Glue
AWS Glue es la herramienta ETL serverless completamente administrada que ofrece Amazon Web Services, con la cual podemos crear soluciones basadas en código tanto para la ingesta como para la transformación de los datos.
AWS Glue incluye un amplio conjunto de conectores tanto para los servicios AWS (RDS, S3, Redshift, etc...) como para servicios de terceros (MongoDB, MongoDB Atlas, conectores JDBC, etc...)
Cuando el esquema de los datos es desconocido, AWS Glue permite inferirlo. Para ello, hemos de construir un rastreador (crawler) para descubrir su estructura.
Con esa información, Glue crea un catálogo que contiene metadatos sobre las diferentes fuentes de datos (compatible con el Hive Catalog). AWS Glue es similar a Amazon Athena en que los datos permanecen en la fuente de datos.
Finalmente, Glue simplifica la orquestación de las ETL, permitiendo ejecutar miles de jobs en workflows y desarrollar y administrar los jobs de forma visual.
Componentes¶
AWS Glue tiene varios componentes que podrían haberse dividido en varios servicios independientes, pero suelen trabajar todos juntos, por lo que AWS los ha agrupado en la familia AWS Glue.
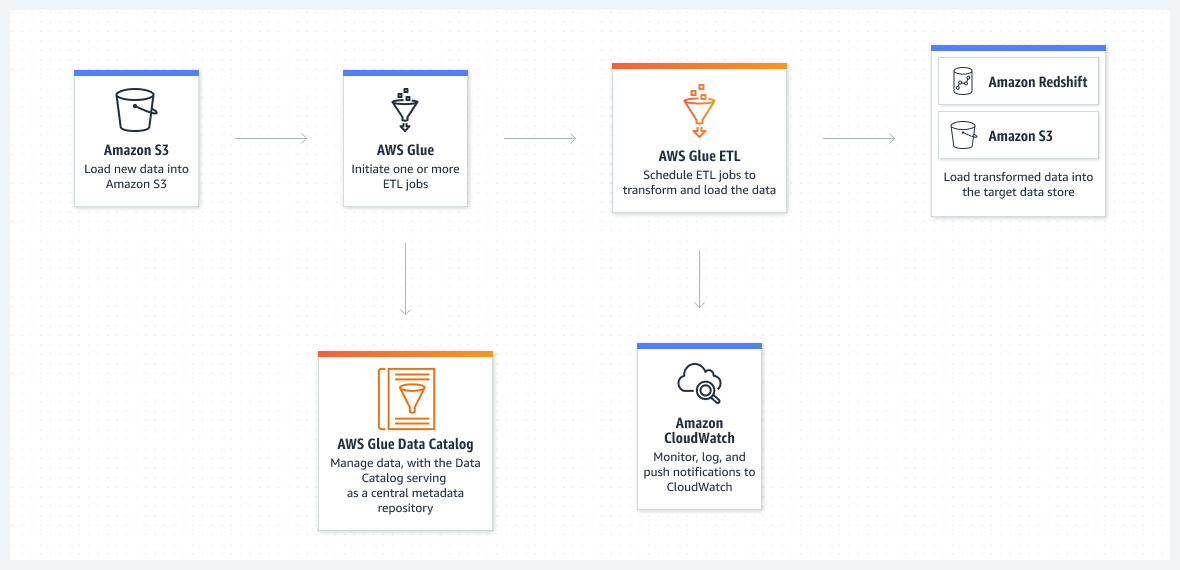
A continuación, vamos a examinar los componentes principales de Glue relacionados con el procesamiento de datos.
Glue ETL jobs¶
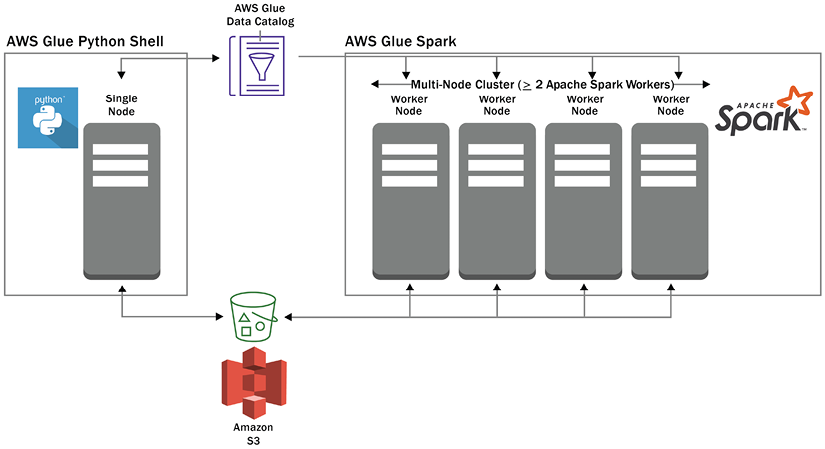
Glue permite trabajar con diferentes motores de integración mediante Python, Spark y Ray para el procesamiento de datos almacenados en diferentes fuentes como S3 o RDS y registrados en el AWS Glue Data Catalog.
Las diferentes tareas ETL se facturan por DPUs (Data Processing Units) utilizadas y la cantidad de tiempo empleado en la ejecución (de forma similar a AWS Lambda). Aproximadamente, y dependiendo de la tecnología, cada DPU cuesta 0,44$ por hora. Más información en la página oficial de precios de AWS Glue.
La siguiente imagen muestra una posible configuración de DPUs, con dos de los motores Glue (un único nodo Python mediante shell a la izquierda, y un cluster de nodos Spark a la derecha):
Alternativas
Existen múltiples herramientas equivalentes a Glue ETL Jobs en otros proveedores cloud y en el ecosistema open source.
En Azure, el servicio equivalente es Azure Data Factory, que ofrece un enfoque más visual y low-code para la creación de pipelines, con más de 90 conectores nativos y soporte para entornos híbridos (on-premise y cloud).
En Google Cloud, Cloud Dataflow permite ejecutar pipelines tanto en batch como en streaming basándose en Apache Beam, lo que lo hace especialmente potente para procesamiento en tiempo real frente al enfoque más batch de Glue.
También existen alternativas agnósticas al proveedor cloud, como Databricks (que ofrece un entorno unificado sobre Spark con notebooks colaborativos), Talend (con una versión open source y amplia conectividad) o Matillion (centrado en ELT con soporte para Snowflake, BigQuery y Redshift). La elección suele depender del ecosistema cloud en el que ya se trabaje: Glue destaca por su integración nativa con S3, Redshift, Athena y el resto del ecosistema AWS.
Glue DataBrew¶
AWS Glue DataBrew es un herramienta no code de transformación de datos que nos permite aplicar transformaciones a los datos de forma visual, sin necesidad de escribir o administrar código (serverless).
Incluye más de 250 transformaciones de datos integradas, que se pueden ensamblar fácilmente de forma gráfica para crear una receta de DataBrew, lo que permite aplicar varias transformaciones a un conjunto de datos, como por ejemplo, limpiar y normalizar datos, eliminar o sustituir valores nulos, estandarizar columnas de fecha y hora para que se ajusten a un estándar, crear codificaciones, etc...
DataBrew incluye funcionalidades tanto para la elaboración de perfiles de datos (recopilación de estadísticas sobre las distintas columnas del conjunto de datos) como para la supervisión de la calidad de los datos. También incluye muchos tipos diferentes de transformaciones, como el formateo de datos, la ofuscación de datos personales, la división o unión de columnas, la conversión de zonas horarias, la detección y eliminación de valores atípicos, etc...
Alternativas
Existen multitud de herramientas similares de preparación visual de datos.
En Azure, la funcionalidad equivalente se encuentra en Power Query dentro de Azure Data Factory, que permite definir transformaciones de datos de forma visual y sin código, aunque no es un servicio independiente como DataBrew.
En Google Cloud, Cloud Dataprep (basado en la tecnología de Trifacta) ofrece una interfaz intuitiva para explorar, limpiar y preparar datos, con sugerencias de transformaciones basadas en machine learning e integración directa con BigQuery y Cloud Storage.
Como alternativas agnósticas al cloud, destacan Trifacta (ahora parte de Alteryx) como plataforma independiente de data wrangling, y PowerQuery dentro de Power BI para escenarios de preparación de datos orientados a analítica y reporting. También herramientas como KNIME o Pentaho Data Integration ofrecen capacidades similares de transformación visual, con la ventaja de ser open source.
Los diferentes componentes de DataBrew son:
- Proyecto
- Conjunto de datos (dataset), que se almacenan en S3.
- Receta (receipt), compuestas de uno o varios pasos de transformación. Estas recetas se pueden guardar, publicar, crear versiones, etc... y compartirlas con otros.
- Trabajo (job), el cual se puede orquestar mediante Step Functions.
Los trabajos de DataBrew cuestan 1$ por sesión y luego 0,48$ por hora de nodo empleado.
Glue Data Catalog¶
AWS Glue también incluye un catálogo de datos para almacenar los metadatos que puede utilizarse para proporcionar una vista lógica de los datos almacenados físicamente en la capa de almacenamiento.
Este catálogo es compatible con el metastore Hive, lo que significa que puede utilizarse con cualquier sistema que pueda trabajar con un metastore Hive
Los objetos (como bases de datos y tablas) del catálogo se pueden referenciar directamente desde el código ETL. Además, cada tabla del catálogo contiene metadatos, como los títulos de las columnas y los tipos de datos de cada columna, una referencia a la ubicación en S3 de los datos que componen esa tabla, y detalles sobre el formato del archivo (como CSV).
Dentro del ecosistema de AWS, varios servicios pueden utilizar AWS Glue Data Catalog. Por ejemplo, Amazon Athena lo utiliza para permitir a los usuarios ejecutar consultas SQL directamente en los datos de Amazon S3, y Amazon EMR y el motor ETL de AWS Glue lo utilizan para permitir a los usuarios hacer referencia a objetos del catálogo (como bases de datos y tablas) directamente desde su código ETL.
El primer millón de datos almacenado en el catálogo es gratis, y a partir ahí, se cobra 1$ por cada 100.000 objetos que superen el millón. También se cobra por las solicitudes realizadas, siendo gratis el primer millón de cada mes y luego 1$ más por cada millón más.
Alternativas
En el ámbito de los catálogos de datos, cada proveedor cloud ofrece su propia solución.
En Azure, Microsoft Purview es el servicio de gobernanza de datos que incluye catalogación, clasificación automática de datos sensibles, linaje y cumplimiento normativo, con soporte para entornos híbridos y multicloud, aunque funciona mejor dentro del ecosistema Microsoft.
En Google Cloud, Dataplex proporciona una capa unificada de metadatos sobre data lakes y data warehouses, integrándose directamente con BigQuery y Cloud Storage para políticas de acceso y descubrimiento de datos.
Como alternativa multicloud y open source, Databricks Unity Catalog ofrece un catálogo agnóstico que permite gobernar datos desde múltiples proveedores (AWS S3, Azure Data Lake Storage, etc.) con un enfoque unificado de permisos y linaje. También merece mención Apache Atlas dentro del ecosistema Hadoop como solución open source de gobernanza y catalogación de metadatos, compatible con el Hive Metastore al igual que el catálogo de Glue.
Glue Crawlers¶
Los rastreadores (crawlers) de AWS Glue son procesos que examinan una fuente de datos (como una ruta en un bucket de S3) e infieren automáticamente el esquema y otra información sobre esa fuente, rellenando automáticamente el catálogo de datos con la información relevante.
Por ejemplo, podemos dirigir un rastreador de AWS Glue a la ubicación de S3 donde hemos exportado los datos de la tabla de customers de nuestra base de datos retail_db. Cuando ejecutamos Glue Crawler, se examina una parte de cada uno de los archivos del origen, identifica el tipo de archivo (CSV o Parquet), utiliza un clasificador para inferir el esquema del archivo (encabezados y tipos de columnas) y, a continuación, añade esa información a una base de datos en el Glue Data Catalog.
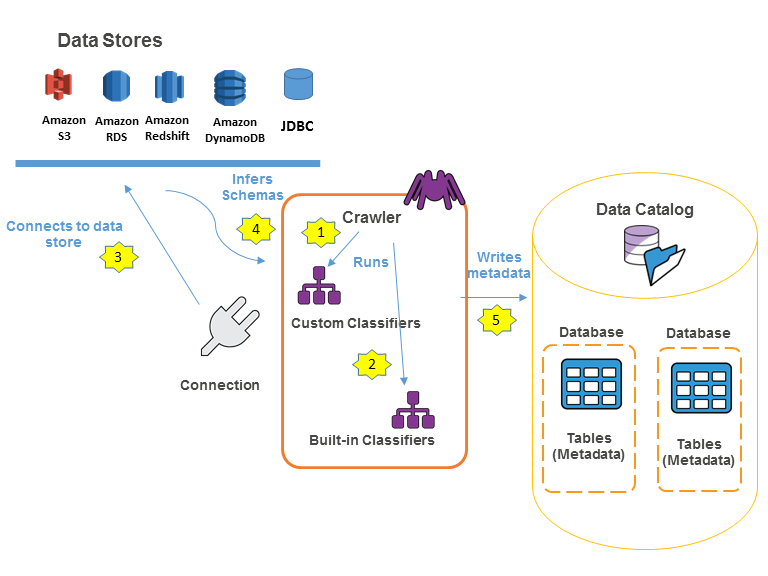
El uso de crawlers es opcional, ya que podemos añadir bases de datos y tablas a Glue Data Catalog utilizando la API de Glue o mediante sentencias SQL en Athena.
Si queremos que el crawler se conecte directamente a otros servicios, haremos uso de conexiones que también almacenaremos en el catálogo de Glue.
Conexiones en AWS Glue¶
Las conexiones (connections) de AWS Glue son objetos del catálogo que almacenan las propiedades necesarias para conectarse a un almacén de datos externo. Se utilizan tanto desde los crawlers (para descubrir esquemas) como desde los jobs ETL (para leer o escribir datos).
AWS Glue soporta varios tipos de conexiones: JDBC (para bases de datos relacionales como MySQL, PostgreSQL, Oracle, SQL Server o MariaDB), Amazon RDS, Amazon Redshift, MongoDB, Kafka y conexiones de red genéricas. En esta sección nos centraremos en las conexiones JDBC a Amazon RDS, ya que es el escenario más habitual en un entorno educativo.
Alternativas
La funcionalidad de descubrimiento automático de esquemas que ofrecen los crawlers de Glue tiene equivalentes parciales en otras plataformas.
En Azure, Microsoft Purview incluye scanners que rastrean fuentes de datos (tanto en Azure como on-premise) para descubrir esquemas, clasificar datos y poblar su catálogo, aunque su enfoque se orienta más hacia la gobernanza que hacia la pura inferencia de esquemas ETL.
En Google Cloud, Dataplex ofrece capacidades de descubrimiento automático de metadatos sobre los datos almacenados en Cloud Storage y BigQuery, aunque no existe un componente tan explícito como el crawler de Glue; adicionalmente, las funciones de catalogación automática están integradas dentro de su servicio Data Catalog.
Como alternativa en el mundo open source, los crawlers se pueden reemplazar creando tablas manualmente en Apache Hive Metastore o utilizando herramientas como el SDK de AWS Glue, scripts de Spark o incluso la API de Athena con sentencias DDL (CREATE EXTERNAL TABLE), lo cual ofrece más control pero requiere mayor esfuerzo manual.
Hola Glue Crawler¶
En los siguientes ejemplos vamos a utilizar los archivos de pdi_sales y pdi_product utilizados a lo largo del curso, y en especial con Pentaho.
Así pues, el primer paso es utilizar un bucket y crear una estructura de carpetas para cada archivo. Realmente cada carpeta debería contener un número indeterminado de archivos con el mismo formato con datos del mismo tipo.
Preparamos los datos¶
En nuestro caso, tenemos el bucket iabd-glue con las carpetas ventas y productos:
s3://iabd-glue/ventas/
s3://iabd-glue/productos/
El siguiente paso es cargar los archivos en las carpetas correspondientes. Por ejemplo, mediante AWS CLI haremos:
aws s3 cp pdi_sales.csv s3://iabd-glue/ventas/
aws s3 cp pdi_product.csv s3://iabd-glue/productos/
Creamos el crawler¶
Una vez cargados los datos en el bucket, vamos a utilizar un crawler para inferir las tablas.
Para ello, tras acceder a AWS Glue, y crearemos un nuevo crawler, al cual hemos llamado crawler-ventas-s3, le indicamos que todavía no tenemos mapeadas tablas en Glue y añadimos un nuevo datasource:
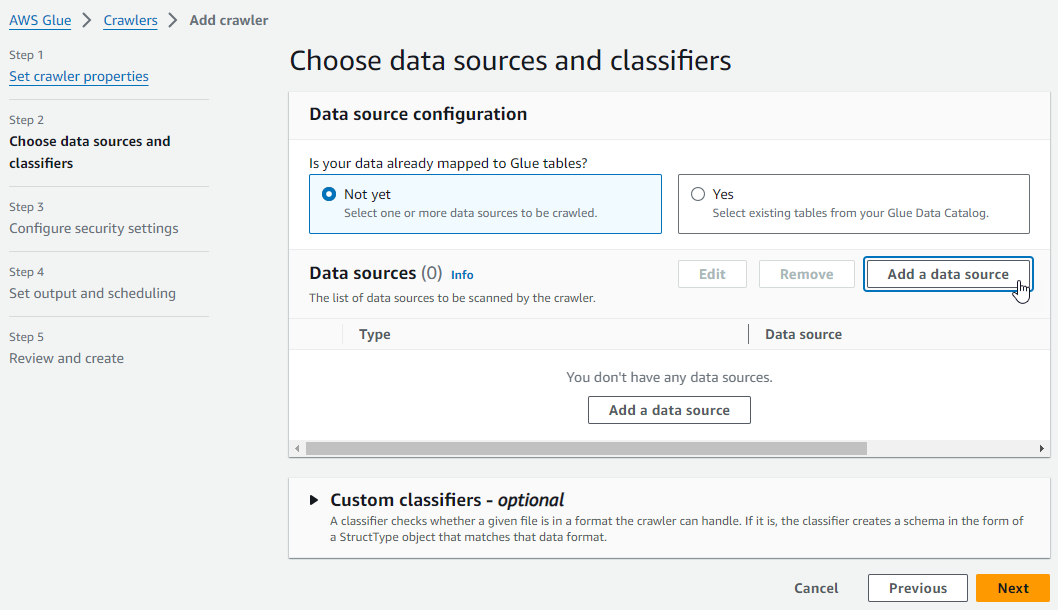
A la hora de crear la fuente de datos, tal y como hemos cargado los datos en S3, seleccionamos como fuente S3 e indicamos la ruta s3://iabd-glue/ventas/:
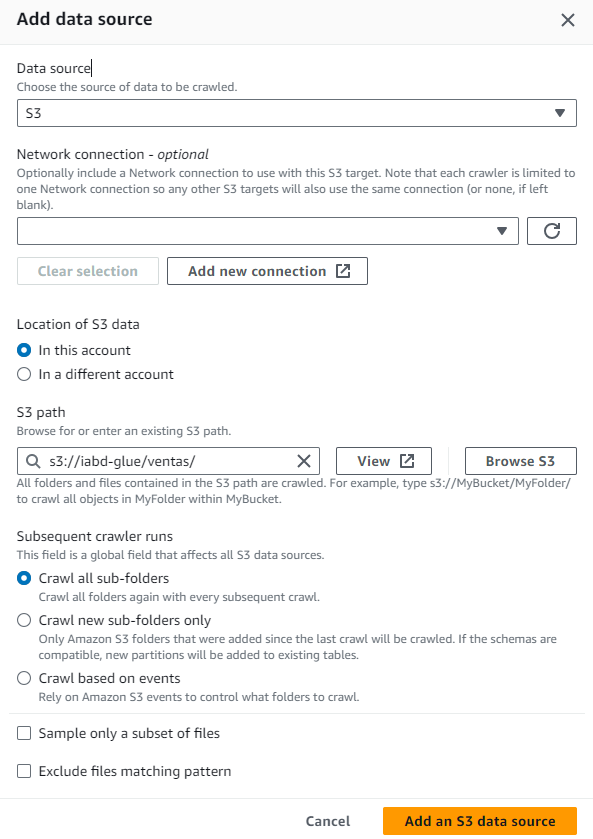
Tras añadirlo y pasar al siguiente paso, seleccionamos el rol LabRole y llegamos al paso 4 de configuración de la salida. En este paso, podemos utilizar una de las bases de datos que tengamos en el catálogo, y si no, crear una. Así pues, vamos a crear la base de datos iabd y posteriomente seleccionamos que ejecute el crawler bajo demanda:
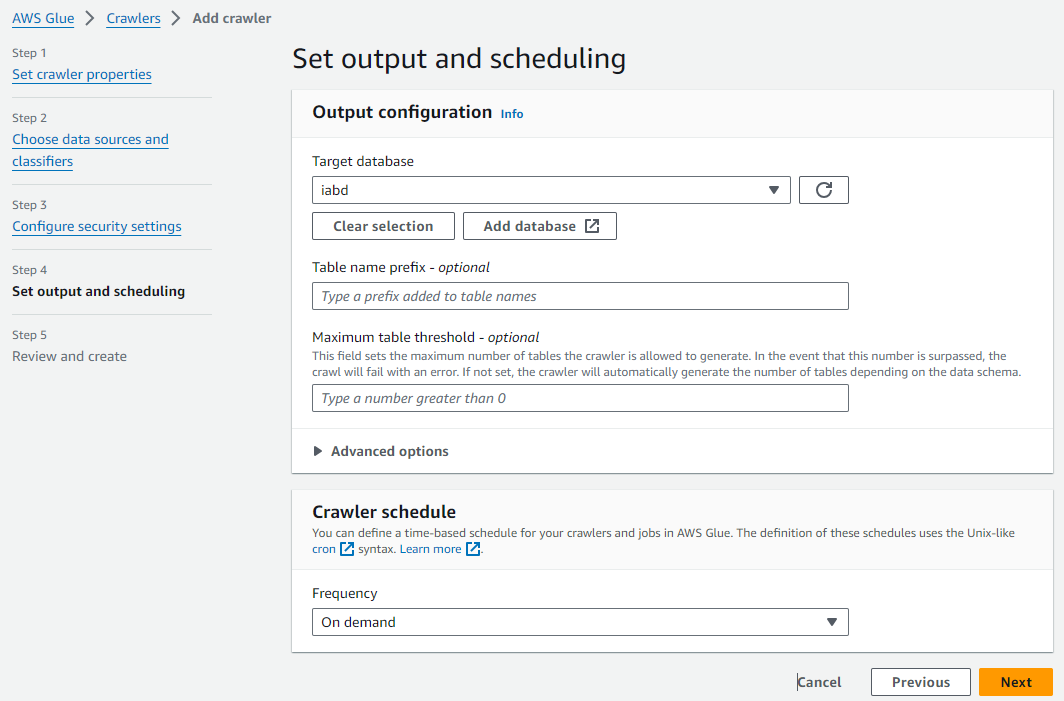
Tras revisar la página de resumen, guardamos el crawler, y estaremos listo para pulsar sobre el botón "Run crawler" y ejecutar el proceso de inferencia de la tabla (el crawler puede tardar algunos minutos).
Comprobamos el resultado¶
Una vez finalizado, si vamos al menú de tablas de Data Catalog, veremos como aparece nuestra tabla:
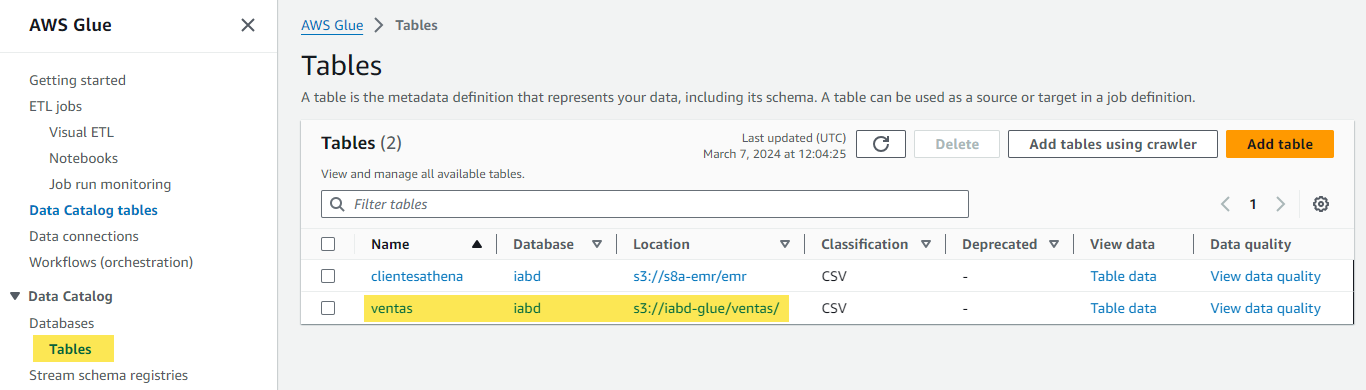
Y si entramos a la tabla, vemos como ha creado las columnas con sus nombres y tipos:
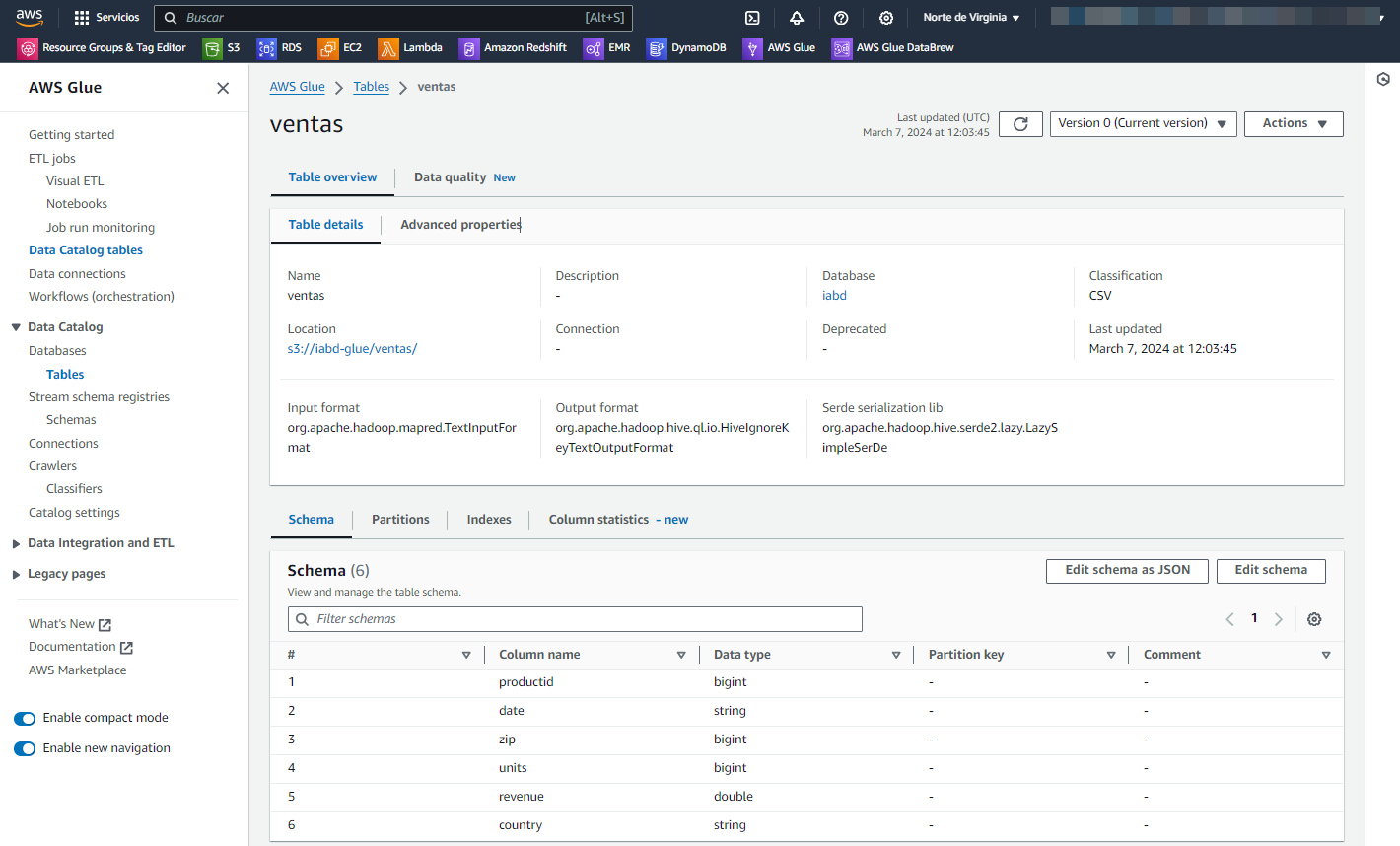
Así pues, ahora repetimos el proceso para crear la tabla productos. Tras crearla, comprobamos su definición:
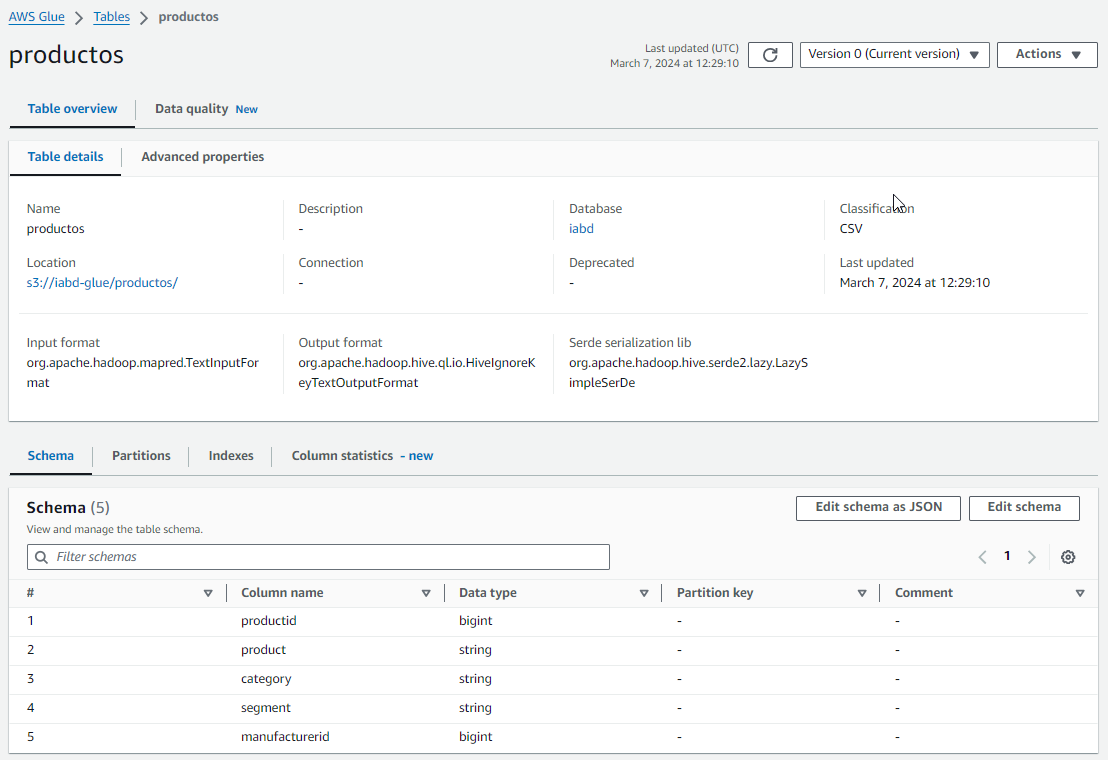
Una vez tenemos ambas tablas creadas, si queremos, podemos comprobar sus datos haciendo uso de AWS Athena.
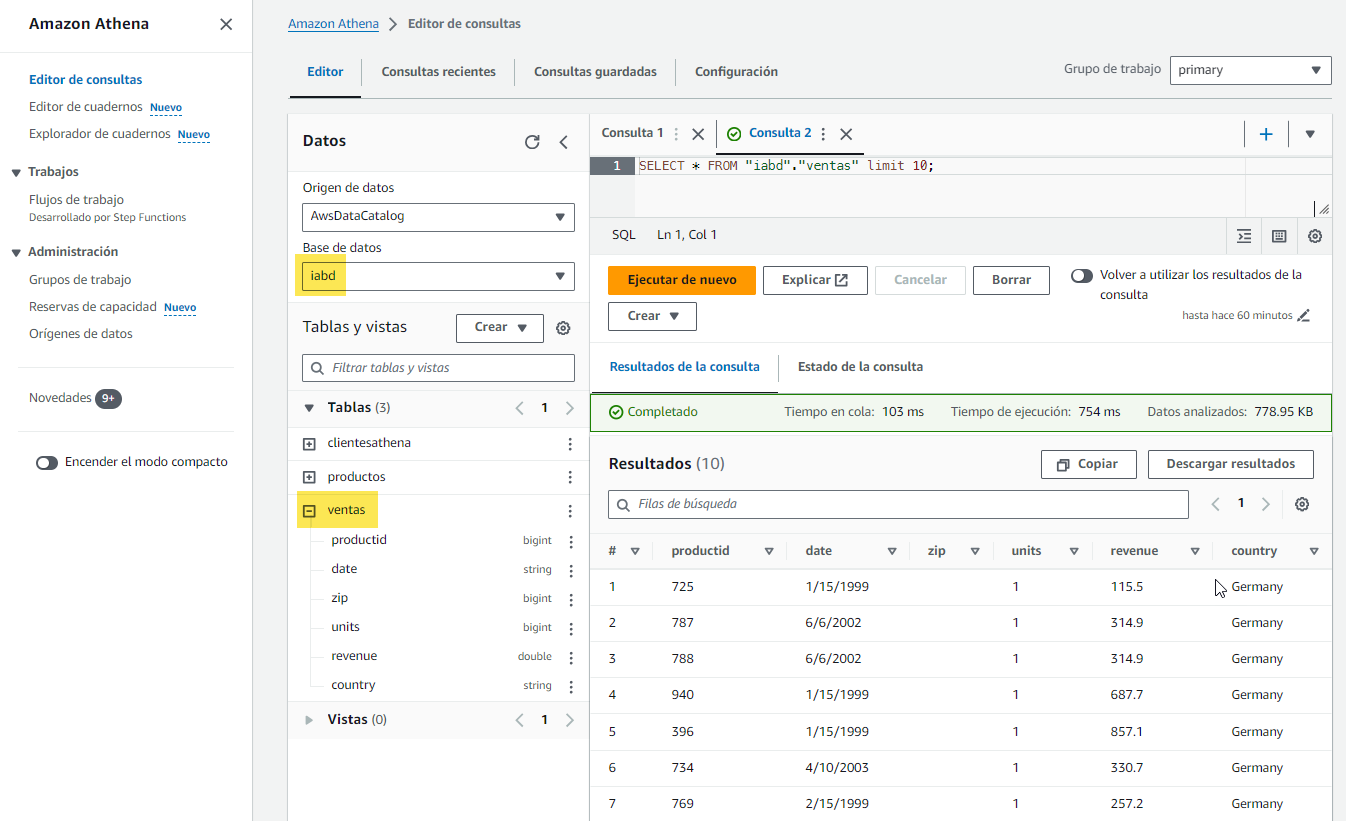
Crear una conexión JDBC¶
A continuación, en vez de utilizar un crawler desde S3, vamos a crear una conexión a una base de datos RDS MySQL para que el crawler pueda conectarse directamente a la base de datos y descubrir las tablas de forma automática.
Para ello, vamos a utilizar la base de datos de retail_db que creamos en la sesión sobre RDS. Para que AWS Glue pueda acceder a una instancia RDS, ambos deben estar dentro de la misma VPC (Virtual Private Cloud). Para ello, hemos de configurar los siguientes elementos de red para que la conexión funcione correctamente:
-
Grupo de seguridad autorreferenciado: El grupo de seguridad asociado a la instancia RDS debe tener una regla de entrada (inbound rule) que permita todo el tráfico TCP desde sí mismo, es decir, configurando el origen con el mismo grupo de seguridad utilizado por RDS. Esto permite que los componentes de Glue se comuniquen entre ellos dentro de la VPC.
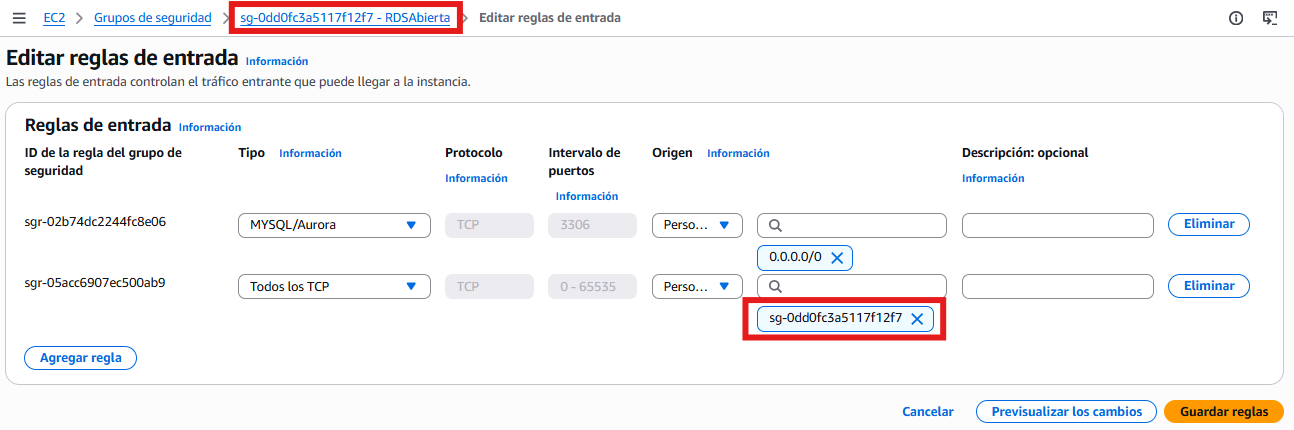
Hola Glue Crawler - Grupo de seguridad autorreferenciado -
Endpoint S3 en la VPC: AWS Glue necesita acceder a S3 para almacenar logs, scripts y datos temporales. Para ello, accederemos al servicio VPC, y crearemos un VPC Endpoint (punto de conexión) de tipo Gateway para el servicio S3, primero seleccionando la opción de Servicios de AWS:
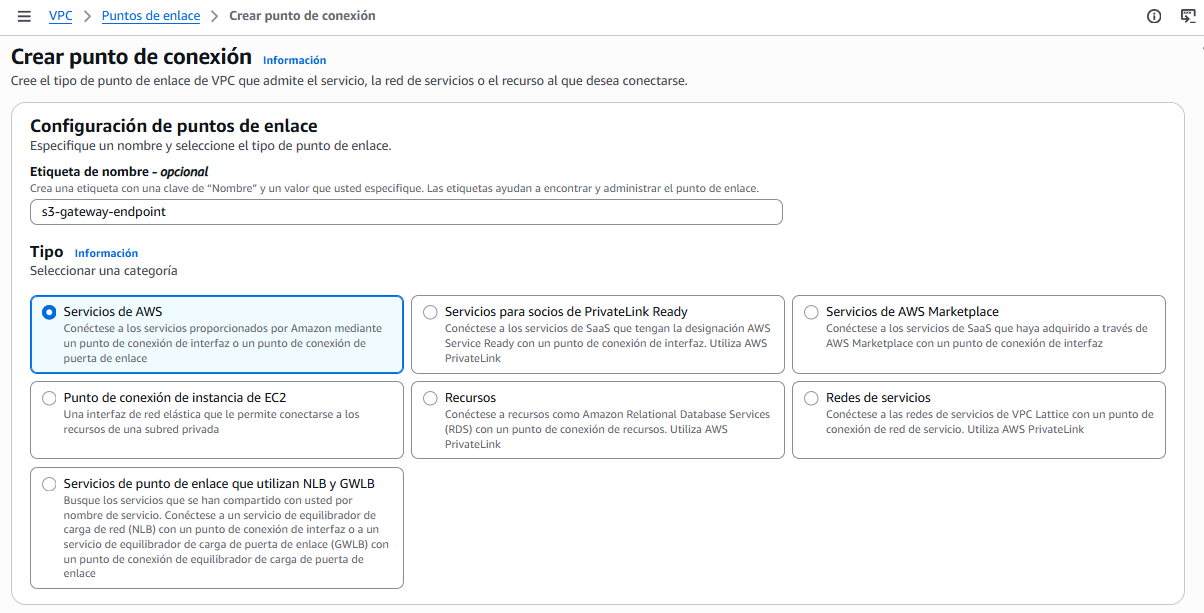
Hola Glue Crawler - Endpoint S3 en la VPC A continuación, tras buscar el servicio S3 de tipo Gateway, lo seleccionamos y lo asociamos a la VPC donde se encuentra la instancia RDS, así como a las subredes y al grupo de seguridad que hemos configurado en el paso anterior:
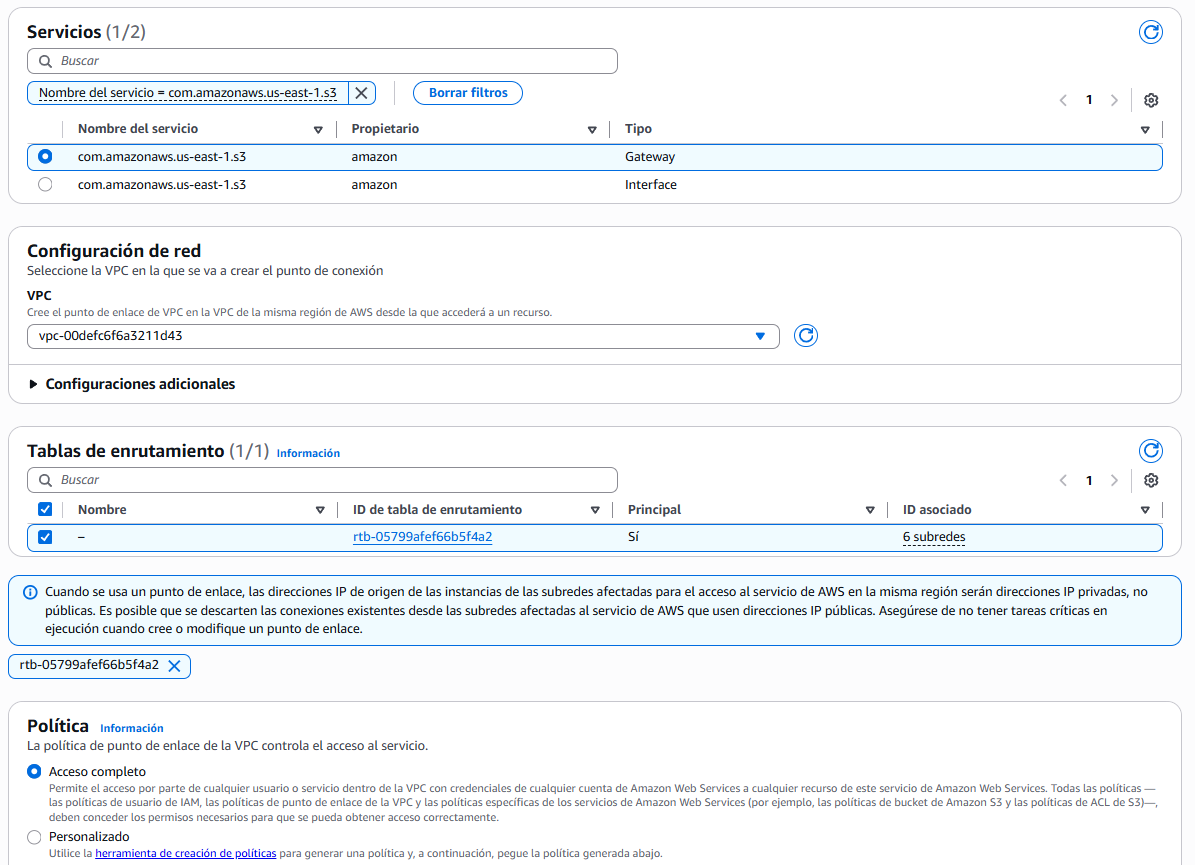
Hola Glue Crawler - Endpoint S3 en la VPC Por último, tras configurarla con una política de acceso completo, creamos la conexión y comprobamos que el estado es Available.
Una vez tenemos la red configurada, podemos crear la conexión JDBC en AWS Glue para que el crawler pueda conectarse a la base de datos RDS y descubrir las tablas automáticamente. Para ello, realizaremos los siguientes pasos:
-
Accedemos a AWS Glue → Data Catalog → Connections y pulsamos Create connection.
-
Tras seleccionar el tipo
MySQL, rellenamos los datos de la conexión: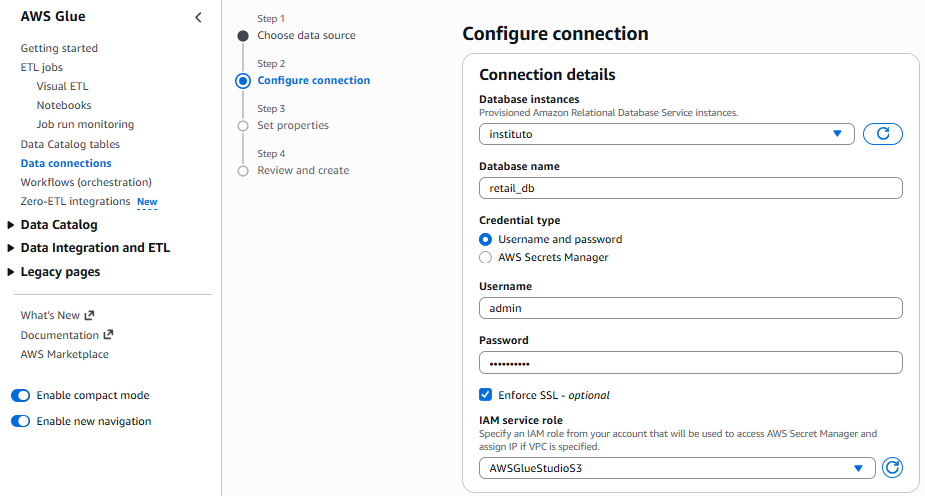
Hola Glue Crawler - Datos de conexión -
En la sección de Network options, seleccionamos:
- La VPC donde se encuentra nuestra instancia RDS.
- La subred (subnet) de la instancia.
- El grupo de seguridad asociado a la instancia RDS (el que tiene la regla autorreferenciada).
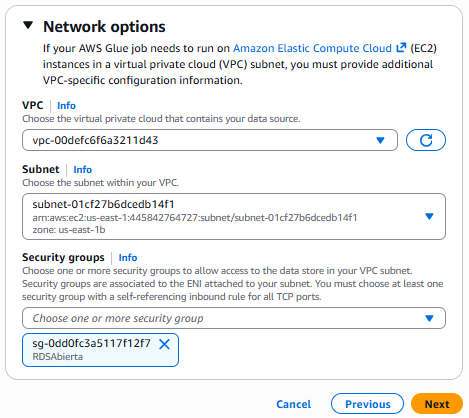
Hola Glue Crawler - Opciones de red
Tras crear la conexión, es recomendable probarla antes de usarla, mediante la opción de Test connection para asegurarnos de que la configuración de red y credenciales es correcta. Si todo está bien configurado (red, credenciales, grupo de seguridad), veremos un mensaje de éxito. En caso contrario, el error más común es un timeout causado por una configuración incorrecta del grupo de seguridad o de los endpoints de la VPC.
Ahora sólo deberíamos seguir los mismos pasos que hemos realizado con el crawler de S3, pero seleccionando esta conexión JDBC para que el crawler se conecte directamente a la base de datos RDS y descubra las tablas de forma automática.
Include path
Cuando seleccionemos qué tablas queremos recuperar, no es necesario seleccionar cada tabla de forma individual, sino que podemos utilizar un include path para indicar qué tablas queremos que el crawler rastree, pudiendo utilizar comodines. Esto es especialmente útil cuando tenemos muchas tablas y queremos evitar seleccionarlas una a una.
Algunos ejemplos serían:
retail_db/%→ todas las tablas de la base de datosretail_dbretail_db/customers→ solo la tablacustomersretail_db/order%→ todas las tablas que empiecen pororder
Si ejecutamos el crawler con esta configuración, se conectará a la base de datos RDS, descubrirá las tablas de la base de datos retail_db y creará las tablas correspondientes en el catálogo de AWS Glue con sus columnas y tipos inferidos correctamente.
Diferencia con los crawlers de S3
A diferencia de los crawlers sobre S3 (que infieren el esquema a partir de los archivos), los crawlers JDBC se conectan directamente al motor de la base de datos y obtienen los metadatos de las tablas del information_schema. Esto significa que la inferencia es exacta, ya que el esquema ya está definido en la propia base de datos.
Hola Glue Studio¶
Mediante Glue Studio vamos a crear una ETL visual de forma similar a como hemos realizado con Pentaho para realizar un join y cargar el resultado en una nueva tabla que almacenaremos en el catálogo.
Realizamos la extracción¶
El primer paso es entrar a Glue Studio desde el menú Visual ETL y crear nuestra ETL arrastrando como fuente un tabla del catálogo:
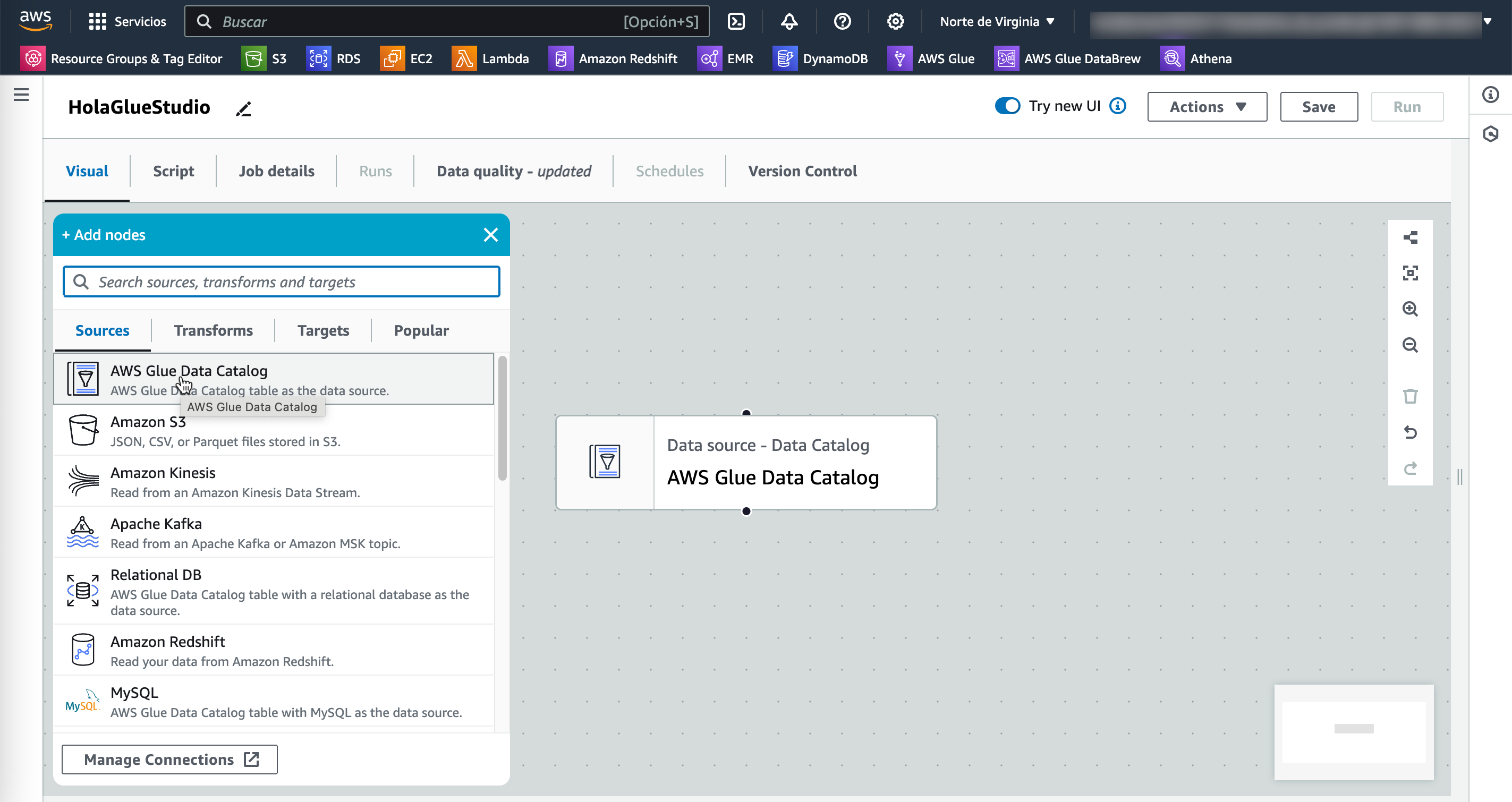
Una vez seleccionado el elemento, seleccionamos la base de datos iabd, la tabla ventas y utilizamos el LabRole que nos ofrece AWS Academy.
Tras seleccionarlo, Glue Studio nos mostrará un preview de los datos:
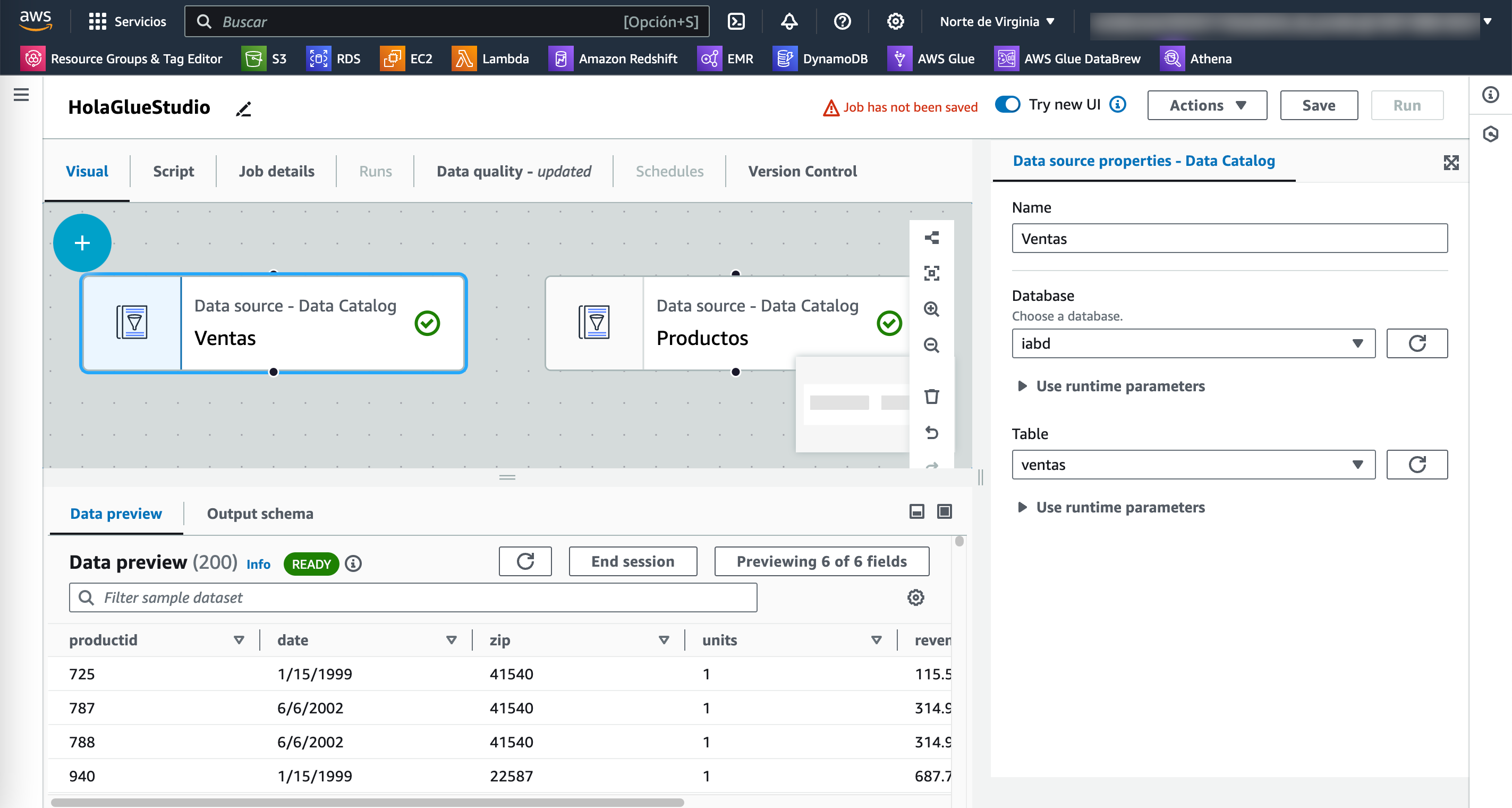
A continuación repetimos el proceso pero ahora con la tabla productos.
Transformamos los datos¶
Una vez cargados los datos, desde la pestaña de Transformaciones, seleccionamos el componente de join:
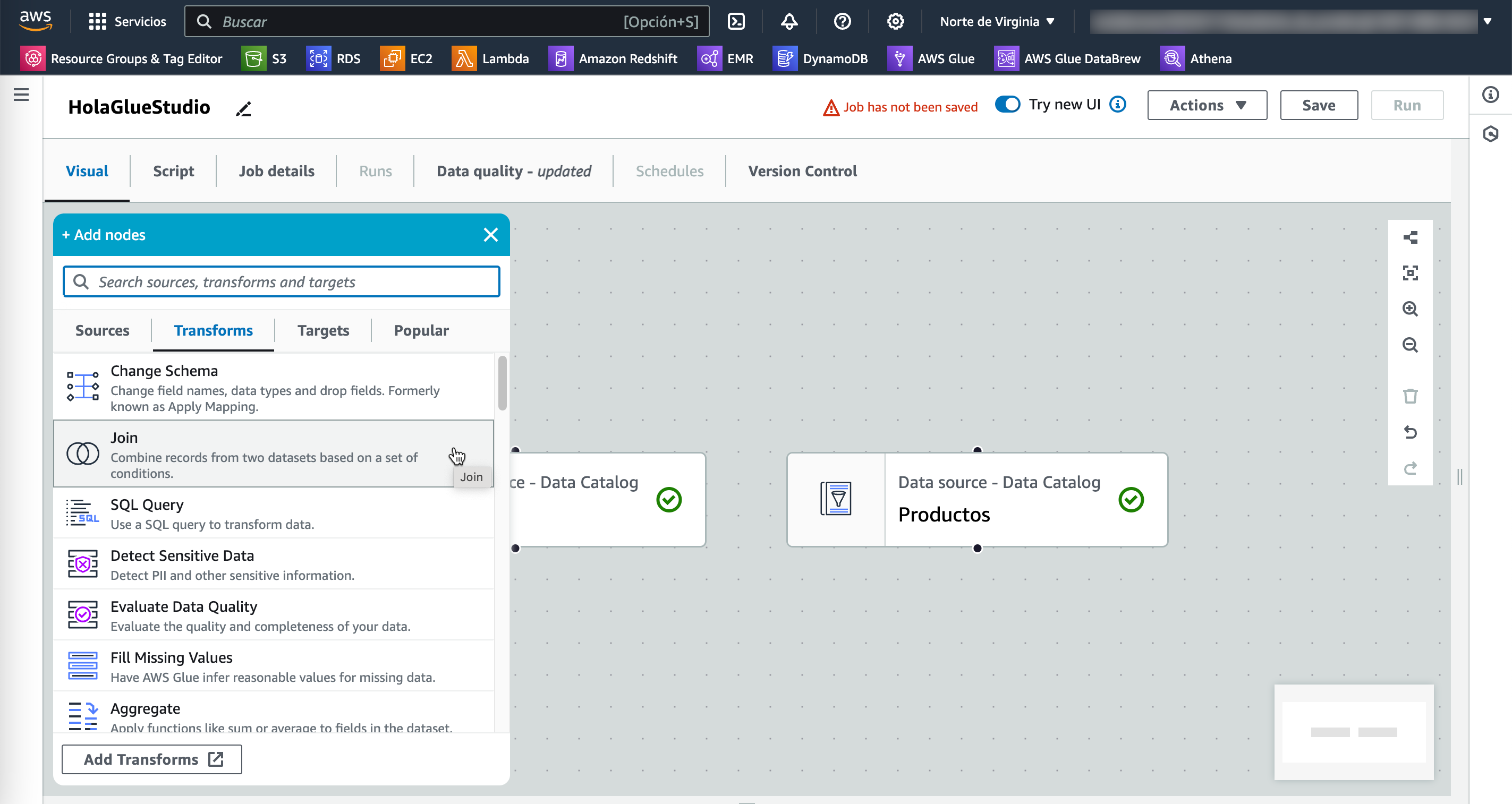
Y configuramos el join seleccionando ambas tablas e indicando la condición de clave ajena con clave primaria:
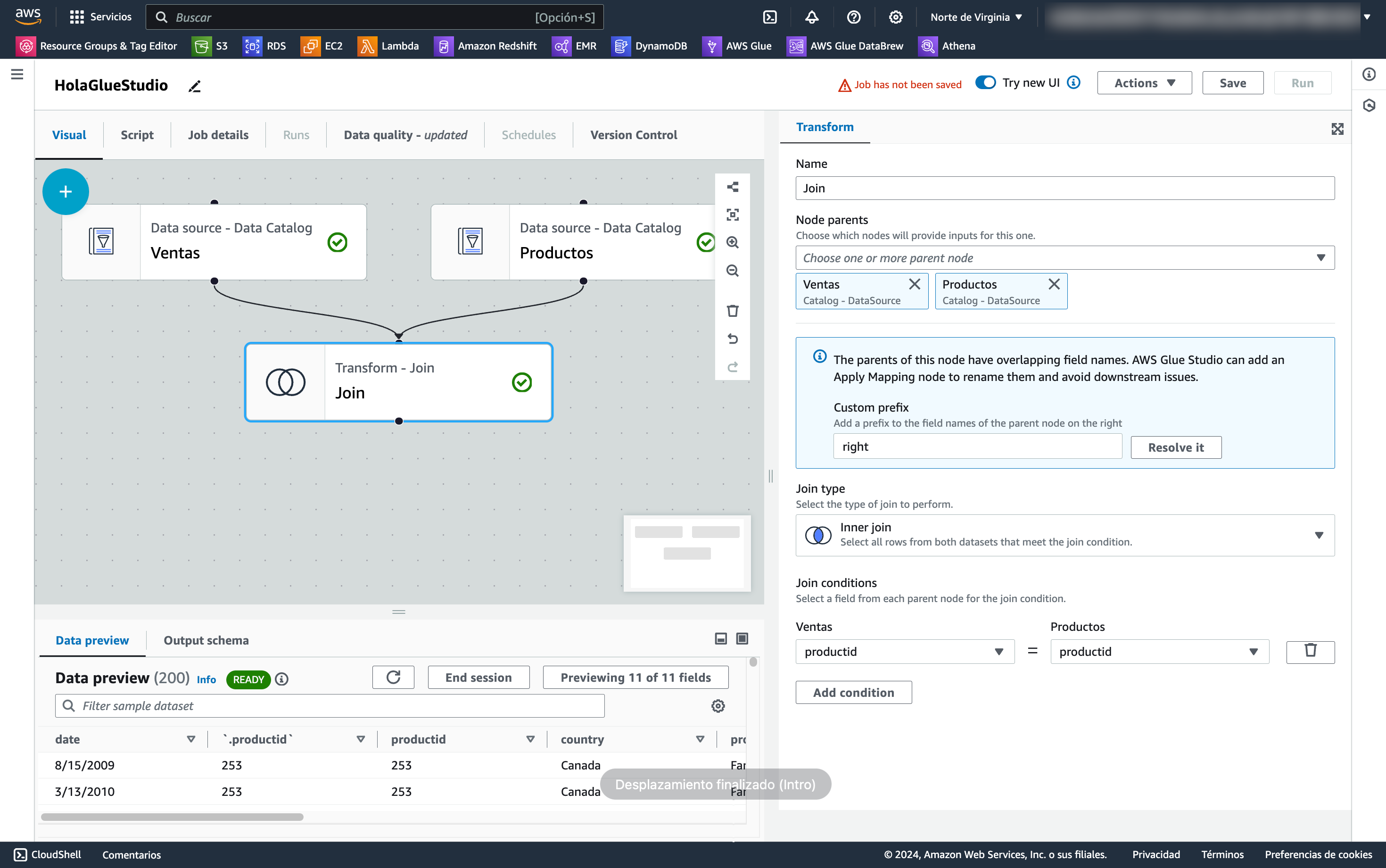
Como ahora tenemos dos campos productid, añadimos una transformación de Drop Fields para eliminar la columna duplicada:
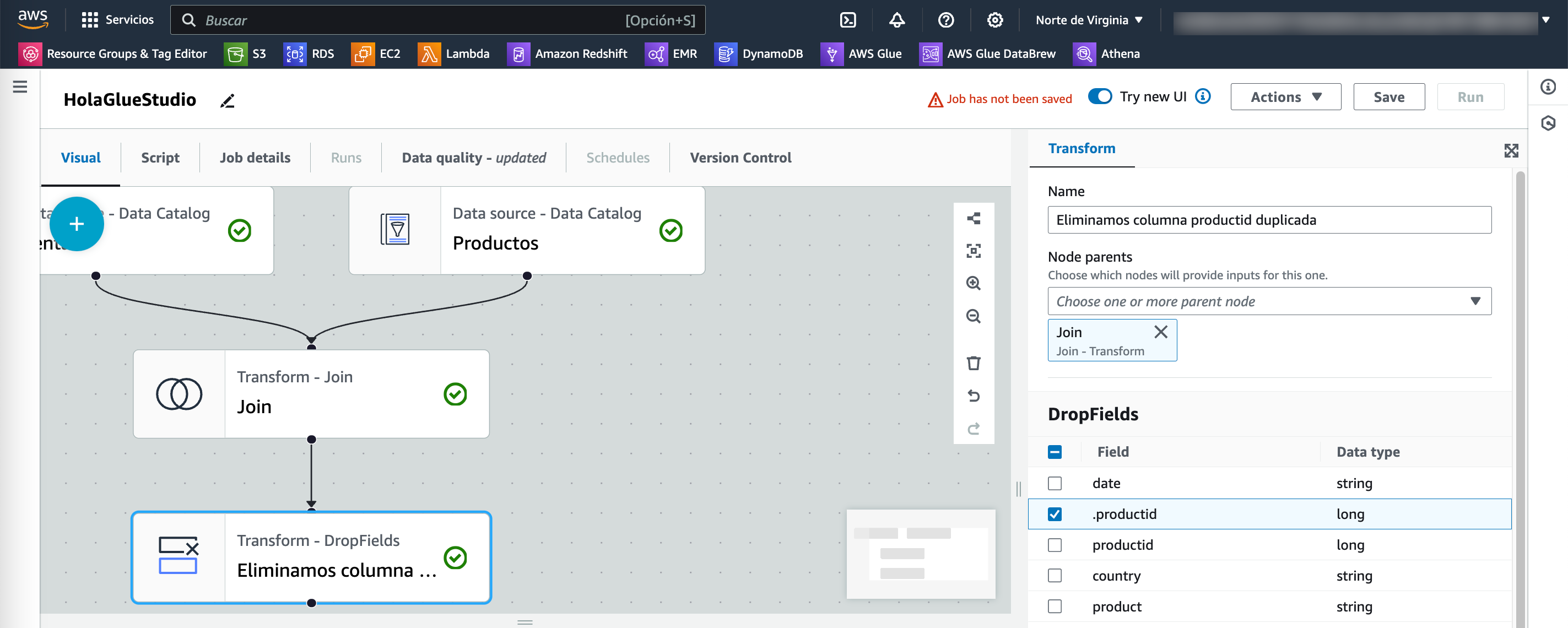
Seleccionamos la carga¶
Y para terminar, vamos a almacenar el resultado en S3 en formato Parquet particionando los datos por país (country) y crear una tabla en el catálogo que apunte a dichos datos.
Para ello, primero elegimos para el destino el servicio S3 y configuramos el nodo padre, el formato Parquet y la ruta de destino (en nuestro caso, le ponemos una nueva carpeta ventas-productos):
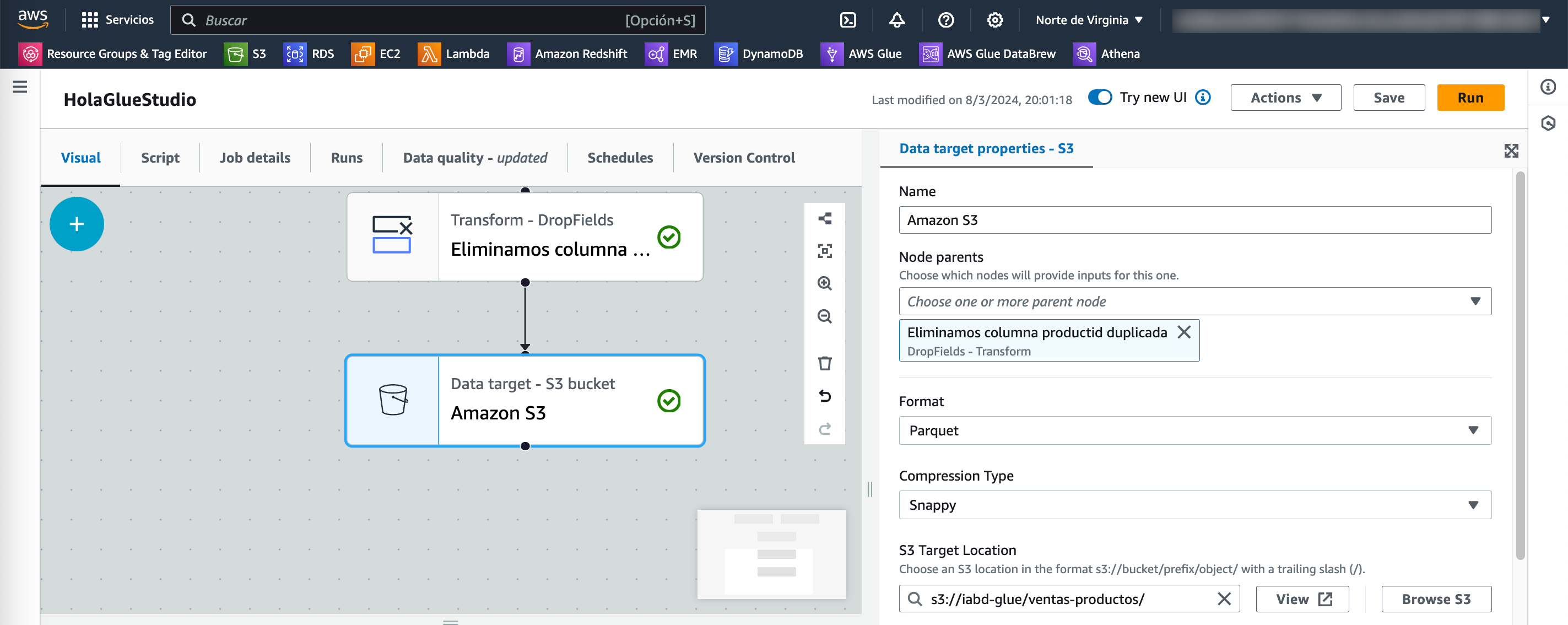
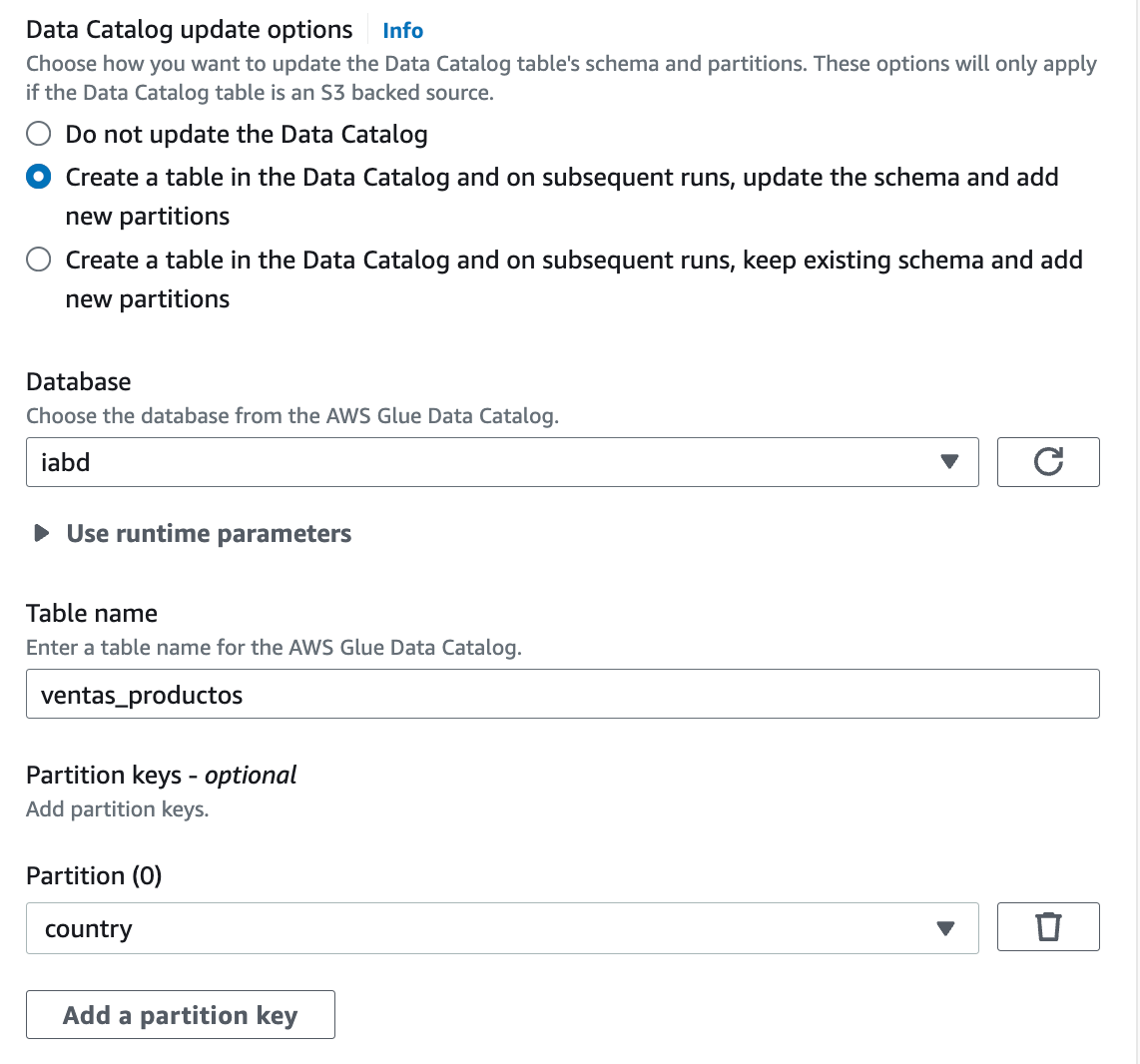
Y a continuación le pedimos que guarde una tabla en el catálogo en la base de datos iabd en una nueva tabla que llamamos ventas_productos:
Probamos la ETL¶
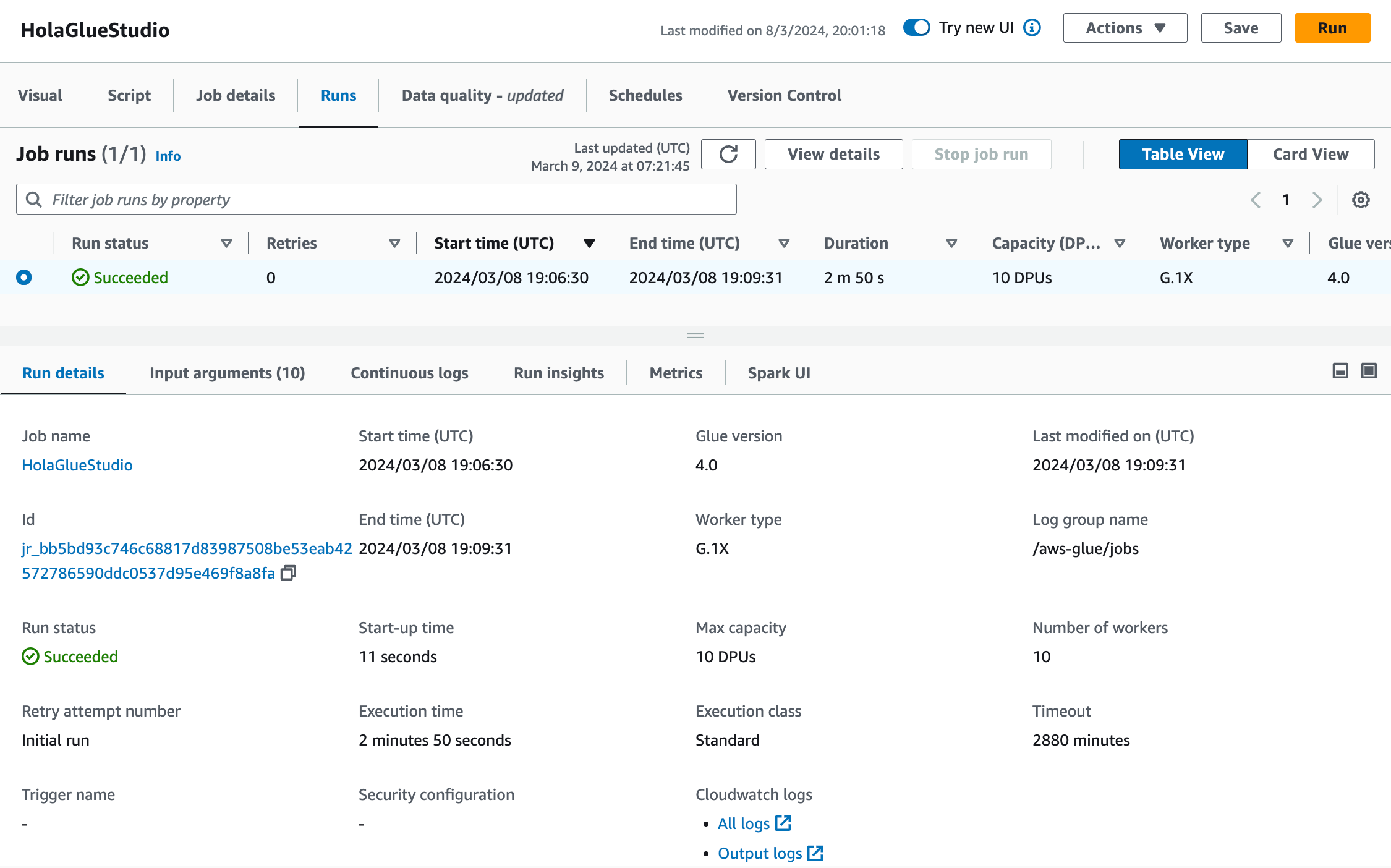
Tras grabar, ya tenemos lista nuestra ETL y la ejecutamos mediante el botón Run naranja situado en la esquina superior derecha.
Si vamos a la pestaña Runs de nuestra ETL, podremos ver el estado y tiempo de ejecución (2m50s lo cual es mucho tiempo para tan poca cantidad de datos, pero ya hemos visto en sesiones previas que el procesamiento distribuido tiene una sobrecarga que, en volúmenes pequeños de datos, penaliza).
Y el último paso es comprobar cómo en S3 se han creado los datos particionados por país:
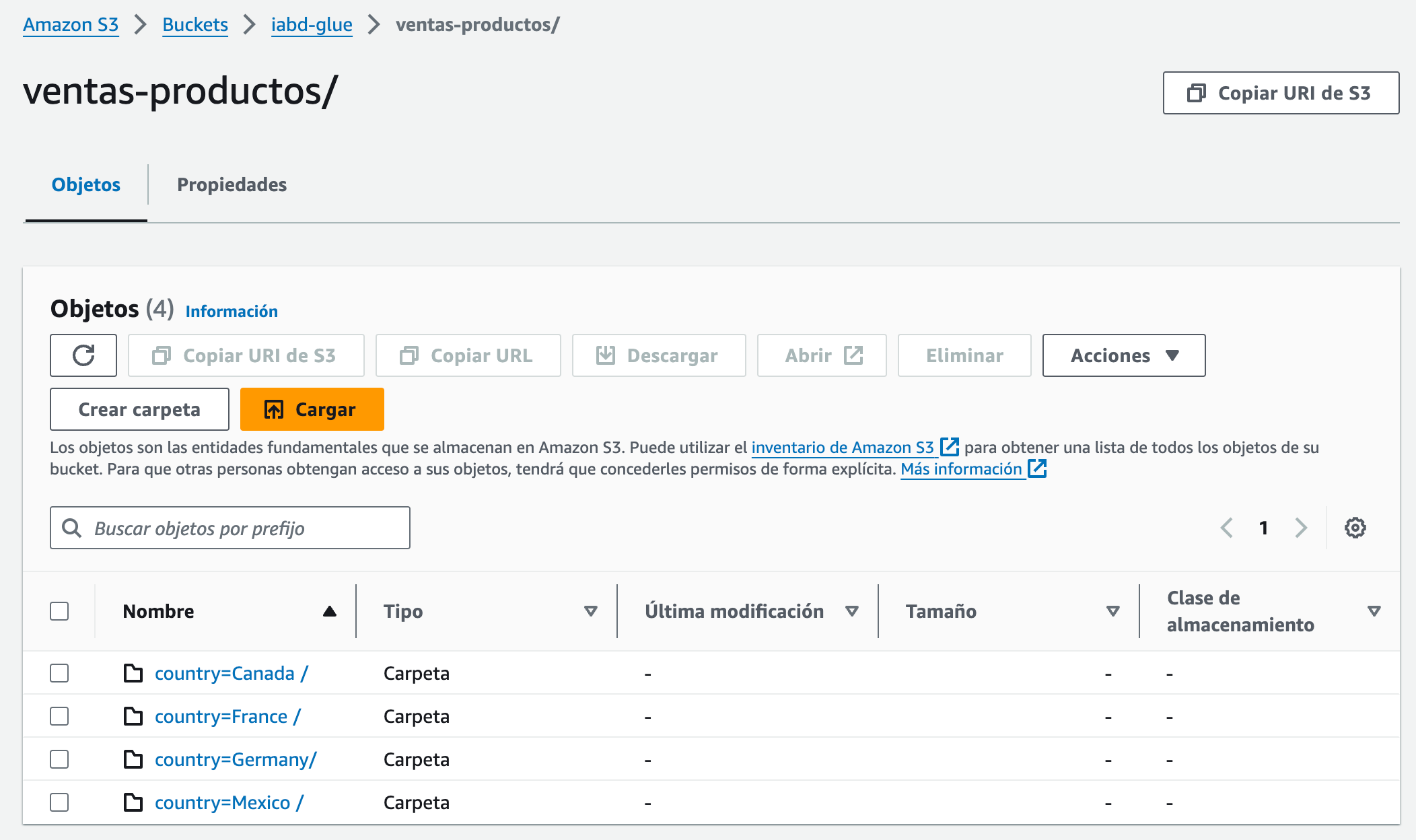
Y tenemos disponible la tabla ventas-producto en el catálogo:
Hola DataBrew¶
En este caso, para utilizar un conjunto de datos más voluminoso y con una casuística más amplia, nos centraremos en un dataset de descubrimiento de fármacos de ChEMBL.
El primer paso es entrar a Glue DataBrew y crear el proyecto de muestra con los datos de CHEMBL, utilizando el LabRole de AWS Academy:
Nada más crear el proyecto, se creará una sesión que tarda alrededor de un minuto en instanciarse.
Cuidado con las sesiones
Cada sesión se factura por franjas de 30 minutos, a 1$. Por ejemplo, si utilizamos 40 minuto serían 2$.
Cabe destacar que las primeras 40 sesiones interactivas son gratuitas para los usuarios de DataBrew por primera vez.
Tras crearse la sesión, veremos un interfaz de trabajo muy parecido al de PowerQuery con los datos mostrados de forma tabular, con un menu superior con las operaciones/transformaciones disponible, y donde podemos observar como tenemos 39 columnas y que sólo se están mostrando 500 filas. Para cada columna, podemos ver un gráfico con diversa información estadística y luego datos de ejemplo de dicha columna. Finalmente, en la parte derecha tenemos los pasos (la receta) que se aplican al dataset:
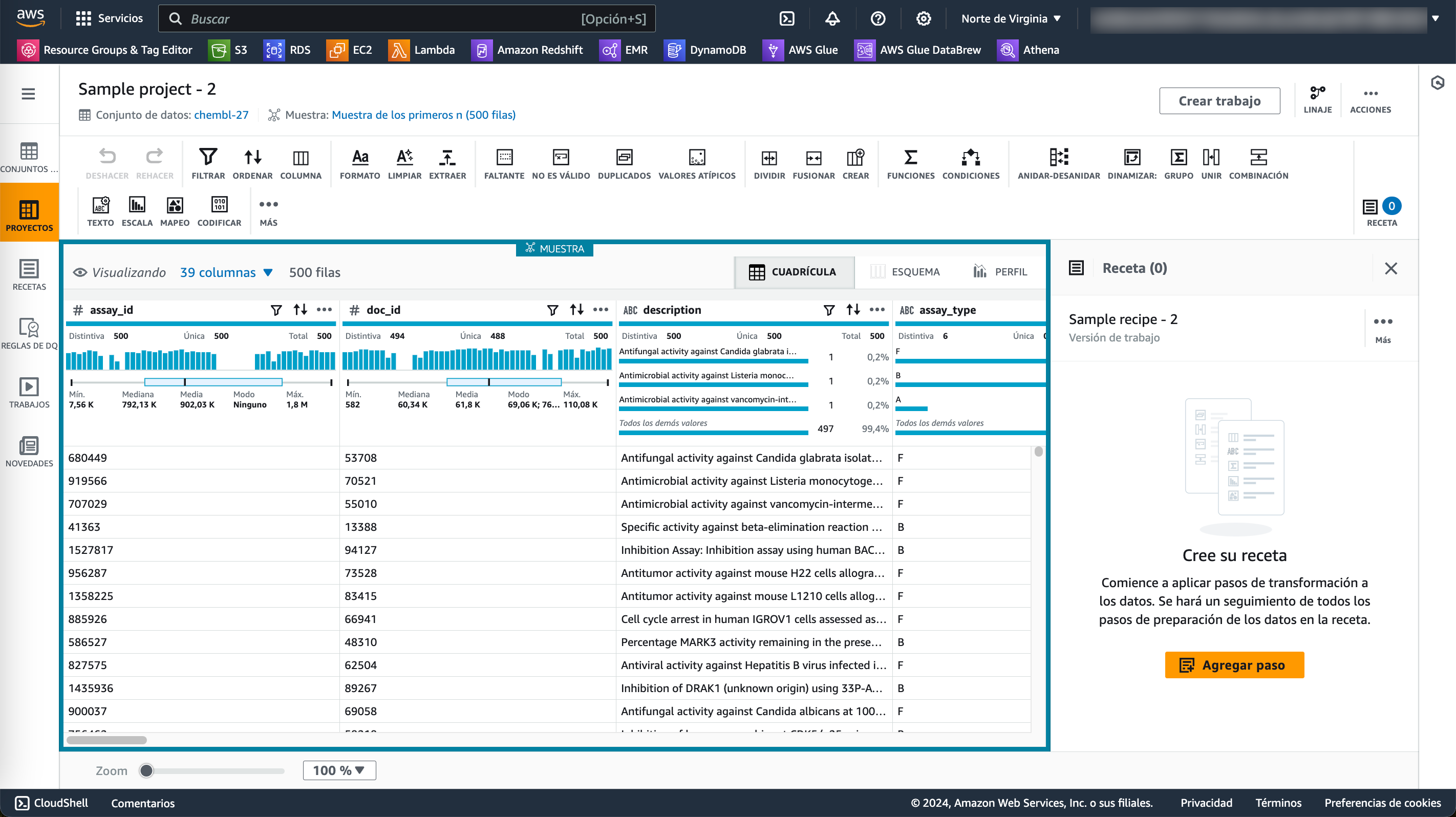
Creando la receta¶
Una vez tenemos el entorno listo, vamos a realizar un conjunto de transformaciones que añadiremos a nuestra receta:
-
El primer paso será eliminar la última columna,
tid_fixedque tiene todos los valores nulos. Para ello, bien desde el menú Columna, o con los tres puntos de la propia columna (...) seleccionamos la opción de Eliminar.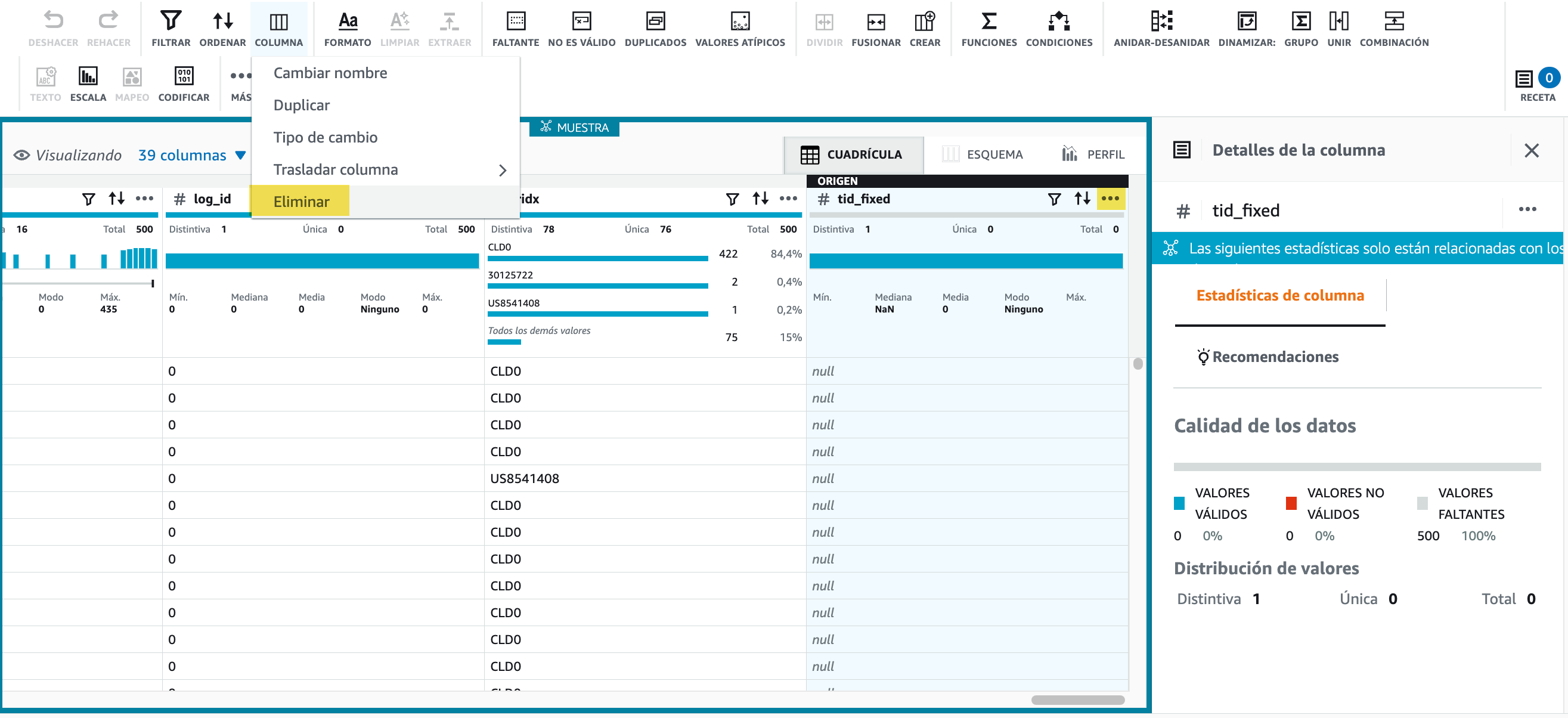
Hola DataBrew - Borrando una columna Tras aplicar los cambios, en la zona de la receta, aparecerá el paso aplicado.
-
A continuación, vamos a filtrar datos. Por ejemplo, seleccionamos la columna
curated_byy seleccionamos para que sea exactamenteAutocuration. En la parte derecha podremos ver una pequeña estadística de los valores existentes y si pulsamos sobre Vista previa, se marcarán en rojo las filas que se eliminarán.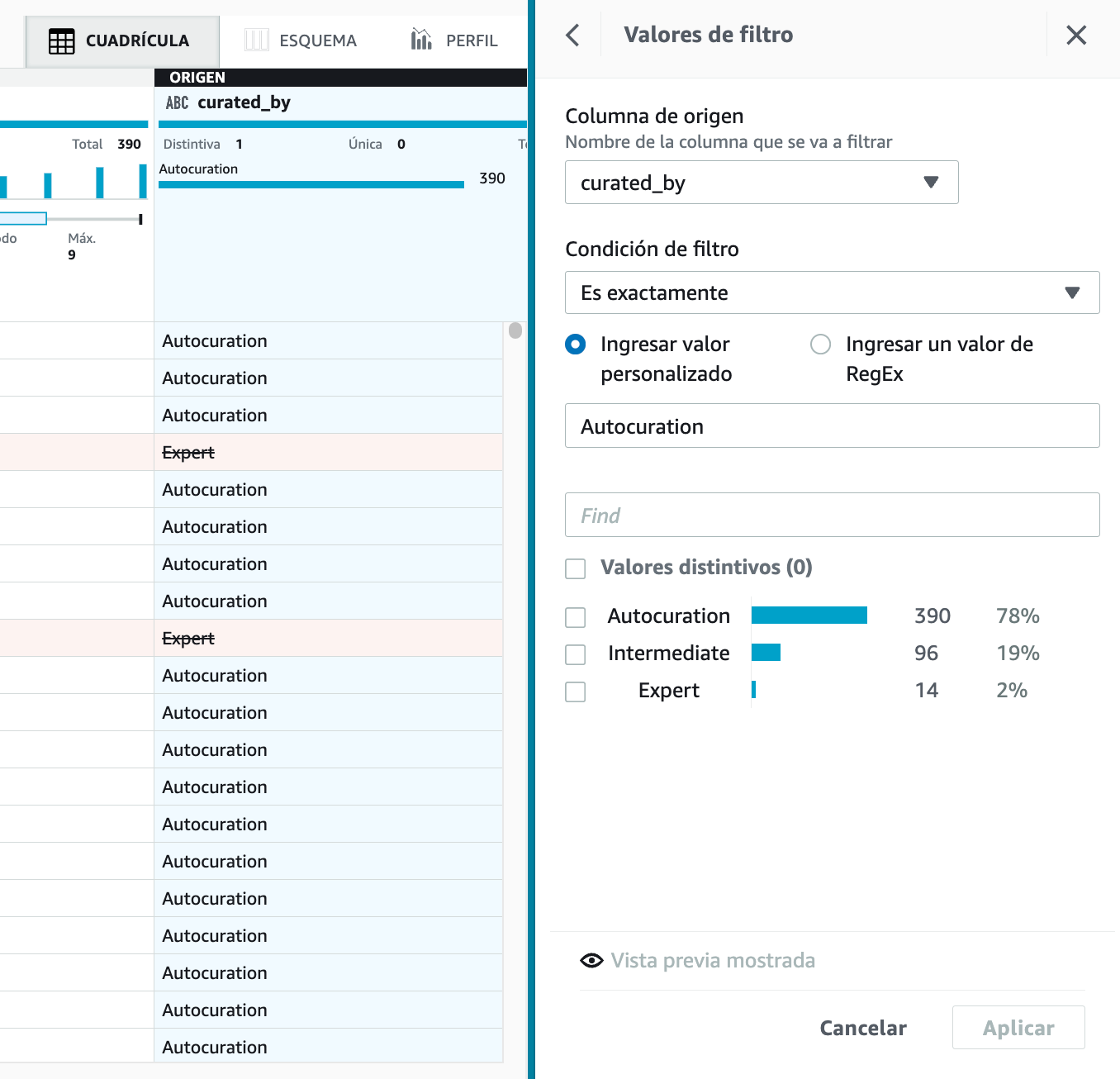
Hola DataBrew - Filtrando datos -
Ahora nos vamos a centrar en la gestión de los valores nulos. Para ello, en la columna
assay_organismcambiaremos los nulos porUnknown, utilizando el menú Faltante y la opción de Rellenar con valor personalizado: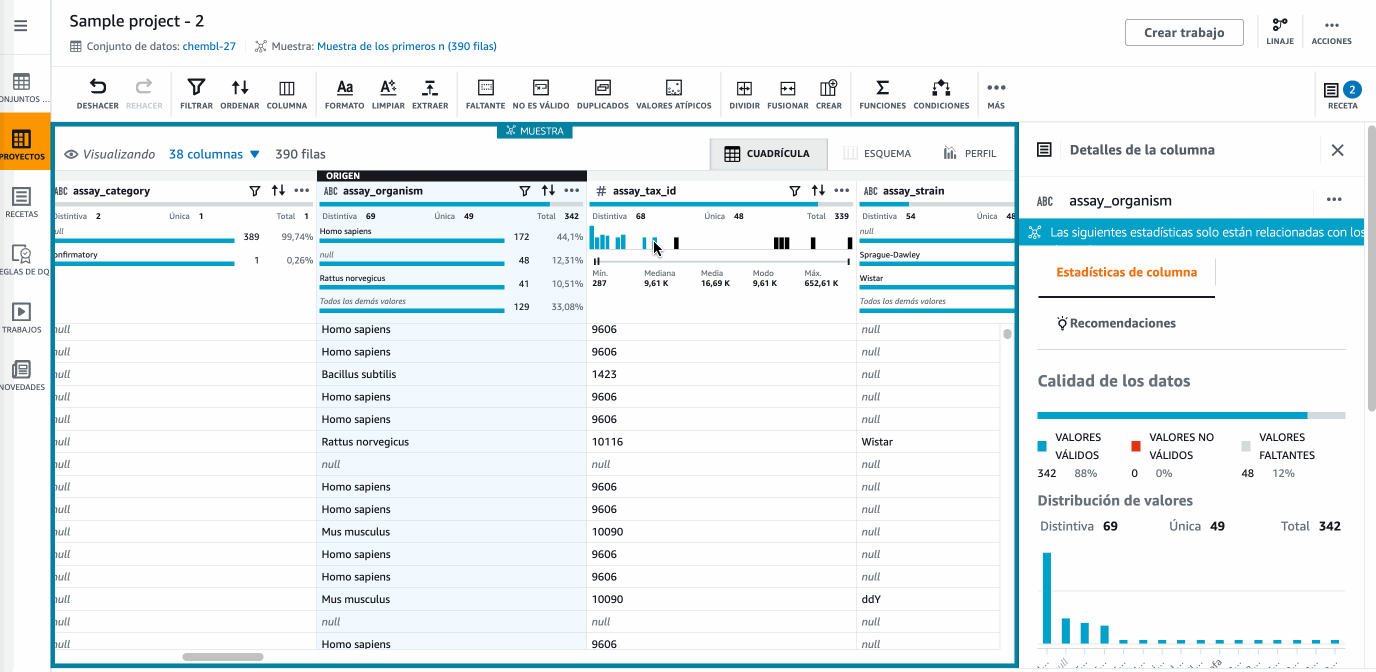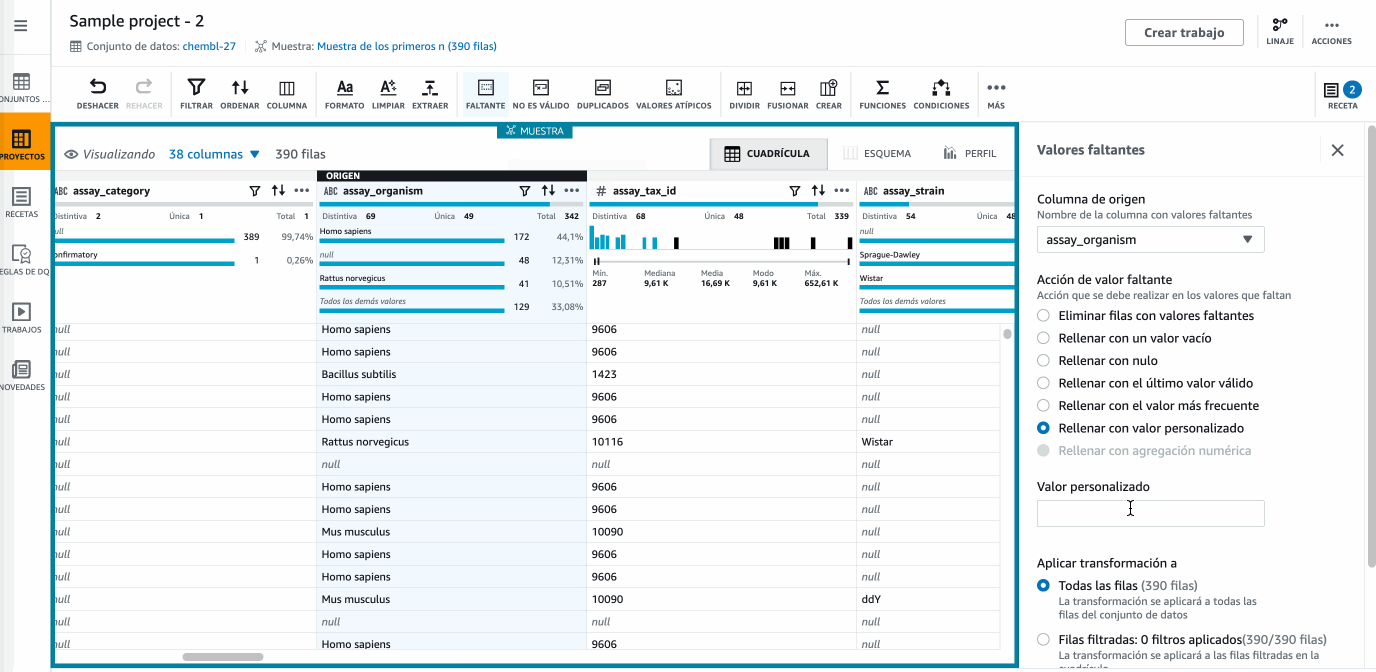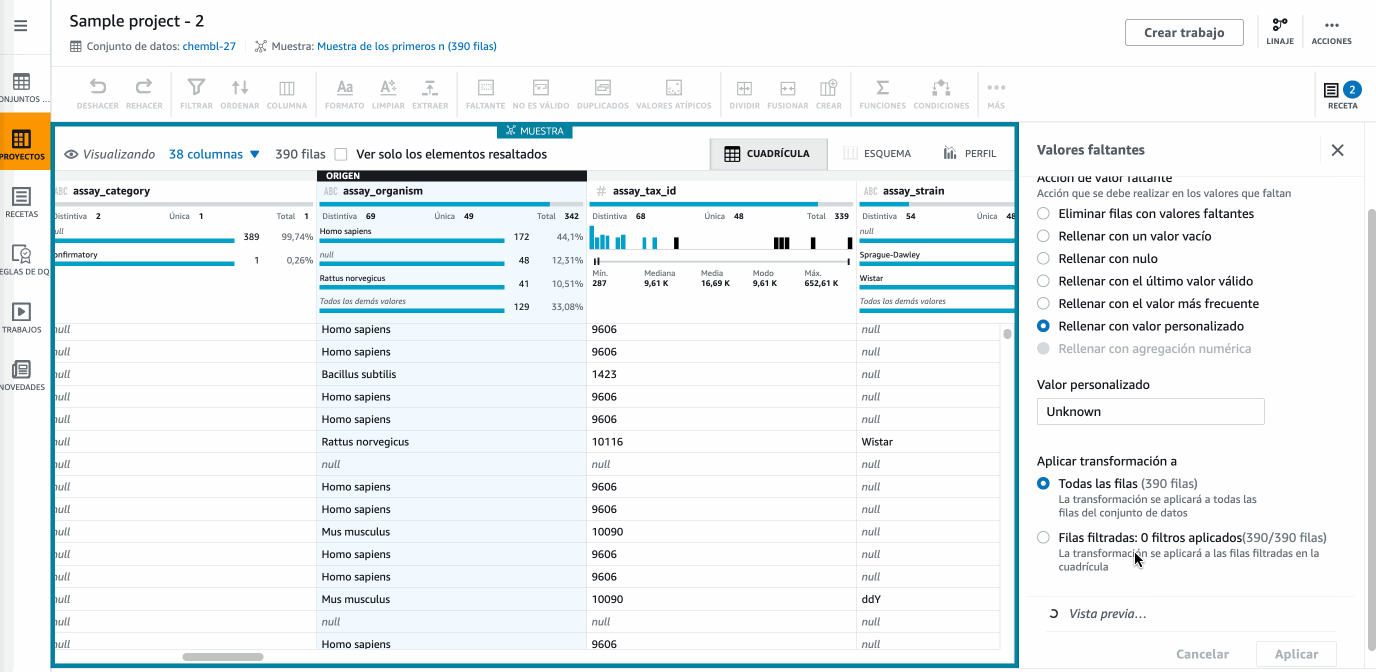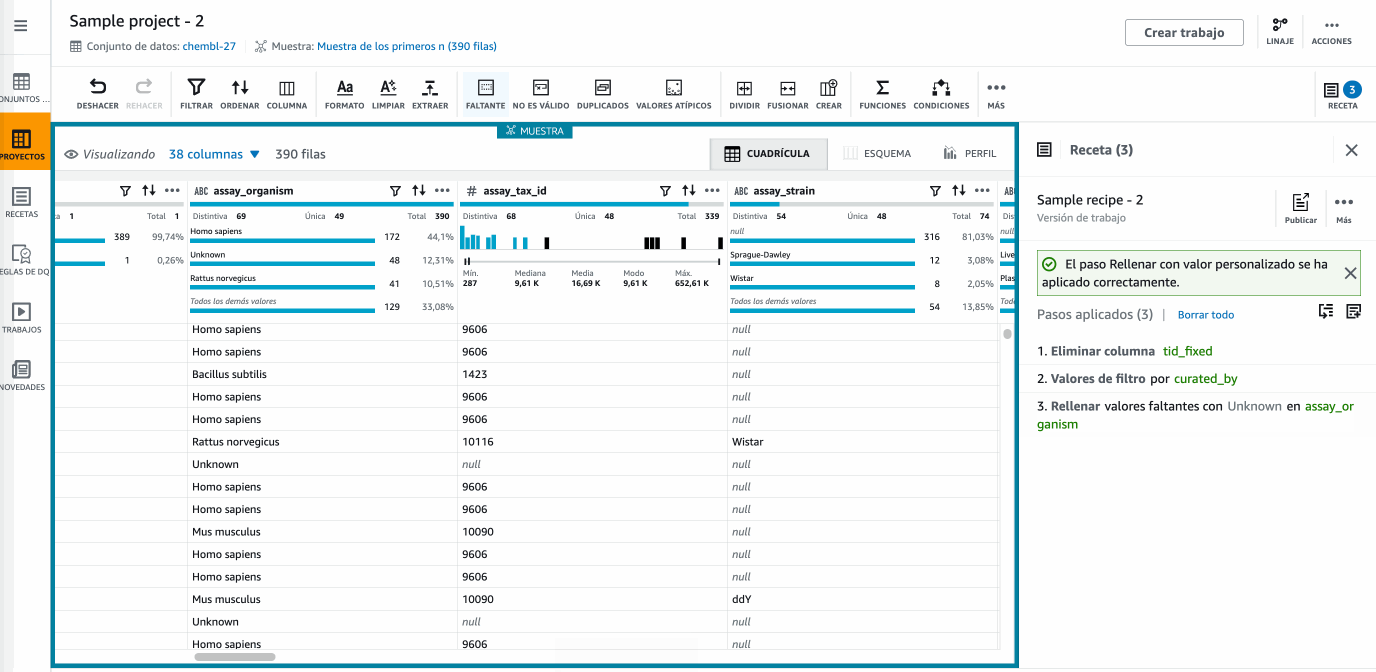
Hola DataBrew - Cambiando los nulos -
Si trabajamos con fechas es muy común crear columnas nuevas con información más útil. En nuestro caso, vamos a añadir una columna que llamaremos
Mescon el nombre del mes que conseguimos con la funciónMONTHNAMEsobre la columnaupdated_on. Para ello, desde el menú Funciones seleccionamos la función de fecha que nos interesa y configuramos los valores: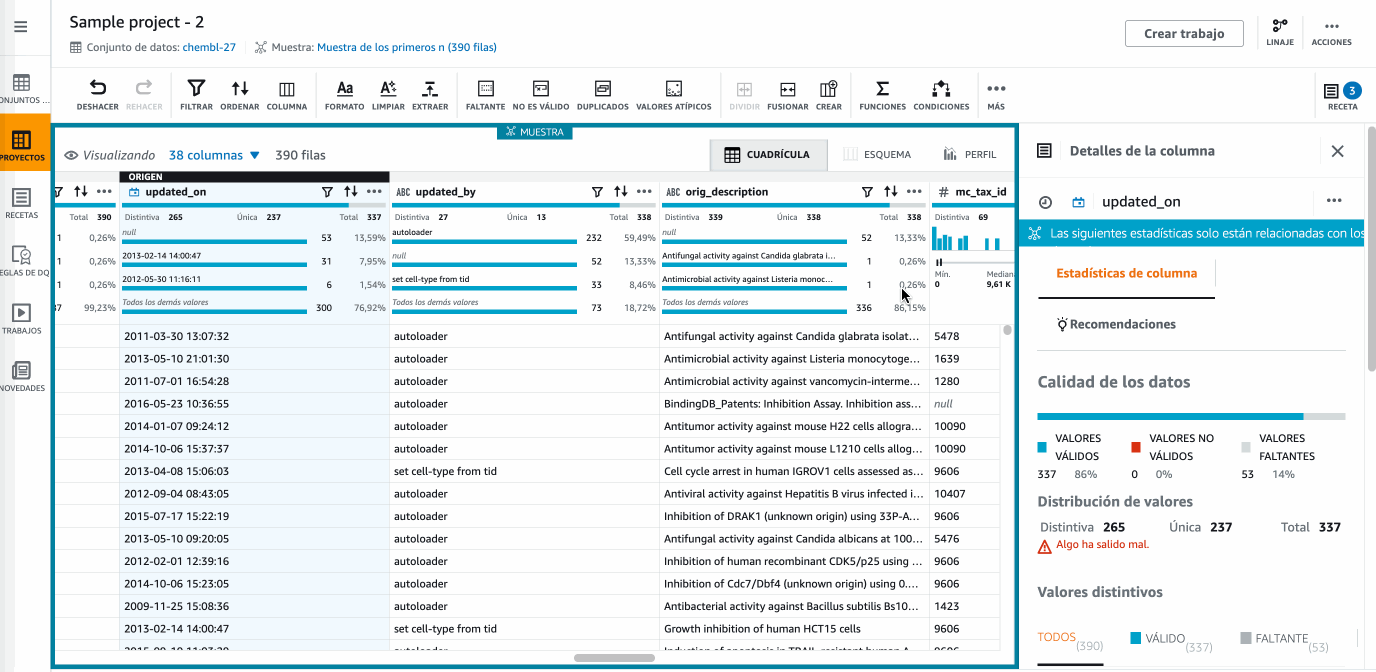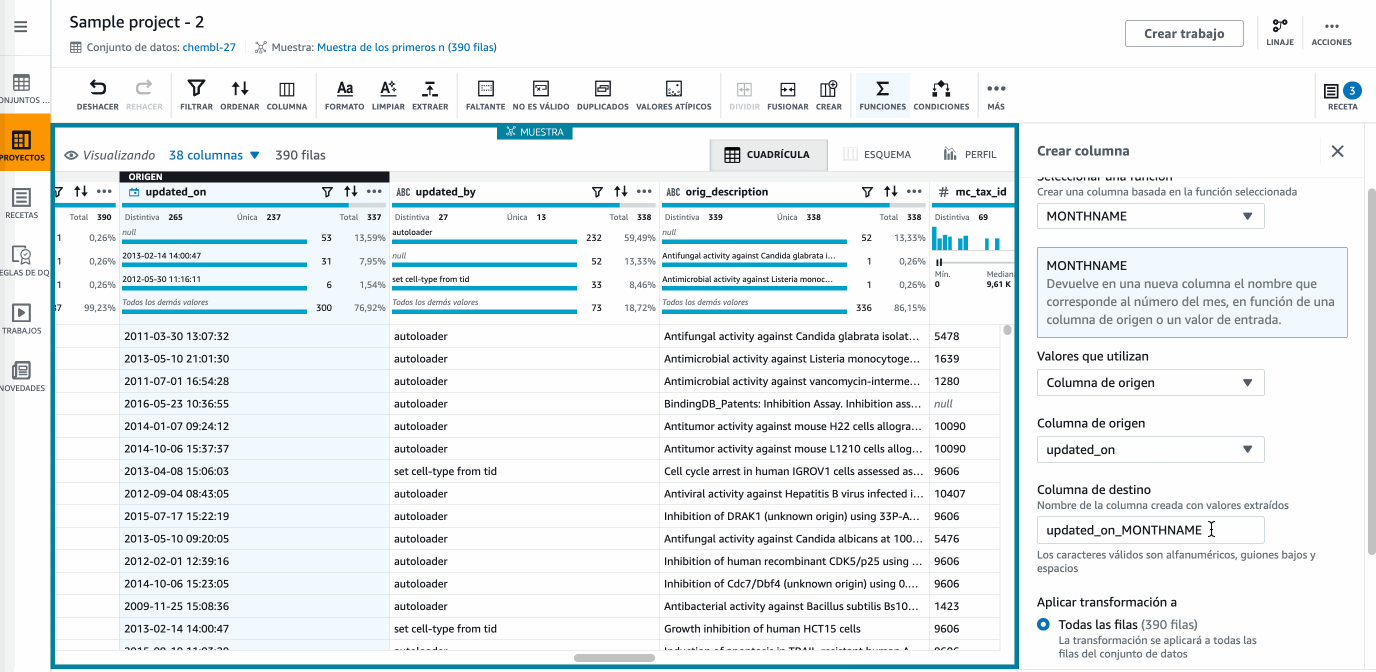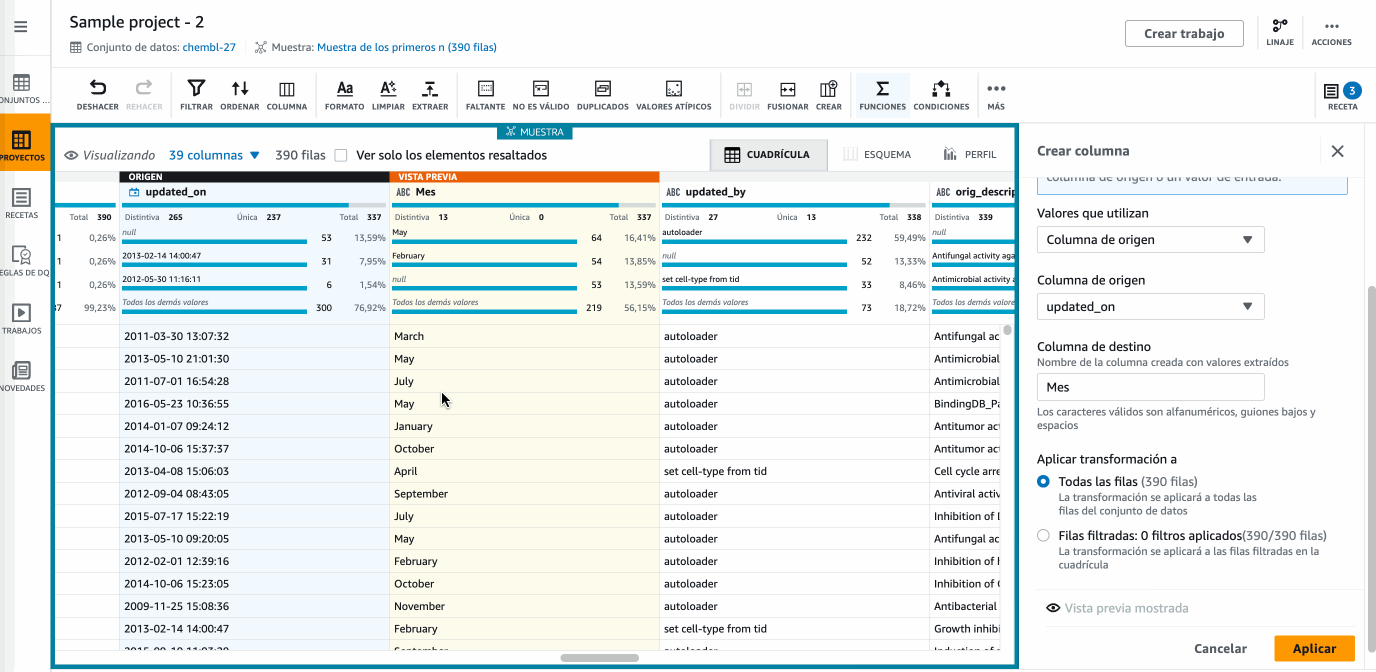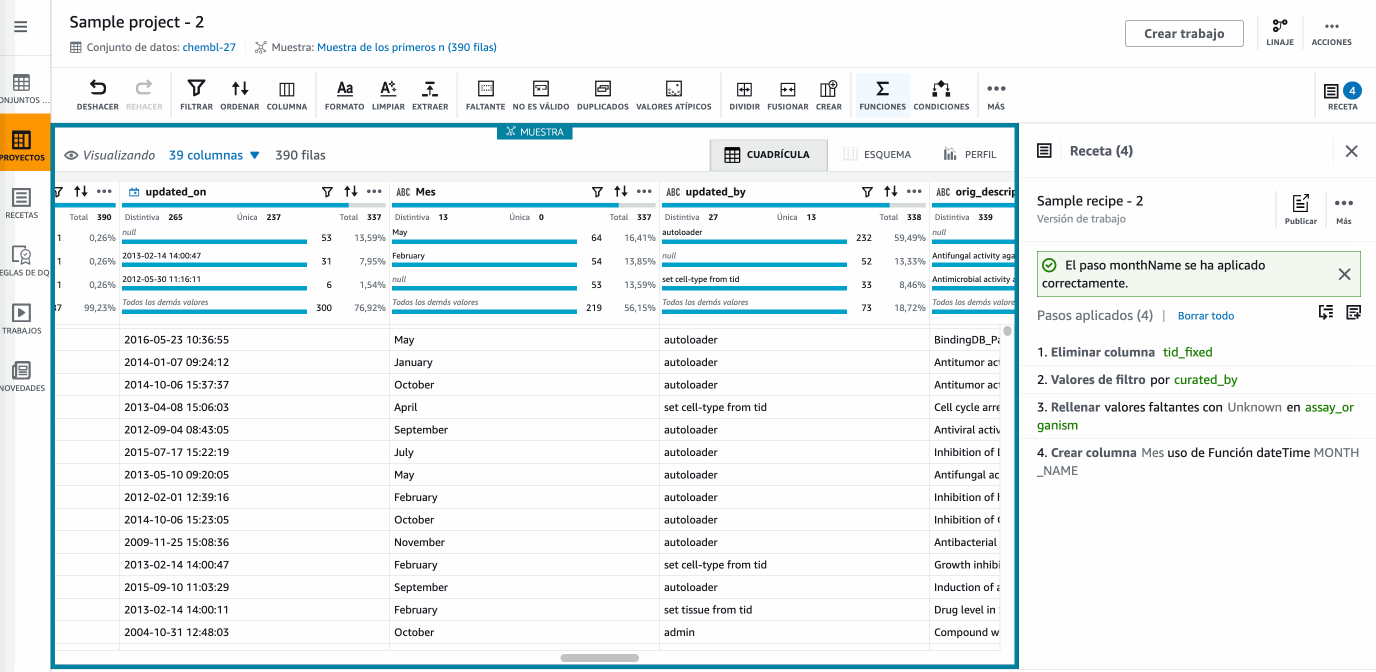
Hola DataBrew - Utilizando funciones -
Una vez ya tenemos nuestra receta completa con todos los pasos necesarios en nuestra transformación, llega el momento de publicarla para crear una versión de la misma y posteriormente poder reutilizarla.
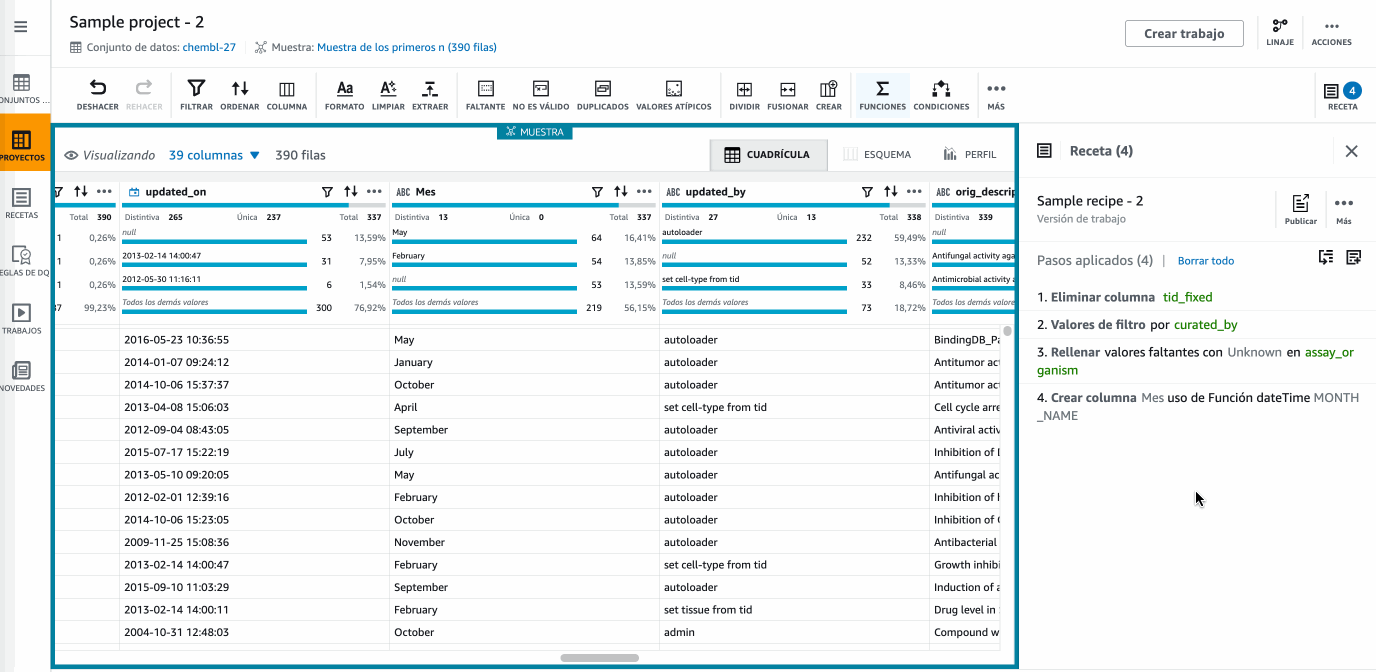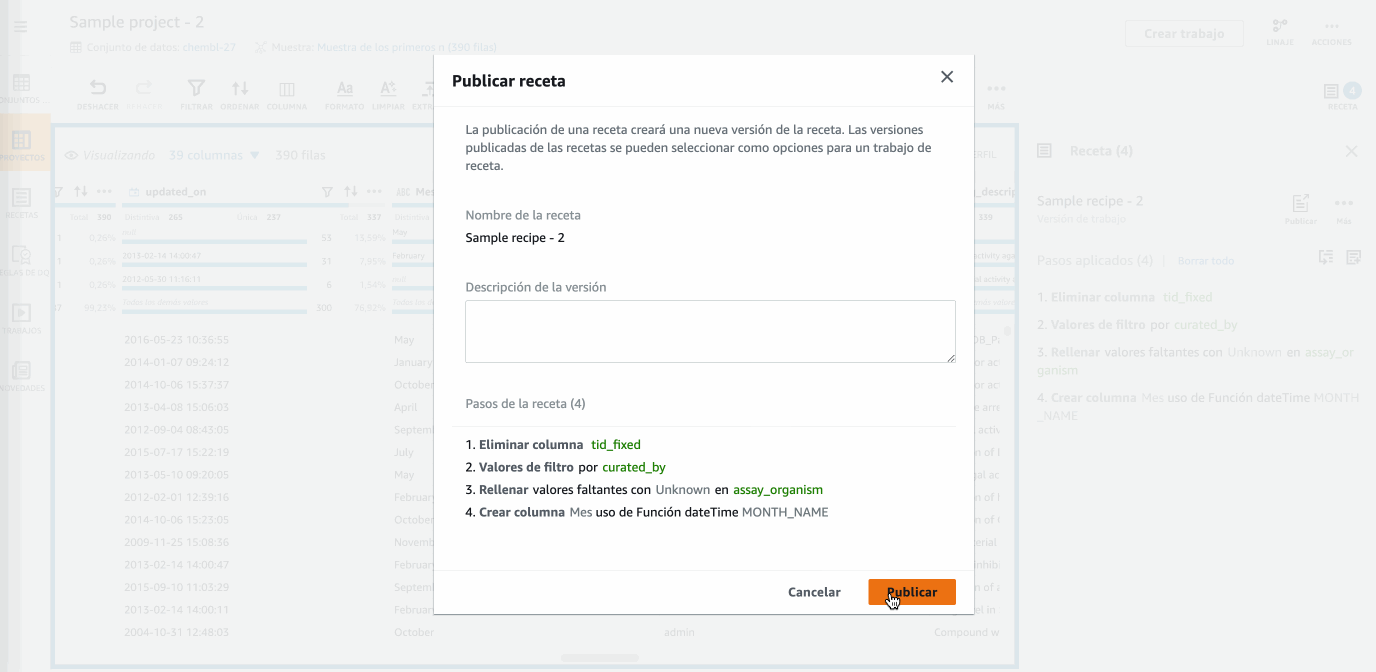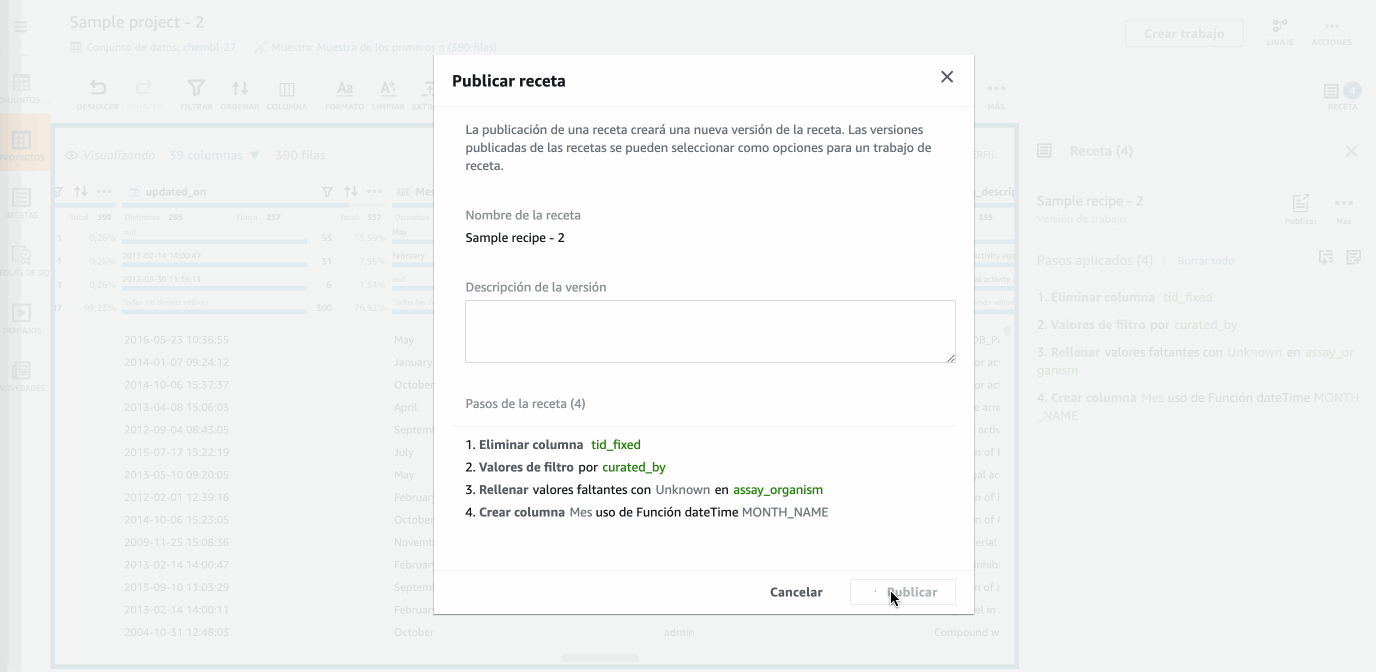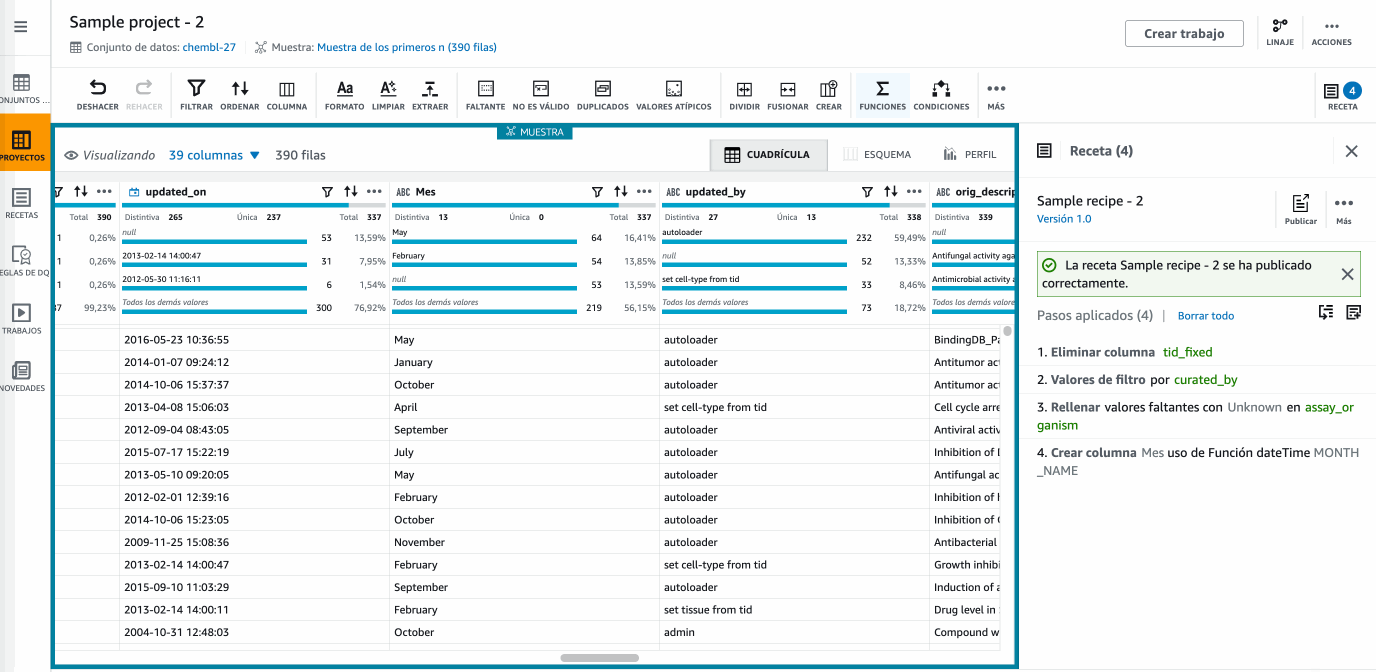
Hola DataBrew - Publicando la receta
De la receta al job¶
-
Si vamos al menú de las recetas, seleccionamos la receta recién publicada, en mi caso
Sample recipe-2, y creamos un trabajo (job) con la misma, en el cual, tras darle un nombre y seleccionar el dataset, vamos a guardar el resultado en S3 tanto en formato CSV como en formato Parquet particionado por la columnaMes, y finalmente seleccionamos el rolLabRole: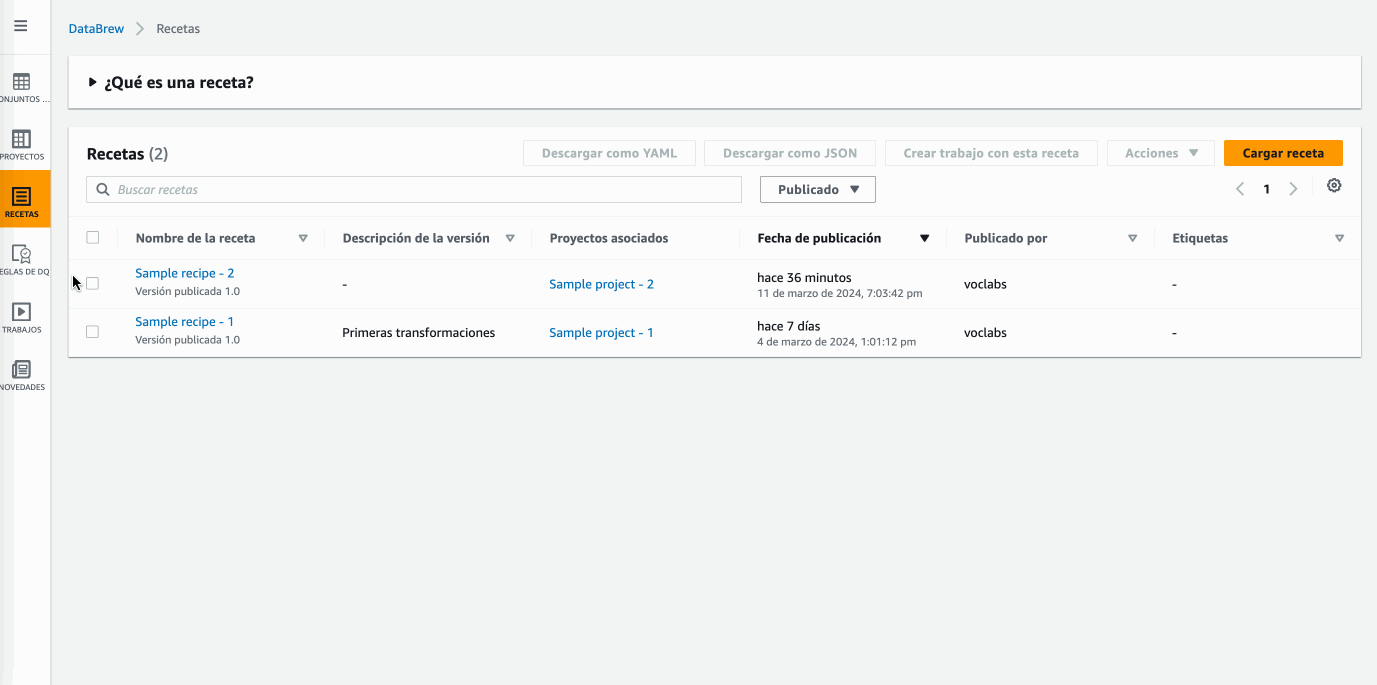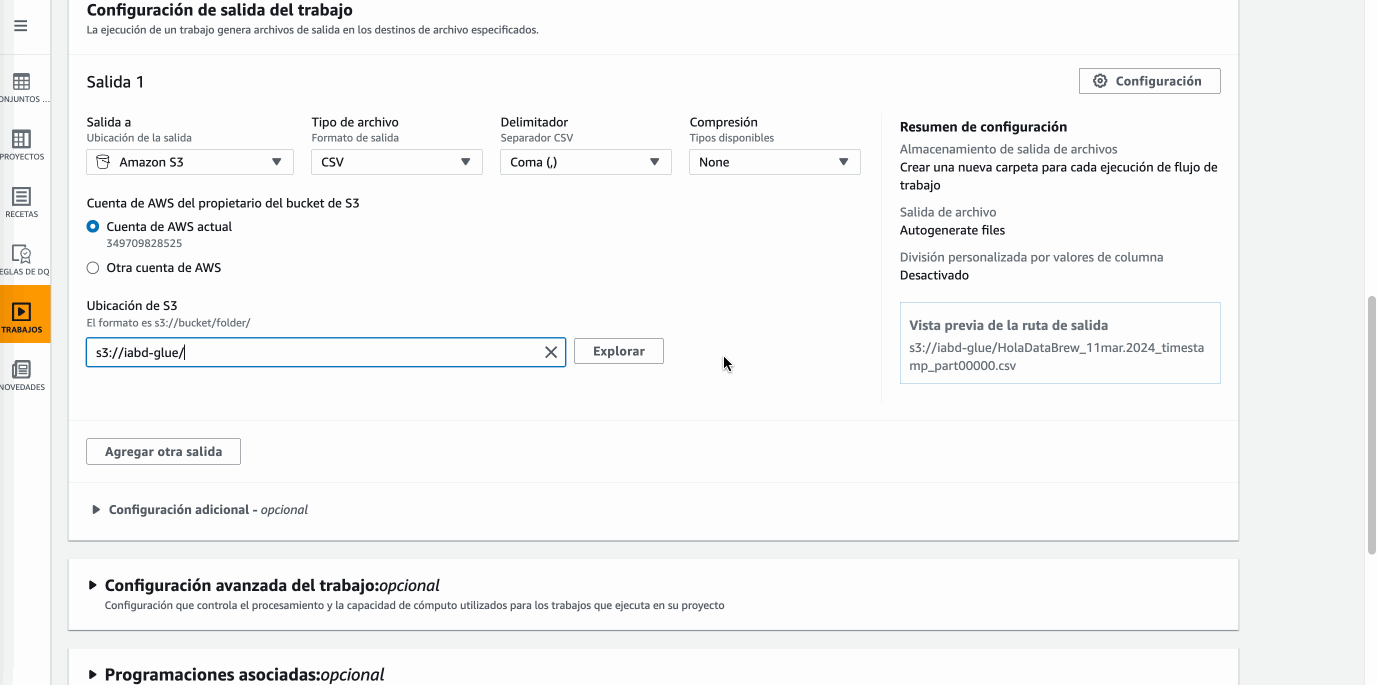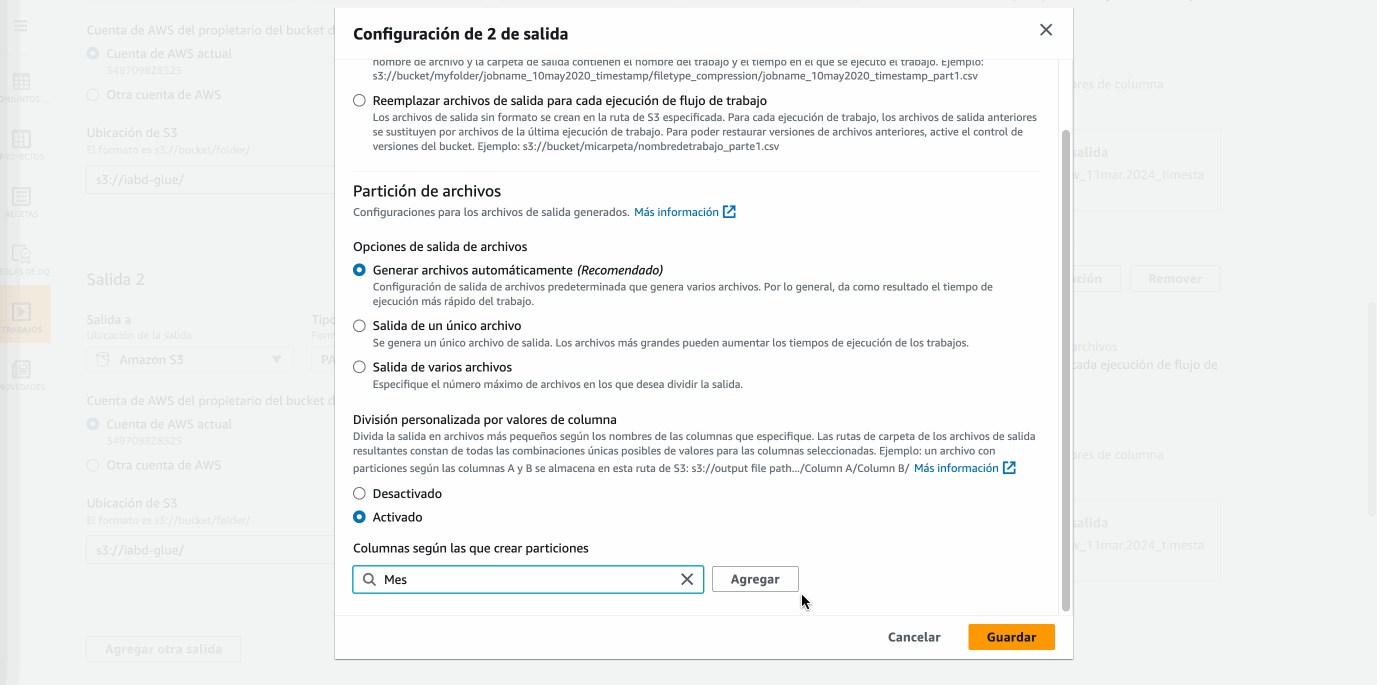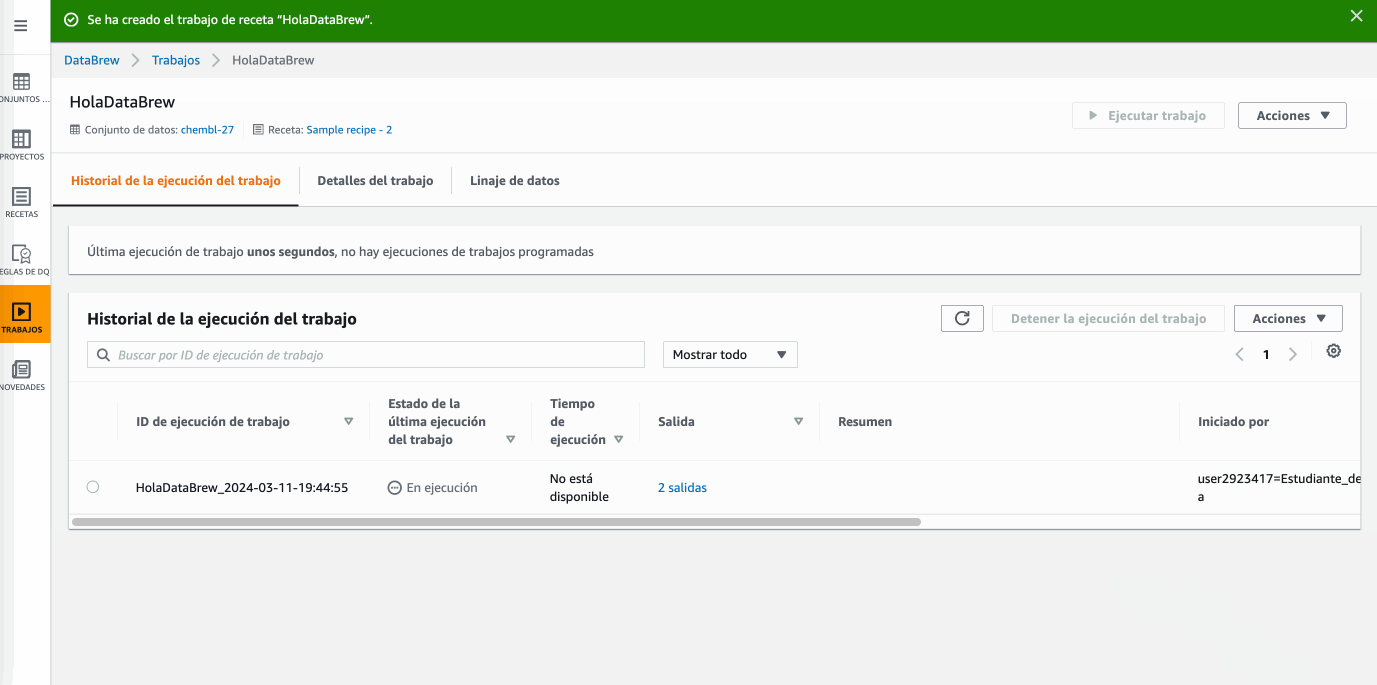
Hola DataBrew - Creando un job Tras la creación, el job se ejecutará automáticamente. Si vamos a S3 veremos cómo ha creado una carpeta por cada salida y dentro estarán los datos transformados.

Hola DataBrew - Resultado del job
Precio de ejecución
A la hora de diseñar una receta, tenemos que pagar por la sesión. Una vez creada, AWS cobrará por cada ejecución de los jobs dependiendo de la cantidad de nodos asignados, a 0,48$ por nodo/hora facturados por minutos. Más información en https://aws.amazon.com/es/glue/pricing/
Entre las diferentes funcionalidades extra que nos ofrece DataBrew es poder programar la ejecución de los jobs (por ejemplo, determinados días/horas o mediante expresiones CRON), así como visualizar el linaje de los datos de los job:
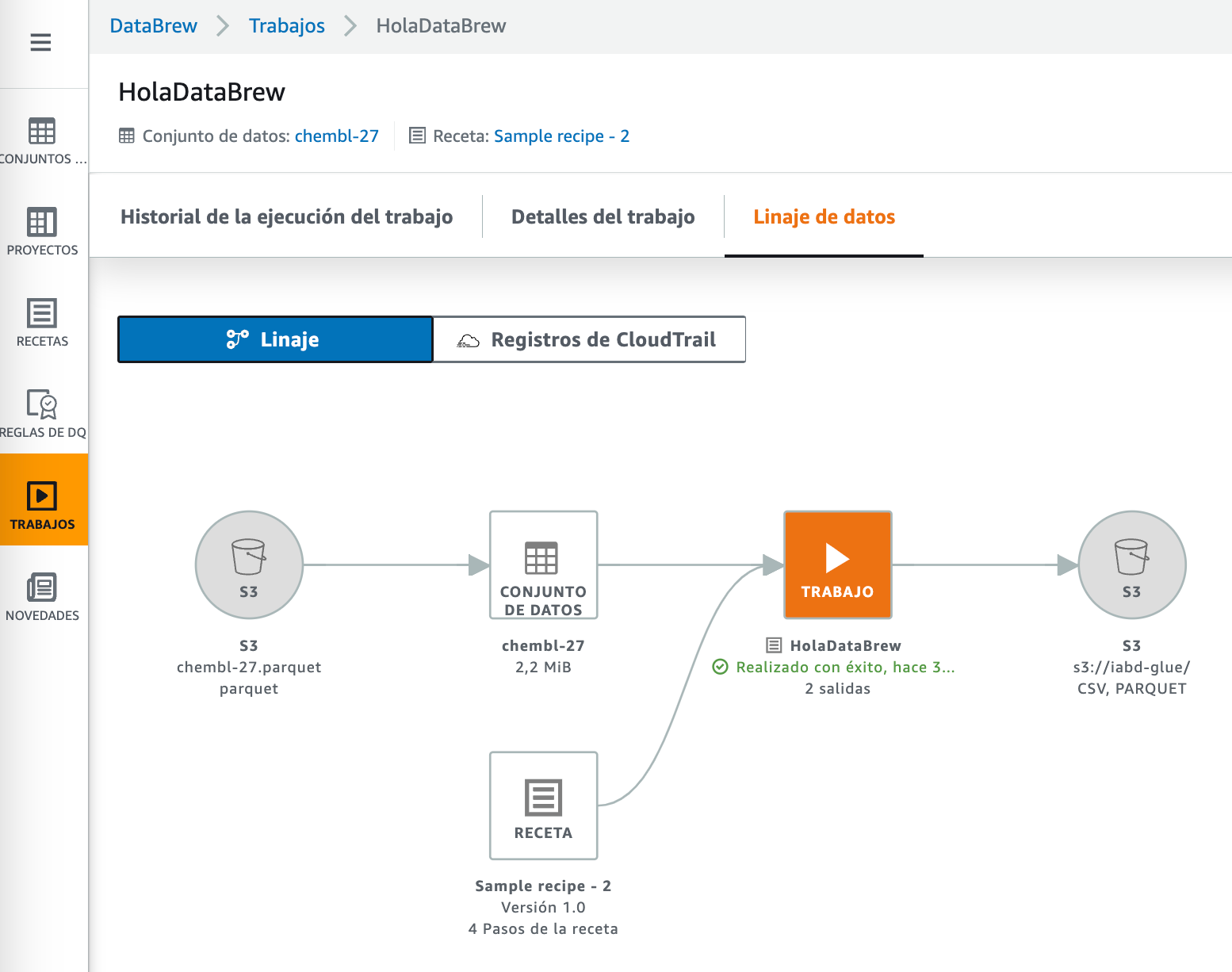
Referencias¶
- AWS Glue User Guide - Documentación oficial
- Getting started with AWS Glue DataBrew - Documentación oficial
- Ejemplo de uso de DataBrew en https://criptonube.com/.
Actividades¶
-
(RABDA.1 / CEBDA.1a, CEBDA.1b / 2p) A partir de los ejemplos de los casos de uso de Hola Glue Crawler y Hola Glue Studio, añade el fichero con los fabricantes y:
- Crea una tabla en el Data Catalog mediante un crawler
- Crea una ETL que realice un Join entre
ventas-productospara añadir el nombre del fabricante y almacena el resultado en S3 en la carpetaventas-productos-fabricantesy genera una nueva tabla llamadaventas_productos_fabricantes.
-
(RABDA.1 / CEBDA.1c, CEBDA.1d / 2p) Mediante Glue DataBrew, sigue el caso de uso de Hola DataBrew y añade los siguientes pasos:
- Elimina también la columna
log_id(menu Columna). - Filtra también por
HomoSapiensla columnamc_organism(menú Filtrar). - Rellenar los valores nulos de la columna
assay_sourcecon el valor más frecuente (menu Faltante). - Pasar a mayúsculas la columna
assay_cell_type(menú Formato).
A continuación, publica la receta y crea y ejecuta el job de forma similar, exportando los datos a S3 tanto en formato CSV como en Parquet particionado por la columna
Mes. - Elimina también la columna
`