Apache Kafka Avanzado¶
En esta sesión estudiaremos cómo crear un cluster de Kafka, realizamos una integración desde un servicio REST hasta su persistencia en S3 y MongoDB haciendo uso de Kafka como middleware de integración, y finalmente veremos como utilizar Kafka Connect para integrar sistemas.
Caso 2: Clúster de Kafka¶
En Kafka hay tres tipos de clústers:
- Un nodo con un broker
- Un nodo con muchos brokers
- Muchos nodos con múltiples brokers
Para nuestro ejemplo, como sólo disponemos de una máquina, crearemos 3 brokers en un nodo.
Creando brokers¶
Para ello, vamos a crear diferentes archivos de configuración a partir del fichero config/server.properties que utilizábamos para arrancar el servidor.
Así pues, crearemos 3 copias del archivo modificando las propiedades broker.id (identificador del broker), listeners (URL y puerto de escucha del broker) y log.dirs (carpeta donde se guardaran los logs del broker):
broker.id=101
listeners=PLAINTEXT://:9092
log.dirs=/opt/kafka_2.13-3.3.1/logs/broker_101
zookeeper.connect=localhost:2181
broker.id=102
listeners=PLAINTEXT://:9093
log.dirs=/opt/kafka_2.13-3.3.1/logs/broker_102
zookeeper.connect=localhost:2181
broker.id=103
listeners=PLAINTEXT://:9094
log.dirs=/opt/kafka_2.13-3.3.1/logs/broker_103
zookeeper.connect=localhost:2181
Una vez creados los tres archivos, ejecutaremos los siguientes comandos (cada uno en un terminal diferente) para arrancar Zookeeper y cada uno de los brokers:
zookeeper-server-start.sh ./config/zookeeper.properties
kafka-server-start.sh ./config/server101.properties
kafka-server-start.sh ./config/server102.properties
kafka-server-start.sh ./config/server103.properties
Creando topics¶
Con cada comando que vayamos a interactuar con Kafka, le vamos a pasar como parámetro --bootstrap-server iabd-virtualbox:9092 para indicarle donde se encuentra uno de los brokers (en versiones antiguas de Kafka se indicaba donde estaba Zookeeper mediante --zookeeper iabd-virtualbox:9092).
A la hora de crear un topic, además de indicarle donde está Zookeeper y el nombre del topic, indicaremos:
- la cantidad de particiones con el parámetro
--partitions - el factor de replicación con el parámetro
--replication-factor
Así pues, vamos a crear un topic con tres particiones y factor de replicación 2:
kafka-topics.sh --create --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092 \
--partitions 3 --replication-factor 2
Si ahora obtenemos la información del topic
kafka-topics.sh --describe --topic iabd-topic-3p2r \
--bootstrap-server iabd-virtualbox:9092
Podemos observar como cada partición tiene la partición líder en un broker distinto y en qué brokers se encuentran las réplicas:
Topic: iabd-topic-3p2r TopicId: lyrv4qXkS1-c09XAXnIj7w PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: iabd-topic-3p2r Partition: 0 Leader: 103 Replicas: 103,102 Isr: 103,102
Topic: iabd-topic-3p2r Partition: 1 Leader: 102 Replicas: 102,101 Isr: 102,101
Topic: iabd-topic-3p2r Partition: 2 Leader: 101 Replicas: 101,103 Isr: 101,103
Produciendo y consumiendo¶
Respecto al código Python, va a ser el mismo que hemos visto antes pero modificando:
- el nombre del topic
- la lista de boostrap_servers (aunque podríamos haber dejado únicamente el nodo principal, ya que Kafka le comunica al cliente el resto de nodos del clúster, es una buena práctica por si el nodo al que nos conectamos de manera explícita está caído).
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(
value_serializer=lambda m: dumps(m).encode('utf-8'),
bootstrap_servers=['iabd-virtualbox:9092','iabd-virtualbox:9093','iabd-virtualbox:9094'])
for i in range(10):
producer.send("iabd-topic-3p2r", value={"nombre": "producer " + str(i)}, key=b"iabd")
# Como el envío es asíncrono, para que no se salga del programa antes de enviar el mensaje, esperamos 1 seg
time.sleep(1)
En el consumidor, además hemos modificado la forma de mostrar los mensajes para visualizar más información:
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'iabd-topic-3p2r',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='iabd-grupo-1',
value_deserializer=lambda m: loads(m.decode('utf-8')),
bootstrap_servers=['iabd-virtualbox:9092','iabd-virtualbox:9093','iabd-virtualbox:9094'])
for m in consumer:
print(f"P:{m.partition} O:{m.offset} K:{m.key} V:{m.value}")
Como ahora tenemos los datos repartidos en dos brokers (por el factor de replicación) y tres particiones, los datos consumidos no tienen por qué llegar en orden (como es el caso), ya que los productores han enviado los datos de manera aleatoria para repartir la carga:
P:1 O:0 K:None V:{'nombre': 'producer 0'}
P:1 O:1 K:None V:{'nombre': 'producer 3'}
P:2 O:0 K:None V:{'nombre': 'producer 1'}
P:2 O:1 K:None V:{'nombre': 'producer 5'}
P:2 O:2 K:None V:{'nombre': 'producer 6'}
P:2 O:3 K:None V:{'nombre': 'producer 7'}
P:2 O:4 K:None V:{'nombre': 'producer 8'}
P:0 O:0 K:None V:{'nombre': 'producer 2'}
P:0 O:1 K:None V:{'nombre': 'producer 4'}
P:0 O:2 K:None V:{'nombre': 'producer 9'}
Para asegurarnos el orden, debemos enviar los mensajes con una clave de partición con el atributo key del método send:
producer.send("iabd-topic-3p2r",
value={"nombre": "producer " + str(i)},
key=b"iabd")
Si volvemos a ejecutar el productor con esa clave, el resultado sí que sale ordenado:
P:0 O:3 K:b'iabd' V:{'nombre': 'producer 0'}
P:0 O:4 K:b'iabd' V:{'nombre': 'producer 1'}
P:0 O:5 K:b'iabd' V:{'nombre': 'producer 2'}
P:0 O:6 K:b'iabd' V:{'nombre': 'producer 3'}
P:0 O:7 K:b'iabd' V:{'nombre': 'producer 4'}
P:0 O:8 K:b'iabd' V:{'nombre': 'producer 5'}
P:0 O:9 K:b'iabd' V:{'nombre': 'producer 6'}
P:0 O:10 K:b'iabd' V:{'nombre': 'producer 7'}
P:0 O:11 K:b'iabd' V:{'nombre': 'producer 8'}
P:0 O:12 K:b'iabd' V:{'nombre': 'producer 9'}
Decisiones de rendimiento¶
Aunque podemos modificar la cantidad de particiones y el factor de replicación una vez creado el clúster, es mejor hacerlo de la manera correcta durante la creación ya que tienen un impacto directo en el rendimiento y durabilidad del sistema:
- si el número de particiones crece con el clúster ya creado, el orden de las claves no está garantizado.
- si se incrementa el factor de replicación durante el ciclo de vida de un topic, estaremos metiendo presión al clúster, que provocará un decremento inesperado del rendimiento.
Cada partición puede manejar un rendimiento de unos pocos MB/s. Al añadir más particiones, obtendremos mejor paralelización y por tanto, mejor rendimiento. Además, podremos ejecutar más consumidores en un grupo. Pero el hecho de añadir más brokers al clúster para que las particiones los aprovechen, provocará que Zookeeper tenga que realizar más elecciones y que Kafka tenga más ficheros abiertos.
Guía de rendimiento
Una propuesta es:
- Si nuestro clúster es pequeño (menos de 6 brokers), crear el doble de particiones que brokers.
- Si tenemos un clúster grande (más de 12 brokers), crear la misma cantidad de particiones que brokers.
- Ajustar el número de consumidores necesarios que necesitamos que se ejecuten en paralelo en los picos de rendimiento.
Independientemente de la decisión que tomemos, hay que realizar pruebas de rendimiento con diferentes configuraciones.
Respecto al factor de replicación, debería ser, al menos 2, siendo 3 la cantidad recomendada (es necesario tener al menos 3 brokers) y no sobrepasar de 4. Cuanto mayor sea el factor de replicación (RF):
- El sistema tendrá mejor tolerancia a fallos (se pueden caer RF-1 brokers)
- Pero tendremos mayor replicación (lo que implicará una mayor latencia si
acks=all) - Y también ocupará más espacio en disco (50% más si RF es 3 en vez de 2).
Respecto al clúster, se recomienda que un broker no contenga más de 2000-4000 particiones (entre todos los topics de ese broker). Además, un clúster de Kafka debería tener un máximo de 20.000 particiones entre todos los brokers, ya que si se cayese algún nodo, Zookeeper necesitaría realizar muchas elecciones de líder.
Caso 3: De AEMET a S3 y MongoDB¶
En este caso de uso vamos a repetir el que hicimos en la sesión de Nifi pero utilizando Kafka como elemento de integración, desacoplando los productores de los consumidores.
Productor de AEMET¶
Tras recuperar la petición REST que realizamos a AEMET vamos a:
- enviar su resultado a un topic que llamaremos
iabd-aemet-bronze. - generar un nuevo mensaje JSON más pequeño con la información que nos interesa, y enviar este nuevo mensaje a un topic que llamaremos
iabd-aemet-silver.
Así pues, primero creamos los topics:
kafka-topics.sh --create --topic iabd-aemet-bronze --bootstrap-server iabd-virtualbox:9092
kafka-topics.sh --create --topic iabd-aemet-silver --bootstrap-server iabd-virtualbox:9092
Y a continuación desarrollamos el productor, que hará uso de la librería request:
from kafka import KafkaProducer
from json import dumps
from datetime import datetime
import time
import requests
# Creamos el productor de Kafka
producer = KafkaProducer(
bootstrap_servers=['iabd-virtualbox:9092'])
# Realizamos la petición REST
url_aemet = "https://www.el-tiempo.net/api/json/v2/provincias/03/municipios/03065"
while True:
r = requests.get(url_aemet)
resp_json = r.json()
producer.send("iabd-aemet-bronze", value=dumps(resp_json).encode('utf-8'))
# Creamos el nuevo mensaje JSON con los datos
temp = resp_json["temperatura_actual"]
humedad = resp_json["humedad"]
ciudad = resp_json["municipio"]["NOMBRE"]
fecha = datetime.now()
fecha_str = dumps(fecha, default=str)
datos_json = {
"fecha": fecha,
"ciudad": ciudad,
"temp": temp,
"humedad": humedad
}
producer.send("iabd-aemet-silver", value=dumps(datos_json, default=str).encode('utf-8'))
time.sleep(60)
Consumidor Bronze¶
En el consumidor del topic iabd-aemet-bronze vamos a recuperar las peticiones REST almacenadas en JSON y las persistiremos en S3, en el mismo bucket que creamos en la sesión de Nifi.
En este caso, como el mensaje ya está en formato JSON y no queremos tratarlo, no hace falta deserializarlo ni volverlo a serializar.
El código Python será similar a:
from kafka import KafkaConsumer
from datetime import datetime
import boto3
# Consumidor Kafka
consumer = KafkaConsumer(
'iabd-aemet-bronze',
enable_auto_commit=True,
group_id='iabd-caso3',
bootstrap_servers=['iabd-virtualbox:9092'])
# Conexión con S3
s3r = boto3.resource('s3', region_name='us-east-1')
bucket = s3r.Bucket('iabd-nifi')
for m in consumer:
resp_json = m.value
# Creamos el nombre del fichero con la fecha y lo metemos en la carpeta bronze
nom_fichero = "bronze/" + datetime.now().isoformat() + ".json"
bucket.put_object(Key=nom_fichero, Body=resp_json)
Consumidor Silver y Productor Gold¶
El siguiente paso es bastante más complejo. Ahora realizaremos los siguientes pasos:
- crearemos un consumidor con los mensajes de la cola silver
- y almacenamos los mensajes en S3
- además, el mismo mensaje lo insertaremos en MongoDB en la colección
caso3 - y cuando tengamos 10 mensajes crearemos uno nuevo con el cálculo de la temperaturas y humedades medias
- para finalmente producir dicho mensaje al topic
iabd-aemet-gold.
Así pues, primero creamos el topic gold:
kafka-topics.sh --create --topic iabd-aemet-gold --bootstrap-server iabd-virtualbox:9092
Así pues, antes de empezar, colocamos las dependencias y la función para transformar un diccionario JSON con todo el contenido en String a diferentes tipos (float, ISODate, ...):
from kafka import KafkaConsumer, KafkaProducer
from datetime import datetime
from json import loads, dumps
from pymongo import MongoClient
import boto3
import pandas as pd
import numpy as np
# Convierte un diccionario JSON con todo el contenido en String a diferentes tipos (float, ISODate, ...)
def esquema_json(dct):
result = {}
if ('fecha' in dct):
result["fecha"] = datetime.fromisoformat(dct["fecha"])
if 'temp' in dct:
result["temp"] = float(dct["temp"])
if 'humedad' in dct:
result["humedad"] = float(dct["humedad"])
if 'ciudad' in dct:
result["ciudad"] = dct["ciudad"]
return result
A continuación definimos las conexiones necesarios para los pasos 1 (consumir Kafka en el topic silver), 2 (enviar a S3), 3 (persistir en MongoDB) y 5 (producir Kafka en el topic gold):
# Paso 1 - Consumir Silver
consumer = KafkaConsumer(
'iabd-aemet-silver',
enable_auto_commit=True,
group_id='iabd-caso3',
bootstrap_servers=['iabd-virtualbox:9092'])
# Paso 2 - Conexión con S3
s3r = boto3.resource('s3', region_name='us-east-1')
bucket = s3r.Bucket('iabd-nifi')
# Paso 3 - Conexión con MongoDB
clienteMongo = MongoClient('mongodb://localhost:27017')
# Paso 5 - Producir Gold
producer = KafkaProducer(
bootstrap_servers=['iabd-virtualbox:9092'])
Y para cada mensaje que consumimos, realizamos los pasos 2 (enviar a S3), 3 (persistir en MongoDB), 4 (calcular los datos agregados) y 5 (producir en Kafka en gold):
cantidad = 1
mensajes = []
for m in consumer:
resp_json = m.value
doc_json = loads(resp_json, object_hook=esquema_json)
mensajes.append(doc_json)
# Paso 2 - Metemos en S3 cada mensaje
nom_fichero = "silver/" + datetime.now().isoformat() + ".json"
bucket.put_object(Key=nom_fichero, Body=resp_json)
# Paso 3 - Lo insertamos en MongoDB
colcaso3 = clienteMongo.iabd.caso3
resultado = colcaso3.insert_one(doc_json)
# Guardamos 10 mensajes
cantidad = cantidad + 1
if cantidad == 11:
print(mensajes)
# Paso 4 - realizamos el cálculo
# Usamos pandas
pd_mensajes = pd.DataFrame(mensajes)
pd_mensajes.temp = pd_mensajes['temp'].astype('float')
pd_mensajes.humedad = pd_mensajes['humedad'].astype('float')
pd_agg = pd_mensajes.groupby("ciudad").agg({"fecha":np.max, "temp":np.mean, "humedad":np.mean})
pd_agg.reset_index(inplace=True)
json_gold = pd_agg.to_json(orient="records")
print(json_gold)
# Paso 5 - producimos el mensaje a Kafka
producer.send("iabd-aemet-gold", value=dumps(json_gold).encode('utf-8'))
# vaciamos la lista e inicializamos el contador
mensajes = []
cantidad = 1
Si en un terminal creamos un consumidor del topic iabd-aemet-gold:
kafka-console-consumer.sh --topic iabd-aemet-gold --from-beginning --bootstrap-server iabd-virtualbox:9092
Veremos que los mensajes que llegan son similares a:
{"ciudad":"Elche\/Elx","fecha":1679416092670,"temp":20.8,"humedad":50.0}
Caso 4: Ahora con Nifi¶
Vamos a repetir el flujo de datos que acabamos de crear en el caso anterior, pero implementandolos mediante Nifi de forma similar al caso 7 de la segunda sesión de Nifi.
Configuración de procesadores de Nifi
En este apartado hemos obviado la configuración de todos los procesadores vistos en el caso 7 de Nifi, ya que podemos copiar y pegarlos dentro de nuevos grupos de procesadores y evitarnos tener que volver a configurarlos.
De REST a Kafka¶
Sobre un grupo de procesadores que hemos llamado caso4kafka_producer_bronze_silver, vamos a utilizar el procesador InvokeHTTP, mediante el cual hacemos la petición GET a la URL https://www.el-tiempo.net/api/json/v2/provincias/03/municipios/03065.
De este procesador, por un lado vamos a conectar directamente con PublishKafka_2_6 para enviar directamente los datos a Kafka al topic, donde además del topic iabd-aemet-bronce, indicaremos que no utilizaremos transacciones (Use Transactions: false), así como que intente garantizar la entrega (Delivery Guarantee: Best Effort):
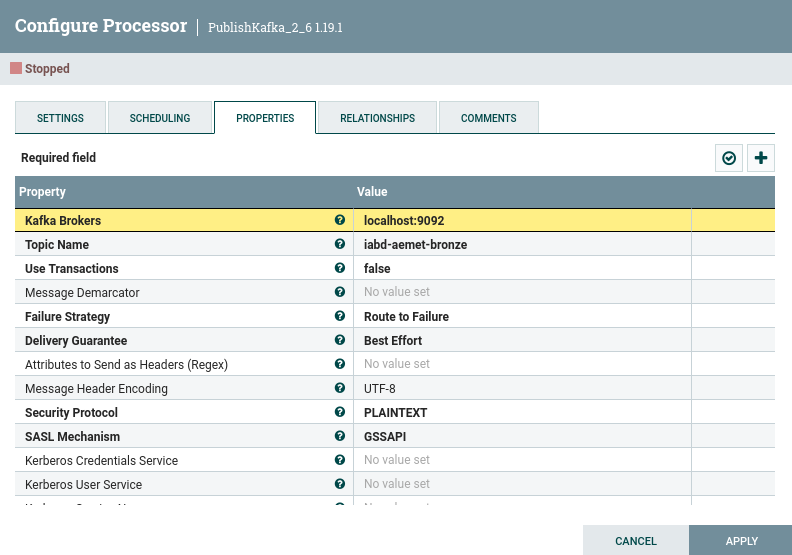
Para el resto de lógica, igual que en la sesión de Nifi, utilizamos EvaluateJSONPath para recoger la ciudad, la temperatura y la humedad, y por último conectamos con AttributesToJSON para generar el JSON que finalmente enviaremos a Kafka.
Ahora, como sí que tenemos un formato más concreto, vamos a utilizar PublishKafkaRecord_2_6 para utilizar un conjunto de registros.
Primero, conectamos todos los procesadores:
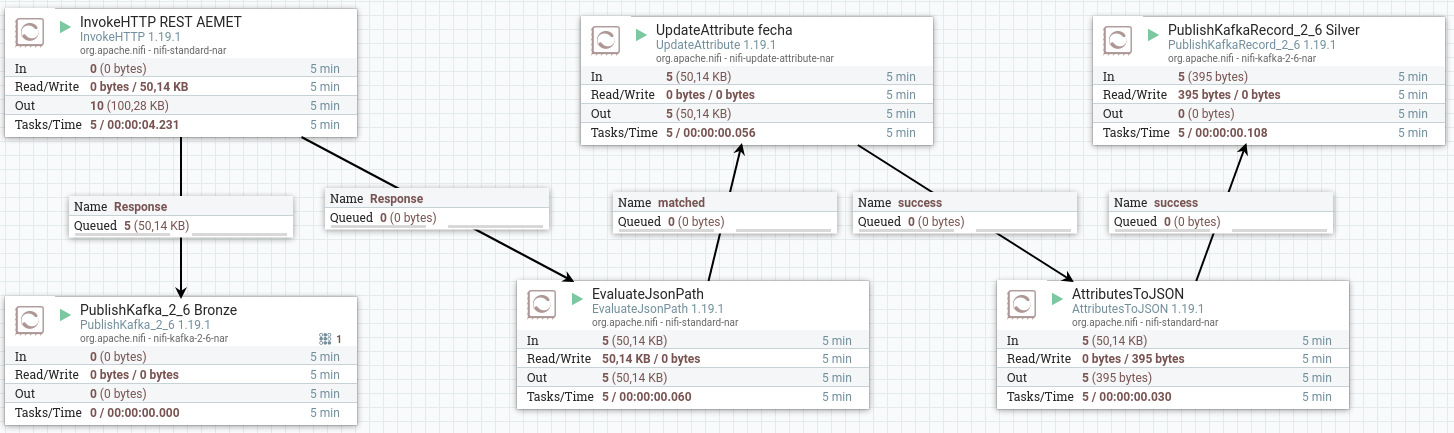
Y configuramos el último procesador con el topic iabd-aemet-silver, pero indicando que vamos a leer tanto como escribir en formato JSON:
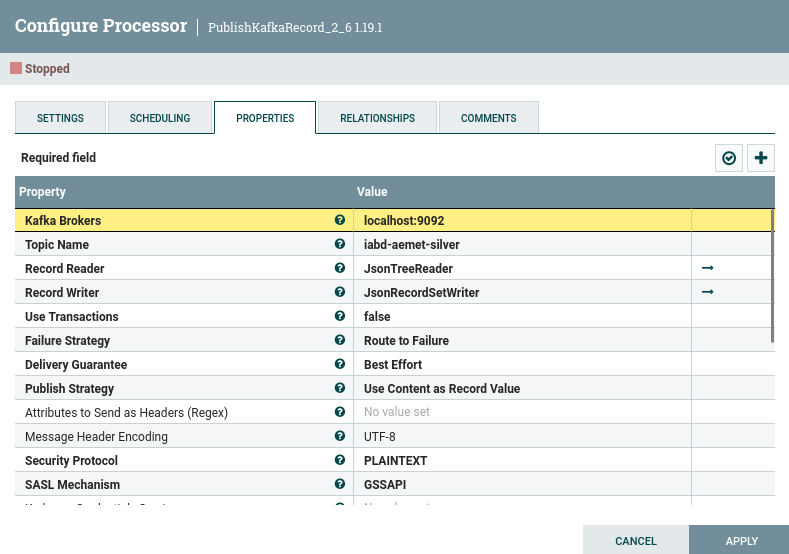
De Kafka a S3¶
Nos vamos a centrar en recuperar los mensajes del topic iabd-aemet-silver y colocarlos en S3, mediante un grupo de procesadores que llamaremos caso4kafka_consumer_bronze que contendrá un flujo similar a:

Y en concreto en el consumidor, hemos de indicar tanto el topic como el grupo de consumidores (Group ID) a iabd-caso4:
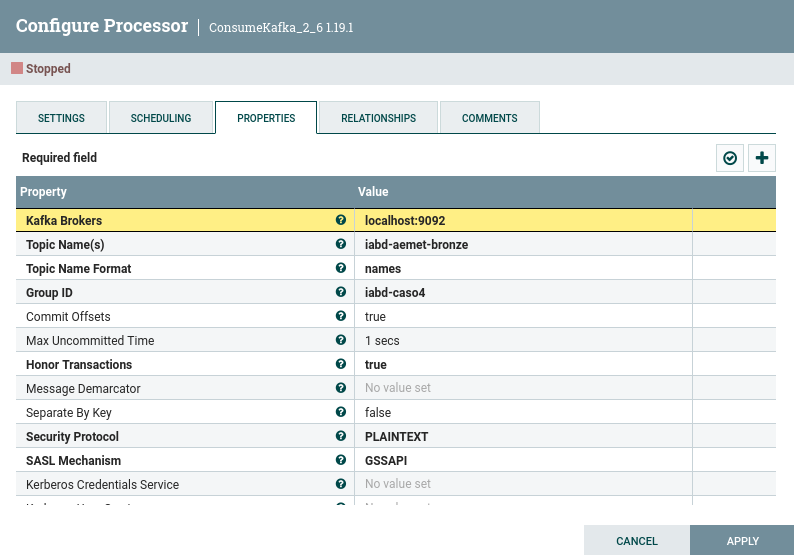
Kafka Connect¶
Si hacerlo con Nifi ya es un avance respecto a tener que codificarlo con Python, ¿qué dirías si Kafka ofreciera una serie de conectores para las operaciones más comunes?
Así pues, Kafka Connect permite importar/exportar datos desde/hacia Kafka, facilitando la integración en sistemas existentes mediante alguno del centenar de conectores disponibles.
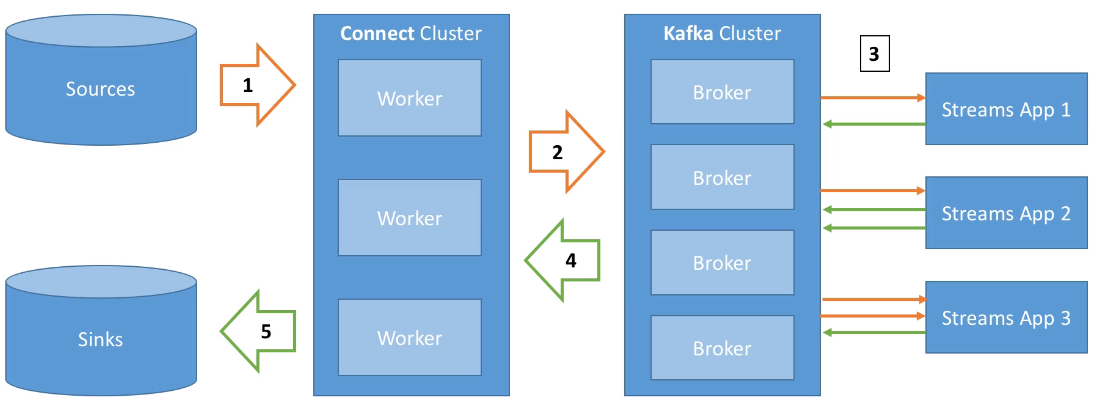
Los elementos que forman Kafka Connect son:
- Conectores fuente (source), para obtener datos desde las fuentes de datos (E en ETL)
- Conectores destino (sink) para publicar los datos en los almacenes de datos (L en ETL).
Estos conectores facilitan que desarrolladores no expertos puedan trabajar con sus datos en Kafka de forma rápida y fiable, de manera que podamos introducir Kafka dentro de nuestros procesos ETL.
Hola Kafka Connect¶
Vamos a realizar un ejemplo muy sencillo leyendo datos de una base de datos para meterlos en Kafka.
Para ello, utilizaremos la base de datos de retail_db que ya hemos empleado en otras sesiones y vamos a cargar en Kafka los datos de la tabla categories:
MariaDB [retail_db]> describe categories;
+------------------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-------------+------+-----+---------+----------------+
| category_id | int(11) | NO | PRI | NULL | auto_increment |
| category_department_id | int(11) | NO | | NULL | |
| category_name | varchar(45) | NO | | NULL | |
+------------------------+-------------+------+-----+---------+----------------
Configuración¶
Cuando ejecutemos Kafka Connect, le debemos pasar un archivo de configuración. Para empezar, tenemos config/connect-standalone.properties el cual ya viene rellenado e indica los formatos que utilizarán los conversores (en nuestro caso ya están configurados para utiliza JSON) y otros aspectos:
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
Los conectores se incluyen en Kafka como plugins. Para ello, primero hemos de indicarle a Kafka donde se encuentran, indicando en el archivo de configuración la ruta donde los almacenaremos (este cambio debemos realizarlo sobre la instalación de nuestra máquina virtual):
plugin.path=/opt/kafka_2.13-3.3.1/plugins
Extrayendo datos mediante Kafka Connect¶
Así pues, el primer paso es crear el archivo de configuración de Kafka Connect con los datos (en nuestro caso lo colocamos en la carpeta config de la instalación de Kafka) utilizando un conector fuente de JDBC:
name=mysql-source
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost/retail_db
connection.user=iabd
connection.password=iabd
table.whitelist=categories
mode=incrementing
incrementing.column.name=category_id
topic.prefix=iabd-retail_db-
Antes de ponerlo en marcha, debemos descargar el conector y colocar la carpeta descomprimida dentro de nuestra carpeta de plugins /opt/kafka_2.13-3.3.1/plugins y descargar el driver de MySQL y colocarlo en la carpeta /opt/kafka_2.13-3.3.1/lib.
Y a continuación ya podemos ejecutar Kafka Connect mediante el comando connect-standalone.sh:
connect-standalone.sh config/connect-standalone.properties config/mysql-source-connector.properties
Si tuviéramos más conectores los añadiríamos como parámetros extra:
connect-standalone.sh config/connect-standalone.properties config/conector1.properties [config/conector2.properties config/conector3.properties ...]
Guava
Es posible que salte un error de ejecución indicando que falta la librería Guava la cual podéis descargar desde aquí y colocar en la carpeta /opt/kafka_2.13-3.3.1/lib
Si ahora arrancamos un consumidor sobre el topic iabd-retail_db-categories:
kafka-console-consumer.sh --topic iabd-retail_db-categories --from-beginning --bootstrap-server iabd-virtualbox:9092
Veremos que aparecen todos los datos que teníamos en la tabla en formato JSON (es lo que hemos indicado en el archivo de configuración de Kafka Connect):
{"schema":{
"type":"struct","fields":[
{"type":"int32","optional":false,"field":"category_id"},
{"type":"int32","optional":false,"field":"category_department_id"},
{"type":"string","optional":false,"field":"category_name"}],
"optional":false,"name":"categories"},
"payload":{"category_id":1,"category_department_id":2,"category_name":"Football"}}
{"schema":{
"type":"struct","fields":[
{"type":"int32","optional":false,"field":"category_id"},
{"type":"int32","optional":false,"field":"category_department_id"},
{"type":"string","optional":false,"field":"category_name"}],
"optional":false,"name":"categories"},
"payload":{"category_id":2,"category_department_id":2,"category_name":"Soccer"}}
...
Autoevaluación
Vamos a dejar el consumidor y Kafka Connect corriendo.
¿Qué sucederá si inserto un nuevo registro en la base de datos en la tabla categories?
Que automáticamente aparecerá en nuestro consumidor.
REST API¶
Como Kafka Connect está diseñado como un servicio que debería correr continuamente, ofrece un API REST para gestionar los conectores. Por defecto está a la escucha el puerto 8083, de manera que si accedemos a http://iabd-virtualbox:8083/ obtendremos información sobre la versión que se está ejecutando:
{"version":"3.3.1","commit":"839b886f9b732b15","kafka_cluster_id":"iHa0JUnTSfm85fvFadsylA"}
Por ejemplo, si queremos obtener un listado de los conectores realizaremos una petición GET a /connectors mediante http://iabd-virtualbox:8083/connectors:
["mysql-source-connector"]
Más información en https://kafka.apache.org/documentation/#connect_rest
Más Kafka Connect
En este apartado sólo hemos visto una pequeña introducción a Kafka Connect, dejando de lado aspectos como la ejecución en modo distribuido (por supuesto, podemos montar un clúster de Kafka Connect), la realización de pequeñas transformaciones sobre los datos o practicar con otro tipo de conectores.
Kafka Streams
Kafka Streams es la tercera pata del ecosistema de Kafka, y permite procesar y transformar datos dentro de Kafka. Una vez que los datos se almacenan en Kafka como eventos, podemos procesar los datos en nuestras aplicaciones cliente mediante Kafka Streams y sus librerías desarrolladas en Java y/o Scala, ya que requiere una JVM.
En nuestro caso, realizaremos en posteriores sesiones un procesamiento similar de los datos mediante Spark Streaming, permitiendo operaciones con estado y agregaciones, funciones ventana, joins, procesamiento de eventos basados en el tiempo, etc...
Kafka y el Big Data¶
El siguiente gráfico muestra cómo Kafka está enfocado principalmente para el tratamiento en streaming, aunque con los conectores de Kafka Connect da soporte para el procesamiento batch:
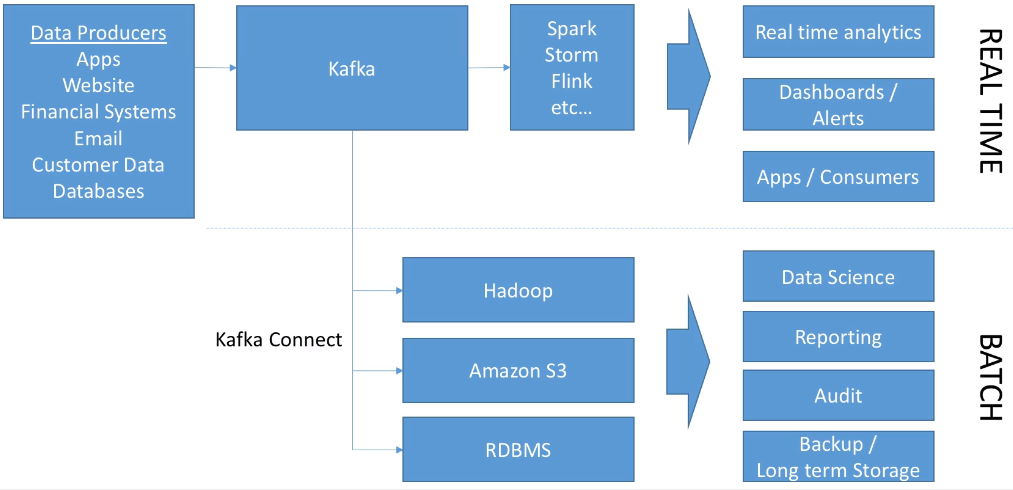
Si echamos la vista atrás y repasamos la arquitectura Kappa de Big Data podemos identificar que las diferentes fuentes de los datos se sustituyen por colas de Kafka permitiendo unir tanto la ingesta batch como en streaming, lo que facilita añadir tanto nuevas fuentes de datos como destinos, pudiendo realizar transformaciones en tiempo real o lanzar procesos más pesados para almacenar el histórico de los datos.
Elasticsearch y Twitter
En la edición de 21/22, en estas sesiones, realizamos diferentes casos de uso con Elasticsearch y Twitter.
Este curso no hemos visto Elasticsearch, y además, el API de Twitter ha dejado de ser gratuita. Si tienes curiosidad, puedes consultar dichos casos de uso en los apuntes del curso pasado.
Referencias¶
- Apache Kafka Series - Learn Apache Kafka for Beginners
- Serie de artículos de Víctor Madrid sobre Kafka en enmilocalfunciona.io.
- Distributed Databases: Kafka por Mikel del Tio.
- Introduction to Kafka Connectors
- Kafka Cheatsheet
Actividades¶
- (RA5075.1 / CE5.1b y CE5.1d / 1p) A partir del caso 2, crea un clúster de Kafka con 4 particiones y 3 nodos. A continuación, en el productor utiliza Faker para crear 10 personas (almacénalas como un diccionario). En el consumidor, muestra los datos de las personas (no es necesario recibirlos ordenados, sólo necesitamos que se aproveche al máximo la infraestructura de Kafka).
- (RA5075.1 / CE5.1b y CE5.1d / 1.5p) Realiza el caso de uso 3 mediante Python, pero separando el
consumidorSilverProductorGolden tres consumidores diferentes, uno que consuma y guarde en S3 (consumidorSilverS3.py), otro que consuma y guarde en MongoDB (consumidorSilverMongoDB.py) y el tercero que consuma, agrupe mensajes y produzca el mensaje al topic gold (consumidorSilverGroupProducerGold.py). - (RA5075.1 / CE5.1d / 1p) Realiza el caso de uso 4 mediante Nifi, pero modificando el primer flujo para que un grupo de procesadores únicamente realice la petición REST y coloque el contenido en topic
iabd-aemet-bronzey en un segundo grupo, se consuman los mensajes de ese topic y se realice la transformación de la petición REST y su posterior producción al topiciabd-aemet-silver. -
(RA5075.1 / CE5.1d / 1p) A partir del ejemplo realizado en el apartado de Kafka Connect, añade otro conector para que consuma los mensajes de la cola y los inserte en MongoDB de forma automática. Para ello, puedes utilizar el MongoDB Connector (Source and Sink) y consultar su documentación y un ejemplo de fichero de configuración.
Ten en cuenta que para lanzar los dos conectores a la ver deberás lanzar Kafka Connect y pasarle todos los conectores como parámetros:
connect-standalone.sh config/connect-standalone.properties config/mysql-source-connector.properties config/mongodb-sink-connector.properties -
(RA5075.1 / CE5.1a / 0.5p) Investiga en qué consiste el patrón CDC (Change Data Capture) y cómo se realiza CDC con Kafka/Kafka Connect, el procesador CaptureChangeMySQL de Nifi y el producto Debezium. ¿Qué ventajas aportan las soluciones CDC?