MongoDB
Apuntes sin actualizar
Estos apuntes pertenecen al curso 22/23 y, por lo tanto, ya no se actualizan.
Puedes acceder a la última versión de esta sesión en https://aitor-medrano.github.io/iabd/sa/mongo.html.
MongoDB (http://www.mongodb.com) es una de las bases de datos NoSQL más conocidas. Sigue un modelo de datos documental, donde los documentos se basan en JSON.
huMONGOus
Como curiosidad, su nombre viene de la palabra inglesa humongous, que significa gigantesco/enorme.
MongoDB destaca porque:
- Soporta esquemas dinámicos: diferentes documentos de una misma colección pueden tener atributos diferentes.
- Aunque inicialmente tenía un soporte limitado de joins, desde la versión 5.2 se pueden realizar incluso entre colecciones particionadas.
- Soporte de transacciones sólo a nivel de aplicación. Lo que en un RDMS puede suponer múltiples operaciones, con MongoDB se puede hacer en una sola operación al insertar/actualizar todo un documento de una sola vez, pero si queremos crear una transacción entre dos documentos, la gestión la debe realizar el driver.
Conceptos¶
Hay una serie de conceptos que conviene conocer antes de entrar en detalle:
- MongoDB tienen el mismo concepto de base de datos que un RDMS. Dentro de una instancia de MongoDB podemos tener 0 o más bases de datos, actuando cada una como un contenedor de alto nivel.
- Una base de datos tendrá 0 o más colecciones. Una colección es muy similar a lo que entendemos como tabla dentro de un RDMS. MongoDB ofrece diferentes tipos de colecciones, desde las normales cuyo tamaño crece conforme lo hace el número de documentos, como las colecciones capped, las cuales tienen un tamaño predefinido y que pueden contener una cierta cantidad de información que se sustituirá por nueva cuando se llene.
- Las colecciones contienen 0 o más documentos, por lo que es similar a una fila o registro de un RDMS.
- Cada documento contiene 0 o más atributos, compuestos de parejas clave/valor. Cada uno de estos documentos no sigue ningún esquema, por lo que dos documentos de una misma colección pueden contener todos los atributos diferentes entre sí.
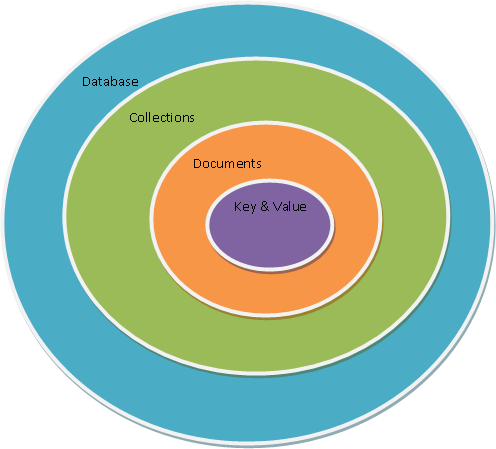
Así pues, tenemos que una base de datos va a contener varias colecciones, donde cada colección contendrá un conjunto de documentos:
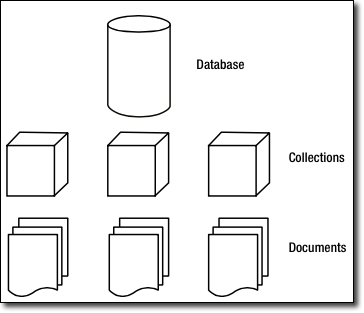
Además, MongoDB soporta índices, igual que cualquier RDMS, para acelerar la búsqueda de datos. Al realizar cualquier consulta, se devuelve un cursor, con el cual podemos hacer cosas tales como contar, ordenar, limitar o saltar documentos.
BSON¶
Mediante JavaScript podemos crear objetos que se representan con JSON. Internamente, MongoDB almacena los documentos mediante BSON (Binary JSON). Podemos consultar la especificación en http://BSONSpec.org
BSON representa un superset de JSON ya que:
- Permite almacenar datos en binario
- Incluye un conjunto de tipos de datos no incluidos en JSON, como pueden ser
ObjectId,DateoBinData.
Podemos consultar todos los tipos que soporta un objeto BSON en http://docs.mongodb.org/manual/reference/bson-types/
Un ejemplo de un objeto BSON podría ser:
var yo = {
nombre: "Aitor",
apellidos: "Medrano",
fnac: new Date("Oct 3, 1977"),
hobbies: ["programación", "videojuegos", "baloncesto"],
casado: true,
hijos: 2,
contacto: {
twitter: "@aitormedrano",
email: "a.medrano@edu.gva.es"
},
fechaCreacion: new Timestamp()
}
Los documentos BSON tienen las siguientes restricciones:
- No pueden tener un tamaño superior a 16 MB.
- El atributo
_idqueda reservado para la clave primaria. - Desde MongoDB 5.0 los nombres de los campos pueden empezar por
$y/o contener el., aunque en la medida de lo posible, es recomendable evitar su uso.
Además MongoDB:
- No asegura que el orden de los campos se respete.
- Es sensible a los tipos de los datos
- Es sensible a las mayúsculas.
Por lo que estos documentos son distintos:
{"edad": "18"}
{"edad": 18}
{"Edad": 18}
Si queremos validar si un documento JSON es válido, podemos usar http://jsonlint.com/. Hemos de tener en cuenta que sólo valida JSON y no BSON, por tanto nos dará errores en los tipos de datos propios de BSON.
Puesta en marcha¶
En la actualidad, MongoDB se comercializa mediante tres productos:
- Mongo Atlas, como plataforma cloud, con una opción gratuita mediante un cluster de 512MB.
- MongoDB Community Edition, versión gratuita para trabajar on-premise, con versiones para Windows, MacOS y Linux.
- MongoDB Enterprise Advanced, versión de pago con soporte, herramientas avanzadas de monitorización y seguridad, y administración automatizada.
Instalación¶
Desde https://www.mongodb.com/try/download/community podemos descargar la versión Community acorde a nuestro sistema operativo.
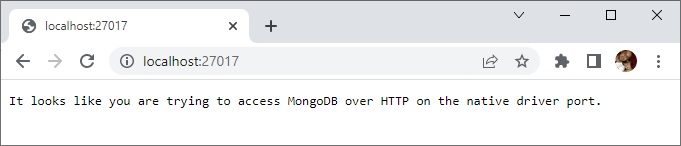
Independientemente de nuestro sistema operativo, por defecto, el demonio se lanza sobre el puerto 27017. Una vez instalado, si accedemos a http://localhost:27017 podremos ver que nos indica cómo estamos intentando acceder mediante HTTP a MongoDB mediante el puerto reservado al driver nativo.
En vez de instalarlo como un servicio en nuestra máquina, a día de hoy, es mucho más cómodo hacer uso de contenedores Docker o utilizar una solución cloud.
Docker¶
Para lanzar el contenedor de Docker al que llamaremos iadb-mongo mediante el siguiente comando:
docker run -p 127.0.0.1:27017:27017 --name iabd-mongo -d mongo
MongoDB y procesadores AVX
Si tenemos un procesador sin soporte para AVX, necesitamos instalar una versión inferior a la 5.0.
Así pues, podemos indicar la versión 4.4:
docker run -p 127.0.0.1:27017:27017 --name iabd-mongo -d mongo:4.4
A continuación vamos a descargar el conjunto de datos sampledata.archive.gz que ofrece MongoDB a modo de prueba, el cual vamos a emplear a lo largo de las diferentes sesiones.
Volvemos al terminal de nuestro sistema y copiamos los datos desde nuestro sistema a la carpeta /tmp del contenedor:
docker cp sampledata.archive.gz iabd-mongo:/tmp
Posteriormente abrimos un terminal dentro de nuestro contenedor (o mediante Attach Shell en VSCode):
docker exec -it iabd-mongo bash
Y finalmente, restauramos los datos mediante mongorestore:
mongorestore --gzip --archive=/tmp/sampledata.archive.gz
Una vez cargados, nos informará que se han restaurado 433281 documentos.
Mongo Atlas¶
Y si preferimos una solución cloud, disponemos de Mongo Atlas, que nos ofrece de manera gratuita un cluster compartido de servidores con 3 nodos y 512 MB para datos. Si queremos una solución serverless o un servidor dedicado, ya tendremos que pasar por caja.

Para comenzar a utilizar Mongo Atlas el primer paso es registrarnos y completar un cuestionario sobre nuestro uso. Tras ello:
-
Creamos el cluster de despliegue. En nuestro caso, hemos realizado el despliegue en AWS en la región de Paris (
eu-west-3) y dejado el nombre por defecto,Cluster 0.

Elección del cluster -
Creamos un usuario/contraseña para autenticar nuestra conexión. En nuestro caso, hemos creado el usuario
iabdcon la contraseñaiabdiabd(después la podemos modificar desde el menú Security -> Database Access):
Configuración del usuario En la misma pantalla, indicamos que permitimos las conexiones desde todas las direcciones IP (esta decisión sólo la tomamos por comodidad, para poder conectarnos desde casa y el centro) mediante la IP
0.0.0.0(después podemos modificar la configuración desde el menú Security -> Network Access). -
Una vez realizados los dos pasos anteriores, comenzará la creación del cluster, la cual puede tardar de 2 a 3 minutos.
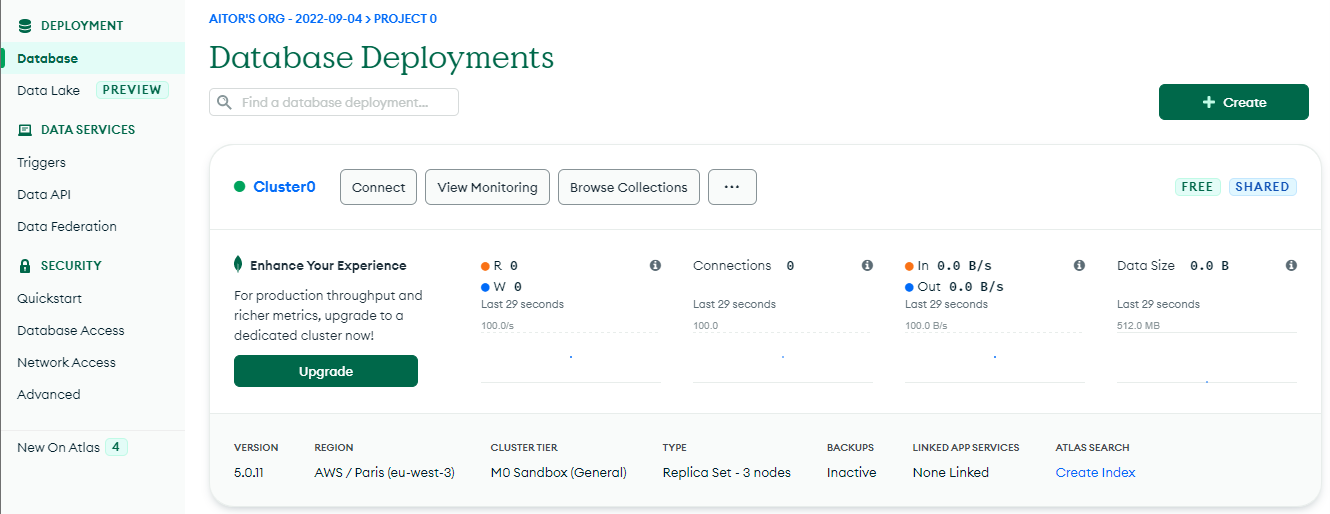
Dashboard del cluster -
A continuación, cargaremos los datos de ejemplo. Para ello, en el menú con los tres puntos (
...), elegiremos la opción Load Sample Dataset. Una vez haya finalizado, podremos ver los datos cargados pulsando sobre el botón Browse Collections:
Colecciones con los datos de prueba
Conexión segura
Mediante srv se establece una conexión segura
Finalmente, para obtener la cadena de conexión, desde el dashboard del cluster con la opción Connect o desde la pestaña Cmd Line Tools del propio cluster, podremos obtener la cadena de conexión, que tendrá un formato similar a :
mongodb+srv://usuario:password@host/basededatos
A continuación, vamos a conocer las diferentes herramientas que nos ofrece MongoDB para posteriormente estudiar todas las operaciones que podemos realizar.
mongosh¶
Tras arrancar el demonio mongod (el cual se lanza automáticamente mediante Docker o con el cluster de Mongo Atlas) llega el momento de acceder mediante el cliente mongosh (en versiones anteriores el comando utilizado era mongo), el cual funciona igual que un shell, de modo que con la fecha hacia arriba visualizaremos el último comando. El cliente utiliza JavaScript como lenguaje de interacción con la base de datos.
Si nos conectamos desde Docker, no necesitamos instalarlo. Primero nos conectamos al contenedor:
docker exec -it iabd-mongo bash
Al conectar con mongosh si no le indicamos nada se conectará por defecto a la base de datos test de localhost. Si queremos conectarnos a una base de datos concreta, por ejemplo a sample_training, la pasaremos como parámetro:
root@3ad17b675fb1:/# mongosh sample_training
Current Mongosh Log ID: 6316498f30f8283fedcfabc2
Connecting to: mongodb://127.0.0.1:27017/sample_training?directConnection=true&serverSelectionTimeoutMS=2000
Using MongoDB: 5.0.4
Using Mongosh: 1.1.2
Si queremos ver las bases de datos que existen ejecutaremos el comando show dbs:
sample_training> show dbs;
admin 41 kB
config 73.7 kB
local 73.7 kB
sample_airbnb 55.1 MB
sample_analytics 9.9 MB
sample_geospatial 999 kB
sample_mflix 48.5 MB
sample_restaurants 6.2 MB
sample_supplies 991 kB
sample_training 43.4 MB
sample_weatherdata 2.49 MB
Si nos quisiéramos conectar a nuestro cluster de Mongo Atlas utilizaremos la cadena de conexión tras el comando mongosh:
root@3ad17b675fb1:/# mongosh mongodb+srv://iabd:iabdiabd@cluster0.dfaz5er.mongodb.net/test
Current Mongosh Log ID: 63164ac26030844c1576f8b4
Connecting to: mongodb+srv://<credentials>@cluster0.dfaz5er.mongodb.net/test
Using MongoDB: 5.0.11
Using Mongosh: 1.1.2
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
Atlas atlas-4wikkb-shard-0 [primary] test>
Uso externo
Si no queremos tener que conectarnos al contenedor o vamos a trabajar con un servidor remoto, podemos instalar únicamente el shell desde https://www.mongodb.com/try/download/shell
MongoDB Database Tools¶
Además del propio servidor de MongoDB y el cliente para conectarse a él, MongoDB ofrece un conjunto de herramientas para interactuar con las bases de datos, permitiendo crear y restaurar copias de seguridad.
Si estamos interesados en introducir o exportar una colección de datos mediante JSON, podemos emplear los comandos mongoimport y mongoexport:
mongoimport -d nombreBaseDatos -c coleccion –-file nombreFichero.json
mongoexport -d nombreBaseDatos -c coleccion nombreFichero.json
Estas herramientas interactúan con datos JSON y no sobre toda la base de datos.
Un caso particular y muy común es importar datos que se encuentran en formato CSV/TSV. Para ello, emplearemos el parámetro --type csv:
mongoimport --type tsv -d test -c poblacion --headerline --drop poblacionEspanya2013.tsv
En vez de realizar un export, es más conveniente realizar un backup en binario mediante mongodump, el cual genera ficheros BSON. Estos archivos posteriormente se restauran mediante mongorestore:
mongodump -d nombreBaseDatos nombreFichero.bson
mongorestore -d nombreBaseDatos nombreFichero.bson
Autoevaluación
Intenta exportar los datos de la base de datos sample_training desde MongoAtlas. Veras que ha creado una carpeta que contiene dos archivos ¿Cuáles son? ¿Qué contiene cada uno de ellos y cual es su formato?
Si necesitamos transformar un fichero BSON a JSON (de binario a texto), tenemos el comando bsondump:
bsondump file.bson > file.json
Info
Más información sobre copias de seguridad en https://www.mongodb.com/docs/manual/core/backups/.
Para poder trabajar con MongoDB desde cualquier aplicación necesitamos un driver. MongoDB ofrece drivers oficiales para casi todos los lenguajes de programación actuales. En la sesión 28 de 'MongoDB y Python' trabajaremos con PyMongo.
Monitorización
Tanto mongostat como mongotop permiten visualizar el estado del servidor MongoDB, así como algunas estadísticas sobre su rendimiento. Si trabajamos con MongoAtlas estas herramientas están integradas en las diferentes herramientas de monitorización de la plataforma.
En versiones anteriores, una herramienta de terceros bastante utilizada era RoboMongo / Robo3T / Studio3T el cual extiende el shell y ofrece un IDE más amigable. A días de hoy, MongoDB tiene su propio IDE conocido como Mongo Compass.
MongoDB Compass¶
En el curso nos vamos a centrar en el uso del shell y la conectividad de MongoDB mediante Python, pero no está de más conocer las herramientas visuales que facilitan el trabajo con MongoDB en el día a día.
Una de ellas es MongoDB Compass, que facilita la exploración y manipulación de los datos. De una manera flexible e intuitiva, Compass ofrece visualizaciones detalladas de los esquemas, métricas de rendimiento en tiempo real así como herramientas para la creación de consultas.
Existen tres versiones de Compass, una completa con todas las características, una de sólo lectura sin posibilidad de insertar, modificar o eliminar datos (perfecta para analítica de datos) y una última versión isolated que solo permite la conexión a una instancia local.
Una vez descargada e instalada la versión que nos interesa, tras crear la conexión a partir de la cadena de conexión (similar a mongodb+srv://iabd:iabdiabd@cluster0.4hm7u8y.mongodb.net/test), veremos en el menú de la izquierda un resumen del cluster, así como las consultas que vayamos almacenando y las diferentes bases de datos almacenadas:
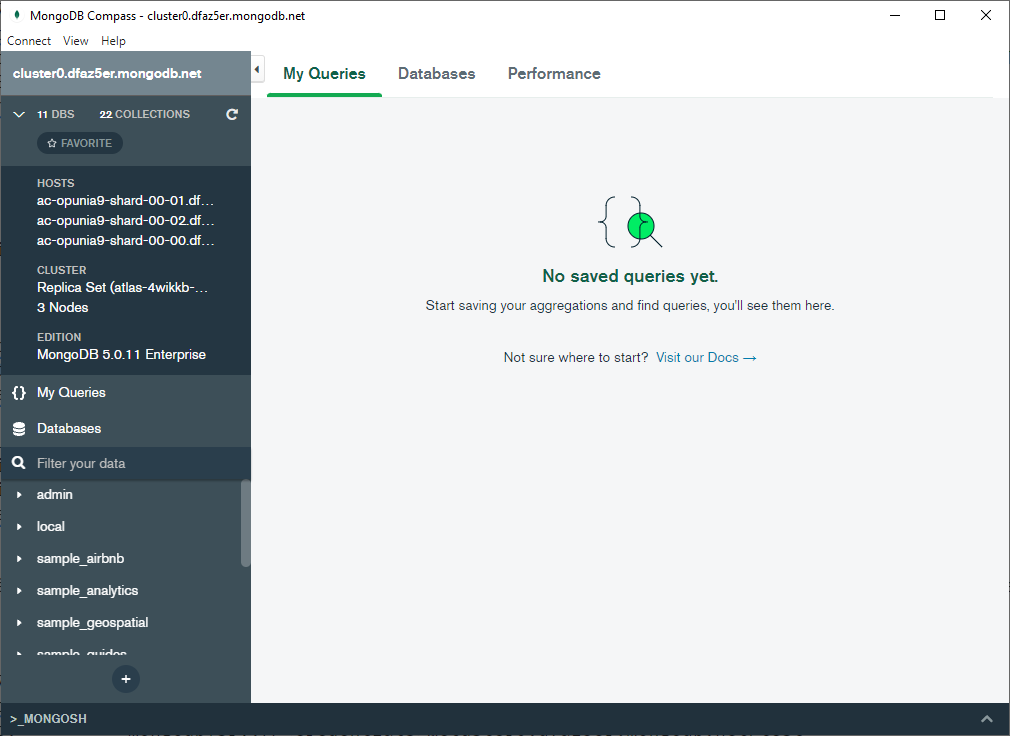
Si seleccionamos una base de datos concreta, y de ella, una colección en el menú de la izquierda, en el panel central tendremos una visualización de los datos contenidos, así como opciones para ver su esquema, realizar consultas agregadas, editar los índices, etc... Además, podremos realizar consultas sobre los datos:
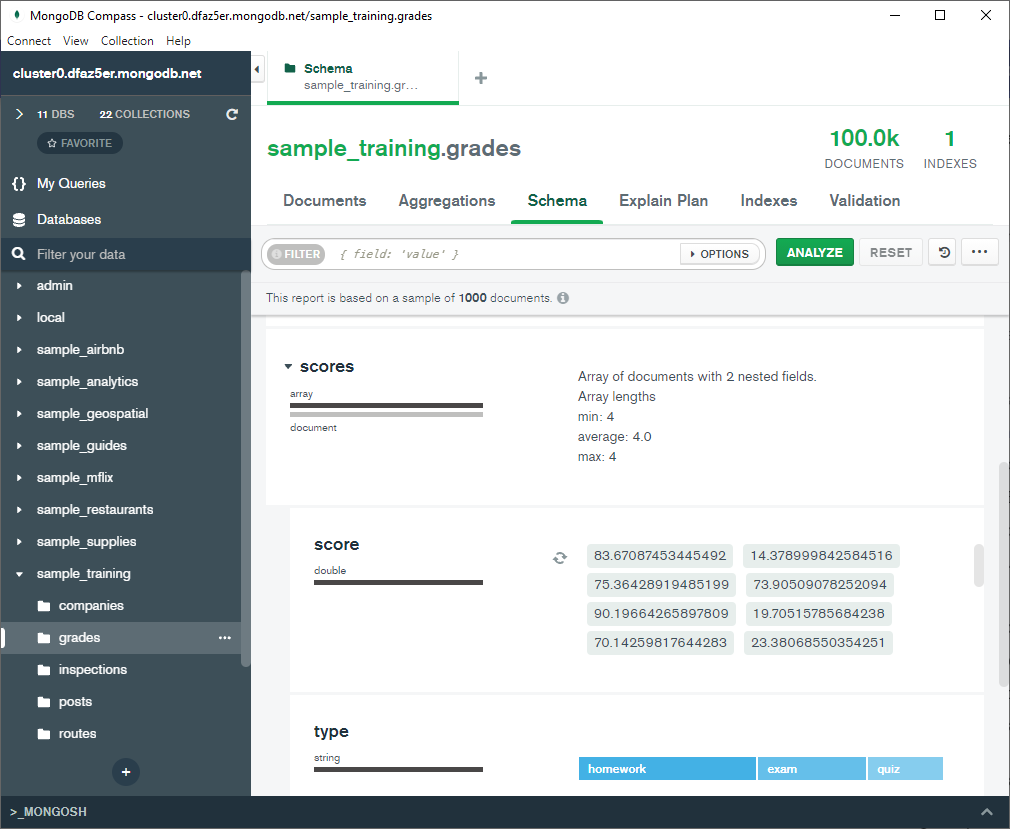
mongosh en Compass
Si te fijas, en la barra inferior podemos desplegar un panel para interactuar mediante comandos como lo haríamos desde mongosh.
MongoDB for VSCode¶
También podemos utilizar la extensión que lleva VSCode para trabajar con MongoDB.
Tras su instalación creamos una conexión a partir de la cadena de conexión (similar a mongodb+srv://iabd:iabdiabd@cluster0.4hm7u8y.mongodb.net/test), y una vez conectados, podremos recorrer las colecciones con los datos así como utilizar un playground para interactuar de manera similar al shell:
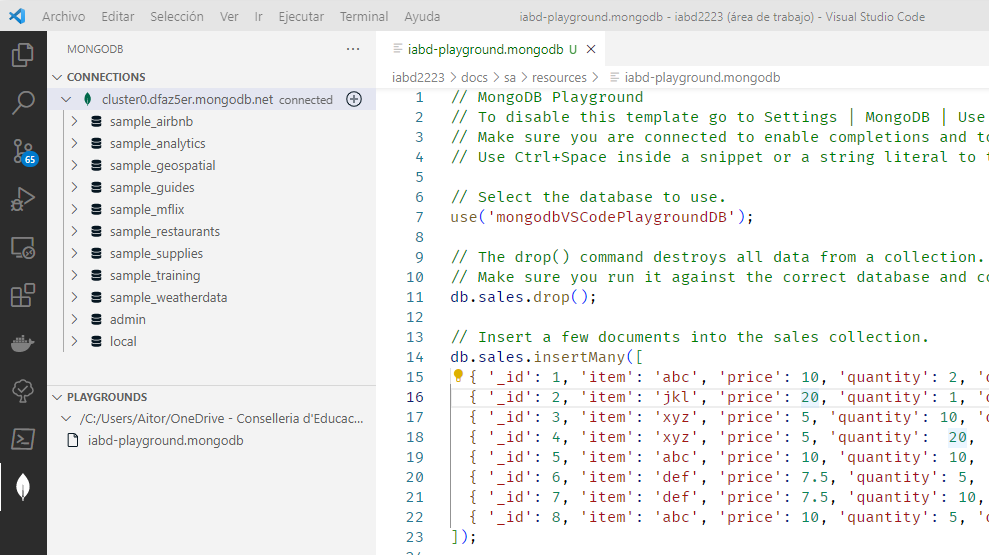
Hola MongoDB¶
Pues una vez que ya nos hemos conectado a MongoDB mediante mongosh, vamos a empezar a interactuar con los datos.
En cualquier momento podemos cambiar la base de datos activa mediante use nombreBaseDatos. Si la base de datos no existiese, MongoDB creará dicha base de datos. Esto es una verdad a medias, ya que la base de datos realmente se crea al insertar datos dentro de alguna colección.
Así pues, vamos a crear nuestra base de datos iabd:
use iabd
Una vez creada, podemos crear nuestra primera colección, que llamaremos people, e insertaremos un persona con nuestros datos personales mediante el método insertOne, al que le pasamos un objeto JSON:
db.people.insertOne({ nombre: "Aitor Medrano", edad: 45, profesion: "Profesor" })
Tras ejecutar el comando, veremos que nos devuelve un objeto JSON con su ACK y el identificador del documento insertado:
{
acknowledged: true,
insertedId: ObjectId("6316fc938cc2bc168bfed066")
}
Una vez insertada, sólo nos queda realizar una consulta para recuperar los datos y comprobar que todo funciona correctamente mediante el método findOne:
db.people.findOne()
Lo que nos dará como resultado un objeto JSON que contiene un atributo _id con el mismo identificador mostrado anteriormente, además de los que le añadimos al insertar la persona:
{
_id: ObjectId("6316fc938cc2bc168bfed066"),
nombre: 'Aitor Medrano',
edad: 45,
profesion: 'Profesor'
}
Como podemos observar, todas las instrucciones van a seguir el patrón de db.nombreColeccion.operacion().
Trabajando con el shell¶
Antes de entrar en detalles en las instrucciones necesarias para realizar las operaciones CRUD, veamos algunos comandos que nos serán muy útiles al interactuar con el shell:
| Comando | Función |
|---|---|
show dbs |
Muestra el nombre de las bases de datos |
show collections |
Muestra el nombre de las colecciones |
db |
Muestra el nombre de la base de datos que estamos utilizando |
db.dropDatabase() |
Elimina la base de datos actual |
db.help() |
Muestra los comandos disponibles |
db.version() |
Muestra la versión actual del servidor |
En el resto de la sesión vamos a hacer un uso intenso del shell de MongoDB. Por ejemplo, si nos basamos en el objeto definido en el apartado de BSON, podemos ejecutar las siguientes instrucciones:
> db.people.insertOne(yo) // (1)
< {
acknowledged: true,
insertedId: ObjectId("631704a042aae0893122f2d6")
}
> db.people.find() // (2)
< [
{
_id: ObjectId("6316fc938cc2bc168bfed066"),
nombre: 'Aitor Medrano',
edad: 45,
profesion: 'Profesor'
},
{
_id: ObjectId("631704a042aae0893122f2d6"),
nombre: 'Aitor',
apellidos: 'Medrano',
fnac: ISODate("1977-10-03T00:00:00.000Z"),
hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
casado: true,
hijos: 2,
contacto: { twitter: '@aitormedrano', email: 'a.medrano@edu.gva.es' },
fechaCreacion: Timestamp({ t: 1662452896, i: 1 })
}
]
> yo.profesion = "Profesor"
< Profesor
> db.people.insertOne(yo) // (3)
< [
{
_id: ObjectId("6316fc938cc2bc168bfed066"),
nombre: 'Aitor Medrano',
edad: 45,
profesion: 'Profesor'
},
{
_id: ObjectId("631704a042aae0893122f2d6"),
nombre: 'Aitor',
apellidos: 'Medrano',
fnac: ISODate("1977-10-03T00:00:00.000Z"),
hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
casado: true,
hijos: 2,
contacto: { twitter: '@aitormedrano', email: 'a.medrano@edu.gva.es' },
fechaCreacion: Timestamp({ t: 1662452896, i: 1 })
},
{
_id: ObjectId("6317056d42aae0893122f2d7"),
nombre: 'Aitor',
apellidos: 'Medrano',
fnac: ISODate("1977-10-03T00:00:00.000Z"),
hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
casado: true,
hijos: 2,
contacto: { twitter: '@aitormedrano', email: 'a.medrano@edu.gva.es' },
fechaCreacion: Timestamp({ t: 1662453101, i: 1 }),
profesion: 'Profesor'
}
]
> db.people.countDocuments() // (4)
< 3
- Si queremos insertar un documento en una colección, hemos de utilizar el método
insertOnepasándole como parámetro el documento que queremos insertar, ya sea a partir de una variable o el propio documento en sí. findrecupera todos los documentos de la colección- Modificamos nuestro documento y los volvemos a insertar. Realmente va a crear un nuevo documento, y no se va a quejar de que ya exista, porque nuestro documento no contiene ningún atributo identificador, por lo que considera que se trata de una nueva persona.
- Obtenemos la cantidad de documentos de la colección mediante
countDocuments.
Con este ejemplo, hemos podido observar como los documentos de una misma colección no tienen por qué tener el mismo esquema, ni hemos necesitado definirlo explícitamente antes de insertar datos. Así pues, el esquema se irá generando y actualizando conforme se inserten documentos. Más adelante veremos que podemos definir un esquema para validar que los datos que insertamos cumplan restricciones de tipos de datos o elementos que obligatoriamente deben estar rellenados.
Empleando JavaScript¶
Ya hemos comentado que el shell utiliza JavaScript como lenguaje de interacción, por lo que podemos almacenar los comandos en un script externo y ejecutarlo mediante load():
load("scripts/misDatos.js");
load("/data/db/scripts/misDatos.js");
Si hacemos una referencia relativa, lo hace respecto a la ruta desde la cual se ejecuta el shell mongosh.
Otra manera de lanzar un script es hacerlo desde la línea de comandos, pasándole como segundo parámetro el script a ejecutar:
mongosh iabd misDatos.js
Si el código a ejecutar no necesita almacenarse en un script externo, el propio shell permite introducir instrucciones en varias líneas:
> for (var i=0;i<10;i++) {
... db.espias.insertOne({"nombre":"James Bond " + i, "agente":"00" + i});
... }
< {
acknowledged: true,
insertedId: ObjectId("63171d2142aae0893122f2e1")
}
> db.espias.find()
< [
{
_id: ObjectId("63171d2142aae0893122f2d8"),
nombre: 'James Bond 0',
agente: '000'
},
{
_id: ObjectId("63171d2142aae0893122f2d9"),
nombre: 'James Bond 1',
agente: '001'
},
...
{
_id: ObjectId("63171d2142aae0893122f2e1"),
nombre: 'James Bond 9',
agente: '009'
}
]
ObjectId¶
En MongoDB, el atributo _id es único dentro de la colección, y hace la función de clave primaria. Se le asocia un ObjectId, el cual es un tipo BSON de 12 bytes que se crea mediante:
- el timestamp actual (4 bytes)
- un valor aleatorio y único por máquina y proceso (5 bytes)
- un contador inicializado a número aleatorio (3 bytes).
Este objeto lo crea el driver y no MongoDB, por lo cual no deberemos considerar que siguen un orden concreto, ya que clientes diferentes pueden tener timestamps desincronizados. Lo que sí que podemos obtener a partir del ObjectId es la fecha de creación del documento, mediante el método getTimestamp() del atributo _id.
Obteniendo la fecha de creación de un documento
> db.people.findOne()._id
< ObjectId("6316fc938cc2bc168bfed066")
> db.people.findOne()._id.getTimestamp()
< ISODate("2022-09-06T07:53:55.000Z")
Este identificador es global, único e inmutable. Esto es, no habrá dos repetidos y una vez un documento tiene un _id, éste no se puede modificar.
Si en la definición del objeto a insertar no ponemos el atributo identificador, MongoDB creará uno de manera automática. Si lo ponemos nosotros de manera explícita, MongoDB no añadirá ningún ObjectId. Eso sí, debemos asegurarnos que sea único (podemos usar números, cadenas, etc…).
Por lo tanto, podemos asignar un identificador al insertar:
> db.people.insert({_id:4, nombre:"Marina", edad:14 })
< { acknowledged: true, insertedIds: { '0': 4 } }
Tipos de datos
Cuidado con los tipos, ya que no es lo mismo insertar un atributo con edad:14 (se considera el campo como entero) que con edad:"14", ya que considera el campo como texto.
O también, si queremos podemos hacer que el _id de un documento sea un documento en sí, y no un entero, para ello, al insertarlo, podemos asignarle un objeto JSON al atributo identificador:
> db.people.insertOne({_id:{nombre:'Aitor', apellidos:'Medrano', twitter:'@aitormedrano'}, ciudad:'Elx'})
< {
acknowledged: true,
insertedId: { nombre: 'Aitor', apellidos: 'Medrano', twitter: '@aitormedrano' }
}
Recuperando datos¶
Para recuperar los datos de una colección o un documento en concreto usaremos el método find():
> db.people.find()
< { _id: ObjectId("6316fc1597eb703de2add36e"),
nombre: 'Aitor',
edad: 45,
profesion: 'Profesor' }
{ _id: ObjectId("6317048697eb703de2add36f"),
nombre: 'Aitor',
apellidos: 'Medrano',
fnac: 1977-10-02T23:00:00.000Z,
hobbies: [ 'programación', 'videojuegos', 'baloncesto' ],
casado: true,
hijos: 2,
contacto: { twitter: '@aitormedrano', email: 'a.medrano@edu.gva.es' },
fechaCreacion: Timestamp({ t: 1662452870, i: 3 }) }
El método find() sobre una colección devuelve un cursor a los datos obtenidos, el cual se queda abierto con el servidor y que se cierra automáticamente a los 30 minutos de inactividad o al finalizar su recorrido. Si hay muchos resultados, la consola nos mostrará un subconjunto de los datos (20). Si queremos seguir obteniendo resultados, solo tenemos que introducir it, para que continúe iterando el cursor.
En cambio, si sólo queremos recuperar un documento hemos de utilizar findOne():
> db.people.findOne()
> { _id: ObjectId("6316fc1597eb703de2add36e"),
nombre: 'Aitor',
edad: 45,
profesion: 'Profesor' }
Preparando los ejemplos
Para los siguientes ejemplos, vamos a utilizar una colección de 10.000 documentos sobre los viajes realizados por los usuarios de una empresa de alquiler de bicicletas, los cuales han sido extraídos de https://ride.citibikenyc.com/system-data.
Esta colección (trips) está cargada tanto en el cluster de MongoAtlas como en el contenedor de Docker (si has seguido las instrucciones) de la base de datos sample_training.
Un ejemplo de viaje sería:
> use sample_training
< 'switched to db sample_training'
> db.trips.findOne()
< { _id: ObjectId("572bb8222b288919b68abf5b"),
tripduration: 889,
'start station id': 268,
'start station name': 'Howard St & Centre St',
'end station id': 3002,
'end station name': 'South End Ave & Liberty St',
bikeid: 22794,
usertype: 'Subscriber',
'birth year': 1961,
'start station location': { type: 'Point', coordinates: [ -73.99973337, 40.71910537 ] },
'end station location': { type: 'Point', coordinates: [ -74.015756, 40.711512 ] },
'start time': 2016-01-01T00:01:06.000Z,
'stop time': 2016-01-01T00:15:56.000Z }
Criterios en consultas¶
Al hacer una consulta, si queremos obtener datos mediante más de un criterio, en el primer parámetro del find podemos pasar un objeto JSON con los campos a cumplir (condición Y).
db.trips.find({'start station id': 405, 'end station id': 146})
{ _id: ObjectId("572bb8222b288919b68ad197"),
tripduration: 1143,
'start station id': 405,
'start station name': 'Washington St & Gansevoort St',
'end station id': 146,
'end station name': 'Hudson St & Reade St',
bikeid: 23724,
usertype: 'Customer',
'birth year': '',
'start station location': { type: 'Point', coordinates: [ -74.008119, 40.739323 ] },
'end station location': { type: 'Point', coordinates: [ -74.0091059, 40.71625008 ] },
'start time': 2016-01-01T13:37:45.000Z,
'stop time': 2016-01-01T13:56:48.000Z }
{ _id: ObjectId("572bb8222b288919b68ad191"),
tripduration: 1143,
'start station id': 405,
'start station name': 'Washington St & Gansevoort St',
'end station id': 146,
'end station name': 'Hudson St & Reade St',
bikeid: 17075,
usertype: 'Customer',
'birth year': '',
'start station location': { type: 'Point', coordinates: [ -74.008119, 40.739323 ] },
'end station location': { type: 'Point', coordinates: [ -74.0091059, 40.71625008 ] },
'start time': 2016-01-01T13:37:38.000Z,
'stop time': 2016-01-01T13:56:42.000Z }
Consejo de Rendimiento
Las consultas disyuntivas, es decir, con varios criterios u operador $and, deben filtrar el conjunto más pequeño cuanto más pronto posible.
Supongamos que vamos a consultar documentos que cumplen los criterios A, B y C. Digamos que el criterio A lo cumplen 40.000 documentos, el B lo hacen 9.000 y el C sólo 200. Si filtramos A, luego B, y finalmente C, el conjunto que trabaja cada criterio es muy grande.
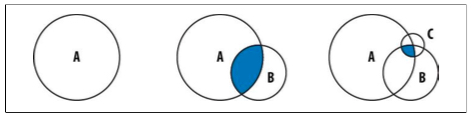
En cambio, si hacemos una consulta que primero empiece por el criterio más restrictivo, el resultado con lo que se intersecciona el siguiente criterio es menor, y por tanto, se realizará más rápido.

MongoDB también ofrece operadores lógicos para los campos numéricos:
| Comparador | Operador |
|---|---|
menor que (<) |
$lt |
menor o igual que (≤) |
$lte |
mayor que (>) |
$gt |
mayor o igual que (≥) |
$gte |
Estos operadores se pueden utilizar de forma simultánea sobre un mismo campo o sobre diferentes campos, sobre campos anidados o que forman parte de un array, y se colocan como un nuevo documento en el valor del campo a filtrar, compuesto del operador y del valor a comparar mediante la siguiente sintaxis:
db.<coleccion>.find({ <campo>: { <operador>: <valor> } })
Por ejemplo, para recuperar los viajes que han durado menos de 5 minutos o comprendidos entre 3 y 5 minutos (el campo almacena el tiempo en segundos), podemos hacer:
db.trips.find({ "tripduration": {$lt:300} })
db.trips.find({ "tripduration": {$gt:180, $lte:300} })
Para los campos de texto, además de la comparación directa, podemos usar el operador $ne para obtener los documentos cuyo campos no tienen un determinado valor (not equal). Así pues, podemos usarlo para averiguar todos los trayectos realizados por usuarios que no son subscriptores (Subscriber):
db.trips.find({ "usertype": {$ne:"Subscriber"} })
Por supuesto, podemos tener diferentes operadores en campos distintos. Por ejemplo, si queremos ver los viajes de menos de un minuto y medio realizado por usuarios que no son subscriptores haríamos:
db.trips.find({ "tripduration": {$lt:90}, "usertype": {$ne:"Subscriber"} })
Case sensitive
Las comparaciones de cadenas se realizan siguiendo el orden UTF8, similar a ASCII, con lo cual no es lo mismo buscar un rango entre mayúsculas que minúsculas.
Con cierto parecido a la condición de valor no nulo de las BBDD relacionales y teniendo en cuenta que la libertad de esquema puede provocar que un documento tenga unos campos determinados y otro no lo tenga, podemos utilizar el operador $exists si queremos averiguar si un campo existe (y por tanto tiene algún valor).
db.people.find({"edad":{$exists:true}})
Polimorfismo
Mucho cuidado al usar polimorfismo y almacenar en un mismo campo un entero y una cadena, ya que al hacer comparaciones para recuperar datos, no vamos a poder mezclar cadenas con valores numéricos. Se considera un antipatrón el mezclar tipos de datos en un campo.
Pese a que ciertos operadores contengan su correspondiente operador negado, MongoDB ofrece el operador $not. Éste puede utilizarse conjuntamente con otros operadores para negar el resultado de los documentos obtenidos.
Por ejemplo, si queremos obtener todas las personas cuya edad no sea múltiplo de 5, podríamos hacerlo así:
db.people.find({edad:{$not: {$mod: [5,0]}}})
Expresiones regulares¶
Finalmente, si queremos realizar consultas sobre partes de un campo de texto, hemos de emplear expresiones regulares. Para ello, tenemos el operador $regexp o, de manera más sencilla, indicando como valor la expresión regular a cumplir:
Por ejemplo, para buscar la cantidad de viajes que salen da alguna estación cuyo nombre contenga Central Park podemos hacer:
db.trips.find({"start station name":/Central Park/}).count()
db.trips.find({"start station name":/central park/i}).count()
db.trips.find({"start station name":{$regex:/central park/i}}).count()
Búsquedas sobre textos
Si vamos a realizar búsquedas intensivas sobre texto, desde MongoDB han creado un producto específico dentro del ecosistema de Mongo Atlas el cual ofrece un mejor rendimiento y mayor funcionalidad que el uso de expresiones regulares, conocido con Mongo Atlas Search.
Si usamos una solución on-premise, mediante índices de texto y el operator $text podemos realizar búsquedas.
Operador $expr¶
El operador $expr es un operador de consulta expresiva que permite utilizar expresiones de agregación dentro de las consultas.
Permite utilizar variables y sentencias condicionales, asi como comparar campos dentro de un documento. Así pues, si queremos comparar valores entre dos campos, podemos hacerlo mediante $expr referenciando a los campos anteponiendo un dolar ($) delante del campo, de manera que si queremos obtener los viajes que comienzan y finalizan en la misma estación podemos hacer:
db.trips.find({ "$expr": { "$eq": [ "$end station id", "$start station id" ]}})
Al poner el $ delante de un campo, en vez de referenciar al campo, lo que hace es referenciar a su valor, por lo que $end station id está referenciando al valor del campo end station id.
Otros operadores
El operador $type permite recuperar documentos que dependan del tipo de campo que contiene.
El operador $where permite introducir una expresión JavaScript.
Proyección de campos¶
Las consultas realizadas hasta ahora devuelven los documentos completos. Si queremos que devuelva un campo o varios campos en concreto, hemos de pasar un segundo parámetro de tipo JSON con aquellos campos que deseamos mostrar con el valor true o 1. Destacar que si no se indica nada, por defecto siempre mostrará el campo _id
> db.trips.find({'start station id': 405, 'end station id': 146}, {tripduration: 1})
< { _id: ObjectId("572bb8222b288919b68ad191"),
tripduration: 1143 }
Por lo tanto, si queremos que no se muestre el _id, lo podremos a false o 0:
> db.trips.find({'start station id': 405, 'end station id': 146}, {tripduration: 1, _id:0})
< { tripduration: 1143 }
No mezcles
Al hacer una proyección, no podemos mezclar campos que se vean (1) con los que no ( 0). Es decir, hemos de hacer algo similar a:
db.<coleccion>.find({ <consulta> }, {<campo1>: 1, <campo2>: 1})
db.<coleccion>.find({ <consulta> }, {<campo1>: 0, <campo2>: 0})
Así pues, sólo se mezclará la visibilidad de los campos cuando queramos ocultar el _id.
Condiciones compuestas con Y / O¶
Para usar la conjunción o la disyunción, tenemos los operadores $and y $or. Son operadores prefijo, de modo que se ponen antes de las subconsultas que se van a evaluar. Estos operadores trabajan con arrays, donde cada uno de los elementos es un documento con la condición a evaluar, de modo que se realiza la unión entre estas condiciones, aplicando la lógica asociada a AND y a OR.
db.trips.find({ $or:[{'start station id': 405}, {'end station id': 146}] })
db.trips.find({ $or:[{ "tripduration": {$lte:70}}, { "tripduration": {$gte:3600}}] })
Realmente el operador $and no se suele usar porque podemos anidar en la consulta dos criterios, al poner uno dentro del otro. Así pues, estas dos consultas hacen lo mismo:
db.trips.find({'start station id': 405, 'end station id': 146})
db.trips.find({ $and:[ {'start station id': 405}, {'end station id': 146} ] })
Consejo de Rendimiento
Las consultas conjuntivas, es decir, con varios criterios excluyentes u operador $or, deben filtrar el conjunto más grande cuanto más pronto posible.
Supongamos que vamos a consultar los mismos documentos que cumplen los criterios A (40.000 documentos), B (9.000 documentos) y C (200 documentos).
Si filtramos C, luego B, y finalmente A, el conjunto de documentos que tiene que comprobar MongoDB es muy grande.
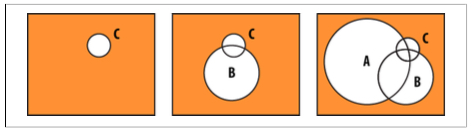
En cambio, si hacemos una consulta que primero empiece por el criterio menos restrictivo, el conjunto de documentos sobre el cual va a tener que comprobar siguientes criterios va a ser menor, y por tanto, se realizará más rápido.

También podemos utilizar el operado $nor, que no es más que la negación de $or y que obtendrá aquellos documentos que no cumplan ninguna de las condiciones.
Autoevaluación
Que obtendríamos al ejecutar la siguiente consulta:
db.trips.find({ "tripduration": {$lte:65}, $nor:[ {usertype:"Customer"}, {"birth year":1989} ] })
Finalmente, si queremos indicar mediante un array los diferentes valores que puede cumplir un campo, podemos utilizar el operador $in:
db.trips.find({ "birth year": {$in: [1977, 1980]} })
Por supuesto, también existe su negación mediante $nin.
Condiciones sobre objetos anidados¶
Si queremos acceder a campos de subdocumentos, siguiendo la sintaxis de JSON, se utiliza la notación punto. Esta notación permite acceder al campo de un documento anidado, da igual el nivel en el que esté y su orden respecto al resto de campos.
Preparando los ejemplos
Para los siguientes ejemplos sobre documentos anidados y arrays, vamos a utilizar una colección de 500 documentos sobre mensajes de un blog.
Esta colección (posts) está cargada tanto en el cluster de MongoAtlas como en el contenedor de Docker (si has seguido las instrucciones) de la base de datos sample_training.
Un ejemplo de mensaje sería:
> use sample_training
'switched to db sample_training'
> db.posts.findOne()
< { _id: ObjectId("50ab0f8bbcf1bfe2536dc3f9"),
body: 'Amendment I\n<p>Congress shall make ...."\n<p>\n',
permalink: 'aRjNnLZkJkTyspAIoRGe',
author: 'machine',
title: 'Bill of Rights',
tags:
'santa',
'xylophone',
'math',
'dream',
'action' ],
comments:
[ { body: 'Lorem ipsum dolor ...',
email: 'HvizfYVx@pKvLaagH.com',
author: 'Santiago Dollins' },
{ body: 'Lorem ipsum dolor sit...',
email: 'WpOUCpdD@hccdxJvT.com',
author: 'Jaclyn Morado' },
{ body: 'Lorem ipsum dolor sit amet...',
email: 'OgDzHfFN@cWsDtCtx.com',
author: 'Houston Valenti' }],
date: 2012-11-20T05:05:15.231Z }
Para acceder al autor de los comentarios de un mensaje usaríamos la propiedad comments.author.
Por ejemplo, para averiguar los mensajes titulados Bill of Rights y que tienen algún comentario creado por Santiago Dollins haríamos:
db.posts.find({title: 'Bill of Rights', "comments.author":'Santiago Dollins'})
Consultas sobre arrays¶
Si trabajamos con arrays, vamos a poder consultar el contenido de una posición del mismo tal como si fuera un campo normal, siempre que sea un campo de primer nivel, es decir, no sea un documento embebido dentro de un array.
Si queremos filtrar teniendo en cuenta el número de ocurrencias del array, podemos utilizar:
$allpara filtrar ocurrencias que tienen todos los valores del array, es decir, los valores pasados a la consulta serán un subconjunto del resultado. Puede que devuelva los mismos, o un array con más campos (el orden no importa)$in, igual que SQL, para obtener las ocurrencias que cumple con alguno de los valores pasados (similar a usar$orsobre un conjunto de valores de un mismo campo). Si queremos su negación, usaremos$nin, para obtener los documentos que no cumplen ninguno de los valores.
Por ejemplo, si queremos obtener los mensajes que contenga las etiquetas dream y action tendríamos:
db.posts.find( {tags: {$all: ["dream", "action"]}} )
En cambio, si queremos los mensajes que contengan alguna de esas etiquetas haríamos:
db.posts.find( {tags: {$in: ["dream", "action"]}} )
Si el array contiene documentos y queremos filtrar la consulta sobre los campos de los documentos del array, tenemos que utilizar $elemMatch, de manera que obtengamos aquellos que al menos encuentre un elemento que cumpla el criterio. Así pues, si queremos recuperar los mensajes que tienen un comentario cuyo autor sea Santiago Dollins haríamos:
db.posts.find( {comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}} )
Criterio con notación punto
En el ejemplo anterior, si sólo hubiéramos tenido un campo para el filtrado, podríamos haber utilizado la notación punto comments.author.
Si sólo queremos los comentarios escritos por un determinado autor, además de en el filtrado, hemos de indicarlo en la proyección:
db.posts.find(
{comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}},
{comments: {$elemMatch: { author: "Santiago Dollins", email: "xnZKyvWD@jHfVKtUh.com"}}} )
Si lo que nos interesa es la cantidad de elementos que contiene un array, emplearemos el operador $size. Por ejemplo, para obtener los mensajes que tienen 10 etiquetas haríamos:
db.posts.find( {tags : {$size : 10}} )
Finalmente, a la hora de proyectar los datos, si no estamos interesados en todos los valores de un campo que es un array, podemos restringir el resultado mediante el operador $slice. Así pues, si quisiéramos obtener los mensajes titulados US Constitution y que de esos mensajes, mostrara sólo tres etiquetas y dos comentarios, haríamos:
> db.posts.find( {title : "US Constitution"}, {comments: {$slice:2}, tags: {$slice:3}} )
< { _id: ObjectId("50ab0f8bbcf1bfe2536dc416"),
body: 'We the People ...',
permalink: 'NhWDUNColpvxFjovsgqU',
author: 'machine',
title: 'US Constitution',
tags: [ 'engineer', 'granddaughter', 'sundial' ],
comments:
[ { body: 'Lorem ipsum dolor ...',
email: 'ftRlVMZN@auLhwhlj.com',
author: 'Leonida Lafond' },
{ body: 'Lorem ipsum dolor sit...',
email: 'dsoLAdFS@VGBBuDVs.com',
author: 'Nobuko Linzey' } ],
date: 2012-11-20T05:05:15.276Z }
Conjunto de valores¶
Igual que en SQL, a partir de un colección, si queremos obtener todos los diferentes valores que existen en un campo, utilizaremos el método distinct:
> db.trips.distinct('usertype')
< [ 'Customer', 'Subscriber' ]
Si queremos filtrar los datos sobre los que se obtienen los valores, le pasaremos un segundo parámetro con el criterio a aplicar:
> db.trips.distinct('usertype', { "birth year": { $gt: 1990 } } )
< [ 'Subscriber' ]
Cursores¶
Al hacer una consulta en el shell se devuelve un cursor. Este cursor lo podemos guardar en un variable, y partir de ahí trabajar con él como haríamos mediante cualquier lenguaje de programación. Si cur es la variable que referencia al cursor, podremos utilizar los siguientes métodos:
| Método | Uso | Lugar de ejecución |
|---|---|---|
cur.hasNext() |
true/false para saber si quedan elementos |
Cliente |
cur.next() |
Pasa al siguiente documento | Cliente |
cur.limit(cantidad) |
Restringe el número de resultados a cantidad |
Servidor |
cur.sort({campo:1}) |
Ordena los datos por campo: 1 ascendente o -1 o descendente |
Servidor |
cur.skip(cantidad) |
Permite saltar cantidad elementos con el cursor |
Servidor |
La consulta no se ejecuta hasta que el cursor comprueba o pasa al siguiente documento (next/hasNext), por ello que tanto limit como sort (ambos modifican el cursor) sólo se pueden realizar antes de recorrer cualquier elemento del cursor.
Como tras realizar una consulta con find, realmente se devuelve un cursor, un uso muy habitual es encadenar una operación de find con sort y/o limit para ordenar el resultado por uno o más campos y posteriormente limitar el número de documentos a devolver.
Así pues, si quisiéramos obtener los tres viajes que más han durado, podríamos hacerlo así:
db.trips.find().sort({"tripduration":-1}).limit(3)
También podemos filtrar previamente a ordenar y limitar:
db.trips.find({usertype:"Customer"}).sort({"tripduration":-1}).limit(3)
Finalmente, podemos paginar utilizando el método skip, para mostrar viajes de 10 en 10 a partir de la tercera página, podríamos hacer algo así:
db.trips.find({usertype:"Customer"}).sort({"tripduration":-1}).limit(10).skip(20)
Autoevaluación
A partir de la colección trips, escribe un consulta que recupere los viajes realizados por subscriptores ordenados descendentemente por su duración y que obtenga los documentos de 15 al 20.
Contando Documentos¶
Para contar el número de documentos, en vez de find usaremos el método countDocuments. Por ejemplo:
> db.trips.countDocuments({"birth year":1977})
< 186
> db.trips.countDocuments({"birth year":1977, "tripduration":{$lt:600}})
< 116
count
Desde la versión 4.0, los métodos count a nivel de colección y de cursor están caducados (deprecated), y no se recomienda su utilización. Aún así, es muy común utilizarlo como método de un cursor:
db.trips.find({"birth year":1977, "tripduration":{$lt:600}}).count()
Cuando tenemos muchísimos datos, si no necesitamos exactitud pero queremos un valor estimado el cual tarde menos en conseguirse (utiliza los metadatos de las colecciones), podemos usar estimatedDocumentCount
> db.trips.estimatedDocumentCount({"birth year":1977})
< 10.000
> db.trips.estimatedDocumentCount({"birth year":1977, "tripduration":{$lt:600}})
< 10.000
Modificando documentos¶
Preparando un persona
Para este apartado, vamos a insertar dos veces la misma persona sobre la cual realizaremos las modificaciones:
db.people.insertOne({ nombre: "Aitor Medrano", edad: 45, profesion: "Profesor" })
db.people.insertOne({ nombre: "Aitor Medrano", edad: 45, profesion: "Profesor" })
Para actualizar (y fusionar datos), se utilizan los métodos updateOne / updateMany dependiendo de cuantos documentos queremos que modifique. Ambos métodos requieren 2 parámetros: el primero es la consulta para averiguar sobre qué documentos, y en el segundo parámetro, los campos a modificar utilizando los operadores de actualización:
db.people.updateOne({nombre:"Aitor Medrano"}, {$set:{nombre:"Marina Medrano", salario: 123456}})
Al realizar la modificación, el shell nos devolverá información sobre cuantos documentos ha encontrado, modificado y más información:
{ acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0 }
Como hay más de una persona con el mismo nombre, al haber utilizado updateOne sólo modificará el primer documento que ha encontrado.
¡Cuidado!
En versiones antiguas de MongoDB, además de utilizar los operadores de actualización, podíamos pasarle como parámetro un documento, de manera que MongoDB realizaba un reemplazo de los campos, es decir, si en el origen había 100 campos y en la operación de modificación sólo poníamos 2, el resultado únicamente contendría 2 campos. Es por ello, que ahora es obligatorio utilizar los operadores.
Si cuando vamos a actualizar, en el criterio de selección no encuentra el documento sobre el que hacer los cambios, no se realiza ninguna acción.
Si quisiéramos que en el caso de no encontrar nada insertase un nuevo documento, acción conocida como upsert (update + insert), hay que pasarle un tercer parámetro al método con el objeto {upsert:true}. Si encuentra el documento, lo modificará, pero si no, creará uno nuevo:
db.people.updateOne({nombre:"Andreu Medrano"},
{$set:{name:"Andreu Medrano", twitter: "@andreumedrano"}},
{upsert: true})
Operadores de actualización¶
MongoDB ofrece un conjunto de operadores para simplificar la modificación de campos.
El operador más utilizado es el operador $set, el cual admite los campos que se van a modificar. Si el campo no existe, lo creará.
Por ejemplo, para modificar el salario haríamos:
db.people.updateOne({nombre:"Aitor Medrano"}, {$set:{salario: 1000000}})
Mediante $inc podemos incrementar el valor de una variable:
db.people.updateOne({nombre:"Aitor Medrano"}, {$inc:{salario: 1000}})
Para eliminar un campo de un documento, usaremos el operador $unset.
De este modo, para eliminar el campo twitter de una persona haríamos:
db.people.updateOne({nombre:"Aitor Medrano"}, {$unset:{twitter: ''}})
Otros operadores que podemos utilizar son $mul, $min, $max y $currentDate. Podemos consultar todos los operadores disponibles en https://www.mongodb.com/docs/manual/reference/operator/update/
Autoevaluación
Tras realizar la siguiente operación sobre una colección vacía:
db.people.updateOne({nombre:'yo'}, {'$set':{'hobbies':['gaming', 'sofing']}}, {upsert: true} );
¿Cuál es el estado de la colección?
Finalmente, un caso particular de las actualizaciones es la posibilidad de renombrar un campo mediante el operador $rename:
db.people.updateMany( {_id:1}, {$rename:{'nickname':'alias', 'cell':'movil'}})
Podemos consultar todas las opciones de configuración de una actualización en https://www.mongodb.com/docs/manual/reference/method/db.collection.update/.
Control de la concurrencia¶
Cuando se hace una actualización múltiple, MongoDB no realiza la operación de manera atómica (a no ser que utilicemos transacciones desde el driver), lo que provoca que se puedan producir pausas (pause yielding). Cada documento en sí es atómico, por lo que ninguno se va a quedar a la mitad.
MongoDB ofrece el método findAndModify para encontrar y modificar un documento de manera atómica, y así evitar que, entre la búsqueda y la modificación, el estado del documento se vea afectado. Además, devuelve el documento modificado. Un caso de uso muy común es para contadores y casos similares.
db.people.findAndModify({
query: {nombre:"Marina Medrano"},
update: {$inc:{salario:100, edad:-30}},
new: true
})
Por defecto, el documento devuelto será el resultado que ha encontrado con la consulta. Si queremos que nos devuelva el documento modificado con los cambios deseados, necesitamos utilizar el parámetro new a true. Si no lo indicamos o lo ponemos a false, tendremos el comportamiento por defecto.
Actualizaciones sobre Arrays¶
Para trabajar con arrays necesitamos nuevos operadores que nos permitan tanto introducir como eliminar elementos de una manera más sencilla que sustituir todos los elementos del array.
Los operadores que podemos emplear para trabajar con arrays son:
| Operador | Propósito |
|---|---|
$push |
Añade uno o varios elementos |
$addToSet |
Añade un elemento sin duplicados |
$pull |
Elimina un elemento |
$pullAll |
Elimina varios elementos |
$pop |
Elimina el primer o el último |
Preparando los ejemplos
Para trabajar con los arrays, vamos a suponer que tenemos una colección de enlaces donde vamos a almacenar un documento por cada site, con un atributo tags con etiquetas sobre el enlace en cuestión
db.enlaces.insertOne({titulo:"www.google.es", tags:["mapas", "videos"]})
De modo que tendríamos el siguiente documento:
{ _id: ObjectId("633c60e8ac452ac9d7f9fe74"),
titulo: 'www.google.es',
tags: [ 'mapas', 'videos' ] }
Añadiendo elementos¶
Si queremos añadir uno o varios elementos, usaremos el operador $push. Cuando queremos añadir varios elementos a la vez, mediante el operador $each le pasamos un array con los datos:
db.enlaces.updateMany({titulo:"www.google.es"},
{$push: {tags:"blog"}} )
db.enlaces.updateMany({titulo:"www.google.es"},
{$push: {tags:{$each:["calendario", "email", "mapas"]}}})
Al hacer estar modificación, el resultado del documento sería:
{ _id: ObjectId("633c61b5ac452ac9d7f9fe75"),
titulo: 'www.google.es',
tags: [ 'mapas', 'videos', 'blog', 'calendario', 'email', 'mapas' ] }
Al utilizar $push no se tiene en cuenta lo que contiene el array, por tanto, si un elemento ya existe, se repetirá y tendremos duplicados. Si queremos evitar los duplicados, usaremos $addToSet:
db.enlaces.updateMany({titulo:"www.google.es"},
{$addToSet:{tags:"buscador"}})
Si queremos añadir más de un campo a la vez sin duplicados, debemos anidar el operador $each igual que hemos hecho antes:
db.enlaces.updateMany({titulo:"www.google.es"},
{$addToSet:{tags:{$each:["drive", "traductor"]}}})
En cambio, si queremos eliminar elementos de un array, usaremos el operador $pull:
db.enlaces.updateMany({titulo:"www.google.es"},
{$pull:{tags:"traductor"}})
Similar al caso anterior, con $pullAll, eliminaremos varios elementos de una sola vez:
db.enlaces.updateMany({titulo:"www.google.es"},
{$pullAll:{tags:["calendario", "email"]}})
Otra manera de eliminar elementos del array es mediante $pop, el cual elimina el primero (-1) o el último (1) elemento del array:
db.enlaces.updateMany({titulo:"www.google.es"}, {$pop:{tags:-1}})
Operador posicional¶
Por último, tenemos el operador posicional, el cual se expresa con el símbolo $ y nos permite modificar el elemento que ocupa una determinada posición del array sin saber exactamente cual es esa posición.
Supongamos que tenemos las calificaciones de los estudiantes (colección students) en un documento con una estructura similar a la siguiente:
{ "_id" : 1, "notas" : [ 80, 85, 90 ] }
y queremos cambiar la calificación de 80 por 82. Mediante el operador posicional haremos:
db.students.updateOne( { _id: 1, notas: 80 }, { $set: { "notas.$" : 82 } } )
De manera similar, si queremos modificar parte de un documento el cual forma parte de un array, debemos usar la notación punto tras el $.
Por ejemplo, supongamos que tenemos estas calificaciones de un determinado alumno, las cuales forman parte de un objeto dentro de un array:
{ "_id" : 4, "notas" :
[ { nota: 80, media: 75 },
{ nota: 85, media: 90 },
{ nota: 90, media: 85 } ] }
Podemos observar como tenemos cada calificación como parte de un objeto dentro de un array. Si queremos cambiar el valor de media a 89 de la calificación cuya nota es 85, haremos:
db.students.updateOne( { _id: 4, "notas.nota": 85 }, { $set: { "notas.$.media" : 89 } } )
Es decir, el $ referencia al documento que ha cumplido el filtro de búsqueda.
Más operadores posicionales
Además del operador posicional $, tenemos disponible el operador posicional $[] que indica que afecta a todos los elementos del array, y el operador posicional $[identificador] que identifica que elementos del array cumplen una condición para su filtrado.
Podemos consultar toda la documentación disponible sobre estos operadores en http://docs.mongodb.org/manual/reference/operator/update-array/
Borrando documentos¶
Para borrar, usaremos los método deleteOne o deleteMany, los cuales funcionan de manera similar a findOne y find. Si no pasamos ningún parámetro, deleteOne borrará el primer documento, o en el caso de deleteMany toda la colección documento a documento. Si le pasamos un parámetro, éste será el criterio de selección de documentos a eliminar.
db.people.deleteOne({nombre:"Marina Medrano"})
Al eliminar un documento, no podemos olvidar que cualquier referencia al documento que exista en la base de datos seguirá existiendo. Por este motivo, manualmente también hay que eliminar o modificar esas referencias.
Si queremos borrar toda la colección, es más eficiente usar el método drop, ya que también elimina los índices.
db.people.drop()
Eliminar un campo
Recordad que eliminar un determinado campo de un documento no se considera un operación de borrado, sino una actualización mediante el operador $unset.
Referencias¶
- Manual de MongoDB
- Cheatsheet oficial
- Comparación entre SQL y MongoDB
- Cursos gratuitos de Mongo University
- Consultas solucionadas sobre la colección
sample_restaurants.restaurantsen w3resource
Actividades¶
-
(RA5075.2 / CE5.2b / 1p) Crea un cluster en MongoAtlas, carga los datos de ejemplo y adjunta capturas de pantalla de:
- Dashboard del cluster
- Bases de datos / colecciones creadas
A continuación, conéctate mediante MongoDB Compass y adjunta una captura de pantalla tras conectar con el clúster.
-
(RA5075.1 / CE5.1d / 2p) Haciendo uso de
mongosh, escribe los comandos necesarios para:- Obtener las bases de datos creadas.
- Sobre la base de datos
sample_trainingy la colecciónzipsaverigua:- Cuantos documentos hay en la ciudad de
SAN DIEGO. - Cuantos documentos tienen menos de 100 personas (campo
pop). - Obtén los estados de la ciudad de
SAN DIEGO(Solución:[ 'CA', 'TX' ]). - Cual es el código postal de la ciudad de
ALLENque no tiene habitantes (sólo recupera elzip, no nos interesa ningún otro campo, ni el_id). - Listado con los 5 códigos postales más poblados (muestra los documentos completos).
- Cantidad de documentos que no tienen menos de 5.000 habitantes ni más de 1.000.000 (debes utilizar el operador
$nor). - Cuantos documentos tienen más habitantes que su propio código postal (campo
zip).
- Cuantos documentos hay en la ciudad de
- Sobre la colección
postsaverigua:- Cuantos mensajes tienen las etiquetas
restaurantomoon. - Los comentarios que ha escrito el usuario
Salena Olmos. - Recupera los mensajes que en
bodycontengan la palabraearth, y devuelve el título, 3 comentarios y 5 etiquetas.
- Cuantos mensajes tienen las etiquetas
-
(RA5075.1 / CE5.1d / 2p) Escribe los comandos necesarios para realizar las siguientes operaciones sobre la colección
zips:-
Crea una entrada con los siguientes datos:
{ city: 'ELX', zip: '03206', loc: { x: 38.265500, y: -0.698459 }, pop: 230224, state: 'España' } -
Crea una entrada con los datos del código postal donde vives (si es el mismo código postal, crea uno diferente).
- Modifica la población de tu código postal a
1.000.000. - Incrementa la población de todas los documentos de
Españaen 666 personas. - Añade un campo
prova ambos documentos con valorAlicante. - Modifica los documentos de
Españay añade un atributotagsque contenga un array vacío. - Modifica todos los documentos de la provincia de
Alicantey añade al atributotagsel valorsun. - Modifica el valor de
sunde tu código postal y sustitúyelo porhouse. - Renombra en los documentos de la provincia de
Alicanteel atributoprovporprovincia - Elimina las coordenadas del zip
03206. - Elimina tu entrada.
-