Datasets
Ya hemos visto que podemos utilizar diferentes datasets existentes en la plataforma para re-entrenar nuestros modelos.
En esta sesión vamos a estudiar cómo crear un dataset a partir de nuestros datos, limpiar un dataset, a reducirlo para que quepa en RAM y como tras crear nuestro dataset, subirlo al Hub.
Cargando datos¶
Para cargar datos, haremos uso de la función load_dataset() de la librería Datasets. Si fuera necesaria instalarla, mediante pip haríamos:
pip install datasets
Podemos cargar archivos con diferentes formatos indicando el formato y los datos:
# CSV & TSV
load_dataset("csv", data_files="mis_datos.csv")
# Texto
load_dataset("text", data_files="mis_datos.txt")
# JSON & JSONL
load_dataset("json", data_files="mis_datos.jsonl")
Para este apartado nos vamos a centrar en los datos de SQuAD (Stanford Question Answering Dataset), compuesto de un conjunto de artículos de Wikipedia, con respuestas a diferentes preguntas sobre los artículos. En nuestro caso, nos vamos a centrar en una versión en castellano que podemos ver en https://huggingface.co/datasets/squad_es o descargarlo de desde https://github.com/ccasimiro88/TranslateAlignRetrieve/tree/master/SQuAD-es-v2.0.
Si descargamos los archivos y los colocamos en la misma carpeta que el siguiente script, podemos realizar una carga local de los datos:
from datasets import load_dataset
squad_dataset = load_dataset("json", data_files="train-v2.0-es.json", field="data")
print(squad_dataset)
Tras ejecutarlo, nos muestra que al cargar el dataset ha creado un split para train, con la cantidad de filas y las columnas contenidas dentro de un DatasetDict:
Generating train split: 442 examples [00:00, 1211.02 examples/s]
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
})
Si queremos obtener más información, podemos mostrar las características:
print(squad_dataset["train"].features)
# {'title': Value(dtype='string', id=None),
# 'paragraphs': [
# {'context': Value(dtype='string', id=None),
# 'qas': [
# {'answers': [{'answer_start': Value(dtype='int64', id=None), 'text': Value(dtype='string', id=None)}],
# 'id': Value(dtype='string', id=None),
# 'is_impossible': Value(dtype='bool', id=None),
# 'plausible_answers': [{'answer_start': Value(dtype='int64', id=None), 'text': Value(dtype='string', id=None)}],
# 'question': Value(dtype='string', id=None)}]
# }
# ]
# }
Y al tratarse de un diccionario, podemos navegar mediante los corchetes para, por ejemplo, recuperar parte de los datos:
print(squad_dataset["train"][0]["title"])
# Beyoncé Knowles
print(squad_dataset["train"][0]["paragraphs"][0])
# {'context': 'Beyoncé Giselle Knowles-Carter (nacida el 4 de septiembre de 1981)..',
# 'qas': [
# {'answers': [{'answer_start': 246, 'text': 'a finales de 1990'}],
# 'id': '56be85543aeaaa14008c9063', 'is_impossible': False, 'plausible_answers': None, 'question': '¿Cuándo Beyonce comenzó a ser popular?'},
# {'answers': ...
Cuando cargamos un dataset, realmente queremos cargar los datos de entrenamiento y los de validación. Para ello, le pasaremos un diccionario con los diferentes archivos para train y para val:
ficheros_datos = {"train": "train-v2.0-es.json", "val": "dev-v2.0-es.json"}
squad_dataset_train = load_dataset("json", data_files=ficheros_datos, field="data")
Obteniendo:
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
val: Dataset({
features: ['title', 'paragraphs'],
num_rows: 35
})
})
Si queremos cargar únicamente una de las partes, le pasaremos el parámetro split con el valor deseado:
ficheros_datos = {"train": "train-v2.0-es.json", "val": "dev-v2.0-es.json"}
squad_dataset_train = load_dataset("json", data_files=ficheros_datos, field="data", split="train")
print(squad_dataset_train)
Si el dataset está en un archivo comprimido en gzip, zip o tar, la librería descomprimirá los datos automáticamente:
ficheros_datos = {"train": "train-v2.0-es.json.zip", "val": "dev-v2.0-es.json.zip"}
squad_dataset_trainval = load_dataset("json", data_files=ficheros_datos, field="data")
print(squad_dataset_trainval)
Carga remota¶
Si el dataset está almacenado en una URL remota, podemos cargarlos directamente:
from datasets import load_dataset
url = "https://raw.githubusercontent.com/ccasimiro88/TranslateAlignRetrieve/master/SQuAD-es-v2.0/"
ficheros_datos = {
"train": url + "train-v2.0-es.json",
"val": url + "dev-v2.0-es.json",
}
squad_remote_dataset = load_dataset("json", data_files=ficheros_datos, field="data")
print(squad_remote_dataset)
Dividiendo el dataset¶
Si en vez de cargar por separado los datos de entrenamiento y los de test, tenemos un único conjunto de datos, podemos dividirlo mediante el método Dataset.train_test_split() indicando el tamaño, por ejemplo, de los datos de test:
from datasets import load_dataset
squad_dataset = load_dataset("json", data_files="train-v2.0-es.json", field="data", split="train")
squad_split_dataset = squad_dataset.train_test_split(test_size=0.1)
print(squad_split_dataset)
De manera que pasamos de un dataset de 442 filas a uno dividido en 397 para entrenamiento y 45 para test:
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 397
})
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 45
})
})
Cargando en Pandas¶
Si estamos trabajando con Pandas y queremos cargar un archivo que está en un dataset de Hugging Face, podemos utilizar la librería de huggingface_hub para crear, eliminar, actualizar y recuperar información de los repositorios.
Por ejemplo, para cargar un dataset CSV con Pandas podríamos hacer:
from huggingface_hub import hf_hub_download
import pandas as pd
REPO_ID = "aitor-medrano/iabd"
FICHERO = "cp_train.csv"
dataset = pd.read_csv(
hf_hub_download(repo_id=REPO_ID, filename=FICHERO, repo_type="dataset")
)
print(dataset)
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 3214 entries, 0 to 3213
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 formula 3214 non-null object
# 1 T 3214 non-null float64
# 2 Cp 3214 non-null float64
# dtypes: float64(2), object(1)
# memory usage: 75.5+ KB
Cargando en streaming¶
Si el dataset ocupa varios gigas, con modelos como BERT o GPT, puede que no quepan en memoria RAM. Para ello, la librería datasets gestiona los datos como ficheros mapeados en memoria realizando un streaming de los datos.

Para este apartado, vamos a utilizar parte de un dataset con código encontrado en GitHub de los diferentes lenguajes de programación, conocido como BigCode.
Gated dataset
El dataset de BigCode está configurado para pedir las credenciales de los usuarios que los utilizan. Esto se conoce como un Gated dataset. Es por ello que tenemos que hacer login en Hugging Face antes de poder descargarlo.
En nuestro caso, nos vamos a centrar en archivos DockerFile para que el dataset sea asumible (alrededor de 1Gb). Así pues, cargamos los datos:
from datasets import load_dataset
bigcode_dataset = load_dataset("bigcode/the-stack-v2", "Dockerfile", split="train")
print(bigcode_dataset)
# Dataset({
# features: ['blob_id', 'directory_id', 'path', 'content_id', 'detected_licenses', 'license_type', 'repo_name', 'snapshot_id', 'revision_id', 'branch_name', 'visit_date', 'revision_date', 'committer_date', 'github_id', 'star_events_count', 'fork_events_count', 'gha_license_id', 'gha_event_created_at', 'gha_created_at', 'gha_language', 'src_encoding', 'language', 'is_vendor', 'is_generated', 'length_bytes', 'extension'],
# num_rows: 4155925
# })
Y el contenido de un documento:
{
"blob_id":"a29dd2b33082d2b98541c66ba3620ae054991503",
"directory_id":"71568d223947f51cb007a8564e5f808e0987779e",
"path":"/src/Dapr/GameServer.Host/Dockerfile",
"content_id":"072b3138be512a71cf4e8bbbdb657497e808d2f6",
"detected_licenses":[
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"license_type":"permissive",
"repo_name":"devblack/OpenMU",
"snapshot_id":"8cdc521178da47c9c7d2daa502dc71688835fd0a",
"revision_id":"1064b0dca1a491bc28f325e42ca6b97d406d6558",
"branch_name":"refs/heads/master",
"visit_date":Timestamp("2023-04-07 10:56:30.043316"),
"revision_date":Timestamp("2023-03-17 20:32:25"),
"committer_date":Timestamp("2023-03-17 20:32:25"),
"github_id":None,
"star_events_count":0,
"fork_events_count":0,
"gha_license_id":None,
"gha_event_created_at":None,
"gha_created_at":None,
"gha_language":None,
"src_encoding":"UTF-8",
"language":"Dockerfile",
"is_vendor":false,
"is_generated":false,
"length_bytes":709,
"extension":""
}
Si ahora cargamos el dataset mediante streaming, pasándole el parámetros streaming=True, en vez de recuperar un Dataset, obtendremos un IterableDataset:
from datasets import load_dataset
streaming_dataset = load_dataset("bigcode/the-stack-v2", "Dockerfile", split="train", streaming=True)
print(streaming_dataset)
# Resolving data files: 100%|█████████████████████████████████████████████████| 976/976 [00:00<00:00, 1064.36it/s]
# IterableDataset({
# features: ['blob_id', 'directory_id', 'path', 'content_id', 'detected_licenses', 'license_type', 'repo_name', 'snapshot_id', 'revision_id', 'branch_name', 'visit_date', 'revision_date', 'committer_date', 'github_id', 'star_events_count', 'fork_events_count', 'gha_license_id', 'gha_event_created_at', 'gha_created_at', 'gha_language', 'src_encoding', 'language', 'is_vendor', 'is_generated', 'length_bytes', 'extension'],
# n_shards: 1
# })
Como sugiere el nombre, para acceder a los elementos del IterableDataset necesitamos iterar sobre él:
print(next(iter(streaming_dataset)))
Los elementos de un dataset en streaming se pueden procesar al vuelo mediante la función map o filter. Por ejemplo, para pasar a mayúsculas el campo license_type haríamos:
def mayusLicencias(registro):
registro["license_type"] = registro["license_type"].upper()
return registro
mapped_dataset = streaming_dataset.map(mayusLicencias)
print(next(iter(streaming_dataset)))
# ... 'detected_licenses': ['MIT', ...], 'license_type': 'PERMISSIVE', 'repo_name': 'devblack/OpenMU' ...
Al vuelo
Debemos tener en cuenta que la transformación se realizará al recorrer el dataset, no al invocar a los métodos map o filter.
Otras opciones son utilizar las operaciones take(), shuffle() o skip() dentro del IterableDataset para trabajar con muestras pequeñas de los datos cargados:
muestra = streaming_dataset.take(100)
muestra_aleatoria = streaming_dataset.shuffle(seed=42, buffer_size=1000).take(500)
rango = streaming_dataset.skip(1000).take(100)
Más información en https://huggingface.co/docs/datasets/stream y https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable.
Limpiando¶
De forma similar a Pandas o Spark, podemos manipular el contenido de los objetos Dataset.
El primer paso debería ser barajar los datos para desordenarlos y coger una muestra. Para ello, emplearemos Dataset.shuffle():
squad_train = squad_dataset_trainval["train"]
print(squad_train[0]["title"]) # Beyoncé Knowles
squad_train_shuffled = squad_train.shuffle(seed=333)
print(squad_train_shuffled[0]["title"]) # Carnaval
Seleccionando filas¶
Para recuperar filas, usaremos el método Dataset.select() pasándole un iterador con las posiciones a seleccionar:
tres_filas = squad_train_shuffled.select([5,10,15])
seis_filas = squad_train_shuffled.select(range(6))
Si queremos seleccionar las filas por algún criterio específico, debemos emplear Dataset.filter() y funciones lambda:
empieza_por_b_filas = squad_train_shuffled.filter(lambda x: x["title"].startswith("B"))
for i in range(empieza_por_b_filas.num_rows):
print(empieza_por_b_filas[i]["title"])
# Beidou _ Navigation _ Satellite _ System (en inglés)
# Biodiversidad
# Boston ...
Trabajando con columnas¶
Al trabajar con columnas, podemos añadir una nueva mediante Dataset.add_column(), cambiarles el nombre con DatasetDict.rename_column() o eliminar una columna con DatasetDict.remove_column():
nueva_columna = ["nueva"] * squad_train_shuffled.num_rows
squad_train_shuffled = squad_train_shuffled.add_column(name="inicial",column=nueva_columna)
# Dataset({
# features: ['title', 'paragraphs', 'inicial'],
# num_rows: 442
# })
squad_train_shuffled = squad_train_shuffled.rename_column(
original_column_name="inicial", new_column_name="modificada"
)
# Dataset({
# features: ['title', 'paragraphs', 'modificada'],
# num_rows: 442
# })
squad_train_shuffled = squad_train_shuffled.remove_columns(["modificada"])
# Dataset({
# features: ['title', 'paragraphs'],
# num_rows: 442
# })
Trabajando con map¶
Y la joya de la corona es la función Dataset.map() para aplicar una transformación a medida.
Por ejemplo, si queremos modificar todos los títulos y pasarlos a minúscula haremos:
from datasets import load_dataset
ficheros_datos = {"train": "train-v2.0-es.json", "test": "dev-v2.0-es.json"}
squad_dataset = load_dataset("json", data_files=ficheros_datos, field="data")
squad_dataset = squad_dataset["train"]
def titulo_minus(registro):
return {"title":registro["title"].lower()}
squad_minus = squad_dataset.map(titulo_minus)
# Mostramos 5 elementos
print(squad_minus.shuffle(seed=987)["title"][:5])
# ['marshall', 'ascensor', 'kanye', 'bbc televisión', 'florida']
Mediante la función map también podemos crear nuevas columnas a partir de los valores de otras. Por ejemplo, añadimos una nueva característica con la cantidad de párrafos y quitamos toda la información existente previamente de los párrafos:
# Añadimos nueva columna
squad_col_num_parrafos = squad_dataset.map(lambda x: {"num_paragraphs":len(x["paragraphs"])})
# Borramos la antigua
squad_col_num_parrafos = squad_col_num_parrafos.remove_columns("paragraphs")
print(squad_col_num_parrafos.shuffle(seed=987)[:5])
# {'title': ['Marshall', 'Ascensor', 'Kanye', 'BBC Televisión', 'Florida'], 'num_paragraphs': [51, 52, 79, 31, 35]}
¿Y si queremos ordenar los párrafos por la cantidad de párrafos? Para ello, podemos utilizar Dataset.sort():
squad_num_parrafos_ordenados = squad_col_num_parrafos.sort("num_paragraphs")
print(squad_num_parrafos_ordenados[:3]) # tres primeros
# {'title': ['Tono _ (música)', 'Uva', 'Letra _ case'], 'num_paragraphs': [10, 10, 12]}
print(squad_num_parrafos_ordenados[-3:]) # tres últimos
# {'title': ['American Idol (en inglés).', 'Nueva York', 'Budismo'], 'num_paragraphs': [127, 148, 149]}
Trabajando con batches¶
El método Dataset.map() admite el argumento batched que, si se establece en True, hace que envíe un lote de datos a la función map a la vez (el tamaño del lote es configurable mediante el parámetro batch_size, pero por defecto es de 1000). Al indicar batched=True, la función map recibe un diccionario con los campos del conjunto de datos, pero cada valor es ahora una lista de valores, y no un único valor, y del mismo modo, devuelve un diccionario con los campos que queremos actualizar o añadir a nuestro conjunto de datos, y una lista de valores.
Por ello, debemos modificar la función que realiza el map para que trabaje con un diccionario de listas.
Para el siguiente ejemplo, vamos a coger el dataset de SQuAD_es desde Hugging Face que contiene más datos, y vamos a comparar el tiempo de ejecución, recodificando la función para trabajar con un diccionario que contiene una lista por cada campo:
from datasets import load_dataset
import time
# Cargamos el dataset desde HF
squad_dataset = load_dataset("squad_es", "v2.0.0", split="train") # (1)!
def titulo_minus(registro):
return {"title":registro["title"].lower()}
inicio = time.time()
squad_minus = squad_dataset.map(titulo_minus) # (2)!
# Map: 100%|██████| 11858/11858 [00:00<00:00, 37926.07 examples/s]
fin = time.time()
print(fin - inicio) # 3.008699893951416
def titulo_minus_batch(batch):
return {"title":[titulo.lower() for titulo in batch["title"]]}
inicio = time.time()
squad_minus = squad_dataset.map(titulo_minus_batch, batched=True) # (3)!
# Map: 100%|██████| 11858/11858 [00:00<00:00, 535210.67 examples/s]
fin = time.time()
print(fin - inicio) # 0.19133710861206055
- Cargamos los datos desde el dataset de Hugging Face
- El mapper normal realiza casi 40.000 registros por segundo
- Al hacerlo con batches realiza más de 500.000 por segundo
Uso de Pandas¶
Para facilitar la conversión entre diferentes formados, podemos usar el método Dataset.set_format() para modificar el formato de salida (por ejemplo, a pandas, numpy, torch, tensorflow, jax, ...), sin modificar el formato original del dataset (el cual es Apache Arrow - arrow).
Así, si por ejemplo queremos pasar los datos a Pandas para trabajar con ellos, transformarlos o visualizarlos, podemos hacer:
print(squad_dataset[0])
squad_dataset.set_format("pandas")
df = squad_dataset[:]
print(df.shape) # (130313, 5)
# Otra forma
df2 = squad_dataset.to_pandas()
print(df2.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 130313 entries, 0 to 130312
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 id 130313 non-null object
# 1 title 130313 non-null object
# 2 context 130313 non-null object
# 3 question 130313 non-null object
# 4 answers 130313 non-null object
# dtypes: object(5)
# memory usage: 5.0+ MB
# Y realizar consultas sobre los datos, por ejemplo, la 5 preguntas con más respuestas
print(df2.groupby("title")["answers"].count().nlargest(5))
# title
# Reina 883
# Nueva York 817
# American Idol (en inglés). 790
# Beyoncé Knowles 753
# Universidad 738
Y para volver a tener un objeto Dataset, podemos utilizar el método Dataset.from_pandas() o resetear el dataset que teníamos mediante Dataset.reset_format():
squad_transformed = Dataset.from_pandas(df)
squad_original = squad_dataset.reset_format()
Creando un dataset desde cero¶
Si en vez de cargar un dataset, tenemos que crear uno, el primer paso será obtener los datos.
Ya sea mediante peticiones a URL externas con la librería request, accediendo a bases de datos relacionales, por ejemplo, mediante SQLAlchemy o a MongoDB mediante PyMongo, lo más normal es crear una estructura de datos mediante una lista o un diccionario y luego crear el dataset a partir del mismo.
Así pues, si en vez de cargar un dataset queremos crear uno desde cero, podemos hacer uso de Dataset.from_dict() o Dataset.from_list() dependiendo de donde tengamos los datos. Por ejemplo, vamos a conectarnos a MongoDB y creamos una lista con todos los datos. A partir de la lista, generamos un Dataset:
from datasets import Dataset
from pymongo import MongoClient
cliente = MongoClient('mongodb+srv://iabd:iabdiabd@cluster0.dfaz5er.mongodb.net')
# Vamos a trabajar con la colección grades de sample_training
iabd_db = cliente.sample_training
grades_coll = iabd_db.grades
# Creamos un dataset vacío mediante una lista
documentos = []
# Recuperamos todas las calificaciones
cursor = grades_coll.find({})
for document in cursor:
del document["_id"] # Quitamos el ObjectId
documentos.append(document)
mongo_dataset = Dataset.from_list(documentos)
print(mongo_dataset)
# Dataset({
# features: ['student_id', 'scores', 'class_id'],
# num_rows: 100000
# })
O si queremos almacenar los datos de forma temporal, por ejemplo, podemos hacer uso de Pandas:
df = pd.DataFrame.from_records(documentos)
df.to_json("grades-docs.jsonl", orient="records", lines=True)
jsonl_dataset = load_dataset("json", data_files="grades-docs.jsonl", split="train")
Persistiendo¶
Cuando cargamos un dataset se cachean los datos para evitar tener que descargar los datos de forma remota y crear las tablas de PyArrow. Podemos averiguar donde se almacenan los datos mediante la propiedad cache_files:
ficheros_datos = {"train": "train-v2.0-es.json", "test": "dev-v2.0-es.json"}
squad_dataset = load_dataset("json", data_files=ficheros_datos, field="data")
print(squad_dataset.cache_files)
# {'train': [{'filename': '/Users/aitormedrano/.cache/huggingface/datasets/json/default-e3ff36a1d8fe78df/0.0.0/ab573428e7a11a7e23eebd41a2a71665ac3789ce311cbad7049572034a9bda05/json-train.arrow'}],
# 'test': [{'filename': '/Users/aitormedrano/.cache/huggingface/datasets/json/default-e3ff36a1d8fe78df/0.0.0/ab573428e7a11a7e23eebd41a2a71665ac3789ce311cbad7049572034a9bda05/json-test.arrow'}]}
Si necesitamos persistir los datos de nuevo con las transformaciones realizadas, podemos hacerlo en diferentes formatos:
- Arrow:
Dataset.save_to_disk() - CSV:
Dataset.to_csv() - Pandas:
Dataset.to_pandas() - JSON:
Dataset.to_json() - Parquet:
Dataset.to_parquet()
Si por ejemplo persistimos el dataset en Arrow:
squad_dataset.save_to_disk("squad_train_test")
Se creará la siguiente estructura en las carpetas, donde para cada split se ha creado su propia carpeta, así como un par de archivos con metadatos:
squad_train_test
├── dataset_dict.json
├── test
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
└── train
├── data-00000-of-00001.arrow
├── dataset_info.json
└── state.json
Una vez que hemos persistido el dataset, lo podemos volver a cargar mediante load_from_disk:
from datasets import load_from_disk
squad_disk = load_from_disk("squad_train_test")
Si queremos persistirlos en formato CSV o JSON, por cada uno de los splits se crea un archivo separado. Para ello, podemos iterar sobre las claves mediante DatasetDict.items():
for split, dataset in squad_dataset.items():
dataset.to_json(f"squad_{split}.jsonl")
Publicando¶
Pues una vez hemos creado nuestro Dataset y lo hemos persistido en disco, el único paso que nos queda es publicar en Hugging Face. Para ello, en vez de subir los archivos a mano como hicimos en la sesión inicial desde el interfaz web o hacer uso de Git y copiar los archivos, desde Python es mucho más cómodo.
Previamente debemos realizar login para autenticarnos, tal como vimos en la sección de Login de la sesión anterior y usar nuestro token de acceso (en este caso, necesitamos que nuestro token sea de escritura):
hf auth login
Login desde un cuaderno Jupyter / Colab
Si trabajamos con un cuaderno de Jupyter o Colab, podemos utilizar la librería de huggingface_hub y al ejecutarlo, nos aparecerá una ventana donde introducir el token de acceso:
from huggingface_hub import login
login()
También podemos hacer uso de la variable de entorno HF_TOKEN para almacenar el token de acceso, ya sea con un Space almacenándolo en un secret de Spaces o en claves privadas de Google Colab.
Una vez autenticado, es tan sencillo como usar el método push_to_hub() (si queremos publicar el dataset como privado, le añadimos el parámetro private=True):
midataset.push_to_hub("aitor-medrano/midatasetpushed")
# midataset.push_to_hub("aitor-medrano/midatasetpushed", private=True)
Si tuviéramos diferentes splits podríamos hacer:
train_dataset.push_to_hub("aitor-medrano/midatasetpushed", split="train")
val_dataset.push_to_hub("aitor-medrano/midatasetpushed", split="validation")
Creando el dataset card
Para crear el dataset card, podemos emplear la aplicación https://huggingface.co/spaces/huggingface/datasets-tagging que facilita rellenar los campos e incluye recomendaciones de otros datasets.
También se recomienda leer la Dataset Card Creation Guide
Datasets multimedia¶
Si nuestro dataset va a contener elementos multimedia con imágenes o audios, podemos subir los archivos en crudo, lo cual es lo más practico en la mayoría de los casos. Si los dataset de imágenes o audios son muy grandes, se recomienda el formato WebDataset, aunque lo más normal, es almacenar el dataset en formato Parquet.
Dicho esto, vamos a ver como trabajar con datasets que contienen elementos multimedia.
Audios¶
Para trabajar con audios, necesitaremos instalar las librerías de audio:
pip install datasets[audio]
Una vez instalado, vamos a cargar un dataset que contiene audios, como es PolyAI/minds14:
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="es-ES", split="train")
print(minds)
# Dataset({
# features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
# num_rows: 486
# })
El dataset contiene 486 archivos de audio, cada uno de los cuales va acompañado de una transcripción, una traducción al inglés y una etiqueta que indica la intención de la consulta de la persona. La columna de audio contiene los datos de audio sin procesar. Veamos uno de los ejemplos:
{'path': '/home/jupyter-iabd/.cache/huggingface/datasets/downloads/extracted/a809f65b01ef0d5806ac705a72b9ca382622a5c03d9a17adf1ee73de4591650b/es-ES~APP_ERROR/60266571dc3604f481bcb50a.wav',
'audio': {'path': '/home/jupyter-iabd/.cache/huggingface/datasets/downloads/extracted/a809f65b01ef0d5806ac705a72b9ca382622a5c03d9a17adf1ee73de4591650b/es-ES~APP_ERROR/60266571dc3604f481bcb50a.wav',
'array': array([ 0. , 0. , 0. , ..., 0. ,
-0.00024414, -0.00024414]),
'sampling_rate': 8000
},
'transcription': 'hola buenas a ver tengo un problema con vuestra aplicación resulta que quiero hacer una transferencia bancaria a una cuenta conocida',
'english_transcription': 'hello good to see I have a problem with your application it turns out that I want to make a bank transfer to a known account',
'intent_class': 2,
'lang_id': 5}
Si nos centramos en el campo audio, vemos como contiene diferentes valores, los cuales forman parte de un objeto Audio:
path: ruta al archivo de audio (en este ejemplo*.wav).array: los datos del audio decodificados, representados por un array de NumPysampling_rate: la frecuencia de muestreo (8,000 Hz).
ejemplo = minds.shuffle()[0]
id2label = minds.features["intent_class"].int2str
label = id2label(ejemplo["intent_class"])
Y si queremos escuchar el audio, usando Gradio podemos crear un componente:
with gr.Blocks() as demo:
with gr.Column():
gr.Audio(audio["path"], label=label)
demo.launch(share=True)
Y reproducir el audio seleccionado:
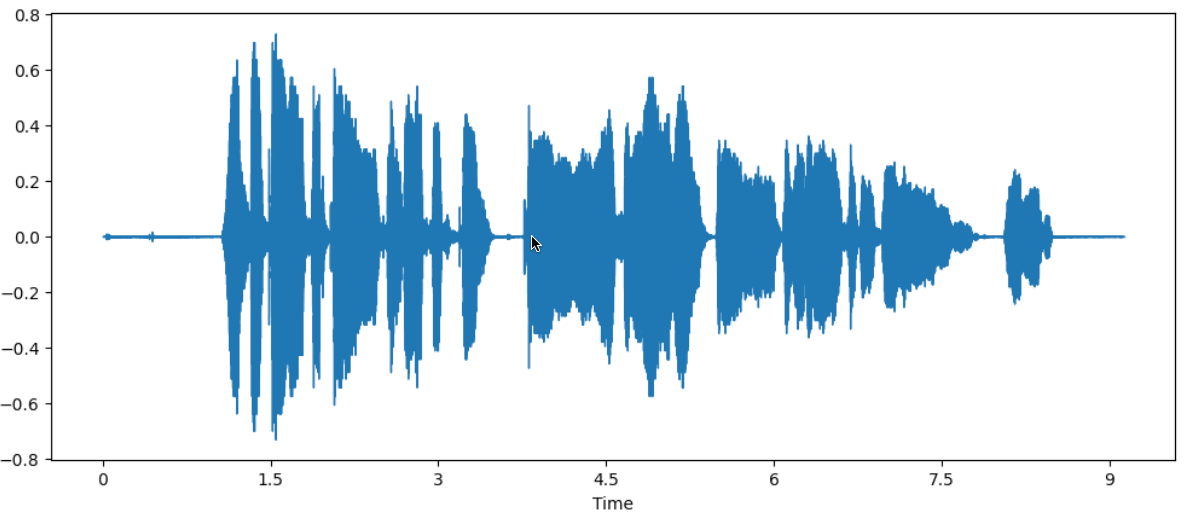
Finalmente, si queremos mostrar un gráfico con el espectograma del audio, y haciendo uso de la librería Librosa:
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = ejemplo["audio"]["array"]
sampling_rate = ejemplo["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
Obteniendo:
Creando un dataset desde Python¶
Si queremos crear un dataset a partir de audios propios, necesitamos crear un diccionario o una lista con la ruta a nuestros audios, y a continuación, llamar al método cast_column para transformar la columna a tipo Audio con las características que hemos visto antes.
Así pues, si tenemos los datos en un diccionario podemos hacer:
audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
Audiofolder¶
Otra posibilidad es crear el dataset a partir de una carpeta con todos los audios, y un archivo metadata.csv con los datos:
folder/train/metadata.csv
folder/train/first_audio_file.mp3
folder/train/second_audio_file.mp3
folder/train/third_audio_file.mp3
Y un archivo de metadatos con:
file_name,transcription
first_audio_file.mp3,este es el texto del primer audio
second_audio_file.mp3,en el segundo audio cuento un chiste
third_audio_file.mp3,y en este audio agradezco al público sus abucheos
Y a continuación, indicamos como primer parámetro autofolder y con data_dir indicamos la carpeta que contiene los audios:
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
Referencias¶
- Documentación oficial de dataset
- El capítulo La librería Dataset del curso NLP de Hugging Face.
Actividades¶
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 2.5p) Siguiendo el ejemplo inicial trabajado en la sesión y sólo empleando Python:
- Descarga los datos de SquadES considerando que los datos remotos son los de entrenamiento y validación.
- Con los datos de entrenamiento, divídelos en entrenamiento y pruebas.
- Tras ello, sobre el dataset de entrenamiento, añade una columna a los datos de entrenamiento con la cantidad de párrafos.
- Filtra los datos de entrenamiento para que el dataset sólo contenga aquellos registros que tienen más de 10 párrafos.
- Elimina la columna con la cantidad de párrafos.
- Persiste todo el dataset en formato Parquet.
- Finalmente, publícalo en Hugging Face, editando la tarjeta y poniendo un documento de ejemplo en la documentación.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 0.5p) Carga en streaming el dataset de imagenet-1k, y muestra la etiqueta de los primeros 5 elementos.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / 1p) Tenemos un dataset con información sobre vuelos retrasados en España y otro con información general sobre los aeropuertos. Se pide:
- Une ambos datasets para que la información de los vuelos contengan el nombre y la ciudad de los aeropuertos.
- Persiste los datos (sin elementos repetidos) en un dataset en formato Arrow.
- Publícalo en Hugging Face.
-
(RAPIA.3 / CEPIA.3b, CEPIA.3c / opcional ) Sobre la base de datos de MongoDB de
sample_trainingdisponible en los datos de muestra de MongoAtlas:- Carga los de estados de
states.js. - Realiza una join entre las colecciones
zipsystates. - Persiste los datos (sin elementos repetidos) en un dataset en formato JSON.
- Publícalo en Hugging Face.
- Carga los de estados de