Kafka: clúster e integración¶
En esta sesión estudiaremos cómo crear un clúster de Kafka, realizaremos una integración desde un servicio REST hasta su persistencia en S3 y MongoDB haciendo uso de Kafka como middleware de integración, y finalmente veremos como utilizar Kafka Connect para integrar sistemas.
Caso 2: Clúster de Kafka¶
En la sesión anterior estudiamos los conceptos que forman un clúster de Kafka: los brokers, el factor de replicación, la réplica líder y el ISR y la coordinación mediante KRaft. Hasta ahora, sin embargo, solo habíamos trabajado con un único broker. En este caso vamos a llevar esa teoría a la práctica montando un clúster real de 3 nodos, para después verlo tolerar la caída de uno de ellos.
Como ya sabemos, en Kafka hay tres tipos de clústers:
- Un nodo con un broker
- Un nodo con muchos brokers
- Muchos nodos con múltiples brokers
A continuación crearemos un clúster de 3 brokers, ya sea sobre la máquina virtual (con Zookeeper) y como con Docker (con KRaft, sin Zookeeper).
De Zookeeper a KRaft
Hasta Kafka 2.8 era obligatorio usar Zookeeper para coordinar el clúster (elección de líder, metadatos, etc.). Desde Kafka 3.3 se considera estable KRaft (Kafka Raft), un protocolo de consenso interno que elimina la dependencia de Zookeeper. En Kafka 4.x (la versión que usamos en Docker), Zookeeper ya ha sido eliminado por completo.
Creando brokers¶
En este caso, levantaremos tres contenedores (kafka-1, kafka-2, kafka-3), cada uno con su propio broker y participando además en el quórum de KRaft como controller.
El docker-compose.yml del curso define el perfil kafka-cluster con los tres brokers. Para arrancarlo, usaremos:
docker compose --profile kafka-cluster up -d
Esto levanta:
| Contenedor | Hostname interno | Puerto externo (host) |
|---|---|---|
iabd-kafka-1 |
kafka-1 |
9094 |
iabd-kafka-2 |
kafka-2 |
9095 |
iabd-kafka-3 |
kafka-3 |
9096 |
iabd-kafka-ui-cluster |
kafka-ui-cluster |
8081 |
Configuración relevante en el docker-compose.yml (extracto del primer broker):
kafka-1:
image: apache/kafka:latest
container_name: iabd-kafka-1
hostname: kafka-1
profiles: ["kafka-cluster"]
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-1:9092,EXTERNAL://localhost:9094
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_MIN_INSYNC_REPLICAS: 2
ports:
- '9094:9094'
Tolerancia a fallos
Como los tres brokers también hacen de controllers (modo combinado), el quórum de KRaft necesita mayoría (2 de 3). El clúster aguanta la caída de 1 nodo; si caen 2, el control plane se detiene aunque algún broker siga sirviendo lecturas.
Entorno legacy con Zookeeper
La máquina virtual conserva Kafka 3.3.1 con Zookeeper por motivos didácticos, igual que vimos en la sesión anterior. Cualquier despliegue moderno (incluido el clúster Docker de este caso) funciona en modo KRaft, sin Zookeeper. Mantenemos esta pestaña como referencia del modelo clásico, pero el entorno recomendado es el de Docker.
Para ello, vamos a crear diferentes archivos de configuración a partir del fichero config/server.properties que utilizábamos para arrancar el servidor.
Así pues, crearemos 3 copias del archivo modificando las propiedades broker.id (identificador del broker), listeners (URL y puerto de escucha del broker) y log.dirs (carpeta donde se guardarán los logs del broker):
server101.properties
broker.id=101
listeners=PLAINTEXT://:9092
log.dirs=$KAFKA_HOME/logs/broker_101
zookeeper.connect=localhost:2181
server102.properties
broker.id=102
listeners=PLAINTEXT://:9093
log.dirs=$KAFKA_HOME/logs/broker_102
zookeeper.connect=localhost:2181
server103.properties
broker.id=103
listeners=PLAINTEXT://:9094
log.dirs=$KAFKA_HOME/logs/broker_103
zookeeper.connect=localhost:2181
Una vez creados los tres archivos, ejecutaremos los siguientes comandos (cada uno en un terminal diferente) para arrancar Zookeeper y cada uno de los brokers:
zookeeper-server-start.sh ./config/zookeeper.properties
kafka-server-start.sh ./config/server101.properties
kafka-server-start.sh ./config/server102.properties
kafka-server-start.sh ./config/server103.properties
Creando topics¶
A la hora de crear un topic, además del nombre, indicaremos:
- la cantidad de particiones con el parámetro
--partitions - el factor de replicación con el parámetro
--replication-factor
Los comandos kafka-topics.sh están dentro de los contenedores, por lo que usaremos docker exec sobre cualquiera de los tres brokers, ya que el clúster propaga la operación:
docker exec -it --workdir /opt/kafka/bin iabd-kafka-1 bash
A continuación, vamos a crear un topic con tres particiones y factor de replicación 2:
./kafka-topics.sh --create --topic iabd-topic-3p2r \
--bootstrap-server kafka-1:9092 \
--partitions 3 --replication-factor 2
Y para describirlo:
./kafka-topics.sh --describe --topic iabd-topic-3p2r \
--bootstrap-server kafka-1:9092
Con cada comando que vayamos a interactuar con Kafka, le vamos a pasar como parámetro --bootstrap-server iabd-virtualbox:9092 para indicarle donde se encuentra uno de los brokers (en versiones antiguas de Kafka se indicaba donde estaba Zookeeper mediante --zookeeper iabd-virtualbox:9092).
Así pues, vamos a crear un topic con tres particiones y factor de replicación 2:
kafka-topics.sh --create --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092 \
--partitions 3 --replication-factor 2
Si ahora obtenemos la información del topic:
kafka-topics.sh --describe --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092
Podemos observar como cada partición tiene la partición líder en un broker distinto y en qué brokers se encuentran las réplicas:
Topic: iabd-topic-3p2r TopicId: yZXO89a7QzOmhg64Up9Mxw PartitionCount: 3 ReplicationFactor: 2 Configs: min.insync.replicas=2
Topic: iabd-topic-3p2r Partition: 0 Leader: 3 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: iabd-topic-3p2r Partition: 1 Leader: 3 Replicas: 3,1 Isr: 1,3 Elr: LastKnownElr:
Topic: iabd-topic-3p2r Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2 Elr: LastKnownElr:
Produciendo y consumiendo¶
Respecto al código Python, va a ser el mismo que hemos visto en la sesión anterior pero modificando:
- el nombre del topic
- la lista de bootstrap_servers (aunque podríamos haber dejado únicamente el nodo principal, ya que Kafka le comunica al cliente el resto de nodos del clúster, es una buena práctica indicarlos todos por si el nodo al que nos conectamos de manera explícita está caído).
Los puertos externos publicados son 9094, 9095 y 9096. Desde el host nos conectamos a localhost en esos tres puertos:
from confluent_kafka import Producer
from json import dumps
import time
producer = Producer({
'bootstrap.servers': 'localhost:9094,localhost:9095,localhost:9096'
})
for i in range(10):
producer.produce("iabd-topic-3p2r", value=dumps({"nombre": "producer " + str(i)}).encode('utf-8'))
# Esperamos a que se entreguen todos los mensajes pendientes.
producer.flush()
time.sleep(1)
from confluent_kafka import Consumer
from json import loads
consumer = Consumer({
'bootstrap.servers': 'localhost:9094,localhost:9095,localhost:9096',
'group.id': 'iabd-grupo-1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': True
})
consumer.subscribe(['iabd-topic-3p2r'])
try:
while True:
m = consumer.poll(1.0)
if m is None:
continue
if m.error():
print(f"Error: {m.error()}")
continue
value = loads(m.value().decode('utf-8'))
print(f"P:{m.partition()} O:{m.offset()} K:{m.key()} V:{value}")
finally:
consumer.close()
Desde otro contenedor
Si ejecutásemos el productor/consumidor desde dentro de la red de Docker (por ejemplo desde el contenedor jupyter para Spark Streaming), usaríamos los hostnames internos: kafka-1:9092,kafka-2:9092,kafka-3:9092.
Los puertos de los brokers son 9092, 9093 y 9094, por lo que nos conectamos a iabd-virtualbox en esos tres puertos:
from confluent_kafka import Producer
from json import dumps
import time
producer = Producer({
'bootstrap.servers': 'iabd-virtualbox:9092,iabd-virtualbox:9093,iabd-virtualbox:9094'
})
for i in range(10):
producer.produce("iabd-topic-3p2r", value=dumps({"nombre": "producer " + str(i)}).encode('utf-8'))
# Esperamos a que se entreguen todos los mensajes pendientes.
producer.flush()
time.sleep(1)
from confluent_kafka import Consumer
from json import loads
consumer = Consumer({
'bootstrap.servers': 'iabd-virtualbox:9092,iabd-virtualbox:9093,iabd-virtualbox:9094',
'group.id': 'iabd-grupo-1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': True
})
consumer.subscribe(['iabd-topic-3p2r'])
try:
while True:
m = consumer.poll(1.0)
if m is None:
continue
if m.error():
print(f"Error: {m.error()}")
continue
value = loads(m.value().decode('utf-8'))
print(f"P:{m.partition()} O:{m.offset()} K:{m.key()} V:{value}")
finally:
consumer.close()
Como ahora tenemos los datos repartidos en dos brokers (por el factor de replicación) y tres particiones, los datos consumidos no tienen por qué llegar en orden (como es el caso), ya que los productores han enviado los datos de manera aleatoria para repartir la carga:
P:1 O:0 K:None V:{'nombre': 'producer 0'}
P:1 O:1 K:None V:{'nombre': 'producer 3'}
P:2 O:0 K:None V:{'nombre': 'producer 1'}
P:2 O:1 K:None V:{'nombre': 'producer 5'}
P:2 O:2 K:None V:{'nombre': 'producer 6'}
P:2 O:3 K:None V:{'nombre': 'producer 7'}
P:2 O:4 K:None V:{'nombre': 'producer 8'}
P:0 O:0 K:None V:{'nombre': 'producer 2'}
P:0 O:1 K:None V:{'nombre': 'producer 4'}
P:0 O:2 K:None V:{'nombre': 'producer 9'}
Para asegurarnos el orden, debemos enviar los mensajes con una clave de partición con el atributo key del método produce:
producer.produce("iabd-topic-3p2r", value=dumps({"nombre": "producer " + str(i)}).encode('utf-8'),
key=b"iabd")
Si volvemos a ejecutar el productor con esa clave, el resultado sí que sale ordenado:
P:0 O:3 K:b'iabd' V:{'nombre': 'producer 0'}
P:0 O:4 K:b'iabd' V:{'nombre': 'producer 1'}
P:0 O:5 K:b'iabd' V:{'nombre': 'producer 2'}
P:0 O:6 K:b'iabd' V:{'nombre': 'producer 3'}
P:0 O:7 K:b'iabd' V:{'nombre': 'producer 4'}
P:0 O:8 K:b'iabd' V:{'nombre': 'producer 5'}
P:0 O:9 K:b'iabd' V:{'nombre': 'producer 6'}
P:0 O:10 K:b'iabd' V:{'nombre': 'producer 7'}
P:0 O:11 K:b'iabd' V:{'nombre': 'producer 8'}
P:0 O:12 K:b'iabd' V:{'nombre': 'producer 9'}
Tolerancia a fallos en acción¶
Hasta ahora hemos producido y consumido contra un clúster sano. Pero el verdadero motivo de montar varios brokers con un factor de replicación mayor que 1 es sobrevivir a la caída de un nodo. Vamos a comprobarlo parando uno de los brokers y observando cómo reacciona el clúster.
Partimos del topic iabd-topic-3p2r que creamos antes, con 3 particiones y factor de replicación 2. Recordemos su estado inicial (lo vimos al describirlo): cada partición tiene su líder en un broker distinto y una réplica en otro.
Topic: iabd-topic-3p2r TopicId: yZXO89a7QzOmhg64Up9Mxw PartitionCount: 3 ReplicationFactor: 2 Configs: min.insync.replicas=2
Topic: iabd-topic-3p2r Partition: 0 Leader: 3 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: iabd-topic-3p2r Partition: 1 Leader: 3 Replicas: 3,1 Isr: 1,3 Elr: LastKnownElr:
Topic: iabd-topic-3p2r Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2 Elr: LastKnownElr:
Vamos a parar el primer broker del clúster, ya que es el lider de la partición 2, para ver cómo el clúster reacciona a su caída.
Para ello, ejecutamos:
docker stop iabd-kafka-1
Y volvemos a describir el topic desde cualquiera de los brokers que siguen vivos:
docker exec -it iabd-kafka-2 /opt/kafka/bin/kafka-topics.sh --describe --topic iabd-topic-3p2r --bootstrap-server kafka-2:9092
Detenemos el primer broker pulsando Ctrl+C en el terminal donde lo arrancamos (el de server101.properties).
Y volvemos a describir el topic desde otro de los brokers:
kafka-topics.sh --describe --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092
Ahora veremos algo parecido a esto (el broker 1 ha desaparecido tanto de los líderes como de los ISR):
Topic: iabd-topic-3p2r TopicId: yZXO89a7QzOmhg64Up9Mxw PartitionCount: 3 ReplicationFactor: 2 Configs: min.insync.replicas=2
Topic: iabd-topic-3p2r Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: iabd-topic-3p2r Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3 Elr: 1 LastKnownElr:
Topic: iabd-topic-3p2r Partition: 2 Leader: 2 Replicas: 1,2 Isr: 2 Elr: 1 LastKnownElr:
Fíjate en lo que ha pasado:
- La partición 2, cuyo líder era el broker
1, ha elegido un nuevo líder: ahora la sirve el broker2. El clúster no ha perdido el acceso a esos datos. - En las particiones 1 y 2, el campo
Isr(in-sync replicas) se ha reducido: la réplica que vivía en el broker1ya no está sincronizada, porque el broker está caído. - La columna
Replicasno cambia: indica dónde deberían estar las réplicas, mientras queIsrindica cuáles están realmente al día. Cuando el broker1vuelva, se pondrá al día y volverá a aparecer enIsr.
Si ahora ejecutamos de nuevo el productor y el consumidor del apartado anterior, siguen funcionando: el clúster ha tolerado la caída de un nodo, justo como prometía el factor de replicación 2.
min.insync.replicas y acks¶
Aquí entra en juego una propiedad que aparece en el docker-compose.yml del clúster y que conviene entender: KAFKA_MIN_INSYNC_REPLICAS: 2.
Si hacemos memoria y recordamos los niveles de acks de la sesión anterior, tenemos que la propiedad min.insync.replicas solo tiene efecto cuando el productor usa acks=all, y define el mínimo de réplicas sincronizadas (ISR) que deben confirmar una escritura para que se considere correcta.
Con nuestra configuración (factor de replicación 2 y min.insync.replicas=2):
- Clúster sano: cada partición tiene 2 ISR. Una escritura con
acks=allnecesita la confirmación de las 2 → funciona. - Un broker caído (el escenario que acabamos de provocar): las particiones afectadas se quedan con 1 sola ISR. Una escritura con
acks=allya no puede cumplir el mínimo de 2 y Kafka la rechaza con el errorNOT_ENOUGH_REPLICAS. Es decir,min.insync.replicases un compromiso explícito entre durabilidad y disponibilidad: conacks=allymin.insync.replicas=2garantizamos que ningún mensaje confirmado se pierde, pero a cambio el topic deja de aceptar escrituras en cuanto cae un broker. Conacks=1(oacks=0), en cambio, el productor seguiría escribiendo aun con un nodo caído, asumiendo el riesgo de pérdida.
¿Por qué con acks=all el productor de antes no ha fallado?
Porque los ejemplos de "Produciendo y consumiendo" no fijan acks y, en confluent-kafka, el valor por defecto del productor es acks=all solo cuando la idempotencia está activada; en una configuración mínima como la nuestra, el productor usa un acks que no exige el quórum completo de ISR. Si quieres reproducir el rechazo NOT_ENOUGH_REPLICAS, añade explícitamente 'acks': 'all' a la configuración del productor, deja un solo broker caído y vuelve a producir.
Finalmente, rearrancamos el broker que habíamos parado:
docker start iabd-kafka-1
kafka-server-start.sh ./config/server101.properties
Si esperamos unos segundos y volvemos a describir el topic, veremos que el broker recuperado se ha reincorporado a los ISR de todas sus particiones: ha copiado los mensajes que se perdió mientras estaba caído y vuelve a estar sincronizado. El clúster ha vuelto a su estado sano sin intervención manual.
Visualízalo en Kafka UI
Todo este proceso se ve muy bien en Kafka UI: en la vista del topic, la columna de réplicas y el indicador de under-replicated partitions cambian en tiempo real conforme paras y arrancas el broker.
Rebalance de consumidores¶
La caída de un broker no es el único evento al que un clúster debe adaptarse. También lo es la entrada o salida de consumidores de un grupo. Cuando esto ocurre, Kafka lanza un rebalance: redistribuye las particiones del topic entre los consumidores activos del grupo.
Podemos verlo con el clúster en marcha. Lanzamos dos consumidores del mismo grupo, cada uno en un terminal distinto, sobre el topic iabd-topic-3p2r (3 particiones):
docker exec -it iabd-kafka-1 /opt/kafka/bin/kafka-console-consumer.sh \
--topic iabd-topic-3p2r --group iabd-rebalance \
--bootstrap-server kafka-1:9092
kafka-console-consumer.sh --topic iabd-topic-3p2r \
--group iabd-rebalance --bootstrap-server iabd-virtualbox:9092
Con dos consumidores y tres particiones, Kafka asigna 2 particiones a uno y 1 al otro. Podemos comprobar el reparto con:
docker exec -it iabd-kafka-1 /opt/kafka/bin/kafka-consumer-groups.sh \
--describe --group iabd-rebalance --bootstrap-server kafka-1:9092
kafka-consumer-groups.sh --describe --group iabd-rebalance \
--bootstrap-server iabd-virtualbox:9092
En la salida, la columna CONSUMER-ID nos dice qué consumidor atiende cada partición. Si ahora paramos uno de los dos consumidores (Ctrl+C), se produce un rebalance: el consumidor que queda asume las 3 particiones. Y si arrancamos un tercero, el reparto vuelve a equilibrarse. Como vimos en la FAQ de la sesión anterior, desde Kafka 2.4 el Cooperative Sticky Assignor hace que estos rebalances sean incrementales: solo se reasignan las particiones que cambian de dueño, sin detener todo el grupo.
Más consumidores que particiones
Si lanzas un cuarto consumidor en este grupo (4 consumidores, 3 particiones), uno de ellos quedará ocioso: no recibirá ninguna partición. El paralelismo máximo de un grupo lo marca el número de particiones del topic, no el de consumidores.
Decisiones de rendimiento¶
Aunque podemos modificar la cantidad de particiones y el factor de replicación una vez creado el clúster, es mejor hacerlo de la manera correcta durante la creación ya que tienen un impacto directo en el rendimiento y durabilidad del sistema:
- si el número de particiones crece con el clúster ya creado, el orden de las claves no está garantizado.
- si se incrementa el factor de replicación durante el ciclo de vida de un topic, estaremos metiendo presión al clúster, que provocará un decremento inesperado del rendimiento. Cada partición puede manejar un rendimiento de unos pocos MB/s. Al añadir más particiones, obtendremos mejor paralelización y por tanto, mejor rendimiento. Además, podremos ejecutar más consumidores en un grupo. Pero el hecho de añadir más particiones tiene un coste: cada una supone más ficheros abiertos en los brokers, más metadatos que el controller de KRaft debe gestionar y rebalances más lentos.
Guía de rendimiento
Una propuesta es:
- Si nuestro clúster es pequeño (menos de 6 brokers), crear el doble de particiones que brokers.
- Si tenemos un clúster grande (más de 12 brokers), crear la misma cantidad de particiones que brokers.
- Ajustar el número de consumidores necesarios que necesitamos que se ejecuten en paralelo en los picos de rendimiento.
Independientemente de la decisión que tomemos, hay que realizar pruebas de rendimiento con diferentes configuraciones.
Respecto al factor de replicación, debería ser, al menos 2, siendo 3 la cantidad recomendada (es necesario tener al menos 3 brokers) y no sobrepasar de 4. Cuanto mayor sea el factor de replicación (RF):
- El sistema tendrá mejor tolerancia a fallos (se pueden caer RF-1 brokers)
- Pero tendremos mayor replicación (lo que implicará una mayor latencia si
acks=all) - Y también ocupará más espacio en disco (50% más si RF es 3 en vez de 2).
Respecto al clúster, se recomienda que un broker no contenga más de 2000-4000 particiones (entre todos los topics de ese broker). Con el modelo clásico de Zookeeper existía además un límite práctico de unas decenas de miles de particiones por clúster, porque la caída de un nodo obligaba a Zookeeper a reelegir el líder de cada partición afectada de forma secuencial. Con KRaft este cuello de botella desaparece: el controller mantiene los metadatos en memoria y propaga los cambios mediante el log replicado, lo que permite clústeres con millones de particiones y failovers mucho más rápidos. Aun así, un número desmesurado de particiones sigue teniendo coste (memoria, ficheros abiertos, tiempo de recuperación), por lo que conviene dimensionarlo con criterio.
Caso 3: De AEMET a S3 y MongoDB¶
En este caso de uso vamos a repetir el que hicimos en la sesión de Nifi pero utilizando Kafka como elemento de integración, desacoplando los productores de los consumidores.
La arquitectura del sistema sería la siguiente:
flowchart LR
AEMET([API el-tiempo.net])
Prod[Productor AEMET]
CBronze[Consumidor Bronze]
CSilver[Consumidor Silver<br/>+ Productor Gold]
Mongo[(MongoDB<br/>iabd.caso3)]
subgraph Kafka["Topics de Kafka"]
Bronze[(iabd-aemet-bronze)]
Silver[(iabd-aemet-silver)]
Gold[(iabd-aemet-gold)]
end
subgraph MinIO["S3 / MinIO — bucket raw-data"]
S3B[/bronze//]
S3S[/silver//]
end
AEMET -->|GET| Prod
Prod --> Bronze
Prod --> Silver
Bronze --> CBronze --> S3B
Silver --> CSilver
CSilver --> S3S
CSilver --> Mongo
CSilver -->|cada 10 mensajes| GoldPara este caso, usaremos el broker único (perfil kafka), porque no necesitamos el clúster del Caso 2, así como los contenedores de MinIO (S3). En cuanto a MongoDB, como no está en el docker-compose.yml, usaremos el clúster de MongoAtlas que hemos empleado durante el curso.
Así pues, los pasos a seguir son:
docker compose --profile kafka up -d
docker compose up -d minio minio-init
Suponemos arrancados Kafka (un solo broker en iabd-virtualbox:9092), MongoDB en local y credenciales de AWS S3 configuradas mediante aws configure.
Antes de empezar, instalamos las dependencias:
pip install confluent-kafka requests boto3 pymongo pandas
Productor de AEMET¶
Tras recuperar la petición REST que realizamos a la API de el-tiempo.net (que reexpone los datos de AEMET) vamos a:
- enviar su resultado a un topic que llamaremos
iabd-aemet-bronze. - generar un nuevo mensaje JSON más pequeño con la información que nos interesa, y enviar este nuevo mensaje a un topic que llamaremos
iabd-aemet-silver.
Así pues, primero creamos los topics:
Los comandos kafka-topics.sh están dentro del contenedor, por lo que usaremos docker exec:
docker exec -it --workdir /opt/kafka/bin iabd-kafka bash
Y dentro del contenedor:
./kafka-topics.sh --create --topic iabd-aemet-bronze \
--bootstrap-server kafka:9092
./kafka-topics.sh --create --topic iabd-aemet-silver \
--bootstrap-server kafka:9092
En este contenedor el broker está configurado con KAFKA_NUM_PARTITIONS: 3, así que los topics tendrán 3 particiones por defecto. Como solo hay un broker, el factor de replicación es 1.
kafka-topics.sh --create --topic iabd-aemet-bronze \
--bootstrap-server iabd-virtualbox:9092
kafka-topics.sh --create --topic iabd-aemet-silver \
--bootstrap-server iabd-virtualbox:9092
A continuación desarrollamos el productor, que hará uso de la librería requests para llamar a la API REST. Como la conexión al broker cambia según dónde estemos ejecutando el código, extraemos la lista de bootstrap servers a una variable:
Si ejecutamos el código desde el host (por ejemplo, VSCode local), usamos el puerto externo:
BOOTSTRAP_SERVERS = "localhost:9094"
Si lo ejecutamos desde el contenedor jupyter, usamos el hostname interno:
BOOTSTRAP_SERVERS = "kafka:9092"
BOOTSTRAP_SERVERS = "iabd-virtualbox:9092"
Veamos el productor:
from confluent_kafka import Producer
from json import dumps
from datetime import datetime
import time
import requests
BOOTSTRAP_SERVERS = "localhost:9094" # Cambiar según infraestructura
def delivery_report(err, msg):
if err is not None:
print(f"Error entregando mensaje: {err}")
else:
print(f"Entregado a {msg.topic()} [P:{msg.partition()} O:{msg.offset()}]")
producer = Producer({
"bootstrap.servers": BOOTSTRAP_SERVERS,
"client.id": "productor-aemet",
"acks": "all", # Esperamos confirmación del líder
"enable.idempotence": True, # Evita duplicados ante reintentos
})
url_aemet = "https://api.el-tiempo.net/json/v3/provincias/03/municipios/03065"
while True:
try:
r = requests.get(url_aemet, timeout=10)
r.raise_for_status()
resp_json = r.json()
except Exception as e:
print(f"Error consultando AEMET: {e}")
time.sleep(10)
continue
# 1) Mensaje BRONZE: la respuesta REST tal cual
producer.produce(
"iabd-aemet-bronze",
value=dumps(resp_json).encode("utf-8"),
callback=delivery_report,
)
# 2) Mensaje SILVER: extraemos los campos que nos interesan
datos_json = {
"fecha": datetime.now().isoformat(),
"ciudad": resp_json["municipio"]["NOMBRE"],
"temp": resp_json["temperatura_actual"],
"humedad": resp_json["humedad"],
}
producer.produce(
"iabd-aemet-silver",
value=dumps(datos_json).encode("utf-8"),
callback=delivery_report,
)
# poll(0) procesa los callbacks pendientes sin bloquear
producer.poll(0)
time.sleep(60)
poll(0) vs flush()
confluent-kafka mantiene una cola interna de mensajes pendientes y dispara los callbacks (delivery_report) cuando se confirma la entrega. Para que esos callbacks se ejecuten, hay que llamar periódicamente a producer.poll(0) (no bloquea) o a producer.flush() (bloquea hasta vaciar la cola). En productores de larga duración, conviene llamar a poll(0) en cada iteración y reservar flush() para el cierre.
Consumidor Bronze¶
En el consumidor del topic iabd-aemet-bronze vamos a recuperar las peticiones REST almacenadas en JSON y las persistiremos en S3 (en la máquina virtual) o en MinIO (en Docker), que es un almacén compatible con el protocolo S3.
En este caso, como el mensaje ya está en formato JSON y no queremos tratarlo, no hace falta deserializarlo ni volverlo a serializar.
En la pila Docker usamos MinIO sobre el bucket raw-data (creado por minio-init al arrancar el perfil spark). Las credenciales son minioadmin / minioadmin123 según el docker-compose.yml:
S3_ENDPOINT = "http://localhost:9000" # "http://minio:9000" desde contenedores
S3_KEY = "minioadmin"
S3_SECRET = "minioadmin123"
S3_BUCKET = "raw-data"
En la máquina virtual usamos S3 real, con las credenciales configuradas previamente mediante aws configure:
S3_BUCKET = "iabd-nifi"
El código Python del consumidor es:
from confluent_kafka import Consumer, KafkaError
from datetime import datetime
import boto3
BOOTSTRAP_SERVERS = "localhost:9094"
consumer = Consumer({
"bootstrap.servers": BOOTSTRAP_SERVERS,
"group.id": "iabd-caso3-bronze", # grupo propio para este consumidor
"auto.offset.reset": "earliest",
"enable.auto.commit": True,
})
consumer.subscribe(["iabd-aemet-bronze"])
# === Conexión con S3 / MinIO ===
# Versión Docker (MinIO):
s3r = boto3.resource(
"s3",
endpoint_url="http://localhost:9000",
aws_access_key_id="minioadmin",
aws_secret_access_key="minioadmin123",
region_name="us-east-1",
)
bucket = s3r.Bucket("raw-data")
# Versión Máquina virtual (S3 real):
# s3r = boto3.resource("s3", region_name="us-east-1")
# bucket = s3r.Bucket("iabd-nifi")
try:
while True:
m = consumer.poll(1.0)
if m is None:
continue
if m.error():
if m.error().code() == KafkaError._PARTITION_EOF:
continue
print(f"Error: {m.error()}")
continue
# Guardamos el JSON tal cual, dentro de la carpeta bronze/
nom_fichero = "bronze/" + datetime.now().isoformat() + ".json"
bucket.put_object(Key=nom_fichero, Body=m.value())
print(f"Guardado {nom_fichero} (P:{m.partition()} O:{m.offset()})")
finally:
consumer.close()
Datalake en s3a:// desde Spark
Aunque aquí usamos boto3 (cliente Python directo), recordad que en Spark accedemos al mismo bucket a través del conector s3a:// (ver sesión de Catálogo y conectividad). El bucket raw-data será la zona bronze del datalake y podrá leerse desde Spark con spark.read.json("s3a://raw-data/bronze/").
Consumidor Silver y Productor Gold¶
El siguiente paso es bastante más complejo. Ahora realizaremos los siguientes pasos:
- crearemos un consumidor con los mensajes de la cola silver
- y almacenamos los mensajes en S3
- además, el mismo mensaje lo insertaremos en MongoDB en la colección
caso3 - y cuando tengamos 10 mensajes crearemos uno nuevo con el cálculo de la temperatura y la humedad medias
- para finalmente producir dicho mensaje al topic
iabd-aemet-gold.
Así pues, primero creamos el topic gold:
docker exec -it --workdir /opt/kafka/bin iabd-kafka \
./kafka-topics.sh --create --topic iabd-aemet-gold \
--bootstrap-server kafka:9092
kafka-topics.sh --create --topic iabd-aemet-gold \
--bootstrap-server iabd-virtualbox:9092
Así pues, antes de empezar, colocamos las dependencias y la función para transformar un diccionario JSON con todo el contenido en String a diferentes tipos (float, ISODate, ...):
from confluent_kafka import Consumer, Producer, KafkaError
from datetime import datetime
from json import loads, dumps
from pymongo import MongoClient
import boto3
import pandas as pd
# === Configuración (ajustar según entorno) ===
BOOTSTRAP_SERVERS = "localhost:9094"
MONGO_URI = "mongodb+srv://usuario:password@host/basededatos"
S3_ENDPOINT = "http://localhost:9000"
S3_KEY = "minioadmin"
S3_SECRET = "minioadmin123"
S3_BUCKET = "raw-data"
# Convierte un diccionario JSON con todo el contenido en String a diferentes
# tipos (float, datetime, ...) usando object_hook al hacer json.loads()
def esquema_json(dct):
result = {}
if "fecha" in dct:
result["fecha"] = datetime.fromisoformat(dct["fecha"])
if "temp" in dct:
result["temp"] = float(dct["temp"])
if "humedad" in dct:
result["humedad"] = float(dct["humedad"])
if "ciudad" in dct:
result["ciudad"] = dct["ciudad"]
return result
A continuación definimos las conexiones necesarias para los pasos 1 (consumir Kafka en el topic silver), 2 (enviar a S3/MinIO), 3 (persistir en MongoDB) y 5 (producir Kafka en el topic gold):
# Paso 1 - Consumir Silver
consumer = Consumer({
"bootstrap.servers": BOOTSTRAP_SERVERS,
"group.id": "iabd-caso3-silver", # grupo propio, distinto del bronze
"auto.offset.reset": "earliest",
"enable.auto.commit": True,
})
consumer.subscribe(["iabd-aemet-silver"])
# Paso 2 - Conexión con S3 / MinIO
# (Versión Docker; en la VM basta con boto3.resource("s3", region_name="us-east-1"))
s3r = boto3.resource(
"s3",
endpoint_url=S3_ENDPOINT,
aws_access_key_id=S3_KEY,
aws_secret_access_key=S3_SECRET,
region_name="us-east-1",
)
bucket = s3r.Bucket(S3_BUCKET)
# Paso 3 - Conexión con MongoDB
clienteMongo = MongoClient(MONGO_URI)
colcaso3 = clienteMongo.iabd.caso3
# Paso 5 - Producir Gold
producer = Producer({
"bootstrap.servers": BOOTSTRAP_SERVERS,
"client.id": "productor-gold",
"acks": "all",
"enable.idempotence": True,
})
def delivery_report(err, msg):
if err is not None:
print(f"Error entregando a {msg.topic()}: {err}")
else:
print(f"Mensaje gold enviado [P:{msg.partition()} O:{msg.offset()}]")
Y para cada mensaje que consumimos, realizaremos los pasos 2 (enviar a S3), 3 (persistir en MongoDB), 4 (calcular los datos agregados) y 5 (producir en Kafka en gold):
mensajes = []
try:
while True:
m = consumer.poll(1.0)
if m is None:
continue
if m.error():
if m.error().code() == KafkaError._PARTITION_EOF:
continue
print(f"Error: {m.error()}")
continue
valor_bytes = m.value()
doc_json = loads(valor_bytes.decode("utf-8"), object_hook=esquema_json)
mensajes.append(doc_json)
# Paso 2 - Guardamos el mensaje en S3/MinIO
nom_fichero = "silver/" + datetime.now().isoformat() + ".json"
bucket.put_object(Key=nom_fichero, Body=valor_bytes)
# Paso 3 - Lo insertamos en MongoDB
# Importante: insert_one() añade el campo _id al dict; para no
# contaminar la lista que usaremos en el agregado, pasamos una copia.
colcaso3.insert_one(doc_json.copy())
# Paso 4 - Cada 10 mensajes calculamos el agregado
if len(mensajes) == 10:
pd_mensajes = pd.DataFrame(mensajes)
pd_agg = (
pd_mensajes
.groupby("ciudad")
.agg(fecha=("fecha", "max"),
temp=("temp", "mean"),
humedad=("humedad", "mean"))
.reset_index()
)
# Convertimos a list[dict] y dejamos las fechas como ISO para
# serializar una sola vez.
registros = pd_agg.to_dict(orient="records")
for r in registros:
if hasattr(r["fecha"], "isoformat"):
r["fecha"] = r["fecha"].isoformat()
mensaje_gold = dumps(registros).encode("utf-8")
print(f"Mensaje gold: {mensaje_gold.decode('utf-8')}")
# Paso 5 - Lo producimos al topic gold
producer.produce(
"iabd-aemet-gold",
value=mensaje_gold,
callback=delivery_report,
)
producer.poll(0)
# Vaciamos el buffer para el siguiente bloque de 10
mensajes = []
finally:
print("Cerrando consumidor y productor...")
producer.flush(timeout=10)
consumer.close()
clienteMongo.close()
Si en un terminal creamos un consumidor del topic iabd-aemet-gold:
docker exec -it --workdir /opt/kafka/bin iabd-kafka
./kafka-console-consumer.sh --topic iabd-aemet-gold \
--from-beginning --bootstrap-server kafka:9092
kafka-console-consumer.sh --topic iabd-aemet-gold \
--from-beginning --bootstrap-server iabd-virtualbox:9092
Veremos que los mensajes que llegan son similares a:
[{"ciudad": "Elche/Elx", "fecha": "2026-05-19T14:32:18.345231", "temp": 20.8, "humedad": 50.0}]
Caso 4: Ahora con Nifi¶
Vamos a repetir el flujo de datos que acabamos de crear en el caso anterior, pero implementándolos mediante Nifi de forma similar al caso 7 de la segunda sesión de Nifi.
Configuración de procesadores de Nifi
En este apartado hemos obviado la configuración de todos los procesadores vistos en el caso 7 de Nifi, ya que podemos copiar y pegarlos dentro de nuevos grupos de procesadores y evitarnos tener que volver a configurarlos.
De REST a Kafka¶
Sobre un grupo de procesadores que hemos llamado caso4kafka_producer_bronze_silver, vamos a utilizar el procesador InvokeHTTP, mediante el cual hacemos la petición GET a la URL https://api.el-tiempo.net/json/v3/provincias/03/municipios/03065.
De este procesador, por un lado vamos a conectar directamente con PublishKafka_2_6 para enviar directamente los datos a Kafka al topic, donde además del topic iabd-aemet-bronze, indicaremos que no utilizaremos transacciones (Use Transactions: false), así como que intente garantizar la entrega (Delivery Guarantee: Best Effort):
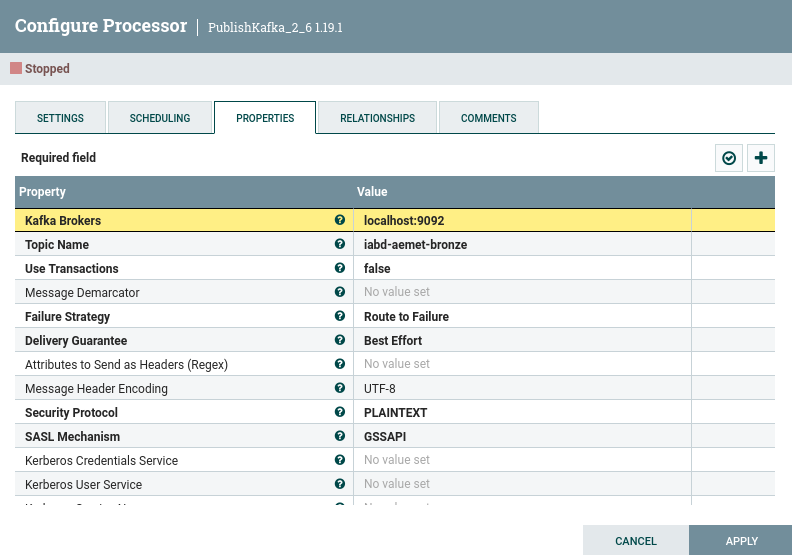
Para el resto de lógica, igual que en la sesión de Nifi, utilizamos EvaluateJSONPath para recoger la ciudad, la temperatura y la humedad, y por último conectamos con AttributesToJSON para generar el JSON que finalmente enviaremos a Kafka.
Ahora, como sí que tenemos un formato más concreto, vamos a utilizar PublishKafkaRecord_2_6 para utilizar un conjunto de registros.
Primero, conectamos todos los procesadores:
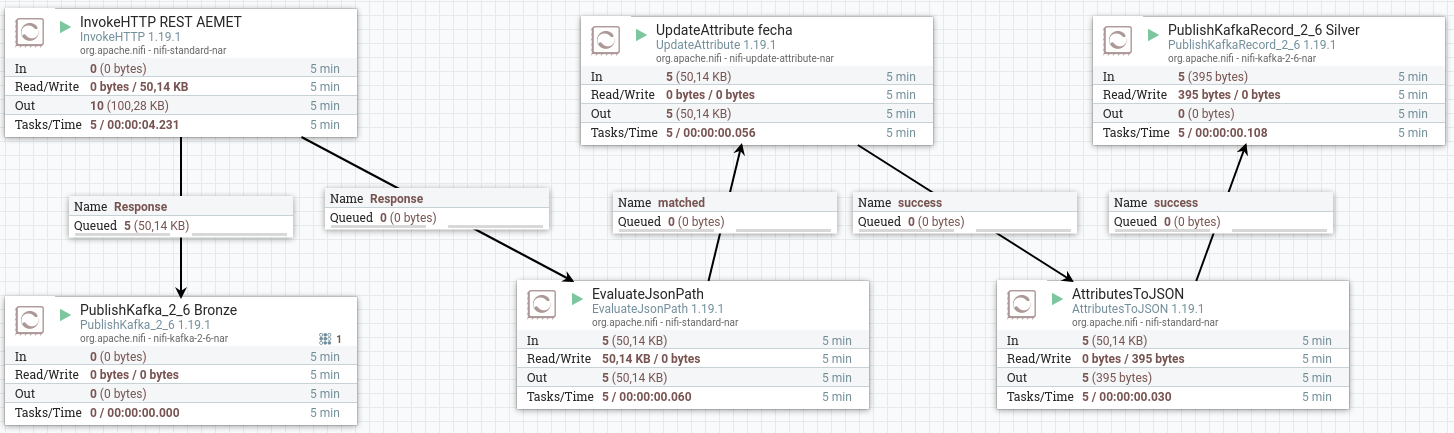
Y configuramos el último procesador con el topic iabd-aemet-silver, pero indicando que vamos a leer tanto como escribir en formato JSON:
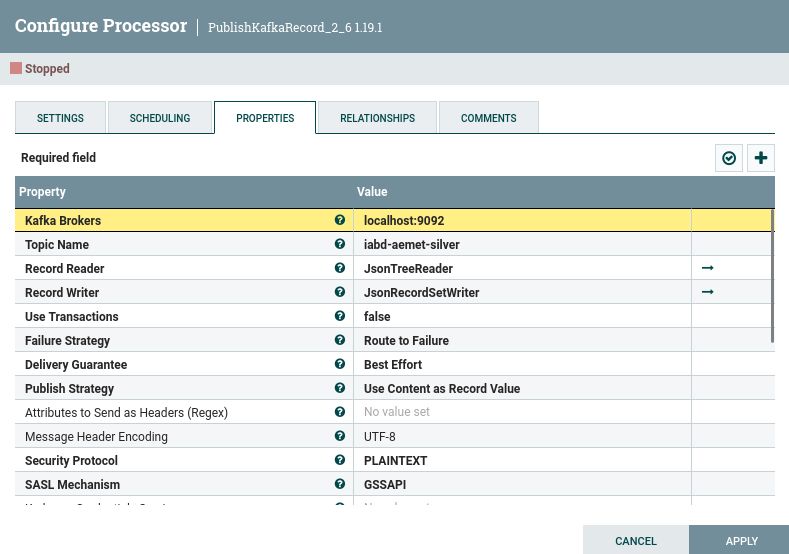
De Kafka a S3¶
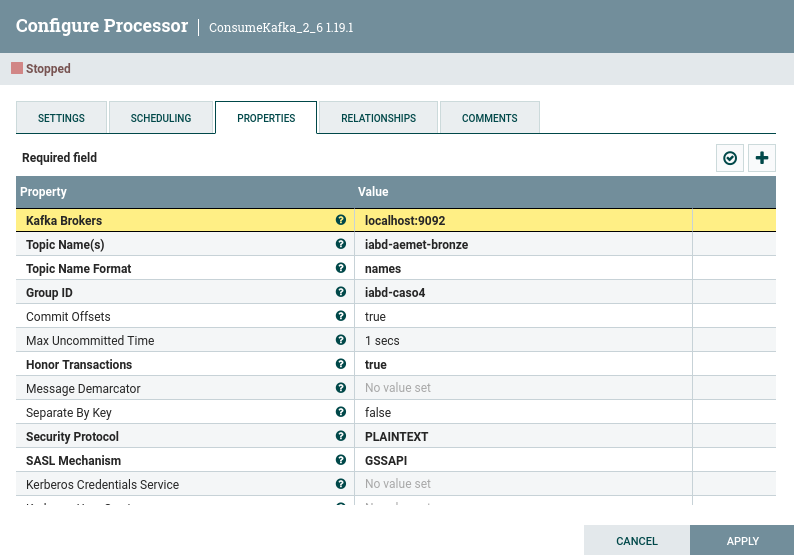
Nos vamos a centrar en recuperar los mensajes del topic iabd-aemet-silver y colocarlos en S3, mediante un grupo de procesadores que llamaremos caso4kafka_consumer_bronze que contendrá un flujo similar a:

Y en concreto en el consumidor, hemos de indicar tanto el topic como el grupo de consumidores (Group ID) a iabd-caso4:
Kafka Connect¶
Si hacerlo con Nifi ya es un avance respecto a tener que codificarlo con Python, ¿qué dirías si Kafka ofreciera una serie de conectores ya programados para las operaciones más comunes?
Kafka Connect permite importar y exportar datos desde/hacia Kafka, facilitando la integración con sistemas existentes mediante alguno del centenar de conectores disponibles. En lugar de escribir un productor o un consumidor, declaramos un conector con un fichero de configuración y Kafka Connect se encarga del resto: paralelización, reintentos, control de offsets y tolerancia a fallos.
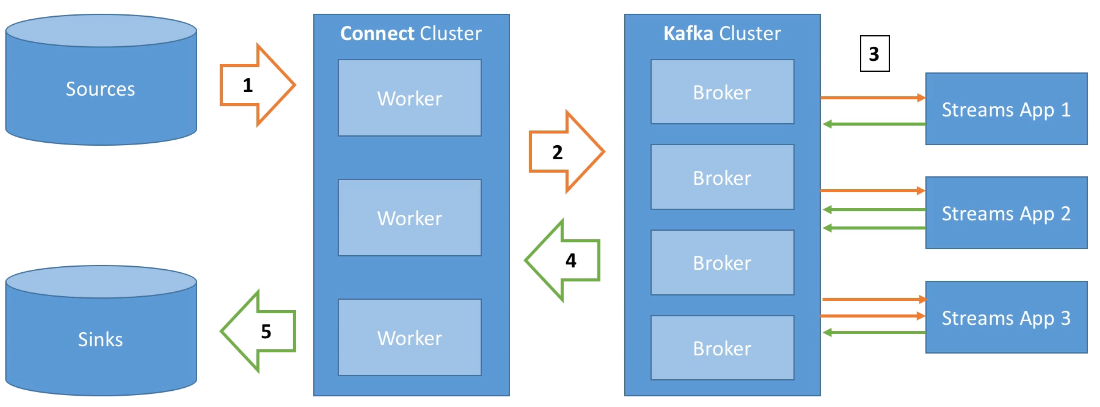
Los elementos que forman Kafka Connect son:
- Conectores fuente (source), para obtener datos desde las fuentes de datos (la E de ETL).
- Conectores destino (sink), para publicar los datos en almacenes de datos externos (la L de ETL).
Entre ambos, Kafka actúa como buffer desacoplado: el conector source escribe en un topic y el conector sink lee de él, sin que ninguno conozca al otro.
Standalone vs Distributed
Kafka Connect puede ejecutarse en dos modos:
- Standalone: un único proceso (worker). El estado de los offsets se guarda en un fichero local (
offset.storage.file.filename). Es sencillo, pero no escala ni tolera fallos. Se arranca conconnect-standalone.shpasándole los conectores como ficheros.properties. - Distributed: uno o varios workers coordinados que comparten el mismo
group.id. El estado (configuración, offsets y estado de los conectores) se guarda en topics internos de Kafka (connect-configs,connect-offsets,connect-status), de modo que si un worker cae, otro retoma su trabajo. Los conectores se gestionan vía API REST con documentos JSON.
En la máquina virtual usaremos el modo standalone por simplicidad; en Docker usaremos el modo distributed, que es el que se utiliza en entornos reales.
Hola Kafka Connect¶
Vamos a realizar un ejemplo sencillo: leer los datos de una tabla de una base de datos relacional e introducirlos automáticamente en un topic de Kafka.
Utilizaremos la base de datos retail_db que ya hemos empleado en otras sesiones y cargaremos en Kafka los datos de la tabla categories:
En el stack del curso, retail_db se encuentra en el contenedor iabd-mysql-datos (perfil datos). Podemos consultar la estructura de la tabla con:
docker exec -it iabd-mysql-datos mysql -uiabd -piabd retail_db -e "describe categories;"
# +------------------------+-------------+------+-----+---------+----------------+
# | Field | Type | Null | Key | Default | Extra |
# +------------------------+-------------+------+-----+---------+----------------+
# | category_id | int | NO | PRI | NULL | auto_increment |
# | category_department_id | int | NO | | NULL | |
# | category_name | varchar(45) | NO | | NULL | |
# +------------------------+-------------+------+-----+---------+----------------+
mysql> describe categories;
# +------------------------+-------------+------+-----+---------+----------------+
# | Field | Type | Null | Key | Default | Extra |
# +------------------------+-------------+------+-----+---------+----------------+
# | category_id | int(11) | NO | PRI | NULL | auto_increment |
# | category_department_id | int(11) | NO | | NULL | |
# | category_name | varchar(45) | NO | | NULL | |
# +------------------------+-------------+------+-----+---------+----------------+
Instalando conectores¶
Los conectores no forman parte del núcleo de Kafka. La distribución de Kafka solo incluye unos pocos conectores de ejemplo (FileStreamSource, FileStreamSink y MirrorSourceConnector); el resto se añaden como plugins los cuales hemos de instalar manualmente. Esto es así porque cada conector tiene sus propias dependencias, y no es posible incluirlas todas en la distribución oficial.
Para nuestro primer ejemplo necesitamos un conector JDBC, que sabe leer de cualquier base de datos relacional. Existen dos opciones habituales:
confluentinc/kafka-connect-jdbc: el más conocido, pero se distribuye bajo la Confluent Community License, no es Apache 2.0. Permite uso gratuito, pero con restricciones (por ejemplo, no se puede ofrecer como servicio gestionado a terceros).Aiven jdbc-connector-for-apache-kafka: funcionalmente equivalente para source y sink, con licencia Apache 2.0 pura. Es el que usaremos, por coherencia con el resto del stack del curso.
La única diferencia práctica para nosotros es el nombre de la clase del conector: io.aiven.connect.jdbc.JdbcSourceConnector en lugar de io.confluent.connect.jdbc.JdbcSourceConnector.
Además, el conector JDBC necesita el driver JDBC de la base de datos, que tampoco viene incluido. Como vamos a conectar con MySQL, necesitaremos también el mysql-connector-j. En nuestro caso, tanto en el stack de Docker como en la máquina virtual, ya tenemos los plugins descargados y configurados.
En el stack del curso, Kafka Connect se ejecuta en el contenedor iabd-kafka-connect y los plugins se cargan desde una carpeta del host montada como volumen:
kafka-connect:
image: apache/kafka:latest
container_name: iabd-kafka-connect
hostname: kafka-connect
profiles: ["kafka"]
depends_on:
kafka:
condition: service_healthy
ports:
- '8083:8083'
command: ["/opt/kafka/bin/connect-distributed.sh",
"/opt/kafka/config/connect-distributed.properties"]
volumes:
- ./kafka/connect-distributed.properties:/opt/kafka/config/connect-distributed.properties:ro
- ./kafka/connect-plugins:/opt/kafka/plugins
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8083/ || exit 1"]
interval: 15s
timeout: 10s
retries: 10
networks:
- spark-net
El fichero connect-distributed.properties (en ./kafka/) configura el worker:
bootstrap.servers=kafka:9092
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# Con schemas.enable=false los mensajes solo llevan el payload (mas legibles).
# Ponlo a true si un conector sink necesita conocer el schema.
key.converter.schemas.enable=false
value.converter.schemas.enable=false
config.storage.topic=connect-configs
offset.storage.topic=connect-offsets
status.storage.topic=connect-status
# Factor de replicacion 1 porque en el perfil "kafka" solo hay un broker.
config.storage.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
listeners=http://0.0.0.0:8083
rest.advertised.host.name=kafka-connect
rest.port=8083
plugin.path=/opt/kafka/plugins
Como hemos comentado, los conectores se cargan como plugins y hay que indicarle a Kafka Connect dónde encontrarlos mediante la propiedad plugin.path. En nuestro caso, los plugins se montan desde la carpeta ./kafka/connect-plugins/ del proyecto, así que esa es la ruta que indicamos en plugin.path. Si comprobamos el contenido de ./kafka/connect-plugins/, veremos que ya tenemos tanto el conector JDBC de Aiven como el conector S3 preparados:
kafka/connect-plugins/
├── jdbc-connector-for-apache-kafka-6.10.0/
│ ├── jdbc-connector-for-apache-kafka-6.10.0.jar
│ └── mysql-connector-j-8.0.33.jar
│ └── ... (jars del conector JDBC)
└── s3-sink-connector-for-apache-kafka-3.4.2/
└── ... (jars del conector S3)
...
Una vez preparados los plugins, levantamos Kafka Connect junto con el broker y la base de datos. Como kafka-connect está en el perfil kafka y retail_db en el perfil datos, hay que arrancar ambos perfiles a la ve:
docker compose --profile kafka --profile datos up -d
Cuando el contenedor arranca, Kafka Connect escanea plugin.path y registra los conectores encontrados. Podemos comprobar que el conector JDBC se ha cargado correctamente:
curl -s http://localhost:8083/connector-plugins
# [{"class":"io.aiven.connect.jdbc.JdbcSinkConnector","type":"sink","version":"6.10.0-SNAPSHOT"},
# {"class":"io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector","type":"sink","version":"3.4.2"},
# {"class":"io.aiven.connect.jdbc.JdbcSourceConnector","type":"source","version":"6.10.0-SNAPSHOT"},
# {"class":"org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type":"source","version":"4.0.0"},
# {"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"4.0.0"},
# {"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"4.0.0"}]
Cuando ejecutemos Kafka Connect en modo standalone, le pasaremos un fichero de configuración del worker. Partimos de config/connect-standalone.properties, que ya viene incluido:
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
Los conectores se cargan como plugins. Debemos indicarle a Kafka dónde se encuentran añadiendo al final del fichero la ruta de la carpeta de plugins (ajusta la ruta a tu versión de Kafka):
plugin.path=$KAFKA_HOME/plugins
Extrayendo datos¶
Ya tenemos el conector instalado. Ahora vamos a definir una instancia de conector que lea de la tabla categories. Usamos un conector source JDBC en modo incrementing: el conector recuerda el último category_id procesado y solo trae las filas nuevas en cada sondeo.
En modo distributed los conectores se crean mediante la API REST enviando un documento JSON. Para ello, hemos de indicar toda la configuración en un fichero, el cual ya tenemos colocado dentro la carpeta kafka:
{
"name": "mysql-categories-source",
"config": {
"connector.class": "io.aiven.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url": "jdbc:mysql://mysql-datos:3306/retail_db",
"connection.user": "iabd",
"connection.password": "iabd",
"table.whitelist": "categories",
"mode": "incrementing",
"incrementing.column.name": "category_id",
"topic.prefix": "iabd-retail_db-",
"poll.interval.ms": "5000"
}
}
Hostname interno, no localhost
Como Kafka Connect se ejecuta dentro de la red de Docker, en connection.url usamos el hostname del contenedor de la base de datos (mysql-datos, puerto interno 3306), no localhost. El localhost:3307 solo es válido desde la máquina anfitriona.
Para registrar el conector hacemos una petición POST al endpoint /connectors (suponiendo que estamos situados sobre la carpeta kafka que contiene el fichero mysql-categories-source.json):
curl -s -X POST -H "Content-Type: application/json" --data @mysql-categories-source.json http://localhost:8083/connectors
# {"name":"mysql-categories-source","config":
# {"connector.class":"io.aiven.connect.jdbc.JdbcSourceConnector",
# "tasks.max":"1",
# "connection.url":"jdbc:mysql://mysql-datos:3306/retail_db",
# "connection.user":"iabd","connection.password":"iabd",
# "table.whitelist":"categories","mode":"incrementing",
# "incrementing.column.name":"category_id",
# "topic.prefix":"iabd-retail_db-","poll.interval.ms":"5000","name":"mysql-categories-source"},
# "tasks":[],"type":"source"}
Y comprobamos que el conector está en marcha (su estado y el de sus tasks deben ser RUNNING):
curl -s http://localhost:8083/connectors/mysql-categories-source/status
# {"name":"mysql-categories-source",
# "connector":{"state":"RUNNING","worker_id":"kafka-connect:8083"},
# "tasks":[{"id":0,"state":"RUNNING","worker_id":"kafka-connect:8083"}],
# "type":"source"}
En modo standalone el conector se define en un fichero .properties que pasaremos como parámetro al arrancar Kafka Connect. Lo colocamos en la carpeta config:
name=mysql-source
connector.class=io.aiven.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost/retail_db
connection.user=iabd
connection.password=iabd
table.whitelist=categories
mode=incrementing
incrementing.column.name=category_id
topic.prefix=iabd-retail_db-
Y arrancamos Kafka Connect con connect-standalone.sh, pasándole el fichero del worker y el del conector:
connect-standalone.sh config/connect-standalone.properties \
config/mysql-source-connector.properties
Si tuviéramos más conectores, los añadiríamos como parámetros adicionales:
connect-standalone.sh config/connect-standalone.properties \
config/conector1.properties [config/conector2.properties ...]
El conector mapea la tabla categories al topic iabd-retail_db-categories (topic.prefix + nombre de la tabla). Si ahora arrancamos un consumidor sobre ese topic:
docker exec -it --workdir /opt/kafka/bin iabd-kafka bash
./kafka-console-consumer.sh --topic iabd-retail_db-categories \
--from-beginning --bootstrap-server kafka:9092
kafka-console-consumer.sh --topic iabd-retail_db-categories \
--from-beginning --bootstrap-server localhost:9092
Veremos que aparecen todos los datos que teníamos en la tabla, en formato JSON. Con value.converter.schemas.enable=false el mensaje contiene únicamente el payload:
{"category_id":1,"category_department_id":2,"category_name":"Football"}
{"category_id":2,"category_department_id":2,"category_name":"Soccer"}
...
Mensajes con schema
Si en el worker dejamos value.converter.schemas.enable=true, cada mensaje incluye además un bloque schema que describe los tipos de cada campo. Es más verboso, pero algunos conectores sink lo necesitan para saber cómo escribir los datos en su destino.
Autoevaluación
Vamos a dejar el consumidor y Kafka Connect corriendo. ¿Qué sucederá si inserto un nuevo registro en la tabla categories?
Como el conector está en modo incrementing, en el siguiente sondeo (cada 5 segundos) detectará la fila nueva por su category_id y la publicará automáticamente en el topic, sin que tengamos que hacer nada.
Cargando datos en S3¶
Hasta ahora hemos cubierto la E de ETL (extraer de MySQL a Kafka). Para cerrar el ciclo con la L (cargar en un destino), añadiremos un conector sink que escriba los mensajes del topic en MinIO, el almacenamiento S3 que ya usamos en las sesiones de Spark.
El sink necesita que MinIO esté arrancado
El conector sink escribe en MinIO, que pertenece al perfil spark. Para este ejemplo completo (JDBC source + S3 sink) hay que levantar los tres perfiles:
docker compose --profile kafka --profile datos up -d
docker compose up -d minio
Del mismo modo que el conector JDBC, Kafka Connect no incluye ningún conector sink de S3 preinstalado por defecto, pero en nuestro stack de Docker ya tenemos el conector de almacenamiento en la nube de Aiven, que incluye un sink de S3 listo para usar.
MinIO es compatible con S3
MinIO implementa el mismo protocolo que Amazon S3. El conector S3 de Aiven sirve igual para MinIO: basta con apuntarlo al endpoint de nuestro contenedor mediante la propiedad aws.s3.endpoint, en lugar de dejar que use el de AWS real.
El conector S3 de Aiven agrupa los mensajes y los vuelca a MinIO en ficheros con formato JSON Lines (jsonl): un mensaje por línea. Cada cierto intervalo (60 segundos por defecto) el conector crea un nuevo fichero con los mensajes acumulados en ese periodo. De este modo, evitamos escribir un fichero por mensaje, lo que sería poco eficiente y generaría una gran cantidad de pequeños ficheros.
Así pues, para configurar el conector crearemos el fichero categories-s3-sink.json donde necesitamos indicarle el topic de origen (iabd-retail_db-categories), el bucket de destino (raw-data) y el endpoint de MinIO (http://minio:9000), junto con las credenciales de acceso. El resto de parámetros son opcionales, pero los dejaremos para que los ficheros resultantes sean legibles y estén organizados bajo un prefijo concreto:
{
"name": "categories-s3-sink",
"config": {
"connector.class": "io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector",
"tasks.max": "1",
"topics": "iabd-retail_db-categories",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"aws.s3.bucket.name": "raw-data",
"aws.s3.endpoint": "http://minio:9000",
"aws.s3.region": "us-east-1",
"aws.access.key.id": "minioadmin",
"aws.secret.access.key": "minioadmin123",
"format.output.type": "jsonl",
"file.name.prefix": "kafka-connect/categories/",
"file.compression.type": "none"
}
}
Conviene destacar algunos parámetros:
format.output.type": "jsonl"hace que cada fichero sea legible (un JSON por línea).file.compression.type": "none"evitamos que se comprima en.gz, para poder inspeccionarlo fácilmente.
Del mismo modo que con el conector JDBC, debemos registrar el conector mediante el API REST. Así pues, si nos situamos sobre la carpeta kafka que contiene el fichero categories-s3-sink.json, hacemos:
curl -s -X POST -H "Content-Type: application/json" --data @categories-s3-sink.json http://localhost:8083/connectors
# {"name":"categories-s3-sink",
# "config": {
# "connector.class":"io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector",
# "tasks.max":"1","topics":"iabd-retail_db-categories",
# "key.converter":"org.apache.kafka.connect.storage.StringConverter",
# "value.converter":"org.apache.kafka.connect.json.JsonConverter",
# "value.converter.schemas.enable":"false",
# "aws.s3.bucket.name":"raw-data","aws.s3.endpoint":"http://minio:9000",
# "aws.s3.region":"us-east-1",
# "aws.access.key.id":"minioadmin","aws.secret.access.key":"minioadmin123",
# "format.output.type":"jsonl",
# "file.name.prefix":"kafka-connect/categories/",
# "file.compression.type":"none",
# "name":"categories-s3-sink"},
# "tasks":[],"type":"sink"}
Comprobando el resultado¶
El conector no escribe un fichero por mensaje. Va acumulando los mensajes y los vuelca de golpe cada cierto intervalo (offset.flush.interval.ms, 60 segundos por defecto). Por eso, al cabo de un minuto, veremos aparecer en el bucket raw-data uno o varios ficheros bajo el prefijo kafka-connect/categories/.
Podemos consultarlo desde la consola web de MinIO (http://localhost:9001) o por línea de comandos:
docker exec -it iabd-minio mc alias set local http://localhost:9000 minioadmin minioadmin123
docker exec -it iabd-minio mc ls --recursive local/raw-data/kafka-connect/
Y ver el contenido de uno de los ficheros:
docker exec -it iabd-minio mc cat local/raw-data/kafka-connect/categories/iabd-retail_db-categories-0-0.jsonl
# {"category_id":1,"category_department_id":2,"category_name":"Football"}
# {"category_id":2,"category_department_id":2,"category_name":"Soccer"}
...
Para ver el flujo en movimiento
La tabla categories es estática: una vez cargada, no llegan filas nuevas, así que el sink hará un único volcado y se quedará quieto. Si quieres ver el conector trabajando de forma continua en clase, inserta un nuevo registro en la tabla categories.
Con esto tenemos un flujo ETL completo y declarativo: el conector source lee de MySQL y publica en un topic, y el conector sink consume ese topic y persiste los datos en MinIO. Kafka desacopla ambos extremos, y nosotros solo hemos escrito dos ficheros JSON de configuración.
REST API¶
Como Kafka Connect está diseñado como un servicio que debe ejecutarse de forma continua, ofrece una API REST para gestionar los conectores sin reiniciar el worker. Por defecto escucha en el puerto 8083.
| Operación | Petición |
|---|---|
| Información del worker | GET http://localhost:8083/ |
| Plugins instalados | GET http://localhost:8083/connector-plugins |
| Listar conectores | GET http://localhost:8083/connectors |
| Crear un conector | POST http://localhost:8083/connectors (cuerpo JSON) |
| Estado de un conector | GET http://localhost:8083/connectors/{nombre}/status |
| Configuración de un conector | GET http://localhost:8083/connectors/{nombre}/config |
| Reiniciar un conector | POST http://localhost:8083/connectors/{nombre}/restart |
| Pausar / reanudar | PUT .../{nombre}/pause · PUT .../{nombre}/resume |
| Borrar un conector | DELETE http://localhost:8083/connectors/{nombre} |
Por ejemplo, para obtener la versión que se está ejecutando:
curl -s http://localhost:8083/ | python3 -m json.tool
{
"version": "4.1.1",
"commit": "...",
"kafka_cluster_id": "..."
}
Y para listar los conectores activos:
curl -s http://localhost:8083/connectors
["mysql-categories-source", "categories-s3-sink"]
En modo standalone la API REST también está disponible (puerto 8083), aunque los conectores se hayan definido por fichero. Por ejemplo, para consultar la versión accederíamos a http://localhost:8083/ y para listar los conectores a http://localhost:8083/connectors.
La diferencia es que, en standalone, si creamos un conector vía REST no sobrevive a un reinicio del worker (el estado no se guarda en topics). En modo distributed, sí.
Más información en la documentación oficial de la REST API.
¿Por qué un conector aparece como FAILED?
Si tras crear un conector su estado es FAILED, la API REST nos da el motivo. Consulta el campo trace de la respuesta de /status:
curl -s http://localhost:8083/connectors/mysql-categories-source/status | python3 -m json.tool
Los errores más habituales son:
Connector class ... could not be found: el plugin no está enplugin.path, o el nombre de la clase está mal escrito. Revisa que la carpeta del conector esté dentro deconnect-plugins/y comprueba conGET /connector-pluginsque se ha cargado.No suitable driver found: el conector JDBC se ha cargado, pero falta el driver de la base de datos.Communications link failure/Connection refused: elconnection.urlno es accesible. En Docker, comprueba que usas el hostname del contenedor (mysql-datos) y nolocalhost, y que ambos contenedores están en la misma red.
Más Kafka Connect
En este apartado solo hemos visto una introducción. Quedan fuera aspectos como el clúster de Kafka Connect (varios workers con el mismo group.id), las transformaciones de un solo mensaje (Single Message Transforms, SMT) para modificar los datos al vuelo, o el uso de un Schema Registry con formatos como Avro.
Kafka Streams
Kafka Streams es la tercera pata del ecosistema de Kafka y permite procesar y transformar datos dentro de Kafka. Una vez que los datos están en Kafka como eventos, podemos procesarlos en nuestras aplicaciones cliente mediante Kafka Streams y sus librerías en Java/Scala (requiere una JVM).
En nuestro caso, realizaremos un procesamiento similar mediante Spark Streaming, que permite operaciones con estado, agregaciones, funciones ventana, joins y procesamiento de eventos basado en el tiempo.
Kafka y el Big Data¶
El siguiente gráfico muestra cómo Kafka está enfocado principalmente para el tratamiento en streaming, aunque con los conectores de Kafka Connect da soporte para el procesamiento batch:
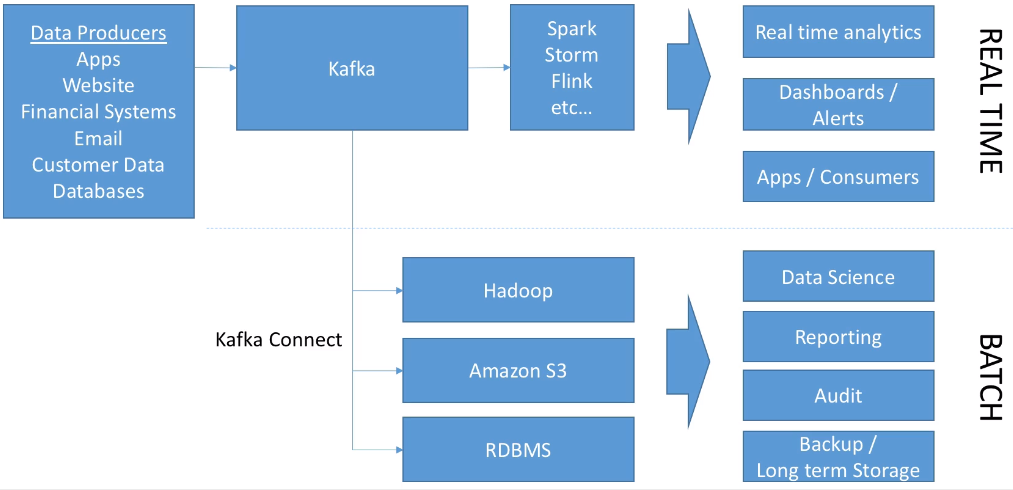
Si echamos la vista atrás y repasamos la arquitectura Kappa de Big Data podemos identificar que las diferentes fuentes de los datos se sustituyen por colas de Kafka permitiendo unir tanto la ingesta batch como en streaming, lo que facilita añadir tanto nuevas fuentes de datos como destinos, pudiendo realizar transformaciones en tiempo real o lanzar procesos más pesados para almacenar el histórico de los datos.
Elasticsearch y Twitter
En la edición de 21/22, en estas sesiones, realizamos diferentes casos de uso con Elasticsearch y Twitter.
Este curso no hemos visto Elasticsearch, y además, el API de Twitter ha dejado de ser gratuita. Si tienes curiosidad, puedes consultar dichos casos de uso en los apuntes de dicho curso.
FAQ¶
Igual que en la sesión anterior, recogemos algunas de las preguntas habituales en entrevistas de trabajo, esta vez centradas en los conceptos de clúster e integración vistos en esta sesión.
¿Cuál es la diferencia entre Replicas e Isr al describir un topic?
Replicas es la lista de brokers donde debería existir una réplica de la partición: se fija al crear el topic (según el factor de replicación) y no cambia salvo que se reasignen particiones manualmente. Isr (in-sync replicas) es el subconjunto de esas réplicas que están realmente al día con el líder.
Cuando un broker se cae o se queda rezagado, su réplica sale del Isr pero sigue figurando en Replicas. Si el broker vuelve y copia los mensajes pendientes, se reincorpora al Isr. Por eso, una partición under-replicated (con menos Isr que Replicas) es una señal de alerta: el topic sigue funcionando, pero ha perdido parte de su tolerancia a fallos.
¿Qué es min.insync.replicas y cómo interactúa con acks=all?
min.insync.replicas define el número mínimo de réplicas sincronizadas (ISR) que deben confirmar una escritura para considerarla correcta. Solo tiene efecto cuando el productor usa acks=all.
La combinación habitual en producción es factor de replicación 3 con min.insync.replicas=2 y acks=all: así una escritura confirmada vive al menos en 2 brokers, y el clúster tolera la caída de 1 nodo sin dejar de aceptar escrituras. Si min.insync.replicas igualara al factor de replicación, la caída de un solo broker bloquearía las escrituras con el error NOT_ENOUGH_REPLICAS. Es, en el fondo, el ajuste explícito del compromiso entre durabilidad y disponibilidad.
¿Cómo se elige el nuevo líder de una partición cuando cae su broker?
Cuando el broker que aloja la réplica líder se cae, el controller del clúster (el controller de KRaft en Kafka 4.x, o Zookeeper en versiones antiguas) promueve a líder a una de las réplicas que siguen en el Isr. Como esa réplica estaba sincronizada, no se pierde ningún mensaje confirmado. Cuando el broker caído vuelve, copia los mensajes que se perdió y se reincorpora al Isr, tal y como comprobamos en el Caso 2.
¿Por qué un clúster de Kafka recomienda un número impar de nodos?
Porque la coordinación del clúster se basa en un quórum por mayoría. Tanto el quórum de controllers de KRaft como, en su día, el ensamblado de Zookeeper, necesitan que más de la mitad de los miembros estén vivos para tomar decisiones. Con 3 nodos se tolera la caída de 1; con 5, la de 2.
Un número par no aporta tolerancia extra y sí más riesgo: 4 nodos toleran la caída de 1 (igual que 3) pero tienen más superficie de fallo. Por eso se eligen siempre cantidades impares (3, 5, 7).
¿Qué es Kafka Connect y qué ventaja aporta frente a escribir un productor/consumidor a mano?
Kafka Connect es un framework —y un servicio— para integrar Kafka con sistemas externos mediante conectores declarativos, sin escribir código. Un conector source lleva datos de un sistema externo a Kafka (la E de un ETL); un conector sink lleva datos de Kafka a un sistema externo (la L).
La ventaja no es solo ahorrarse el código: Kafka Connect resuelve de serie la gestión de offsets, los reintentos, el paralelismo mediante tasks, la tolerancia a fallos y el escalado horizontal. Reescribir todo eso de forma robusta en un script propio es costoso y propenso a errores. Se reserva el código a medida para la lógica de negocio que ningún conector existente cubre.
¿Qué diferencia hay entre el modo standalone y el modo distributed de Kafka Connect?
En modo standalone el worker se ejecuta en un único proceso y la configuración de los conectores y sus offsets se guardan en ficheros locales. Es sencillo, pero no tiene tolerancia a fallos ni escalado: si el proceso muere, la ingesta se detiene.
En modo distributed se ejecutan varios workers con el mismo group.id, formando un clúster. La configuración, los offsets y el estado de los conectores se guardan en topics internos de Kafka (connect-configs, connect-offsets, connect-status), de modo que cualquier worker puede retomar el trabajo de otro que falle. Los conectores se gestionan por la API REST, no por fichero. Es el modo recomendado para producción y el que usamos en el stack Docker del curso.
¿Por qué los conectores no vienen incluidos en Kafka y hay que instalarlos como plugins?
Porque cada conector tiene sus propias dependencias (drivers JDBC, SDKs de servicios cloud, librerías de cada base de datos...) y empaquetarlas todas en la distribución oficial la haría enorme y llena de conflictos de versiones. Kafka solo incluye unos conectores de ejemplo (FileStream*, MirrorMaker); el resto se añaden colocando sus JARs en una carpeta declarada en plugin.path. Al arrancar, el worker escanea esa ruta y registra lo que encuentra. Esto mantiene el núcleo ligero y permite elegir exactamente los conectores —y las versiones— que cada despliegue necesita.
¿Qué es el patrón CDC (Change Data Capture) y qué relación tiene con Kafka?
CDC es la técnica de capturar los cambios (inserciones, actualizaciones, borrados) que ocurren en una base de datos y emitirlos como un flujo de eventos. La forma robusta de hacerlo es leer el log de transacciones de la base de datos (el binlog de MySQL, el WAL de PostgreSQL), de modo que se capturan todos los cambios sin sondear ni añadir carga de consultas.
En el ecosistema Kafka, herramientas como Debezium son conectores source de Kafka Connect que hacen exactamente esto: publican cada cambio de la base de datos como un evento en un topic. La ventaja frente al modo incrementing que usamos en esta sesión es que el modo incrementing solo detecta filas nuevas mediante una columna creciente, mientras que CDC captura también actualizaciones y borrados, y lo hace casi en tiempo real.
¿Qué papel juega Kafka en una arquitectura de Big Data como la Kappa?
En la arquitectura Kappa, Kafka actúa como la columna vertebral del sistema: todas las fuentes de datos escriben en topics, y todos los consumidores (procesamiento en tiempo real, carga del histórico, analítica) leen de ellos. Como los mensajes se retienen un tiempo configurable y no se borran al consumirse, un mismo flujo puede alimentar a la vez un procesamiento streaming y un proceso batch que reprocesa el histórico.
Esto elimina la duplicidad de la arquitectura Lambda (que mantenía una capa batch y una streaming separadas): con Kafka como única fuente de verdad, añadir una nueva fuente o un nuevo destino es conectar un productor o un consumidor más, sin tocar el resto del sistema.
Referencias¶
- Apache Kafka Series - Learn Apache Kafka for Beginners
- Serie de artículos de Víctor Madrid sobre Kafka en enmilocalfunciona.io.
- Introduction to Kafka Connectors
- Kafka Cheatsheet
Actividades¶
- (RABDA.1 / CEBDA.1b y CEBDA.1d / 2p) A partir del caso 2, crea un clúster de Kafka con 3 nodos y un topic con 4 particiones y factor de replicación 2. A continuación, mediante Python, en el productor utiliza Faker para crear 10 personas (almacénalas como un diccionario). En el consumidor, muestra los datos de las personas (no es necesario recibirlos ordenados, sólo necesitamos que se aproveche al máximo la infraestructura de Kafka).
Finalmente, detén un nodo del cluster y comprueba que el flujo de mensajes sigue funcionando sin perder ningún mensaje, y que al volver a arrancar el nodo, se reincorpora alIsry vuelve a ser parte del clúster. - (RABDA.1 / CEBDA.1b y CEBDA.1d / 2p) Realiza el caso de uso 3 mediante Python, pero separando el
consumerSilverProductorGolden tres consumidores diferentes, uno que consuma y guarde en S3 (consumerSilverS3.py), otro que consuma y guarde en MongoDB (consumerSilverMongoDB.py) y el tercero que consuma, agrupe mensajes y produzca el mensaje al topic gold (consumerSilverGroupProducerGold.py). - (RABDA.1 / CEBDA.1d / opcional) Realiza el caso de uso 4 mediante Nifi, pero modificando el primer flujo para que un grupo de procesadores únicamente realice la petición REST y coloque el contenido en topic
iabd-aemet-bronzey en un segundo grupo, se consuman los mensajes de ese topic y se realice la transformación de la petición REST y su posterior producción al topiciabd-aemet-silver. -
(RABDA.1 / CEBDA.1d / opcional) A partir del ejemplo realizado en el apartado de Kafka Connect, añade otro conector para que consuma los mensajes de la cola y los inserte en MongoDB de forma automática. Para ello, puedes utilizar el MongoDB Connector (Source and Sink) y consultar su documentación y un ejemplo de fichero de configuración.
Ten en cuenta que para lanzar los dos conectores a la vez deberás lanzar Kafka Connect y pasarle todos los conectores como parámetros:
connect-standalone.sh config/connect-standalone.properties config/mysql-source-connector.properties config/mongodb-sink-connector.properties -
(RABDA.1 / CEBDA.1a / opcional) Investiga en qué consiste el patrón CDC (Change Data Capture) y cómo se realiza CDC con Kafka/Kafka Connect, el procesador CaptureChangeMySQL de Nifi y el producto Debezium. ¿Qué ventajas aportan las soluciones CDC?