MongoDB y Python
Apuntes sin actualizar
Estos apuntes pertenecen al curso 22/23 y, por lo tanto, ya no se actualizan.
Puedes acceder a la última versión de esta sesión en https://aitor-medrano.github.io/iabd/sa/pymongo.html.
Para acceder a MongoDB desde Python nos vamos a centrar en la librería PyMongo.
Para instalar la librería mediante pip usaremos el comando (recuerda hacerlo dentro de un entorno virtual):
pip install pymongo
Se recomienda consultar la documentación o el API para cualquier duda o aclaración.
Versión
En el momento de escribir los apuntes, estamos utilizando la versión 4.3.2 de PyMongo.
Hola PyMongo¶
Un ejemplo básico podría ser similar a:
from pymongo import MongoClient
cliente = MongoClient('mongodb://localhost:27017')
iabd_db = cliente.iabd
# Recuperamos las colecciones
print(iabd_db.list_collection_names())
people_coll = iabd_db.people
# Recuperamos una persona
persona = people_coll.find_one()
print(persona)
MongoClient¶
A partir de la URI de conexión a MongoDB, hemos de instanciar la clase MongoClient, ya sea pasándole una URI con la cadena de conexión, o mediante parámetros:
uri = "mongodb+srv://usuario:contrasenya@host"
cliente = MongoClient(uri)
Parámetros adicionales
A la hora de crear el cliente, también podemos indicarle diferentes opciones de configuración:
cliente200Retry = MongoClient(uri, connectTimeoutMS=200, retryWrites=True)
Realmente, al crear la conexión se inicializa un pool de conexiones, de manera que se crean 100 conexiones, y en vez de crear y destruir una conexión por cada petición, se reutilizan, de manera que cada petición asigna y libera una conexión conforme necesidad. Por defecto, el tamaño del pool es de 100 conexiones.
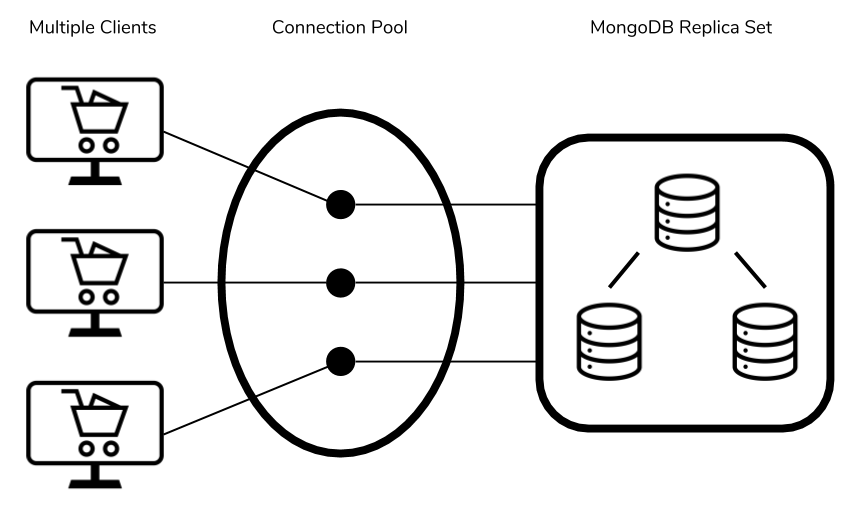
Podemos obtener información de la conexión mediante la propiedad state. Por ejemplo, en nuestro caso, nos hemos conectado a MongoAtlas y de la salida del estado podemos ver los diferentes hosts que forman parte del conjunto de réplicas:
cliente = MongoClient('mongodb+srv://iabd:iabdiabd@cluster0.dfaz5er.mongodb.net/')
print(cliente.state)
# Database(MongoClient(host=['ac-opunia9-shard-00-01.dfaz5er.mongodb.net:27017', 'ac-opunia9-shard-00-02.dfaz5er.mongodb.net:27017', 'ac-opunia9-shard-00-00.dfaz5er.mongodb.net:27017'], document_class=dict, tz_aware=False, connect=True, authsource='admin', replicaset='atlas-4wikkb-shard-0', tls=True), 'state')
Conexión a un réplica
Si nos queremos conectar a un conjunto de réplicas e indicar los nodos a los que nos podemos conectar, podemos separar los hosts con comas e indicar finalmente con un parámetro el nombre del conjunto de réplicas:
client = MongoClient('mongodb://usuario1:contra1@host1:puerto1,host2:puerto2/?replicaSet=nombreReplica')
A partir del cliente, podemos obtener información diversa. Por ejemplo, podemos recuperar un listado de las bases de datos mediante list_database_names():
print(cliente.list_database_names())
# ['sample_airbnb', 'sample_analytics', 'sample_geospatial', 'sample_guides', 'sample_mflix', 'sample_restaurants', 'sample_supplies', 'sample_training', 'sample_weatherdata', 'admin', 'local']
Para conectarnos a una base de datos en concreto, únicamente accederemos a ella como una propiedad del cliente:
bd = cliente.sample_mflix
bd = cliente["sample_mflix"] # tb podemos acceder como si fuera un diccionario
Bases de datos y colecciones Lazy
Es conveniente tener en cuenta que tantos las colecciones como las bases de datos se crean y carga de forma perezosa, esto es, hasta que no realizamos una operación sobre ellas, no se accede realmente a ellas. Así pues, para crear realmente una colección, hemos de insertar un documento en ella.
Una vez tenemos la base de datos, el siguiente paso es obtener una colección:
coleccion = bd.movies
coleccion = bd["movies"]
Si queremos obtener el nombre de todas las colecciones usaremos el método list_collection_names():
print(bd.list_collection_names())
['users', 'movies', 'sessions', 'theaters', 'comments']
Tolerancia a fallos!
Al crear una conexión, conviene especificar el tamaño del pool y el timeout de las conexiones:
db = MongoClient(URI, maxPoolSize=50, wtimeout=2500)[nombreBD]
Se recomienda siempre especificar un wtimeout, ya que cuando se realiza una escritura con mayoría de escrituras, si fallase algún nodo no se quedaría colgado esperando.
Si no encontrase el servidor, lanzará un ServerSelectionTimeoutError el cual deberíamos capturar.
Primeras consultas¶
Finalmente, sobre una colección ya podemos realizar consultas y otras operaciones:
movies = bd.movies
movies.count_documents({})
# 23530
movies.find_one()
# {'_id': ObjectId('573a1390f29313caabcd4135'), 'plot': 'Three men hammer on an anvil and pass a bottle of beer around.', 'genres': ['Short'], 'runtime': 1, 'cast': ['Charles Kayser', 'John Ott'], 'num_mflix_comments': 1, 'title': 'Blacksmith Scene', 'fullplot': 'A stationary ...', 'countries': ['USA'], 'released': datetime.datetime(1893, 5, 9, 0, 0), 'directors': ['William K.L. Dickson'], 'rated': 'UNRATED', 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-26 00:03:50.133000000', 'year': 1893, 'imdb': {'rating': 6.2, 'votes': 1189, 'id': 5}, 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.0, 'numReviews': 184, 'meter': 32}, 'lastUpdated': datetime.datetime(2015, 6, 28, 18, 34, 9)}}
Por ejemplo, podemos filtrar las películas cuya actriz sea Salma Hayek. Al realizar la consulta, find devuelve un cursor, el cual podemos recorrer:
cursor = movies.find( { "cast": "Salma Hayek" } )
for movie in cursor:
print(movie)
{
'_id': ObjectId('573a1399f29313caabceea6d'),
'awards': {'nominations': 1, 'text': '1 nomination.', 'wins': 0},
'cast': ['David Arquette', 'John Hawkes', 'Salma Hayek', 'Jason Wiles'],
'countries': ['USA'],
...
'writers': ['Robert Rodriguez', 'Tommy Nix'],
'year': 1994
}
{'_id': ObjectId('573a139af29313caabcef0b6'),
'awards': {'nominations': 14, 'text': '27 wins & 14 nominations.', 'wins': 27},
'cast': ['Ernesto Gómez Cruz', 'María Rojo', 'Salma Hayek', 'Bruno Bichir'],
'countries': ['Mexico'],
...
}
Si queremos contar los documentos que cumplen un criterio, en vez de find, usaremos count_documents pasándole el criterio de filtrado:
cantidad = movies.count_documents( { "cast": "Salma Hayek" } )
Para seleccionar los campos que queremos recuperar, necesitamos pasar un segundo parámetro con la proyección:
cursor = movies.find( { "cast": "Salma Hayek" }, { "title": 1, "cast": 1} )
for movie in cursor:
print(movie)
{'_id': ObjectId('573a1399f29313caabceea6d'), 'cast': ['David Arquette', 'John Hawkes', 'Salma Hayek', 'Jason Wiles'], 'title': 'Roadracers'}
{'_id': ObjectId('573a139af29313caabcef0b6'), 'cast': ['Ernesto Gómez Cruz', 'María Rojo', 'Salma Hayek', 'Bruno Bichir'], 'title': 'Midaq Alley'}
...
Como ya vimos al hacer consultas en sesiones anterior, si no queremos el campo _id, tenemos que indicarlo:
cursor = movies.find( { "cast": "Salma Hayek" }, { "title": 1, "cast": 1, "_id": 0} )
for zip in cursor:
print(zip)
{'cast': ['David Arquette', 'John Hawkes', 'Salma Hayek', 'Jason Wiles'], 'title': 'Roadracers'}
{'cast': ['Ernesto Gèmez Cruz', 'Marèa Rojo', 'Salma Hayek', 'Bruno Bichir'], 'title': 'Midaq Alley'}
{'title': 'Desperado', 'cast': ['Antonio Banderas', 'Salma Hayek', 'Joaquim de Almeida', 'Cheech Marin']}
...
BSON
Cuando necesitemos pasar los documentos BSON a JSON, utilizaremos la función dumps que transforma el documento a JSON:
cursor = movies.find( { "cast": "Salma Hayek" } )
from bson.json_util import dumps
print(dumps(cursor, indent=2))
"""
[
{
"_id": {
"$oid": "573a1399f29313caabceea6d"
},
"plot": "Cynical look at a 50's rebellious Rocker who has to confront his future, thugs with knives, and the crooked town sheriff.",
"genres": [
"Action",
"Drama"
],
"runtime": 95,
"rated": "R",
"cast": [
"David Arquette",
"John Hawkes",
"Salma Hayek",
"Jason Wiles"
],
...
"""
Agregaciones¶
Para realizar consultas mediante el framework de agregación, usaremos el método aggregate, el cual recibe un array con el pipeline:
Por ejemplo, vamos a recuperar el título y el casting de las películas dirigidas por Sam Raimi:
match_stage = { "$match": { "directors": "Sam Raimi" } }
project_stage = { "$project": { "_id": 0, "title": 1, "cast": 1 } }
pipeline = [
match_stage,
project_stage
]
sam_raimi_aggregation = movies.aggregate(pipeline)
for movie in sam_raimi_aggregation:
print(movie)
{'cast': ['Bruce Campbell',
'Ellen Sandweiss',
'Richard DeManincor',
'Betsy Baker'],
'title': 'The Evil Dead'}
{'cast': ['Bruce Campbell',
'Sarah Berry',
'Dan Hicks',
'Kassie Wesley DePaiva'],
'title': 'Evil Dead II'}
{'cast': ['Liam Neeson', 'Frances McDormand', 'Colin Friels', 'Larry Drake'],
'title': 'Darkman'}
Otro ejemplo, donde recuperamos los directores y la valoración media de sus películas, ordenadas de mejor a peor:
unwind_stage = { "$unwind": "$directors" }
group_stage = {
"$group": {
"_id": {
"director": "$directors"
},
"average_rating": { "$avg": "$imdb.rating" }
}
}
sort_stage = {
"$sort": { "average_rating": -1 }
}
# Creamos un pipeline con las tres fases
pipeline = [
unwind_stage,
group_stage,
sort_stage
]
director_ratings = movies.aggregate(pipeline)
for director in director_ratings:
print(director)
{'_id': {'director': 'Sara Hirsh Bordo'}, 'average_rating': 9.4}
{'_id': {'director': 'Kevin Derek'}, 'average_rating': 9.3}
{'_id': {'director': 'Michael Benson'}, 'average_rating': 9.0}
{'_id': {'director': 'Slobodan Sijan'}, 'average_rating': 8.95}
{'_id': {'director': "Bozidar 'Bota' Nikolic"}, 'average_rating': 8.9}
...
O realizamos un join entre las películas y sus comentarios para recuperar una película por su identificador:
from bson.objectid import ObjectId
peliculaId = "573a13aef29313caabd2c349"
pipeline = [
{
"$match": {
"_id": ObjectId(peliculaId)
}
}, {
"$lookup": {
"from": "comments",
"localField": "_id",
"foreignField": "movie_id",
"as": 'comentarios'
}
}
]
peliculaConComentarios = movies.aggregate(pipeline).next()
print(peliculaConComentarios)
{'_id': ObjectId('573a13aef29313caabd2c349'),
'awards': {'nominations': 48,
'text': 'Nominated for 1 Oscar. Another 21 wins & 48 nominations.',
'wins': 22},
'cast': ['Christian Bale', 'Michael Caine', 'Liam Neeson', 'Katie Holmes'],
'comentarios': [{'_id': ObjectId('5a9427658b0beebeb696f672'),
'date': datetime.datetime(1972, 3, 2, 15, 58, 41),
'email': 'donald_sumpter@gameofthron.es',
'movie_id': ObjectId('573a13aef29313caabd2c349'),
'name': 'Maester Luwin',
'text': 'Atque ...'}],
'countries': ['USA', 'UK'],
'directors': ['Christopher Nolan'],
'fullplot': 'When ...",
'genres': ['Action', 'Adventure'],
'imdb': {'id': 372784, 'rating': 8.3, 'votes': 860733},
'languages': ['English', 'Urdu', 'Mandarin'],
'lastupdated': datetime.datetime(2015, 8, 31, 0, 1, 54, 590000),
'metacritic': 70,
'num_mflix_comments': 1,
'plot': 'After training ....',
'poster': 'https://m.media-amazon.com/images/M/MV5BZmUwNGU2ZmItMmRiNC00MjhlLTg5YWUtODMyNzkxODYzMmZlXkEyXkFqcGdeQXVyNTIzOTk5ODM@._V1_SY1000_SX677_AL_.jpg',
'rated': 'PG-13',
'released': datetime.datetime(2005, 6, 15, 0, 0),
'runtime': 140,
'title': 'Batman Begins',
'type': 'movie',
'writers': ['Bob Kane (characters)',
'David S. Goyer (story)',
'Christopher Nolan (screenplay)',
'David S. Goyer (screenplay)'],
'year': 2005}
Trabajando con cursores¶
A continuación vamos a realizar algunas operaciones sobre los cursores con PyMongo y a comparar a cómo podemos realizar la misma operación mediante el motor de agregaciones.
Limitando¶
Sobre el cursor podemos restringir la cantidad de resultados devueltos mediante el método .limit() equivalente a la agregación $limit:
limited_cursor = movies.find(
{ "directors": "Sam Raimi" },
{ "_id": 0, "title": 1, "cast": 1 }
).limit(2)
for movie in limited_cursor:
print(movie)
pipeline = [
{ "$match": { "directors": "Sam Raimi" } },
{ "$project": { "_id": 0, "title": 1, "cast": 1 } },
{ "$limit": 2 }
]
limited_aggregation = movies.aggregate( pipeline )
for movie in limited_aggregation:
print(movie)
[
{
"cast": [
"Bruce Campbell",
"Ellen Sandweiss",
"Richard DeManincor",
"Betsy Baker"
],
"title": "The Evil Dead"
},
{
"title": "Evil Dead II",
"cast": [
"Bruce Campbell",
"Sarah Berry",
"Dan Hicks",
"Kassie Wesley DePaiva"
]
}
]
Ordenando¶
Para ordenar usaremos el método .sort() que además de los campos de ordenación, indicaremos si el criterio será ascendente (ASCENDING) o descendente (DESCENDING), de forma similar a como lo hacemos con la operación de agregación $sort:
from pymongo import DESCENDING, ASCENDING
sorted_cursor = movies.find(
{ "directors": "Sam Raimi" },
{ "_id": 0, "year": 1, "title": 1, "cast": 1 }
).sort("year", ASCENDING)
for movie in sorted_cursor:
print(movie)
pipeline = [
{ "$match": { "directors": "Sam Raimi" } },
{ "$project": { "_id": 0, "year": 1, "title": 1, "cast": 1 } },
{ "$sort": { "year": ASCENDING } }
]
sorted_aggregation = movies.aggregate( pipeline )
for movie in sorted_aggregation:
print(movie)
[
{
"cast": [
"Bruce Campbell",
"Ellen Sandweiss",
"Richard DeManincor",
"Betsy Baker"
],
"title": "The Evil Dead",
"year": 1981
},
{
"year": 1987,
"title": "Evil Dead II",
"cast": [
"Bruce Campbell",
"Sarah Berry",
"Dan Hicks",
"Kassie Wesley DePaiva"
]
},
{
"year": 1990,
...
}
]
En el caso de tener una clave compuesta de ordenación, le pasaremos como parámetro una lista de tuplas clave/criterio:
sorted_cursor = movies.find(
{ "cast": "Tom Hanks" },
{ "_id": 0, "year": 1, "title": 1, "cast": 1 }
).sort([("year", ASCENDING), ("title", ASCENDING)])
for movie in sorted_cursor:
print(movie)
pipeline = [
{ "$match": { "cast": "Tom Hanks" } },
{ "$project": { "_id": 0, "year": 1, "title": 1, "cast": 1 } },
{ "$sort": { "year": ASCENDING, "title": ASCENDING } }
]
sorted_aggregation = movies.aggregate( pipeline )
for movie in sorted_aggregation:
print(movie)
[
{
"cast": [
"Tom Hanks",
"Daryl Hannah",
"Eugene Levy",
"John Candy"
],
"title": "Splash",
"year": 1984
},
{
"cast": [
"Tom Hanks",
"Jackie Gleason",
"Eva Marie Saint",
"Hector Elizondo"
],
"title": "Nothing in Common",
"year": 1986
},
{
"cast": [
"Tom Hanks",
"Elizabeth Perkins",
"Robert Loggia",
"John Heard"
],
"title": "Big",
"year": 1988
},
{
"cast": [
"Sally Field",
"Tom Hanks",
"John Goodman",
"Mark Rydell"
],
"title": "Punchline",
"year": 1988
},
...
]
Saltando¶
Cuando paginamos los resultados, para saltar los documentos, haremos uso del método .skip(), el cual es similar a la operación $skip.
Por ejemplo, la siguiente consulta devuelve 13 documentos, de manera que al saltarnos 12, sólo nos devolverá uno:
skipped_sorted_cursor = movies.find(
{ "directors": "Sam Raimi" },
{ "_id": 0, "title": 1, "year": 1, "cast": 1 }
).sort("year", ASCENDING).skip(12)
for movie in skipped_sorted_cursor:
print(movie)
pipeline = [
{ "$match": { "directors": "Sam Raimi" } },
{ "$project": { "_id": 0, "year": 1, "title": 1, "cast": 1 } },
{ "$sort": { "year": ASCENDING } },
{ "$skip": 12 }
]
sorted_skipped_aggregation = movies.aggregate( pipeline )
for movie in sorted_skipped_aggregation:
print(movie)
[
{
"cast": [
"James Franco",
"Mila Kunis",
"Rachel Weisz",
"Michelle Williams"
],
"title": "Oz the Great and Powerful",
"year": 2013
}
]
CRUD¶
Para estas operaciones, vamos a trabajar con la colección iabd.people que utilizamos en la primera sesión de MongoDB.
Inserción¶
from pymongo import MongoClient
cliente = MongoClient("mongodb+srv://iabd:iabdiabd@cluster0.4hm7u8y.mongodb.net/?retryWrites=true&w=majority", server_api=ServerApi('1'))
bd = cliente.iabd
people = bd.people
yo = { "nombre": "Aitor Medrano", "edad": 45, "profesion": "Profesor" }
resultado = people.insert_one(yo)
print(resultado.acknowledged) # True
print(resultado.inserted_id) # 6366b5c85afaf1b75dc90a20
Tras realizar una operación de inserción con insert_one, obtenemos un objeto InsertOneResult del cual cabe destacar dos campos:
acknowledged: un campo booleano que nos indica si la operación ha sido exitosa, oFalsecuando indicamos unWriteConcern(w=0), es decir, es escritura fire-and-forget.inserted_id: valor delObjectId.
Si queremos insertar más de una documento a la vez, usaremos insert_many, el cual devuelve un objeto InsertManyResult.
Join¶
Ya hemos estudiado que al insertar un documento que está relacionado con otro, necesitamos que los campos contengan el mismo valor (normalmente, el ObjectId)
Por ejemplo, si queremos añadir un comentario a una película, hemos de unir el identificador de la película en cada comentario haciendo uso de objeto ObjectId:
from bson.objectid import ObjectId
comments = db.comments
comment_doc = {"name": usuario.nombre, "email": usuario.email,
"movie_id": ObjectId(movie_id), "text": comentario, "date": fecha}
comments.insert_one(comment_doc))
Gestión de errores¶
A la hora de insertar un documento se puede dar el caso de lanzar un DuplicateKeyError, ya sea por el atributo identificador o por un índice de tipo único. En dicho caso, podemos capturar la excepción y ajustar el comportamiento o informar al usuario, dependiendo de la gravedad del error.
Por ejemplo, si insertamos una persona con un _id que ya existe:
doc = {
"_id": 1,
"nombre": "Aitor Medrano"
}
try:
result = people.insert_one(doc)
print(res.inserted_id)
except errors.DuplicateKeyError:
usuario_id = doc["_id"]
print(f"El usuario #{usuario_id} ya existe en el sistema.")
Borrado¶
El borrado de documento es similar a la creación, pudiendo utilizar delete_one para borrar el primer documento encontrado, o delete_many para borrar todos los documentos encontrados:
resultado = people.delete_many({ "edad" : 45})
print(resultado.deleted_count)
En ambas operaciones, obtenemos un objeto DeleteResult del cual destacamos la propiedad deleted_count para averiguar cuantos documentos han sido eliminados.
Borrado de colecciones
Para vaciar una colección, podemos borrar todos los documentos:
people.delete_many({})
Aunque es mejor borrar la colección entera:
people.drop()
Modificación¶
De forma similar a como lo hemos realizado mediante mongosh, para modificar documentos emplearemos los métodos update_one y update_many, los cuales devuelve un objeto UpdateResult:
resultado = people.update_one({"nombre":"Aitor Medrano"}, {"$set":{"nombre":"Marina Medrano", "salario": 123456}})
print(resultado.matched_count) # (1)!
print(resultado.modified_count) # (2)!
matched_countnos devuelve la cantidad de documentos encontradosmodified_countnos devuelve la cantidad de documentos modificados
Tal como vimos, en las operaciones update, le podemos pasar un tercer parámetro (opcional) con upsert=False (valor por defecto) op True, cuando queramos que se inserte un nuevo documento si no encuentra ninguno. En este caso, modified_count y matched_count serán 0.
Otro argumento opcional que conviene conocer es bypass_document_validation=False (valor por defecto), el cual, si lo ponemos a True ignorará las validaciones (si hay alguna) para los documentos que modifiquemos.
Operador
Recuerda utilizar un operador de modificación en el segundo parámetro. Si no, el documento del segundo parámetro sustituirá por completo al documento encontrado.
Operaciones consistentes¶
Preferencias de lectura¶
Para realizar lecturas consistentes podemos configurar la preferencias de lectura, tal como vimos en la sesión anterior.
Para ello, PyMongo ofrece un conjunto de clases para indicar las preferencias de lectura, las cuales podemos configurar a nivel de cliente:
Niveles de lectura
Los diferentes niveles vienen definidos en el objeto ReadPreference el cual ofrece los valores estudiados en la sesión anterior: PRIMARY, PRIMARY_PREFERRED, SECONDARY, SECONDARY_PREFERRED y NEAREST.
client = MongoClient(
'localhost:27017',
replicaSet='iabd',
readPreference='secondaryPreferred')
Si en vez de indicar la preferencia a nivel de cliente, lo queremos realizar a nivel de base de datos o de colección, hemos de emplear los métodos get_database y get_collection pasándole un segundo parámetro con la opción deseada:
from pymongo import ReadPreference
print(client.read_preference) # SecondaryPreferred(tag_sets=None)
db = client.get_database('iabd', read_preference=ReadPreference.SECONDARY)
print(db.read_preference) # Secondary(tag_sets=None)
coll = db.get_collection('people', read_preference=ReadPreference.PRIMARY)
print(coll.read_preference) # Primary()
Finalmente, si en cualquier momento queremos cambiar las preferencias a nivel de colección, podemos emplear el método with_options:
coll2 = coll.with_options(read_preference=ReadPreference.NEAREST)
print(coll.read_preference) # Primary()
print(coll.read_preference) # Nearest(tag_sets=None)
Escrituras consistentes¶
Tal como vimos en la sesión anterior, para indicar la consistencia en la escritura, haremos uso de la propiedad write_concern. Para ello, de la misma forma que hemos indicado la preferencia de lectura, hacemos uso del método with_options:
coll.with_options(write_concern=WriteConcern(w="majority")).insert_one({
"nombre": nombre,
"email": email,
"password": hashed_pw
})
Si tenemos una aplicación crítica, no nos podemos permitir perder los datos. Por ello, necesitamos que las escritura se propaguen a la mayoría de los nodos con la opción w: majority para asegurarnos que las escrituras se propagan a la mayoría de nodos del conjunto de nodos.
Si sucede un problema en los nodos secundarios, puede ser que el primario no reciba los ACK necesarios. Si llegan más escrituras que lecturas, puede llegar el momento en que se produzca un atasco.
Para evitar esto, para cada escritura que realicemos con la mayoría de los nodos, siempre hay que indicar un timeout. La longitud del timeout vendrá determinada por la red y el hardware que dispongamos, pero siempre hemos de indicarlo.
coll.with_options(write_concern=WriteConcern(w="majority", wtimeout="2500").insert_one({
"nombre": nombre,
"email": email,
"password": hashed_pw
})
Bulk writes
En ocasiones necesitamos ejecutar una bateria de operaciones a granel (bulk) las cuales se ejecutan como un proceso batch. Para ello se emplea el método bulk_write:
result = db.test.bulk_write(array_operaciones)
Transacciones¶
Ya hemos comentado en numerosas ocasiones toda operación en un único documento es atómica, de ahí embeber documentos y arrays para modelar las relaciones de datos en un sólo documento cubre la mayoría de los casos de usos transaccionales.
Cuando necesitamos atomicidad de lecturas y escrituras entre varios documentos (en una o más colecciones), MongoDB soporta transacciones multidocumento. Mediante las transacciones distribuidas, las transacciones puede operar entre varias operaciones, colecciones, bases de datos, documentos y particiones (shards).
Tipos de API¶
MongoDB ofrece dos API para utilizar transacciones. La primera, conocida como Core API, disponible desde la versión 4.0 de MongoDB, tiene una sintaxis similar a las bases de datos relacionales (por ejemplo, con operaciones como start_transaction y commit_transaction), y la segunda se conoce como Callback API, desde la versión 4.2, el cual es el enfoque actualmente recomendado.
El Core API no ofrece lógica de reintentos para la mayoría de errores y necesita que el desarrollador programe la lógica de las operaciones, la función transaccional que realiza commit y la lógica de errores y reintentos necesaria.
En cambio, el Callback API ofrece una única función que engloba un alto grado de funcionalidad comparadas con el Core API, incluyendo el inicio de una transacción asociada a una sesión lógica, ejecutar la función definida como callback y realizando el commit de la transacción (o abortándola en caso de error). Esta función también incluye la lógica de reintentos para manejar los errores al hacer commit.
En ambas APIs, el desarrollador se responsabiliza de iniciar la sesión lógica que se utilizará en la transacción. Ambas APIs requieren que las operaciones transaccionales se asocien a ésta sesión lógica (pasándola como parámetro a cada operación). Cada sesión lógica en MongoDB registra el tiempo y la secuencia de las operaciones en el contexto completo del despliegue de MongoDB.
Hola Mundo Callback API¶
Vamos a simular que tenemos una aplicación de gestión de un almacén, en la cual tenemos que realizar las siguientes operaciones dentro de una transacción:
pedidos.insert_one({"producto": "ps5", "cantidad": 100}, session=miSesion)
inventario.update_one({"producto": "ps5", "cantidad": {"$gte": 100}},
{"$inc": {"cantidad": -100}}, session=miSesion)
Veamos mediante un ejemplo el flujo del código transaccional haciendo uso del Callback API.
from pymongo import MongoClient, ReadPreference
from pymongo.write_concern import WriteConcern
from pymongo.read_concern import ReadConcern
uriString = 'mongodb+srv://iabd:iabdiabd@cluster0.4hm7u8y.mongodb.net/?retryWrites=true&w=majority'
cliente = MongoClient(uriString)
miWCMajority = WriteConcern('majority', wtimeout=1000)
# Paso 0: Creamos dos colecciones e insertamos un documento en cada una
bd = client.get_database( "iabd", write_concern=miWCMajority)
bd.pedidos.insert_one({"producto": "ps5", "cantidad":0})
bd.inventario.insert_one({"producto": "ps5", "cantidad": 1000})
# Paso 1: Definir el callback que indica la secuencia de las operaciones a realizar dentro de la transacción
def callback(miSesion):
pedidos = miSesion.cliente.iabd.pedidos
inventario = miSesion.cliente.iabd.inventario
# Importante: Debemos pasarle la sesión a cada operación
pedidos.insert_one({"producto": "ps5", "cantidad": 100}, session=miSesion)
inventario.update_one({"producto": "ps5", "cantidad": {"$gte": 100}},
{"$inc": {"cantidad": -100}}, session=miSesion)
# Paso 2: Iniciar una sesión de cliente.
with cliente.start_session() as session:
# Paso 3: Empleamos with_transaction para iniciar la transacción, ejecutar el callback y realizar el commit (o abortar en caso de error).
session.with_transaction(
callback,
read_concern=ReadConcern("local"),
write_concern=miWCMajority,
read_preference=ReadPreference.PRIMARY,
)
PyMODM
PyMODM es una librería ODM que abstrae el acceso a MongoDB mediante un mapeo objeto-documento. De forma similar a los frameworks ORM en los entornos relacionales, como son Hibernate (Java), Doctrine/Eloquent (PHP) o el ORM de Django, abstrae y simplifica el acceso a la base de datos.
Un ejemplo de definición de un objeto y su persistencia sería:
class User(MongoModel):
# Utiliza el 'email'como campo '_id'
email = fields.EmailField(primary_key=True)
nombre = fields.CharField()
apellido = fields.CharField()
usuario = User('a.medrano@edu.gva.es', 'Aitor', 'Medrano').save()
Hemos decidido no profundizar en su conocimiento ya que el equipo de MongoDB ha pausado su mantenimiento desde hace ya dos años.
Caso de uso - PIA: Login¶
El siguiente proyecto se basa inicialmente en el artículo How To Add Authentication to Your App with Flask-Login.
A partir de él, vamos a crear una aplicación en Flask que ataca a una base de datos de MongoDB para almacenar la información del proyecto PIA Lara.
Esta primera versión de la aplicación únicamente se centra en la gestión de los usuarios, distinguiendo entre los diferentes roles:
Administrador: superusuario, puede crear, editar y eliminar todo tipo de usuarios.Técnico: usuario que supervisará a los clientes, el cual, más adelante, puede llegar a crear textos predefinidos para los clientes.Cliente: usuario final de la aplicación que, más adelante, grabará los audios.
Simplicidad
El presente caso de uso se ha organizado para intentar simplificar al máximo el código y preparar un esqueleto que facilite el crecimiento de la aplicación. Aún así, una solución basada en Django o el uso de herramientas de mapeo entre los datos y los objetos del dominio serían un punto de partida para siguientes fases del proyecto.
Estructura¶
Una vez descargado el proyecto y tras descomprimirlo, o clonado desde https://github.com/aitor-medrano/piafplogin, veremos que tiene la siguiente estructura:
PIAFPLOGIN/
├── migrations/
│ └── user_migration.py
├── project/
│ ├── static/
│ │ ├── pialara.js
│ │ └── pialara.png
│ ├── templates/
│ │ ├── base.html
│ │ ├── index.html
│ │ ├── login.html
│ │ └── profile.html
│ ├── __init__.py
│ ├── auth.py
│ ├── db.py
│ ├── main.py
│ └── models.py
├── .ini
└── requirements.txt
El primer paso es crear un entorno virtual:
python3 -m venv app-env
Y activarlo:
source app-env/bin/activate
A continuación instalaremos las dependencias mediante:
pip3 install -r requirements.txt
Configuración¶
Para configurar el proyecto, partimos del fichero .ini que reside en la raíz del mismo y contiene los datos de configuración a MongoDB y la clave secreta que utiliza Flask para encriptar la sesión:
[PROD]
SECRET_KEY = eac5e91171438960ddec0c9c469a4c3dd42e96aea462afc5ab830f78527ad80e
PIALARA_DB_URI = mongodb+srv://usuario:contraseña@cluster0.xyz.mongodb.net
PIALARA_DB_NAME = pialara
[LOCAL]
SECRET_KEY = eac5e91171438960ddec0c9c469a4c3dd42e96aea462afc5ab830f78527ad80e
PIALARA_DB_URI = localhost
PIALARA_DB_NAME = pialara
Secret Key
Para generar una clave secreta, tal como indica la documentación de Flask, podemos ejecutar el siguiente comando:
python3 -c 'import secrets; print(secrets.token_hex())'
Una vez ya hemos configurado la conexión y antes de arrancar la aplicación, vamos a cargar unos datos básicos con usuarios. Para ello, en la carpeta migrations tenemos el archivo users_migration.py, el cual lee la configuración del archivo anterior, y crea tres usuarios:
from pymongo import MongoClient
from werkzeug.security import generate_password_hash
import os
import configparser
config = configparser.ConfigParser()
config.read(os.path.abspath(os.path.join(".ini")))
DB_URI = config['PROD']['PIALARA_DB_URI']
DB_NAME = config['PROD']['PIALARA_DB_NAME']
# DB_URI = config['LOCAL']['PIALARA_DB_URI']
# DB_NAME = config['LOCAL']['PIALARA_DB_NAME']
db = MongoClient(DB_URI)[DB_NAME]
usuarios = [
{"nombre":"Admin", "email":"admin@admin.com", "password":generate_password_hash("admin", method='sha256'), "rol":"Administrador"},
{"nombre":"Alumno", "email":"alumno@alumno.com", "password":generate_password_hash("alumno", method='sha256'), "rol":"Técnico"},
{"nombre":"Severo Ochoa", "email":"s8a@s8a.com", "password":generate_password_hash("s8a", method='sha256'), "rol":"Cliente", "parent":"alumno@alumno.com"},
]
try:
db.users.insert_many(usuarios)
except Exception as e:
print(e)
Destacar que al definir los documentos con los usuarios, encriptamos la contraseña mediante la función generate_password_hash para no almacenarla en la base de datos en texto plano.
Así pues, ejecutamos la migración:
python3 migrations/users_migration.py
Finalmente podemos arrancar la aplicación:
flask --app project --debug run
Y acceder a la aplicación a través de http://127.0.0.1:5000/:

Una vez que un usuario ha entrado a la aplicación, por ejemplo, si es un administrador, dispondrá de las opciones que hemos comentado anteriormente:

Blueprints¶
El archivo .ini que hemos configurado previamente define unos valores que la aplicación va a cargar desde el archivo __init__.py, el cual actúa como factoría de la aplicación y le indica a Flask los blueprints a utilizar:
from flask import Flask
from flask_login import LoginManager
from . import db
import os
import configparser
config = configparser.ConfigParser()
config.read(os.path.abspath(os.path.join(".ini")))
def create_app():
app = Flask(__name__)
# cargamos la configuración
app.config['PIALARA_DB_URI'] = config['LOCAL']['PIALARA_DB_URI']
app.config['PIALARA_DB_NAME'] = config['LOCAL']['PIALARA_DB_NAME']
app.config['SECRET_KEY'] = config['LOCAL']['SECRET_KEY']
# configuramos flask-login con la ruta del login
login_manager = LoginManager()
login_manager.login_view = 'auth.login'
login_manager.init_app(app)
# función que utiliza flask-login para recuperar el usuario
@login_manager.user_loader
def load_user(user_id):
return db.get_user_by_id(user_id)
# blueprint para las rutas de autenticación
from .auth import auth as auth_blueprint
app.register_blueprint(auth_blueprint)
# blueprint para la aplicación
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
return app
Un blueprint permite organizar un grupo de vistas y código en módulos. En vez de registrar las vistas y el resto de código en la aplicación, se registran en el blueprint, y éste es que se registra en la aplicación en la función create_app.
En nuestro caso, vamos a empezar con dos blueprints, uno para las funciones de autenticación, y otra para las funciones de gestión de usuarios. El código de cada blueprint irá en un módulo separado. Como la gestión de usuarios necesita primero la autenticación, vamos a ver cómo funciona.
Login¶
Para la gestión de la autenticación, nos hemos apoyado en la librería Flask-login que facilita la gestión la sesión del usuario.
En archivo auth.py contiene la lógica del login y el logout:
from flask import Blueprint, render_template, redirect, url_for, request, flash
from flask_login import login_user, login_required, logout_user, current_user
from werkzeug.security import check_password_hash
from . import db
auth = Blueprint('auth', __name__)
@auth.route('/login')
def login():
return render_template('login.html')
@auth.route('/login', methods=['POST'])
def login_post():
email = request.form.get('email')
password = request.form.get('password')
remember = True if request.form.get('remember') else False
user = db.get_user(email)
# comprobamos si el usuario existe
# cogemos la contraseña, la hasheamos y la comparamos con la contraseña hasheada
if not user or not check_password_hash(user.password, password):
flash('Por favor, comprueba tus datos y vuélvelo a intentar.')
# si el usuario no existe, o está mal la contraseña, recargamos la página
return redirect(url_for('auth.login'))
# marcamos al usuario como autenticado en flask_login
login_user(user, remember=remember)
return redirect(url_for('main.profile', nombre = current_user.nombre))
@auth.route('/logout')
@login_required
def logout():
logout_user()
flash('Sesión cerrada con éxito')
return redirect(url_for('auth.login'))
Los usuarios van a entrar al sistema mediante su email y una contraseña. Así pues, una vez hayamos recuperado un usuario por dicho email, creamos el hash de la contraseña recibida, y vemos si comprueba con la recuperada de la base de datos.
El método login_user de la línea 27 pertenece a la librería Flask-Login y se utiliza para indicar que el usuario ha sido autenticado, de manera que lo almacena en la sesión. La variable user es una clase propia que hemos definido nosotros con los atributos básicos de un usuario,el cual se encuentra en el archivo models.py:
from flask_login import UserMixin
class User(UserMixin):
def __init__(self, id, email, nombre, password, rol, parent = ""):
self.id = id
self.email = email
self.nombre = nombre
self.password = password
self.rol = rol
self.parent = parent
def __str__(self):
return f"{self.email} ({self.nombre} / {self.password})"
Como se puede observar, la clase define los atributos básicos de un usuario. El atributo parent lo vamos a emplear para que los clientes almacenen el email del técnico que tienen asignado.
Plantillas¶
Las diferentes plantillas heredan de una plantilla base.html, la cual emplea el framework Bulma para la apariencia de la web. Su funcionamiento es muy similar a Bootstrap.
Por ejemplo, vamos a revisar un fragmento de la plantilla base para ver cómo gestionamos la visualización del menú dependiendo del rol del usuario:
...
<section class="hero is-white is-fullheight">
<nav class="navbar is-transparent">
<div class="navbar-brand">
<a class="navbar-item" href="https://piafplara.es">
<img src="{{ url_for('static', filename='pialara.png') }}" alt="PIA Lara: un proyecto que habla por ti" width="112" height="28">
</a>
<div class="navbar-burger burger" data-target="navbarPIALara">
<span></span>
<span></span>
<span></span>
</div>
</div>
<div id="navbarPIALara" class="navbar-menu">
<div class="navbar-start">
<a href="{{ url_for('main.index') }}" class="navbar-item">
Inicio
</a>
{% if not current_user.is_authenticated %}
<a href="{{ url_for('auth.login') }}" class="navbar-item">
Login
</a>
{% endif %}
{% if current_user.is_authenticated %}
<a href="{{ url_for('main.profile') }}" class="navbar-item">
Perfil
</a>
{% if current_user.rol == "Administrador" %}
<div class="navbar-item has-dropdown is-hoverable">
<a class="navbar-link" href="#">
Usuarios
</a>
<div class="navbar-dropdown is-hidden-mobile is-boxed">
<a class="navbar-item" href="{{ url_for('main.user_create') }}">
Alta
</a>
<a class="navbar-item" href="{{ url_for('main.user_list') }}">
Listado
</a>
</div>
</div>
{% endif %}
...
En la línea 6 utilizamos la función url_for con el parámetro static para indicarle que cargue la imagen con el logo del proyecto desde la carpeta static.
Al utilizar la librería Flask Login, tendremos siempre disponible el usuario logueado en la variable current_user. Además de las propiedades que hayamos definido en la clase, disponemos de la función is_authenticated para comprobar si está autenticado (línea 20). De igual forma, podemos comprobar el rol y condicionar el contenido dependiendo de si es Administrador, Técnico o Cliente (línea 24).
Acceso a los datos¶
Todo el acceso a los datos los hemos encapsulado en el archivo db.py:
from pymongo import MongoClient
from bson.objectid import ObjectId
from pymongo import ASCENDING
from flask import current_app, g
from werkzeug.local import LocalProxy
from project.models import User
def get_db():
"""
Método de configuración para obtener una instancia de db
"""
db = getattr(g, "_database", None)
PIALARA_DB_URI = current_app.config["PIALARA_DB_URI"]
PIALARA_DB_DB_NAME = current_app.config["PIALARA_DB_NAME"]
if db is None:
db = g._database = MongoClient(
PIALARA_DB_URI,
maxPoolSize=50,
timeoutMS=2500
)[PIALARA_DB_DB_NAME]
return db
# Utilizamos LocalProxy para leer la variable global usando sólo db
db = LocalProxy(get_db)
La función get_db utiliza el objeto g, el cual en Flask, es un objeto especial que es único para cada petición. Se utiliza para almacenar datos que serán accesibles desde múltiples funciones durante el request. Así pues, almacenamos la conexión, mejor dicho, el pool de conexiones a MongoDB en vez de crear un nuevo pool cada vez que queramos obtener acceso a la base de datos.
A continuación, creamos un LocalProxy para leer la variable global usando sólo la referencia db, de manera que internamente cada referencia a db realmente está llamando a get_db().
A continuación, mostramos un par de métodos del mismo archivo que muestran cómo obtenemos datos desde MongoDB haciendo uso de PyMongo:
def get_all_users():
"""
Devuelve una lista con todos los usuarios del sistema
"""
try:
return list(db.users.find({}).sort("nombre", ASCENDING))
except Exception as e:
return e
def get_user_by_id(id):
"""
Devuelve un objeto User a partir de su id
"""
try:
usuario = db.users.find_one({"_id":ObjectId(id)})
usuario_obj = User( id=usuario["_id"],
email=usuario.get("email"),
nombre=usuario.get("nombre"),
password=usuario.get("password"),
rol=usuario.get("rol"),
parent=usuario.get("parent"))
return usuario_obj
except Exception as e:
return e
...
Cuando recuperamos un usuario por su id, lo convertimos en un objeto User para que Flask Login falicita la gestión de la autenticación. En cambio, en el listado de todos los usuarios, vamos a acceder al cursor de usuarios que ofrece MongoDB.
Referencias¶
- Tutorial oficial de PyMongo
- Introduction to Multi-Document ACID Transactions in Python
- How To Use Transactions in MongoDB
Actividades¶
-
(RA5074.3 / CE4.3d / 4p) A partir del caso de uso de PIA Login, se pide:
- (0.25) Configurar la URI de Mongo Atlas para atacar vuestra propia base de datos.
- (0.25) Modificar la migración para introducir más usuarios (al menos uno más de cada rol)
- (0.75) Cuando un usuario pulsa sobre su nombre, actualmente aparece un formulario para editar sus datos, pero no puede cambiar la contraseña. Modifica (o crea) el/los formulario/s adecuado/s para que cada usuario pueda cambiar su propia contraseña.
- (0.75) Desde el rol
Administrador, al crear un usuario, si es un cliente, debe mostrar un desplegable con todos los técnicos disponibles. - (1) Tanto el
Técnicocomo elCliente, al dar de alta o editar un cliente, almacenarán datos necesarios para el proyecto, como son el sexo, la fecha de nacimiento y la patología. - (1) Cuando un
Técnicovisualiza el listado de sus clientes, debe recuperar únicamente el nombre, el sexo, la edad y su patología.