InfluxDB
Series temporales
Una serie temporal es un conjunto de valores que se miden y, por lo tanto, se almacenan de forma secuencial en el tiempo. Te recomiendo que le eches un vistazo a la sesión sobre Series Temporales, donde estudiamos sus características.
InfluxDB es una base de datos NoSQL de series temporales (Time Series Database, TSDB) de código abierto desarrollada por InfluxData. Se diseñó con el objetivo de obtener altas tasas de ingestión y realizar consultas eficientes de datos con marcas de tiempo, por lo que es muy utilizada en aplicaciones de monitorización de IoT, métricas DevOps y análisis en tiempo real.
A diferencia de las bases de datos SQL relacionales como MySQL o documentales como MongoDB, InfluxDB está optimizada específicamente para manejar datos indexados por tiempo: cada punto de datos tiene una marca temporal (timestamp) que actúa como clave primaria.
Además de una solución open source mediante InfluxDB Core (con licencia MIT), ofrece soporte empresarial mediante InfluxDB Enterprise así como una solución cloud con InfluxDB Cloud o mediante un servicio AWS como Amazon Managed Service for InfluxDB.
Ecosistema¶
InfluxDB forma parte de un ecosistema con diversas herramientas, destacando Telegraf, un agente de recopilación de métricas que puede enviar datos a InfluxDB.
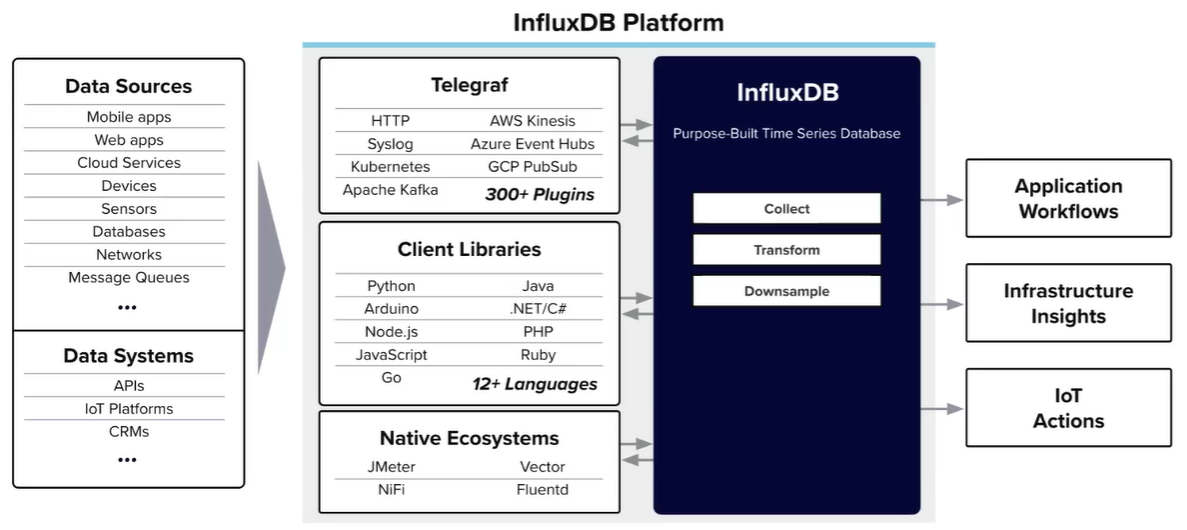
Elementos¶
Antes de entrar en detalle, es útil familiarizarse con los elementos básicos que componen el modelo de datos de InfluxDB, el cual está diseñado en torno al tiempo.
Los conceptos clave de los modelos de series temporales son:
-
Bucket: Es el contenedor de datos más alto, combina el concepto de base de datos con las políticas de retención. Todos los datos de InfluxDB se escriben en un bucket, el cual almacena puntos de datos para tantas medidas como queramos.
Sobre los buckets conviene destacar que:
- todo bucket, al crearlo, se configura un período de retención, el cual determina cuanto tiempo se almacenarán los datos de series temporales dentro del bucket. Una buena configuración del período de retención implica una gestión óptima del sistema, facilitando deshacerse de los datos inútiles y poniendo el foco en los datos recientes, que aportan mayor valor al proyecto, al mismo tiempo que se reducen los costes de almacenamiento. Por supuesto, podemos definir un tiempo de retención infinito, lo que implica que los datos no se eliminarán nunca.
- se pueden crear tokens que controlan los permisos de lectura y escritura, con alcance a un bucket específico.
-
Medida (measurement): Equivale a una tabla lógica que agrupa datos de la misma naturaleza. Todos los puntos de una medida comparten el mismo conjunto de etiquetas generales. Por ejemplo, la medida
sensor_temppara datos de temperatura. Dicho esta, una medida en InfluxDB es similar una tabla SQL con la marca temporal como índice clave predefinido. -
Etiqueta (tag): Es un par de clave-valor de tipo string indexado, utilizado para agrupar datos y facilitar el filtrado de metadatos. Ejemplos de tags serían
host="servidor1"olugar="oficina". Las etiquetas se indexan, por lo que filtrar por tags es muy eficiente. Se recomienda usar tags para aquella información de filtrado o agrupamiento (por ejemplo, ubicación o tipo de sensor) que no cambie frecuentemente. Aunque no es recomendable, podemos tener datos sin etiquetas. -
Campo: Par de clave-valor que contiene el dato real (del tipo numérico, booleano o texto). Por ejemplo,
temperatura=23.5. Los campos no se indexan, por lo que las consultas que filtran por campos deben escanear todos los datos existentes y son más lentas. Por eso, conviene guardar como campo aquello que cambia por cada punto de datos (por ejemplo, la lectura de un sensor).No todos los campos tienen que estar presentes en cada punto de datos, es decir, se puede dar el caso que tengamos campos que sólo se rellenan en determinadas ocasiones.
-
Puntos de datos: Es un registro único que consta de una medida, un conjunto de etiquetas, un conjunto de campos y un timestamp. Por ejemplo:
name: censo time mariposas abejas zona responsable 2025-08-18T00:00:00Z 1 30 1 amedranoEste punto pertenece a la medida
censo, tiene etiquetas (zona=1,responsable=amedrano), campos (mariposas=1,abejas=30) y su timestamp. Todo punto de datos debe tener al menos un campo. Cada punto se identifica de forma única por la medida, los tags (opcionales) más el instante de tiempo. Si dos puntos de datos comparten la medida, el conjunto de etiquetas y el timestamp, el último recibido sobrescribirá al existente, independientemente de los campos que contuviese. -
Timestamp: Tiempo exacto asociado a cada punto, en UTC o epoch. InfluxDB ordena los datos internamente por tiempo. En cada medición el campo de tiempo es obligatorio y actúa como clave primaria implícita. Por defecto tiene precisión de nanosegundos, aunque se puede modificar mediante la llamada de escritura del API que estemos empleando.
-
Serie: Es el conjunto de puntos que comparten la misma medida y los mismos valores de etiquetas. Equivale a una combinación única de measurement + tagset. Por ejemplo, para la medida
climacon tagsciudad=Elcheypais=ES, todos los puntos con esa combinación de tags forman una serie. Cada serie contiene múltiples puntos con timestamps distintos.Cardinalidad de las series
Recuerda que una serie se define por la combinación única de la medida, el conjunto de etiquetas y los campos.
Cuando una base de datos contiene muchas series, de forma similar a cuando una base de datos relacional contiene muchos índices, el rendimiento se ve penalizado. Pero ¿cuándo tenemos demasiada cardinalidad?
Por ejemplo, en la solución cloud que ofrece InfluxDB, en la capa gratuita, se permiten hasta un máximo de 10.000 series por cuenta, mientras que si pagas, puedes llegar al millón.
Dicho esto, si hacemos un buen uso de las etiquetas (para almacenar aquellos valores que no cambian entre un punto de dato y otro emitido desde el mismo origen) y dejamos en los campos los valores a medir, no tendremos problemas de cardinalidad.
-
Organización: Elemento superior que permite agrupar uno o más buckets, que además encapsula otros servicios como usuarios, cuadros de mandos, tareas, etc...
En resumen, la información en InfluxDB se organiza jerárquicamente: org > bucket > medida > tag > punto > campo.
---
config:
treemap:
useMaxWidth: true
diagramPadding: 8
---
treemap-beta
"Organización S8A"
"Bucket A"
"Medida 1"
"Tag 1a"
"Punto 1a1"
"Campo 1a1a"
"Valor 1a1a": 2
"Campo 1a1b"
"Valor 1a1b": 2
"Punto 1a2": 1
"Tag 1b"
"Punto 1b1"
"Campo 1b1a"
"Valor 1b1a": 2
"Campo 1b1b"
"Valor 1b1b": 2
"Campo 1b1c"
"Valor 1b1c": 2
"Medida 2"
"Tag 2a"
"Punto 2a1": 1
"Punto 2a2": 1
"Punto 2a3": 1
"Bucket B"
"Medida 3"
"Tag 3a"
"Punto 3a1"
"Campo 3a1a"
"Valor 3a1a": 2Por ejemplo, un registro de temperatura de un sensor puede ser:
- bucket:
IoTData - medida:
sensor_sala - tag:
ubicacion="sala1" - campo:
temp=22.5 - timestamp:
2025-05-30T16:00:00Z
Compartiendo la filosofía de esquemas dinámicos de los sistemas NoSQL, el esquema de un bucket se infiere a partir de los valores almacenados. Es por ello que no tenemos que definir las columnas y sus tipos, no hay que dar valores a todas las etiquetas o campos, podemos añadir etiquetas y campos en cualquier momento, etc...
Puedes encontrar más información sobre los elementos en la documentación oficial.
InfluxDB no es relacional
Como has visto, InfluxDB no contiene los mismos elementos que una base de datos relacional, pero más o menos hay cierta equivalencia:
| InfluxDB | Base de datos relacional |
|---|---|
| Organización | Schema/Esquema |
| Bucket | Base de datos |
| Medida | Tabla |
| Punto de datos | Fila/Registro |
| Campo | Columna de datos |
| Tag | Columna indexada |
| Nombre del campo | Nombre de columna de datos |
| Valor del campo | Valor de columna de datos |
| Timestamp | Columna de fecha/hora |
| Serie | Conjunto de registros únicos |
Protocolo de línea¶
Para escribir puntos de datos en InfluxDB se utiliza el protocolo del línea, el cual define un formato de texto específico, donde tras el nombre de la medida, indicamos las etiquetas separadas por comas, los campos separados por espacio y finalmente el instante temporal (por defecto en nanosegundos):
medida[,{clave-tag=valor-tag}] [,clave-campo=valor-campo}] [unix-timestamp]
El primer espacio en blanco separa la medida y etiquetas de los valores, y el segundo los campos del timestamp.
Ejemplos de medidas con diferente información serían:
# medida campo-valor
sensor_sala temp=21.5
# medida campo-valor timestamp
sensor_sala temp=22.5 1755863106000000
# medida, etiqueta campo-valor timestamp
sensor_sala, ubicacion=sala1 temp=23.5 1755863107000000
# medida, etiqueta1, etiqueta2 campo-valor timestamp
sensor_sala, ubicacion=sala1, sensor=sensor1 temp=24.5 1755863108000000
# medida, etiqueta1, etiqueta2 campo1-valor, campo2-valor timestamp
sensor_sala, ubicacion=sala1, sensor=sensor1 temp=24.5, humedad=60 1755863109000000
Primeros pasos¶
Una vez ya conocemos los conceptos básicos, vamos a poner en marcha InfluxDB en local. Si quieres usar la nube, puedes crear un cuenta en InfluxDB.
Trabajando en local¶
En vez de instalarlo en Linux mediante el paquete influxdb2 (para InfluxDB v2), nosotros nos vamos a centrar en el uso de Docker mediante la imagen influxdb, además de conectarlo tanto con Node-RED para ingestar datos como con Grafana para más adelante pintarlos.
¿v2 o v3?
Actualmente conviven la versión 2 y la versión 3 de InfluxDB. Aunque la versión 3 tiene mejor rendimiento y compresión de almacenamiento (haciendo uso del motor IOx con soporte para SQL, InfluxQL y Flux), se trata de una versión que todavía no está implantada completamente en el mercado, ya que se liberó en abril del 2025.
Por ello, en esta sesión nos centraremos en la versión 2.7 y su motor TSM (Time Structured Merge Tree), la cual es estable y ampliamente utilizada. La mayoría de los conceptos y comandos son similares en ambas versiones.
Tras la instalación, es necesario crear usuarios y credenciales, definir las bases de datos o buckets y configurar las políticas de retención. Por lo tanto, si solo queremos instalar InfluxDB desde Docker, ejecutaremos el siguiente comando que creará al usuario admin, con contraseña admin123 dentro de la organización my-org y un bucket inicial al que hemos llamado my-bucket.
docker run --name InfluxDB -d -p 8086:8086 -v "./data:/var/lib/influxdb2" -v "./config:/etc/influxdb2" -e DOCKER_INFLUXDB_INIT_MODE=setup -e DOCKER_INFLUXDB_INIT_USERNAME=admin -e DOCKER_INFLUXDB_INIT_PASSWORD=IABadmin123 -e DOCKER_INFLUXDB_INIT_ORG=my-org -e DOCKER_INFLUXDB_INIT_BUCKET=my-bucket influxdb
Si en cambio, queremos integrarlo con otros servicios como Telegraf, Grafana y Node-RED, usaremos el siguiente archivo docker-compose.yml, el cual expone InfluxDB en el puerto 8086, Grafana en el 3000 y Node-RED en el 1880:
services:
influxdb:
image: influxdb:2.7
container_name: iot-influxdb
ports:
- "8086:8086"
volumes:
- influxdb_data:/var/lib/influxdb2
environment:
- DOCKER_INFLUXDB_INIT_MODE=setup
- DOCKER_INFLUXDB_INIT_USERNAME=admin
- DOCKER_INFLUXDB_INIT_PASSWORD=admin123
- DOCKER_INFLUXDB_INIT_ORG=my-org
- DOCKER_INFLUXDB_INIT_BUCKET=my-bucket
- DOCKER_INFLUXDB_INIT_ADMIN_TOKEN=my-secret-token
- TZ=Europe/Madrid
telegraf:
image: telegraf:1.30
container_name: iot-telegraf
depends_on:
- influxdb
volumes:
- ./telegraf.conf:/etc/telegraf/telegraf.conf:ro
environment:
- HOST_PROC=/host/proc
- HOST_SYS=/host/sys
- HOST_ETC=/host/etc
privileged: true
grafana:
image: grafana/grafana:10.3.1
container_name: iot-grafana
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
nodered:
image: nodered/node-red:latest
container_name: iot-nodered
ports:
- "1880:1880"
volumes:
- nodered_data:/data
environment:
- TZ=Europe/Madrid
depends_on:
- influxdb
volumes:
influxdb_data:
grafana_data:
nodered_data:
Para crear los contenedores ejecutaremos el comando:
docker compose -p iot -f docker-compose.yml up -d
Tras conectarnos al contenedor de InfluxDB mediante docker exec -it iot-influxdb bash, podemos comprobar que el servicio está funcionando correctamente comprobando la versión instalada mediante influxd version:
influxd version
# InfluxDB v2.7.12 (git: ec9dcde5d6) build_date: 2025-05-20T22:48:39Z
Al arrancar InfluxDB por primera vez, se realiza una configuración inicial: se crea un usuario administrador, una organización y un bucket de datos. Si no lo hemos configurando en el script de creación de los contenedores, también podemos hacerlo mediante el comando influx setup.
Influx UI¶
Si accedemos al interfaz web http://localhost:8086 podremos explorar los datos, crear consultas y dashboards sencillos. Al entrar nos aparecerá la pantalla de login, a la cual entraremos con el usuario admin / admin123 que hemos configurado previamente en la configuración de Docker.

Desde la ventana de inicio, podemos cargar datos, explorar los datos existentes o crear un cuadro de mandos:
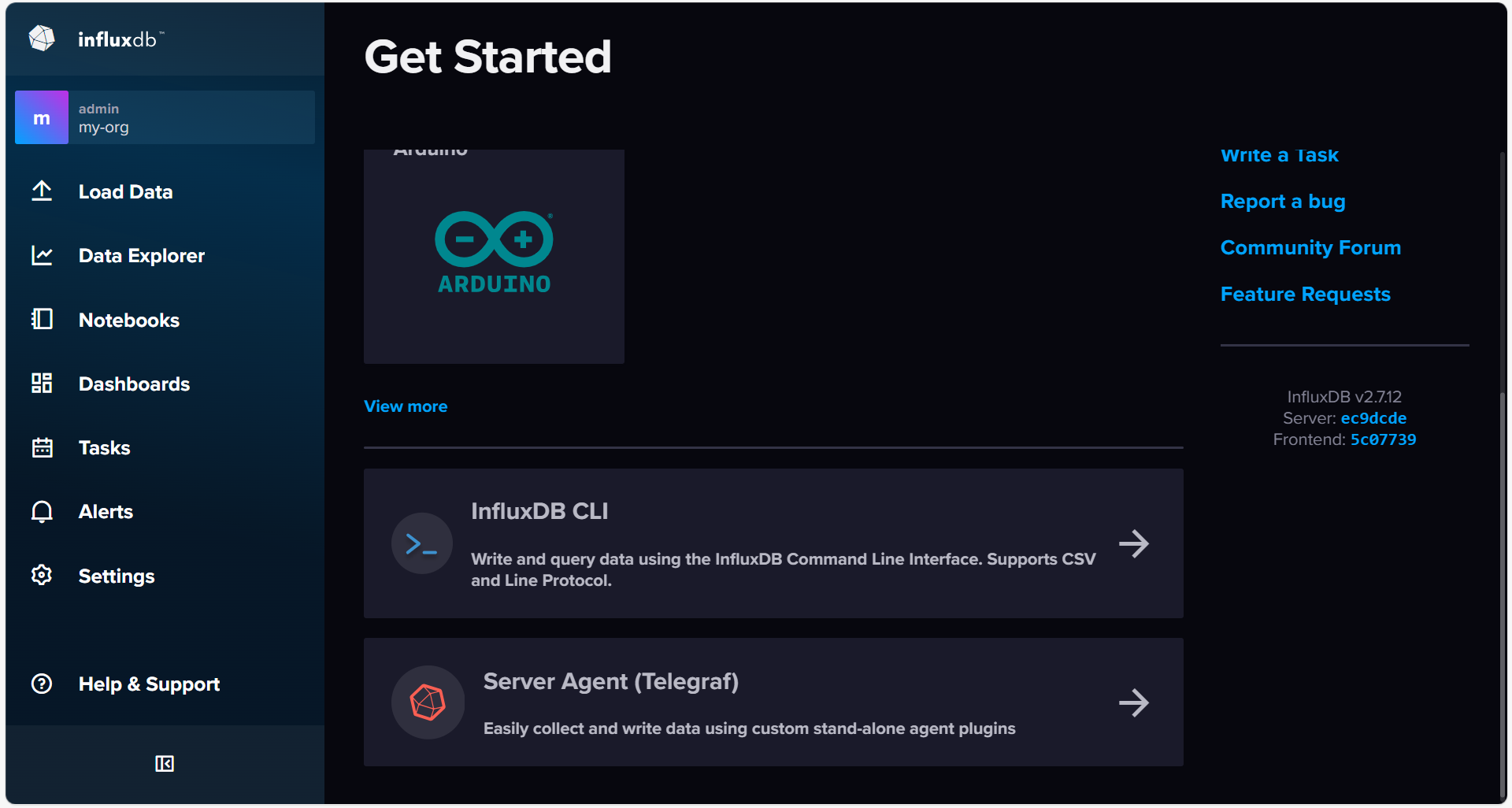
Las partes más destacables que iremos estudiando a lo largo de la sesión son:
- Los datos del usuario, en la opción About del usuario autenticado. Además, podremos gestionar los diferentes usuarios de nuestra organización.
- La página de Load Data para cargar datos, ya sea mediante la importación de datos en formato CSV, en formato de protocolo de línea. Dentro de Load Data, además cabe destacar:
- La página de Buckets para crearlos y configurar sus políticas de retención.
- La página para crear los API Tokens de acceso, ya sean de control total o de sólo lectura.
- La página Data Explorer para explorar los datos mediante una gran variedad de tipos de visualización.
- Las páginas Tasks, Alerts y Dashboards para crear tareas (script Flux que se ejecutan de forma periódica), alertas (que lanzan una notificación tras un evento) y cuadros de mandos, respectivamente.
Influx CLI¶
Además del interfaz gráfico, también podemos hacer uso de un API Rest y bibliotecas de cliente (mediante Python, Java, etc..) para acceder a InfluxDB. Para las tareas administrativas y de gestión, InfluxCLI es la interfaz de línea de comandos oficial.
Instalando las CLI
A no ser que estemos conectados directamente al servidor, necesitaremos instalar las Influx CLI en nuestro sistema, ya sea Windows, Linux o Mac.
Mediante el comando influx podemos:
- Gestionar organizaciones, usuarios, buckets y tokens.
- Ejecutar consultas en Flux (lenguaje de consultas de InfluxDB 2.x).
- Importar y exportar datos.
- Automatizar tareas de administración.
Si sólo ejecutamos influx sin ningún parámetro, obtendremos información de todos los comandos disponibles.
Antes de realizar algunas operaciones, debemos autenticarnos creando un perfil de configuración (tanto la organización como el token los configuramos en la creación del contenedor Docker):
influx config create \
--config-name mi_config \
--host-url http://localhost:8086 \
--org my-org \
--token my-secret-token \
--active
# Active Name URL Org
# * mi_config http://localhost:8086 my-org
Para evitar tener que crear el perfil de configuración para cada sesión, también podemos configurar las variables de entorno INFLUX_HOST, INFLUX_ORG e INFLUX_TOKEN.
Una vez creada la configuración o configuradas las variables de entorno, algunas operaciones comunes que podemos realizar con las organizaciones y los buckets son:
# Listar organizaciones
influx org list
# ID Name
# c97c62172ed16973 my-org
# Crear una nueva organización
influx org create --name s8a
# ID Name
# 8b930c0b22883953 s8a
# Listar buckets
influx bucket list
# ID Name Retention Shard group duration Organization ID Schema Type
# 930dcb5f364d95c6 _monitoring 168h0m0s 24h0m0s c97c62172ed16973 implicit
# 8cb0d47ac28eb2f9 _tasks 72h0m0s 24h0m0s c97c62172ed16973 implicit
# a4aaf60639844f0c my-bucket infinite 168h0m0s c97c62172ed16973 implicit
# Crear un nuevo bucket
influx bucket create \
--name h2v \
--org s8a \
--retention 30d
# ID Name Retention Shard group duration Organization ID Schema Type
# 68d82e97d2704efc h2v 720h0m0s 24h0m0s 8b930c0b22883953 implicit
En estas operaciones, además de mostrar las organizaciones y buckets disponibles, hemos creado la organización s8a la cual contiene el bucket h2v para guardar datos sobre el proyecto de Hidrógeno Verde.
A lo largo de la sesión volveremos al uso del CLI, tanto para realizar consultas como cargar datos externos.
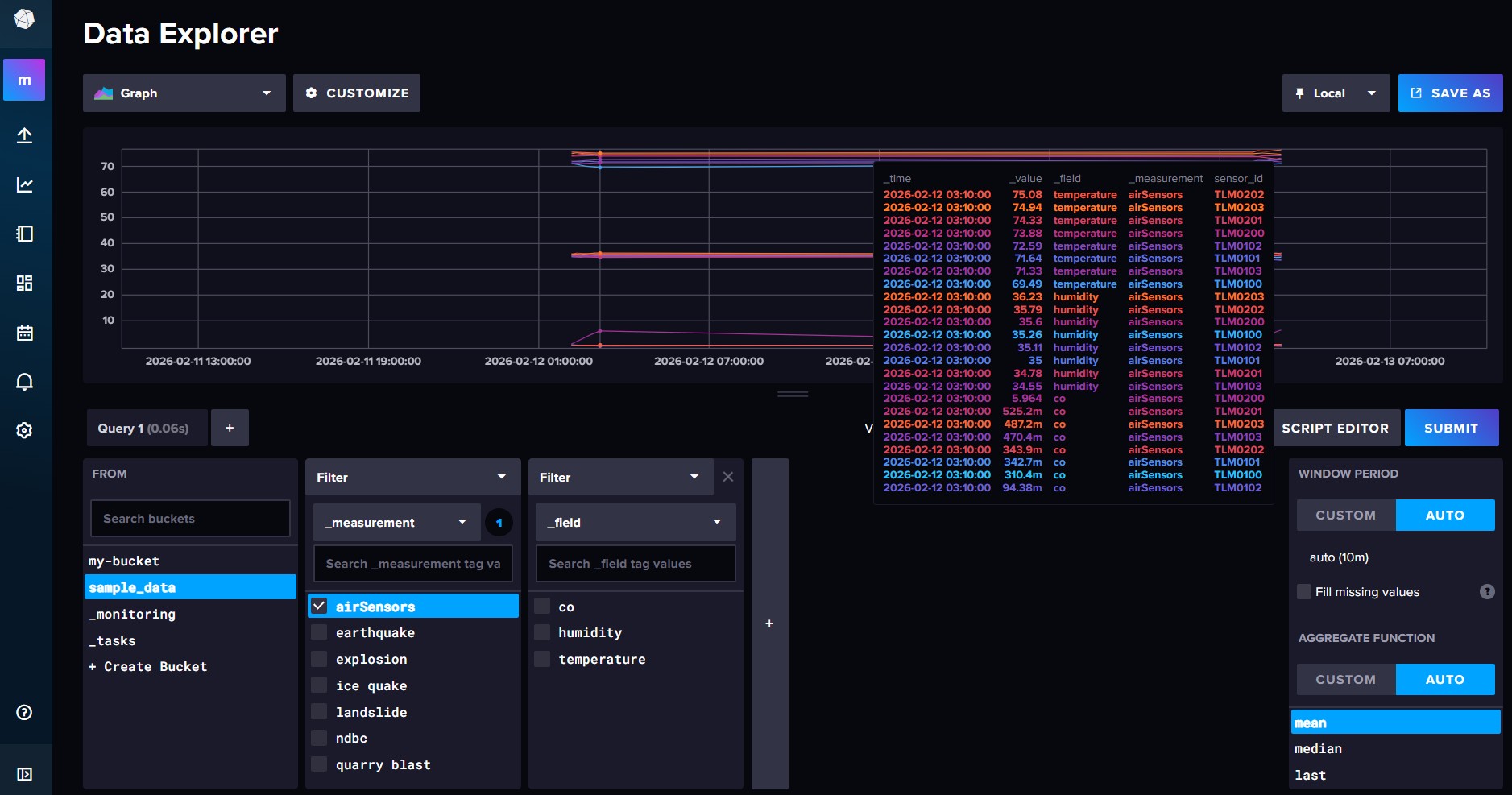
Cargando datos de ejemplo¶
La forma más sencilla es utilizar una plantilla. Si accedemos a Settings, en la opción Templates podemos cargar la siguiente plantilla:
https://github.com/influxdata/community-templates/blob/master/sample-data/sample-data.yml
sample_data tendremos diferentes medidas:
Creando una tarea¶
Otra posibilidad para añadir datos es mediante el uso de tareas. El primer paso será crear un nuevo bucket para guardar la información. Para ello, podemos hacerlo desde el interfaz gráfico desde la opción Load Data -> Buckets -> Create Bucket (recuerda seleccionar la organización de s8a):

O bien mediante el CLI:
influx bucket create --name sensores --org s8a
Una vez creado el bucket, para cargar datos de ejemplo de sensores de aire, vamos a crear una tarea. En InfluxDB, las tareas permiten programar la ejecución de consultas y scripts de forma automática.
Para ello, desde InfluxDB UI, accedemos a la opción de Tasks (el icono del calendario) y creamos una nueva:
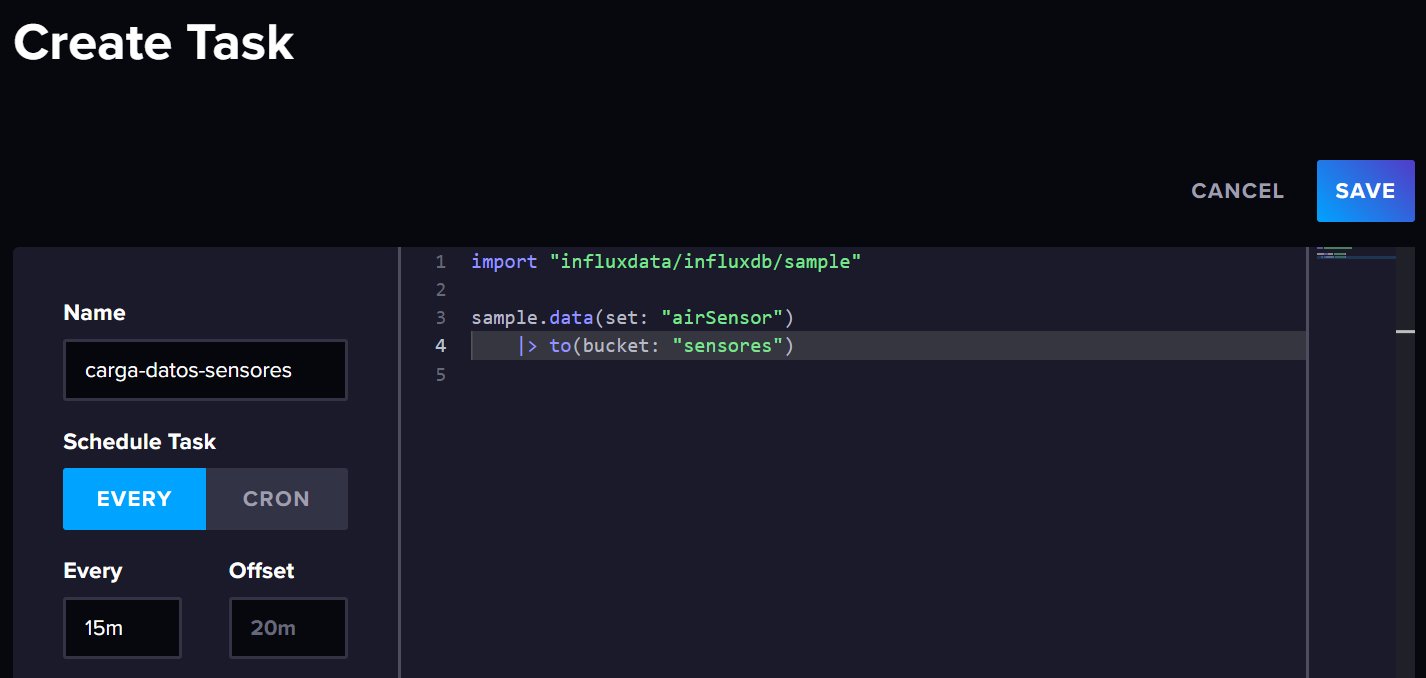
Y adjuntamos el siguiente fragmento de código:
import "influxdata/influxdb/sample"
sample.data(set: "airSensor")
|> to(bucket: "sensores")
Sin entrar en detalles del código (está escrito en Flux, el cual estudiaremos más adelante), podemos ver que se está utilizando la función sample.data para cargar datos de ejemplo en el bucket sensores. En las opciones de la tarea, le pondremos un nombre, por ejemplo, carga-datos-sensores y que se ejecute cada 5m (5 minutos).
También podíamos haber realizado la misma operación con el CLI. Para ello, primero creamos un fichero con el código de Flux:
import "influxdata/influxdb/sample"
option task = {
name: "carga-datos-sensores",
every: 5m
}
sample.data(set: "airSensor")
|> to(bucket: "sensores")
Y a continuación, creamos la tarea:
influx task create --org "s8a" --file carga_datos_sensores.flux
Podemos comprobar las tareas existentes con:
influx task list --org s8a
# ID Name Organization ID Organization Status Every Cron ScriptID
# 0f61f129ad4cb000 carga-datos-sensores 8b930c0b22883953 s8a active 5m
Copias de seguridad
Para crear y restaurar copias de seguridad mediante InfluxCLI usaremos los comandos influx backup e influx restore respectivamente:
influx backup --bucket "sensores" ./micopia
influx restore --bucket "sensores" --new-bucket "sensores_new" ./micopia
Ingesta de datos¶
InfluxDB admite varios métodos para ingestar datos desde dispositivos o fuentes externas. Lo fundamental es escribirlos en el protocolo de línea que hemos estudiado previamente.
Dependiendo del enfoque, podemos emplear:
- Uso de un API HTTP para enviar datos directamente a través de peticiones REST.
- Uso de clientes o agentes como Telegraf para recopilar y enviar datos automáticamente.
- Uso de InfluxCLI para cargar datos desde la línea de comandos o desde archivos.
API HTTP¶
El uso del API v2 es la vía más común, enviando una petición POST al endpoint /write cuyo cuerpo cumple el formato de protocolo de línea. Por ejemplo, si realizamos la petición usando curl, haríamos:
curl --request POST 'http://localhost:8086/api/v2/write?org=my-org&bucket=my-bucket' \
--header "Authorization: Token my-secret-token
--data-binary 'temperatura,ubicacion=sala valor=22.5 1700000000000000000'
Si queremos cambiar la precisión a segundos le añadimos el parámetro precision=s en la URL:
curl --request POST 'http://localhost:8086/api/v2/write?org=my-org&bucket=my-bucket&precision=s' \
--header "Authorization: Token my-secret-token
--data-binary 'temperatura,ubicacion=sala valor=22.5 1700000000'
curl --request POST https://us-east-1-1.aws.cloud2.influxdata.com/api/v2/write?bucket=noaa --header "Authorization: Bearer 22ZmhVXtOpfkkG9jrDt4hSC0fW6pSODVQQsUhVwVliO_TTmywt5KIcibmrtPRWakxTq4s-J9iTFHEGc1AhbHog==" --header "Content-Type: text/plain; charset=utf-8" --header "Accept: application/json" --data-binary "$(curl --request GET https://docs.influxdata.com/downloads/bay-area-weather.lp)"
En este ejemplo, temperatura es la medida, ubicacion=sala es una etiqueta, valor=22.5 es el campo, y el último número es el timestamp (epoch en nanosegundos).
InfluxQL
InfluxDB v1.x permite la sentencia SQL-like INSERT, por ejemplo:
USE my-bucket
INSERT temperatura,ubicacion=oficina valor=21.0 1700003600000000000
Esto escribe un punto idéntico al anterior. La sintaxis es INSERT <medición>,<tag>=<valor_tag> <field>=<valor_field> <timestamp>.
Telegraf¶
Aunque Telegraf se sale del alcance de la presente sesión, cabe destacar que es un agente de recopilación de métricas. Permite la ingesta de datos a traves de más de 200 plugins de entrada (por ejemplo, para monitorización de software, de sistemas operativos Linux o Windows, así como de protocolos IoT), además de más de 20 plugins de salida (por ejemplo, para InfluxDB v2). Para ello, se configura el plugin de salida influxdb_v2 con la URL del servidor, el token de autenticación, la organización y el bucket de destino. Luego, Telegraf se encarga de recolectar las métricas configuradas (por ejemplo, del sistema o de aplicaciones) y enviarlas a InfluxDB usando el protocolo de línea.
Además, dispone de más de 20 plugins de procesamiento para renombrar, emplear expresiones regulares o realizar filtrado o transformaciones sobre los datos.
Un ejemplo de configuración sería:
[[outputs.influxdb_v2]]
urls = [http://localhost:8086]
token = "my-secret-token"
organization = "my-org"
bucket = "my-bucket"
Influx CLI¶
Mediante el CLI también podemos escribir datos en InfluxDB de varias formas, pero siempre con la opción write, ya sea:
-
Directamente desde la salida estándar:
echo "sensor_sala,ubicacion=sala1 temp=23.5" | influx write --bucket "my-bucket" -
A partir de un fichero con formato de protocolo de línea:
datos.plsensor_sala,ubicacion=sala1 temp=23.5El cual cargamos con el parámetro
--file:influx write --bucket "my-bucket" --file datos.pl -
Desde un archivo CSV, el cual puede estar anotado:
datos_anotados.csv#datatype measurement,tag,field,dateTime:RFC3339 measurement,ubicacion,temp,time sensor_sala,sala1,23.5,2025-10-03T15:00:00ZEl cual cargamos con el parámetro
--filey con--format csv:influx write --bucket "my-bucket" --file datos_anotados.csv --format csv -
O a partir de un CSV sin anotar
datos_sinanotar.csvmeasurement,ubicacion,temp,time sensor_sala,sala1,23.5,2025-10-03T15:00:00ZDonde indicamos el formato de las columnas mediante el parámetro
--header:influx write --bucket "my-bucket" --file datos_sinanotar.csv --format csv -- header "#datatype measurement,tag,field,dateTime:RFC3339"
Librerías de cliente¶
Existen diferentes librerías para cada lenguaje de programación desde el cual queramos acceder a Influx, ya sea Java, Go, Scala, Python, PHP, C#, Ruby, Arduino, Kotlin, etc...
Por ejemplo, para acceder desde Python, tras instalar la librería mediante pip install influxdb-client, haremos algo similar a:
from datetime import datetime, timezone
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
with InfluxDBClient(
url = "http://localhost:8086",
token = "my-secret-token") as cliente:
punto = Point("sensor_sala") /
.tag("ubicacion", "sala1") /
.field("valor", 23.5) /
.time(time=datetime.now(timezone.utc))
write_api = cliente.write_api(write_options=SYNCHRONOUS)
write_api.write(bucket="my-bucket", org="my-org", record=punto)
En el apartado de InfluxDB y Python profundizaremos en su uso.
InfluxDB ordena los puntos por tiempo y los almacena de forma eficiente. No importa si llegan desordenados o con timestamps pasados; se indexan por tiempo internamente. Al escribir, hay que asegurarse de usar el formato correcto de tiempo y, en InfluxDB 2.x, especificar el bucket de destino (por API).
Flux¶
InfluxDB ofrece diversos lenguajes de consulta dependiendo de la versión con la que trabajemos:
- InfluxQL para Influx v1: similar a SQL, sencillo para consultas básicas.
- Flux para Influx v2: más potente y flexible, orientado a análisis avanzado.
- SQL para Influx v3
Todos permiten filtrar por tiempo, agrupar datos y realizar agregaciones.
Cuando realizamos una consulta sobre InfluxDB el resultado esta orientado a columnas (en contraposición de los sistemas relacionales que están basados a filas).
InfluxQL
InfluxQL es un lenguaje similar a SQL adaptado a series temporales. Permite emplear funciones de agregación (MEAN, SUM, COUNT, etc.), agrupar por intervalos temporales, así como clausulas LIMIT, ORDER BY time DESC, GROUP BY fill() (para completar intervalos vacíos). Algunos ejemplos:
SELECT * FROM "temperatura"
SELECT * FROM "temperatura"
WHERE "ubicacion" = "oficina" AND time >= "2025-05-30T00:00:00Z"
-- Agrupación por tag
SELECT COUNT("valor") FROM "sensor"
GROUP BY "ubicacion"
-- Agrupación por tiempo - Temmperatura media
SELECT MEAN("valor") FROM "temperatura"
WHERE time >= now() - 24h
GROUP BY time(1h) -- agrupa cada media por bloques de 1 hora
-- Cuenta registros por cada 10 minutos en la sala, rellenando intervalos vacíos con el valor previo.
SELECT COUNT("valor")
FROM "temperatura"
WHERE "ubicacion"="sala" AND time > '2025-05-30T00:00:00Z'
GROUP BY time(10m) fill(previous) -- fill completa intervalos vacíos
En general, las consultas InfluxQL siguen la forma SELECT <agregaciones> FROM <medición> [WHERE <condiciones>] [GROUP BY time(<interval>), <tags>].
En esta sesión nos vamos a centrar en Flux, el cual es el lenguaje nativo de InfluxDB 2.0, y se utiliza para:
- Escribir consultas para recuperar datos.
- Transformar y dar forma a los datos según sea necesario.
- Integrarse con otras fuentes de datos.
Flux es un lenguaje funcional que utiliza una notación basada en pipe-forward (tuberías hacia delante) donde se encadenan funciones de manera que la salida de una función es la entrada de la siguiente:
|> from (bucket: "bucket1")
|> funcion1
|> funcion2
|> funcionN
graph LR
A[Bucket: bucket1] -->|"|> from()"| B[Stream de Datos]
B -->|"|> funcion1()"| C[Datos Transformados 1]
C -->|"|> funcion2()"| D[Datos Transformados 2]
D -->|"|> ..."| E[...]
E -->|"|> funcionN()"| F[Resultado Final]Sintaxis básica¶
Se trata de un lenguaje declarativo. Aunque la sintaxis pipe-forward exprese la lógica de computación, el motor Flux realiza las operaciones en el orden en el cual se optimice el rendimiento.
Las funciones pueden recibir parámetros (los cuales tienen nombre) y devolver resultados::
f = (x) => x
f(x:1)
f(x:1.1) // devuelve 1.1
f(x:"hola") // devuelve "hola"
f(x:true) // devuelve true
f(x:f) // devuelve f
Además, las funciones son polimórficas:
batman = {nombre: "Bruce", apellido: "Wayne", edad: 35}
aitor = {nombre: "Aitor", apellido: "Medrano"}
// Creamos una función nombre que devuelve el nombre de una persona
nombre = (persona) => persona.nombre
nombre(batman) // "Bruce"
nombre(aitor) // "Aitor"
Las funciones predicado devuelven un valor booleano (true o false) y se usan para filtrar datos:
esMayorDeEdad = (persona) => persona.edad >= 18
esMayorDeEdad(batman) // true
esMayorDeEdad(aitor) // false
Para acceder a las propiedades de un objeto, podemos emplear tanto notación de corchetes como de punto, aunque se recomienda la notación de corchetes para evitar problemas con caracteres especiales en el nombres de columnas:
filter(fn: (r) => r["_measurement"] == "medida1")
filter(fn: (r) => r._measurement == "medida1")
Flux es un lenguaje fuertemente tipado, por lo que no podemos mezclar tipos de datos en operaciones:
// Correcto
r._value + 10 // si r._value es numérico
r._value + " texto" // si r._value es cadena
// Incorrecto
r._value + 10 // si r._value es cadena
r._value + " texto" // si r._value es numérico
Además, en tiempo de ejecución no se puede modificar el tipo de una variable. El tipo de un objeto es immutable:
cadena1 = "hola"
cadena2 = "adios" // Error: no se puede asignar un nuevo valor a cadena1
mi_funcion = (a, b) => if a > b then a else b // En una comparación, ambos operandos deben ser del mismo tipo
mi_funcion(a: 33, b: cadena1) // Error: ambos operandos deben ser del mismo tipo
En Flux no hay bucles, lo más parecido es la función map, que aplica una función a cada fila de una tabla:
|> map(fn: (r) => ({ r with nueva_columna: r._value * 2 }))
Flujos de tablas¶
El flujo de datos en Flux se basa en tablas. Cada tabla tiene un esquema (columnas y tipos) y filas (registros). Las tablas se procesan secuencialmente a través de las funciones encadenadas.
Un punto importante es que, al usarse el operador pipe forward, las funciones Flux operan en cada fila de cada tabla que se les aplica. No se puede pedir a Flux que opere en una tablas sí pero no en otras, ni que opere sobre una fila y no sobre otras. Cada fila de cada tabla sufrirá las mismas transformaciones.
Así pues, cada función toma una o más tablas como entrada y produce una o más tablas como salida.
Los pasos para realizar una consulta con Flux son:
-
Definir la fuente de datos mediante la función
from, la cual recibe como parámetro el nombre de un bucket:from(bucket:"sensores") -
Indicar la ventana temporal mediante la función
range, la cual acepta los parámetrosstarty/ostop, además de permitir valores relativos negativos o absolutos mediante timestamps:// relativo que se detiene "ahora" from(bucket:"ejemplo-bucket") |> range (start: -1h) // relativo entre inicio y fin from(bucket:"ejemplo-bucket") |> range (start: -1h, stop: -10m) // absoluto from(bucket:"ejemplo-bucket") |> range (2026-01-05T23:30:00Z, stop: 2026-02-06T00:00:00Z) -
Filtrar los datos, mediante la función
filterpara restringir los datos a partir de datos de los atributos o columnas. La funciónfilterespera como parámetro una función anónima cuya lógica realice el filtrado, pudiendo acceder al campo_measurementpara acceder a una medida,_fieldpara un campo,_valueal valor o directamente el nombre del tag:// patrón (registro) => (registro.propiedad operadorComparación expresión) // ejemplo sencillo (r) => (r._measurement == "sensor_sala") // ejemplo compuesto (r) => (r._measurement == "sensor_sala") and (r.field == "temp") // función filter con criterio de filtrado filter(fn: (r) => r._measurement == "sensor_sala" and r.field == "temp" and r.ubicacion="sala1") -
Finalmente, mediante
yieldse produce la consulta y obtiene el resultado de la consulta:from(bucket:"ejemplo-bucket") |> range (start: -1h) |> filter(fn: (r) => r._measurement == "sensor_sala" and r.field == "temp") |> yield()
Flux y CLI
Para realizar consultas desde el CLI, usaremos la opción query seguida de la sentencia Flux:
influx query 'buckets()'
influx query 'from(bucket:"ejemplo-bucket") |> range (start: -1h)"
Desde un fichero:
echo "buckets()" > consulta.flux
influx query --file consulta.flux
Por ejemplo, para obtener la temperatura media de la sala1 de la última hora, haríamos:
|> from(bucket: "ejemplo-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_sala" and r.ubicacion == "sala1")
|> mean()
|> yield(name: "mean")
Si te fijas, en la línea 4 se ha indicado la función de agregación mean que calcula la media de los datos recibidos.
Transformando los datos¶
Más allá de las consultas básicas, Flux permite transformar, agregar, remuestrear y procesar datos de diversas formas.
La función map() permite iterar sobre cada fila de los datos y modificar sus valores. Es una de las funciones más versátiles de Flux.
map() recibe un parámetro fn que contiene una función anónima. Esta función procesa cada fila como un registro r, donde cada par clave-valor representa una columna y su valor.
Por ejemplo, para convertir temperaturas de °C a °F:
from(bucket: "ejemplo-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_sala" and r._field == "temp")
|> map(fn: (r) => ({r with _value: (r._value * 1.8) + 32.0}))
Operador with
El operador with permite extender el registro existente, conservando todas las columnas originales y solo modificando o añadiendo las especificadas.
Otras transformaciones comunes con map() incluyen:
-
Asignación condicional de estados, creando una nueva columna basada en el valor de otra (por ejemplo, para clasificar niveles de CO):
from(bucket: "ejemplo-bucket") |> range(start: -6h) |> filter(fn: (r) => r._field == "co") |> map(fn: (r) => ({ r with state: if r._value < 10 then "ok" else "warning" })) -
Aletas con lógica compleja, integrando funciones externas para enviar notificaciones o realizar acciones:
import "contrib/sranka/telegram" from(bucket: "ejemplo-bucket") |> range(start: -1h) |> filter(fn: (r) => r._field == "co") |> map(fn: (r) => ({r with state: if r._value < 10 then "ok" else "warning"})) |> filter(fn: (r) => r.state == "warning") |> map(fn: (r) => { telegram.message( token: "bot-token", channel: "-12345", text: "CO peligroso en ${r.room}: ${r._value} ppm" ) return r })Telegram
Para poder usar Telegram dentro de InfluxDB debemos obtener el token de un bot y el identificador del canal al que queremos enviar los mensajes:
- Crea el bot: habla con
@BotFathermediante/newbot - Crea un canal en Telegram y añade el bot como administrador
- Envía un mensaje en el canal (mencionando al bot:
@tubot hola) -
Obtén el identificador ejecutando:
curl https://api.telegram.org/bot<TU_TOKEN>/getUpdates -
Busca el campo "chat":{"id":-123456789} en la respuesta. El identificador de canal normalmente es un número negativo (ej:
-1001234567890).
- Crea el bot: habla con
Agregar datos¶
La función group() permite reorganizar los datos según columnas específicas. Por defecto, from() agrupa los datos por serie (medida, tags y campo).
// Agrupar solo por campo, ignorando tags
from(bucket: "ejemplo-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_sala")
|> group(columns: ["_field"])
// Desagrupar completamente (una sola tabla)
from(bucket: "ejemplo-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_sala")
|> group()
Importancia del agrupamiento
El agrupamiento determina cómo se aplican las funciones de agregación. Cada tabla en el flujo de datos se procesa independientemente.
Las funciones de agregación eliminan las columnas que no están en la clave de grupo y devuelven un único valor por tabla de entrada.
Las funciones de agregación más comunes son:
mean(): Media aritméticasum(): Suma de valorescount(): Número de registrosmin()/max(): Valores mínimo/máximomedian(): Medianastddev(): Desviación estándar
Algunos ejemplos de agregación:
// Temperatura media por sala
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._field == "temp")
|> mean()
// Temperatura media global (todas las salas)
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._field == "temp")
|> group() // desagrupar
|> mean()
// Contar puntos reportados por sala
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._measurement == "sensor_sala")
|> group(columns: ["room"])
|> count()
Asignar timestamp a agregados
Tras una agregación, _time se pierde. Puedes duplicar _stop como nuevo _time:
|> mean()
|> duplicate(column: "_stop", as: "_time")
Por otro lado, las funciones de selección devuelven una o más filas de cada tabla, conservando todas las columnas, siendo las más comunes:
first()/last(): Primera/última filamax()/min(): Fila con valor máximo/mínimotop(n: N)/bottom(n: N): N filas con valores más altos/bajossample(n: N): N filas aleatorias
Algunos ejemplos de selección:
// Primera temperatura registrada por sala
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._field == "temp")
|> first()
// Temperatura máxima por sala
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._field == "temp")
|> max()
// Top 3 lecturas de temperatura
from(bucket: "ejemplo-bucket")
|> range(start: -6h)
|> filter(fn: (r) => r._field == "temp")
|> top(n: 3)
Pivotar a esquema relacional
La función pivot() transforma los datos al formato relacional tradicional (SQL), donde cada campo es una columna.
from(bucket: "ejemplo-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_sala")
|> filter(fn: (r) => r.room == "sala1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
Resultado:
| _time | _measurement | room | co | hum | temp |
|---|---|---|---|---|---|
| 2022-01-01T14:00:00Z | sensor_sala | sala1 | 1 | 36.3 | 22.8 |
| 2022-01-01T15:00:00Z | sensor_sala | sala1 | 3 | 36.2 | 22.7 |
Remuestreo¶
El remuestreo (downsampling) reduce el número de puntos agrupándolos en ventanas temporales, mejorando el rendimiento de las consultas y optimizando el almacenamiento.
La función aggregateWindow() facilita el remuestreo:
every: Duración de cada ventanafn: Función de agregación o seleccióntimeSrc: (Opcional) Columna para el timestamp (por defecto_stop)
// Media cada 2 horas
from(bucket: "ejemplo-bucket")
|> range(start: -24h)
|> filter(fn: (r) => r._field == "temp")
|> aggregateWindow(every: 2h, fn: mean)
// Máximo cada 30 minutos
from(bucket: "ejemplo-bucket")
|> range(start: -24h)
|> filter(fn: (r) => r._field == "temp")
|> aggregateWindow(every: 30m, fn: max)
// Mediana cada hora con timestamp personalizado
from(bucket: "ejemplo-bucket")
|> range(start: -24h)
|> filter(fn: (r) => r._field == "temp")
|> aggregateWindow(every: 1h, fn: median, timeSrc: "_start")
Automatización con tareas¶
Las tareas de InfluxDB permiten ejecutar consultas Flux de forma programada. Normalmente, las tareas procesan datos y los escriben de vuelta a InfluxDB usando to().
Por ejemplo, la siguiente tarea remuestrea diariamente la temperatura de la sala1 y guarda el resultado en un nuevo bucket:
option task = {
name: "Remuestreo diario de temperatura",
every: 1d,
}
from(bucket: "sensores")
|> range(start: -task.every)
|> filter(fn: (r) => r._measurement == "sensor_sala")
|> filter(fn: (r) => r._field == "temp")
|> aggregateWindow(every: 1h, fn: mean)
|> to(bucket: "sensores-agregados", org: "mi-org")
Opciones de tareas
name: Nombre descriptivo de la tareaevery: Intervalo de ejecución (ej:1h,30m,1d)offset: (Opcional) Retraso desde el inicio del intervalocron: (Alternativa aevery) Expresión cron para programación avanzada
También es posible programar tareas con un offset, para que se ejecuten un tiempo después del inicio del intervalo. Por ejemplo, para realizar un backup semanal 3 horas después del inicio de la semana:
option task = {
name: "Backup semanal",
every: 1w,
offset: 3h, // ejecutar 3 horas después del inicio de la semana
}
from(bucket: "sensores")
|> range(start: -task.every)
|> to(bucket: "backup", org: "mi-org")
Autoevaluación
Ahora que hemos visto cómo escribir datos en InfluxDB y cómo consultarlos con Flux, ¿podrías deducir qué realiza la siguiente consulta?
import "experimental/csv"
relativeToNow = (tables=<-) => tables
|> elapsed()
|> sort(columns: ["_time"], desc: true)
|> cumulativeSum(columns: ["elapsed"])
|> map(fn: (r) => ({r with _time: time(v: int(v: now()) - r.elapsed * 1000000000)})) csv.from(url: "https://influx-testdata.s3.amazonaws.com/noaa.csv")
|> relativeToNow()
|> limit(n: 100)
|> to(bucket: "noaa")
El fragmento anterior es una función que convierte un flujo de datos con timestamps relativos (por ejemplo, "hace 5 minutos") a timestamps absolutos basados en el tiempo actual (now()). Luego, se aplica esta función a un conjunto de datos CSV de ejemplo, limitando el resultado a las 100 filas más recientes, y finalmente se escribe el resultado en un bucket de InfluxDB.
InfluxDB y Python¶
El primer paso es instalar la librería influxdb_client:
pip install influxdb_client
Tanto para insertar datos, como para consultarlos, vamos a necesitar conectarnos mediante un cliente y los datos de acceso (url del host, token de acceso y organización). Para ello, crearemos un InfluxDBClient:
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
# Parámetros de conexión
url = "http://localhost:8086"
token = "mi_token_aquí"
org = "mi_organización"
bucket = "mi_bucket"
# Conexión al cliente
client = InfluxDBClient(url=url, token=token, org=org)
Insertando datos¶
Para insertar un punto de datos, instanciaremos un Point indicando la medida y tantos campos como necesitemos. A continuación, mediante el método write de un WriteApi persistimos el punto y finalmente cerramos la conexión:
# Preparar el punto de datos
punto = Point("temperatura").field("valor", 23.5)
# Enviar el punto
write_api = client.write_api(write_options=SYNCHRONOUS)
write_api.write(bucket=bucket, org=org, record=punto)
# Cerrar conexión
client.close()
Al crear un punto, si queremos indicarle alguna etiqueta o de forma explícita el timestamp, podemos emplear los métodos tag o time respectivamente:
from datetime import datetime, timezone
punto = (
Point("temperatura")
.tag("ubicacion", "sala1")
.field("valor", 23.5)
.time(datetime.now(timezone.utc), WritePrecision.NS)
)
Consultando datos con Flux¶
Para recuperar datos y realizar consultas desde Python, primero recuperaremos el cliente de consulta QueryApi, para luego realizar la consulta mediante el método query. La consulta puede ser tanto una sentencia Flux como una sentencia InfluxQL:
query_api = client.query_api()
consulta = 'from(bucket:"mi_bucket") |> range(start: -1h)'
result = query_api.query(org=org, query=consulta)
for table in result:
for record in table.records:
print(record)
Node-RED e InfluxDB¶
Para insertar datos en InfluxDB desde Node-RED, necesitamos instalar el conector node-red-contrib-influxdb que añadirá los nodos influxdb out para insertar datos en InfluxDB, e influxdb in para cargar datos desde InfluxDB en NodeRed. Para ello, desde la paleta, instalaremos el conector:
Utilizando un nodo de tipo función, crearemos un mensaje JSON con los datos a introducir. En nuestro caso, simulamos datos de temperatura, humedad y peso de una colmena. Para ello, definimos una lista con dos objetos, el primero con los campos y el segundo con el conjunto de etiquetas:
msg.payload = [
{ // campos
temp_Int_1: Math.random() * 10,
temp_Int_2: Math.random() * 10,
humedad_Int : 11,
peso: 11 + Math.random(),
temp_Ext: Math.random() * 10,
humedad_Ext : 11,
vel_Viento : 11,
dir_Viento : 11
},
{ // etiquetas
colmena: "pvc",
lugar: "Villena"
}
];
return msg;
Una vez tenemos los datos, ya podemos utilizar un nodo influxdb out, donde:
-
Configuraremos el servidor al que vamos a conectarnos, indicando la versión 2 del API, la URL del servidor con el nombre del contenedor Docker (en nuestro caso
iot-influxdb) y el token de acceso (my-secret-token):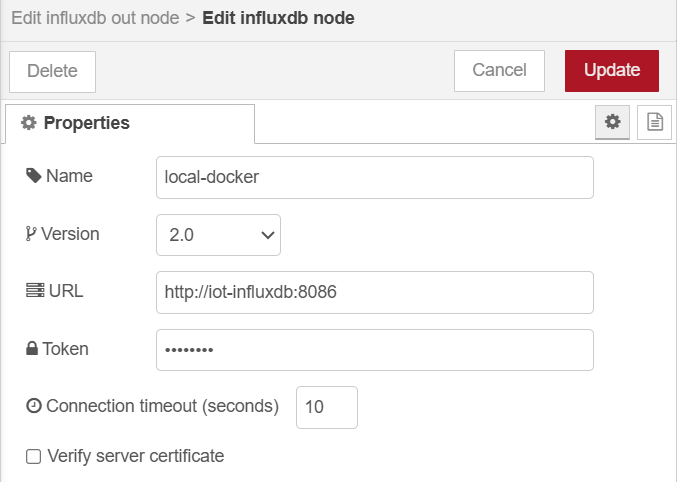
Configuración del servidor InfluxDB en NodeRed -
En la propia configuración de nodo de escritura en Influx, indicamos los datos relativos a la organización (
my-org), bucket (my-bucket), medida (por ejemplo, ennodered-s8a) y la precisión de las inserciones.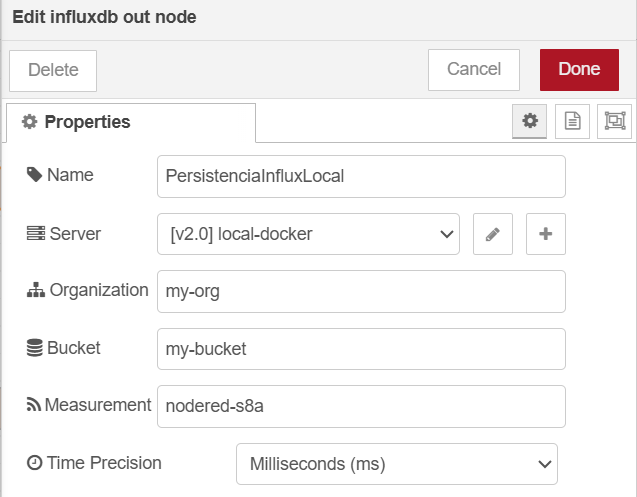
Configuración del servidor InfluxDB en NodeRed
Así pues, tendremos como resultado un flujo similar al siguiente, donde inyectamos, por ejemplo, cada 15 segundos un mensaje, rellenamos los datos en un nodo función y finalmente los insertamos en InfluxDB:

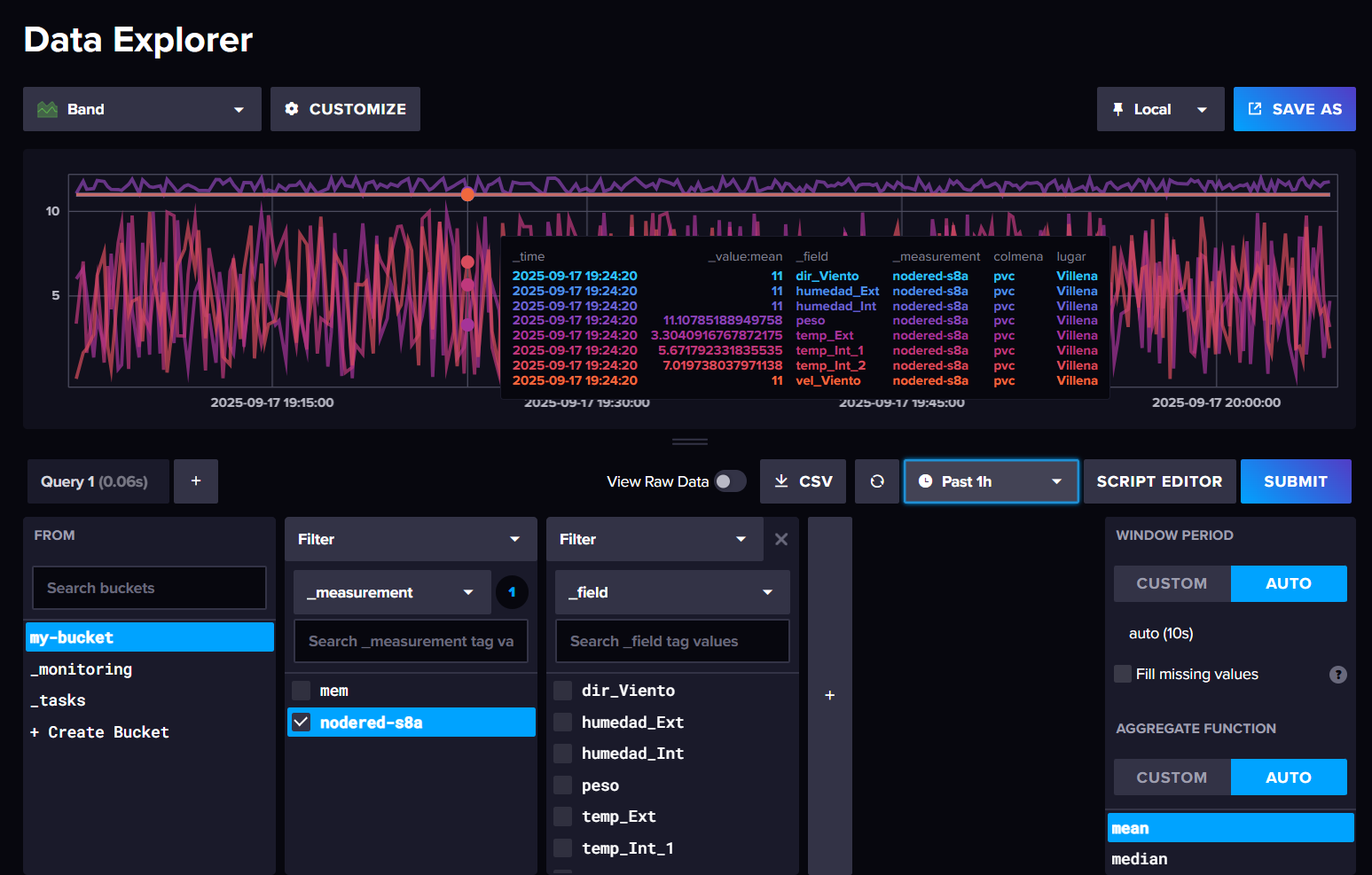
Finalmente, si desplegamos el flujo y lo ejecutamos, comenzarán a insertarse datos en Influx. Si vamos a Influx UI, y en el explorador de datos creamos una consulta con la medida que acabamos de crear, comprobaremos que los datos se han insertado correctamente en InfluxDB:
Cuadros de mandos¶
Interfaz gráfico¶
Desde InfluxDB 2.x se incluye una interfaz web integrada accesible en http://localhost:8086. Permite explorar buckets, escribir consultas (InfluxQL y Flux), visualizar resultados en gráficas y crear dashboards personalizados. Es la herramienta de administración y análisis de InfluxDB 2.x. La documentación oficial indica que esta UI se provee con el servicio y se accede vía navegador.
Antiguamente, para la monitorización y visualización de datos de las versiones InfluxDB 1.x se utilizaba Chronograf, la cual permite visualizar datos en tiempo real y crear dashboards de forma sencilla. Incluye plantillas prediseñadas y bibliotecas para gráficos, permitiendo construir y clonar cuadros de mandos rápidamente. También ofrece control de usuario, gestión de alertas y administración de clústeres de InfluxDB.
En resumen¶
Si comparamos con SQL, en InfluxDB las mediciones (measurements) son análogas a las tablas SQL, pero el índice principal siempre es el tiempo. Los tags son pares clave-valor indexados (como columnas con índice), mientras que los fields son datos propiamente dichos sin índice (como columnas sin índice). No hay soporte para operaciones avanzadas de SQL como JOIN o HAVING. InfluxDB es “schemaless” (esquema flexible): puede agregar nuevas mediciones, tags o fields en cualquier momento sin migraciones costosas. En resumen, InfluxDB maneja grandes volúmenes de datos temporales más rápido que una base relacional, pero renuncia a funciones como relaciones complejas por tabla, priorizando la eficiencia temporal.
Si comparamos con MongoDB, InfluxDB está especializado en datos de series temporales, mientras que MongoDB es una base de datos de documentos genérica. InfluxDB sobresale en escenarios de alta escritura continua de datos etiquetados en el tiempo, y permite consultas rápidas tras la inserción. MongoDB, por su parte, almacena documentos JSON flexibles (sin esquema fijo) y admite índices de tiempo a través de funcionalidades como colecciones de series temporales o índices TTL, pero no está optimizado desde su núcleo para análisis de series temporales. Como resumen: InfluxDB ofrece alto rendimiento y compresión para métricas o eventos con marcas de tiempo, mientras que MongoDB ofrece flexibilidad de esquema y escalabilidad horizontal para datos generales.
Referencias¶
- Documentación oficial de InfluxDB y de Flux.
- Time to Awesome, a book on InfluxDB.
- Conectando NodeRed con InfluxDB
Actividades¶
-
(RABDA.1 / CEBDA.1d / 2p) Supongamos un sistema de monitorización de temperaturas en tres habitaciones (
sala,oficina,entrada). Se pide:- Dentro de la organización
s8a, crea el bucketinflux-s8a. - Crea un fichero en formato de protocolo de línea que inserte en la medida
temperaturavalores para las tres habitaciones (mínimo 10 valores para cada habitación con timestamps separados a lo largo de un día). - Recupera todas las temperaturas.
- Recupera las temperaturas de la entrada.
- Recupera las temperaturas media por hora de la oficina.
- Dentro de la organización
-
(RABDA.1 / CEBDA.1d / 1p) Haciendo uso de Python, inserta temperaturas cada 10 minutos durante 2 horas en la sala. A continuación, calcula la temperatura media en esa sala cada 30 minutos.
-
(RABDA.1 / CEBDA.1d / 1p) Haciendo uso de Influx UI, crea un cuadro de manos que muestre la temperatura actual de cada una de las salas, así como la temperatura media del rango seleccionado.
-
(opcional) ¿Por qué no conviene usar la temperatura como tag? ¿Qué pasaría si lo hiciéramos?
-
Una vez tenemos unos conocimiento básicos sobre InfluxDB, vamos a ponerlo en práctica en el PIIAFP Hidrógeno Verde. Para ello, usaremos los siguientes datos:
- Organización:
s8a - Bucket:
h2v - Medida:
temperaturas
- Organización: