Rendimiento
En esta sesión vamos a estudiar cómo mejorar el rendimiento respecto al acceso y procesamiento de los datos en MongoDB.
Índices¶
Los índices son una parte importante de la gestión de bases de datos. Un índice en una base de datos es similar a un índice de un libro; permite saltar directamente a la parte del libro en vez de tener que pasar las páginas buscando el tema o la palabra que nos interesa.
En el caso de MongoDB, un índice es una estructura de datos que almacena información sobre los valores de determinados campos de los documentos de una colección. Esta estructura permite recorrer los datos y ordenarlos de manera muy rápida. Así pues, los índices se utilizan tanto al buscar un documento como al ordenar los datos de una consulta.
Como idea base, emplear índices mejora el rendimiento de las consultas.
Índices y consultas agregadas
También podemos utilizar índices dentro del framework de agregación, sólo que en las fases de $match, $sort
Cuando una colección no contiene un índice, al buscar un documento, se realizará un escaneo de toda la colección, lo que se conoce como un collection scan, operación que tiene una complejidad lineal O(N), ya que la búsqueda de un documento es proporcional a la cantidad de documentos de la colección.
Preparando los ejemplos
Para los siguientes ejemplos, vamos a trabajar con dos colecciones distintas.
Por un lado, vamos a utilizar la colección de las 100.000 calificaciones que han obtenido diferentes estudiantes en diferentes trabajos, exámenes o cuestionarios almacenadas en sample_training.grades.
Un ejemplo de una calificación sería:
> db.grades.findOne()
< {
"_id": ObjectId("56d5f7eb604eb380b0d8d8cf"),
"student_id": 0,
"scores": [
{
"type": "exam",
"score": 91.97520018439039
},
{
"type": "quiz",
"score": 95.80410375967175
},
{
"type": "homework",
"score": 89.62485475572984
},
{
"type": "homework",
"score": 51.621532832724846
}
],
"class_id": 350
}
Y por el otro, vamos a utilizar la colección con casi 30.000 poblaciones (realmente, información sobre los códigos postales) almacenadas en sample_training.zips.
Un ejemplo de una población sería:
> db.zips.findOne()
< {
"_id": ObjectId("5c8eccc1caa187d17ca6ed29"),
"city": "CLEVELAND",
"zip": "35049",
"loc": {
"y": 33.992106,
"x": 86.559355
},
"pop": 2369,
"state": "AL"
}
Para comprobar el impacto del uso de índices, vamos a empezar con un ejemplo para ver cómo de rápido puede hacerse una consulta que tiene un índice respecto a uno que no lo tiene.
Para analizar el plan de ejecución de una consulta, podemos emplear el método explain() sobre un cursor:
> db.grades.find({"student_id" : 0, "class_id": 7}).explain("executionStats")
< {
explainVersion: '1',
queryPlanner: {
namespace: 'sample_training.grades',
indexFilterSet: false,
parsedQuery: {
'$and': [ { class_id: { '$eq': 7 } },{ student_id: { '$eq': 0 } } ]
},
queryHash: '3C69C349',
planCacheKey: '3C69C349',
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: {
stage: 'COLLSCAN',
filter: {
'$and': [ { class_id: { '$eq': 7 } },{ student_id: { '$eq': 0 } } ]
},
direction: 'forward'
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 104,
totalKeysExamined: 0,
totalDocsExamined: 100000,
executionStages: {
stage: 'COLLSCAN',
filter: {
'$and': [ { class_id: { '$eq': 7 } },{ student_id: { '$eq': 0 } } ]
},
nReturned: 1,
executionTimeMillisEstimate: 37,
works: 100001,
advanced: 1,
needTime: 99999,
needYield: 0,
saveprovincia: 100,
restoreprovincia: 100,
isEOF: 1,
direction: 'forward',
docsExamined: 100000
}
},
command: {
...
},
serverInfo: {
...
},
serverParameters: {
...
},
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1694280295, i: 27 }),
signature: {
hash: Binary(Buffer.from("237c7c32a8e17870315a7b2a7eb95a61fd2cc581", "hex"), 0),
keyId: 7230891675508277000
}
},
operationTime: Timestamp({ t: 1694280295, i: 27 })
}
explain
En cuanto al método explain(), nos va a permitir averiguar si una consulta utiliza el índice que esperamos, si utiliza un índice al realizar una proyección u ordenación de resultados, así como averiguar qué parte del plan de ejecución es más costoso.
El plan de ejecución devuelve mucha información, pero nos vamos a centrar en unos pocos atributos para analizar el resultado.
A grosso modo podemos observar como el resultado se divide en dos partes:
queryPlanner(línea4): muestra información sobre la consulta, indicando el plan ganador enwinningPlan(línea15)winningPlan.stage(línea16): muestra información de la acción realizada. Puede tomar los valores:COLLSCAN: escaneo completo de una colecciónIXSCAN: escaneo a partir de un índiceFETCH: al recuperar documentosSHARD_MERGE: al fusionar resultados de las particiones
executionStats: muestra estadísticas de ejecución (línea16)executionTimeMillis: tiempo empleado
Del resultado obtenido, se puede observar mediante la propiedad queryPlanner.winningPlan.stage que ha utilizado un COLLSCAN, lo que significa que se ha realizado un escaneo completo de toda la colección para encontrar los datos, es decir, no se ha usado ningún índice en la consulta. Esta consulta sólo devuelve un documento (executionStats.nReturned) pero ¡ha tenido que escanear los 100.000 existentes (executionStats.totalDocsExamined)!
Cuando vamos a buscar un elemento es mucho más rápido hacer un findOne que find, porque mientras find recorre toda la colección, con findOne en cuanto encuentre un documento, el cursor se detendrá.
Por defecto, el campo _id esta indexado. Así pues, vamos a buscar el mismo documento de antes, pero ahora mediante el campo indexado:
> db.grades.find({_id: ObjectId("56d5f7eb604eb380b0d8d8d3")}).explain("executionStats")
> {
queryPlanner : {
...
winningPlan : {
stage : "IDHACK"
},
rejectedPlans : [ ]
},
executionStats : {
executionSuccess : true,
nReturned : 1,
executionTimeMillis : 0,
totalKeysExamined : 1,
totalDocsExamined : 1,
executionStages : {
...
}
},
...
ok : 1,
...
}
Ahora MongoDB sólo ha escaneado el documento que ha devuelto ( executionStats.totalKeysExamined), y ha utilizado un índice para acceder al campo _id (valor IDHACK en winningPlan.stage). Al haber utilizado un índice, hemos evitado tener que mirar en más documentos. Esta consulta se ha realizado más rápidamente (y a mayor número de documentos más se nota la diferencia). Por supuesto, no siempre vamos a buscar por su _id, así que vamos a ver cómo crear nuevos índices.
Toda la información sobre el uso de índices con MongoDB se encuentra disponible en http://docs.mongodb.org/manual/core/indexes/.
Simples¶
Para crear un índice hemos de utilizar el método createIndex({ <atributo> : <orden> }). Si lo hacemos sobre un único campo, se conoce como índice simple.
Orden en los índices
El orden de los índices (1 para ascendente, -1 para descendente) no importa para un índice sencillo, pero sí que tendrá un impacto en los índices compuestos cuando se utilizan para ordenar o con una condición de rango.
El campo sobre el que se crea el índice puede tener valores únicos o un rango de valores, así como tratarse de un campo anidado dentro de otro documento (utilizaremos la notación .).
Si queremos crear un índice sobre la propiedad class_id en orden ascendente haríamos lo siguiente (vemos que nos devuelve el nombre del índice creado):
> db.grades.createIndex( {"class_id":1} )
< class_id_1
Si ahora volvemos a ejecutar la consulta sobre el identificador de la clase, comprobaremos como ahora ya realiza una búsqueda directa (valor FETCH en winningPlan.stage) y que no ha tenido que recorrer todos los documentos (pasa de 100.000 a 213).
> db.grades.find({"class_id" : 7}).explain("executionStats")
< {
queryPlanner : {
plannerVersion : '1',
...
winningPlan: {
stage: 'FETCH',
inputStage: {
stage: 'IXSCAN',
keyPattern: {
class_id: 1
},
indexName: 'class_id_1',
isMultiKey: false,
multiKeyPaths: {
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { class_id: [ '[7, 7]' ] }
}
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 213,
executionTimeMillis: 9,
totalKeysExamined: 213,
totalDocsExamined: 213,
executionStages: {
stage: 'FETCH',
nReturned: 213,
...
}
},
...,
ok : 1
}
Índice sobre _id
Todas las colecciones tienen creados un índice sobre el campo _id, el cual es único, aunque al visualizarlo no nos diga que lo sea, ya que no permite que se inserten dos _id iguales.
Cuidado con crear índices a lo loco
Un aspecto a considerar de los índices es que aceleran mucho las búsquedas, pero ralentizan las inserciones/modificaciones y hace que la información ocupe más espacio en disco. Por ello, deberemos considerar añadir índices a las colecciones donde el número de lecturas sea mayor que el de escrituras. Si sucede al revés, el uso de índices puede provocar un deterioro en el rendimiento.
Volvamos a nuestra consulta inicial donde recuperábamos las calificaciones de un determinado estudiante de una clase. Ahora mismo únicamente tenemos un índice sobre el identificador de la clase, pero no sobre el estudiante.
La pregunta es: cuando le pasamos a la consulta más columnas que las que tienen índices ¿sirve de algo?
Si ahora volvemos a ejecutar la consulta, vemos que ya no recorre toda la colección, pero ¿entendemos lo que está haciendo?
> db.grades.find({"student_id" : 0, "class_id": 7}).explain("executionStats")
< {
explainVersion: '1',
queryPlanner: {
...
winningPlan: {
stage: 'FETCH',
filter: {
student_id: {
'$eq': 0
}
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
class_id: 1
},
indexName: 'class_id_1',
isMultiKey: false,
multiKeyPaths: {
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { class_id: [ '[7, 7]' ] }
}
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 213,
totalDocsExamined: 213,
...
}
},
...
ok: 1,
}
En la planificación decide realizar una búsqueda del student_id 0 sobre el conjunto de datos obtenidos tras haber recorrido el índice de la class_id 7, es decir, primero recorre el índice (inputStage), y sobre el resultado obtenido, busca dicho estudiante. Por ello, recorre 213 documentos y a posteriori devuelve el único documento que cumple la condición.
Así pues, cuando tenemos una consulta sobre diferentes campos y alguno de ellos contiene un índice, primero utilizará dicho índice para quedarse con un subconjunto de los datos, y sobre dicho resultado, continuará filtrando los datos. Así pues, la respuesta corta es sí.
Pero, y si creamos el índice sobre el identificador el estudiante y repetimos la consulta ¿mejorará el rendimiento?
> db.grades.createIndex({"student_id":1})
< student_id_1
> db.grades.find({"student_id" : 0, "class_id": 7}).explain("executionStats")
< {
explainVersion: '1',
queryPlanner: {
...
winningPlan: {
stage: 'FETCH',
filter: {
class_id: {
'$eq': 7
}
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
student_id: 1
},
indexName: 'student_id_1',
isMultiKey: false,
multiKeyPaths: {
student_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { student_id: [ '[0, 0]' ] }
}
},
rejectedPlans: [
...
]
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 10,
totalDocsExamined: 10,
...
},
...
ok: 1,
}
En esta ocasión, vuelve a repetir estrategia pero con el índice de estudiantes (ya que devuelve menos documentos que el índice de clases), de manera que ahora sólo recorre 10 documentos.
Si nos centramos en la línea 33 y los planes rechazados (ahora aparece rellenado porque al tener dos índices, va a probar con cada uno de ellos por separado), vemos las diferentes consultas alternativas que ha generado MongoDB y que ha rechazado por implicar un peor rendimiento. Por ejemplo, elige el índice class_id_1 y luego busca el estudiante 0 o prueba a hacer una conjunción (AND_SORTED) de los dos índices y luego filtrar por la condición compuesta:
rejectedPlans: [
{
stage: 'FETCH',
filter: {
student_id: {
'$eq': 0
}
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
class_id: 1
},
indexName: 'class_id_1',
isMultiKey: false,
multiKeyPaths: {
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { class_id: [ '[7, 7]' ] }
}
},
{
stage: 'FETCH',
filter: {
'$and': [ { class_id: { '$eq': 7 } },{ student_id: { '$eq': 0 } } ]
},
inputStage: {
stage: 'AND_SORTED',
inputStages: [
{
stage: 'IXSCAN',
keyPattern: {
class_id: 1
},
indexName: 'class_id_1',
isMultiKey: false,
multiKeyPaths: {
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { class_id: [ '[7, 7]' ] }
},
{
stage: 'IXSCAN',
keyPattern: {
student_id: 1
},
indexName: 'student_id_1',
isMultiKey: false,
multiKeyPaths: {
student_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { student_id: [ '[0, 0]' ] }
}
]
}
}
]
Trabajando con MongoDBCompass¶
Además de crear y consultar los índices mediante el shell de MongoDB, podemos utilizar la herramienta gráfica MongoDBCompass.
Una característica muy útil es la posibilidad de visualizar el plan de ejecución de una forma gráfica y más cómoda. Para ello, en la pestaña de consultas, si repetimos la última consulta y pulsamos en Explain, podemos ver:
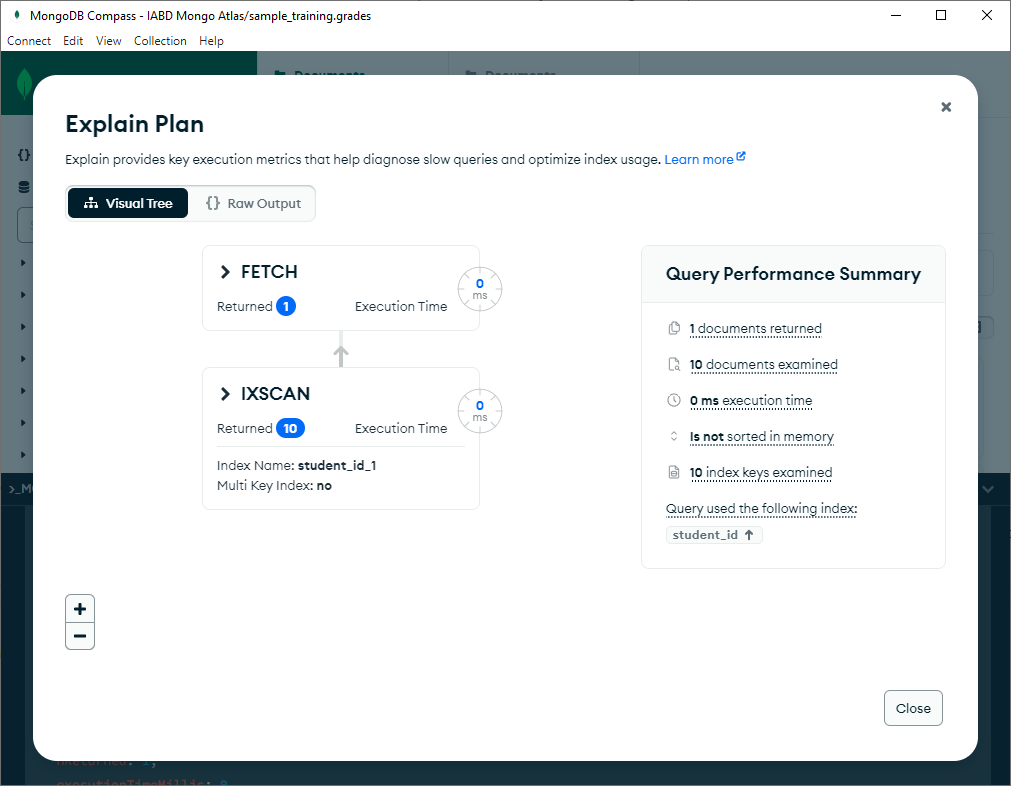
En la parte izquierda, un grafo con los pasos realizados:
- Primero el escaneo
IXSCANmediante el índicestudent_id_1, el cual devuelve 10 documentos. - Del resultado, se realiza el
FETCHque devuelve un único documento.
En la parte derecha, nos muestra un resumen del rendimiento, cantidad de documentos y claves examinadas, así como el tiempo de ejecución total.
Compuestos¶
Si queremos aplicar un índice sobre más de una propiedad, podemos crear índices compuestos, indicando las propiedades separadas por coma, de manera que el índice agrupa por la primera propiedad, y después por el/los siguiente(s) campo(s), hasta un máximo de 32 campos.
Así pues, ahora crearemos un índice compuesto sobre el identificador del estudiante y de la clase:
> db.grades.createIndex({"student_id":1, "class_id":1})
Y vemos si cambia su comportamiento respecto a los dos índices individuales:
> db.grades.find({"student_id" : 0, "class_id": 7}).explain("executionStats")
< {
explainVersion: '1',
queryPlanner: {
...
winningPlan: {
stage: 'FETCH',
inputStage: {
stage: 'IXSCAN',
keyPattern: {
student_id: 1,
class_id: 1
},
indexName: 'student_id_1_class_id_1',
isMultiKey: false,
multiKeyPaths: {
student_id: [],
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { student_id: [ '[0, 0]' ], class_id: [ '[7, 7]' ] }
}
},
rejectedPlans: [
{
stage: 'FETCH',
filter: {
class_id: {
'$eq': 7
}
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
student_id: 1
},
indexName: 'student_id_1',
isMultiKey: false,
multiKeyPaths: {
student_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { student_id: [ '[0, 0]' ] }
}
},
{
stage: 'FETCH',
filter: {
student_id: {
'$eq': 0
}
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
class_id: 1
},
indexName: 'class_id_1',
isMultiKey: false,
multiKeyPaths: {
class_id: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { class_id: [ '[7, 7]' ] }
}
}
]
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 1,
totalKeysExamined: 1,
totalDocsExamined: 1,
...
}
},
...
ok: 1,
}
Podemos observar como ahora sólo examina una única clave y un documento, utilizando el índice student_id_1_class_id_1, y que rechaza emplear los índices simples, ya sea el del estudiante como el de la clase.
Es importante destacar que, en los índices compuestos, el orden de los índices importa, y mucho. Si hacemos una consulta que sólo utilice el atributo class_id, el índice compuesto no se va a utilizar, ya que los identificadores de clases realmente son índices secundarios a partir del identificador del estudiante, y localizar una clase implicaría volver a recorrer todos los estudiantes.
Pero volviendo al índice creado, si hacemos una consulta por ambos campos, da igual el orden que utilizamos en la búsqueda que siempre va a utilizar el índice. Esto es, las siguientes consultas van a utilizar el mismo índice student_id_1_class_id_1, ya que el orden de los campos en la consulta no importa:
db.grades.find({"student_id" : 0, "class_id": 7})
db.grades.find({"class_id" : 7, "student_id": 0})
No es lo mismo
No confundir los índices compuestos con hacer 2 o más índices sobre diferentes propiedades.
Prefijos¶
Si creamos un índice sobre los campos (A,B,C), el índice se va a utilizar para las búsquedas sobre (A), sobre la dupla (A,B) y sobre el trio (A,B,C). Es decir, los índices se usan con los subconjuntos por la izquierda (prefijos) de los índices compuestos.
Si tenemos varios índices candidatos a la hora de ejecutar, el optimizador de consultas de MongoDB los usará en paralelo y se quedará con el resultado del primero que termine. Más información en http://docs.mongodb.org/manual/core/query-plans/
Para mejorar el espacio y el rendimiento en las inserciones/modificaciones, si tenemos un índice compuesto sobre (A,B,C) y uno sencillo sobre (A), es recomendable eliminar éste último, ya que el compuesto va a conseguir el mismo propósito sin necesidad de duplicar la información.
Regla ESR
La regla ESR define el orden a definir a la hora de crear un índice compuesto, empezando por la igualdad (Equality), luego la ordenación (Sort), y finalmente el rango (Range).
Por ejemplo, para la siguiente consulta
db.zips.find(
{ state: 'AL',
pop: { $gt: 10000 }
}).sort(
{ city: 1 }
)
La propiedad state tiene la igualdad, pop: { $gt: 10000 } se basa en un rango y city se emplea para ordenar.
Así pues, siguiendo la regla ESR el índice óptimo sería:
{ state: 1, city: 1, pop: 1 }
Más información en https://www.mongodb.com/docs/manual/tutorial/equality-sort-range-rule
Ordenando¶
Cuando ordenamos los datos mediante una operación sort, MongoDB va a intentar utilizar todos los índices disponibles.
Con los índices simples, MongoDB puede recorrer el índice en ambas direcciones, hacia adelante (forward) o hacia atrás (backward), dando igual el orden en que definimos el índice.
Conviene entender bien qué sucede cuando ordenamos por varios campos. Para ello, lo recomendable es crear índices compuestos.
Una característica de los índices compuestos es que podemos utilizar sus prefijos para ordenar los documentos, e incluso, podemos filtrar y ordenar las consultas dividiendo el índice compuesto entre los predicados de filtrado y ordenación.
Por ejemplo, si tenemos el índice (A,B,C,D), podemos hacer una consulta que filtre por (A,B) y que ordene por (C), y estaría utilizando el índice compuesto.
Además, si el orden de los campos es inverso, mientras el orden del índice al completo se respete, se seguirá empleado el índice, recorriendo el índice en modo backward (hacía atrás) (en vez del modo forward, hacia adelante).
Por lo tanto, en el caso de los índices compuestos, el orden en el que se definen y su sentido es muy importante.
Si tenemos el índice (A,-B, C, -D), el índice compuesto se utilizará tanto para:
db.iabd.find({"A":"aaa"}).sort({"B":-1})
db.iabd.find({"A":"aaa", ).sort({"B":-1,"C":1})
db.iabd.find({"A":"aaa", "B":"bbb"}).sort({"C":1})
db.iabd.find({"A":"aaa", "B":"bbb"}).sort({"C":1, "D":-1})
db.iabd.find({"A":"aaa", ).sort({"B":-1,"C":1, "D":-1})
como para su inversos:
db.iabd.find({"A":"aaa", ).sort({"B":1,"C":-1})
db.iabd.find({"A":"aaa", "B":"bbb"}).sort({"C":-1})
db.iabd.find({"A":"aaa", ).sort({"B":1,"C":-1, "D":1})
pero no para:
db.iabd.find({"B":"bbb")
db.iabd.find({"A":"aaa", ).sort({"B":1,"C":1})
db.iabd.find({"A":"aaa", ).sort({"B":1,"C":-1, "D":-1})
Parciales¶
En ocasiones, por cuestiones de espacio y rendimiento en el mantenimiento, queremos crear los índices sobre un subconjunto de los documentos de una colección. Para ello, le pasaremos a la propiedad partialFilterExpression el criterio que debe cumplir el índice parcial.
Si sobre la colección zips queremos poner un índice sobre el estado únicamente para los documentos cuya población es igual o superior a 5000, podemos hacer uso de un índice parcial:
db.zips.createIndex(
{"state":1},
{ partialFilterExpression: { "pop": { $gte: 5000 } } }
)
Sólo se empleará el índice cuando hagamos una consulta sobre dichos campos y obtengamos un subconjunto de los datos almacenados (la condición debe ser tan o más restrictiva que la de la definición del índice). Por ejemplo:
db.zips.find({"state":"AL") // No emplea el índice, no utiliza el filtro
db.zips.find({"state":"AL", "pop": { $lt: 4000 } }) // No emplea el índice, ya que no cumple el filtro
db.zips.find({"state":"AL", "pop": { $gt: 6500 } }) // Sí emplea el filtro
Así pues, si comprobamos el plan de ejecución veremos que sí que utiliza el índice creado (provincia_1), que se trata de un índice parcial (isPartial:true) y que no examina todos los documentos (sólo 229):
> db.zips.find({"state":"AL", "pop": { $gt: 6500 } }).explain("executionStats")
< {
explainVersion: '1',
queryPlanner: {
...
winningPlan: {
stage: 'FETCH',
filter: {
pop: { '$gt': 6500 }
},
inputStage: {
stage: 'IXSCAN',
keyPattern: {
state: 1
},
indexName: 'state_1',
isMultiKey: false,
multiKeyPaths: {
state: []
},
isUnique: false,
isSparse: false,
isPartial: true,
indexVersion: 2,
direction: 'forward',
indexBounds: { state: [ '["AL", "AL"]' ] }
}
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 188,
executionTimeMillis: 0,
totalKeysExamined: 229,
totalDocsExamined: 229,
...
},
...
ok: 1,
}
La ventaja de utilizar índices parciales es que son más ligeros en su creación y mantenimiento y utilizan menos espacio que un índice sobre todos los posibles valores.
Dispersos¶
Un tipo especial de índice parcial son los índices dispersos (sparse), los cuales únicamente indexan aquellos documentos que tienen el campo (incluso con valor nulo), saltando aquellos donde el campo no existe.
Así pues, estas dos sentencias son equivalentes:
db.zips.createIndex({"state":1}, {sparse:true})
db.zips.createIndex({"state":1}, {partialFilterExpression: {"state":{$exists: true}} })
Autoevaluación
Suponemos que tenemos los siguientes documentos en una colección llamada 'people' con los siguientes documentos:
> db.iabd.find()
< { "_id" : ObjectId("50a464fb0a9dfcc4f19d6271"), "nombre" : "Andreu", "cargo" : "Técnico" }
{ "_id" : ObjectId("50a4650c0a9dfcc4f19d6272"), "nombre" : "Aitor", "cargo" : "CEO" }
{ "_id" : ObjectId("50a465280a9dfcc4f19d6273"), "nombre" : "Marina" }
Y hay un índice definido del siguiente modo:
db.iabd.createIndex({cargo:1}, {sparse:1})
Si realizamos la siguiente consulta, ¿Qué documentos aparecerán y por qué?
db.iabd.find({cargo:null})
- Ningún documento, ya que la consulta utiliza el índice y no puede haber documentos que no contengan el campo
cargo - Ningún documento, ya que la consulta de
cargo:nullsólo encuentra documentos que de manera explícita tienen el cargo a nulo, independientemente del índice. - El documento de
Marina, ya que la consulta no utilizará el índice - Todos los documentos de la colección, ya que todos cumplen que
cargo:null
El documento de Marina, ya que el índice no se ejecutará sobre este documento.
Únicos¶
Un índice único es similar al que creamos en cualquier sistema gestor de bases datos, prohibiendo valores duplicados para el campo indexado. MongoDB, por defecto, crea un índice único en el campo _id para cada colección.
Por ejemplo, para la colección zips si queremos asegurarnos que no hay dos zip repetidos podemos hacer crearemos el índice pasándole como segundo parámetro {unique: true}:
db.zips.createIndex( { "zip": 1 }, { unique: true } )
Además, una vez creado el índice, no permitirá insertar valores duplicados.
En un índice compuesto, la univocidad se realiza entre las combinaciones de valores de todos los campos del índice. Por ejemplo, las siguientes operaciones no violan el índice único, ya que las combinaciones de nombre y cargo no se repiten:
> db.iabd.createIndex( { "nombre": 1, "cargo": 1 }, { unique: true } )
> db.iabd.insert({"nombre": "Marina", "cargo": "Técnico"})
> db.iabd.insert({"nombre": "Marina", "cargo": "CEO"})
Datos duplicados
Si ya tenemos una colección con datos duplicados, MongoDB no nos va a dejar crear un índice único
¿Y qué sucede si insertamos un documento que no contiene el campo indexado? Pues el primero que insertemos, funcionará. Pero si insertamos un segundo documento, no lo insertará, ya que MongoDB almacenará como nulo el valor del primer documento, y para el segundo, se quejará que ya existe uno con dicho valor.
Multiclave¶
Preparando los ejemplos
Para los ejemplos con arrays vamos a trabajar con la colección de mensajes de un blog almacenada en la colección sample_training.posts. Un ejemplo de mensaje sería:
{
"_id": {
"$oid": "50ab0f8bbcf1bfe2536dc40e"
},
"body": "Four score and seven years ago our fathers brought forth on this continent a new nation...",
"permalink": "aBkusYpZxvbvJkgGjTDv",
"author": "machine",
"title": "Gettysburg Address",
"tags": [
"season", "rest", "viola", "saudi arabia", "difference",
"computer", "humor", "valley", "scene", "jute"
],
"comments": [
{
"body": "Lorem ipsum dolor sit amet...",
"email": "bONSPozL@irpkmUiT.com",
"author": "Flora Duell"
},
...
],
"date": {
"$date": "2012-11-20T05:05:15.264Z"
}
}
Por supuesto, podemos crear índices sobre propiedades que forman parte de un array. Así pues, podemos crear un índice sobre el autor de los comentarios mediante:
db.posts.createIndex( {comments.author:1} )
Pero además también podemos crear un índice sobre todas las etiquetas, lo cual indexa cada elemento del array, con lo que podemos buscar por cualquier objeto del array. Este tipo de índices se conocen como multiclave:
db.posts.createIndex( {tags:1} )
Cuando se indexa una propiedad que es un array, se crea un índice multiclave para todos los valores del array de todos los documentos. Internamente, está creando un índice simple para cada uno de los valores. El uso de estos índices son lo que hacen que las consultas sobre documentos embebidos funcionen tan rápido.
db.posts.find( {"tags": {"$all":["computer","humor"]} } )
Es importante destacar que sólo se pueden crear índices compuestos multiclave cuando únicamente una de las propiedades del índice compuesto es un array; es decir, no puede haber dos propiedades array en un índice compuesto, ya que provocaría un producto cartesiano y su rendimiento no sería escalable.
Otros tipos de índices¶
-
Geoespaciales, para trabajar con coordenadas.
-
De texto, para realizar búsquedas dentro de un campo:
db.posts.createIndex({"body": "text"}) db.posts.createIndex({"body": "text"}, { default_language: "english" }) // o spanishPudiendo realizar búsquedas con el operador
$text:db.posts.find( { $text: { $search: "seven" } })Estos índices también pueden ser compuestos, sensibles o no a las mayúsculas, permitiendo delimitar los tokenizadores, el idioma, así como asignar diferente peso a cada campo del índice.
-
Insensibles a las mayúsculas (case insensitivity): permiten la realización de consultas que realizan comparaciones de cadena sin tener en cuenta las mayúsculas. Para ello, emplearemos el parámetro
collation, indicando el idioma mediantelocaley el nivel de comparación constrength(por ejemplo, si queremos que ignore las tildes, diéresis, etc...):db.posts.createIndex( {title: 1}, {collation: { locale: 'en', strength: 2 }} ) -
Comodín (wildcards) para crear índices sobre campos cuyos nombres pueden cambiar dentro de una colección, permitiendo realizar consultas indexadas en un conjunto de campos desconocido.
db.posts.createIndex( { "$**" : 1 } ) db.posts.createIndex( { "comments.$**" : 1 } ) -
Hash, centrado en el uso de sharding.
-
TTL (Time-to-live): utilizados para eliminar los documentos pasados un determinado tiempo. Por ejemplo, si queremos que se eliminen los posts que tienen más de un año de duración (3600 * 24 * 365 = 31536000) haríamos:
db.posts.createIndex( { date: 1 }, { expireAfterSeconds: 31536000 } )
Manejando índices¶
En versiones previas a la 4.4, los índices se podían crear en foreground, de manera que al crear un índice se bloqueaban a todos los writers o en modo background que no penalizaba las escrituras, pero tardaba más.
Actualmente, se utiliza un mecanismo optimizado el cual es el método por defecto y ya no se indica si se hacen en foreground o background.
Si al crear un índice, le queremos indicar un nombre, lo podemos hacer pasándole un segundo parámetro:
db.grades.createIndex( { student_id: 1 }, { name: "student_idx" } )
64
Una colección puede tener hasta 64 índices
Una vez creados, podemos consultar los índices de una determinada colección mediante el método getIndexes():
db.grades.getIndexes() // muestra los índices de la colección grades
Si vemos que no usamos un índice o que su rendimiento es peor, podemos borrarlo empleando el método dropIndex(atributo):.
db.grades.dropIndex( {"student_id":1} ) // borra el índice indicando la propiedad student_id
db.grades.dropIndex( "student_idx" ) // borra el índice por su nombre
Rendimiento¶
En cuanto al rendimiento, algunos de los operadores que no utilizan los índices eficientemente son los operadores $where, $nin y $exists. Cuando estos operadores se emplean en una consulta hay que tener en mente un posible cuello de botella cuando el tamaño de los datos incremente.
Al explicar los índices ya hemos visto que podemos obtener información sobre la operación realizada mediante el método explain().
El atributo indexOnly nos dice si toda la información que queremos recuperar se encuentra en el índice. Este atributo va a depender de los campos que quiera que me devuelva la consulta, si son un subconjunto del índice utilizado.
Como los índices consumen espacio en disco y memoria, es importante vigilar y planificar su uso, para no sobrepasar las prestaciones de nuestro sistema, de manera que sólo utilicemos índices cuando tengamos consultas que se repiten en el tiempo y que empiezan a ser lentas.
Vigilar la RAM
Los índices deben caber en memoria.
Para averiguar el tamaño de los índices (en bytes):
db.grades.stats() // obtiene estadísticas de la colección
db.grades.totalIndexSize() // obtiene el tamaño de los índices
No obstante, si los índices están en disco, pese a ser algorítmicamente mejores que no tener, al ser más grandes que la RAM disponible, no se obtienen beneficios por la penalización de la paginación.
Mucho cuidado con los índices multiclave porque crecen fácilmente, y si el documento tiene que moverse a disco, el cambio supone tener que cambiar todos los puntos de índice del array. Aunque sea más responsabilidad de un administrador de bases de datos (DBA), los desarrolladores debemos saber si el índice va a caber en memoria. Si no van a caber es mejor no usarlos.
Autoevaluación
Hemos actualizado un documento con una clave llamada etiquetas que provoca que el documento tenga que moverse a disco. Supongamos que el documento contiene 10.000 etiquetas en él y que el array de etiquetas está indexado con un índice multiclave.
¿Cuántos elementos tienen que actualizarse en el índice para acomodar el movimiento? 1
Forzando índices¶
Si en algún momento queremos forzar el uso de un determinado índice al realizar una consulta, necesitaremos usar el método hint({campo:1}
Si queremos que se utilice el índice asociado a la propiedad twitter:
db.iabd.find({nombre:"Aitor Medrano", twitter:"aitormedrano"}).hint({twitter:1})
Si por algún motivo no queremos usar índices y forzar un escaneo de toda la colección, le pasaremos el operador $natural al método hint().
db.iabd.find({nombre:"Aitor Medrano", twitter:"aitormedrano"}).hint({$natural:1})
Si usamos un hint sobre un índice sparse y no hay documentos a devolver con dicho índice porque todos sus campos son nulos, la consulta no devolverá nada, aunque haya documentos que sin dicho índice si cumplen los criterios.
Un caso particular que conviene destacar es cuando utilizamos los los operadores $gt, $lt, $ne …, los cuales provocan un uso ineficiente de los índices, al tener que recorrer toda la colección de índices. Si hacemos una consulta sobre varios atributos y en uno de ellos usamos $gt, $lt o similar, es mejor hacer un hint sobre el resto de atributos que sí tienen una selección directa.
Por ejemplo, supongamos que en la colección de zips quieséramos obtener las poblaciones del estado de Alabama (AL) que tienen una población comprendida entre 10000 y 50000:
db.zips.find({ "pop":{$gt:10000, $lte:50000}, "state":"AL" })
Para esta consulta, suponiendo que tenemos un índice tanto en pop como en state, sería conveniente hacer el hint sobre el state:
db.zips.find({ "pop":{$gt:10000, $lte:50000}, "state":"AL" }).hint({"state":1})
Colecciones limitadas¶
Una colección limitada (capped collection) es una colección de tamaño fijo (por cantidad de documentos o tamaño de la colección), donde se garantiza el orden natural de los datos, es decir, el orden en que se insertaron.
Una vez se llena la colección, se eliminan los datos más antiguos, y los datos más recientes se añaden al final, de manera similar a un buffer circular, asegurando que el orden natural de la colección sigue el que se insertaron los registros.
Este tipo de colecciones se utilizan para logs y auto-guardado de información, ya que su rendimiento es muy alto para inserciones, permitiendo obtener datos similares a "logs de la última hora". Otro uso es para el cacheo de pequeñas cantidades de datos, ya que los datos más recientes normalmente son los más relevantes.
Se crean de manera explícita mediante el método createCollection, pasándole el tamaño en bytes de la colección y valor capped a true. Por ejemplo, si queremos crear una colección para auditar datos de 20 KB haríamos:
db.createCollection("auditoria", {capped:true, size:20480})
Los documentos que se añaden a una colección limitada se pueden modifican, pero no pueden crecer en tamaño. Si sucede, la modificación fallará. Además, tampoco se pueden eliminar documentos de la colección. Para ello, hay que borrar toda la colección (drop) y volver a crearla.
También podemos limitar el número de elementos que se pueden añadir a la colección mediante el parámetro max en la creación de la colección. Sin embargo, hay que asegurarse de disponer de suficiente espacio en la colección para los elementos que queremos añadir. Si la colección se llena antes de que el número de elementos se alcance, se eliminará el elemento más antiguo de la colección.
Si retomamos el ejemplo anterior, pero fijamos su máximo a 100 elementos, crearíamos la colección del siguiente modo:
db.createCollection("auditoria", {capped:true, size:20480, max:100})
El shell de MongoDB ofrece la utilidad validate() para comprobar la consistencia de la colección, ya sea limitada o no. Para comprobar el estado de la colección anterior haríamos:
> db.auditoria.validate()
< {
ns: 'iabd.auditoria',
nInvalidDocuments: 0,
nNonCompliantDocuments: 0,
nrecords: 10,
nIndexes: 1,
keysPerIndex: { _id_: 10 },
indexDetails: { _id_: { valid: true } },
valid: true,
repaired: false,
warnings: [],
errors: [],
extraIndexEntries: [],
missingIndexEntries: [],
corruptRecords: [],
ok: 1
}
Si queremos consultar los datos de una colección limitada, por su idiosincrasia, los resultados aparecerán en el orden de inserción. Si queremos obtenerlos en orden inverso, le tenemos que pasar el operador $natural al método sort():
db.auditoria.find() // orden natural
db.auditoria.find().sort({ $natural:-1 }) // orden inverso
Finalmente, si queremos averiguar si una colección es limitada, disponemos del método isCapped():
db.auditoria.isCapped() // true
De forma alternativa, podríamos utilizar un índice TTL dentro de una colección ordinaria (ya que podemos expirar y eliminar datos dependiendo del valor de un campo de tipo fecha), pero perderíamos parte de las prestaciones que ofrecen las colecciones capped.
Vistas¶
Una vista de MongoDB es una estructura sobre la cual podemos realizar consultas (pero no modificar, es decir, es de solo lectura) definida a través de un pipeline de agregación aplicada a otras colecciones o vistas. MongoDB no almacena el contenido de una vista en el disco. En su lugar, el contenido de una vista se genera dinámicamente tras cada consulta.
De forma similar a las vistas de los sistemas gestores relacionales, una vista permite:
- Puede crear entidades consultables que muestren solo campos específicos, ocultando información confidencial a determinados usuarios o aplicaciones. Esto ayuda a reforzar la seguridad al limitar la exposición de datos confidenciales.
- Puede simplificar estructuras de datos complejas presentando solo la información relevante, lo que permite a los usuarios trabajar con una representación más concisa y comprensible de la colección subyacente.
- Puede encapsular consultas complejas de uso frecuente, lo que permite un acceso coherente y simplificado a los datos sin necesidad de que los usuarios escriban la misma lógica de agregación repetidamente.
- Puede combinar información de varias colecciones en un resultado unificado sin fusionar físicamente los datos, lo que permite una fácil integración de datos de diferentes fuentes con fines analíticos.
Para crear una vista, usaremos el método db.createView(nombreVista, nombreColeccion, pipeline). Por ejemplo, la siguiente vista recupera los zips de Alabama:
use sample_training
db.createView(
"zips_al",
"zips",
[
{ $match: { "state": "AL" } }
]
)
Para recuperar los datos de la vista, realizaríamos una consulta sobre la propia vista:
db.zips_al.find()
Un tipo especial de estructura son las vistas materializadas, las cuales almacenan el resultado de una agregación de forma precalculada en disco mediante las etapas $merge o $out.
db.zips.aggregate([
{ $match: { "state": "AL" } },
{ $out: "zips_al_vm" }
]);
Realmente no son vistas como tal, sino una agregación bajo demanda que persiste el resultado en una nueva colección. A nivel de rendimiento, las vistas materializadas bajo demanda ofrecen un rendimiento de lectura mejorado con respecto a las vistas normales, ya que se recuperan del disco en lugar de calcularse durante la consulta, a costa de que no se actualizan automáticamente. Es decir, requieren una actualización manual para reflejar los cambios en los datos subyacentes, ya sea mediante un scheduled trigger en Mongo Atlas o volviendo a ejecutar el pipeline de agregación, de manera que se vuelve a persistir los resultados actualizados en la colección, lo que implica que se actualice con los datos más recientes.
Profiling¶
Trabajando en local
Para poder trabajar el profiling, no podemos hacerlo mediante MongoDB Atlas. Por ello, se recomienda utilizar una instalación en local o mediante un contenedor Docker.
MongoDB incorpora varias herramientas para el control del rendimiento.
Por ejemplo, la colección db.system.profile auditará las consultas ejecutadas. Podemos indicar el nivel de las consultas a auditar mediante tres niveles: 0 (ninguna), 1 (consultas lentas), 2 (todas las consultas)
Si queremos que se auditen todas las consultas, lo indicaremos del siguiente modo:
> db.setProfilingLevel(2)
< { was: 0, slowms: 100, sampleRate: 1, ok: 1 }
El método setProfilingLevel() también admite un segundo parámetro para indicar el número mínimo de milisegundos de las consultas para ser auditadas.
Por defecto, MongoDB automáticamente escribe en el log las consultas que tardan más de 100ms.
Si queremos indicar estas propiedades al arrancar el demonio, le pasaremos los parámetros --profile y/o --slowms:
mongod --profile=1 --slowms=15
Si en algún momento queremos consultar el estado del profiling podemos utilizar db.getProfilingStatus().
> db.getProfilingStatus()
< { was: 2, slowms: 100, sampleRate: 1, ok: 1 }
Sobre los datos auditados, podemos hacer find sobre db.system.profile y filtrar por los campos mostrados:
db.system.profile.find({ millis : { $gt : 1000 } }).sort({ts : -1})
db.system.profile.find().limit(10).sort( { ts : -1 } ).pretty()
Dentro de estas consultas algunos campos significativos son:
op: tipo de operación, ya seacommand,query,insert, …millis: tiempo empleado en la operaciónts: timestamp de la operación
Podéis consultar todos los campos disponibles en http://docs.mongodb.org/manual/reference/database-profiler/
Otras herramientas para controlar el rendimiento que se ejecutan en un terminal, son:
-
mongotop→ similar a la herramientatopde UNIX, muestra el tiempo empleado por MongoDB en las diferentes colecciones, indicando tanto el tiempo empleado en lectura como en escrituras. Para ello, si queremos se ejecute cada tres segundos, en un terminal:mongotop 3 ns total read write 2023-10-11T18:45:17Z admin.atlascli 0ms 0ms 0ms admin.system.version 0ms 0ms 0ms config.collections 0ms 0ms 0ms config.system.sessions 0ms 0ms 0ms config.transactions 0ms 0ms 0ms iabd.auditoria 0ms 0ms 0ms iabd.contacto 0ms 0ms 0ms iabd.restaurants 0ms 0ms 0ms iabd.system.profile 0ms 0ms 0ms iabd.usuario 0ms 0ms 0ms -
mongostat→ muestra el número de operaciones por cada tipo que se realizan por segundo a nivel de servidor, lo que nos da una instantánea de los que está haciendo el servidor.mongostat 5 insert query update delete getmore command dirty used flushes vsize res qrw arw net_in net_out conn time *0 *0 *0 *0 0 0|0 0.0% 7.6% 0 2.75G 399M 0|0 0|0 111b 59.8k 21 Oct 11 18:46:20.551 *0 1 *0 *0 0 2|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 329b 64.3k 21 Oct 11 18:46:25.550 *0 *0 *0 *0 0 1|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 259b 60.1k 21 Oct 11 18:46:30.550 *0 *0 *0 *0 0 2|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 289b 61.9k 21 Oct 11 18:46:35.540 *0 *0 *0 *0 0 3|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 353b 60.3k 21 Oct 11 18:46:40.547 *0 *0 *0 *0 0 2|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 246b 60.2k 21 Oct 11 18:46:45.547 *0 *0 *0 *0 0 1|0 0.1% 7.6% 0 2.75G 399M 0|0 0|0 112b 59.9k 21 Oct 11 18:46:50.545
Referencias¶
- Curso M201: MongoDB Performance de MongoDB University
- Libro MongoDB: The Definitive Guide, 3rd Edition de Shannon Bradshaw, Eoin Brazil y Kristina Chodorow.
- Libro Mastering MongoDB 6.x - Third Edition de Alex Giamas.
Actividades¶
-
(RABDA.4 / CEBDA.4a, CEBDA.4b / 2p) Para la siguiente actividad, se recomienda trabajar con una instalación de MongoDB en local, ya sea mediante Docker o una instalación propia.
Tenemos los datos de 1.000.000 de restaurantes con una estructura similar al siguiente documento:
{ _id: ObjectId("65291f2d09ae7e23eba2b3df"), name: 'Perry Street Brasserie', cuisine: 'French', stars: 0.3, address: { street: '959 Iveno Square', city: 'Fokemlid', state: 'AL', zipcode: '18882' } }Nos han dicho que les interesa optimizar las siguientes consultas, en las cuales no utilizan el framework de agregación:
- Obtener la cantidad de restaurantes de un determinado tipo de cocina para un estado determinado que tenga una calificación superior a 3 estrellas.
- Obtener los datos de los restaurantes de un determinado tipo de cocina para un estado determinado que tenga una calificación comprendida entre dos valores y ordenar dichos datos por la ciudad.
- Obtener los datos de los restaurantes de una determinada ciudad que sea de un tipo de cocina, ordenados por la cantidad de estrellas.
Así pues, se pide adjuntar los comandos empleados y capturas de pantalla para:
- Carga los datos almacenados en
restaurants.zipen la coleccióniabd.restaurants. - Habilita la auditoria de MongoDB para registrar las consultas que tardan más de 90ms.
- Ejecuta
mongotop 3para comprobar el rendimiento de la coleccióniabd.restaurants - Comprueba el rendimiento mediante el plan de ejecución de las diferentes consultas.
- Comprueba qué consulta es la que más tarda utilizando
db.system.profile. - Crea los índices necesarios para optimizar las consultas y justifica la elección del tipo de índices y sus campos.
- Comprueba que se utilizan los índices mediante los planes de ejecución y compara el rendimiento actual respecto al previo al crear los índices.
Actividades de ampliación (opcional):
-
(RABDA.4 / CEBDA.4b / 1p) Supongamos que tenemos un índice similar al siguiente:
{ "nombre": 1, "dir.provincia": -1, "dir.ciudad": -1, "cp": 1 }Identifica los prefijos que se utilizarán (si lo hacen) para las siguientes consultas y justifica el motivo, tanto al filtrar como al ordenar los resultados:
db.alumnado.find( { "nombre": { $gt: "P" } } ).sort( { "dir.ciudad": -1 } )db.alumnado.find( { "nombre": "Marina" } ).sort({ "dir.provincia": 1, "dir.ciudad": 1 } )db.alumnado.find( { "nombre": "Marina", "dir.provincia": { $lt: "S"} } ).sort( { "dir.provincia": 1 } )db.alumnado.find( { "dir.ciudad": "Elche" } ).sort( { "dir.ciudad": -1 } )db.alumnado.find( { "dir.provincia": "Alicante", "nombre": "Marina" } ).sort( { "dir.ciudad": -1 } )
-
(RABDA.4 / CEBDA.4b / 1p) Realiza las siguientes acciones anotando el comando necesario:
- Crea una colección llamada
nombres. - Añade 5 documentos con tu nombre con diferentes combinaciones de mayúsculas y minúsculas, pero ninguno que esté todo en minúsculas.
- Crea una consulta que busque tu nombre en minúsculas.
- Crea un índice con el locale en español sobre el nombre.
- Repite la consulta del punto 3 y comprueba cómo devuelve todos los documentos existentes.
- Crea una colección llamada
-
(RABDA.4 / CEBDA.4b / 1p) Investiga para qué sirven los índices ocultos en MongoDB, indicando al menos dos casos de uso donde tiene sentido su utilización.
-
10.000, es decir, todos los valores existentes en el índice multiclave. ↩