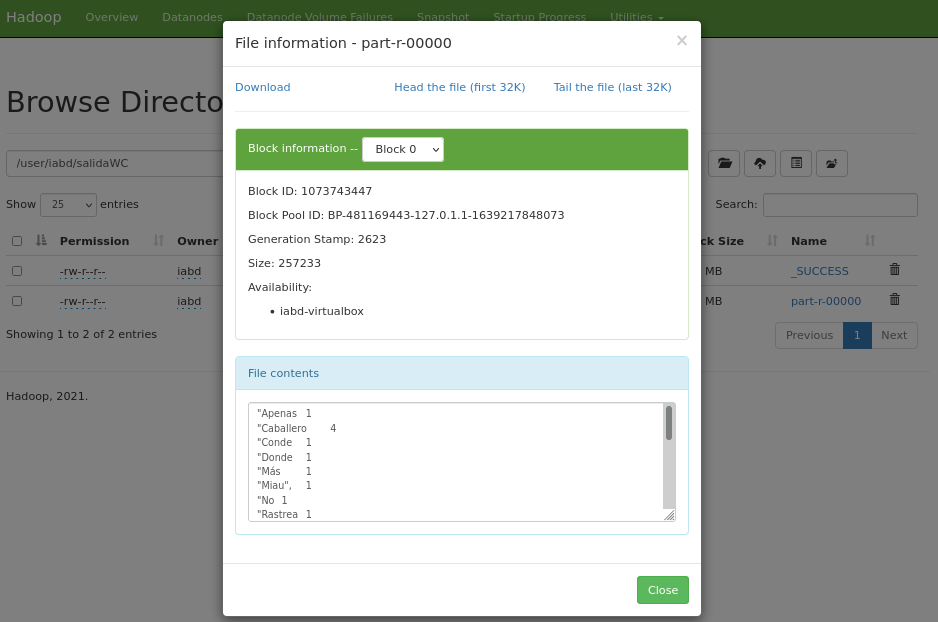
Si accedemos al interfaz gráfico de HDFS (http://iabd-virtualbox:9870/explorer.html#/user/iabd/salidaWC), podremos ver cómo se ha creado la carpeta salidaWC y dentro contiene dos archivos:
_SUCCESS: indica que el job de MapReduce se ha ejecutado correctamentepart-r-00000: bloque de datos con el resultado
Autoevaluación
¿Qué comando HDFS utilizarías para obtener el contenido de la carpeta /user/iabd/salidaWC? 1 ¿Y para obtener el contenido del archivo generado? 2
MapReduce en Python¶
El API de MapReduce está escrito en Java, pero mediante Hadoop Streaming podemos utilizar MapReduce con cualquier lenguaje compatible con el sistema de tuberías Unix (|).
Para entender cómo funciona, vamos a reproducir el ejemplo anterior mediante Python.
Mapper¶
Primero creamos el mapeador, el cual se encarga de parsear línea a línea el fragmento de documento que reciba, y va a generar una nueva salida con todas las palabras de manera que cada nueva línea la compongan una tupla formada por la palabra, un tabulador y el número 1 (hay una ocurrencia de dicha palabra)
#!/usr/bin/python3
import sys
for linea in sys.stdin:
# eliminamos los espacios de delante y de detrás
linea = linea.strip()
# dividimos la línea en palabras
palabras = linea.split()
# creamos tuplas de (palabra, 1)
for palabra in palabras:
print(palabra, "\t1")
Si queremos probar el mapper, podríamos ejecutar el siguiente comando:
cat el_quijote.txt | python3 mapper.py
Obteniendo un resultado similar a:
...
gritos 1
al 1
cielo 1
allí 1
se 1
renovaron 1
las 1
maldiciones 1
...
Reducer¶
A continuación, en el reducer vamos a recibir la salida del mapper y parsearemos la cadena para separar la palabra del contador.
Para llevar la cuenta de las palabras, vamos a meterlas dentro de un diccionario para incrementar las ocurrencias encontradas.
Cuidado con la memoria
En un caso real, hemos de evitar almacenar todos los datos que recibimos en memoria, ya que es posible que al trabajar con big data no quepa en la RAM de cada datanode. Para ello, se recomienda el uso de la librería itertools, por ejemplo, utilizando la función groupby().
Finalmente, volvemos a crear tuplas de palabra, tabulador y cantidad de ocurrencias.
#!/usr/bin/python3
import sys
# inicializamos el diccionario
dictPalabras = {}
for linea in sys.stdin:
# quitamos espacios de sobra
linea = linea.strip()
# parseamos la entrada de mapper.py
palabra, cuenta = linea.split('\t', 1)
# convertimos cuenta de string a int
try:
cuenta = int(cuenta)
except ValueError:
# cuenta no era un numero, descartamos la linea
continue
try:
dictPalabras[palabra] += cuenta
except:
dictPalabras[palabra] = cuenta
for palabra in dictPalabras.keys():
print(palabra, "\t", dictPalabras[palabra])
Para probar el proceso completo, ejecutaremos el siguiente comando:
cat el_quijote.txt | python3 mapper.py | python3 reducer.py > salida.tsv
Si abrimos el fichero, podemos ver el resultado:
don 1072
quijote 812
de 9035
la 5014
mancha 50
miguel 3
cervantes 3
...
Hadoop Streaming¶
Una vez comprobados que los algoritmos de mapeo y reducción funcionan, vamos a procesarlos dentro de Hadoop para aprovechar la computación distribuida.
Para ello, haremos uso de Hadoop Streaming, el cual permite ejecutar jobs Map/Reduce con cualquier script (y por ende, codificados en cualquier lenguaje de programación) que pueda leer de la entrada estándar (stdin) y escribir a la salida estándar (stdout). De este manera, Hadoop Streaming envía los datos en crudo al mapper vía stdin y tras procesarlos, se los pasa al reducer vía stdout.
La sintaxis para ejecutar los jobs es:
mapred streaming \
-input miCarpetaEntradaHDFS \
-output miCarpetaSalidaHDFS \
-mapper scriptMapper \
-reducer scriptReducer
Versiones 1.x
En versiones más antiguas de Hadoop, en vez de utilizar el comando mapred, se utiliza el comando hadoop jar rutaDeHadoopStreaming.jar <parámetros>, siendo normalmente la ruta del jar $HADOOP_HOME/share/hadoop/tools/lib.
Así pues, en nuestro caso ejecutaríamos el siguiente comando si tuviésemos los archivos (tanto los datos como los scripts) dentro de HDFS:
mapred streaming \
-input el_quijote.txt \
-output salidaPy \
-mapper mapper.py \
-reducer reducer.py
Permisos de ejecución
Recuerda darle permisos de ejecución a ambos scripts (chmod u+x mapper.py y chmod u+x reducer.py) para que Hadoop Streaming los pueda ejecutar
Como queremos usar los archivos que tenemos en local, debemos indicar cada uno de los elementos mediante el parámetro -file. Así pues, con el siguiente comando, cogerá como fichero de entrada el_quijote.txt desde HDFS en la ruta /user/iabd, colocará la salida en HDFS en la ruta /user/iabd/salidaPy (y fallará si dicha carpeta ya existe, por lo que deberías eliminarla previamente mediante hdfs dfs -rm -r /user/iabd/salidaPy), y utilizará los scripts de Python desde la carpeta local donde se ejecuta el comando:
mapred streaming \
-input el_quijote.txt \
-output salidaPy \
-mapper mapper.py -file mapper.py \
-reducer reducer.py -file reducer.py
Una vez finalizado el job, podemos comprobar cómo se han generado el resultado en HDFS mediante:
hdfs dfs -head /user/iabd/salidaPy/part-00000
Referencias¶
- Documentación de Apache Hadoop.
- Hadoop: The definitive Guide, 4th Ed - de Tom White - O'Reilly
- Artículo de Hadoop por dentro.
- Tutorial de Hadoop de Tutorialspoint.
Actividades¶
Para los siguientes ejercicios, copia el comando y/o haz una captura de pantalla donde se muestre el resultado de cada acción.
-
(RABDA.2 / CEBDA.2b / opcional) Sobre Hadoop, ejecuta el siguiente comando y explica qué sucede:
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 8 24Al cambiar los valores de 8 y de 24, ¿qué estamos cambiando relamente? ¿El resultado varía?
-
(RABDA.2 / CEBDA.2b / 2p) Vuelve a contar las palabras que tiene El Quijote, pero haciendo usos de los scripts Python, teniendo en cuenta que el proceso de mapeo va a limpiar las palabras de signos ortográficos (quitar puntos, comas, paréntesis) y en el reducer vamos a considerar que las palabras en mayúsculas y minúsculas son la misma palabra.
- Tip: para la limpieza, puedes utilizar el método de
stringtranslatede manera que elimine lasstring.punctuation.
Debes ejecutar ambos script como procesos MapReduce mediante Hadoop Streaming y comprobar en HDFS el archivo que se ha creado.
- Tip: para la limpieza, puedes utilizar el método de
-
(RABDA.4 / CEBDA.4a / 1p) Entra en Hadoop UI y en YARN, y visualiza los procesos que se han ejecutado en las actividades 1 y 2, comprobando la configuración tanto en Hadoop UI como en YARN así como la ejecución de los jobs arrancando el Job History Server.