Lambda
AWS Lambda¶
La informática serverless permite crear y ejecutar aplicaciones y servicios sin aprovisionar ni administrar servidores, es decir, los servidores siguen existiendo pero son invisibles para los desarrolladores de servicios.
AWS Lambda (https://aws.amazon.com/es/lambda/) es un servicio de informática sin servidor que proporciona tolerancia a errores y escalado automático, y que se factura por el tiempo de ejecución (cantidad de milisegundos por el número de invocaciones a la función). Para ello, permite la ejecución de código en el servidor con soporte para múltiples lenguajes (Java, C#, Python, Go, ...) sin necesidad de configurar una instancia EC2.
Otras plataformas serverless
Si no trabajamos con AWS, podemos utilizar las Google Cloud Functions o las Azure Functions.
De esta manera, no tenemos que preocuparnos de elegir el tipo de instancia, es decir, no tenemos que pensar en cantidades de procesadores o memoria necesaria, ni instalar actualizaciones del sistema operativo o gestionar las conexiones remotas.
Respecto al pago, no tendremos que pagar por infraestructura cuando el código no se ejecuta, sabiendo que sólo se va a ejecutar cuando nosotros queramos.
Los pasos para desarrollar una función serverless son:
- Codificar la funcionalidad en nuestro lenguaje de programación preferido.
- Subir el código y las dependencias (como librerías o módulos)
- Crear la función determinando el entorno de ejecución
- Invocar la función para ejecutar el código en la nube.
Por último, definimos como origen de eventos a un servicio de AWS (S3, DynamoDB, Elastic Load Balancing...) o una aplicación creada por un desarrollador que desencadena la ejecución de una función de Lambda. Además, podemos encadenar funciones Lambda para flujos de trabajo mediante AWS Step Functions.
Creando una función¶
Al crear una función Lambda, primero le asignaremos un nombre a la función. Tras elegir el entorno de ejecución (versión de Python, Node.js, etc...), hemos de elegir el rol de ejecución (en el caso de AWS Academy, elegimos el rol LabRole), mediante un permiso de IAM, dependiendo de los servicios con los que tenga que interactuar...(al menos el rol AWSLambdaBasicExecutionRole y AWSLambdaVPCAccessExecutionRole).
Respecto a la configuración de la función, deberemos:
- Agregar un desencadenador / origen de evento.
- Agregar el código de la función.
- Especificar la cantidad de memoria en MB que se asignará a la función (de 128MB a 3008MB)
- Si queremos, podemos configurar las variables del entorno, la descripción, el tiempo de espera, la VPC específica en la que se debe ejecutar la función, las etiquetas que desea utilizar y otros ajustes.
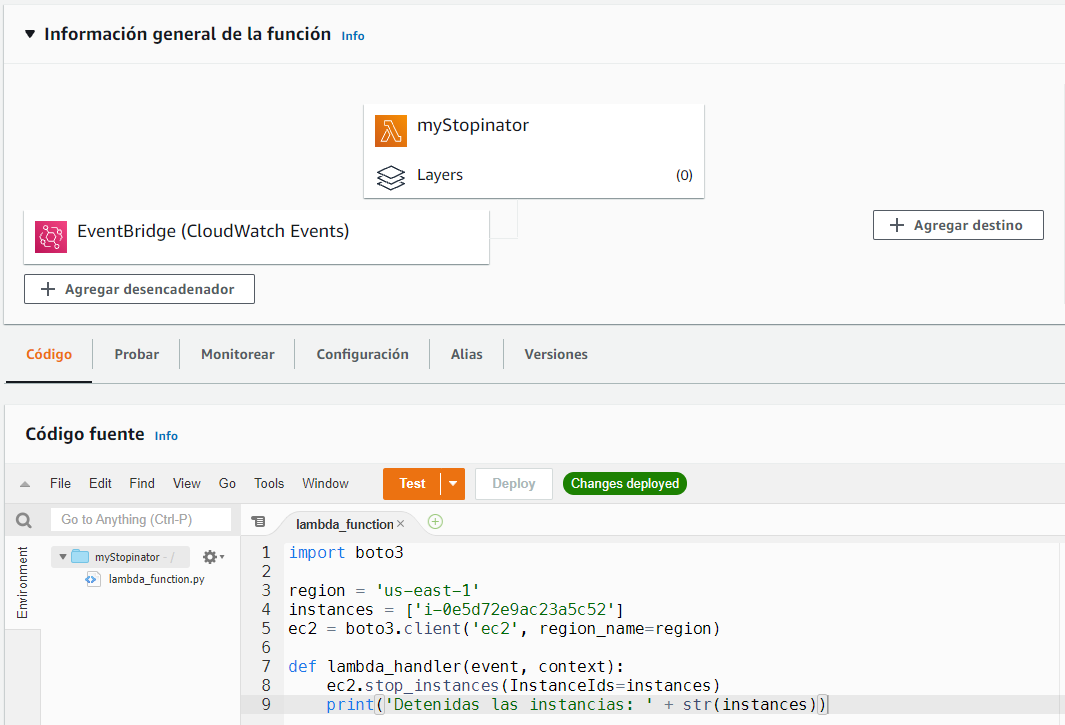
Cargando código
Además de poder utilizar el IDE que ofrece AWS, podemos subir nuestras propias funciones en formato zip o desde S3. El fichero que contiene las funciones por defecto se llamará lambda_function y el manejador def_handler. Si queremos cambiar alguno de esos nombres, hay que editar el controlador en la configuración en tiempo de ejecución de la función.
Precios¶
Ya hemos comentado que AWS Lambda no tiene costes asociados a la infraestructura en sí, si no a la ejecución de las funciones. Así pues, el coste de AWS Lambda va a depender directamente de tres elementos:
- Cantidad de invocaciones de las funciones, siendo el primer millón de peticiones realizadas cada mes gratuitas, y posteriormente, $0.0000002 por petición.
- Tiempo de ejecución empleado, siendo los primeros 400 000 GB/segundos de tiempo de computación al mes gratuitos, y posteriormente 0,0000166667 USD por cada GB/segundo
- Memoria reservada para la ejecución, pudiendo reservar desde 128 MB a 10.240 MB en incrementos de 1 MB, siendo el precio de los 128 MB de $0,0000000021.
Si nuestras aplicaciones no tienen un volumen elevadísimo de peticiones y el gasto de tiempo y memoria es normal, el uso de AWS Lambda puede reducir muchísimos los costes de su despliegue:
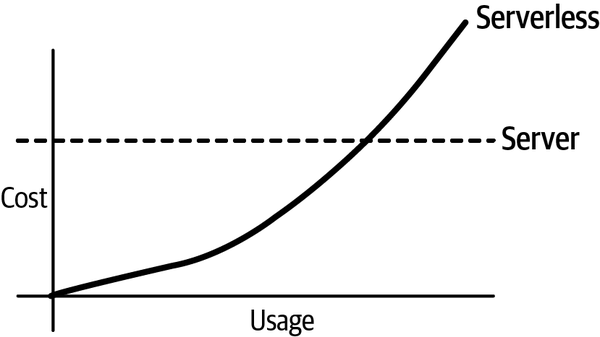
Más información en https://aws.amazon.com/es/lambda/pricing/
Restricciones¶
Las restricciones más destacables son:
- Permite hasta 1000 ejecuciones simultáneas en una única región.
- La cantidad máxima de memoria que se puede asignar para una sola función Lambda es de 3008 MB.
- El tiempo de ejecución máximo para una función Lambda es de 15 minutos.
Consejos de uso
- Tratar las funciones como stateless
- Incluir sólo lo necesario, minimizando las dependencias
- Reutilizar el entorno de ejecución temporal (fragmento de código que queda fuera del manejador)
- Incluir sentencias de log
- Utilizar variables de entorno, por ejemplo, para el nombre de los buckets o cadenas de conexión.
Caso de uso 1: Comprobar web¶
Vamos a comprobar el estado de salud de una web utilizando una de las plantillas que ofrece AWS Lambda.
Cloudwatch
Si quieres más información sobre Cloudwatch, te recomiendo consultar la sesión sobre Monitorización.
Vamos a emplear EventBridge para crear eventos que disparen la función Lambda, por ejemplo cada minuto tal como haría un comando cron, y publicaremos el resultado en CloudWatch para inspeccionar las métricas y monitorizar los recursos, pudiendo crear una alarma que nos envíe un mail cuando la web se haya caído.
Creando la función¶
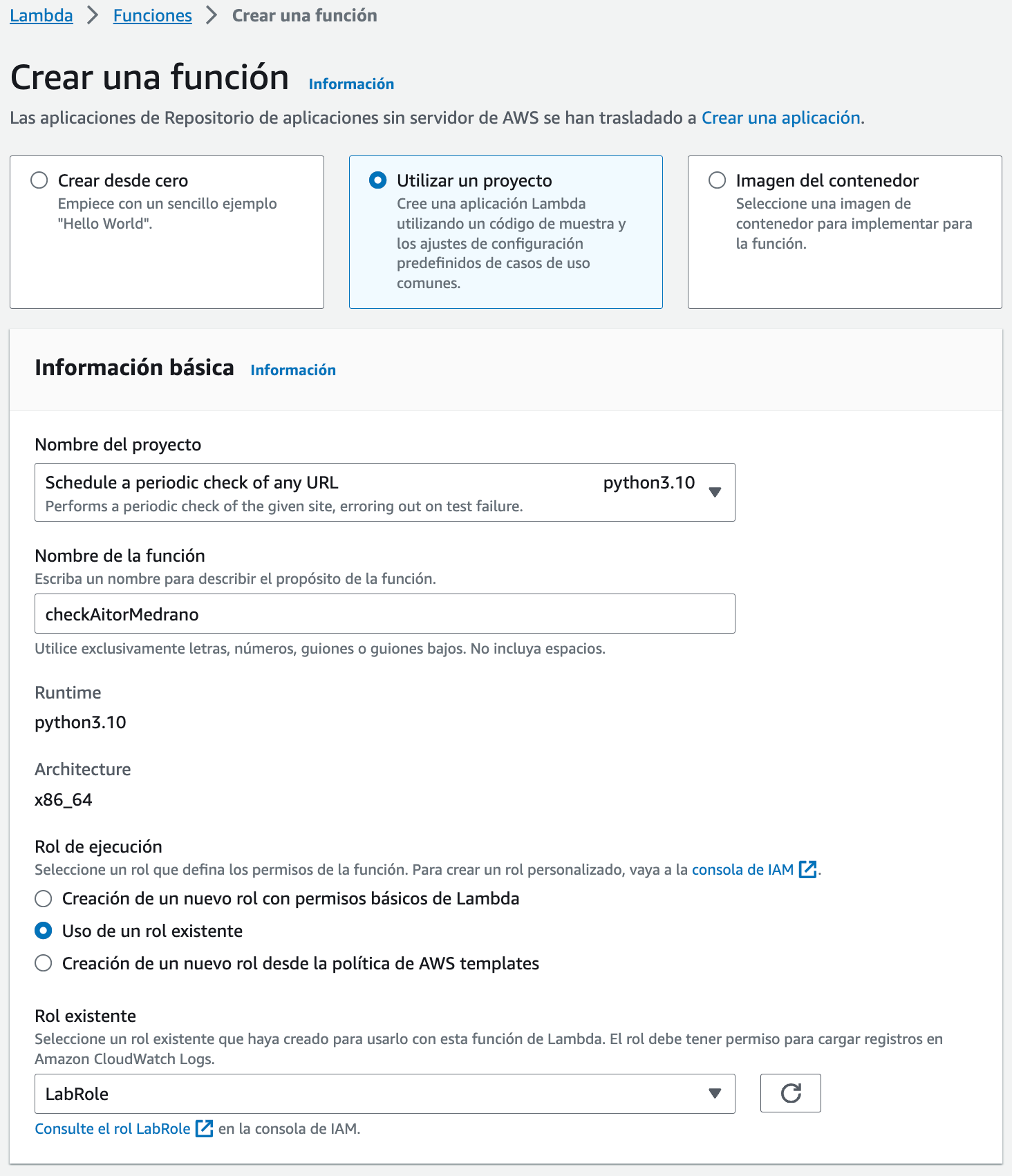
Así pues, vamos a crear una nueva función, y utilizaremos un nuevo proyecto de tipo Schedule a periodic check of any URL, le pondremos un nombre a la función y elegiremos el rol LabRole (ya lo tenemos creado en la cuenta AWS Academy):
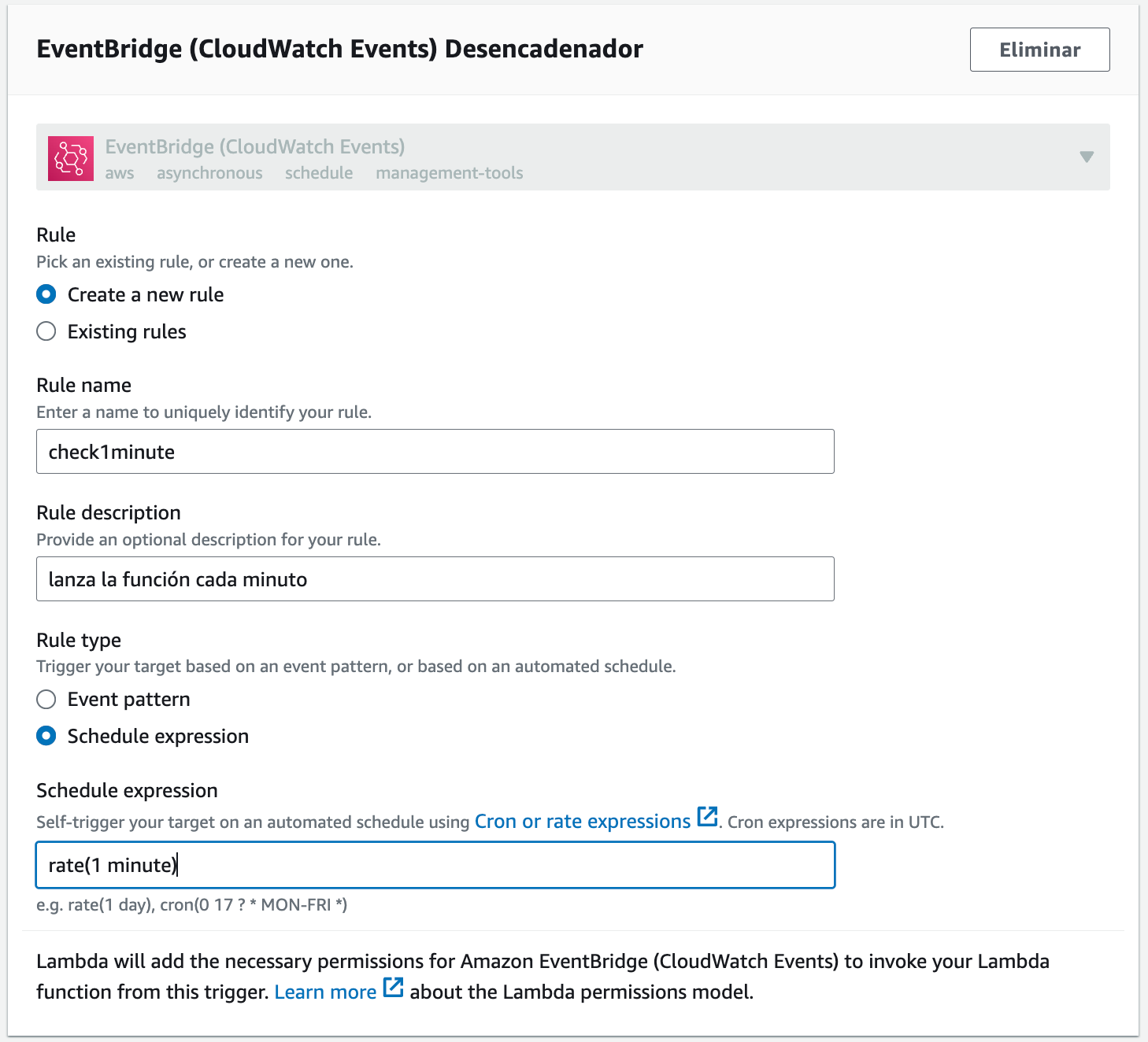
A continuación, más abajo, configuraremos EventBridge para crear una nueva regla, ya sea mediante una expresión cron o un valor periódico mediante una expresión rate (en nuestro caso, como queremos que para este ejercicio se ejecute cada minuto, hemos empleado rate(1 minute)):
Y por último, mediante variables de entorno, introducimos los valores de la web a comprobar y el texto a buscar:
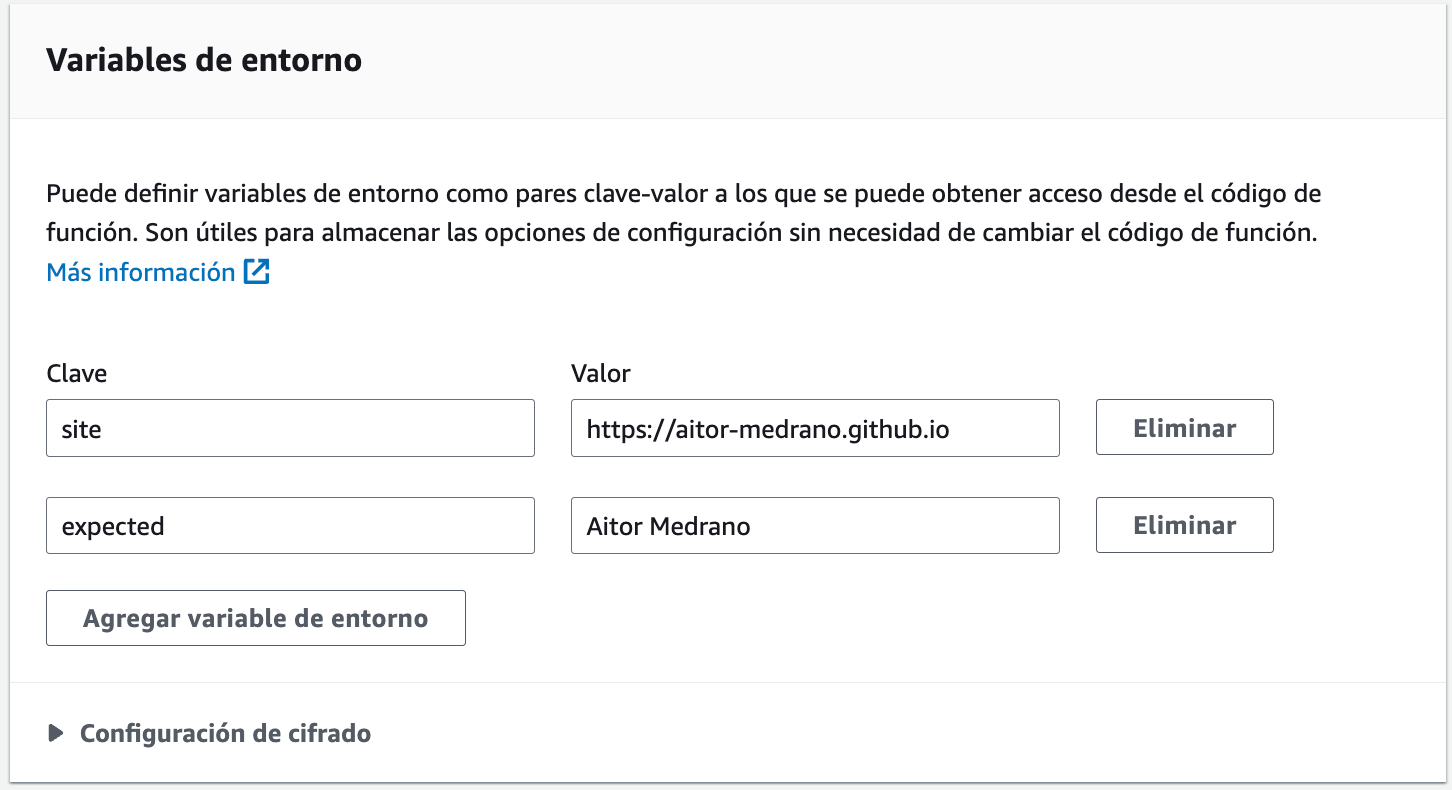
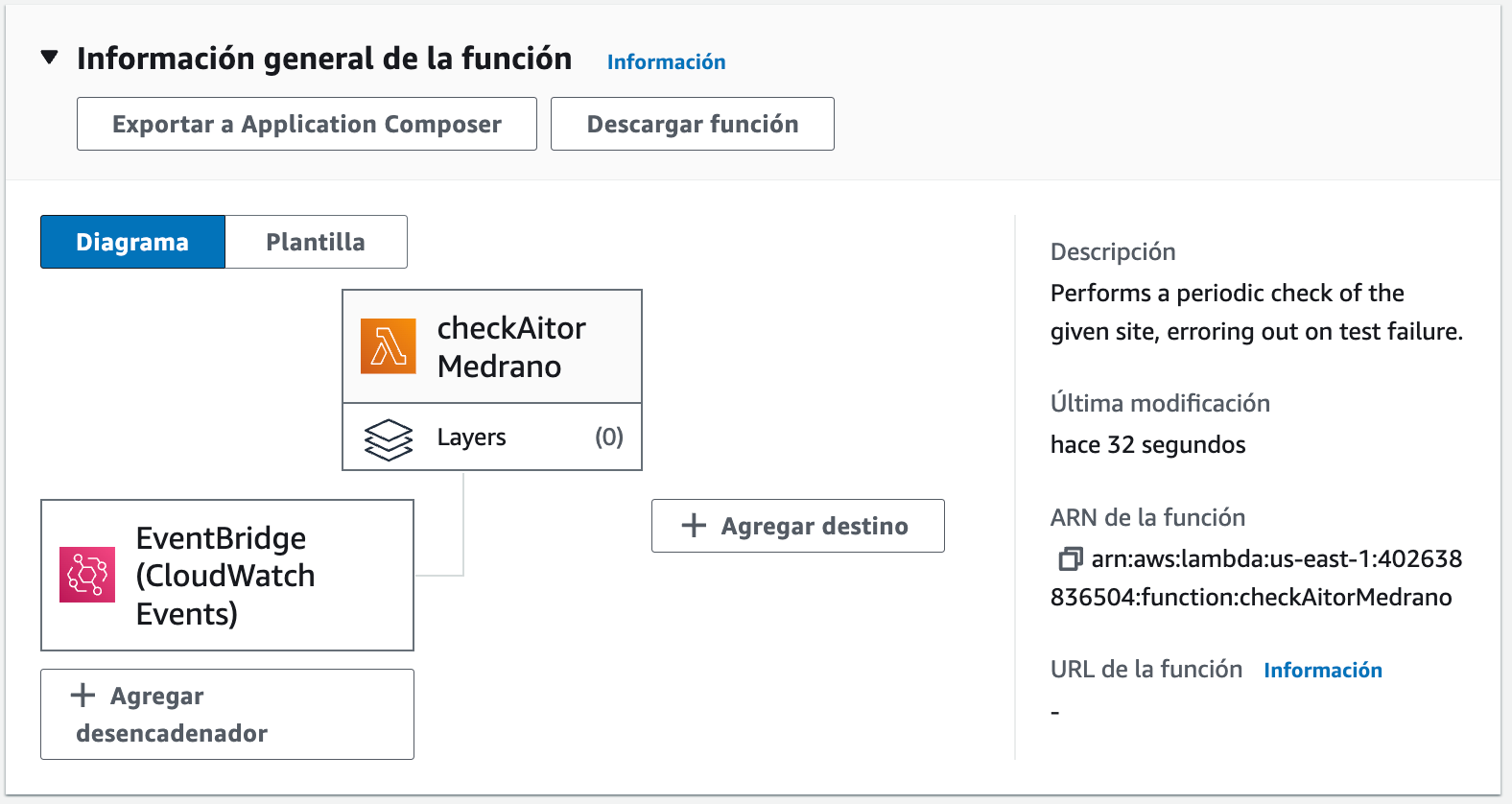
Tras crear la función, podemos ver un resumen gráfico, donde aparece el desencadenador de EventBridge y la función creada:
Comprobando si funciona¶
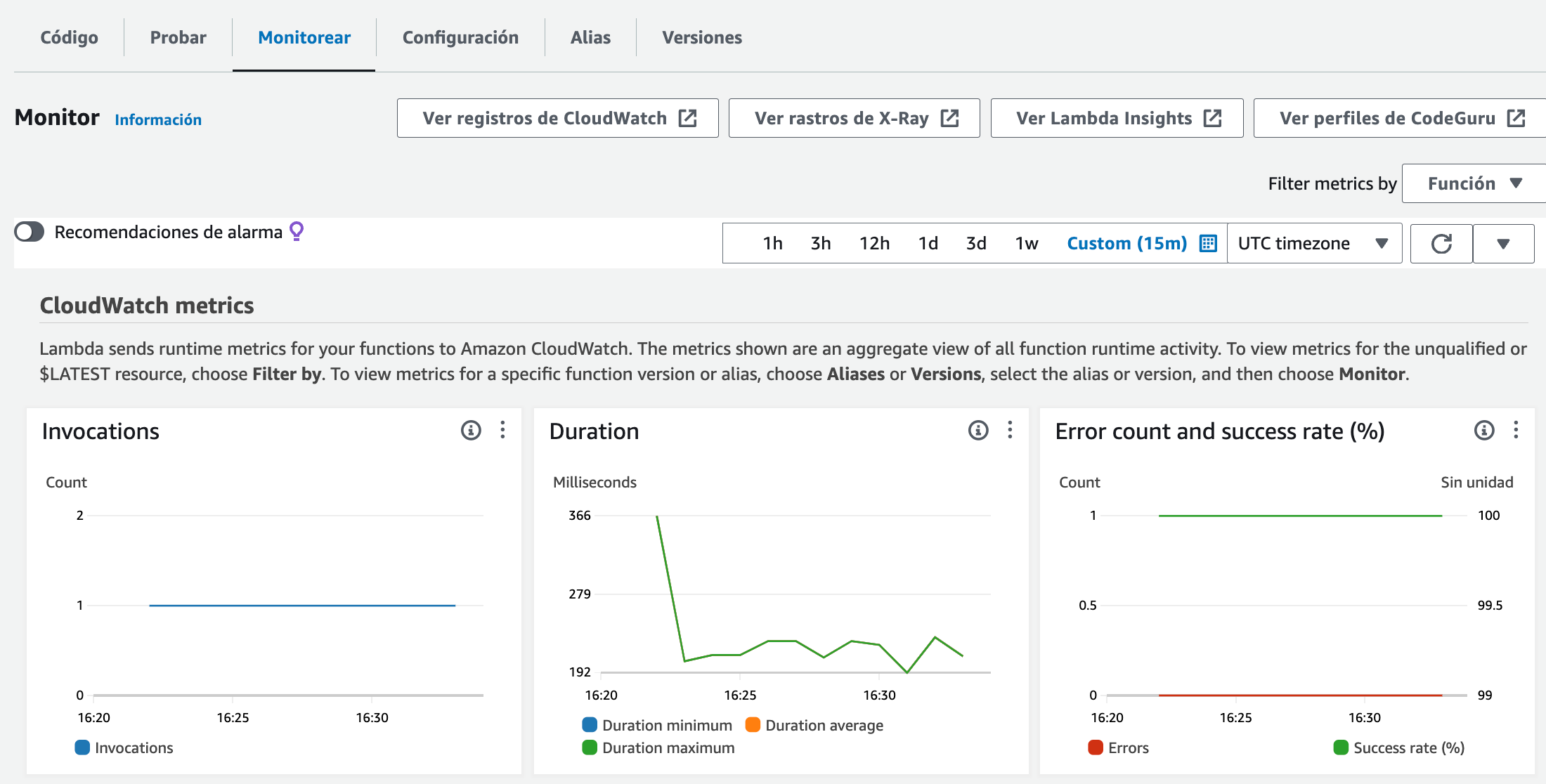
Para comprobar el resultado, podemos emplear la pestaña de Monitorear y comprobar el resultado de los cuadros Invocations, donde podemos ver la cantidad de peticiones realizadas, Duration, con el tiempo empleado por cada llamada y Error count and success que es la que nos va a indicar cuantas comprobaciones han sido exitosas o no
En nuestro caso, hemos esperado un rato para que se ejecuten varias llamadas, y el resultado es el siguiente:
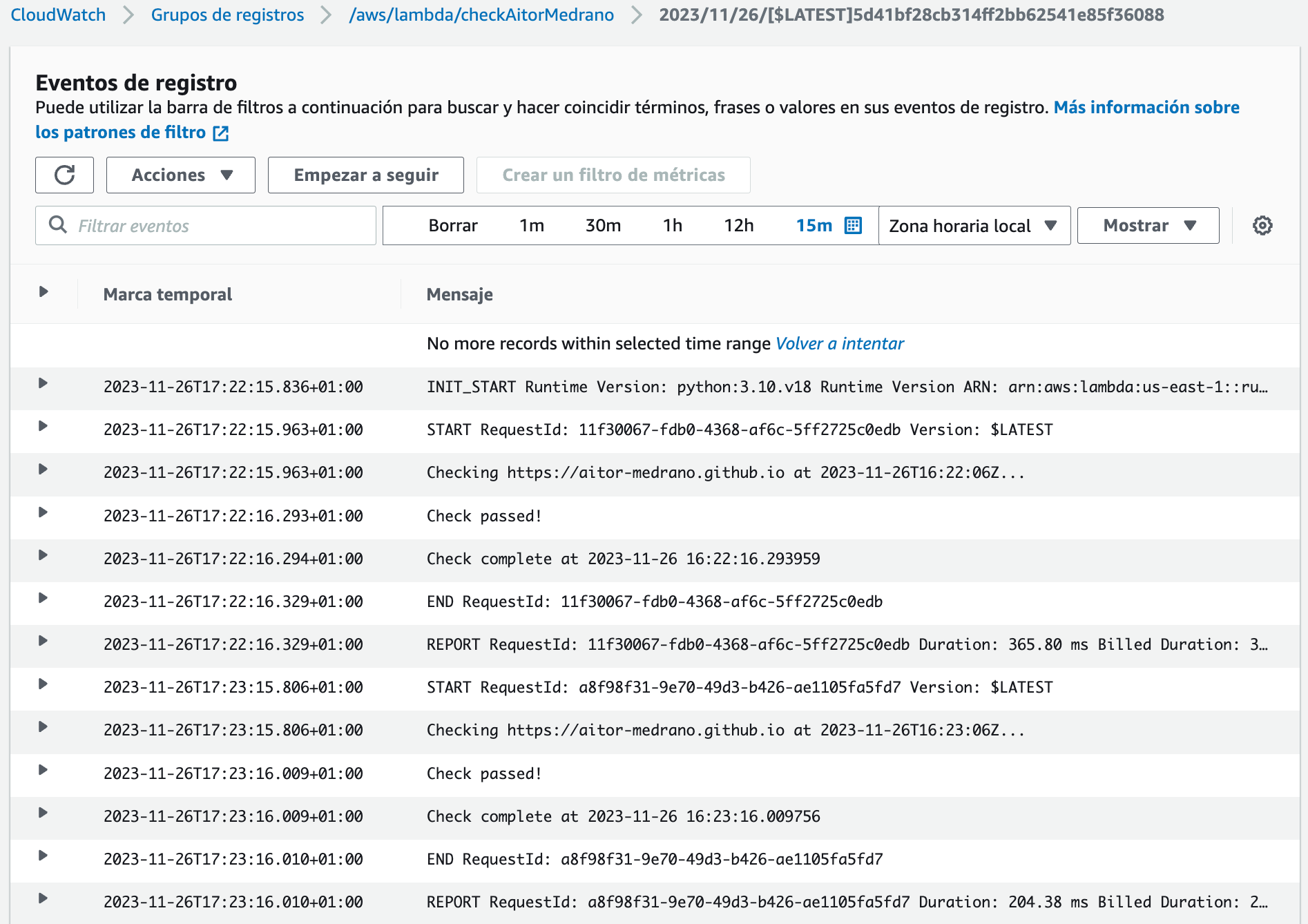
Si queremos ver los ficheros de log creados, pulsamos sobre el botón Ver registros de Cloudwatch y una vez cargado, hacemos click sobre el último registro de eventos, comprobaremos los mensajes (puedes buscar la cadena Check passed!):
Creando una alarma¶
Y si falla, ¿cómo me entero? Para ello, podemos crear una alarma en CloudWatch. Para ello, en el menú lateral de Cloudwath, en Todas las alarmas, seleccionamos Crear alarma.
El primer paso es elegir la métrica que va a monitorizar. En nuestro caso:
-
Elegiremos la métrica Lambda
Seleccionamos la métrica Lambda en Cloudwatch -
Seleccionamos por Nombre de función
-
Buscamos el nombre de nuestra función (en mi caso
checkAitorMedrano) y la métrica de error: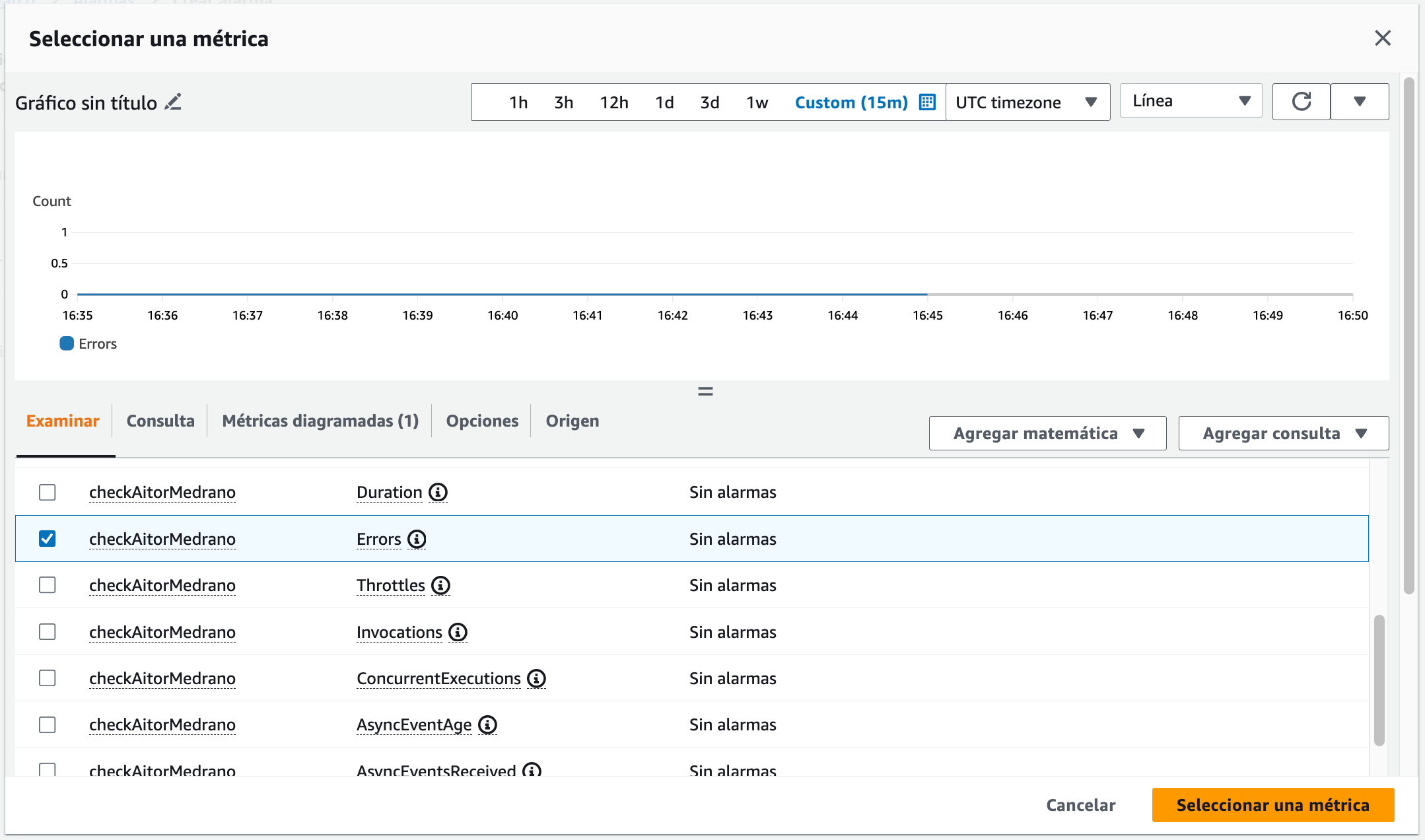
Configuramos la métrica de error En el gráfico podemos observar como todos los valores obtenidos son 0, lo que implica que no haya fallado nunca.
Otras métricas
Además del valor error, podemos monitorizar otras propiedades, destacando:
- Invocations: cantidad de llamadas a la función, sean exitosas o no.
- Duration: tiempo empleado en ejecutar la función
- Throttles: cantidad de llamadas que no han podido ser atendidas por superar el límite configurado en AWS Lambda.
Se recomienda siempre crear alarmas sobre las propiedades errors y throttles para vigilar el correcto funcionamiento.
-
Tras añadir la métrica, nos centramos en configurar la alarma. Para ello, vamos a cambiar el cálculo a la suma, y una condición de mayor que 0:
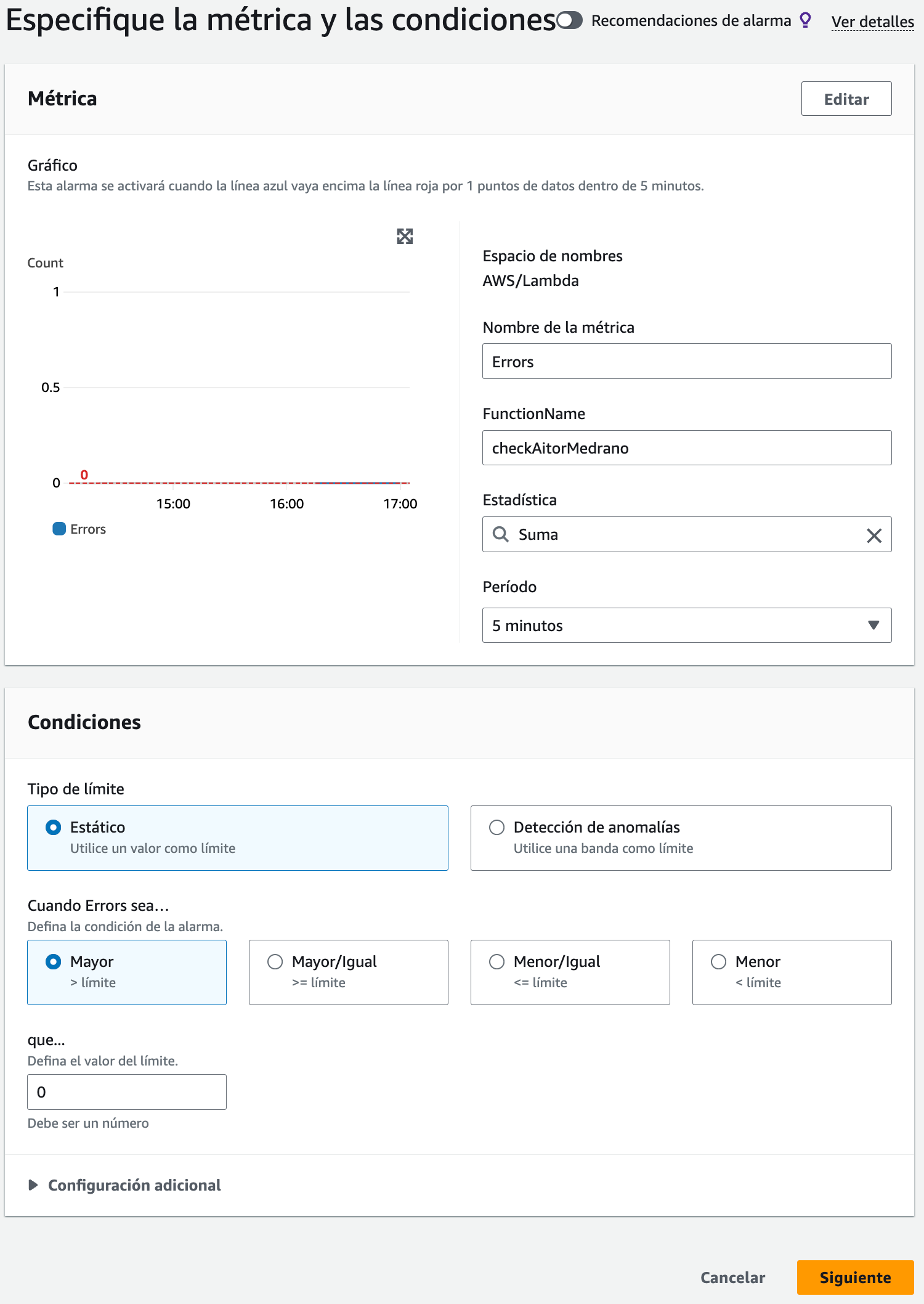
Configuramos la alarma -
A continuación, vamos a crear una acción para cuando salte la alarma. Así pues, seleccionamos En modo alarma, y creamos un nuevo tema SNS que va a recibir una notificación cuando salte la alarma al detectar un error en los últimos 5 minutos. Para el tema, le ponemos un nombre y le indicamos un email que notificará cuando salte la alarma:
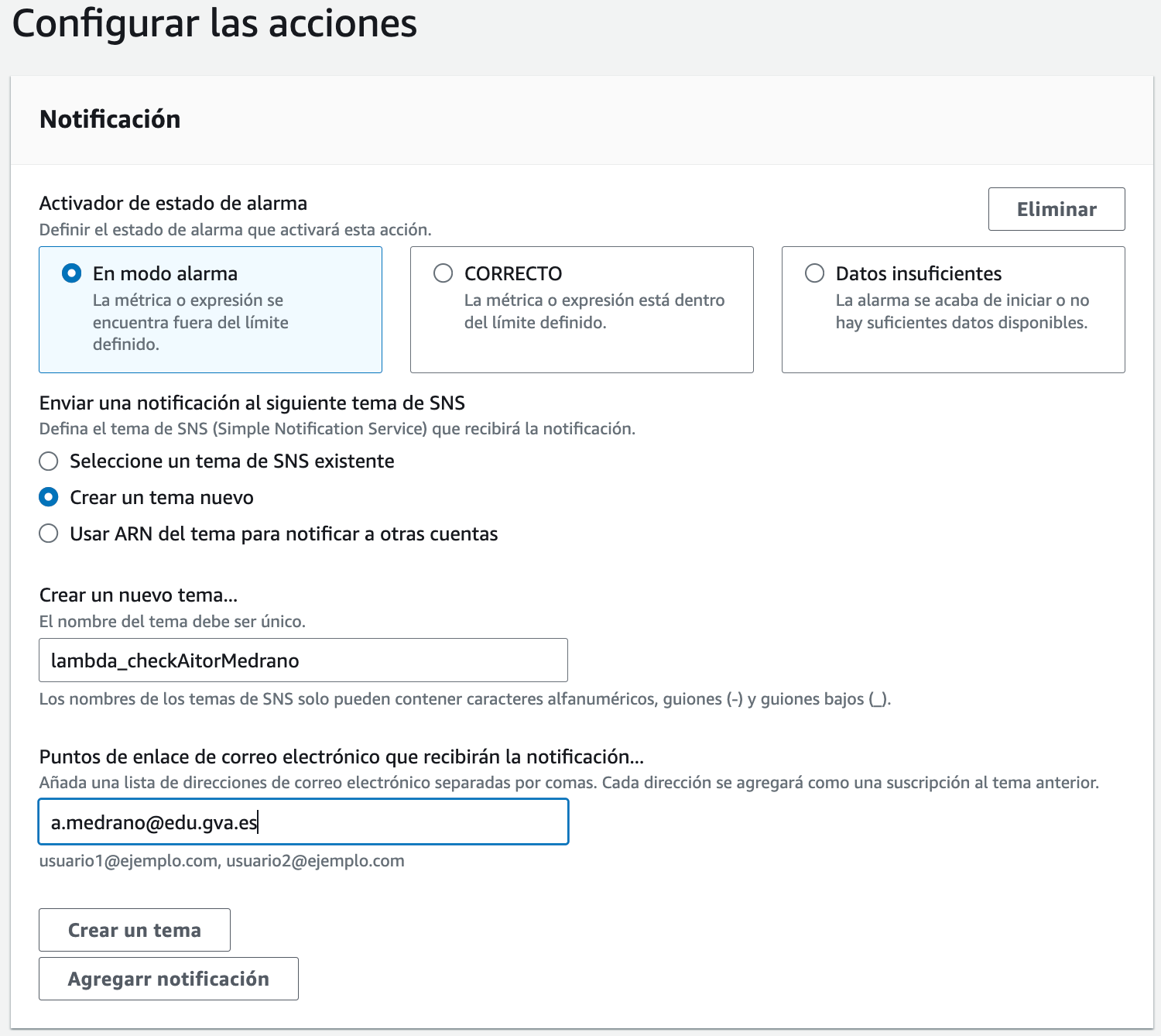
Configuramos la acción de la alarma Tras crear el tema, pulsamos Siguiente.
-
Le ponemos nombre a la alarma (
checkAitorMedranoAlarm) y una descripción. - Visualizamos el resumen y finalmente creamos definitivamente la alarma.
Confirmar la suscripción al email
Antes de poder ejecutar la alarma, es conveniente acceder a nuestro email y confirmar la suscripción al tema SNS.
Para comprobar la alarma, volvemos a la función Lambda y modificamos la variable de entorno expected, y le ponemos un valor que no existe en la página, como por ejemplo, Lambda.
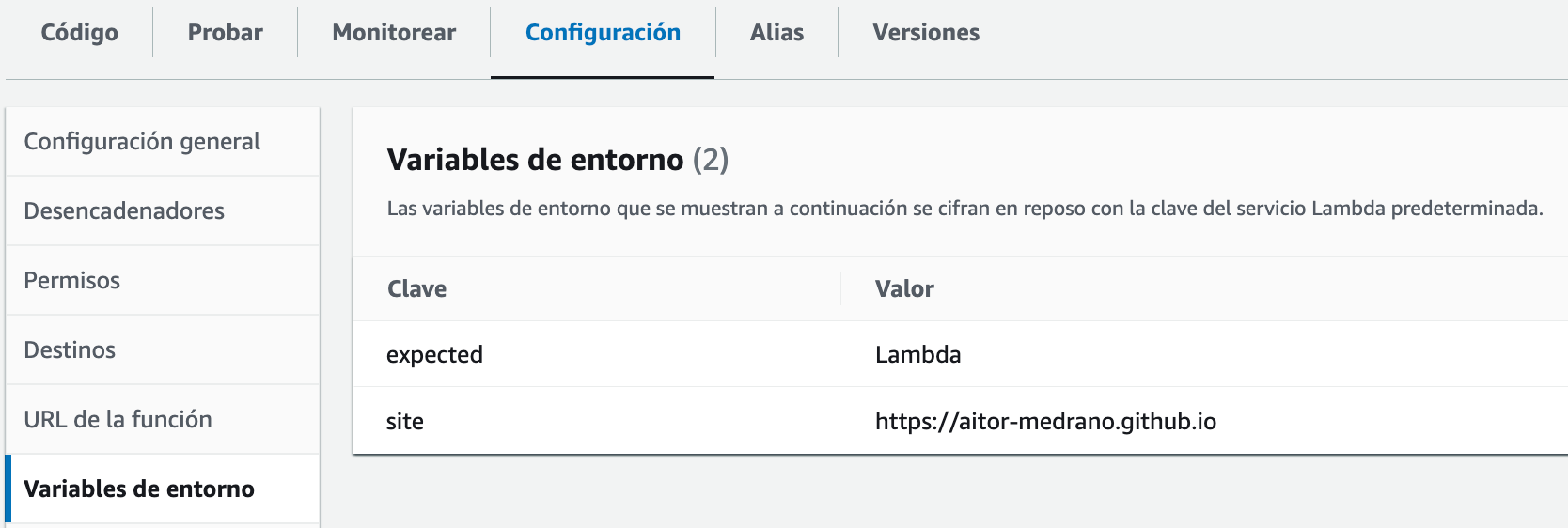
Y al cabo de unos minutos, recibiremos un email similar al siguiente donde podemos ver el nombre de la alarma y el motivo de que sale, así como su fecha:
You are receiving this email because your Amazon CloudWatch Alarm "checkAitorMedranoAlarm"
in the US East (N. Virginia) region has entered the ALARM state, because
"Threshold Crossed: 1 out of the last 1 datapoints [1.0 (26/11/23 17:54:00)]
was greater than the threshold (0.0) (minimum 1 datapoint for OK -> ALARM transition)."
at "Sunday 26 November, 2023 17:59:02 UTC".
View this alarm in the AWS Management Console:
https://us-east-1.console.aws.amazon.com/cloudwatch/deeplink.js?region=us-east-1#alarmsV2:alarm/checkAitorMedranoAlarm
Alarm Details:
- Name: checkAitorMedranoAlarm
- Description: # Alarma en la web aitormedrano.github.io
Parece que se ha producido un error y no se ha podido acceder a la web
- State Change: OK -> ALARM
- Reason for State Change: Threshold Crossed: 1 out of the last 1 datapoints [1.0 (26/11/23 17:54:00)]
was greater than the threshold (0.0) (minimum 1 datapoint for OK -> ALARM transition).
- Timestamp: Sunday 26 November, 2023 17:59:02 UTC
- AWS Account: 402638836504
- Alarm Arn: arn:aws:cloudwatch:us-east-1:402638836504:alarm:checkAitorMedranoAlarm
Threshold:
- The alarm is in the ALARM state when the metric is GreaterThanThreshold 0.0 for at least 1
of the last 1 period(s) of 300 seconds.
Monitored Metric:
- MetricNamespace: AWS/Lambda
- MetricName: Errors
- Dimensions: [FunctionName = checkAitorMedrano]
- Period: 300 seconds
- Statistic: Sum
- Unit: not specified
- TreatMissingData: missing
Caso de uso 2: Desde cero¶
Para este caso, vamos a crear una función que acceda a MongoDB y nos devuelva un documento.
Para ello, vamos a crear en local un archivo con el código a ejecutar. Primero crearemos una carpeta code, y dentro de ella, colocaremos este fragmento de código dentro de un archivo nombrado lambda_function.py, y contendrá una función lambda_handler:
from pymongo import MongoClient
from bson.json_util import dumps
client = MongoClient('mongodb+srv://iabd:iabdiabd@cluster0.dfaz5er.mongodb.net')
def lambda_handler(event, context): # (1)!
un_doc = client.sample_training.zips.find_one()
return {
'statusCode': 200,
'body': dumps(un_doc)
}
- El parámetro
eventes un mapa con los datos de entrada que recibe del desencadenador. En cambio, el parámetrocontextse utiliza para obtener información sobre la invocación y el entorno de ejecución de la función (por ejemplo, tiempo restante, nombre de la función o request ID).
Como puedes observar, vamos a trabajar con los datos que hemos utilizado en las sesiones de MongoDB, y utilizaremos PyMongo para acceder a MongoDB desde Python.
Creando un zip¶
Sin Docker
Si no queremos usar Docker, deberíamos crearnos un entorno virtual, e instalar las librerías. A continuación, comprimir el archivo con el código y el entorno virtual en un zip.
Más información en la documentación oficial.
El siguiente paso es encapsular la función dentro de un zip que contenga las dependencias (librerías) que utiliza nuestra función. Para ello, vamos a hacer uso de Docker para simplificar el proceso.
Para ello, creamos un dockerfile que crea la estructura de carpetas necesarias e instala las dependencias:
FROM ubuntu:20.04
RUN mkdir function
RUN cd function
COPY code/lambda_function.py function/lambda_function.py
WORKDIR /function
RUN apt-get update
RUN apt-get install python3-pip -y
RUN apt-get install zip -y
RUN pip install -t . pymongo
RUN zip -r linux-lambda.zip *
A continuación, debemos ejecutar una serie de comandos:
-
Creamos la imagen
docker build -t lambda_mongo . -
Creamos una contenedor temporal
docker create -ti --name tempforzip lambda_mongo -
Sacamos el zip del contenedor temporal
docker cp tempforzip:/function/linux-lambda.zip linux-lambda.zip -
Borramos el contenedor temporal
docker rm -f tempforzip
Una vez tenemos el archivo linux-lambda.zip ya estamos listos para crear nuestra nueva función.
Cargando código¶
Así pues, vamos a crear una función desde cero (seleccionaremos Python como lenguaje y el LabRole como rol existente de ejecución):
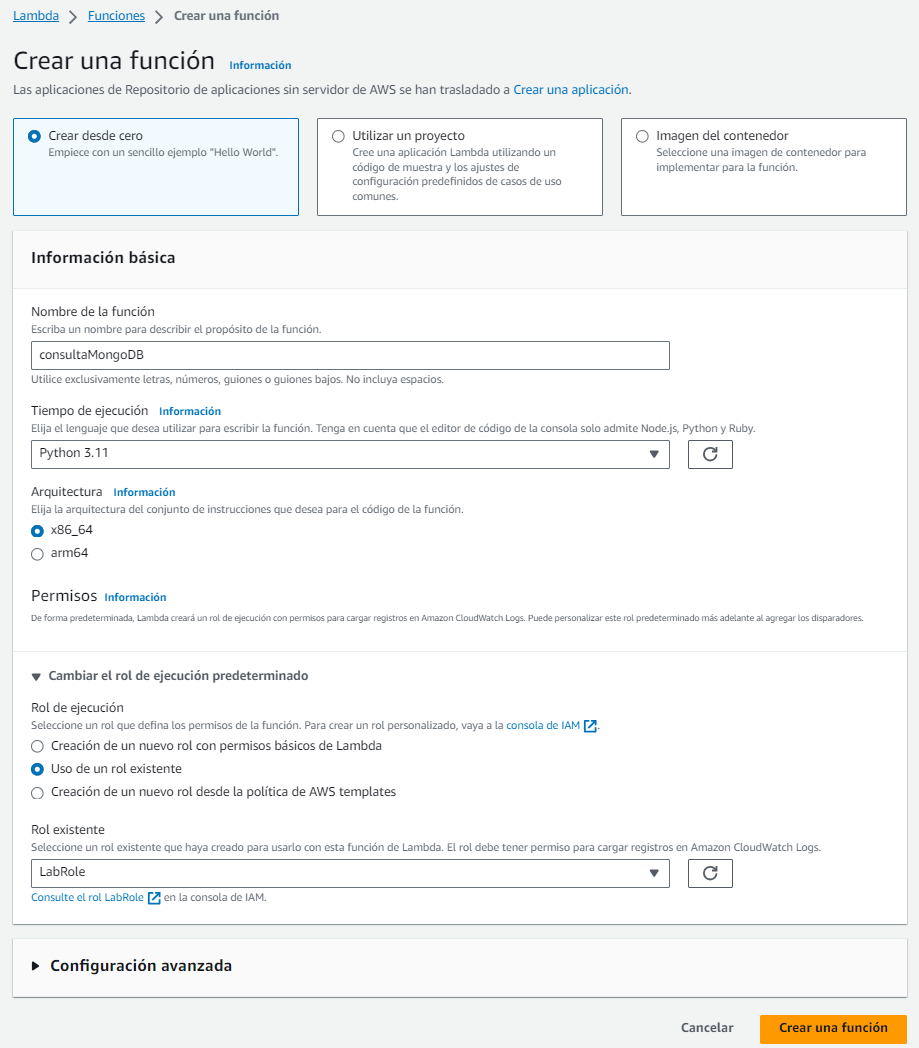
Una vez creada, en la pestaña Código, pulsaremos sobre el desplegable Carga desde para poder seleccionar el archivo zip recién creado.
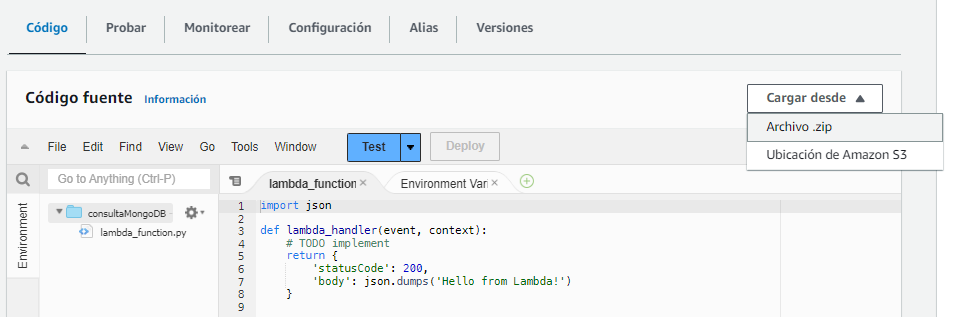
Al hacerlo, se sustituirá el código fuente y podremos probar mediante el botón azul Test:
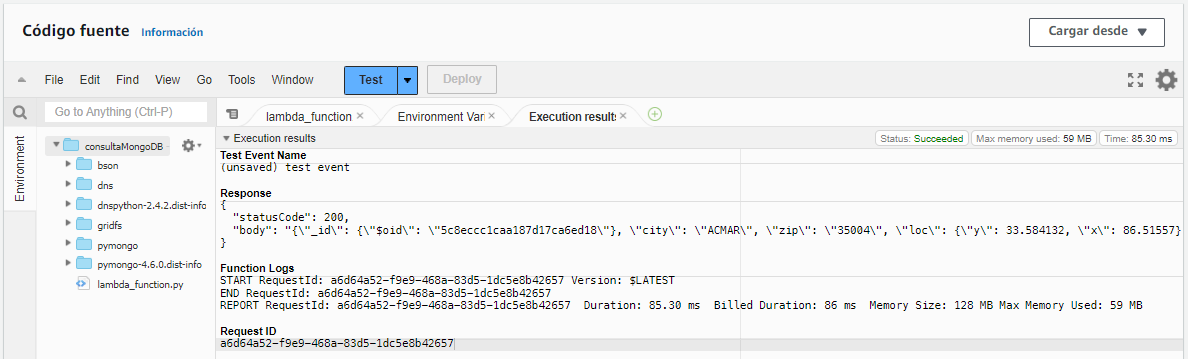
Al ejecutarlo, veremos que aparece un documento con los datos de un código postal, además de ver el tiempo que ha tardado (85 ms), y la memoria empleada (59MB).
Invocando mediante AWS CLI¶
Si queremos invocar una función desde AWS CLI utilizaremos el comando aws lambda invoke, tanto para hacer llamadas síncronas como asíncronas:
aws lambda invoke --function-name consultaMongoDB --cli-binary-format raw-in-base64-out response.json
Si comprobamos el contenido del archivo response.json generado, obtendremos algo similar a:
{"statusCode": 200,
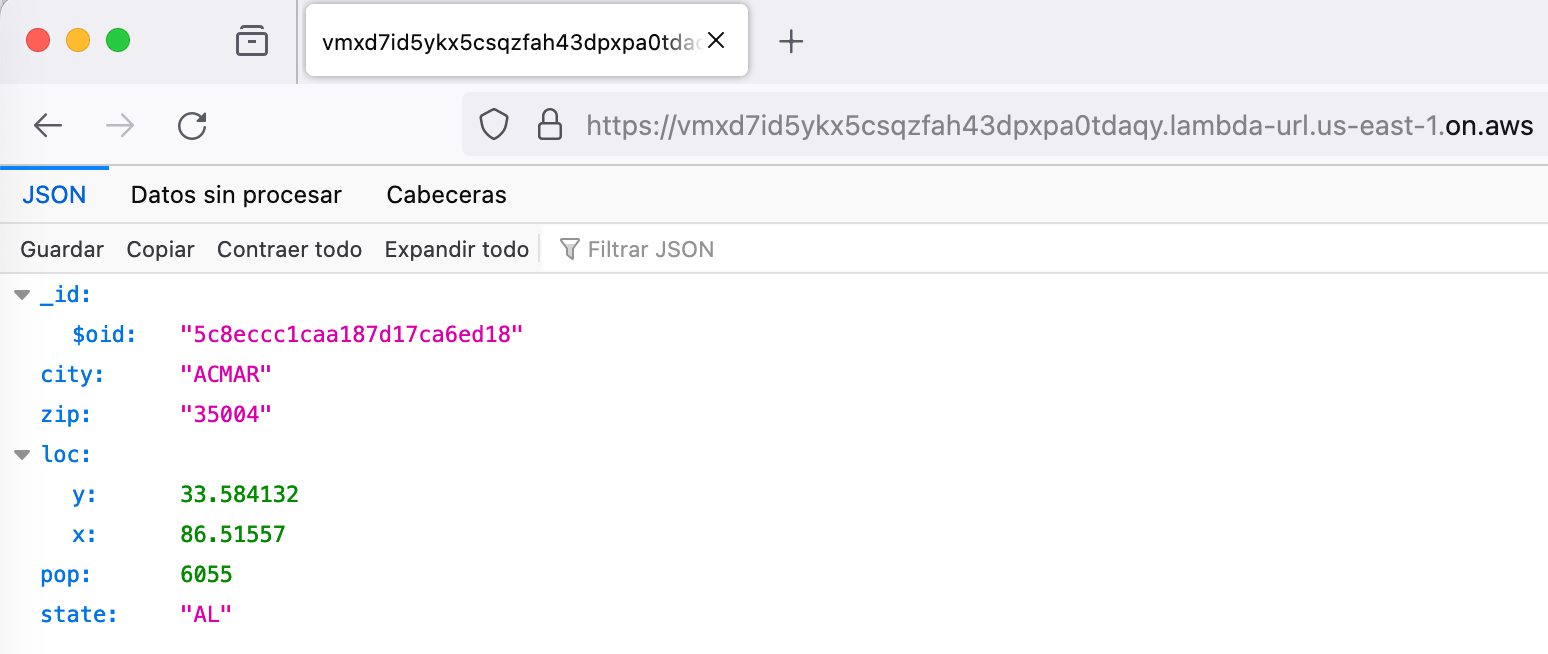
"body": "{\"_id\": {\"$oid\": \"5c8eccc1caa187d17ca6ed18\"}, \"city\": \"ACMAR\", \"zip\": \"35004\", \"loc\": {\"y\": 33.584132, \"x\": 86.51557}, \"pop\": 6055, \"state\": \"AL\"}"}
Más información en la documentación oficial.
Función pública¶
Mediante Lambda, podemos hacer que cualquier función sea accesible via una URL.
Esto lo podemos hacer al crear la función, en la configuración avanzada, marcando la opción Habilitar URL de la función, o una vez creada, en la pestaña Configuración, en la opción URL de función, donde al activarla elegiremos los permisos:
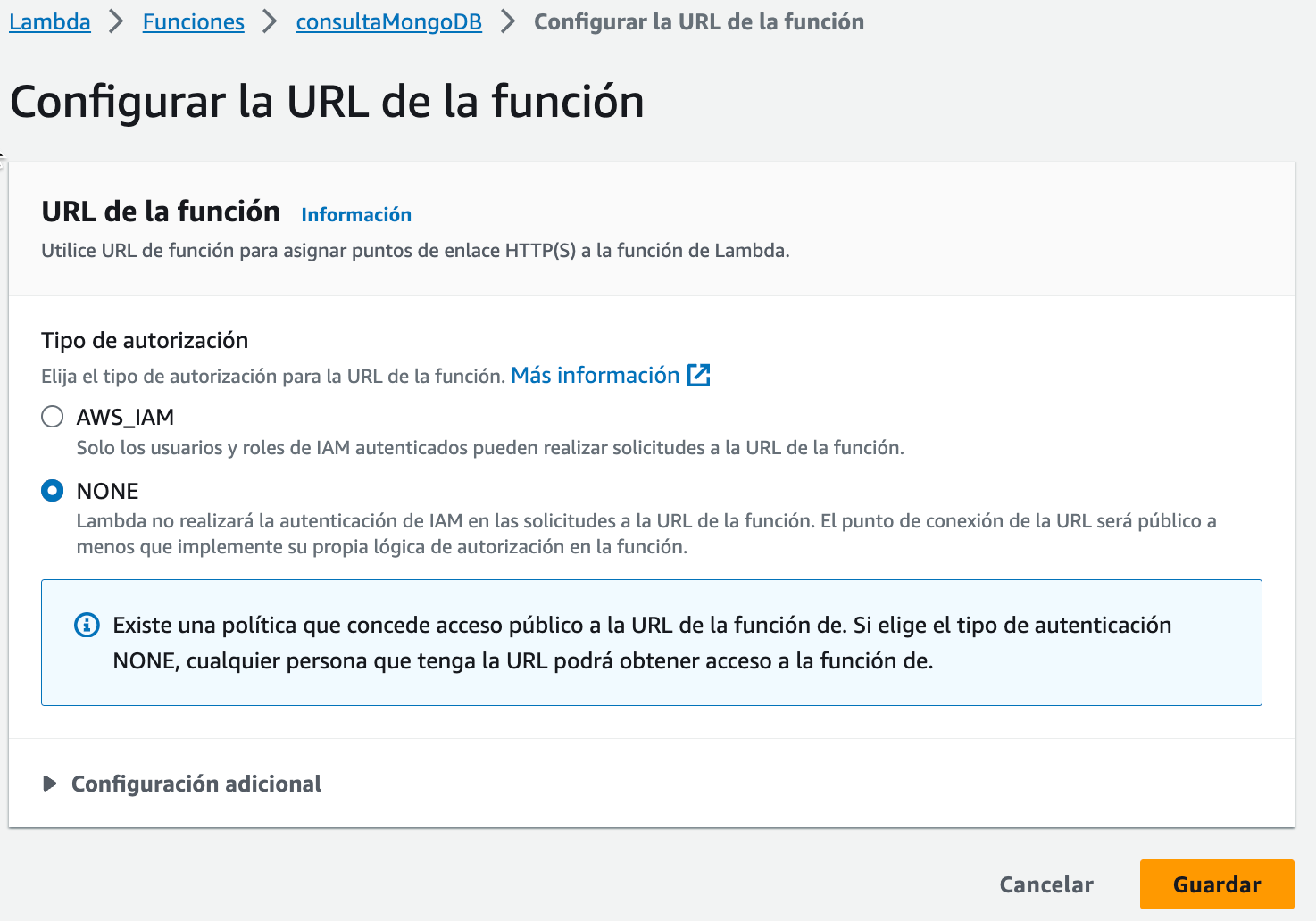
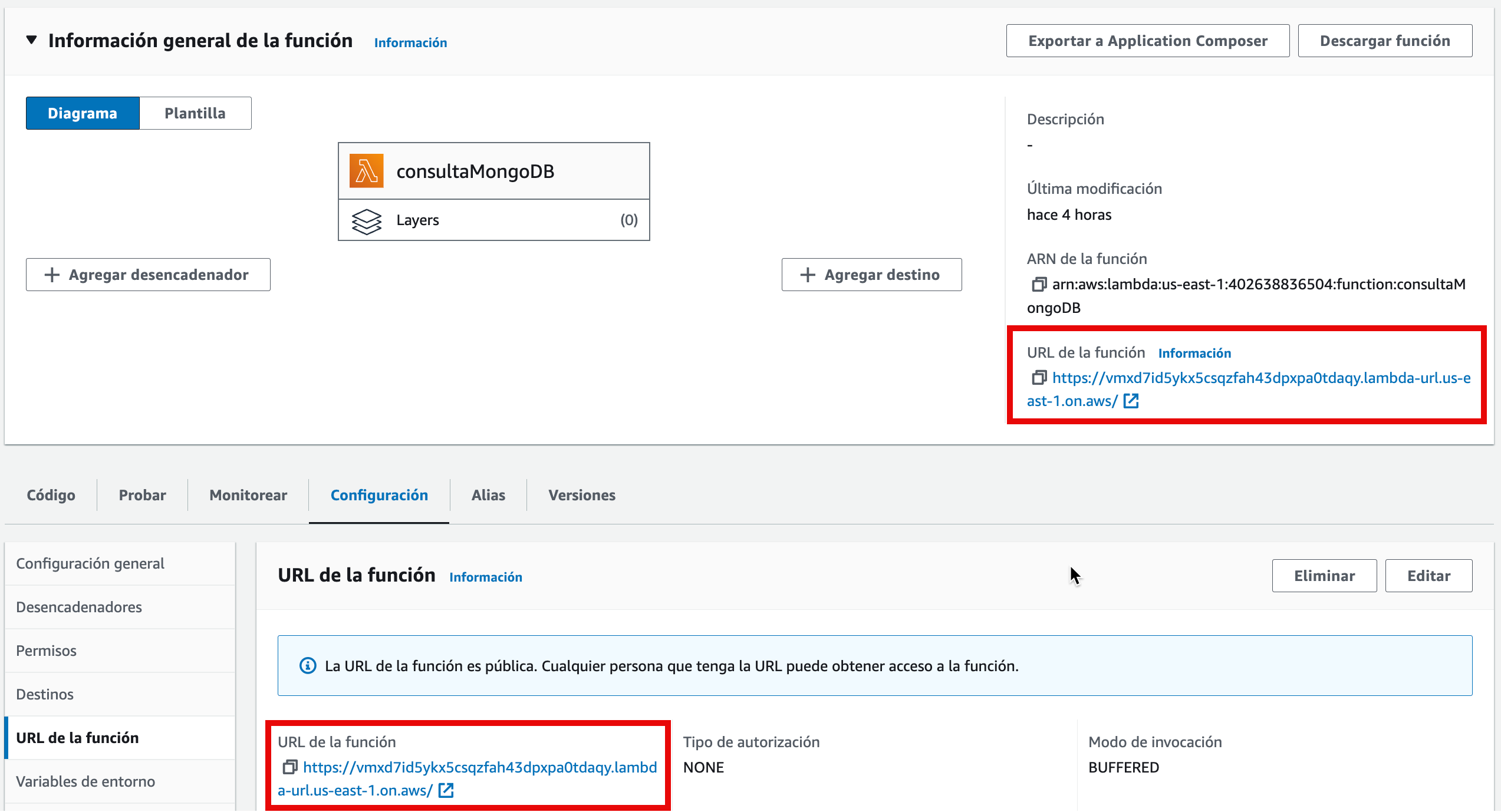
Tras crearla, tanto en la misma opción, como en el resumen de la función, aparecerá la URL de la función, la cual siempre contendrá lambda-url en mitad del dominio y terminará con on.aws:
Y si accedemos, veremos el resultado de la llamada a MongoDB:
Si hubiéramos querido crear la URL para la función mediante AWS CLI necesitaríamos utilizar el parámetro lambda create-function-url-config:
aws lambda create-function-url-config --function-name consultaMongoDB --auth-type NONE
AWS Elastic Beanstalk¶
AWS ElasticBeanstalk es un servicio PaaS que facilita la implementación, el escalado y la administración de aplicaciones y servicios web con rapidez. Nosotros, como desarrolladores, sólo deberemos cargar el código, elegir el tipo de instancia y de base de datos, configurar y ajustar el escalador automático. Beanstalk automáticamente administra la implementación, desde el aprovisionamiento de capacidad, el balanceo de carga y el escalado automático hasta la monitorización del estado de las aplicaciones. Al mismo tiempo, si queremos, podemos mantener el control total de los recursos de AWS que alimentan la aplicación y acceder a los recursos subyacentes en cualquier momento.
Es compatible con Java, .NET, PHP, Node.js, Python, Ruby, Go y Docker, y se despliegan en servidores como Apache, Nginx o IIS.
No se aplican cargos por utilizar ElasticBeanstalk, sólo se paga por los recursos que AWS utilice (instancia, base de datos, almacenamiento S3, etc...)
Referencias¶
Actividades¶
- (RABDA.2, RABDA.4 / CEBDA.2b, CEBDA.4a, CEBDA.4b, CEBDA.4c / 1p) Realiza el caso de uso 1, pero con otra URL y cadena. Adjunta capturas de pantalla del código fuente, de las variables de entorno, de las métricas capturadas tras más de 10 minutos, así como del resultado de la activación de la alarma donde te envíe un mail a tu cuenta de correo electrónico.
-
(RABDA.2 / CEBDA.2b / 1p) Realiza el caso de uso 2, pero modifícalo para que tanto la URI de MongoDB como el nombre de la colección los obtenga de variables de entorno configuradas en la función.
Puede que tengas que añadir código similar al siguiente fragmento para leer las variables:
import os uri = os.environ["MONGODB_URI"]Comprueba el funcionamiento de la función tanto desde la consola de AWS, del AWS CLI como accediendo mediante una URL, y adjunta una captura de cada resultado.