Hugging Face
Introducción¶
Hugging Face se fundó en 2016 con el propósito inicial de desarrollar una aplicación de chatbot. A partir de 2018 comenzó a abrir a la comunidad open source partes de sus modelos NLP, los cuales ganaron popularidad dentro de la comunidad IA.
A día de hoy es la plataforma por excelencia de modelos y datasets, facilitando el descubrimiento, distribución, uso y fine-tuning de modelos pre-entrenados.
Gran parte de la fama adquirida por Hugging Face se debe a sus librerías, en concreto Transformers (para trabar con textos) y Diffusers (para tareas basadas en imágenes), permitiéndonos a los desarrolladores importar y trabajar rápidamente con una gran variedad de modelos pre-entrenados como GPT2 (una versión temprana de ChatGPT), Stable Diffusion o WhisperAI.
Hola Traductor¶
Vamos a comenzar con un par de ejemplos muy sencillos para hacernos una idea de lo que podemos hacer. Nuestro Hola Mundo particular va a ser cargar un modelo que traduce de inglés a castellano. Para ello, vamos a utilizar el modelo Helsinki-NLP/opus-mt-en-es que la Universidad de Helsinki ha entrenado a partir de los corpus de OpusMT, y luego ha liberado en HuggingFace.
Así pues, haciendo uso de la librería Transformers (ya la estudiaremos en profundidad tanto en el bloque de Redes Neuronales como en NLP) cargamos el modelo y creamos un pipeline donde le indicamos que el modelo es de tipo traducción. Sin entrar en muchos detalles, un pipeline es una abstracción para simplificar el código sin entrar a las particularidades de cada modelo. Posteriormente, invocamos al pipeline creado con la frase de entrada, el cual realiza la inferencia sobre el modelo indicado, y recibimos la frase de salida:
from transformers import pipeline
frase_en = "I like to play basketball and being a geek"
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
frase_es = pipe(frase_en)
print(frase_es[0]['translation_text'])
# Me gusta jugar al baloncesto y ser un friki
Así de simple. Con un par de líneas realmente hemos cargado un modelo de IA ya creado, y hemos realizado una inferencia sobre él.
Hola Difusor¶
¿Y si no queremos utilizar un traductor en nuestras aplicaciones pero sí que queremos generar imágenes? En este caso, en vez de la librería transformers , necesitamos utilizar la librería diffusers para generar datos similares a los datos con los que se ha entrenado.
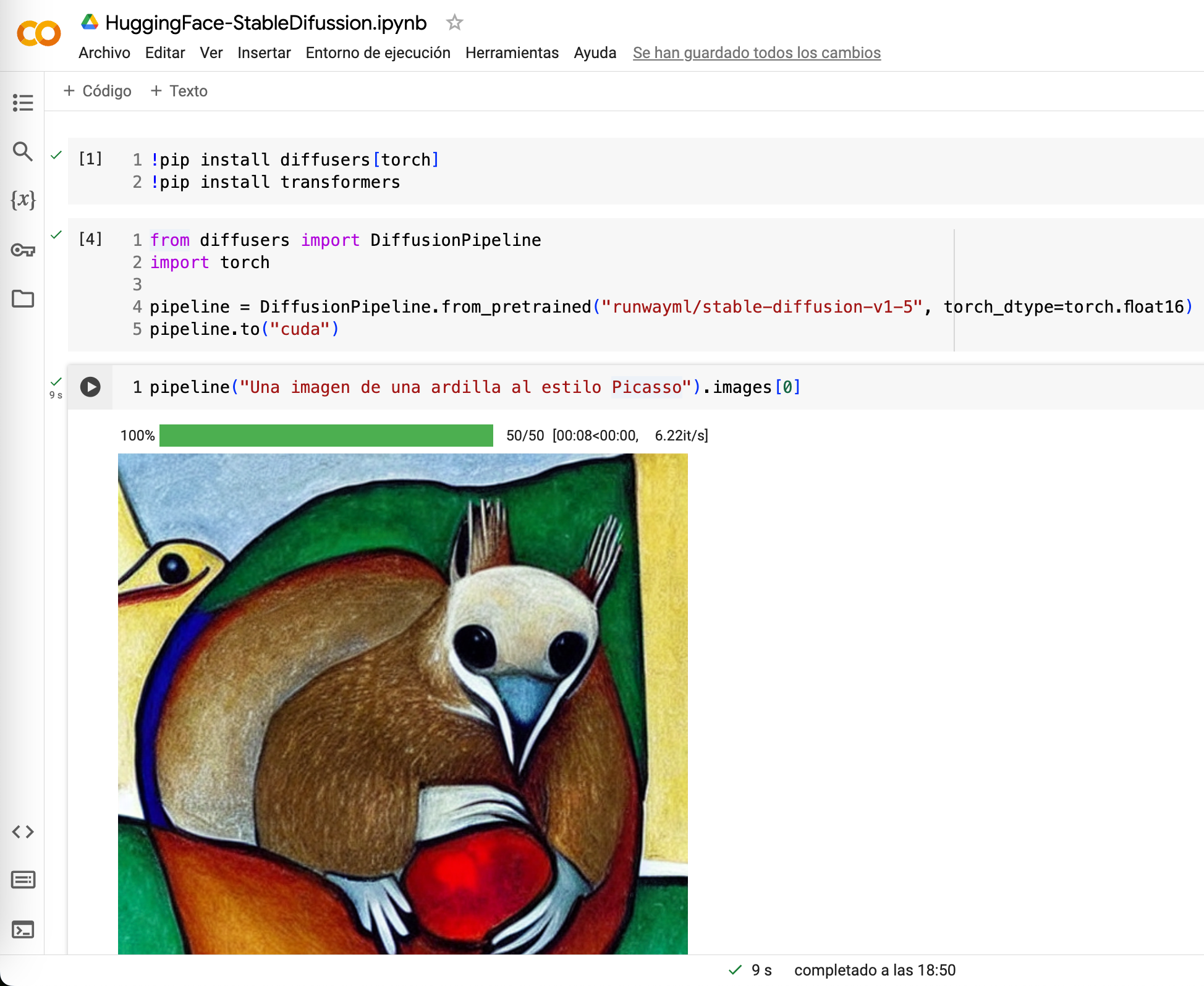
En este caso, vamos a utilizar el modelo Stable Diffusion (una librería estándar de generación de imágenes), y con sólo 5 líneas de código generar una imagen de una ardilla al estilo de Picasso:
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("sd-legacy/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline.to("cuda")
pipeline("Una imagen de una ardilla al estilo Picasso").images[0]
Probando en Colab
Para probar ambos ejemplos, vamos a comenzar con Google Colab, herramienta que ya habéis visto en las primeras sesiones y nos permite ejecutar cuadernos Jupyter sobre máquinas de Google. Para ello, necesitamos tener una cuenta de Google.
Con el siguiente cuaderno podemos probar el modelo traductor:
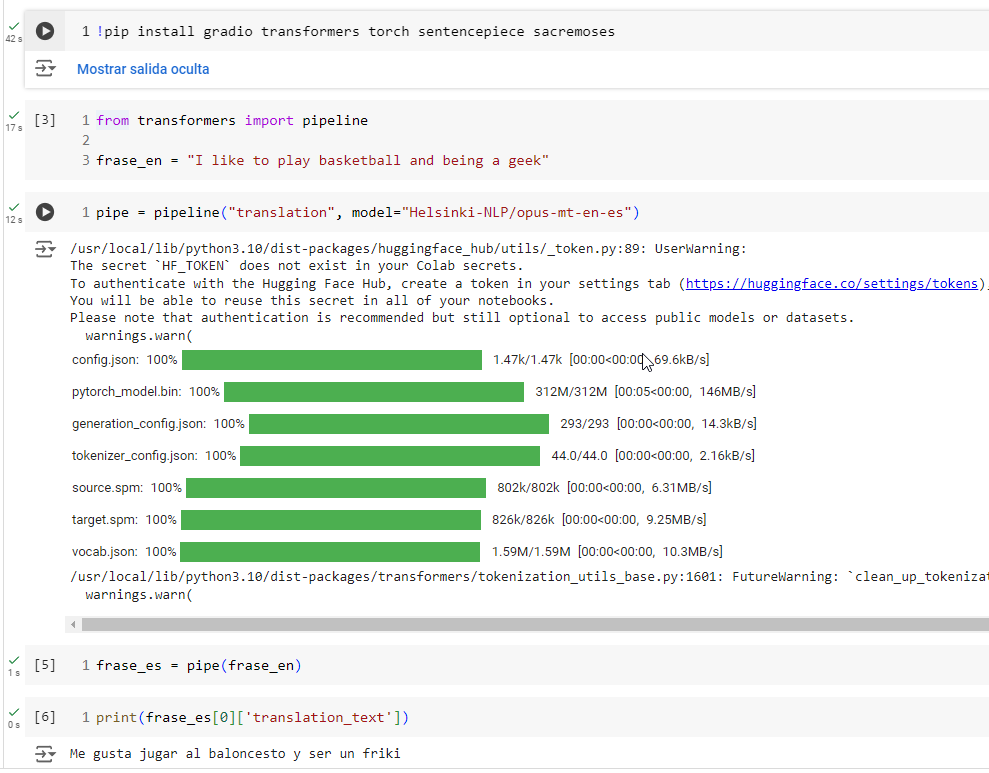
Y para probar la generación de imágenes, tenemos el siguiente cuaderno:
Probando en local
Si queremos probarlo en local en nuestro ordenador, el primer paso es crear un entorno virtual y activarlo:
python3 -m venv venv
source venv/bin/activate
A continuación, instalamos las librerías adecuadas:
pip install transformers torch sentencepiece sacremoses
Y una vez creado el script, ya puedes ejecutarlo mediante python3 hola-traductor.py.
pip install diffusers torch transformers
Dependiendo de si tienes tarjeta gráfica o no, necesitarás modificar un poco el código. Si no tienes CPU, necesitarás cambiar el tipo de datos a float32 y no utilizar CUDA:
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float32)
pipeline("Una imagen de una ardilla al estilo Picasso").images[0].save("hola-hf.png")
En la última línea, en vez de obtener únicamente la imagen, la persistimos en disco en el archivo hola-hf.png.
Cambiando el modelo
¿Y si cambiamos el modelo por uno más nuevo?
Sustituye las primeras líneas con el siguiente fragmento y comprueba si el estilo/calidad de la imagen cambia:
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
...
¿Y si no queremos traducir ni generar una imagen y estamos interesados en otro tipo de tarea o modelo?
Hub¶
El Hugging Face Hub es una plataforma con más de 400.000 modelos, 100.000 conjuntos de datos y 150.000 demos en el cual podemos colaborar y reutilizar en nuestros desarrollos de ML.
El Hub de Hugging Face funciona a modo de repositorio Git que almacena todos los archivos necesarios de:
- Modelos (models): incluyendo los últimos modelos NLP, de visión artificial o tratamiento de audio.
- Espacios (spaces): aplicaciones interactivas para probar los modelos directamente desde el navegador.
- Conjuntos de datos (datasets): con datos de diferentes dominios.
Repositorios¶
Los repositorios permiten almacenar el código y los assets para hacer copias de seguridad de nuestro trabajo, compartirlo con la comunidad y trabajar en equipo. Para ello, se utiliza un repositorio Git para la gestión del control de versiones y facilitar el trabajo colaborativo.
El primer paso es crearnos una cuenta en Hugging Face y a continuación, instalar el cliente de Hugging Face para poder interactuar con todas las herramientas disponibles.
Organizaciones
Hemos creado una organización llamada IABDs8a para agrupar al alumnado del IES Severo Ochoa.
HuggingFace-CLI¶
Para poder subir nuestro código al Hub, podemos realizarlo desde el interfaz gráfico, o hacer uso del CLI.
Para ello, el primer paso es instalarlo:
pip install huggingface_hub
Mediante el CLI vamos a poder interactuar con Hugging Face para descargar repositorios, espacios, modelos o archivos de forma individual, así como subir todo tipo de artefactos y recursos.
Cambio de comandos
Con la última versión del paquete huggingface_hub, los comandos han cambiado de nombre. Por ejemplo, el comando huggingface-cli ahora es hf. Revisa la documentación oficial para más detalles.
Token de acceso¶
Para poder acceder, previamente tenemos que obtener un token de acceso. Para ello, desde el interfaz web, accedemos a la sección de "Access Token" y generamos un token:
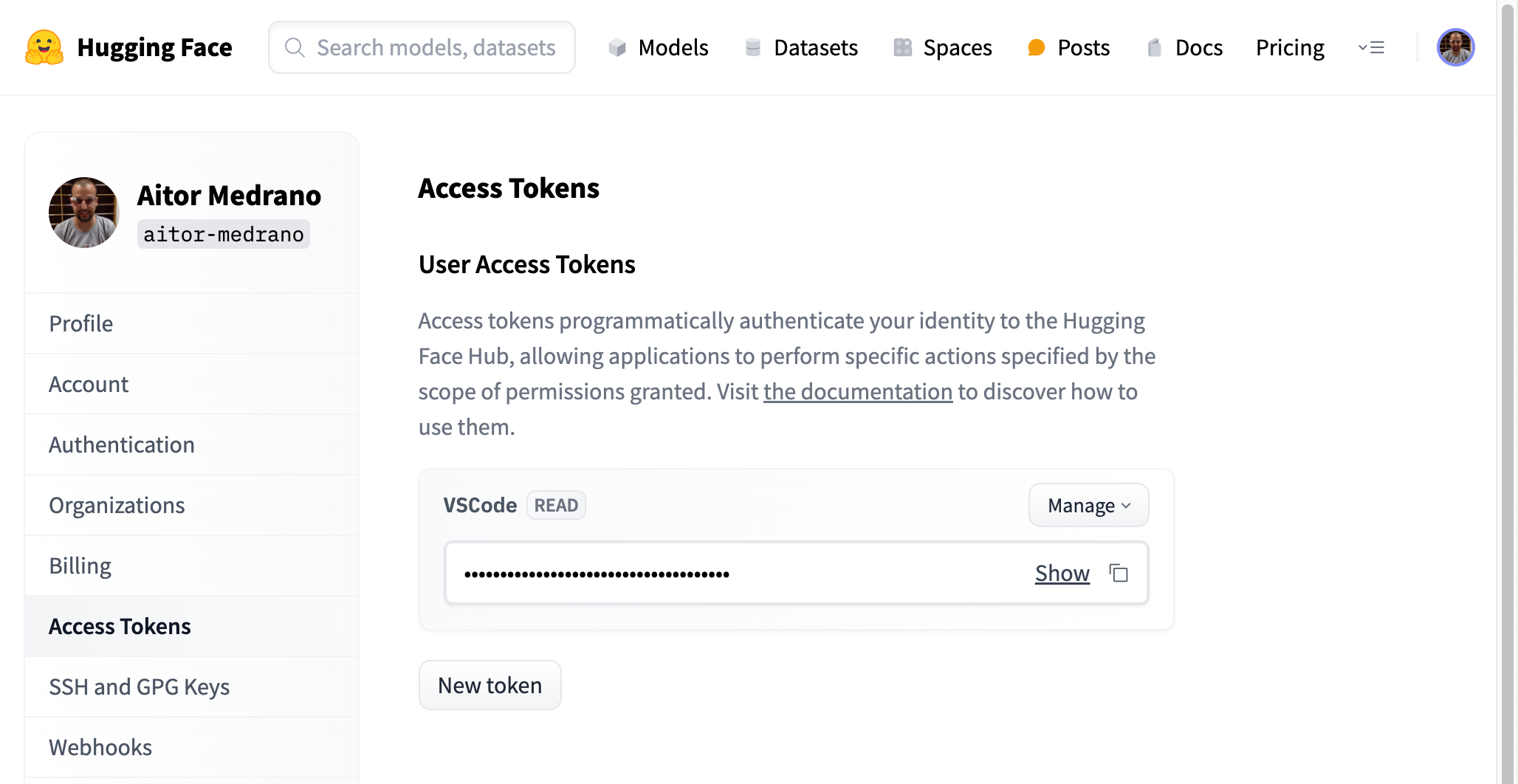
Lectura o escritura
A la hora de generar el token, podemos crear tokens de:
- Con granularidad fina, donde podremos configurar en detalle a qué le damos permiso.
- Lectura (read): para la lectura de los repositorios públicos y de los que somos miembros, y por tanto, nos sirve para descargar modelos privados o realizar inferencia
- Escritura (write): para la escritura en los repositorios que tenemos acceso, por ejemplo, para entrenar un modelo o modificar la tarjeta de un modelo.
Podemos generar tantos tokens como queramos, para diferentes aplicaciones o servicios.
Login¶
Tras crear una cuenta y obtener el access token, ya podemos hacer login con hf auth login:
> hf auth login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Token is valid (permission: read).
Your token has been saved in your configured git credential helpers (osxkeychain).
Your token has been saved to /Users/aitormedrano/.cache/huggingface/token
Login successful
Por ejemplo, para comprobar si hemos entrado bien al sistema le pasaremos el parámetro whoami:
> hf auth whoami
aitor-medrano
Otro comando muy útil para saber cuanto ocupa los datos descargados en nuestro ordenador local es utilizar el parámetro cache scan:
> hf cache scan
REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH
------------------------------ --------- ------------ -------- -------------- ------------- ---- ----------------------------------------------------------------------------------
runwayml/stable-diffusion-v1-5 model 5.5G 15 22 minutes ago 3 weeks ago main /Users/aitormedrano/.cache/huggingface/hub/models--runwayml--stable-diffusion-v1-5
Done in 0.0s. Scanned 1 repo(s) for a total of 5.5G.
Una vez tenemos el token ya podemos clonar los espacios y modelos y utilizar el token para autenticarnos.
Spaces¶
Mediante los espacios podemos construir y desplegar modelos de IA, así como aplicaciones de demostración para probarlos.
Podemos crear demos de forma rápida, con una pocas líneas de Python, con las librerías Gradio o Streamlit, y utilizar controles multimodales que facilitan el testeo de los modelos.
Por ejemplo, si vamos a los espacios, podemos ordenarlos por los que tienen más likes, y entrar a MusicGen y ver los diferentes controles para introducir texto, subir un archivo, así como posteriormente reproducir un audio o un vídeo:
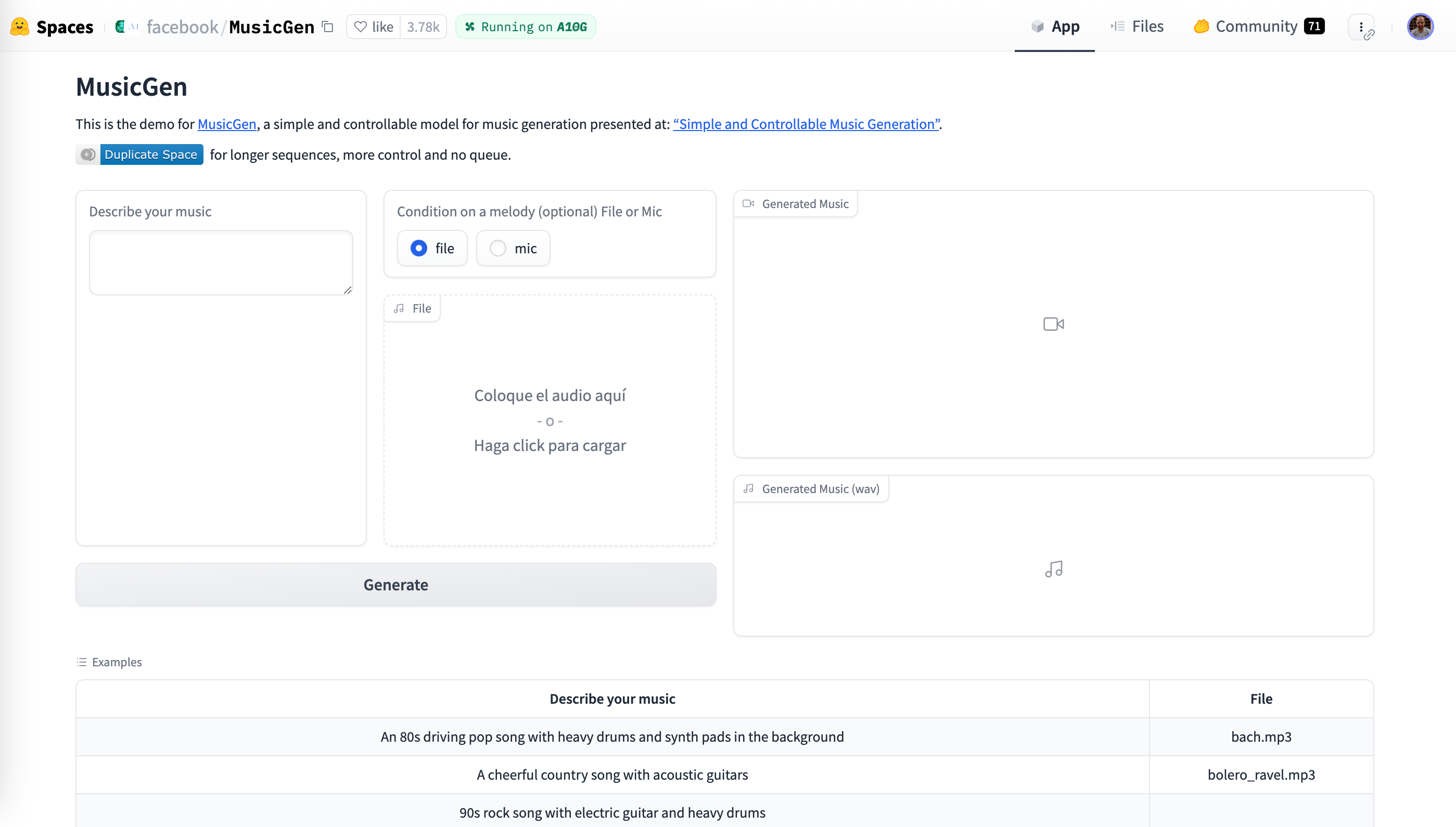
Otros espacios no tienen apariencia de formulario, como FacePoke (prueba a subir una foto de un retrato, o una versión menos interactiva como expression-editor), o permiten el uso de la aplicación en tiempo real como Realtime-whisper-large-v3-turbo, pudiendo ofrecer elementos de ejemplo para probar los modelos como Kolors-Virtual-Try-On.
En este bloque, y en concreto en la próxima sesión nos vamos a centrar en Gradio para la creación del interfaz de usuario.
El uso básico de los espacios es gratuito, pero si necesitamos emplear GPU puede ser que necesitemos pagar por su uso.
Hola Spaces¶
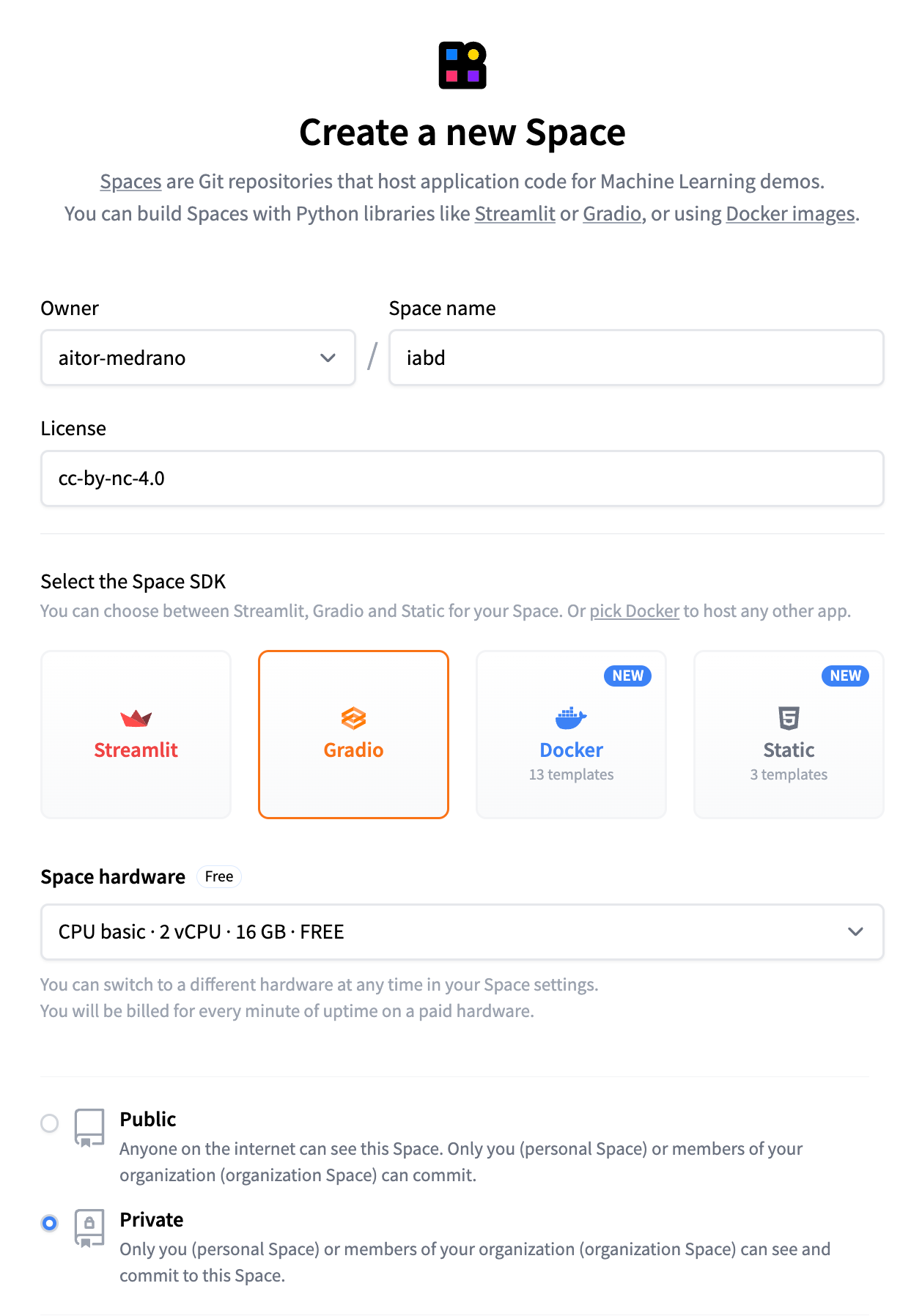
Para familiarizarnos con ellos, vamos a crear nuestro espacio que utilizaremos a lo largo del bloque. Para ello, dentro de la pestaña Spaces, creamos uno nuevo (Create new Space), y vemos como primero indicamos un nombre, una licencia, el SDK que utilizaremos para el prototipado, el hardware empleado y la visibilidad del mismo:
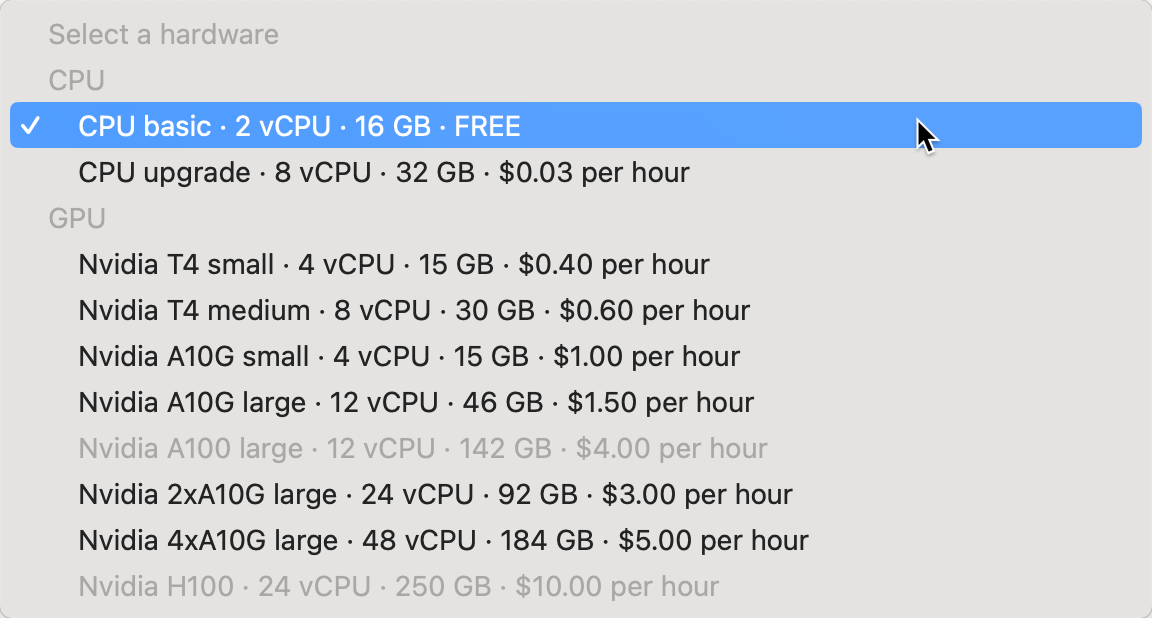
Si desplegamos sobre el tipo de hardware, podemos ver las diferentes opciones de tamaño y precio que ofrece la plataforma por hora de ejecución:
En nuestro caso, vamos a coger la instancia gratuita y elegiremos un proyecto Gradio con una plantilla en blanco (blank). Como podéis observar, además de Streamlit, podemos usar imágenes de Docker o utilizar plantillas estáticas. Finalmente, seleccionamos que queremos hacer nuestro espacio en abierto, para que sea accesible por cualquiera.
Tras ello, nos saldrá una página con información para clonar el repositorio creado:
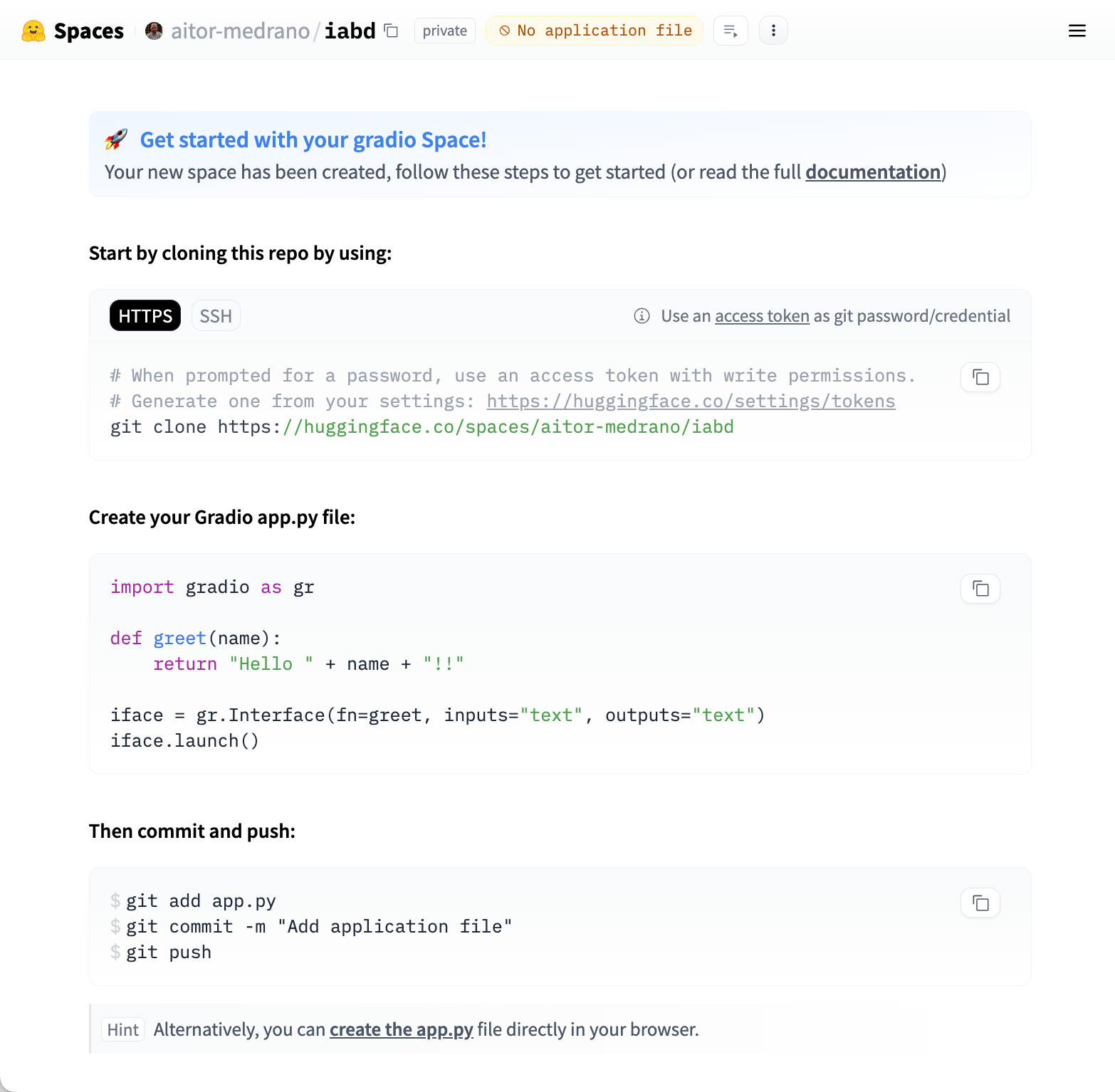
En nuestro caso, vamos a añadir la aplicación inicial desde el navegador pulsando sobre el enlace "create the app.py" y añadimos el siguiente fragmento que emplea Gradio y realizamos un commit desde el interfaz web:
import gradio as gr
def saluda(nombre):
return "Hola " + nombre + "!"
demo = gr.Interface(fn=saluda, inputs="text", outputs="text")
demo.launch(share=True)
Si ahora vamos nuestro perfil, podremos ver cómo se ha creado el espacio, y si pulsamos sobre él, aparecerá la aplicación:
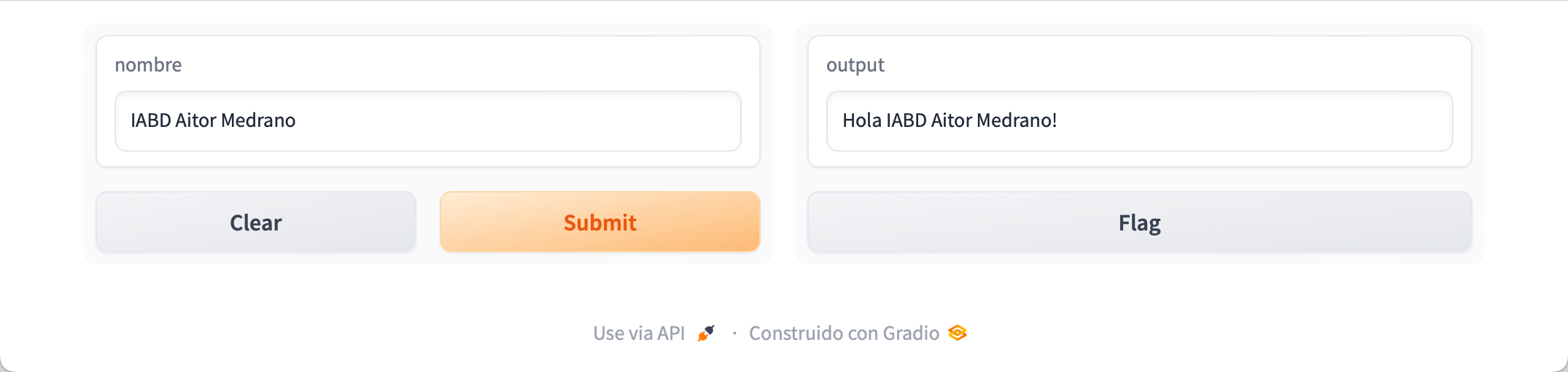
Probando en local
Para probar Gradio en local, el primer paso será instalar la librería:
pip install gradio
Y a continuación, lanzar el script pero en vez de con el intérprete de Python, con el comando gradio:
gradio app.py
¿Te aparece una dirección local y otra remota? ¿Dónde se está ejecutando el código de la URL remota?
Hola Spaces 2.0¶
Vamos a reutilizar el ejemplo inicial de generar una imagen desde Stable Difussion para generar un prototipo que nos permita escribir el prompt y visualizar el resultado.
Para ello, desde la pestaña Files, añadimos un nuevo fichero con el código de nuestra aplicación que ahora llamaremos stable-app.py ahora será similar a:
import gradio as gr
from diffusers import DiffusionPipeline
import torch
def stable(prompt):
pipeline = DiffusionPipeline.from_pretrained("sd-legacy/stable-diffusion-v1-5", torch_dtype=torch.float32)
return pipeline(prompt).images[0]
demo = gr.Interface(fn=stable, inputs="text", outputs="image")
demo.launch()
Para indicarle al Space que este fichero es la nueva aplicación, editamos el fichero README.md que contiene la configuración del espacio (título, colores del banner, descripción y el nombre del script que lanza la aplicación):
---
title: IABD
emoji: 🌍
colorFrom: blue
colorTo: indigo
sdk: gradio
sdk_version: 4.25.0
app_file: stable-app.py
pinned: false
license: cc-by-nc-4.0
short_description: Probando los Spaces en IABD
---
Algunos de los campos los podemos editar directamente desde el interfaz gráfico, pero también podemos editar directamente el archivo:
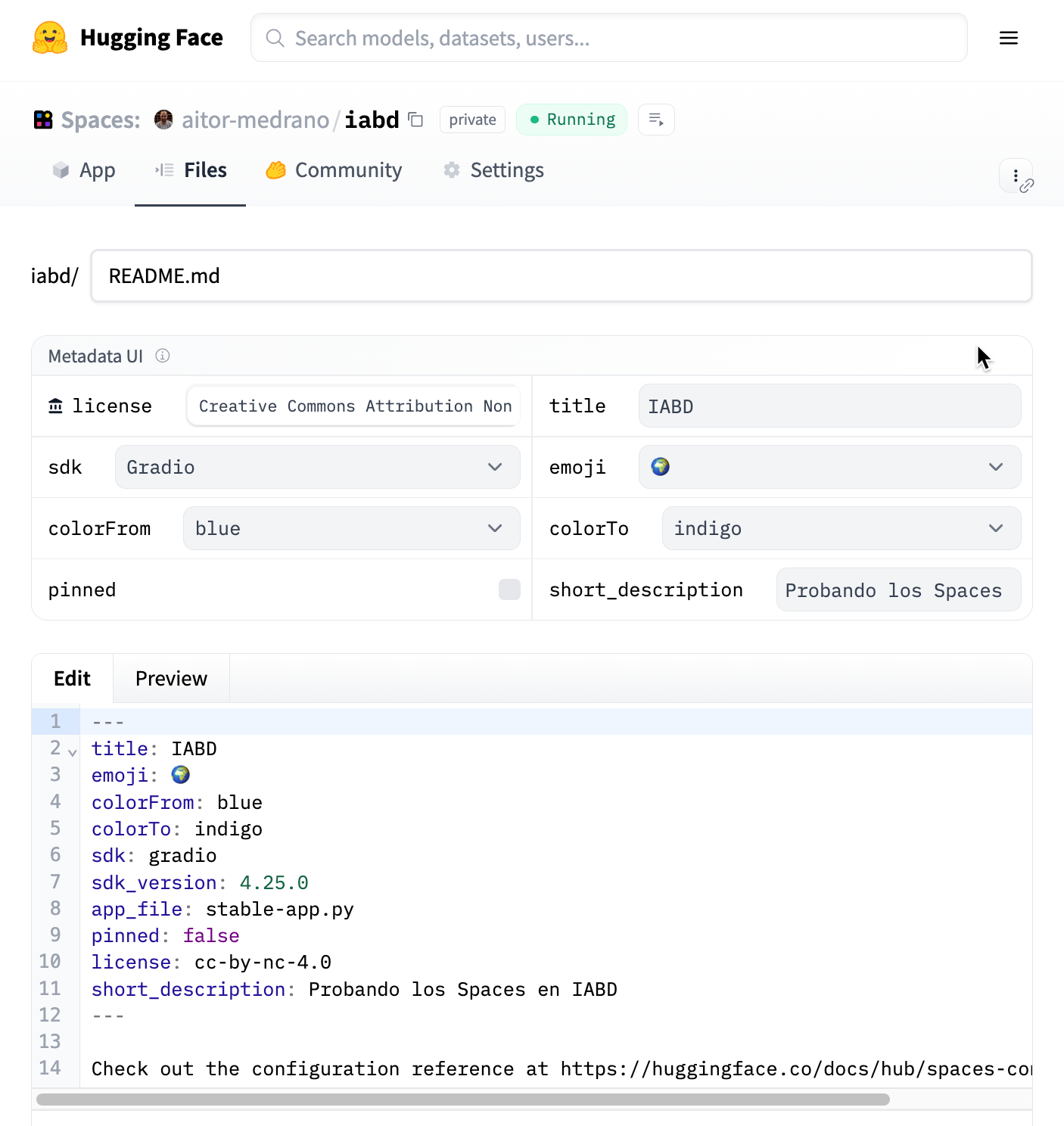
Si ahora volvemos a la pestaña de la aplicación veremos que ha fallado ¿El motivo? Claramente no hemos instalado ninguna de las librerías que necesita nuestro ejemplo. Por defecto, los Spaces ya tienen instaladas las librerías huggingface_hub para gestionar los repositorios y ficheros del Hub, requests para realizar llamadas a APIs externas, datasets para cargar y mostrar datos (la veremos en una próxima sesión) y el SDK seleccionado, ya sea gradio o streamlit.
Para instalar otras dependencias, añadiremos a la raíz un archivo nombrado requirements.txt:
diffusers
torch
transformers
accelerate
Tras hacer el commit del archivo, el espacio volverá a construirse. Y tras ello, ya podemos introducir nuestro prompt y tras más de 17 minutos (no utiliza GPU) podremos ver el resultado:
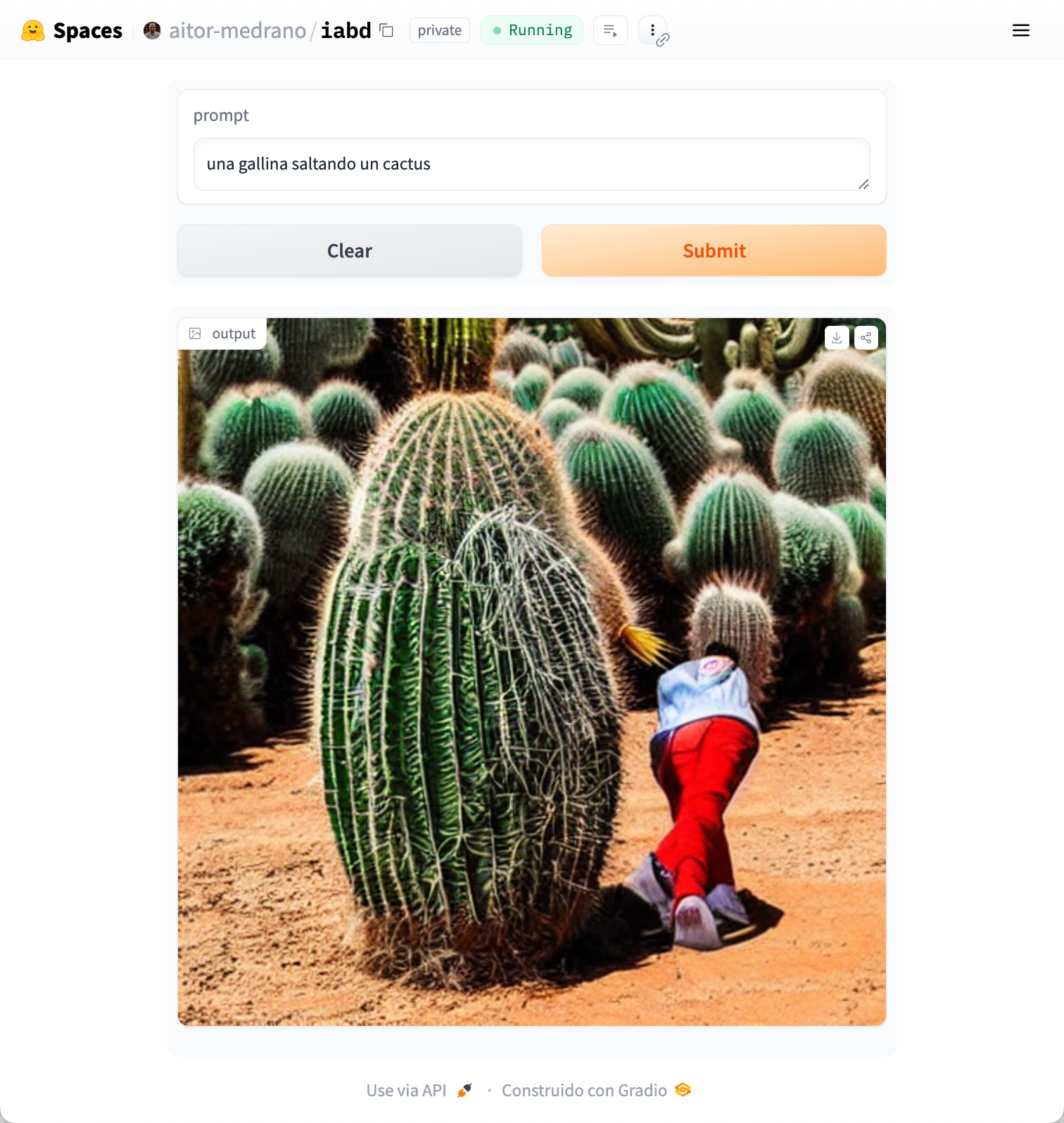
Modelos¶
Hugging Face ofrece multitud de modelos que podemos probar y utilizar en nuestras aplicaciones. Además, si queremos, podemos utilizar alguna técnica de transferencia de conocimiento para crear nuestros propios modelos adaptados a nuestras necesidades.
Si entramos a la página de Modelos, podemos buscar un modelo por tarea o palabra clave, y ordenar los resultados por popularidad, tendencia o actualizaciones recientes.
Si entramos a un modelo en concreto, por ejemplo a speecht5_tts o opus-mt-en-es, podemos ver una ficha con información del modelo como el método de entrenamiento, la licencia de uso, estadísticas de uso e interacciones de la comunidad, herramientas para utilizar el modelo (Inference API) o importarlo en nuestro propio código, así como qué espacios utilizan este modelo.
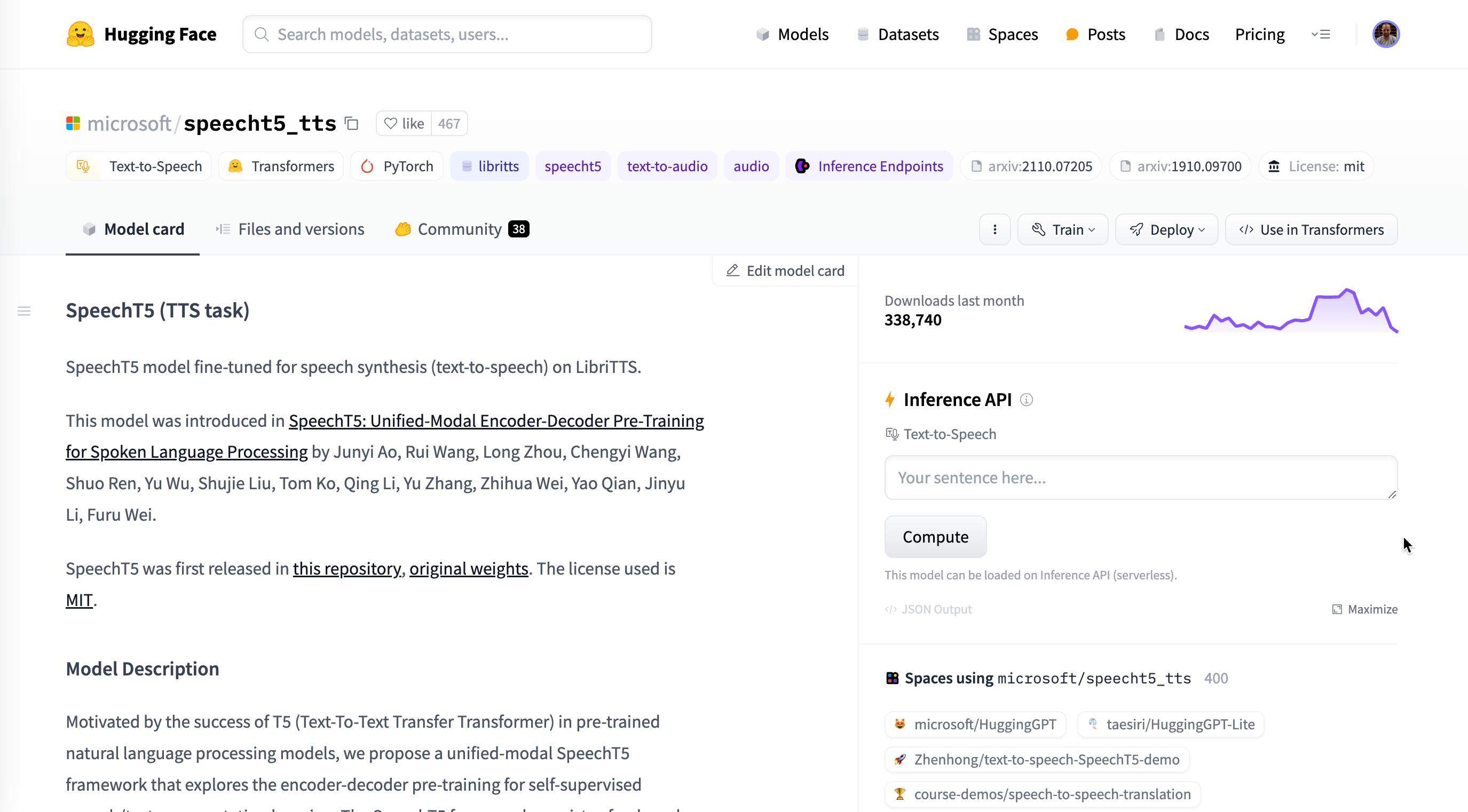
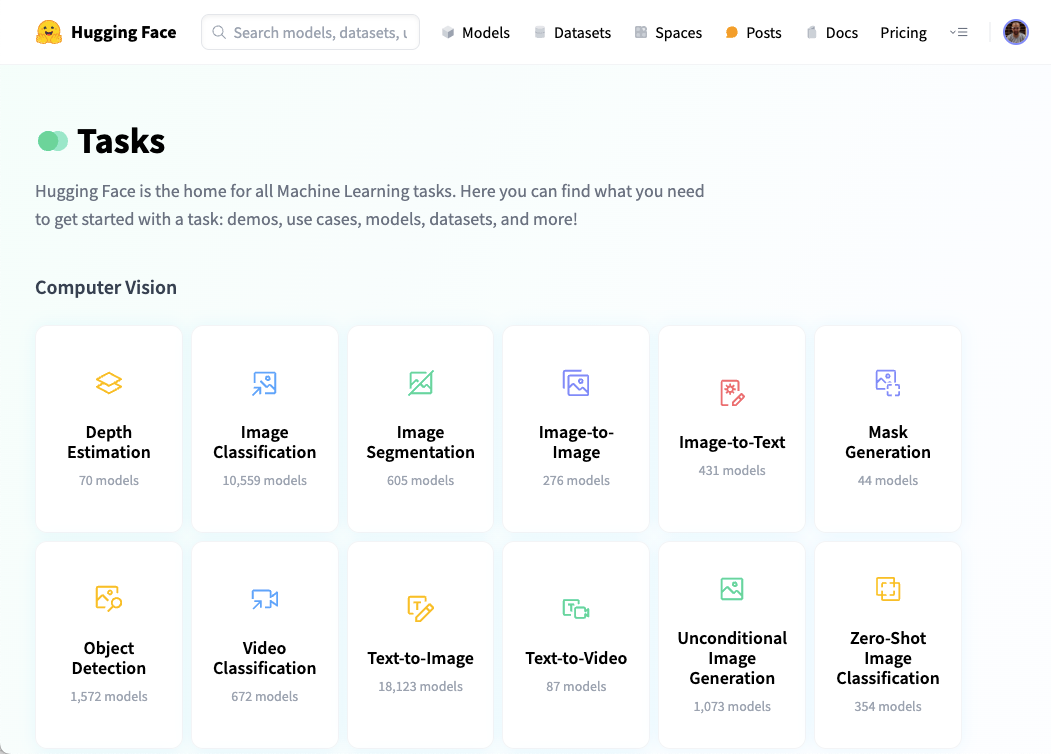
Por último, la página tareas (Tasks) agrupa todos los modelos de IA por su utilidad:
Creando un modelo¶
El primer paso es crear un modelo que implícitamente inicializará un repositorio donde almacenar el código fuente y los artefactos.
Para crear el modelo, de forma similar a cómo hicimos al crear el espacio, vamos a nuestro perfil y pulsamos sobre + New Model y tras ponerle un nombre y una licencia, accederemos a su panel donde tenemos por una parte una card que hace de página de inicio, la pestaña con los ficheros y versiones que hace de repositorio, así como la posibilidad de interactuar con la comunidad y las preferencias.
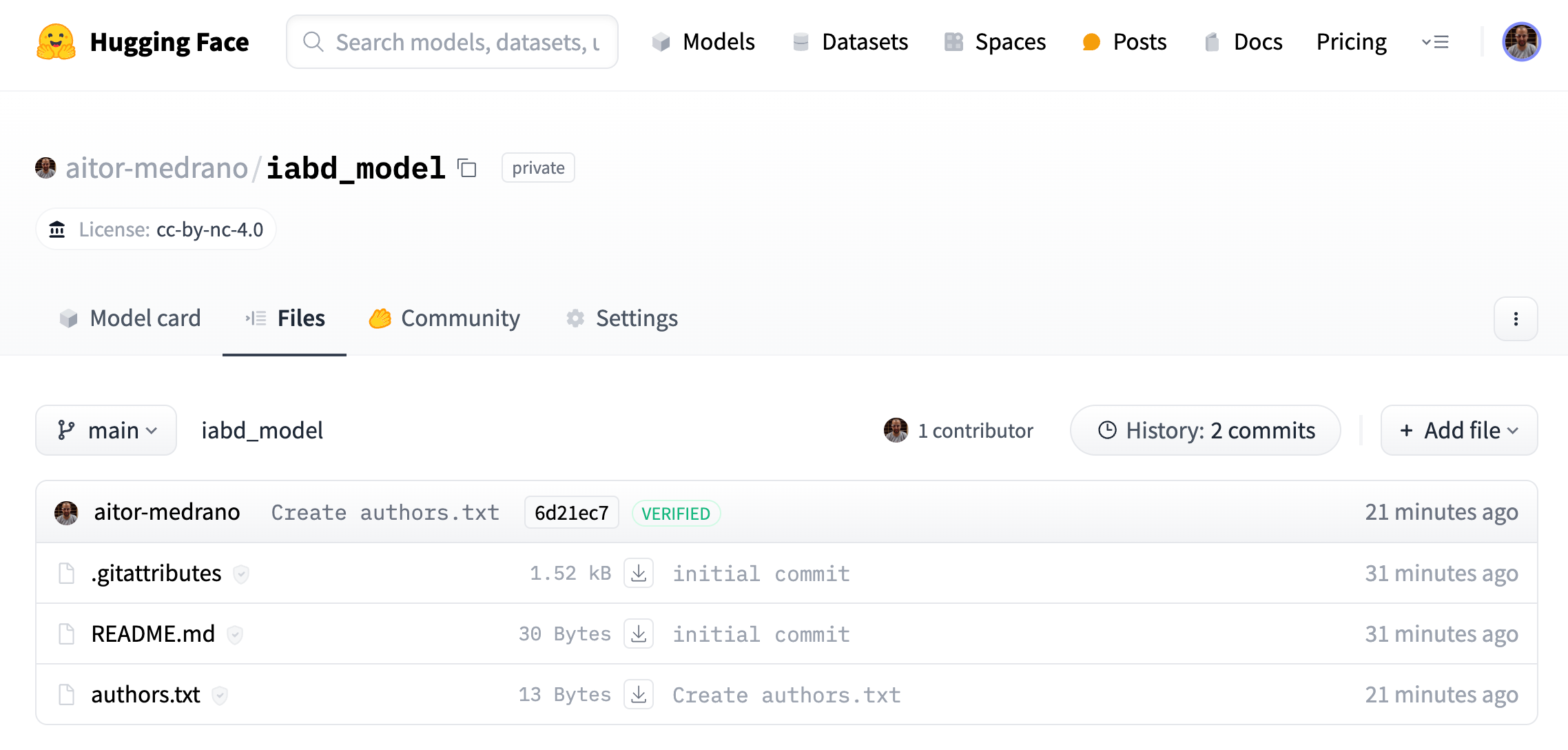
Vamos a ir a la pestaña de Files and versions y añadimos un archivo desde el interfaz web (+Add file), por ejemplo, lo nombramos authors.txt y ponemos nuestro nombre en el contenido:
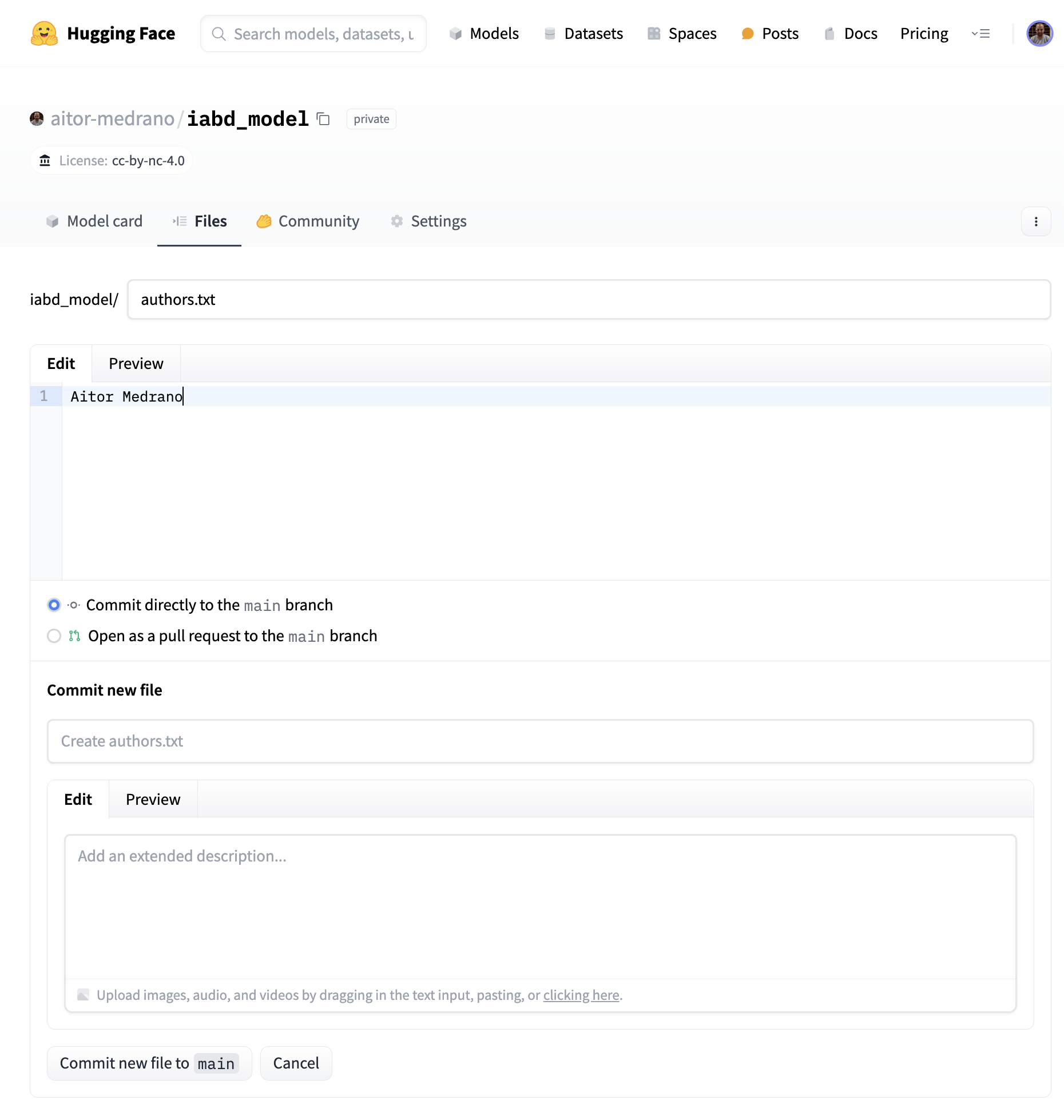
Y si ahora vamos a la pestaña de archivos, vemos como tenemos el archivo recién añadido, así como el archivo README.md que nos permite configurar la página de inicio de nuestro modelo:
Usando Git¶
Para poder trabajar con el repositorio ya hemos visto que podemos hacerlo mediante el interfaz web, aunque lo más cómodo para nosotros será trabajar mediante Git y GitLFS. GitLFS es una extensión para trabajar con archivos de gran tamaño (superiores a 10Mb), ya que es posible, que bien nuestros modelos o bien nuestros datasets tengan un tamaño considerable.
Así pues, como es probable que trabajemos con archivos superiores a los 10Mb, instalaremos en nuestro sistema git-lfs:
sudo apt-get install git-lfs # Ubuntu
brew install git-lfs # MacOS
Usando SSH
Para evitar tener que poner el usuario y contraseña al hacer push, es más cómodo generar una clave SSH y subirla a nuestro perfil.
Antes de generar una clave, es posible que ya tengamos una generada en ~/.ssh (Linux/MacOS) o en C:\\Users\\<usuario>\\.ssh (Windows) con algún archivo similar a id_rsa.pub. Si no fuera el caso, sí que tenemos que generar una clave y añadirla al agente:
ssh-keygen
ssh-add ~/.ssh/id_rsa
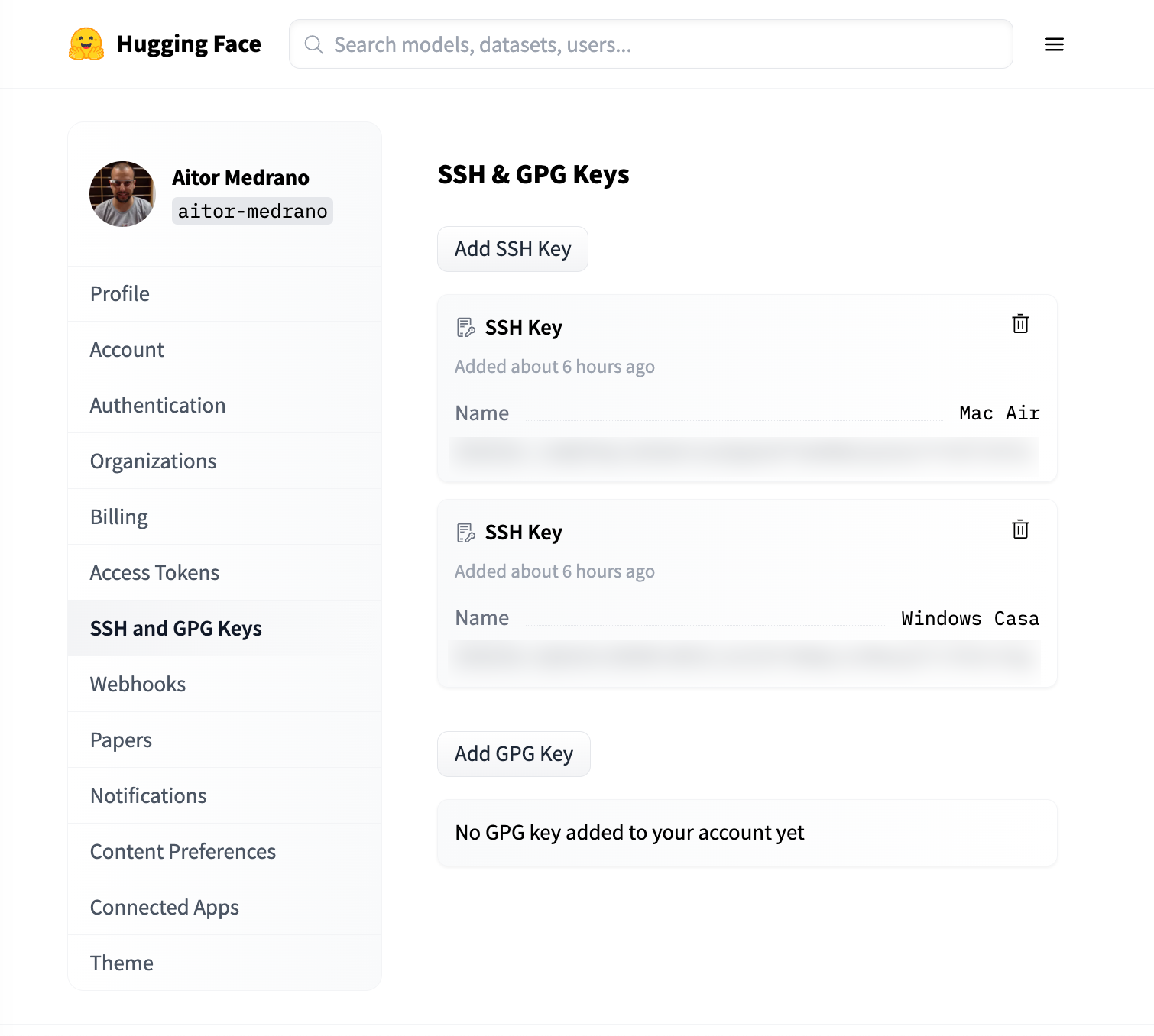
A continuación, vamos a las preferencias del usuario, y en la opción SSH and GPG Keys, creamos una nueva clave, poniendo como identificador, por ejemplo, el nombre de nuestro ordenador, y en la clave, pegamos el contenido del archivo .pub generado anteriormente.
Y haciendo uso de git, clonamos el repositorio:
git clone git@hf.co:aitor-medrano/iabd_model
cd iabd_model
Y comprobamos como se han descargado los archivos del modelo, incluyendo el que hemos creado previamente:
% ls
README.md authors.txt
Y habilitamos Git-LFS:
git lfs install
Si nuestros ficheros van a superar los 5GB, también deberemos habitarlos en Hugging Face:
huggingface-cli lfs-enable-largefiles .
Para seguir con este ejemplo, vamos a descargarnos los archivos del modelo omarques/autotrain-dogs-and-cats-1527055142 (config.json, preprocessor_config.json y el modelo pytorch_model.bin) y pegarlos dentro de nuestra carpeta iabd_model. Tras ello, los subimos mediante Git al repositorio:
aitormedrano@MacBook-Air-de-Aitor iabd_model % git add .
aitormedrano@MacBook-Air-de-Aitor iabd_model % git commit -m "Primera version"
[main ab99892] Primera version
4 files changed, 56 insertions(+)
create mode 100644 config.json
create mode 100644 preprocessor_config.json
create mode 100644 pytorch_model.bin
aitormedrano@MacBook-Air-de-Aitor iabd_model % git push
Uploading LFS objects: 100% (1/1), 352 MB | 26 MB/s, done.
Enumerando objetos: 8, listo.
Contando objetos: 100% (8/8), listo.
Compresión delta usando hasta 8 hilos
Comprimiendo objetos: 100% (6/6), listo.
Escribiendo objetos: 100% (6/6), 1.16 KiB | 1.16 MiB/s, listo.
Total 6 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To hf.co:aitor-medrano/iabd_model
6d21ec7..ab99892 main -> main
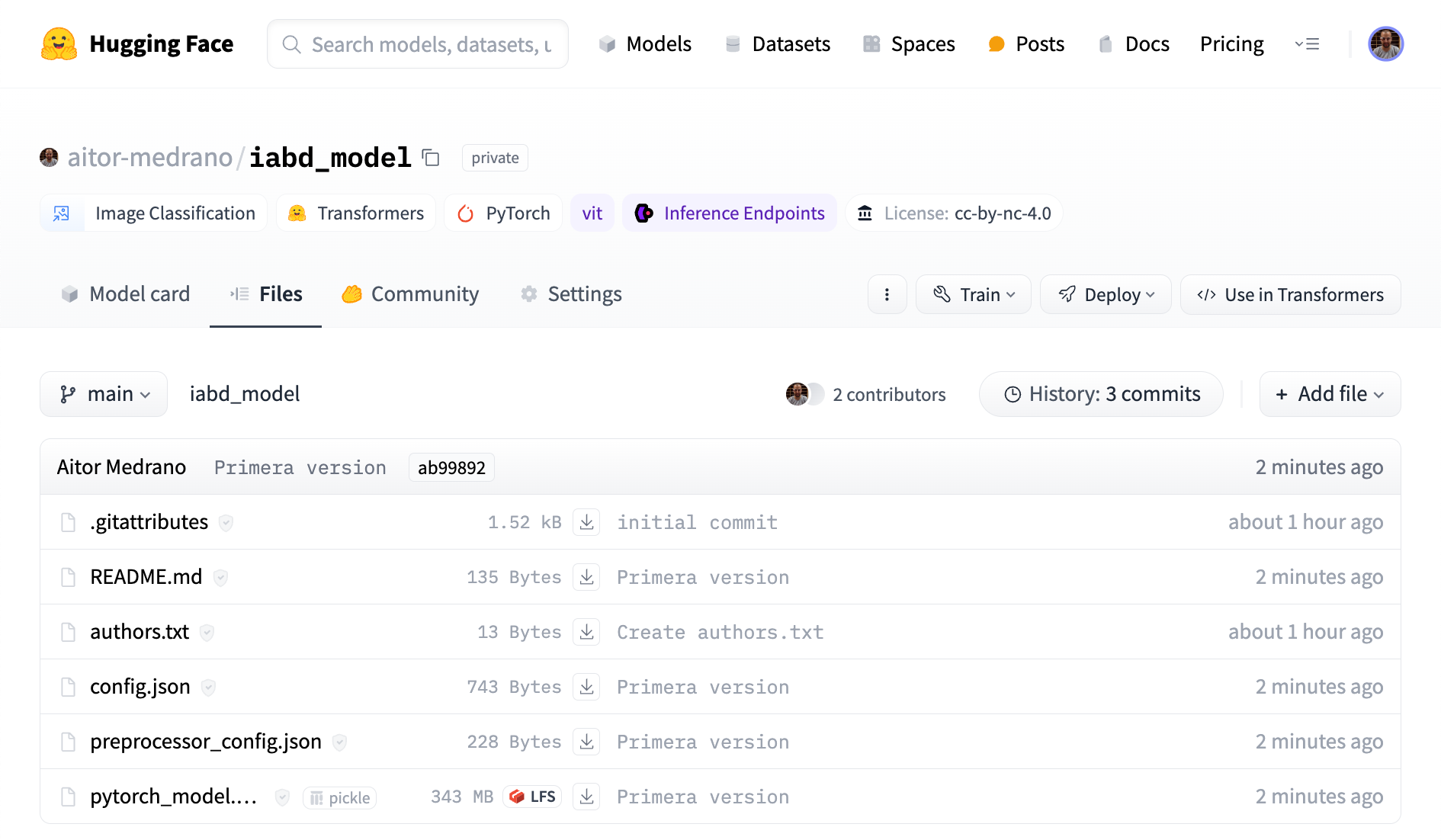
Si ahora vamos a la página web, veremos cómo ya aparecen los mismos archivos y cómo el archivo pytorch_model.bin se ha marcado como LFS:
Model Card¶
La tarjeta del modelo aporta información muy útil, como es la categoría de este, así como librerías, datasets, idiomas o los resultados obtenidos en la fase evaluación del modelo.
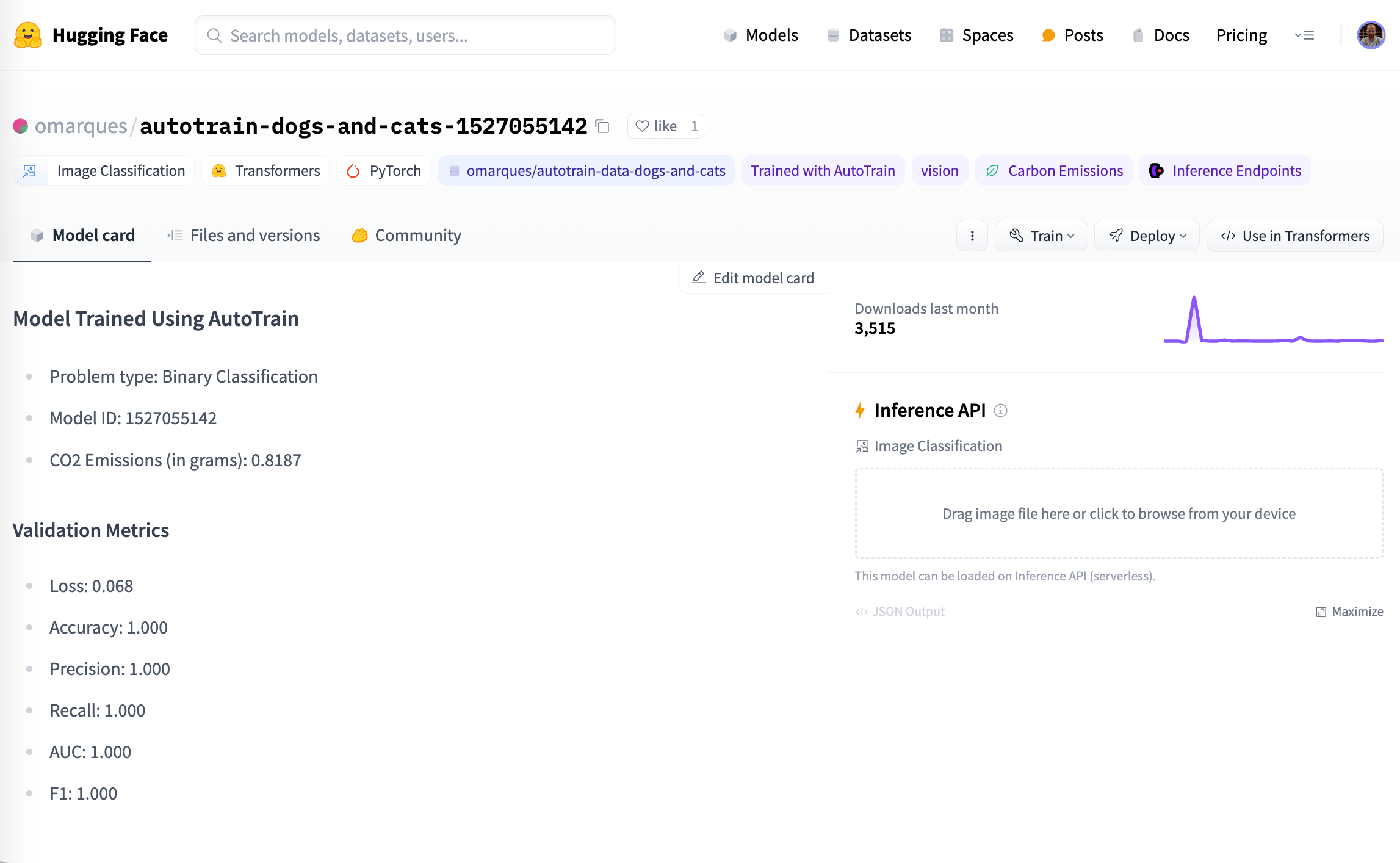
Si nos fijamos en la tarjeta del modelo de que hemos escogido anteriormente, podemos ver toda la información mostrada, con las diferentes etiquetas (Image Classification, Pytorch, etc...), así como las estadísticas y el bloque para probar el modelo directamente:
Así pues, vamos a editar nuestra tarjeta, y añadiremos los siguientes elementos:
tags:
- vision
- image-classification
datasets:
- omarques/autotrain-data-dogs-and-cats
De manera, que ahora nuestro modelo tendrá la siguiente apariencia:
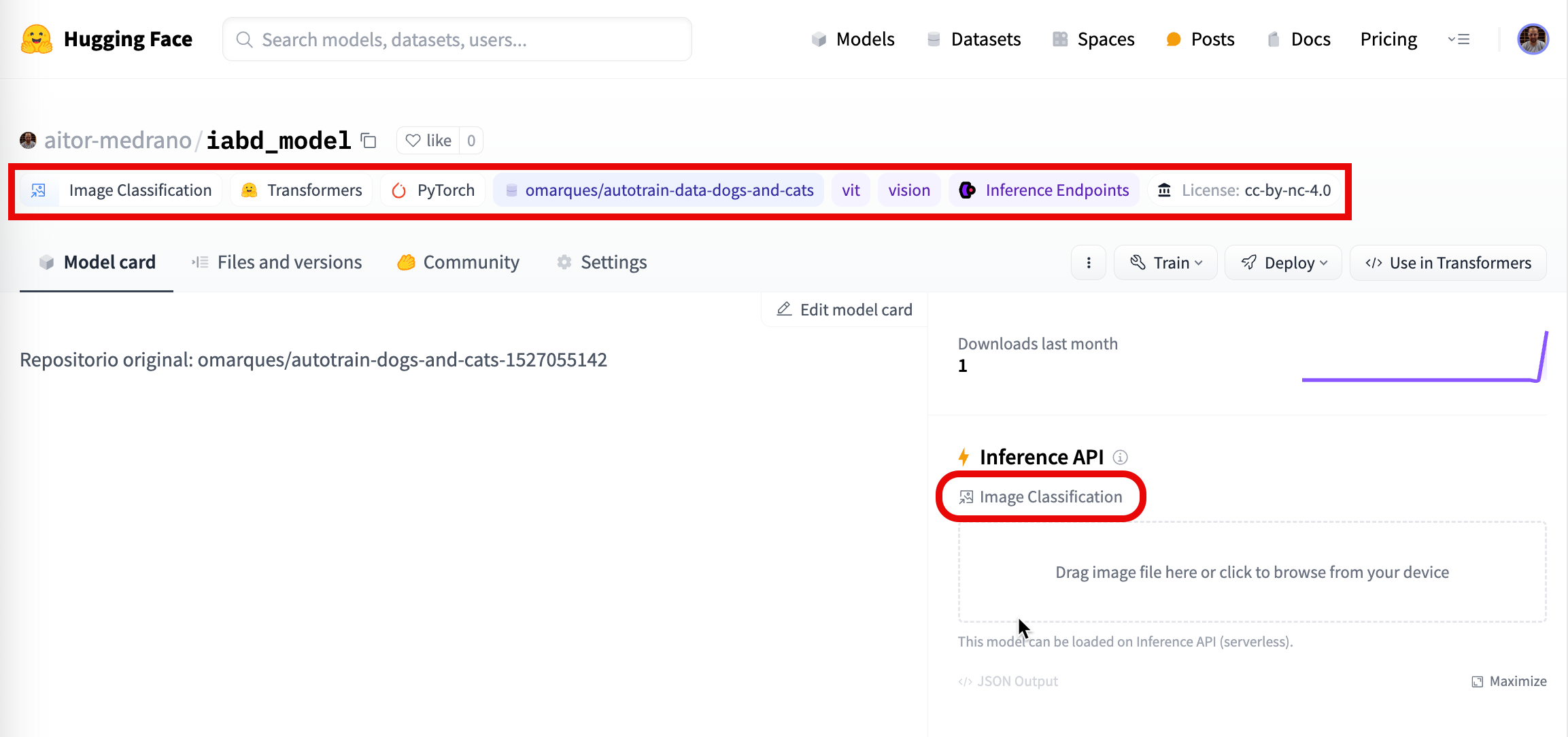
En próximas sesiones donde nos centremos en el fine-tuning, volveremos a la tarjeta del modelo para anotar toda la información obtenida.
Inference API¶
Si vamos a la tarjeta de nuestro modelo, si nuestro modelo tiene la suficiente visibilidad social (likes) veremos que en la parte derecha se ha marcado dentro del bloque de Inference API que se trata de un modelo de clasificación de imágenes y nos permite arrastrar una imagen.
Esta API utiliza un widget el cual obtiene información de los metadatos del modelo y del archivo de configuración (config.json) para saber qué interfaz mostrar. Si queremos, podemos indicarlo de forma explícita mediante el pipeline_tag de la tarjeta del modelo, por ejemplo, en nuestro caso image-classification.
Por ejemplo, si le pasamos una foto al bloque, veremos cómo se carga el modelo y al finalizar, nos muestra la predicción que ha realizado categorizando la imagen:
{kind=link}
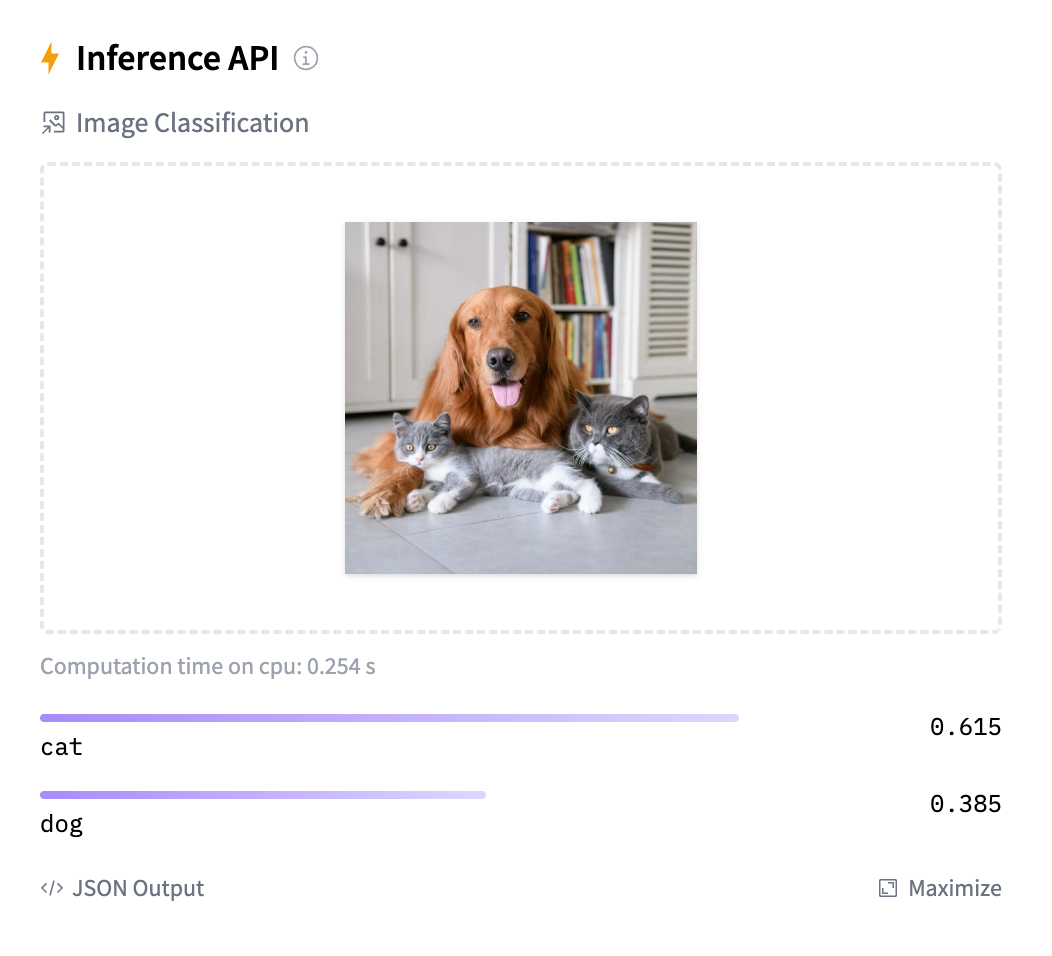
Valores de ejemplo
Aunque a priori se pueden añadir elementos para probar el modelo directamente, actualmente no funciona, al menos, para poner imágenes de entrada.
Pipelines¶
Ya hemos estudiado anteriormente que los pipelines son una abstracción para realizar inferencia sobre los modelos, simplificando el código complejo mediante un API dedicada a tareas.
Por ejemplo, podemos utilizarlo pasándole por parámetro la tarea a realizar o el modelo a utilizar:
from transformers import pipeline
pipe = pipeline("text-classification")
result = pipe("Me encanta venir a clase al IES Severo Ochoa")
print(result)
# [{'label': 'POSITIVE', 'score': 0.9526600241661072}]
Si queremos, podemos indicarle, además de la tarea, qué modelo queremos emplear:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
result = pipe("What is big data?")
print(result)
# [{'generated_text': "What is big data?\n\nBig data describes all kinds of things and I know who is a big data guy! I'd love to talk about anything related to big data science or what I hear in our labs, but that's really boring."}]
trad = pipeline("text2text-generation", model="google/flan-t5-base")
result = trad("translate from spanish to english: Me encanta disfrutar las vacaciones en la playa")
print(result)
# [{'generated_text': 'I love having holidays on the beach'}]
El listado de tareas disponibles se pueden consultar en la API del método transformers.pipeline con el parámetro task, por ejemplo, audio-classification, image-segmentation, image-to-text, token-classification, etc...
Datasets¶
Por último, Hugging Face también ofrece un entorno para la utilización y publicación de datasets, organizados por categorías, tamaños, lenguajes y licencias de uso:
Por ejemplo, uno de los datasets más utilizados al estudiar redes neuronales es el MNIST que contiene 70.000 imágenes de 28x28 en blanco y negro con los dígitos transcritos. Como podemos observar, el entorno ofrece previsualización de todas las columnas, así como la posibilidad de utilizar el dataset con unas pocas líneas de código:
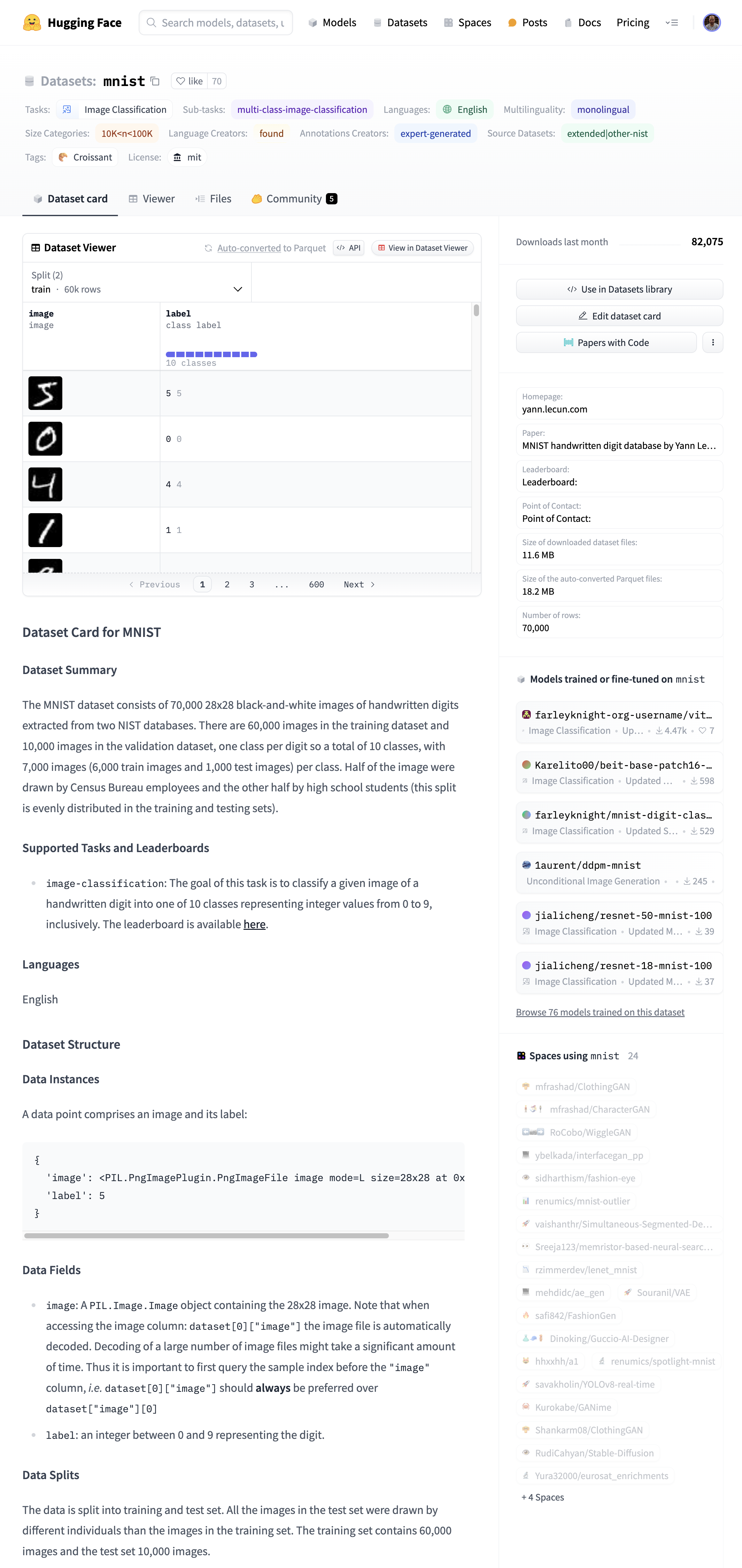
Si queremos usar el dataset, podemos pulsar sobre el botón Use in Datasets library o codificar el siguiente fragmento:
from datasets import load_dataset
mnist_dataset = load_dataset("mnist")
print(mnist_dataset)
# DatasetDict({
# train: Dataset({
# features: ['image', 'label'],
# num_rows: 60000
# })
# test: Dataset({
# features: ['image', 'label'],
# num_rows: 10000
# })
# })
Y si queremos acceder a una imagen:

imagen = mnist_dataset["train"]["image"][0]
etiqueta = mnist_dataset["train"]["label"][0]
print(etiqueta) # 5
Además, al abstraer los datos dentro de la librería datasets, se crea la estructura de datos necesaria para entrenar los modelos más fácilmente mediante la clase Trainer que facilita realizar el mismo proceso de fine-tuning a diferentes modelos (esto lo estudiaremos más adelante en la sesión sobre fine-tuning).
Creando nuestro dataset¶
Aunque más adelante veremos cómo utilizar la librería datasets para cargar, filtrar y persistir datasets, vamos a ver cómo crear un dataset en HuggingFace para almacenar los datos. Para ello, el primer paso es crearlo desde el interfaz gráfico, y a continuación, podemos acceder a la pestaña de Files y subiremos, por ejemplo, los datos de cp_train.csv, cp_test.csv y cp_val.csv:
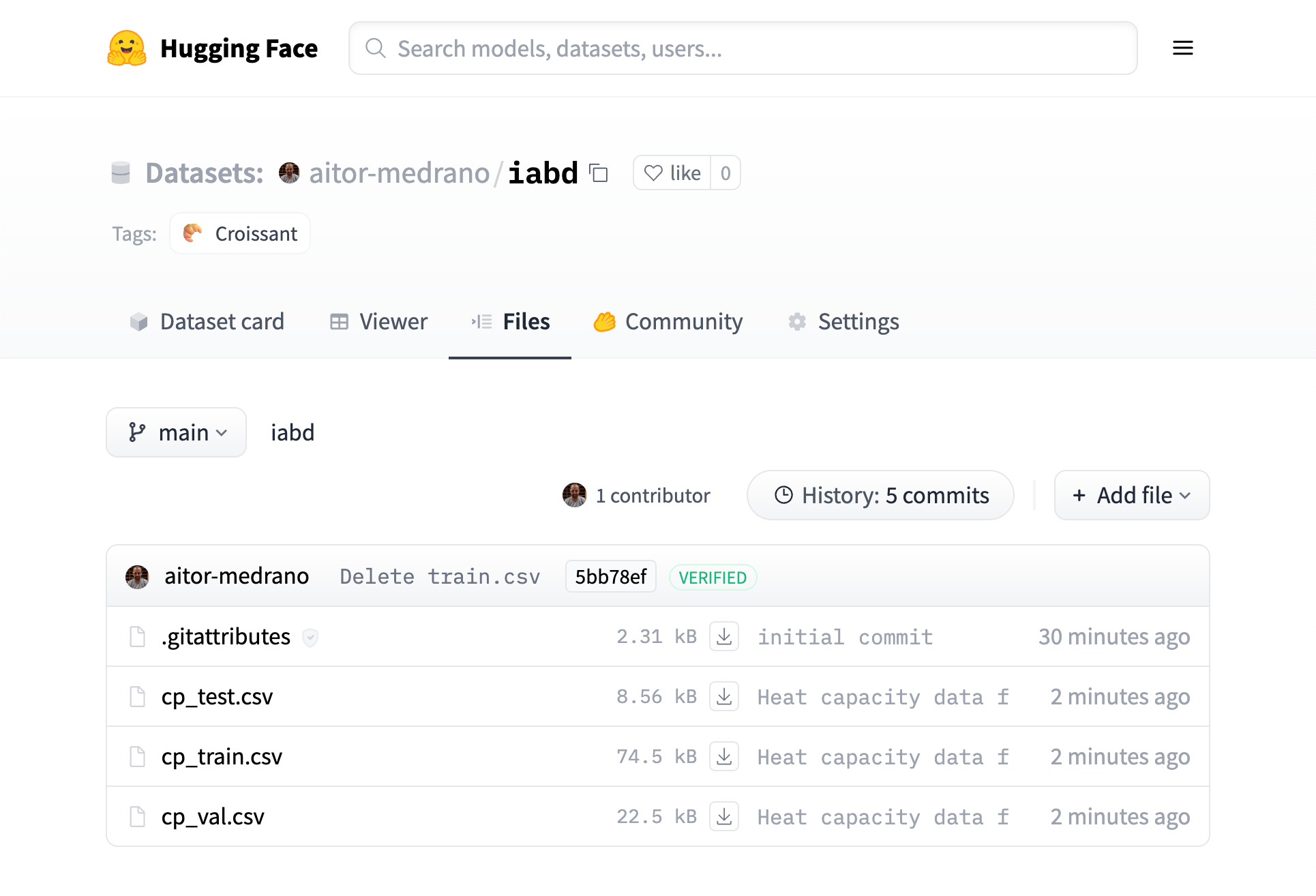
Una vez añadidos los archivos, automáticamente se mostrará la información (ya que los nombres de archivos contienen token reconocidos, como test, train, val...). Más información en https://huggingface.co/docs/datasets/repository_structure:
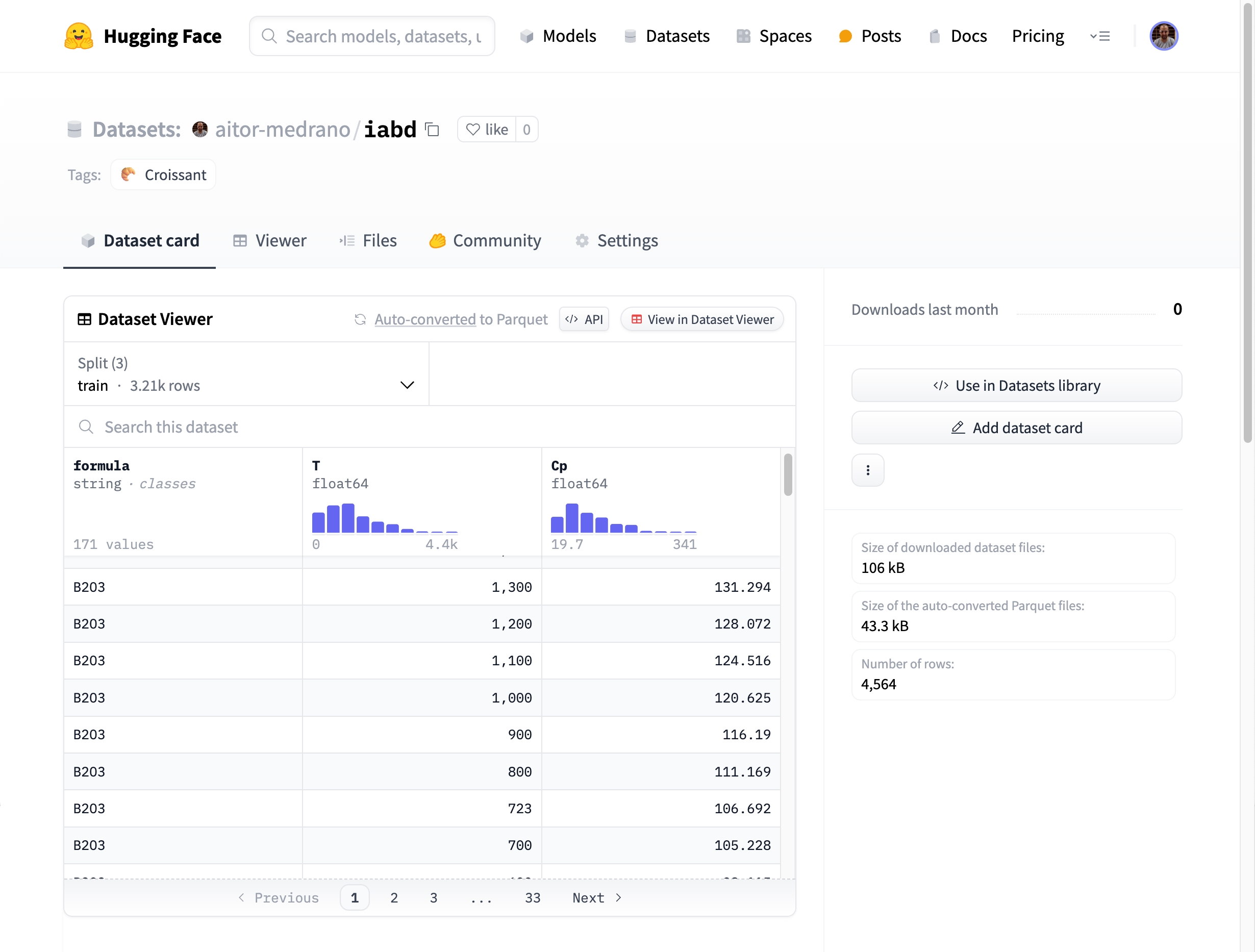
Y si editamos el archivo README.md, podemos añadir información extra como el tamaño del dataset, la licencia o fuera de los metadatos, toda la información que queramos como, por ejemplo, la descripción de los campos:
---
size_categories:
- 1K<n<10K
---
Extraído de <https://github.com/anthony-wang/BestPractices/tree/master/data>.
Campos:
* Formula (`string`)
* T (`float64`): Temperatura (K)
* CP (`float64`): Capacidad calorífica (J/mol K)
Para terminar, si queremos usar nuestro dataset, de la misma forma que antes, usaremos el método load_dataset, indicando el usuario y el nombre del dataset:
from datasets import load_dataset
iabd_dataset = load_dataset("aitor-medrano/iabd")
print(iabd_dataset)
Y al ejecutarlo podemos ver la descarga de las tres partes, así como los nombres de las características y la cantidad de filas de cada uno de los splits:
Downloading readme: 100%|██████████████████████████████████████████████████| 229/229 [00:00<00:00, 478kB/s]
Downloading data: 100%|████████████████████████████████████████████████| 74.5k/74.5k [00:00<00:00, 308kB/s]
Downloading data: 100%|████████████████████████████████████████████████| 22.5k/22.5k [00:00<00:00, 153kB/s]
Downloading data: 100%|███████████████████████████████████████████████| 8.56k/8.56k [00:01<00:00, 7.97kB/s]
Generating train split: 3214 examples [00:00, 148561.75 examples/s]
Generating validation split: 980 examples [00:00, 530376.51 examples/s]
Generating test split: 370 examples [00:00, 289748.41 examples/s]
DatasetDict({
train: Dataset({
features: ['formula', 'T', 'Cp'],
num_rows: 3214
})
validation: Dataset({
features: ['formula', 'T', 'Cp'],
num_rows: 980
})
test: Dataset({
features: ['formula', 'T', 'Cp'],
num_rows: 370
})
})
Referencias¶
- Tutorial inicial sobre NLP y características de Hugging Face
- Sugerencias de formación sobre Hugging Face
Actividades¶
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 3p) Crea un entorno virtual e instala las librerías de Hugging Face necesarias para ejecutar tanto el traductor como el modelo 2-1 de Stable Difussion. Genera un par de frases e imágenes. Anota con comentarios en el código el tiempo necesario para la generación de los resultados, y adjunta tanto las traducciones como las imágenes generadas.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c, CEPIA.3d / 1p) Crea una cuenta en Hugging Face, instala las CLI y tras hacer login, averigua cuanto ocupan los modelos descargados.
-
(RAMIA.1 / CEMIA.1d, CEMIA.1e / 2p) Basándote en lo aprendido a partir de los casos de uso de Hola Spaces y Hola Spaces 2.0, mediante Gradio tanto en Hugging Face como en local, crea un nuevo espacio en tu cuenta que permita realizar traducciones a partir de una caja de texto.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / opcional) Crea un modelo y siguiendo el ejemplo de Usando Git, configura tu clave SSH, y añade los archivos necesarios para poder inferir imágenes de perros y gatos desde el interfaz web. Posteriormente, mediante Python, realiza la inferencia del modelo haciendo uso de un Pipeline.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2p) Crea un dataset en Hugging Face a partir de los datos de entrenamiento (
titanic_train.csv) y pruebas (titanic_test.csv) del Titanic. A continuación, desde Python mediante la librería datasets, recupera los datos y muestra sus características.