Agregaciones
Apuntes sin actualizar
Estos apuntes pertenecen al curso 22/23 y, por lo tanto, ya no se actualizan.
Puedes acceder a la última versión de esta sesión en https://aitor-medrano.github.io/iabd/sa/agregaciones.html.
Para poder agrupar datos y realizar cálculos sobre éstos, MongoDB ofrece diferentes alternativas:
-
Mediante operaciones Map-reduce con la operación
mapreduce()cuyo uso está deprecated desde MongoBD 5.0. -
Mediante el uso conjunto de
$functiony$accumulatorque permiten definir expresiones de agregación mediante JavaScript. -
Mediante operaciones de agrupación sencilla, como pueden ser las operaciones
count()odistinct(). -
Mediante el uso del Aggregation Framework, basado en el uso de pipelines, el cual permite realizar diversas operaciones sobre los datos. Este framework es el mecanismo más eficiente y usable para la realización de agregaciones, y por tanto, en el que nos vamos a centrar en esta sesión.
Para ello, a partir de una colección, mediante el método
aggregatele pasaremos un array con las fases a realizar:db.productos.aggregate([ {$group: {_id:"$fabricante", numProductos:{$sum:1}} }, {$sort: {numProductos:-1}} ])
Pipeline de agregación¶
Las agregaciones usan un pipeline, conocido como Aggregation Pipeline, de ahí el uso de un array con [ ] donde cada elemento es una fase del pipeline, de modo que la salida de una fase es la entrada de la siguiente:
db.coleccion.aggregate([op1, op2, ... opN])
Cuidado con el tamaño
El resultado del pipeline es un documento y por lo tanto está sujeto a la restricción de BSON, que limita su tamaño a 16MB.
En la siguiente imagen se resumen los pasos de una agrupación donde primero se eligen los elementos que vamos a agrupar mediante $match, el resultado saliente se agrupan con $group, y sobre los agrupado mediante $sum se calcula el total:
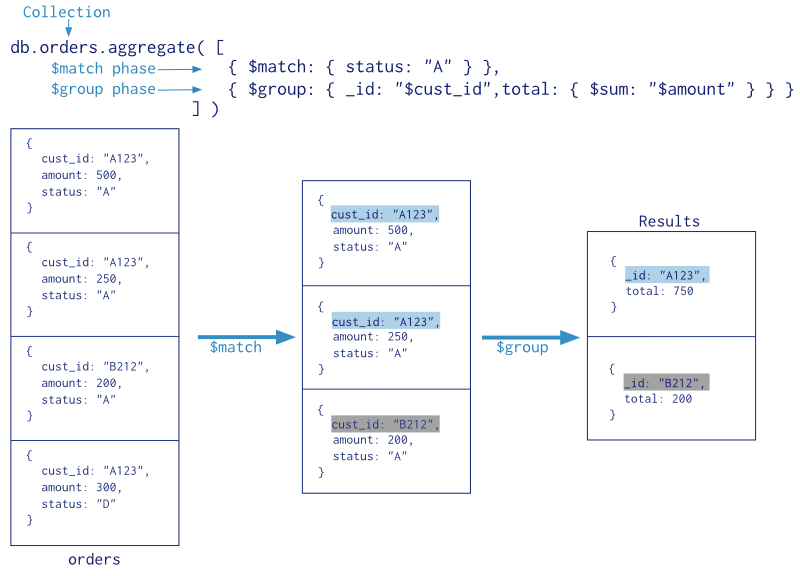
Al realizar un pipeline dividimos las consultas en fases, donde cada fase utiliza un operador para realizar una transformación. Aunque no hay límite en el número de fases en una consulta, es importante destacar que el orden importa, y que hay optimizaciones para ayudar a que el pipeline tenga un mejor rendimiento (por ejemplo, hacer un $match al principio para reducir la cantidad de datos)
Operadores del pipeline¶
Antes de nada destacar que las fases se pueden repetir, por lo que una consulta puede repetir operadores.
A continuación vamos a estudiar todos estos operadores:
| Operador | Descripción | Cardinalidad |
|---|---|---|
| $project | Proyección de campos, es decir, propiedades en las que estamos interesados. También nos permite modificar un documento, o crear un subdocumento (reshape) | 1:1 |
| $match | Filtrado de campos, similar a where | N:1 |
| $group | Para agrupar los datos, similar a group by | N:1 |
| $sort | Ordenar | 1:1 |
| $skip | Saltar | N:1 |
| $limit | Limitar los resultados | N:1 |
| $unwind | Separa los datos que hay dentro de un array | 1:N |
Preparando los ejemplos
Para los siguientes ejemplos, vamos a utilizar una colección de productos (productos.js) de un tienda de electrónica con las características y precios de los mismos.
Un ejemplo de un producto sería:
> db.productos.findOne()
{
"_id" : ObjectId("5345afc1176f38ea4eda4787"),
"nombre" : "iPad 16GB Wifi",
"fabricante" : "Apple",
"categoria" : "Tablets",
"precio" : 499
}
Para cargar este archivo desde la consola nos podemos conectar a nuestro cluster y realizar la carga:
mongosh mongodb+srv://iabd:iabdiabd@cluster0.dfaz5er.mongodb.net/iabd < productos.js
O si ya nos hemos conectado previamente:
load("productos.js")
$group¶
La fase group agrupa los documentos con el propósito de calcular valores agregados de una colección de documentos. Por ejemplo, podemos usar $group para calcular la media de páginas visitas de manera diaria.
Cuidado
La salida de $group esta desordenada
La salida de $group depende de cómo se definan los grupos. Se empieza especificando un identificador (por ejemplo, un campo _id) para el grupo que creamos con el pipeline. Para este campo _id, podemos especificar varias expresiones, incluyendo un único campo proveniente de un documento del pipeline, un valor calculado de una fase anterior, un documento con muchos campos y otras expresiones válidas, tales como constantes o campos de subdocumentos. También podemos usar operadores de $project para el campo _id.
Cuando referenciemos al valor de un campo lo haremos poniendo entre comillas un $ delante del nombre del campo. Así pues, para referenciar al fabricante de un producto lo haremos mediante $fabricante.
> db.productos.aggregate([
{ $group: {
_id: "$fabricante",
total: { $sum:1 }
}
}])
< { _id: 'Apple', total: 4 }
{ _id: 'Samsung', total: 2 }
{ _id: 'Sony', total: 1 }
{ _id: 'Google', total: 1 }
{ _id: 'Amazon', total: 2 }
Si lo que queremos es que el valor del identificador contenga un objeto, lo podemos hacer asociandolo como valor:
> db.productos.aggregate([
{ $group: {
_id: { "empresa": "$fabricante" },
total: { $sum:1 }
}
}])
<
{ _id: { empresa: 'Sony' }, total: 1 }
{ _id: { empresa: 'Apple' }, total: 4 }
{ _id: { empresa: 'Google' }, total: 1 }
{ _id: { empresa: 'Samsung' }, total: 2 }
{ _id: { empresa: 'Amazon' }, total: 2 }
También podemos agrupar más de un atributo, de tal modo que tengamos un _id compuesto. Por ejemplo:
> db.productos.aggregate([
{ $group: {
_id: {
"empresa": "$fabricante",
"tipo": "$categoria" },
total: {$sum:1}
}
}])
< { _id: { empresa: 'Apple', tipo: 'Tablets' }, total: 3 }
{ _id: { empresa: 'Sony', tipo: 'Portátiles' }, total: 1 }
{ _id: { empresa: 'Apple', tipo: 'Portátiles' }, total: 1 }
{ _id: { empresa: 'Samsung', tipo: 'Smartphones' }, total: 1 }
{ _id: { empresa: 'Amazon', tipo: 'Tablets' }, total: 2 }
{ _id: { empresa: 'Google', tipo: 'Tablets' }, total: 1 }
{ _id: { empresa: 'Samsung', tipo: 'Tablets' }, total: 1 }
Siempre _id
Cada expresión de $group debe especificar un campo _id.
Acumuladores¶
Además del campo _id, la expresión $group puede incluir campos calculados. Estos otros campos deben utilizar uno de los siguientes acumuladores.
| Nombre | Descripción |
|---|---|
$addToSet |
Devuelve un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones) |
$first |
Devuelve el primer valor del grupo. Se suele usar después de ordenar. |
$last |
Devuelve el último valor del grupo. Se suele usar después de ordenar. |
$max |
Devuelve el mayor valor de un grupo |
$min |
Devuelve el menor valor de un grupo. |
$avg |
Devuelve el promedio de todos los valores de un grupo |
$push |
Devuelve un array con todos los valores del campo seleccionado entre cada documento del grupo (puede haber repeticiones) |
$sum |
Devuelve la suma de todos los valores del grupo |
A continuación vamos a ver ejemplos de cada uno de estos acumuladores.
$sum¶
El operador $sum acumula los valores y devuelve la suma.
Por ejemplo, para obtener el montante total de los productos agrupados por fabricante, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"empresa": "$fabricante"
},
totalPrecio: {$sum:"$precio"}
}
}])
< { _id: { empresa: 'Apple' }, totalPrecio: 2296 }
{ _id: { empresa: 'Samsung' }, totalPrecio: 1014.98 }
{ _id: { empresa: 'Sony' }, totalPrecio: 499 }
{ _id: { empresa: 'Google' }, totalPrecio: 199 }
{ _id: { empresa: 'Amazon' }, totalPrecio: 328 }
$avg¶
Mediante $avg podemos obtener el promedio de los valores de un campo numérico.
Por ejemplo, para obtener el precio medio de los productos agrupados por categoría, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"}
}
}])
< { _id: { categoria: 'Smartphones' }, precioMedio: 563.99 }
{ _id: { categoria: 'Portátiles' }, precioMedio: 499 }
{ _id: { categoria: 'Tablets' }, precioMedio: 396.4271428571428 }
$addToSet¶
Mediante $addToSet obtendremos un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones).
Por ejemplo, para obtener para cada empresa las categorías en las que tienen productos, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"fabricante":"$fabricante"
},
categorias: {$addToSet:"$categoria"}
}
}])
< { _id: { fabricante: 'Apple' }, categorias: [ 'Portátiles', 'Tablets' ] }
{ _id: { fabricante: 'Amazon' }, categorias: [ 'Tablets' ] }
{ _id: { fabricante: 'Sony' }, categorias: [ 'Portátiles' ] }
{ _id: { fabricante: 'Google' }, categorias: [ 'Tablets' ] }
{ _id: { fabricante: 'Samsung' }, categorias: [ 'Tablets', 'Smartphones' ] }
$push¶
Mediante $push también obtendremos un array con todos los valores para los campos seleccionados entre cada documento del grupo, pero con repeticiones. Es decir, funciona de manera similar a $addToSet pero permitiendo elementos repetidos.
Por ello, si reescribimos la consulta anterior pero haciendo uso de $push obtendremos categorías repetidas:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
categorias: {$push:"$categoria"}
}
}])
< { _id: { empresa: 'Sony' }, categorias: [ 'Portátiles' ] }
{ _id: { empresa: 'Apple' }, categorias: [ 'Tablets', 'Tablets', 'Tablets', 'Portátiles' ] }
{ _id: { empresa: 'Google' }, categorias: [ 'Tablets' ] }
{ _id: { empresa: 'Samsung' }, categorias: [ 'Smartphones', 'Tablets' ] }
{ _id: { empresa: 'Amazon' }, categorias: [ 'Tablets', 'Tablets' ] }
$max y $min¶
Los operadores $max y $min permiten obtener el mayor y el menor valor, respectivamente, del campo por el que se agrupan los documentos.
Por ejemplo, para obtener el precio del producto más caro que tiene cada empresa haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
precioMaximo: {$max:"$precio"},
precioMinimo: {$min:"$precio"},
}
}])
{ "_id" : { "empresa" : "Amazon" }, "precioMaximo" : 199, "precioMinimo" : 129 }
{ "_id" : { "empresa" : "Sony" }, "precioMaximo" : 499, "precioMinimo" : 499 }
{ "_id" : { "empresa" : "Samsung" }, "precioMaximo" : 563.99, "precioMinimo" : 450.99 }
{ "_id" : { "empresa" : "Google" }, "precioMaximo" : 199, "precioMinimo" : 199 }
{ "_id" : { "empresa" : "Apple" }, "precioMaximo" : 699, "precioMinimo" : 499 }
Doble $group¶
Si queremos obtener el resultado de una agrupación podemos aplicar el operador $group sobre otro $group.
Por ejemplo, para obtener el precio medio de los precios medios de los tipos de producto por empresa haríamos:
> db.productos.aggregate([
{$group: {
_id: {
"empresa":"$fabricante",
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"} // (1)!
}
},
{$group: {
_id: "$_id.empresa",
precioMedio: {$avg: "$precioMedio"} // (2)!
}
}
])
< { _id: 'Google', precioMedio: 199 }
{ _id: 'Sony', precioMedio: 499 }
{ _id: 'Samsung', precioMedio: 507.49 }
{ _id: 'Apple', precioMedio: 549 }
{ _id: 'Amazon', precioMedio: 164 }
- Precio medio por empresa y categoría
- Precio medio por empresa en base al precio medio anterior
$first y $last¶
Estos operadores devuelven el valor resultante de aplicar la expresión al primer ($first) y/o último ($last) elemento de un grupo de documentos que comparten el mismo grupo por clave.
Por ejemplo, para obtener para cada empresa, cual es el tipo de producto que más tiene y la cantidad de dicho tipo haríamos:
> db.productos.aggregate([
{$group: {
_id: {
"empresa": "$fabricante",
"tipo" : "$categoria" },
total: {$sum:1}
}
},
{$sort: {"total":-1}},
{$group: {
_id:"$_id.empresa",
producto: {$first: "$_id.tipo"}, // (1)!
cantidad: {$first:"$total"}
}
}
])
< { _id: 'Sony', producto: 'Portátiles', cantidad: 1 }
{ _id: 'Samsung', producto: 'Tablets', cantidad: 1 }
{ _id: 'Amazon', producto: 'Tablets', cantidad: 2 }
{ _id: 'Apple', producto: 'Tablets', cantidad: 3 }
{ _id: 'Google', producto: 'Tablets', cantidad: 1 }
- Al agrupar por empresa, elegimos la categoría de producto que tiene más unidades
$project¶
Si queremos realizar una proyección sobre el conjunto de resultados y quedarnos con un subconjunto de los campos usaremos el operador $project. Como resultado obtendremos el mismo número de documentos, y en el orden indicado en la proyección.
La proyección dentro del framework de agregación es mucho más potente que dentro de las consultas normales. Se emplea para:
- renombrar campos.
- introducir campos calculados en el documento resultante mediante
$add,$substract,$multiply,$divideo$mod - transformar campos a mayúsculas
$toUppero minúsculas$toLower, concatenar campos mediante$concatu obtener subcadenas con$substr. - transformar campos en base a valores obtenidos a partir de una condición mediante expresiones lógicas con los operadores de comparación vistos en las consultas.
> db.productos.aggregate([
{$project:
{
_id: 0, // (1)!
"empresa": { "$toUpper": "$fabricante" }, // (2)!
"detalles": { // (3)!
"categoria": "$categoria",
"precio": { "$multiply": ["$precio", 1.1] } // (4)!
},
"elemento": "$nombre" // (5)!
}
}
])
< { empresa: 'APPLE',
detalles: { categoria: 'Tablets', precio: 548.9000000000001 },
elemento: 'iPad 16GB Wifi' }
{ empresa: 'APPLE',
detalles: { categoria: 'Tablets', precio: 658.9000000000001 },
elemento: 'iPad 32GB Wifi' }
...
- Ocultamos el campo
_id - Transforma un campo y lo pasa a mayúsculas
- Crea un documento anidado
- Incrementa el precio el 10%
- Renombra el campo
$match¶
El operador $match se utiliza principalmente para filtrar los documentos que pasarán a la siguiente etapa del pipeline o a la salida final.
Por ejemplo, para seleccionar sólo las tablets haríamos:
db.productos.aggregate([{$match:{categoria:"Tablets"}}])
Aparte de igualar un valor a un campo, podemos emplear los operadores usuales de consulta, como $gt, $lt, $in, etc…
Se recomienda poner el operador $match al principio del pipeline para limitar los documentos a procesar en siguientes fases. Si usamos este operador como primera fase podremos hacer uso de los indices de la colección de una manera eficiente.
Así pues, para obtener la cantidad de Tablets de menos de 500 euros haríamos:
> db.productos.aggregate([
{$match:
{categoria:"Tablets",
precio: {$lt: 500}}},
{$group:
{_id: {"empresa":"$fabricante"},
cantidad: {$sum:1}}
}
])
< { _id: { empresa: 'Samsung' }, cantidad: 1 }
{ _id: { empresa: 'Amazon' }, cantidad: 2 }
{ _id: { empresa: 'Google' }, cantidad: 1 }
{ _id: { empresa: 'Apple' }, cantidad: 1 }
$sort¶
El operador $sort ordena los documentos recibidos por el campo, y el orden indicado por la expresión indicada al pipeline.
Por ejemplo, para ordenar los productos por precio descendentemente haríamos:
db.productos.aggregate({$sort:{precio:-1}})
El operador $sort ordena los datos en memoria, por lo que hay que tener cuidado con el tamaño de los datos. Por ello, se emplea en las últimas fases del pipeline, cuando el conjunto de resultados es el menor posible.
Si retomamos el ejemplo anterior, y ordenamos los datos por el precio total tenemos:
> db.productos.aggregate([
{$match:{categoria:"Tablets"}},
{$group:
{_id: {"empresa":"$fabricante"},
totalPrecio: {$sum:"$precio"}}
},
{$sort:{totalPrecio:-1}} // (1)!
])
< { _id: { empresa: 'Apple' }, totalPrecio: 1797 }
{ _id: { empresa: 'Samsung' }, totalPrecio: 450.99 }
{ _id: { empresa: 'Amazon' }, totalPrecio: 328 }
{ _id: { empresa: 'Google' }, totalPrecio: 199 }
- Al ordenar los datos, referenciamos al campo que hemos creado en la fase de $group
Un operador muy relacionado es $sortByCount. Este operador es similar a realizar las siguientes operaciones:
{ $group: { _id: <expresion>, cantidad: { $sum: 1 } } },
{ $sort: { cantidad: -1 } }
Así pues, podemos reescribir la consulta que hemos hecho en el operador $group:
db.productos.aggregate([
{ $group: {
_id: "$fabricante",
total: { $sum:1 }
}
},
{$sort: {"total": -1}}
])
Y hacerla con:
db.productos.aggregate([{ $sortByCount: "$fabricante"}])
{ _id: 'Apple', count: 4 }
{ _id: 'Samsung', count: 2 }
{ _id: 'Amazon', count: 2 }
{ _id: 'Sony', count: 1 }
{ _id: 'Google', count: 1 }
$skip y $limit¶
El operador $limit únicamente limita el número de documentos que pasan a través del pipeline.
El operador recibe un número como parámetro:
db.productos.aggregate([{$limit:3}])
Este operador no modifica los documentos, sólo restringe quien pasa a la siguiente fase.
De manera similar, con el operador $skip, saltamos un número determinado de documentos:
db.productos.aggregate([{$skip:3}])
El orden en el que empleemos estos operadores importa, y mucho, ya que no es lo mismo saltar y luego limitar, donde la cantidad de elementos la fija $limit:
> db.productos.aggregate([{$skip:2}, {$limit:3}])
< { _id: ObjectId("635194b32e6059646a8e7fee"),
nombre: 'iPad 64GB Wifi',
categoria: 'Tablets',
fabricante: 'Apple',
precio: 699 }
{ _id: ObjectId("635194b32e6059646a8e7fef"),
nombre: 'Galaxy S3',
categoria: 'Smartphones',
fabricante: 'Samsung',
precio: 563.99 }
{ _id: ObjectId("635194b32e6059646a8e7ff0"),
nombre: 'Galaxy Tab 10',
categoria: 'Tablets',
fabricante: 'Samsung',
precio: 450.99 }
En cambio, si primero limitamos y luego saltamos, la cantidad de elementos se obtiene de la diferencia entre el límite y el salto:
> db.productos.aggregate([{$limit:3}, {$skip:2}])
> { _id: ObjectId("635194b32e6059646a8e7fee"),
nombre: 'iPad 64GB Wifi',
categoria: 'Tablets',
fabricante: 'Apple',
precio: 699 }
$sample
Si tenemos un dataset muy grande, y queremos probar las consultas con un número reducido de documentos, podemos emplear el operador $sample y reducir la cantidad de documentos de manera aleatoria:
db.productos.aggregate([ { $sample: { size: 3 } } ])
$unwind¶
El operador $unwind es muy interesante y se utiliza sólo con operadores array. Al usarlo con un campo array de tamaño N en un documento, lo transforma en N documentos con el campo tomando el valor individual de cada uno de los elementos del array.
Si retomamos el ejemplo de la sesión anterior donde actualizábamos una colección de enlaces, teníamos un enlace con la siguiente información:
> db.enlaces.findOne()
< { _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es',
tags: [ 'mapas', 'videos', 'blog', 'calendario', 'email', 'mapas' ] }
Podemos observar como el campo tags contiene 6 valores dentro del array (con un valor repetido). A continuación vamos a desenrollar el array:
> db.enlaces.aggregate([
{$match:{titulo:"www.google.es"}},
{$unwind:"$tags"}
])
< { _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'mapas' }
{ _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'videos' }
{ _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'blog' }
{ _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'calendario' }
{ _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'email' }
{ _id: ObjectId("635533668420cd585aac88f3"),
titulo: 'www.google.es', tags: 'mapas' }
Así pues hemos obtenido 6 documentos con el mismo _id y titulo, es decir, un documento por elemento del array.
De este modo, podemos realizar consultas que sumen/cuenten los elementos del array. Por ejemplo, si queremos obtener las 3 etiquetas que más aparecen en todos los enlaces haríamos:
> db.enlaces.aggregate([
{"$unwind":"$tags"},
{"$group":
{"_id":"$tags",
"total":{$sum:1}
}
},
{"$sort":{"total":-1}},
{"$limit": 3}
])
< { _id: 'mapas', total: 2 }
{ _id: 'blog', total: 1 }
{ _id: 'calendario', total: 1 }
Doble $unwind¶
Si trabajamos con documentos que tienen varios arrays, podemos necesitar desenrollar los dos arrays. Al hacer un doble unwind se crea un producto cartesiano entre los elementos de los 2 arrays.
Supongamos que tenemos los datos del siguiente inventario de ropa:
> db.inventario.drop();
> db.inventario.insertOne({'nombre':"Camiseta",
'tallas':["S", "M", "L"],
'colores':['azul', 'blanco', 'naranja', 'rojo']})
> db.inventario.insertOne({'nombre':"Jersey",
'tallas':["S", "M", "L", "XL"],
'colores':['azul', 'negro', 'naranja', 'rojo']})
> db.inventario.insertOne({'nombre':"Pantalones",
'tallas':["32x32", "32x30", "36x32"],
'colores':['azul', 'blanco', 'naranja', 'negro']})
Para obtener un listado de cantidad de pares talla/color haríamos:
> db.inventario.aggregate([
{$unwind: "$tallas"},
{$unwind: "$colores"},
{$group:
{ '_id': {'talla': '$tallas', 'color': '$colores'},
'total' : {'$sum': 1}
}
}
])
{ "_id" : { "talla" : "XL", "color" : "rojo" }, "total" : 1 }
{ "_id" : { "talla" : "XL", "color" : "negro" }, "total" : 1 }
{ "_id" : { "talla" : "L", "color" : "negro" }, "total" : 1 }
{ "_id" : { "talla" : "M", "color" : "negro" }, "total" : 1 }
...
$lookup¶
Si necesitamos unir los datos de dos colecciones, emplearemos el operador $lookup, el cual realiza un left outer join a una colección de la misma base de datos para filtrar los documentos de la colección joineada.
El resultado es un nuevo campo array para cada documento de entrada, el cual contiene los documentos que cumplen el criterio del join.
El operador $lookup utiliza cuatro parámetros:
from: colección con la que se realiza el join.localField: campo de la colección origen (sería la clave ajena).foreignField: campo en la colección destino que permite la unión (sería la clave primaria de la otra colección).as: nombre del array que contendrá los documentos enlazados.
Preparando los datos
Vamos a utilizar la colección zips empleada en anteriores sesiones la cual tiene una estructura similar a:
{ _id: ObjectId("5c8eccc1caa187d17ca6ed18"),
city: 'ACMAR',
zip: '35004',
loc: { y: 33.584132, x: 86.51557 },
pop: 6055,
state: 'AL' }
A continuación vamos a crear una nueva colección llamada state con el nombre de los estados (states.js), la cual cargaremos en la base de datos sample_training:
db.states.insertMany([
{
"name": "Alabama",
"abbreviation": "AL"
},
{
"name": "Alaska",
"abbreviation": "AK"
},
...
])
Vamos a estudiar como funciona el operador $lookup mediante un ejemplo. Primero vamos a recuperar los tres estados más poblados. Para ello, podríamos hacer la siguiente consulta agregada:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3}
])
{ _id: 'CA', totalPoblacion: 29760021 }
{ _id: 'NY', totalPoblacion: 17990455 }
{ _id: 'TX', totalPoblacion: 16986510 }
Si ahora queremos recuperar el nombre de esos tres estados, añadimos una nueva fase:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
])
Y ahora obtenemos para cada documento, un array con los documentos que coinciden (en este caso es una relación 1:1, y por eso cada array sólo contiene un elemento):
{ _id: 'CA',
totalPoblacion: 29760021,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0cd5"),
name: 'California',
abbreviation: 'CA' } ] }
{ _id: 'NY',
totalPoblacion: 17990455,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0cf4"),
name: 'New York',
abbreviation: 'NY' } ] }
{ _id: 'TX',
totalPoblacion: 16986510,
estados:
[ { _id: ObjectId("63565cd82889ecee358e0d02"),
name: 'Texas',
abbreviation: 'TX' } ] }
Como la relación siempre va a provocar la creación de un array, mediante $unwind, lo podemos deshacer:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"}
])
{ _id: 'CA',
totalPoblacion: 29760021,
estados:
{ _id: ObjectId("63565cd82889ecee358e0cd5"),
name: 'California',
abbreviation: 'CA' } }
{ _id: 'NY',
totalPoblacion: 17990455,
estados:
{ _id: ObjectId("63565cd82889ecee358e0cf4"),
name: 'New York',
abbreviation: 'NY' } }
{ _id: 'TX',
totalPoblacion: 16986510,
estados:
{ _id: ObjectId("63565cd82889ecee358e0d02"),
name: 'Texas',
abbreviation: 'TX' } }
Así pues, para finalmente obtener el nombre de cada estado, mediante $project recuperamos el campo name:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$sort:{"totalPoblacion":-1}} ,
{$limit: 3},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"},
{$project: {
"estado": "$estados.name",
"poblacion": "$totalPoblacion"
}}
])
Obteniendo el resultado deseado:
{ _id: 'CA', estado: 'California', poblacion: 29760021 }
{ _id: 'NY', estado: 'New York', poblacion: 17990455 }
{ _id: 'TX', estado: 'Texas', poblacion: 16986510 }
Persistiendo los resultados¶
Una vez hemos realizado nuestras consultas mediante el framework de agregación, es muy posible que queramos almacenar el resultado en una nueva colección para poder volver a consultar el resultado sin necesidad de ejecutar todas las fases.
Para ello, podemos emplear los operadores:
$outrecoge los documentos de una agregación y los persiste en una colección, sobrescribiendo los datos existentes.$mergesimilar a$out, pero permite añadir el resultado a la misma colección y además soporta trabajar con colecciones particionadas.
Por ejemplo, vamos a basarnos en las consultas con join, para crear una nueva colección con la población total de todos dos estados, y la vamos a almacenar en una nueva colección denominada states_population:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"},
{$project: {
"estado": "$estados.name",
"poblacion": "$totalPoblacion"
}},
{$out: "states_population"}
])
Tras su ejecución, podemos recuperar los datos:
> db.states_population.findOne()
< { _id: 'WY', estado: 'Wyoming', poblacion: 453588 }
De SQL al Pipeline de agregaciones¶
Ya hemos visto que el pipeline ofrece operadores para realizar la misma funcionalidad de agrupación que ofrece SQL.
Si relacionamos los comandos SQL con el pipeline de agregaciones tenemos las siguientes equivalencias:
| SQL | Pipeline de Agregaciones |
|---|---|
| WHERE | $match |
| GROUP BY | $group |
| HAVING | $match |
| SELECT | $project |
| ORDER BY | $sort |
| LIMIT | $limit |
| SUM() | $sum |
| COUNT() | $sum / $sortByCount |
| join | $lookup |
Podemos encontrar ejemplos de consultas SQL transformadas al pipeline en https://www.mongodb.com/docs/manual/reference/sql-aggregation-comparison/
Limitaciones¶
Hay que tener en cuenta las siguiente limitaciones:
- En versiones anteriores a la 2.6, el pipeline devolvía en cada fase un objeto BSON, y por tanto, el resultado estaba limitado a 16MB
- Actualmente, sólo cada documento que forme parte del resultado final debe ocupar menos de 16MB.
- Las fases tienen un límite de 100MB en memoria. Si una fase excede dicho límite, se producirá un error. En este caso, hay que habilitar el uso de disco mediante
allowDiskUseen las opciones de la agregación.
Más información en https://www.mongodb.com/docs/manual/core/aggregation-pipeline-limits/
Agregaciones con Compass¶
MongoDB Compass nos ofrece la herramienta Aggregation Pipeline Builder para crear, borrar y reorganizar fácilmente fases en un pipeline, así como evaluar los documento resultantes en tiempo real.
Vamos a practicar con la colección de zips:
Y vamos a reproducir la consulta con $lookup que acabamos de realizar, pero en nuestro caso, iremos paso a paso:
db.zips.aggregate([
{$group: {
_id: "$state",
"totalPoblacion": {$sum:"$pop"}
}},
{$lookup: {
from: "states",
localField: "_id",
foreignField: "abbreviation",
as: "estados"
}},
{$unwind:"$estados"},
{$project: {
"estado": "$estados.name",
"poblacion": "$totalPoblacion"
}}
])
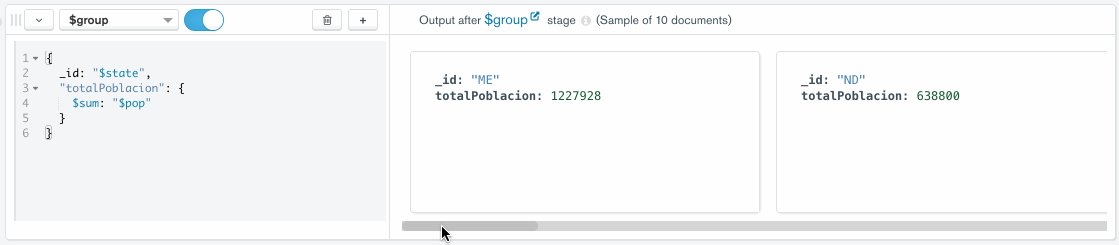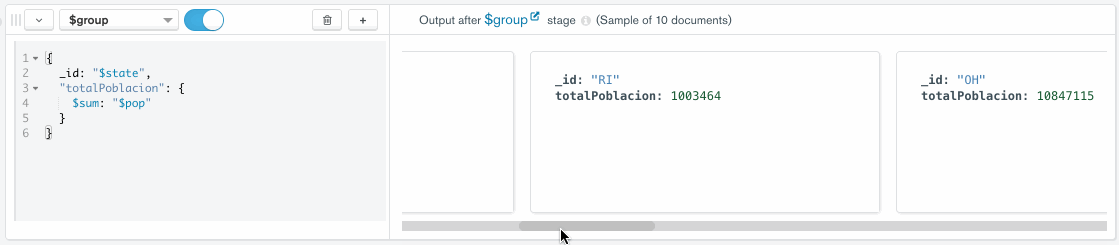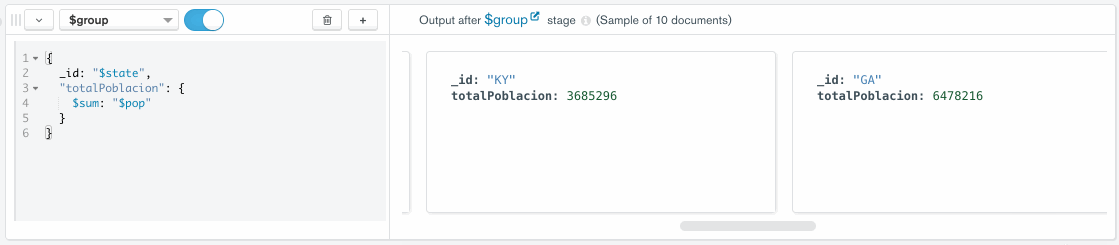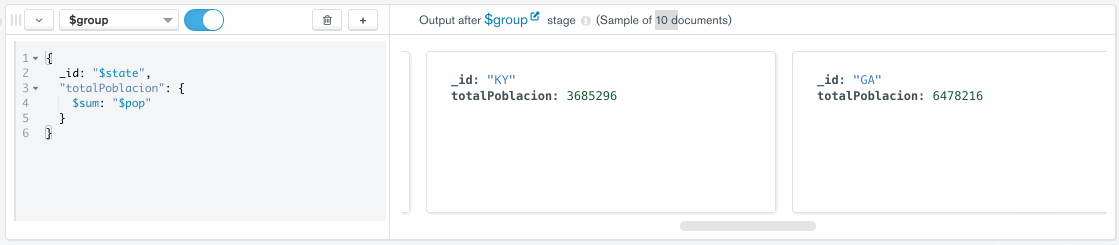
Para ello, pulsamos sobre el botón de Add Stage, seleccionamos el operador $group y escribimos la expresión de agrupación. Al hacerlo, en el panel anexo aparecerán 10 documentos de muestra con el resultado de ejecutar dicha fase:
Paso a paso, iremos añadiendo el resto de fases hasta tenerlas todas, pudiendo ver los datos que va generando cada fase:

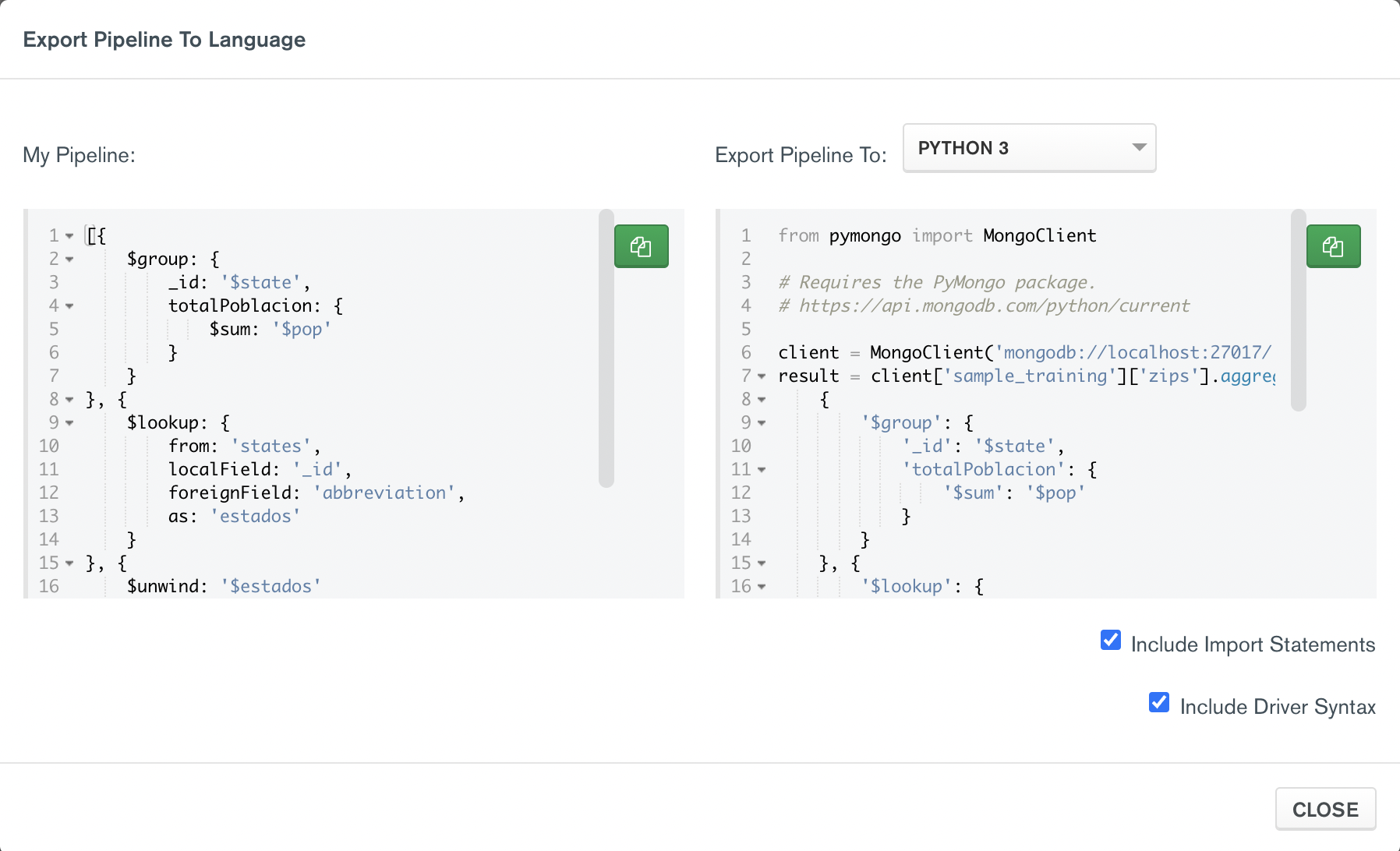
Una vez tenemos nuestra agregación, podemos obtener una versión del pipeline en Python, Java, C# o Node.js, mediante la opción Export-to-Language.
Referencias¶
- Documentación oficial del Aggregation Framework.
- Curso M121: The MongoDB Aggregation Framework de la Mongo University.
- Libro Practical MongoDB Aggregations
Actividades¶
Para las siguientes actividades, vamos a utilizar la base de datos sample_mflix, y en concreto, la colección movies . Un documento de ejemplo sería similar a:
{ _id: ObjectId("573a1390f29313caabcd548c"),
plot: 'The Civil War divides ...',
genres: [ 'Drama', 'History', 'Romance' ],
runtime: 165,
rated: 'NOT RATED',
cast:
[ 'Lillian Gish',
'Mae Marsh',
'Henry B. Walthall',
'Miriam Cooper' ],
poster: 'https://m.media-amazon.com/images/M/MV5BYTM4ZDhiYTQtYzExNC00YjVlLTg2YWYtYTk3NTAzMzcwNTExXkEyXkFqcGdeQXVyNjU0OTQ0OTY@._V1_SY1000_SX677_AL_.jpg',
title: 'The Birth of a Nation',
fullplot: 'Two brothers...',
countries: [ 'USA' ],
released: 1915-03-03T00:00:00.000Z,
directors: [ 'D.W. Griffith' ],
writers:
[ 'Thomas Dixon Jr. (adapted from ...")',
'Thomas Dixon Jr. (play)',
'Thomas Dixon Jr. (novel)',
'D.W. Griffith',
'Frank E. Woods' ],
awards: { wins: 2, nominations: 0, text: '2 wins.' },
lastupdated: '2015-09-11 00:32:27.763000000',
year: 1915,
imdb: { rating: 6.8, votes: 15715, id: 4972 },
type: 'movie',
tomatoes:
{ viewer: { rating: 3.2, numReviews: 4358, meter: 57 },
dvd: 2004-06-29T00:00:00.000Z,
critic: { rating: 8, numReviews: 38, meter: 100 },
lastUpdated: 2015-09-10T18:30:23.000Z,
consensus: 'Racial depictions aside...',
rotten: 0,
production: 'Gravitas',
fresh: 38 },
num_mflix_comments: 0 }
-
(RA5075.1 / CE5.1d / 3p) Haciendo uso del framework de agregación y el shell de MongoDB, resuelve las siguientes consultas:
- (0.5) Encuentra todas las películas que entre sus géneros (
genres) se encuentre elDrama. Sólo queremos recuperar el título y la calificación (rating) de IMDB. - (0.5) Recupera los títulos de las tres películas románticas (
Romance) con mayor calificación en IMDB que se lanzaron (released) antes del 2001. - (0.5) Averigua la cantidad de películas que hay de cada categoría de calificación (
rated). -
(0.5) Teniendo en cuenta las películas anteriores al año 2001, para cada género, recupera la media y la máxima calificación en IMDB así como el tiempo ajustado (con trailers, los cuales duran 12 minutos) de la película más larga, ordenando los géneros por popularidad.
El resultado será similar a:
{ _id: 'Film-Noir', nota_media: 7.62, mejor_nota: 8.3, tiempo_ajustado: 123 } { _id: 'Documentary', nota_media: 7.555313351498638, mejor_nota: 9.4, tiempo_ajustado: 1152 } { _id: 'Short', nota_media: 7.386, mejor_nota: 8.6, tiempo_ajustado: 56 } ... -
(0.5) Sobre la consulta anterior, además de la información ya recuperada, queremos buscar qué película recomendar de cada categoría siempre y cuando duren un máximo de 218 minutos y tengan al menos una calificación de 7. (pista: necesitas utilizar
$first)El resultado será similar a:
{ _id: 'Documentary', titulo_recomendado: 'Cosmos', nota_recomendado: 9.3, tiempo_recomendado: 60, popularidad: 7.69695945945946, mejor_nota: 9.3, tiempo_ajustado_maslargo: 212 } { _id: 'Sci-Fi', titulo_recomendado: 'Blade Runner', nota_recomendado: 8.2, tiempo_recomendado: 117, popularidad: 7.3999999999999995, mejor_nota: 8.2, tiempo_ajustado_maslargo: 209 } ... -
(0.5) Recupera las 5 películas más comentadas (los comentarios se almacenan en la colección
comments), devolviendo el título, su género y la cantidad de comentarios. Además, queremos almacenar el resultado en la colecciónmovies_most_commented.> db.most_commented_movies.findOne() < { _id: ObjectId("573a13bff29313caabd5e91e"), sumComments: 161, movie: { imdb: { rating: 6.4 }, title: 'The Taking of Pelham 1 2 3' } }
- (0.5) Encuentra todas las películas que entre sus géneros (
-
(RA5075.1 / CE5.1d / 1p) Haciendo uso de MongoDBCompass, mejora la siguiente consulta que obtiene los tres documentales más premiados, siempre y cuando hayan ganado algún premio:
var pipeline = [ { $sort: {"awards.wins": -1}}, // Ordenamos por premios ganados { $match: {"awards.wins": { $gte: 1}}}, { $limit: 20}, // Obtenemos las 20 películas que han ganado más de un premio { $match: { genres: {$in: ["Documentary"]}, // Nos quedamos con los documentales }}, { $project: { title: 1, genres: 1, awards: 1}}, { $limit: 3}, ]; db.movies.aggregate(pipeline)Adjunta una captura inicial y otra final, y la exportación de la agregación a Python.